

Analysis of the Impact of Different Improvement Methods Based on YOLOV8 for Weed Detection
Abstract
1. Introduction
- (1)
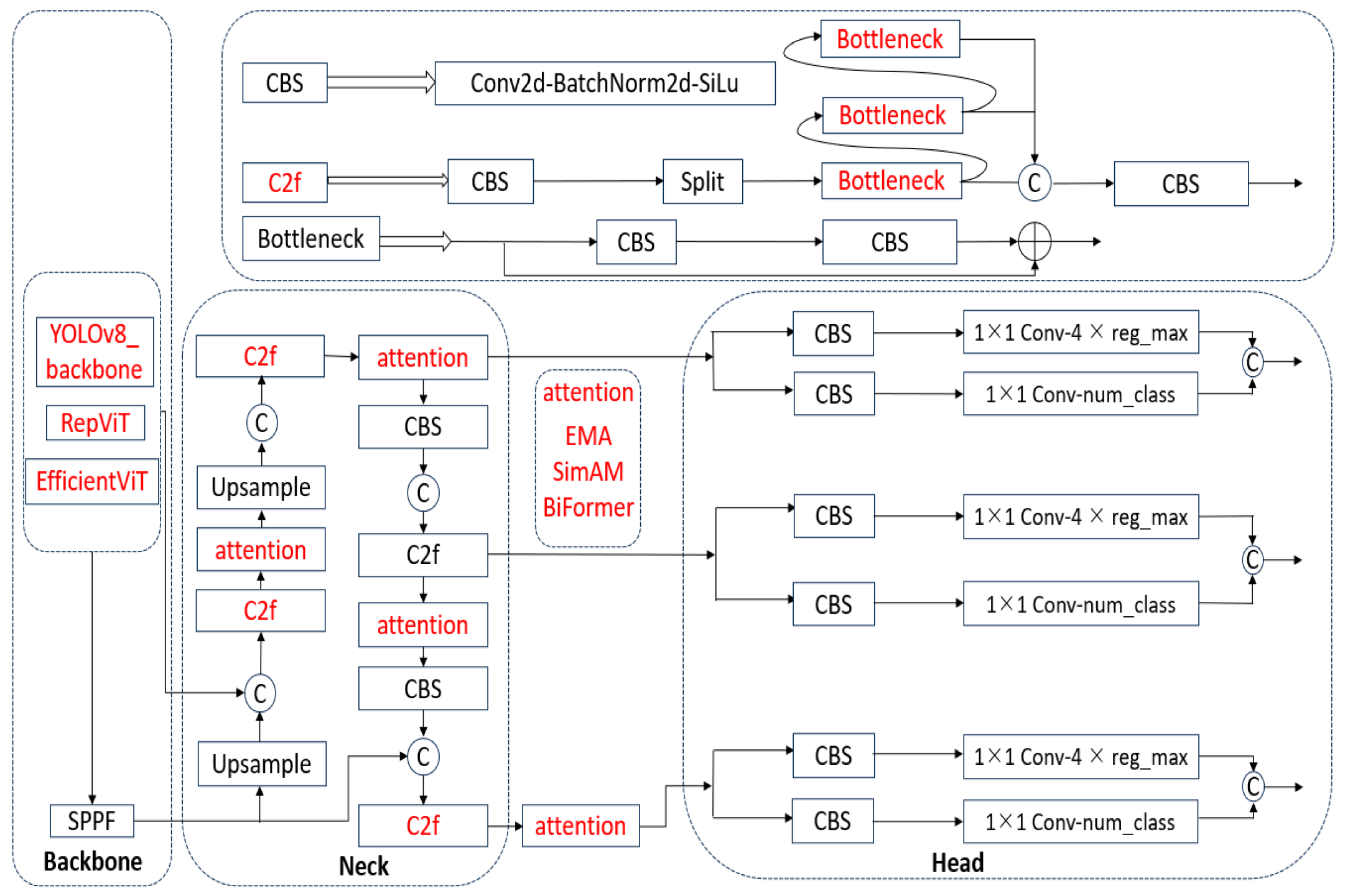
- The backbone network is enhanced by replacing the original backbone network with two alternatives: RepViT, a lightweight network, and EfficientViT, a dense object detection network.
- (2)
- In the improvement to the neck part, various attention mechanisms such as EMA, SimAM, and BiFormer are integrated to evaluate their impact on weed recognition accuracy. The optimal attention mechanism for the weed detection task is then selected based on comparative analysis.
- (3)
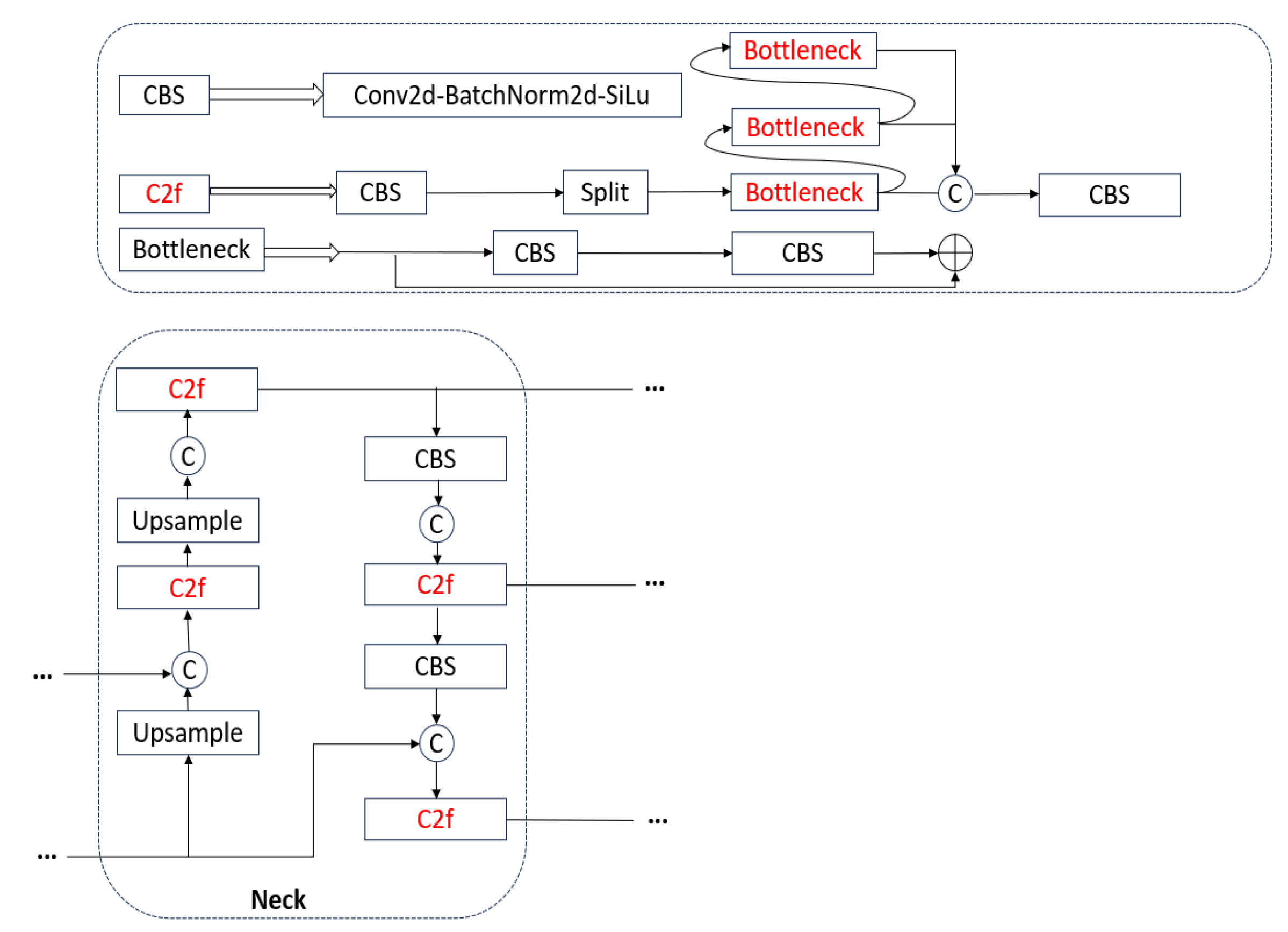
- Partial enhancements are made to the C2f module and BottleNeck by substituting ordinary convolution with dynamic snake convolution. This dynamic snake convolution improves the capability to extract features of needle-shaped elongated weeds.
- (4)
- The detection models established through different improvement methods underwent multiple experimental validations. Initially, various attention mechanisms and enhanced key modules were integrated into three different backbone networks. Subsequently, the performance of the improved models was tested on a weed dataset. Following this, ablation experiments were conducted to compare the effects of the three improvement methods on weed detection performance and select the optimal model suitable for the task. Finally, heatmap analysis was performed, visualizing feature maps using GradCam to analyze feature extraction.
2. Materials and Methods
2.1. Datasets
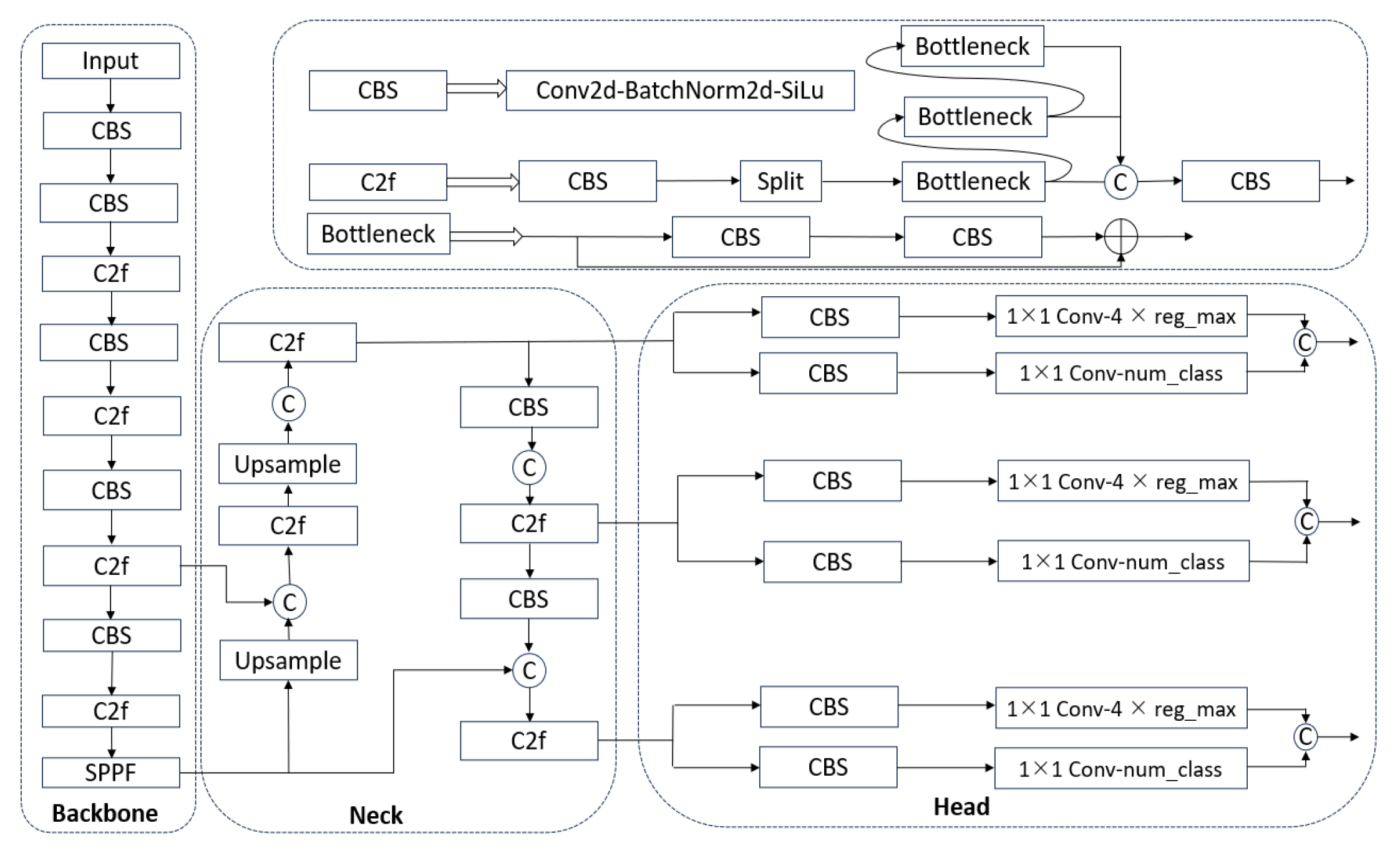
2.2. YOLOv8 Object Detection Algorithm
2.3. Backbone Network Improvements
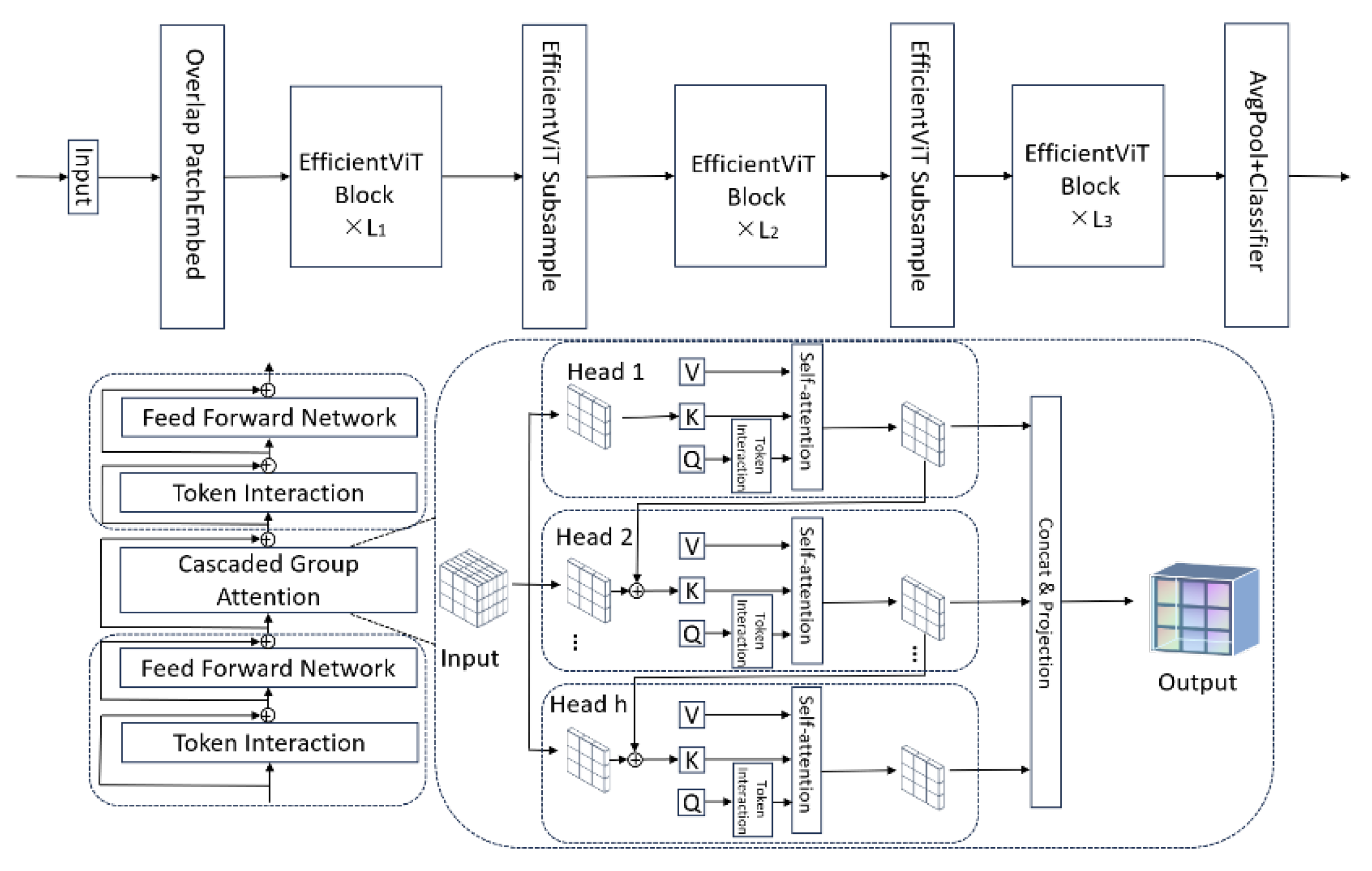
2.3.1. EfficientViT Dense Prediction Network
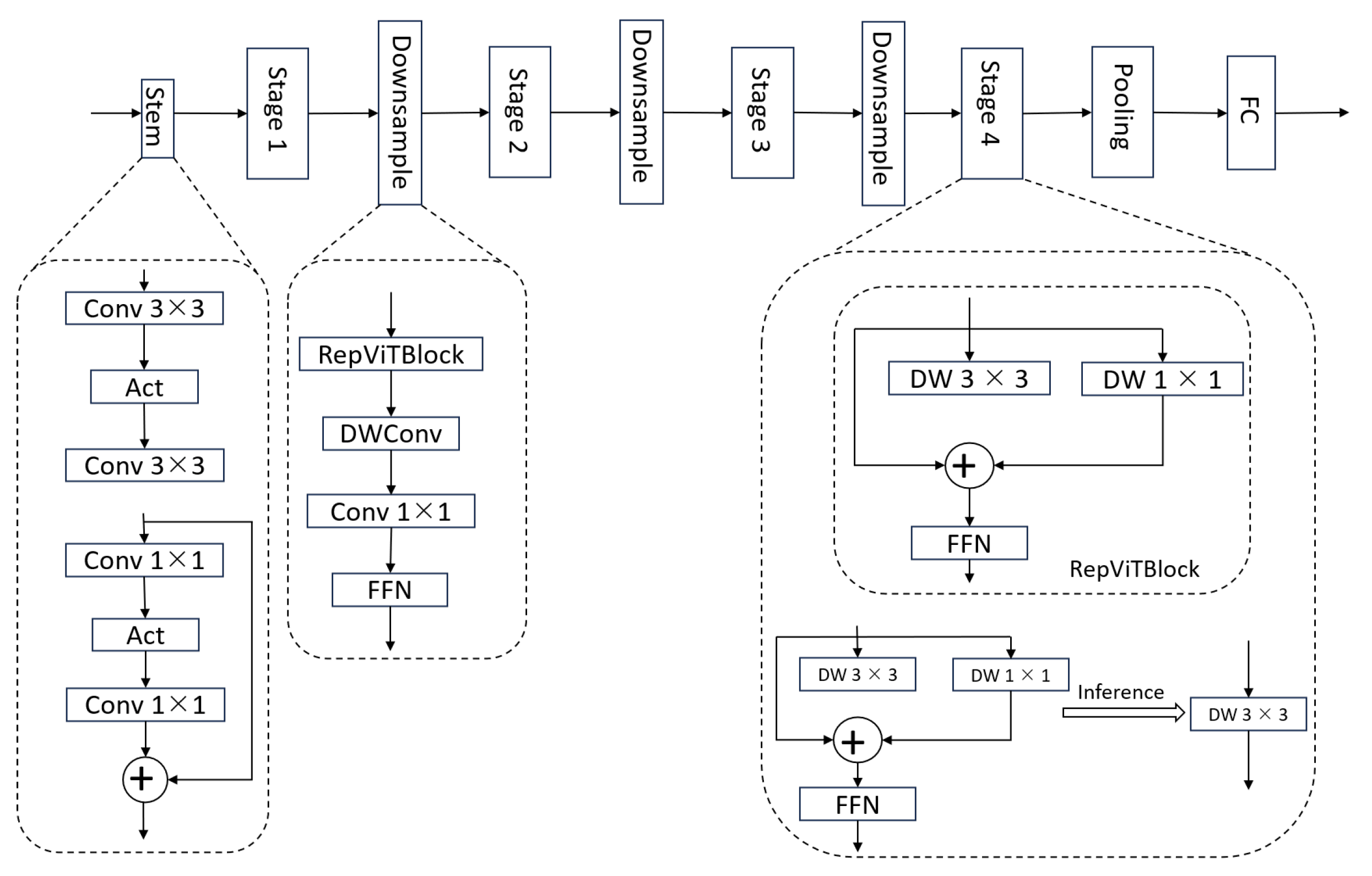
2.3.2. RepViT Lightweight Network
2.4. Key Module Improvements
Dynamic Snake Convolution
2.5. Attention Mechanisms
2.5.1. SimAM Attention Mechanism
2.5.2. EMA Attention Mechanism
- (1)
- Feature grouping: The input feature map is divided into G sub-features in order to learn different semantics;
- (2)
- Parallel sub-network: The parallel sub-network is divided into three branches, namely two 1 × 1 branches and one 3 × 3 branch. The former aggregates horizontal and vertical position coding through global average pooling, and the latter captures multi-scale features;
- (3)
- Cross-space learning: The outputs of 1 × 1 and 3 × 3 in the parallel sub-network are aggregated across spatial information in different spatial dimensional directions to realize different scales of feature fusion and capture more comprehensive contextual information.
2.5.3. BiFormer
- (1)
- Divide the input feature map into S × S lattices, and then obtain Q, K, and V by linear mapping.
- (2)
- Average the Q and K of each region to obtain the regional average values of and ; construct a directed graph to obtain the region in which each key–value pair in each region should be involved by means of the adjacency matrix, where the adjacency matrix can be expressed as below.
- (3)
- Calculate the routing index matrix by the adjacency matrix to obtain the most relevant top k regions for each region to participate in the fine-grained operation as relevant regions.
- (4)
- Since the routing regions are scattered throughout the feature map and are difficult to compute, they are first aggregated.
- (5)
- The aggregated , pairs use the attention operation to obtain the final attention.
2.6. Experiments
2.6.1. Experiment Protocol
- (1)
- To further validate the improved network’s ability to enhance performance in weed detection tasks, the improved network is first subjected to comparative experiments with the original network.
- (2)
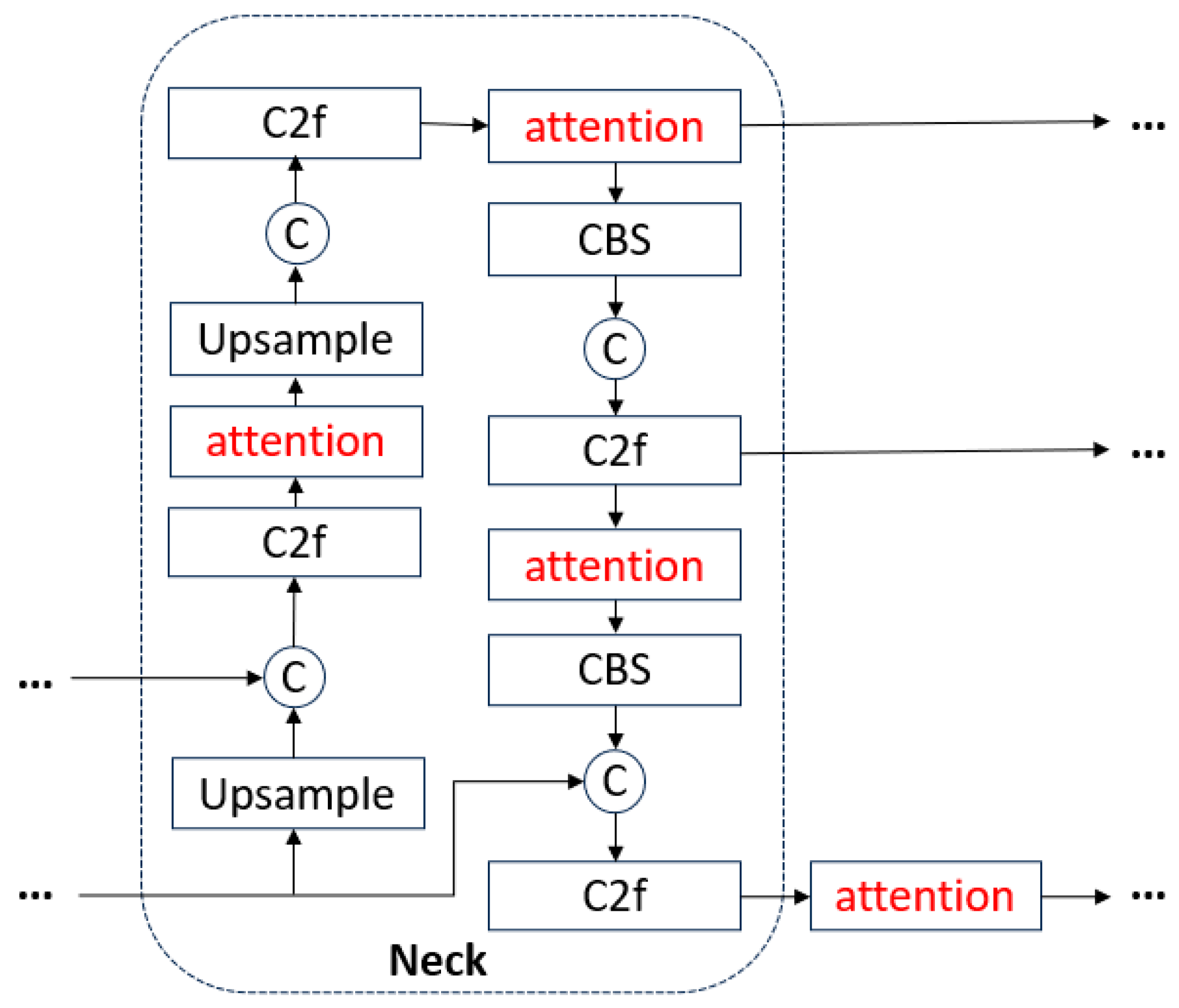
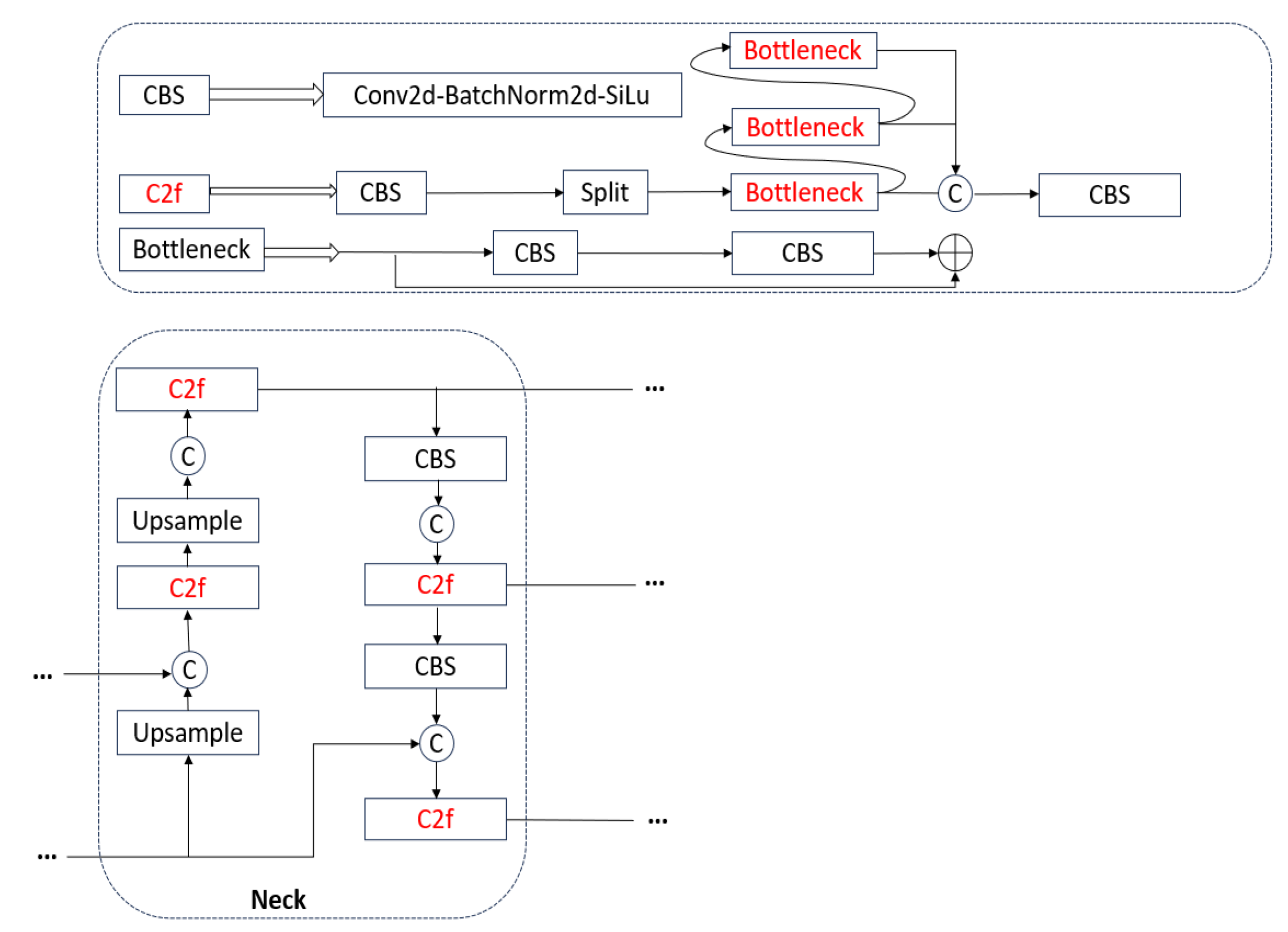
- Under the condition of equal training parameters, the improved backbone network is combined with various attention mechanisms and enhancements to important modules. The network structure of the improved model is illustrated in Figure 12, with the red color representing the three methods of improvement.
- (3)
- Following the comparison of individually enhanced models, Section 3 of this chapter will conduct ablation experiments to assess the extent to which different combinations of improvement methods affect weed detection performance. The optimal improvement method will be selected for application in weed detection tasks. This experiment is conducted on a Windows 10 Professional system, with PyTorch version 2.1.0 and CUDA version 12.1.0. Specific configurations are detailed in Table 1, and the hyperparameters for training the improved model are outlined in Table 2.
2.6.2. Evaluation Metrics
2.6.3. Results
3. Ablation Experiments
3.1. Analysis of Ablation Experiments Results
3.2. Heatmap Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Los Alamitos, CA, USA, 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; Kwon, Y.; Michael, K.; Fang, J.; Yifu, Z.; Wong, C.; Montes, D.J.Z.; et al. Ultralytics/Yolov5: V7.0—YOLOv5 SOTA Realtime Instance Segmentation 2022. Available online: https://ui.adsabs.harvard.edu/abs/2022zndo...3908559J/abstract (accessed on 19 April 2024).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLO 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 19 April 2024).
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y.M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Xu, K.; Li, H.; Cao, W.; Zhu, Y.; Chen, R.; Ni, J. Recognition of Weeds in Wheat Fields Based on the Fusion of RGB Images and Depth Images. IEEE Access 2020, 8, 110362–110370. [Google Scholar] [CrossRef]
- Xu, X.H.; Quan, H.R.; He, K.Y.; Wang, L.; Wang, X.Q.; Wang, Q. Proportional Fluorescence Sensing Analysis of Pesticide Residues in Agricultural Environment. Trans. Chin. Soc. Agric. Mach. 2020, 51, 229–234. [Google Scholar]
- Wang, B.J.; Lan, Y.B.; Chen, M.M.; Liu, B.H.; Wang, G.B.; Liu, H.T. Application Status and Prospect of Machine Learning in Unmanned Farm. J. Chin. Agric. Mech. 2021, 42, 186–192+217. [Google Scholar] [CrossRef]
- Yuan, T.; Hu, T.; Ma, C.; Li, L.Y.; Zheng, X.G.; Qian, D.L. Weed Target Detection Algorithm in Paddy Field Based on YOLOv4. Acta Agric. Shanghai 2023, 39, 109–117. [Google Scholar] [CrossRef]
- Coates, A.; Ng, A.Y. Learning Feature Representations with K-Means. In Neural Networks: Tricks of the Trade; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7700, pp. 561–580. [Google Scholar]
- Cao, Y.L.; Zhao, Y.W.; Yang, L.L.; Li, J.; Qin, L.L. Weed Ldentification Method in Rice Field Based on Improved DeepLabv3+. Trans. Chin. Soc. Agric. Mach. 2023, 54, 242–252. [Google Scholar]
- Shang, W.Q.; Qi, H.B. Identification Algorithm of Field Weeds Based on Improved Faster R-CNN and Transfer Learning. J. Chin. Agric. Mech. 2022, 43, 176–182. [Google Scholar] [CrossRef]
- Jiang, H.; Zhang, C.; Qiao, Y.; Zhang, Z.; Zhang, W.; Song, C. CNN Feature Based Graph Convolutional Network for Weed and Crop Recognition in Smart Farming. Comput. Electron. Agric. 2020, 174, 105450. [Google Scholar] [CrossRef]
- Wada, K. Labelme: Image Polygonal Annotation with Python. Available online: https://github.com/wkentaro/labelme (accessed on 19 April 2024).
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Li, X.; Hu, X.; Yang, J. Spatial Group-Wise Enhance: Improving Semantic Feature Learning in Convolutional Networks. arXiv 2019, arXiv:1905.09646. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. arXiv 2019, arXiv:1905.02244. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv 2016, arXiv:1608.06993. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. arXiv 2018, arXiv:1807.06521. [Google Scholar] [CrossRef]
- Webb, B.S.; Dhruv, N.T.; Solomon, S.G.; Tailby, C.; Lennie, P. Early and Late Mechanisms of Surround Suppression in Striate Cortex of Macaque. J. Neurosci. Off. J. Soc. Neurosci. 2005, 25, 11666–11675. [Google Scholar] [CrossRef] [PubMed]
- Qiao, S.; Shen, W.; Zhang, Z.; Wang, B.; Yuille, A. Deep Co-Training for Semi-Supervised Image Recognition. arXiv 2018, arXiv:1803.05984. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-Cam: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configure | Version/Model |
|---|---|
| CPU | Intel Xeon W-2223 |
| GPUs | GTX3090 |
| CUDA | 12.1 |
| Pytorch | 2.1.0 |
| Epoch | 300 |
|---|---|
| Batch | 16 |
| Learning Rate | 0.01 |
| IOU | 0.7 |
| Classes | 3 |
| Improved Methodology | Accuracy/% | Recall Rate/% | mAP(0.5)% | mAP(0.50:95)/% |
|---|---|---|---|---|
| YOLOv8 | 91.1 | 88.4 | 90.5 | 83.3 |
| DCNv3 | 91.9 | 89.3 | 96.2 | 83.7 |
| DySkD | 96.7 | 94.2 | 96.9 | 84.3 |
| SimAM | 95.6 | 90.7 | 96.4 | 82.5 |
| EMA | 96.2 | 91.1 | 96.2 | 82.3 |
| BiFormer | 95.0 | 93.9 | 95.7 | 83.1 |
| YOLOv8_DSEB | 95.9 | 94.3 | 96.5 | 83.8 |
| Improved Methodology | Accuracy/% | Recall Rate/% | mAP(0.5)/% | mAP(0.5:0.95)/% |
|---|---|---|---|---|
| EfficientViT | 96.0 | 93.7 | 96.5 | 84.0 |
| DCNv3 | 96.5 | 91.8 | 95.6 | 83.4 |
| DySkD | 96.3 | 92.5 | 96.5 | 83.4 |
| SimAM | 97.0 | 92.6 | 96.4 | 83.3 |
| EMA | 96.7 | 92.1 | 96.6 | 83.8 |
| BiFormer | 97.4 | 93.1 | 96.5 | 84.1 |
| YOLOv8_EDSEB | 96.7 | 93.1 | 96.4 | 83.3 |
| Improved Methodology | Accuracy/% | Recall Rate/% | mAP(0.5)/% | mAP(0.5:0.95)/% |
|---|---|---|---|---|
| RepViT | 96.1 | 92.3 | 96.0 | 83.1 |
| DCNv3 | 96.5 | 91.8 | 95.6 | 83.4 |
| DySkD | 96.9 | 92.5 | 96.6 | 83.4 |
| SimAM | 96.0 | 93.9 | 96.4 | 83.3 |
| EMA | 96.3 | 92.2 | 96.5 | 83.3 |
| BiFormer | 96.5 | 93.7 | 96.3 | 83.2 |
| YOLOv8_RDSEB | 95.9 | 93.3 | 96.5 | 83.4 |
| Improvement Methods | Precision/% | Recall/% | mAP(0.5)/% | mAP(0.5:0.95)% |
|---|---|---|---|---|
| YOLOv8 | 91.1 | 88.4 | 90.5 | 83.3 |
| YOLOv8 + Dynamic snake | 96.7 | 94.2 | 96.9 | 84.3 |
| YOLOv8 + Dynamic snake + SimAM | 97.0 | 93.3 | 96.8 | 84.2 |
| YOLOv8 + Dynamic snake + EMA | 95.6 | 94.2 | 96.7 | 83.9 |
| YOLOv8 + Dynamic snake +BiFormer | 95.1 | 93.3 | 96.2 | 83.6 |
| Improvement Methods | Precision/% | Recall/% | mAP(0.5)/% | mAP(0.5:0.95)% |
|---|---|---|---|---|
| EfficientViT | 96.0 | 93.7 | 96.5 | 84.0 |
| EfficientViT + Dynamic snake | 96.3 | 92.5 | 96.5 | 83.4 |
| EfficientViT + Dynamic snake + SimAM | 97.1 | 94.3 | 96.9 | 84.1 |
| EfficientViT + Dynamic snake + EMA | 97.3 | 92.7 | 96.6 | 83.6 |
| EfficientViT + Dynamic snake + BiFormer | 95.6 | 92.8 | 96.6 | 83.6 |
| Improvement Methods | Precision/% | Recall/% | mAP(0.5)/% | mAP(0.5:0.95)% |
|---|---|---|---|---|
| RepViT | 96.1 | 92.3 | 96.0 | 83.1 |
| RepViT + Dynamic snake | 96.9 | 92.5 | 96.6 | 83.4 |
| RepViT + Dynamic snake + SimAM | 97.0 | 92.4 | 96.3 | 83.4 |
| RepViT + Dynamic snake + EMA | 95.4 | 93.5 | 96.2 | 83.2 |
| RepViT + Dynamic snake + BiFormer | 95.1 | 93.3 | 96.2 | 83.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, C.; Wan, F.; Ma, G.; Mou, X.; Zhang, K.; Wu, X.; Huang, X. Analysis of the Impact of Different Improvement Methods Based on YOLOV8 for Weed Detection. Agriculture 2024, 14, 674. https://doi.org/10.3390/agriculture14050674
He C, Wan F, Ma G, Mou X, Zhang K, Wu X, Huang X. Analysis of the Impact of Different Improvement Methods Based on YOLOV8 for Weed Detection. Agriculture. 2024; 14(5):674. https://doi.org/10.3390/agriculture14050674
Chicago/Turabian StyleHe, Cuncai, Fangxin Wan, Guojun Ma, Xiaobin Mou, Kaikai Zhang, Xiangfeng Wu, and Xiaopeng Huang. 2024. "Analysis of the Impact of Different Improvement Methods Based on YOLOV8 for Weed Detection" Agriculture 14, no. 5: 674. https://doi.org/10.3390/agriculture14050674
APA StyleHe, C., Wan, F., Ma, G., Mou, X., Zhang, K., Wu, X., & Huang, X. (2024). Analysis of the Impact of Different Improvement Methods Based on YOLOV8 for Weed Detection. Agriculture, 14(5), 674. https://doi.org/10.3390/agriculture14050674