
Improved YOLOv5 Network for Detection of Peach Blossom Quantity

Abstract
1. Introduction
- (1)
- A peach flower image dataset is constructed (a total of 5000 images) to provide data support for the training and validation of the peach flower detection model.
- (2)
- An additional layer dedicated to small object detection is added. Because it is fused with shallower feature maps, the new feature map has strong semantic information and precise location information, which can be used to improve the detection rate of buds.
- (3)
- The combination of a context extraction module (CAM) and a feature refinement module (FSM) is adopted. The CAM module is used to extract context information, while feature refinement through the FSM module can further suppress conflicting information and improve the accuracy of flower detection.
- (4)
- To improve model performance, the K-means++ algorithm is used to help the initial clustering center escape the local optimum and reach the global optimum, while the SIoU loss function replaces the original CIoU function in order to more fully consider the influence of the vector direction between the ground truth box and the predicted box while providing faster model convergence.
2. Materials and Methods
2.1. Image Dataset
2.1.1. Image Acquisition
2.1.2. Image Processing
2.2. Research Methods
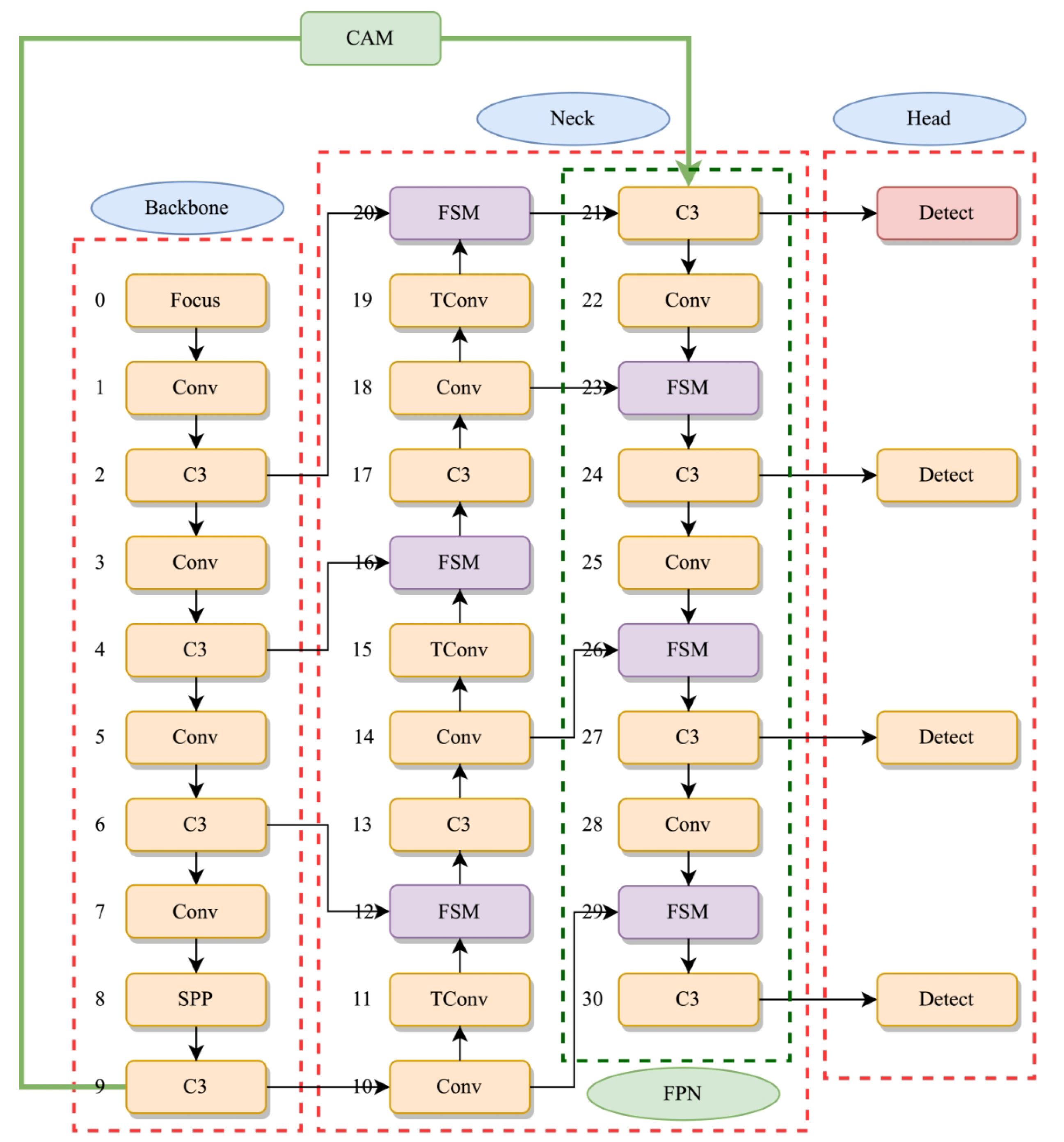
2.2.1. Small Object Detection Layer
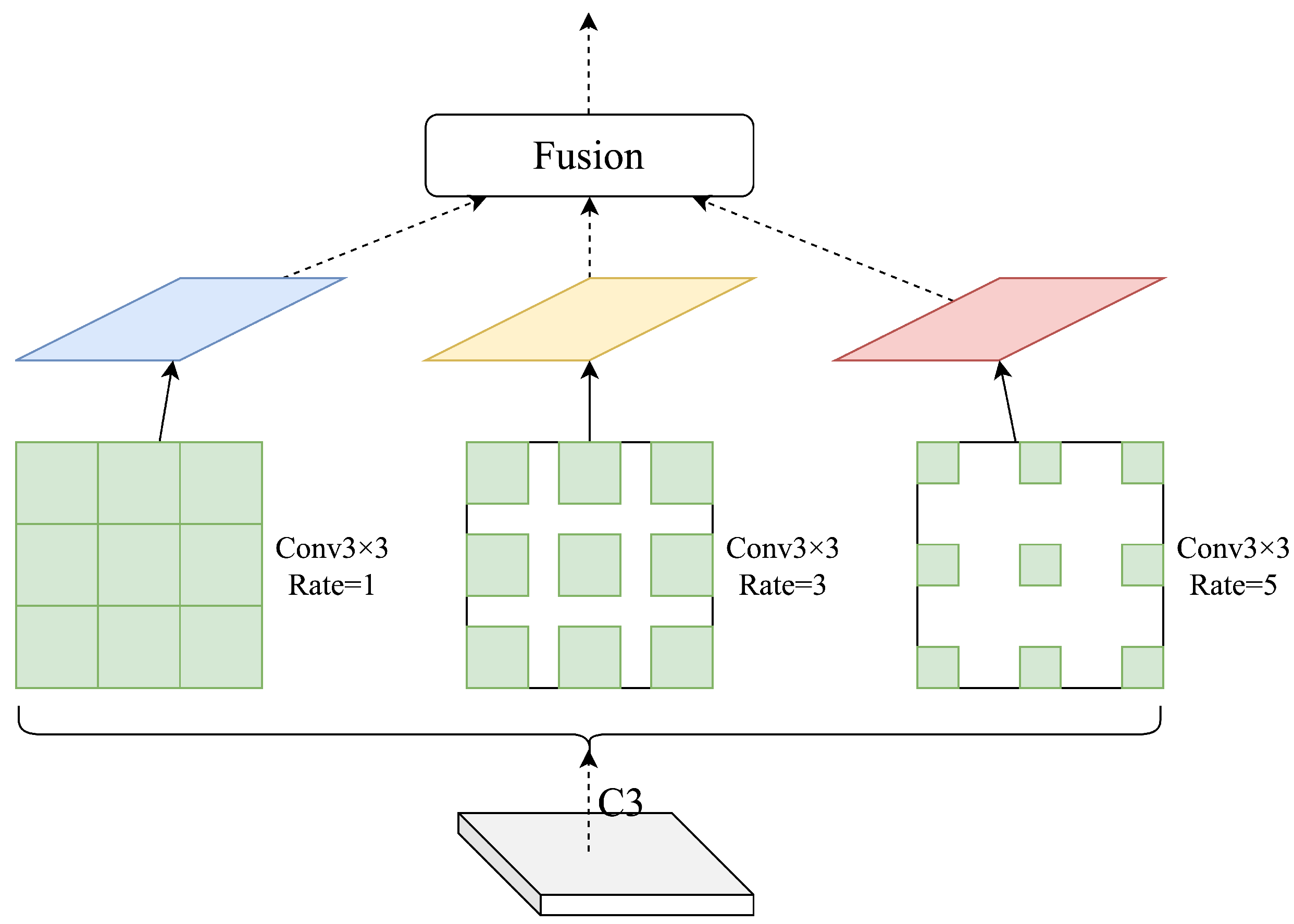
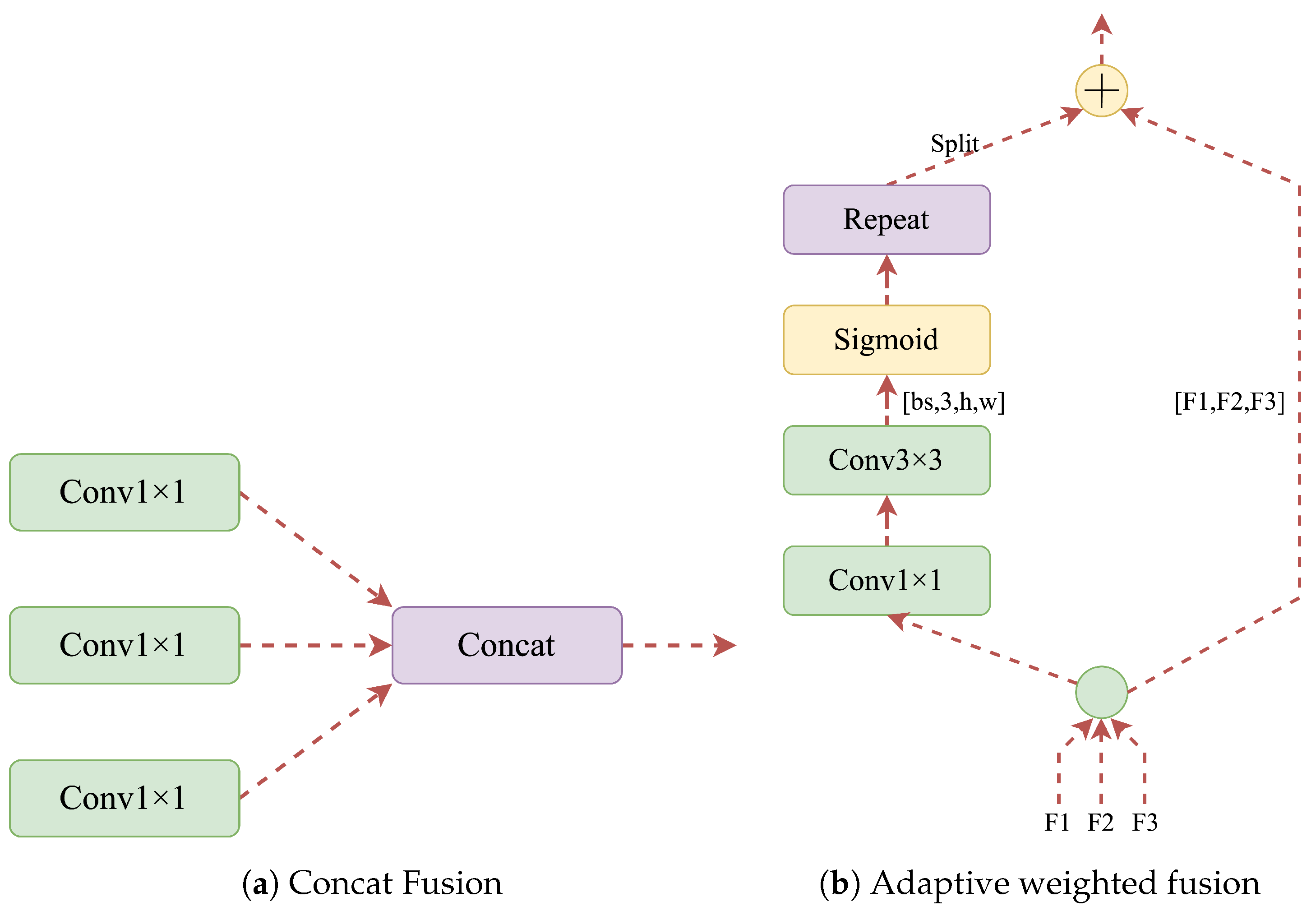
2.2.2. Context Enhancement Module
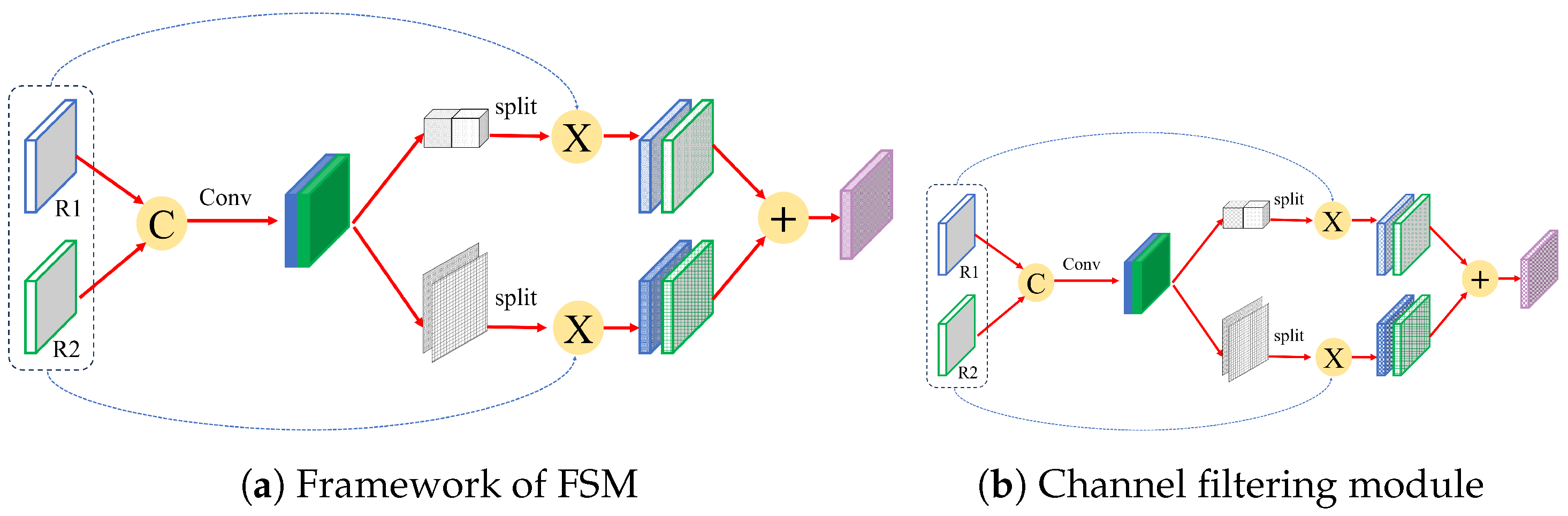
2.2.3. Feature Refinement Module
2.2.4. K-Means++ Custom Anchor Box
- (1)
- Randomly select a label box as the cluster center (Center1).
- (2)
- Calculate the shortest distance between the other annotation boxes and all current cluster centers. Based on the shortest distance result, calculate the probability of each annotation box being selected as the next cluster center and select the next cluster center based on this probability. Iterate the process until x cluster centers are selected.
- (3)
- After determining the cluster center, calculate the Distance between each annotation box and each cluster center, then assign them to the nearest cluster center. Based on this, calculate the mean of all annotation boxes contained in each cluster center in each dimension and update them to reflect the new cluster center. Iterate this process until the set number of iterations is reached or the cluster center no longer changes, then output x cluster center attributes. In the above process, the calculation formulas for the shortest distance , Distance, and probability are shown in Equations (8)–(10), respectively:
2.2.5. Improved Loss Function
2.3. Experimental Environment and Parameter Settings
2.4. Evaluation Index
3. Results
3.1. Impact of Improvement Methods on Model Performance
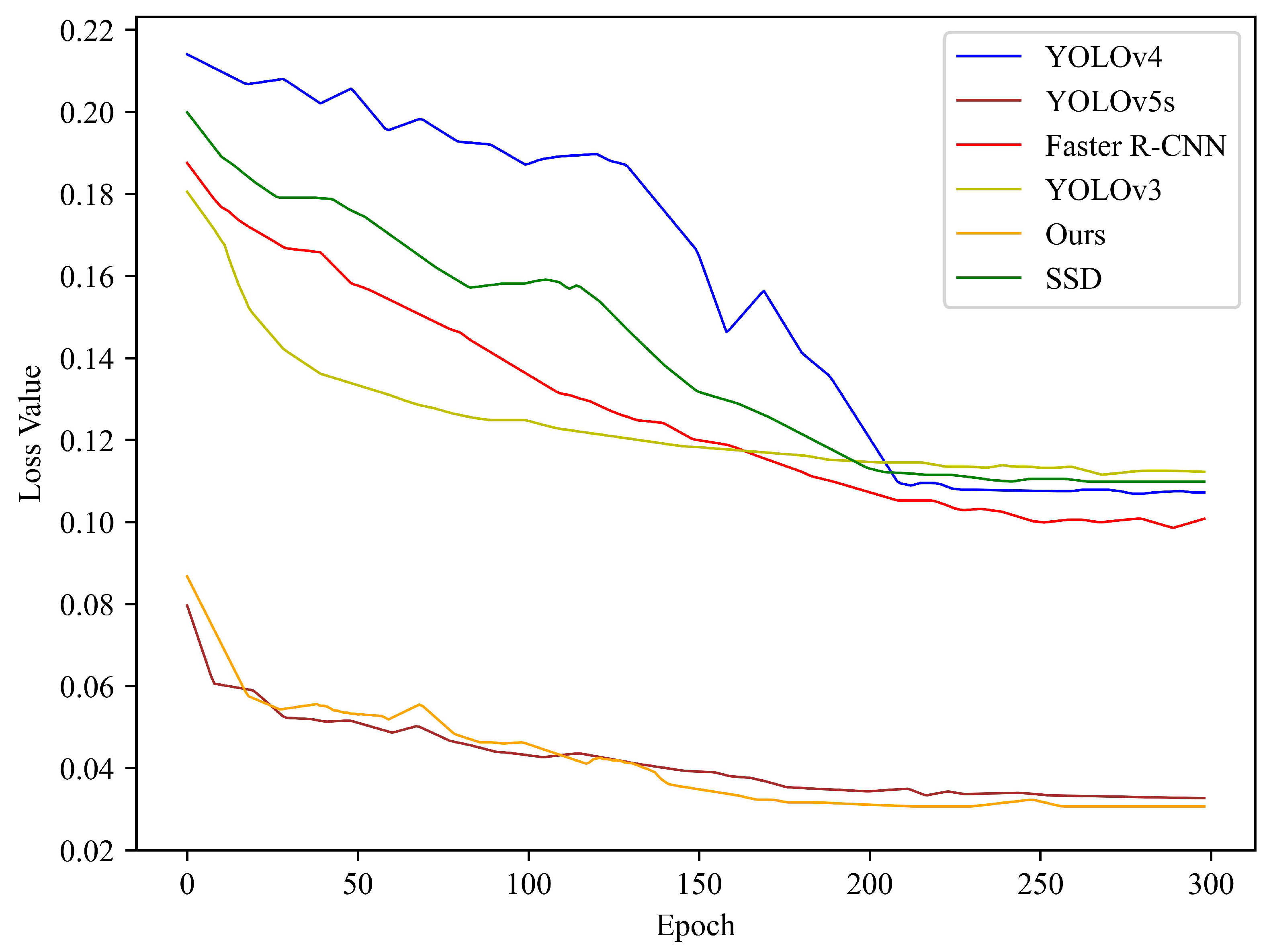
3.2. Performance Comparison of Mainstream Target Detection Models
3.3. Comparison of Loss Values
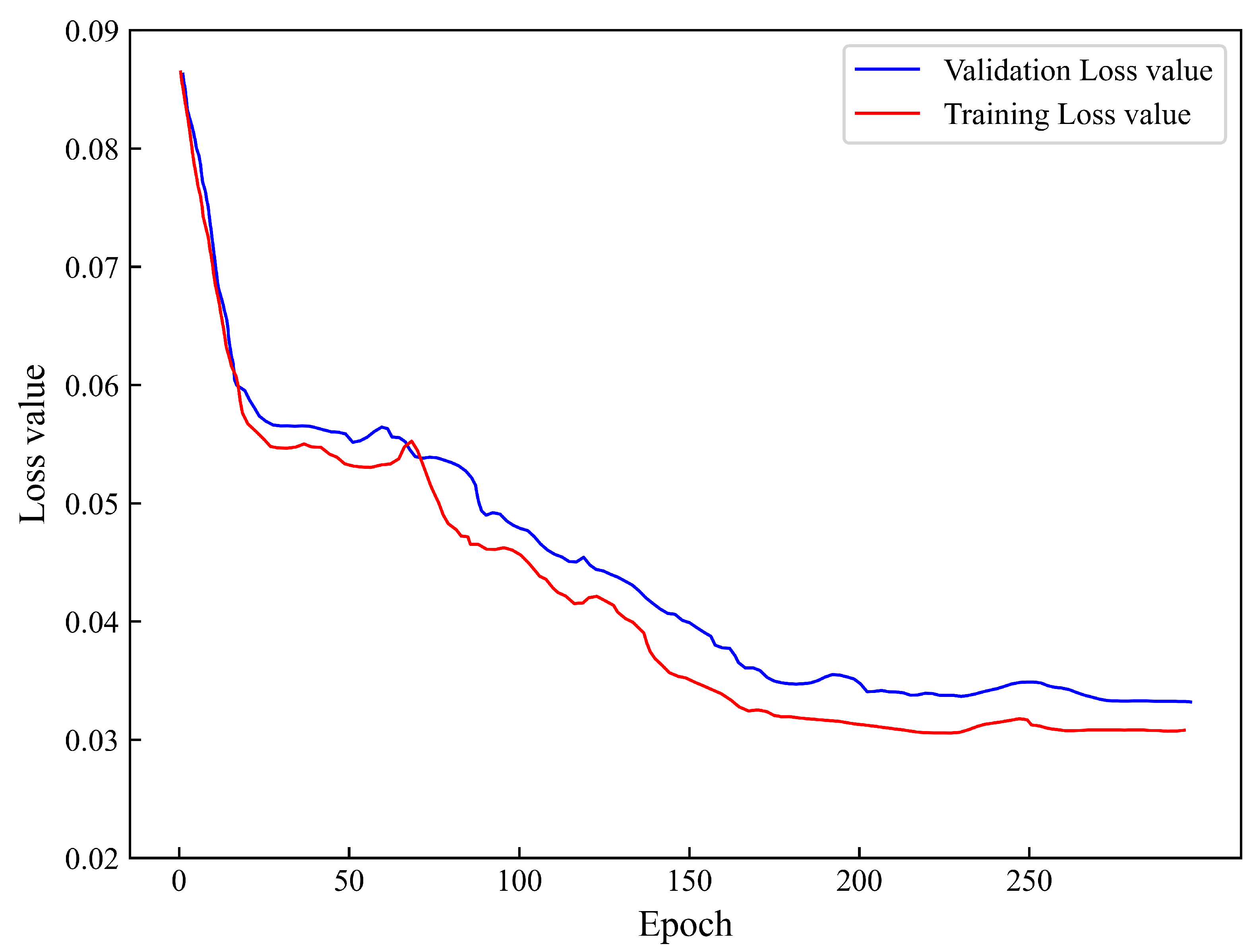
3.4. Model Application
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lakso, A.; Robinson, T. Principles of orchard systems management optimizing supply, demand and partitioning in apple trees. In Proceedings of the VI International Symposium on Integrated Canopy, Rootstock, Environmental Physiology in Orchard Systems 451, Wenatchee, WA, USA, Penticton, BC, Canada, 17 July 1996; pp. 405–416. [Google Scholar]
- He, L.; Fang, W.; Zhao, G.; Wu, Z.; Fu, L.; Li, R.; Majeed, Y.; Dhupia, J. Fruit yield prediction and estimation in orchards: A state-of-the-art comprehensive review for both direct and indirect methods. Comput. Electron. Agric. 2022, 195, 106812. [Google Scholar] [CrossRef]
- Jimenez, C.M.; Díaz, J.B.R. A statistical model to estimate potential yields in peach before bloom. J. Am. Soc. Hortic. Sci. 2003, 128, 297–301. [Google Scholar] [CrossRef]
- Chanana, Y.; Kaur, B.; Kaundal, G.; Singh, S. Effect of flowers and fruit thinning on maturity, yield and quality in peach (Prunus persica Batsch). Indian J. Hortic. 1998, 55, 323–326. [Google Scholar]
- Link, H. Significance of flower and fruit thinning on fruit quality. Plant Growth Regul. 2000, 31, 17–26. [Google Scholar] [CrossRef]
- Dennis, F.J. The history of fruit thinning. Plant Growth Regul. 2000, 31, 1–16. [Google Scholar] [CrossRef]
- Netsawang, P.; Damerow, L.; Lammers, P.S.; Kunz, A.; Blanke, M. Alternative approaches to chemical thinning for regulating crop load and alternate bearing in apple. Agronomy 2022, 13, 112. [Google Scholar] [CrossRef]
- Kong, T.; Damerow, L.; Blanke, M. Influence on apple trees of selective mechanical thinning on stress-induced ethylene synthesis, yield, fruit quality, (fruit firmness, sugar, acidity, colour) and taste. Erwerbs-Obstbau 2009, 51, 39–53. [Google Scholar] [CrossRef]
- Romano, A.; Torregrosa, A.; Balasch, S.; Ortiz, C. Laboratory device to assess the effect of mechanical thinning of flower buds, flowers and fruitlets related to fruitlet developing stage. Agronomy 2019, 9, 668. [Google Scholar] [CrossRef]
- Kon, T.M.; Schupp, J.R.; Yoder, K.S.; Combs, L.D.; Schupp, M.A. Comparison of chemical blossom thinners using ‘Golden Delicious’ and ‘Gala’pollen tube growth models as timing aids. HortScience 2018, 53, 1143–1151. [Google Scholar] [CrossRef]
- Penzel, M.; Pflanz, M.; Gebbers, R.; Zude-Sasse, M. Tree-adapted mechanical flower thinning prevents yield loss caused by over-thinning of trees with low flower set in apple. Eur. J. Hortic. Sci. 2021, 86, 88–98. [Google Scholar] [CrossRef]
- Aggelopoulou, A.; Bochtis, D.; Fountas, S.; Swain, K.C.; Gemtos, T.; Nanos, G. Yield prediction in apple orchards based on image processing. Precis. Agric. 2011, 12, 448–456. [Google Scholar] [CrossRef]
- Krikeb, O.; Alchanatis, V.; Crane, O.; Naor, A. Evaluation of apple flowering intensity using color image processing for tree specific chemical thinning. Adv. Anim. Biosci. 2017, 8, 466–470. [Google Scholar] [CrossRef]
- Hočevar, M.; Širok, B.; Godeša, T.; Stopar, M. Flowering estimation in apple orchards by image analysis. Precis. Agric. 2014, 15, 466–478. [Google Scholar] [CrossRef]
- Wang, Z.; Verma, B.; Walsh, K.B.; Subedi, P.; Koirala, A. Automated mango flowering assessment via refinement segmentation. In Proceedings of the 2016 International Conference on Image and Vision Computing New Zealand (IVCNZ), Palmerston North, New Zealand, 21–22 November 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–6. [Google Scholar]
- Wang, Z.; Underwood, J.; Walsh, K.B. Machine vision assessment of mango orchard flowering. Comput. Electron. Agric. 2018, 151, 501–511. [Google Scholar] [CrossRef]
- Zhang, Z.; Luo, M.; Guo, S.; Liu, G.; Li, S.; Zhang, Y. Cherry fruit detection method in natural scene based on improved yolo v5. Trans. Chin. Soc. Agric. Mach. 2022, 53, 232–240. [Google Scholar]
- Dias, P.A.; Tabb, A.; Medeiros, H. Apple flower detection using deep convolutional networks. Comput. Ind. 2018, 99, 17–28. [Google Scholar] [CrossRef]
- Dias, P.A.; Tabb, A.; Medeiros, H. Multispecies fruit flower detection using a refined semantic segmentation network. IEEE Robot. Autom. Lett. 2018, 3, 3003–3010. [Google Scholar] [CrossRef]
- Sun, K.; Wang, X.; Liu, S.; Liu, C. Apple, peach, and pear flower detection using semantic segmentation network and shape constraint level set. Comput. Electron. Agric. 2021, 185, 106150. [Google Scholar] [CrossRef]
- Wang, X.A.; Tang, J.; Whitty, M. Side-view apple flower mapping using edge-based fully convolutional networks for variable rate chemical thinning. Comput. Electron. Agric. 2020, 178, 105673. [Google Scholar] [CrossRef]
- Wang, X.A.; Tang, J.; Whitty, M. DeepPhenology: Estimation of apple flower phenology distributions based on deep learning. Comput. Electron. Agric. 2021, 185, 106123. [Google Scholar] [CrossRef]
- Tian, Y.; Yang, G.; Wang, Z.; Wang, H.; Li, E.; Liang, Z. Apple detection during different growth stages in orchards using the improved yolo-v3 model. Comput. Electron. Agric. 2019, 157, 417–426. [Google Scholar] [CrossRef]
- Farjon, G.; Krikeb, O.; Hillel, A.B.; Alchanatis, V. Detection and counting of flowers on apple trees for better chemical thinning decisions. Precis. Agric. 2020, 21, 503–521. [Google Scholar] [CrossRef]
- Wu, D.; Lv, S.; Jiang, M.; Song, H. Using channel pruning-based yolo v4 deep learning algorithm for the real-time and accurate detection of apple flowers in natural environments. Comput. Electron. Agric. 2020, 178, 105742. [Google Scholar] [CrossRef]
- Tian, Y.; Yang, G.; Wang, Z.; Li, E.; Liang, Z. Instance segmentation of apple flowers using the improved mask R–CNN model. Biosyst. Eng. 2020, 193, 264–278. [Google Scholar] [CrossRef]
- Xia, Y.; Lei, X.; Herbst, A.; Lyu, X. Research on pear inflorescence recognition based on fusion attention mechanism 77 with yolov5. INMATEH-Agric. Eng. 2023, 69, 11–20. [Google Scholar] [CrossRef]
- Shang, Y.; Zhang, Q.; Song, H. Application of deep learning using yolov5s to apple flower detection in natural scenes. Trans. Chin. Soc. Agric. Eng. 2022, 9, 222–229. [Google Scholar]
- Tao, K.; Wang, A.; Shen, Y.; Lu, Z.; Peng, F.; Wei, X. Peach flower density detection based on an improved cnn incorporating attention mechanism and multi-scale feature fusion. Horticulturae 2022, 8, 904. [Google Scholar] [CrossRef]
- Andriyanov, N.; Khasanshin, I.; Utkin, D.; Gataullin, T.; Ignar, S.; Shumaev, V.; Soloviev, V. Intelligent system for estimation of the spatial position of apples based on yolov3 and real sense depth camera D415. Symmetry 2022, 14, 148. [Google Scholar] [CrossRef]
- Fan, S.; Liang, X.; Huang, W.; Zhang, V.J.; Pang, Q.; He, X.; Li, L.; Zhang, C. Real-time defects detection for apple sorting using NIR cameras with pruning-based yolov4 network. Comput. Electron. Agric. 2022, 193, 106715. [Google Scholar] [CrossRef]
- Li, Y.; Wang, J.; Wu, H.; Yu, Y.; Sun, H.; Zhang, H. Detection of powdery mildew on strawberry leaves based on dac-yolov4 model. Comput. Electron. Agric. 2022, 202, 107418. [Google Scholar] [CrossRef]
- Yan, B.; Fan, P.; Lei, X.; Liu, Z.; Yang, F. A real-time apple targets detection method for picking robot based on improved yolov5. Remote Sens. 2021, 13, 1619. [Google Scholar] [CrossRef]
- Wang, Z.; Jin, L.; Wang, S.; Xu, H. Apple stem/calyx real-time recognition using yolo-v5 algorithm for fruit automatic loading system. Postharvest Biol. Technol. 2022, 185, 111808. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Arthur, D.; Vassilvitskii, S. How slow is the k-means method? In Proceedings of the Twenty-Second Annual Symposium on Computational Geometry, Sedona, AZ, USA, 5–7 June 2006; pp. 144–153. [Google Scholar]
- Gevorgyan, Z. Siou loss: More powerful learning for bounding box regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Horton, R.; Cano, E.; Bulanon, D.; Fallahi, E. Peach flower monitoring using aerial multispectral imaging. J. Imaging 2017, 3, 2. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | mAP/% | FPS |
|---|---|---|
| YOLOv5s | 83.1 | 45.61 |
| YOLOv5s + CAM + concat | 86.2 | 44.89 |
| YOLOv5s + CAM + weight | 85.1 | 44.86 |
| Adopt Module | mAP/% |
|---|---|
| Concat | 83.1 |
| FSM | 87.9 |
| Feature Map Scale | Anchor Box Size | ||
|---|---|---|---|
| Anchor Box 1 | Anchor Box 2 | Anchor Box 3 | |
| 80 × 80 | [10, 13] | [16, 30] | [33, 23] |
| 40 × 40 | [30, 61] | [62, 45] | [59, 119] |
| 20 × 20 | [116, 90] | [156, 198] | [373, 326] |
| Parameter Name | Value |
|---|---|
| Iterations | 300 epochs |
| Learning rate | 0.01 |
| Momentum factor | 0.973 |
| Batch size | 16 |
| IOU threshold | 0.5 |
| Small Object Detection Layer | CAM | FSM | K-Means++ | SIOU | mAP/% | FPS |
|---|---|---|---|---|---|---|
| - | - | - | - | - | 83.1 | 45.61 |
| - | - | - | - | 87.9 | 44.98 | |
| - | - | - | - | 86.2 | 44.86 | |
| - | - | - | - | 86.6 | 44.62 | |
| - | - | - | - | 84.7 | 45.13 | |
| - | - | - | - | 84.9 | 45.21 | |
| - | - | - | 88.3 | 43.17 | ||
| - | - | 88.9 | 39.31 | |||
| - | 89.5 | 38.86 | ||||
| 90.2 | 38.67 |
| Model | P/% | R/% | AP/% (IOU = 0.5) | mAP/% | FPS | ||
|---|---|---|---|---|---|---|---|
| Bud | Blossom | Faded | |||||
| SSD | 71.2 | 88.7 | 74.3 | 72.4 | 77.6 | 74.5 | 32.26 |
| Faster R-CNN | 79.8 | 89.1 | 83.9 | 81.7 | 86.7 | 84.1 | 25.88 |
| YOLOv3 | 82.5 | 81.2 | 78.0 | 79.2 | 88.5 | 81.9 | 31.12 |
| YOLOv4 | 82.7 | 86.8 | 84.4 | 83.4 | 86.9 | 84.9 | 36.52 |
| YOLOv5s | 83.3 | 90.4 | 79.7 | 79.7 | 89.9 | 83.1 | 45.61 |
| Our Method | 90.1 | 93.2 | 87.5 | 89.8 | 93.3 | 90.2 | 38.67 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, L.; Yao, J.; Cao, H.; Chen, H.; Teng, G. Improved YOLOv5 Network for Detection of Peach Blossom Quantity. Agriculture 2024, 14, 126. https://doi.org/10.3390/agriculture14010126
Sun L, Yao J, Cao H, Chen H, Teng G. Improved YOLOv5 Network for Detection of Peach Blossom Quantity. Agriculture. 2024; 14(1):126. https://doi.org/10.3390/agriculture14010126
Chicago/Turabian StyleSun, Li, Jingfa Yao, Hongbo Cao, Haijiang Chen, and Guifa Teng. 2024. "Improved YOLOv5 Network for Detection of Peach Blossom Quantity" Agriculture 14, no. 1: 126. https://doi.org/10.3390/agriculture14010126
APA StyleSun, L., Yao, J., Cao, H., Chen, H., & Teng, G. (2024). Improved YOLOv5 Network for Detection of Peach Blossom Quantity. Agriculture, 14(1), 126. https://doi.org/10.3390/agriculture14010126