


AG-YOLO: A Rapid Citrus Fruit Detection Algorithm with Global Context Fusion


Abstract
1. Introduction
- (1)
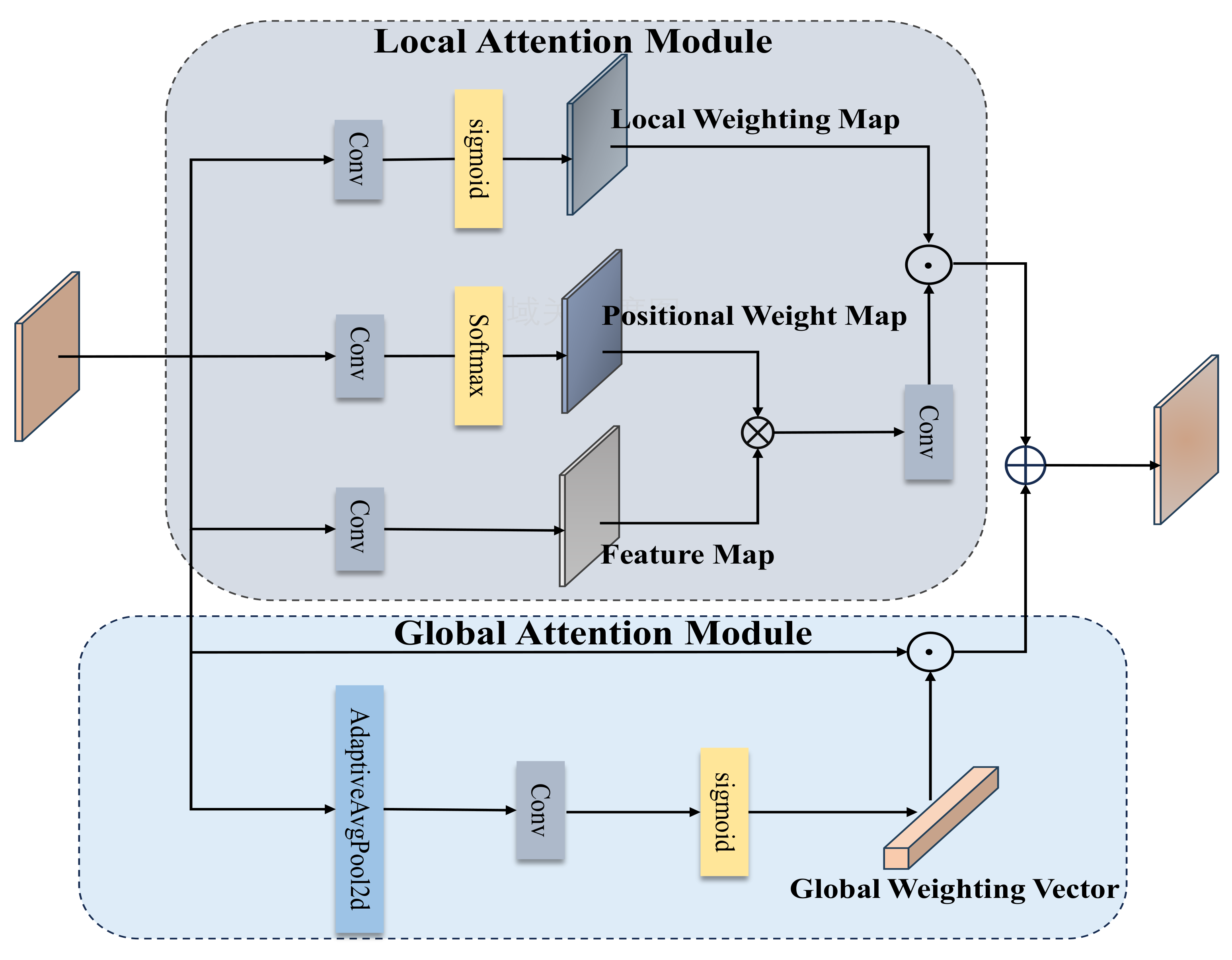
- The study introduces the Global Context Fusion Module (GCFM) to effectively merge local and global contexts. In contrast to conventional methodologies, the GCFM employs self-attention mechanisms to selectively emphasize essential features of occluded targets. Moreover, it enables interaction and fusion between occluded regions and other image areas, facilitating a more comprehensive understanding of the image’s semantic content and structural composition. This utilization of global context information notably enhances the model’s capacity to discern the relationship between occluded fruit targets and their background, thereby improving the detection capability for such occluded targets.
- (2)
- The utilization of NextViT as the backbone network highlights its superior global perception and representation capabilities compared to traditional convolutional neural networks, attributed to its Vision Transformer-based architecture. The Transformer (Vaswani et al. 2017) [28] architecture of NextViT provides the network with extensive global awareness, allowing it to process information from all areas across the input image simultaneously, rather than focusing solely on localized regions.This capability proves particularly advantageous for addressing challenges in object detection tasks involving issues like occlusion and scale variations.
- (3)
- To meet the training requirements of the proposed model in this paper, a dataset specifically for occluded citrus fruits was collected, generated, and selected. The dataset contains ripe yellow fruit data and unripe green fruit data, segmented into subsets based on occlusion types, including branch-occluded, densely occluded, severely branch-occluded, and severely densely occluded within each color category. This rigorous classification method ensures the diversity and comprehensiveness of the dataset.
2. Datasets
2.1. Image Data Collection
2.2. Dataset Creation
3. Methods
3.1. The Architecture of AG-YOLO
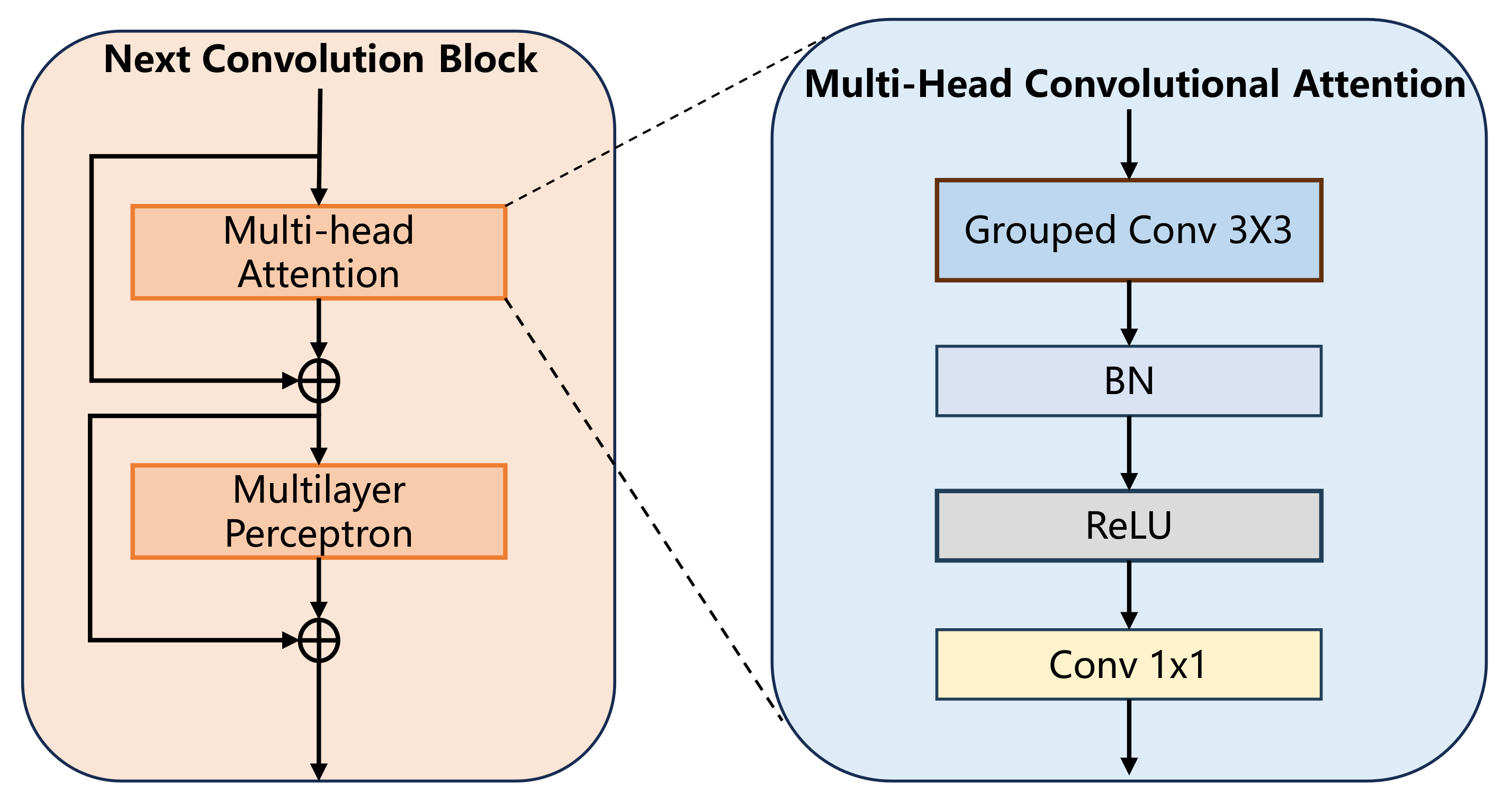
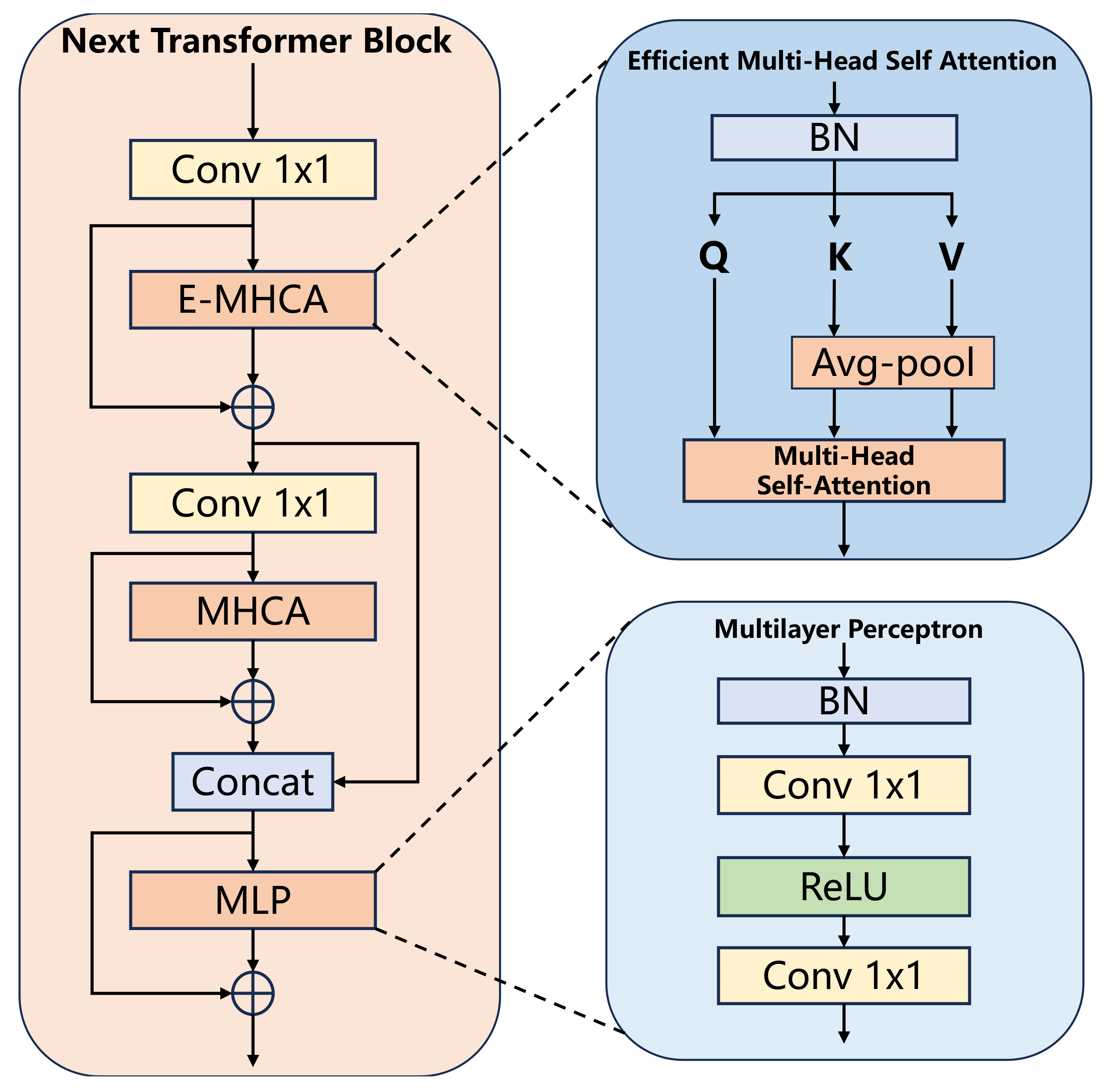
3.2. Backbone Network NextViT
3.3. Global Context Fusion Module GCFM
4. Experiments
4.1. Experimental Environment and Parameter Settings
4.2. Model Evaluation Metrics
4.3. Quantitative Analysis Evaluation
4.4. Ablation Study
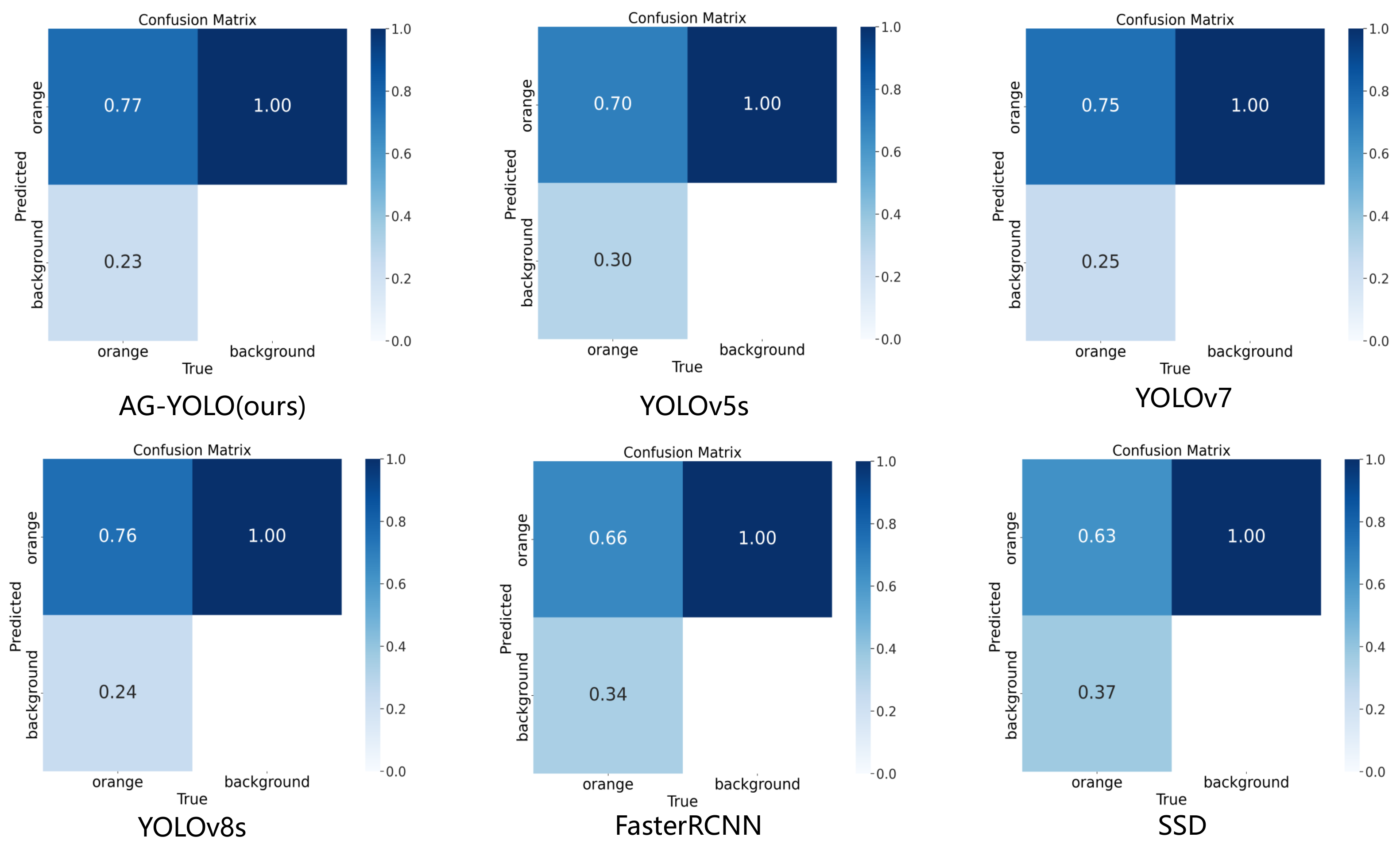
4.5. Qualitative Analysis Evaluation
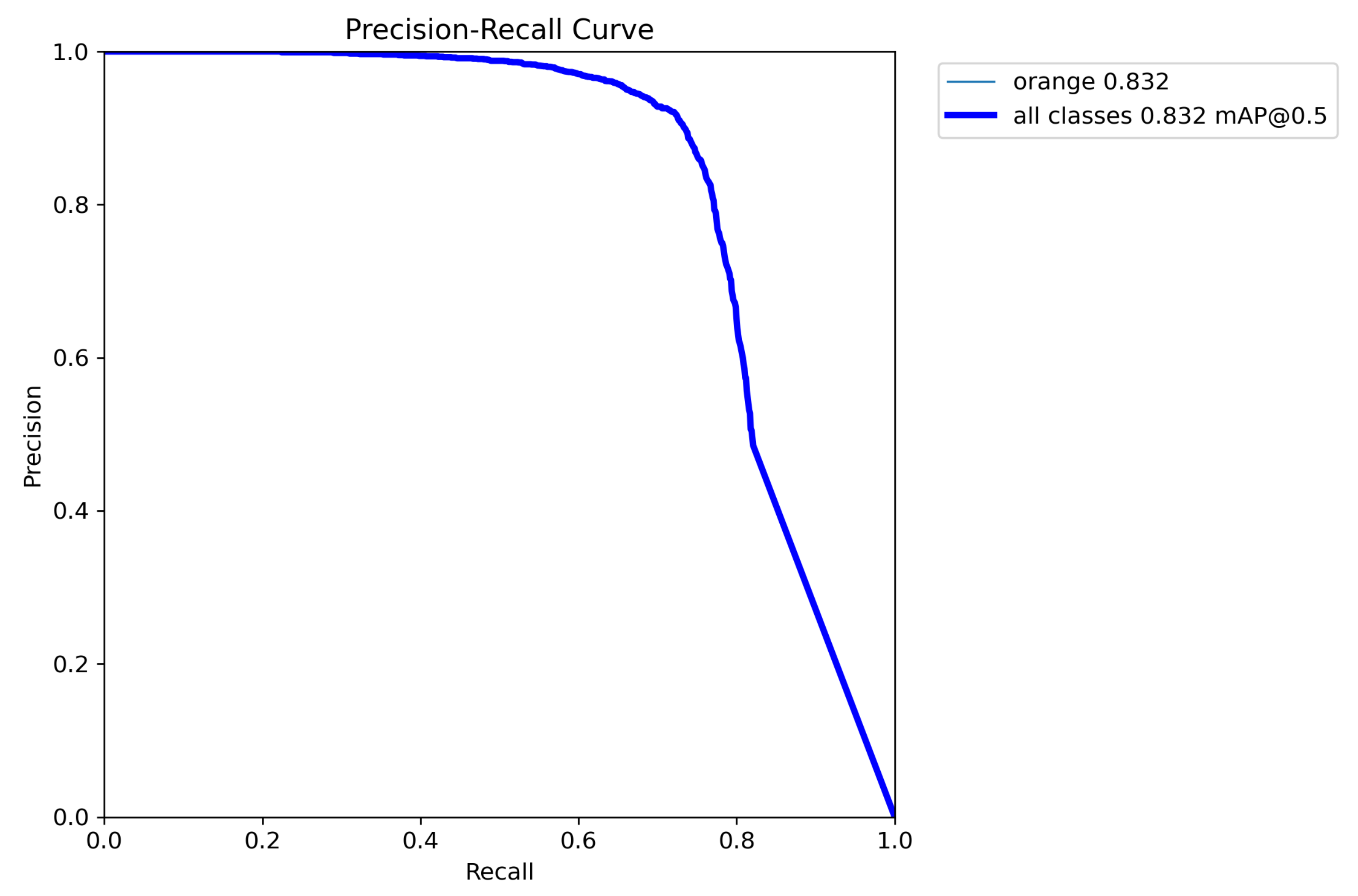
4.6. The Detection Performance of AG-YOLO in Different Weather Conditions and PR Curves
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hamuda, E.; Mc Ginley, B.; Glavin, M.; Jones, E. Improved image processing-based crop detection using Kalman filtering and the Hungarian algorithm. Comput. Electron. Agric. 2018, 148, 37–44. [Google Scholar] [CrossRef]
- Lu, J.; Sang, N. Detecting citrus fruits and occlusion recovery under natural illumination conditions. Comput. Electron. Agric. 2015, 110, 121–130. [Google Scholar] [CrossRef]
- Lin, X.; Li, L.; Gao, Z.; Yi, C.; Li, Q. Revised quasi-circular randomized Hough transform and its application in camellia-fruit recognition. Trans. Chin. Soc. Agric. Eng. 2013, 29, 164–170. [Google Scholar]
- Song, H.; He, D.; Pan, J. Recognition and localization methods of occluded apples based on convex hull theory. Trans. Chin. Soc. Agric. Eng. 2012, 28, 174–180. [Google Scholar]
- Feng, Q.; Chen, W.; Yang, Q. Identification and localization of overlapping tomatoes based on linear structured vision system. J. China Agric. Univ. 2015, 20, 100–106. [Google Scholar]
- Sun, S.; Wu, Q.; Tan, J.; Long, Y.; Song, H. Recognition and reconstruction of single apple occluded by branches. J. Northwest A&F Univ. (Nat. Sci. Ed.) 2017, 45, 138–146. [Google Scholar]
- Sun, J.; Sun, Y.; Zhao, R.; Ji, Y.; Zhang, M.; Li, H. Tomato Recognition Method Based on Iterative Random Circle and Geometric Morphology. Trans. Chin. Soc. Agric. Mach. 2019, 50, 22–26. [Google Scholar]
- Kuznetsova, A.; Maleva, T.; Soloviev, V. Using YOLOv3 algorithm with pre-and post-processing for apple detection in fruit-harvesting robot. Agronomy 2020, 10, 1016. [Google Scholar] [CrossRef]
- Sozzi, M.; Cantalamessa, S.; Cogato, A.; Kayad, A.; Marinello, F. Automatic bunch detection in white grape varieties using YOLOv3, YOLOv4, and YOLOv5 deep learning algorithms. Agronomy 2022, 12, 319. [Google Scholar] [CrossRef]
- Zhang, C.; Li, T.; Zhang, W. The detection of impurity content in machine-picked seed cotton based on image processing and improved YOLOV4. Agronomy 2021, 12, 66. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Koirala, A.; Walsh, K.; Wang, Z.; McCarthy, C. Deep learning for real-time fruit detection and orchard fruit load estimation: Benchmarking of ‘MangoYOLO’. Precis. Agric. 2019, 20, 1107–1135. [Google Scholar] [CrossRef]
- Tian, Y.; Yang, G.; Wang, Z.; Wang, H.; Li, E.; Liang, Z. Apple detection during different growth stages in orchards using the improved YOLO-V3 model. Comput. Electron. Agric. 2019, 157, 417–426. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Yang, J.; Qian, Z.; Zhang, Y.; Qin, Y.; Miao, H. Real-time recognition of tomatoes in complex environments based on improved YOLOv4-tiny. Trans. Chin. Soc. Agric. Eng 2022, 9, 215–221. [Google Scholar]
- Tongbin, H. Citrus fruit recognition method based on the improved model of YOLOv5. J. Huazhong Agric. Univ. 2022, 41, 170–177. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Mu, Y.; Chen, T.S.; Ninomiya, S.; Guo, W. Intact detection of highly occluded immature tomatoes on plants using deep learning techniques. Sensors 2020, 20, 2984. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Afonso, M.; Fonteijn, H.; Fiorentin, F.S.; Lensink, D.; Mooij, M.; Faber, N.; Polder, G.; Wehrens, R. Tomato fruit detection and counting in greenhouses using deep learning. Front. Plant Sci. 2020, 11, 571299. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Bi, S.; Gao, F.; Chen, J.; Zhang, L. Detection Method of Citrus Based on Deep Convolution Neural Network. Trans. Chin. Soc. Agric. Mach. 2019, 50, 181–186. [Google Scholar]
- Li, J.; Xia, X.; Li, W.; Li, H.; Wang, X.; Xiao, X.; Wang, R.; Zheng, M.; Pan, X. Next-vit: Next generation vision transformer for efficient deployment in realistic industrial scenarios. arXiv 2022, arXiv:2207.05501. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Liu, S.; Li, F.; Zhang, H.; Yang, X.B.; Qi, X.; Su, H.; Zhu, J.; Zhang, L. DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR. arXiv 2022, arXiv:2201.12329v4. [Google Scholar]
- Li, F.; Zhang, H.; Liu, S.; Guo, J.; Ni, L.M.; Zhang, L. DN-DETR: Accelerate DETR Training by Introducing Query DeNoising. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 13609–13617. [Google Scholar]
- Liu, Y.; Zhang, Y.; Wang, Y.; Zhang, Y.; Tian, J.; Shi, Z.; Fan, J.; He, Z. SAP-DETR: Bridging the Gap Between Salient Points and Queries-Based Transformer Detector for Fast Model Convergency. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 15539–15547. [Google Scholar]
- Wang, Y.; Zhang, X.; Yang, T.; Sun, J. Anchor DETR: Query Design for Transformer-Based Object Detection. arXiv 2021, arXiv:2109.07107. [Google Scholar]
- Meng, D.; Chen, X.; Fan, Z.; Zeng, G.; Li, H.; Yuan, Y.; Sun, L.; Wang, J. Conditional DETR for Fast Training Convergence. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 3631–3640. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Occlusion | Severe Occlusion | Overlap | Severe Overlap |
|---|---|---|---|---|
| Unripe fruit | 129 | 58 | 100 | 20 |
| Ripe fruit | 337 | 142 | 102 | 69 |
| Network | P/% | R/% | mAP50/% | mAP50:95/% |
|---|---|---|---|---|
| AG-YOLO (ours) | 90.6 | 73.4 | 83.2 | 60.3 |
| YOLOv5s | 86.7 | 67.7 | 79.0 | 57.1 |
| YOLOv7 | 85.4 | 69.6 | 79.9 | 53.2 |
| YOLOv8s | 85.1 | 67.5 | 77.6 | 57.0 |
| Faster RCNN | 50.6 | 81.1 | 77.3 | 47.2 |
| SSD | 87.8 | 61.5 | 70.9 | 42.8 |
| Network | mAP50/% | mAP50:95/% | /% | /% | /% |
|---|---|---|---|---|---|
| AG-YOLO (ours) | 83.2 | 60.3 | 18.8 | 47.2 | 69.2 |
| DAB-DETR | 77.5 | 48.5 | 12.0 | 39.0 | 65.0 |
| DN-DETR | 74.0 | 49.1 | 15.8 | 38.6 | 65.5 |
| SAP-DETR | 78.4 | 50.9 | 15.5 | 41.4 | 67.0 |
| Anchor-DETR | 76.3 | 47.7 | 12.9 | 38.2 | 63.9 |
| Conditional-DETR | 78.0 | 49.6 | 13.8 | 40.0 | 66.1 |
| Network | Backbone | P/% | R/% | mAP50/% | mAP50:95/% |
|---|---|---|---|---|---|
| AG-YOLO w/o GCFM | CSPDarknet53 | 86.7 | 67.7 | 79.0 | 57.1 |
| AG-YOLO w/o GCFM | NextViT | 92.3 | 72.1 | 83.0 | 59.8 |
| AG-YOLO w/ GCFM | CSPDarknet53 | 86.7 | 67.0 | 78.4 | 57.3 |
| AG-YOLO w/ GCFM | NextViT | 90.6 | 73.4 | 83.2 | 60.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, Y.; Huang, Z.; Liang, Y.; Liu, Y.; Jiang, W. AG-YOLO: A Rapid Citrus Fruit Detection Algorithm with Global Context Fusion. Agriculture 2024, 14, 114. https://doi.org/10.3390/agriculture14010114
Lin Y, Huang Z, Liang Y, Liu Y, Jiang W. AG-YOLO: A Rapid Citrus Fruit Detection Algorithm with Global Context Fusion. Agriculture. 2024; 14(1):114. https://doi.org/10.3390/agriculture14010114
Chicago/Turabian StyleLin, Yishen, Zifan Huang, Yun Liang, Yunfan Liu, and Weipeng Jiang. 2024. "AG-YOLO: A Rapid Citrus Fruit Detection Algorithm with Global Context Fusion" Agriculture 14, no. 1: 114. https://doi.org/10.3390/agriculture14010114
APA StyleLin, Y., Huang, Z., Liang, Y., Liu, Y., & Jiang, W. (2024). AG-YOLO: A Rapid Citrus Fruit Detection Algorithm with Global Context Fusion. Agriculture, 14(1), 114. https://doi.org/10.3390/agriculture14010114