
Prediction Model of Pigsty Temperature Based on ISSA-LSSVM


Abstract
:1. Introduction
2. Methodology
2.1. LSSVM Prediction Model
2.2. Sparrow Search Algorithm
3. Optimized Sparrow Search Algorithm
3.1. Location Initialization
- (1)
- Let be the unit cube in s-dimensional Euclidean space, if :where represents the decimal part of .
- (2)
- Take good point , p is the minimum prime number satisfying .
- (3)
- If the deviation satisfies , where is a constant related only to and ( and are arbitrary positive numbers), then is called a good point set. Mapping it to the search space is:where and represent the upper and lower bounds of j-th dimension, respectively.
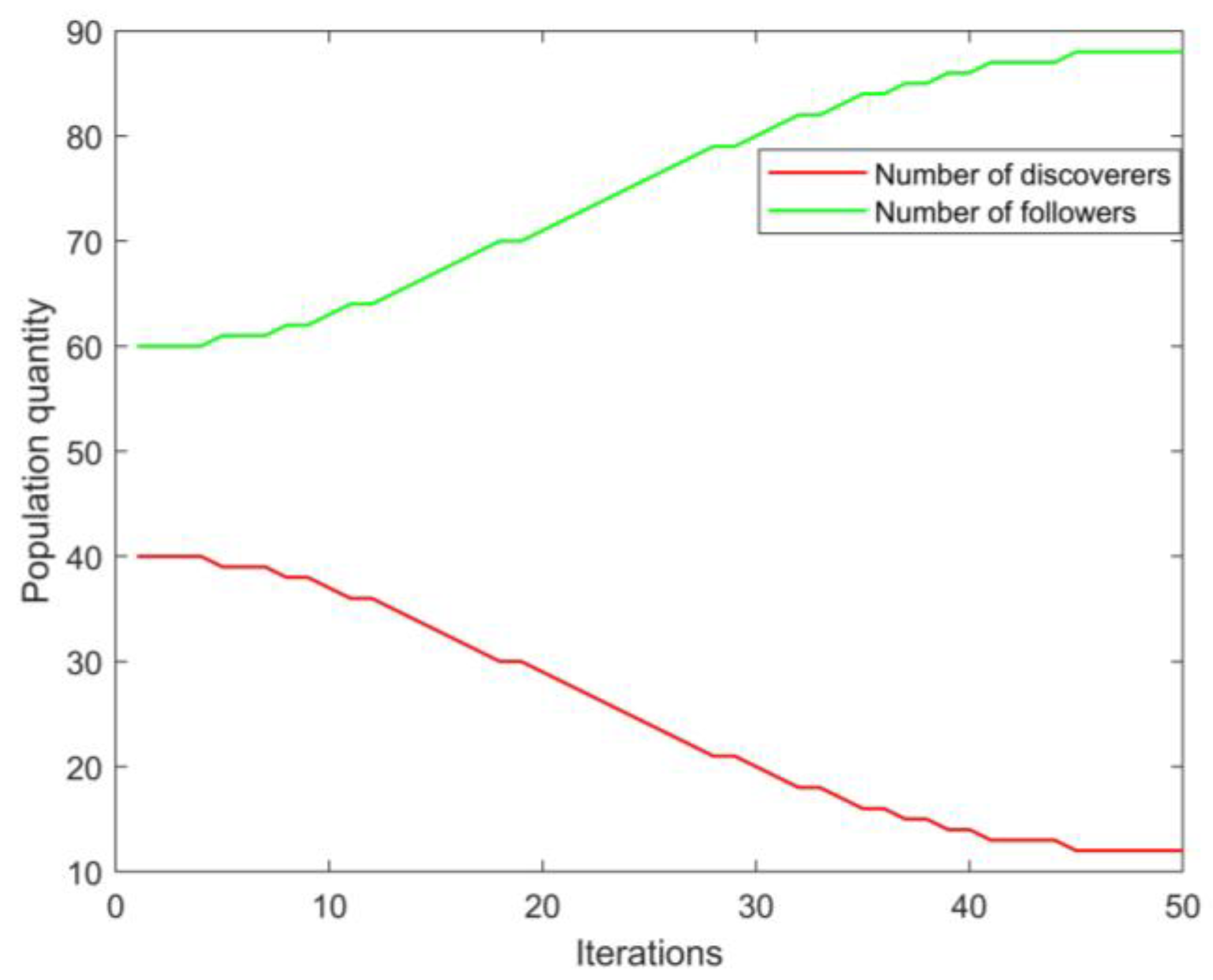
3.2. Discoverer–Follower Number Adaptive Adjustment Strategy
3.3. Adaptive t-Distribution Variation
4. Results and Discussion
4.1. ISSA Performance Test
4.1.1. Analysis of Test Results
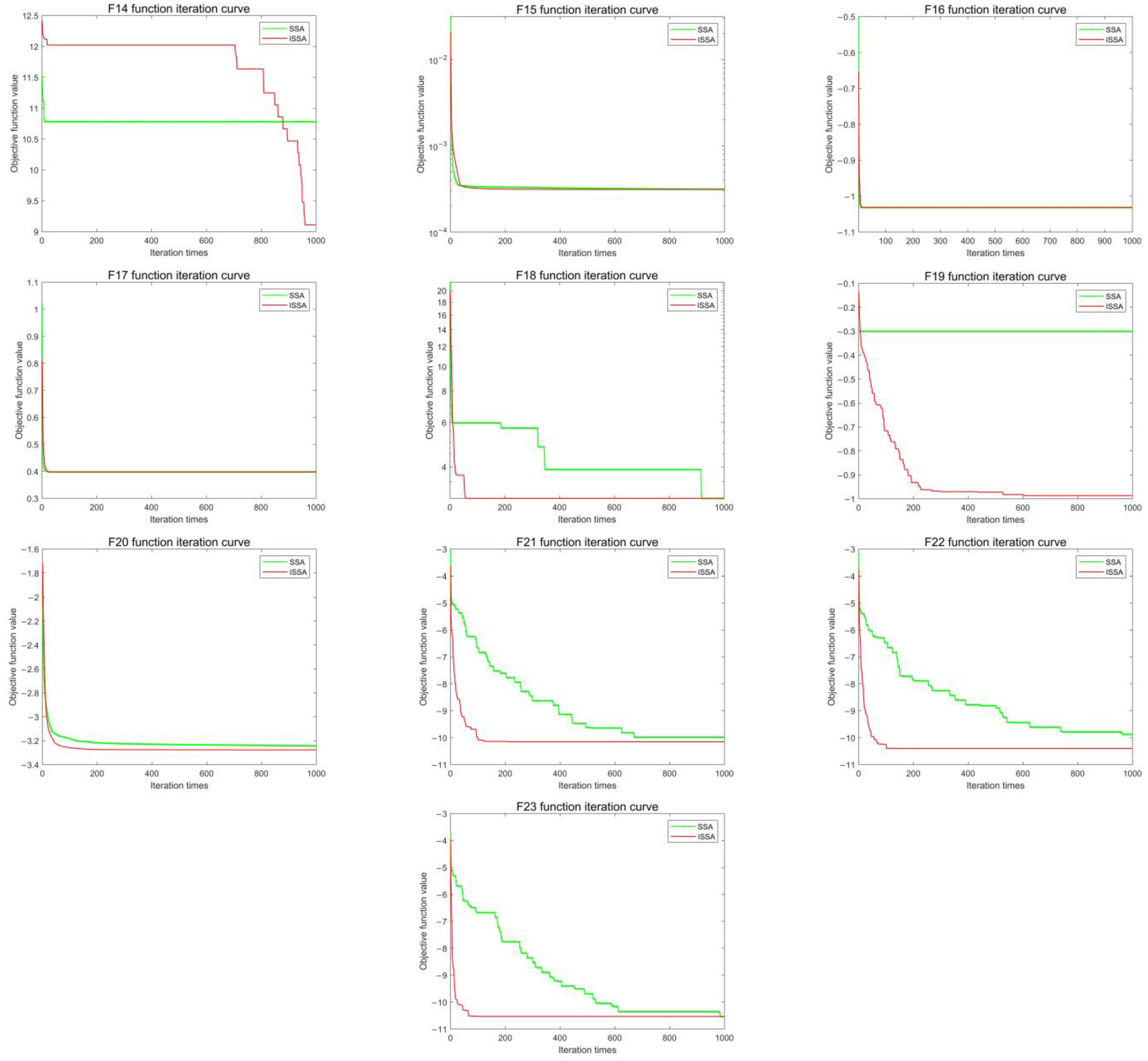
4.1.2. Iterative Curve Analysis
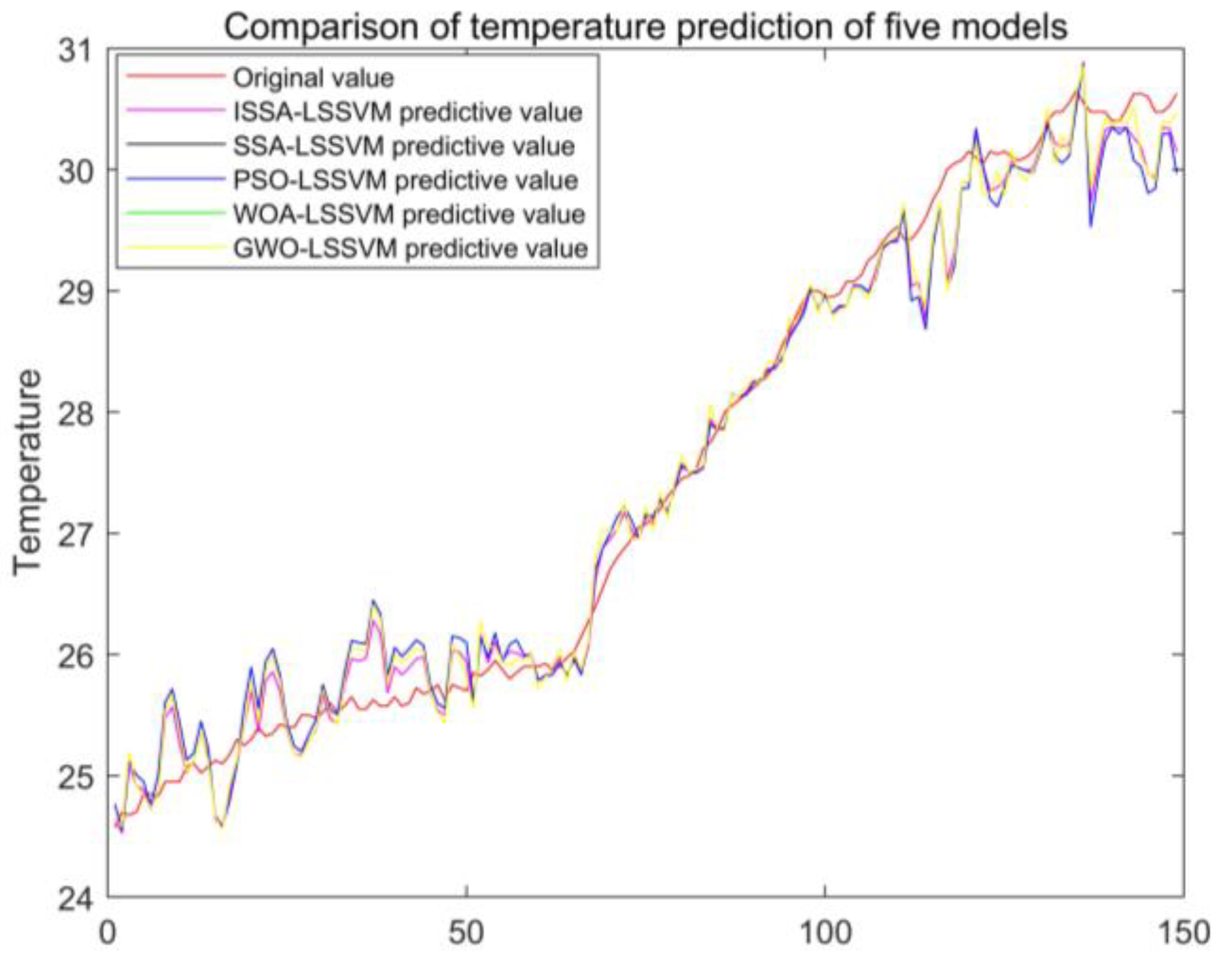
4.2. Comparison of Pig House Temperature Predictions
5. Conclusions
- (1)
- Taking into account the fact that SSA is prone to falling into a local optimum in the late iteration, the present study successfully enhanced SSA by employing three optimization methods: reverse good point set, adaptive parameter adjustment, and adaptive t-distribution variation.
- (2)
- To evaluate the performance of the ISSA proposed in this study, 23 benchmark test functions were chosen and tested in two aspects: convergence accuracy and convergence speed. When compared to SSA, the results showed that the ISSA proposed in this paper has higher convergence accuracy and speed, as well as stronger local and global search ability.
- (3)
- The prediction effect of the ISSA-LSSVM model was tested by comparing it to the LSSVM model optimized by four standard algorithms: SSA, PSO, GWO, and WOA. According to the results, the ISSA-LSSVM prediction model developed in this work achieved the best prediction effect and can provide accurate data support for the predictive control of the internal temperature of the pigsty.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Nomenclature
| Improved sparrow search algorithm | |
| Sparrow search algorithm | |
| Support vector regression | |
| Least squares support vector machine | |
| Random forest | |
| Genetic algorithm | |
| Couple simulated annealing | |
| Sparrow search algorithm | |
| Training samples of LSSVM | |
| Input vector of LSSVM | |
| Output results of LSSVM | |
| Dimension of LSSVM input vector | |
| Number of LSSVM training samples | |
| Hyperplane weight coefficient vector | |
| Offset | |
| Nonlinear mapping function | |
| Regularization parameter | |
| Error vector | |
| Lagrange vector | |
| Lagrange multiplier | |
| Identity matrix | |
| Kernel mapping matrix | |
| Kernel function parameter | |
| Search space dimension | |
| Number of sparrows in population | |
| The location of the i-th sparrow in d-dimensional space | |
| Current number of iterations | |
| Maximum number of iterations | |
| Random number | |
| Random numbers conforming to Gaussian distribution | |
| Matrix with elements of 1 and size of 1 × d | |
| Early warning value of the sparrow population | |
| Safety value of the sparrow population | |
| The optimal position in the sparrow population | |
| The worst position in the sparrow population | |
| Matrix with elements of 1 or −1 and size of 1 × d | |
| Step length control parameters | |
| Random numbers with values ranging from −1 to 1 | |
| Global optimal fitness | |
| The fitness of the current sparrow | |
| The current worst fitness | |
| Minimal constant | |
| S-dimensional unit cube | |
| Good point | |
| The minimum prime number satisfying the condition | |
| Deviation | |
| , | Any positive |
| Good point set | |
| The upper limit of the j-dimensional search space | |
| The lower bound of the j-dimensional search space | |
| The i-th individual of dimension j | |
| Reverse individual of the i-th individual of dimension j | |
| Adaptive adjustment coefficient | |
| Proportionality factor | |
| Number of discoverers in sparrow population | |
| Number of followers in sparrow population | |
| Gamma function | |
| Degree of freedom | |
| Dynamic compilation probability | |
| Current number of iterations | |
| The t distribution with iter degrees of freedom | |
| Hunting zone | |
| Fmin | Optimized value |
| Optimal value of test results | |
| The worst test results | |
| Average test results | |
| Standard value of test results | |
| Whale optimization algorithm | |
| Grey wolf optimization | |
| Particle swarm optimization | |
| Mean square error | |
| Mean absolute error | |
| Coefficient of determination |
References
- Pexas, G.; Mackenzie, S.G.; Jeppsson, K.H.; Olsson, A.C.; Wallace, M.; Kyriazakis, I. Environmental and economic consequences of pig-cooling strategies implemented in a European pig-fattening unit. J. Clean. Prod. 2021, 290, 125784. [Google Scholar] [CrossRef]
- Liu, F.; Zhao, W.; Le, H.H.; Cottrell, J.J.; Green, M.P.; Leury, B.J.; Dunshea, F.R.; Bell, A.W. Review: What have we learned about the effects of heat stress on the pig industry? Animal 2022, 16, 100349. [Google Scholar] [CrossRef] [PubMed]
- Teixeira, A.D.R.; Veroneze, R.; Moreira, V.E.; Campos, L.D.; Januário, R.S.C.; Reis, F.C.P.H. Effects of heat stress on performance and thermoregulatory responses of Piau purebred growing pigs. J. Therm. Biol. 2021, 99, 103009. [Google Scholar] [CrossRef]
- Howden, S.M.; Crimp, S.J.; Stokes, C.J. Climate change and Australian livestock systems: Impacts, research and policy issues. Anim. Prod. Sci. 2008, 48, 780–788. [Google Scholar] [CrossRef]
- Carroll, J.A.; Burdick, N.C.; Chase, C.C.; Coleman, S.W.; Spiers, D.E. Influence of environmental temperature on the physiological, endocrine, and immune responses in livestock exposed to a provocative immune challenge. Domest. Anim. Endocrin 2012, 43, 146–153. [Google Scholar] [CrossRef]
- Morteza, T.; Saman, A.M.; Abbas, R.; Majid, R.; Mostafa, R.J. Applied machine learning in greenhouse simulation; new application and analysis. IPA 2018, 5, 253–268. [Google Scholar]
- Ayad, S.; Seyed, M.S. The effect of dynamic solar heat load on the greenhouse microclimate using CFD simulation. Renew. Energ. 2019, 138, 722–737. [Google Scholar]
- Raphael, L.; Ido, S. Greenhouse temperature modeling: A comparison between sigmoid neural networks and hybrid models. Math. Comput. Simulat 2003, 65, 19–29. [Google Scholar]
- Matej, G.; Robert, S.M.; Kevin, J.L. Forecasting indoor temperatures during heatwaves using time series models. Build. Environ. 2018, 143, 727–739. [Google Scholar]
- Tian, W.; Zhang, X.; Lv, D.; Wang, L.; Liu, Q. Sliding mode control strategy of 3-UPS/S shipborne stable platform with LSTM neural network prediction. Ocean Eng. 2022, 265, 112497. [Google Scholar] [CrossRef]
- Wen, J.; Chen, X.; Li, X.; Li, Y. SOH prediction of lithium battery based on IC curve feature and BP neural network. Energy 2022, 261, 125234. [Google Scholar] [CrossRef]
- Dai, T.; Xiao, Y.; Liang, X.; Li, Q.; Li, T. ICS-SVM: A user retweet prediction method for hot topics based on improved SVM. Digit. Commun. Netw. 2022, 8, 186–193. [Google Scholar] [CrossRef]
- Ye, Y.; Wang, L.; Wang, Y.; Qin, L. An EMD-LSTM-SVR model for the short-term roll and sway predictions of semi-submersible. Ocean. Eng. 2022, 256, 111460. [Google Scholar] [CrossRef]
- Song, Y.; Xie, X.; Wang, Y.; Yang, S.; Ma, W.; Wang, P. Energy consumption prediction method based on LSSVM-PSO model for autonomous underwater gliders. Ocean. Eng. 2021, 230, 108982. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, R. Short term wind energy prediction model based on data decomposition and optimized LSSVM. Sustain. Energy Technol. 2022, 52, 102025. [Google Scholar] [CrossRef]
- Narjes, N.; Sultan, N.Q.; Ely, S.; Alireza, B. Evolving LSSVM and ELM models to predict solubility of non-hydrocarbon gases in aqueous electrolyte systems. Measurement 2020, 164, 107999. [Google Scholar]
- Chen, H.; Deng, T.; Du, T.; Chen, B.; Skibniewski, M.J.; Zhang, L. An RF and LSSVM–NSGA-II method for the multi-objective optimization of high-performance concrete durability. Cem. Concr. Comp. 2022, 129, 104446. [Google Scholar] [CrossRef]
- Reza, G.G.; Reza, S.; Mohammad, T.; Mohsen, S.; Ghassem, Z. A novel PSO-LSSVM model for predicting liquid rate of two phase flow through wellhead chokes. J. Nat. Gas. Sci. Eng. 2015, 24, 228–237. [Google Scholar]
- Huihui, Y.; Yingyi, C.; Shahbaz, G.H.; Daoliang, L. Prediction of the temperature in a Chinese solar greenhouse based on LSSVM optimized by improved PSO. Comput. Electron. Agr. 2016, 122, 94–102. [Google Scholar]
- Liu, Y.; Cao, Y.; Wang, L.; Chen, Z.S.; Qin, Y. Prediction of the durability of high-performance concrete using an integrated RF-LSSVM model. Constr. Build. Mater. 2022, 356, 129232. [Google Scholar] [CrossRef]
- Pan, X.; Xing, Z.; Tian, C.; Wang, H.; Liu, H. A method based on GA-LSSVM for COP prediction and load regulation in the water chiller system. Energ. Build. 2021, 230, 110604. [Google Scholar] [CrossRef]
- Sadra, R.; Fariborz, R.; Hossein, S. Prediction of oil-water relative permeability in sandstone and carbonate reservoir rocks using the CSA-LSSVM algorithm. J. Petrol. Sci. Eng. 2019, 173, 170–186. [Google Scholar]
- Jiankai, X.; Bo, S. A novel swarm intelligence optimization approach: Sparrow search algorithm. J. Petrol. Sci. Eng. 2020, 8, 22–34. [Google Scholar]
- Wu, H.; Zhang, A.; Han, Y.; Nan, J.; Li, K. Fast stochastic configuration network based on an improved sparrow search algorithm for fire flame recognition. Knowl.-Based Syst. 2022, 245, 108626. [Google Scholar] [CrossRef]
- Zhang, Z.; Han, Y. Discrete sparrow search algorithm for symmetric traveling salesman problem. Appl. Soft Comput. 2022, 118, 108469. [Google Scholar] [CrossRef]
- Xiong, J.; Liang, W.; Liang, X.; Yao, J. Intelligent quantification of natural gas pipeline defects using improved sparrow search algorithm and deep extreme learning machine. Chem. Eng. Res. Des. 2022, 183, 567–579. [Google Scholar] [CrossRef]
- Li, J.; Lei, Y.; Yang, S. Mid-long term load forecasting model based on support vector machine optimized by improved sparrow search algorithm. Energy Rep. 2022, 8, 491–497. [Google Scholar] [CrossRef]
- Kathiroli, P.; Selvadurai, K. Energy efficient cluster head selection using improved Sparrow Search Algorithm in Wireless Sensor Networks. J. King Saud. Univ.-Com. 2021, 34, 8564–8575. [Google Scholar] [CrossRef]
- Azaza, M.; Echaieb, K.; Tadeo, F.; Fabrizio, E.; Iqbal, A.; Mami, A. Fuzzy Decoupling Control of Greenhouse Climate. Arab. J. Sci. Eng. 2015, 40, 2805–2812. [Google Scholar] [CrossRef]
- Dan, X.; Shangfeng, D.; Gerard, V.W. Double closed-loop optimal control of greenhouse cultivation. Control Eng. Pract. 2019, 85, 90–99. [Google Scholar]
- He, G.; Lu, X. Good point set and double attractors based-QPSO and application in portfolio with transaction fee and financing cost. Expert. Syst. Appl. 2022, 209, 118339. [Google Scholar] [CrossRef]
- Ren, L.; Liu, T.; Zhao, Q.; Yang, J.; Cao, Y. Method for Measurement Uncertainty Evaluation of Cylindricity Error Based on Good Point Set. Procedia CIRP 2018, 75, 373–378. [Google Scholar]
- Ma, J.; Hao, Z.; Sun, W. Enhancing sparrow search algorithm via multi-strategies for continuous optimization problems. Inform. Process. Manag. 2022, 59, 102854. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Function | Range | D | Fmin |
|---|---|---|---|
| [−100, 100] | 30 | 0 | |
| [−10, 10] | 30 | 0 | |
| [−100, 100] | 30 | 0 | |
| [−100, 100] | 30 | 0 | |
| [−30, 30] | 30 | 0 | |
| [−100, 100] | 30 | 0 | |
| [−1.28, 1.28] | 30 | 0 | |
| [−500, 500] | 30 | −418.98 × D | |
| [−5.12, 5.12] | 30 | 0 | |
| [−32, 32] | 30 | 0 | |
| [−600, 600] | 30 | 0 | |
| [−50, 50] | 30 | 0 | |
| [−50, 50] | 30 | 0 | |
| [−65, 65] | 2 | 1 | |
| [−5, 5] | 4 | 0.0003 | |
| [−5, 5] | 2 | −1.0316 | |
| [−5, 5] | 2 | 0.398 | |
| [−2, 2] | 2 | 3 | |
| [1, 3] | 3 | −3.86 | |
| [0, 1] | 6 | −3.32 | |
| [0, 10] | 4 | −10.1532 | |
| [0, 10] | 4 | −10.4028 | |
| [0, 10] | 4 | −10.5363 |
| Best | Aver | Worst | Std | ||
|---|---|---|---|---|---|
| F1 | SSA | 1.86557543252123 × 10−242 | 1.51061153412230 × 10−31 | 2.75307698567120 × 10−30 | 5.88942497435157 × 10−31 |
| ISSA | 0 | 4.27081085628363 × 10−220 | 1.28124306546856 × 10−218 | 0 | |
| F2 | SSA | 3.592764117337923 × 10−69 | 1.05215088499046 × 10−20 | 2.43515575039904 × 10−19 | 4.53784333352281 × 10−20 |
| ISSA | 1.84978498166486 × 10−251 | 4.29094165698757 × 10−111 | 1.28568003884339 × 10−109 | 2.34722079918870 × 10−110 | |
| F3 | SSA | 1.57252444000000 × 10−316 | 1.75380114435615 × 10−29 | 5.24283828182607 × 10−28 | 9.57092940402367 × 10−29 |
| ISSA | 0 | 4.08090592234734 × 10−216 | 1.18669288637180 × 10−214 | 0 | |
| F4 | SSA | 0 | 2.68229508846477 × 10−15 | 7.48325233341391 × 10−14 | 1.36387615638502 × 10−14 |
| ISSA | 0 | 4.23113317831045 × 10−110 | 1.26933880920409 × 10−108 | 2.31748492435314 × 10−109 | |
| F5 | SSA | 7.37154207400960 × 10−10 | 1.01500859821868 × 10−06 | 8.92127514819244 × 10−06 | 1.82490752625067 × 10−06 |
| ISSA | 2.02843770289964 × 10−08 | 3.21506718912247 × 10−05 | 0.000306574454002731 | 6.12484232097627 × 10−05 | |
| F6 | SSA | 1.56911637210232 × 10−12 | 4.19577804214889 × 10−10 | 3.33187941051024 × 10−09 | 7.42866519675952 × 10−10 |
| ISSA | 1.01094813931186 × 10−09 | 1.78671987291765 × 10−07 | 7.13605599408916 × 10−07 | 1.91302170819916 × 10−07 | |
| F7 | SSA | 1.80477227557695 × 10−05 | 0.000198096255476805 | 0.000528324129619586 | 0.000121590006922501 |
| ISSA | 5.27992087356204 × 10−06 | 0.000142503068818720 | 0.000405066308104379 | 9.21025478001756 × 10−05 | |
| F8 | SSA | −11,237.3936187566 | −9657.18320228176 | −4579.19580237451 | 2896.59237596103 |
| ISSA | −12,569.1802910539 | −11,269.3676884736 | −9123.99096788646 | 1684.18987077972 | |
| F9 | SSA | 0 | 0 | 0 | 0 |
| ISSA | 0 | 0 | 0 | 0 | |
| F10 | SSA | 8.88178419700125 × 10−16 | 7.40148683083438 × 10−15 | 1.21680443498917 × 10−13 | 2.30635643744382 × 10−14 |
| ISSA | 8.88178419700125 × 10−16 | 8.88178419700125 × 10−16 | 8.88178419700125 × 10−16 | 0 | |
| F11 | SSA | 0 | 0 | 0 | 0 |
| ISSA | 0 | 0 | 0 | 0 | |
| F12 | SSA | 1.27509765131711 × 10−12 | 3.20233465455875 × 10−09 | 4.27856730875005 × 10−08 | 9.80134028046934 × 10−09 |
| ISSA | 9.00023672308502 × 10−11 | 1.94549274675890 × 10−08 | 1.97480880547144 × 10−07 | 4.16506384216889 × 10−08 | |
| F13 | SSA | 1.84551272423733 × 10−11 | 2.58346876541052 × 10−08 | 2.88453177196628 × 10−07 | 6.67681501393322 × 10−08 |
| ISSA | 1.36344744810396 × 10−11 | 5.68536045532780 × 10−07 | 4.12656208404738 × 10−06 | 9.85108667605740 × 10−07 | |
| F14 | SSA | 0.998003837794450 | 10.7790901579504 | 12.6705058111356 | 3.68791818335545 |
| ISSA | 0.998003837874042 | 9.10878963650822 | 12.6705058111356 | 5.23300836072021 | |
| F15 | SSA | 0.000307492589579077 | 0.000314072147588383 | 0.000338641964046121 | 8.43080111283077 × 10−06 |
| ISSA | 0.000307490742550469 | 0.000311706465277887 | 0.000334894582494230 | 6.28323981896366 × 10−06 | |
| F16 | SSA | −1.03162845348988 | −1.03162845348988 | −1.03162845348988 | 5.23183651370722 × 10−16 |
| ISSA | −1.03162841956848 | −1.03162845227174 | −1.03162845348988 | 6.18203052512082 × 10−09 | |
| F17 | SSA | 0.397887357736325 | 0.397887357729958 | 0.397887357729738 | 1.20252259235403 × 10−12 |
| ISSA | 0.397887359151452 | 0.397887357777177 | 0.397887357729738 | 2.59559338214047 × 10−10 | |
| F18 | SSA | 2.99999999999994 | 2.99999999999993 | 2.99999999999992 | 3.31916413768800 × 10−15 |
| ISSA | 3.00000000000000 | 3.00000000000160 | 3.00000000003893 | 7.08653172659052 × 10−12 | |
| F19 | SSA | −0.300478907194946 | −0.300478907194947 | −0.300478907194946 | 2.25840514163348 × 10−16 |
| ISSA | −1.49167852264867 | −0.986643720836295 | −0.491061108810976 | 0.268605209990880 | |
| F20 | SSA | −3.32199517069621 | −3.24277992836144 | −3.13162152458857 | 0.0769381219422981 |
| ISSA | −3.32195416785194 | −3.27710827822330 | −3.19200891896637 | 0.0600220205695463 | |
| F21 | SSA | −10.1531996788662 | −9.98326627360475 | −5.05519772893287 | 0.930763554085670 |
| ISSA | −10.1531996790582 | −10.1530522023380 | −10.1493123664807 | 0.000708596958649054 | |
| F22 | SSA | −10.4029403823562 | −9.87138850942744 | −5.08767182506027 | 1.62183185350483 |
| ISSA | −10.4028967931467 | −10.4029283303084 | −10.4029405667897 | 4.63028789889682 × 10−05 | |
| F23 | SSA | −10.5364098155995 | −10.5364023952920 | −10.5361871795855 | 4.06477576396309 × 10−05 |
| ISSA | −10.5363318802579 | −10.5364043533081 | −10.5364098118706 | 1.46076002558824 × 10−05 |
| MAE | MSE | R2 | |
|---|---|---|---|
| ISSA-LSSVM | 0.2105 | 0.0766 | 0.9818 |
| SSA-LSSVM | 0.2259 | 0.0895 | 0.9788 |
| PSO-LSSVM | 0.2590 | 0.1175 | 0.9721 |
| GWO-LSSVM | 0.2259 | 0.0895 | 0.9788 |
| WOA-LSSVM | 0.2259 | 0.0895 | 0.9788 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Zhang, W.; Wu, C.; Zhu, F.; Li, Z. Prediction Model of Pigsty Temperature Based on ISSA-LSSVM. Agriculture 2023, 13, 1710. https://doi.org/10.3390/agriculture13091710
Zhang Y, Zhang W, Wu C, Zhu F, Li Z. Prediction Model of Pigsty Temperature Based on ISSA-LSSVM. Agriculture. 2023; 13(9):1710. https://doi.org/10.3390/agriculture13091710
Chicago/Turabian StyleZhang, Yuqing, Weijian Zhang, Chengxuan Wu, Fengwu Zhu, and Zhida Li. 2023. "Prediction Model of Pigsty Temperature Based on ISSA-LSSVM" Agriculture 13, no. 9: 1710. https://doi.org/10.3390/agriculture13091710
APA StyleZhang, Y., Zhang, W., Wu, C., Zhu, F., & Li, Z. (2023). Prediction Model of Pigsty Temperature Based on ISSA-LSSVM. Agriculture, 13(9), 1710. https://doi.org/10.3390/agriculture13091710