


MSFCA-Net: A Multi-Scale Feature Convolutional Attention Network for Segmenting Crops and Weeds in the Field


Abstract
1. Introduction
2. Materials and Methods
2.1. Dataset Collection
2.1.1. Soybean Dataset
2.1.2. Sugar Beet Dataset
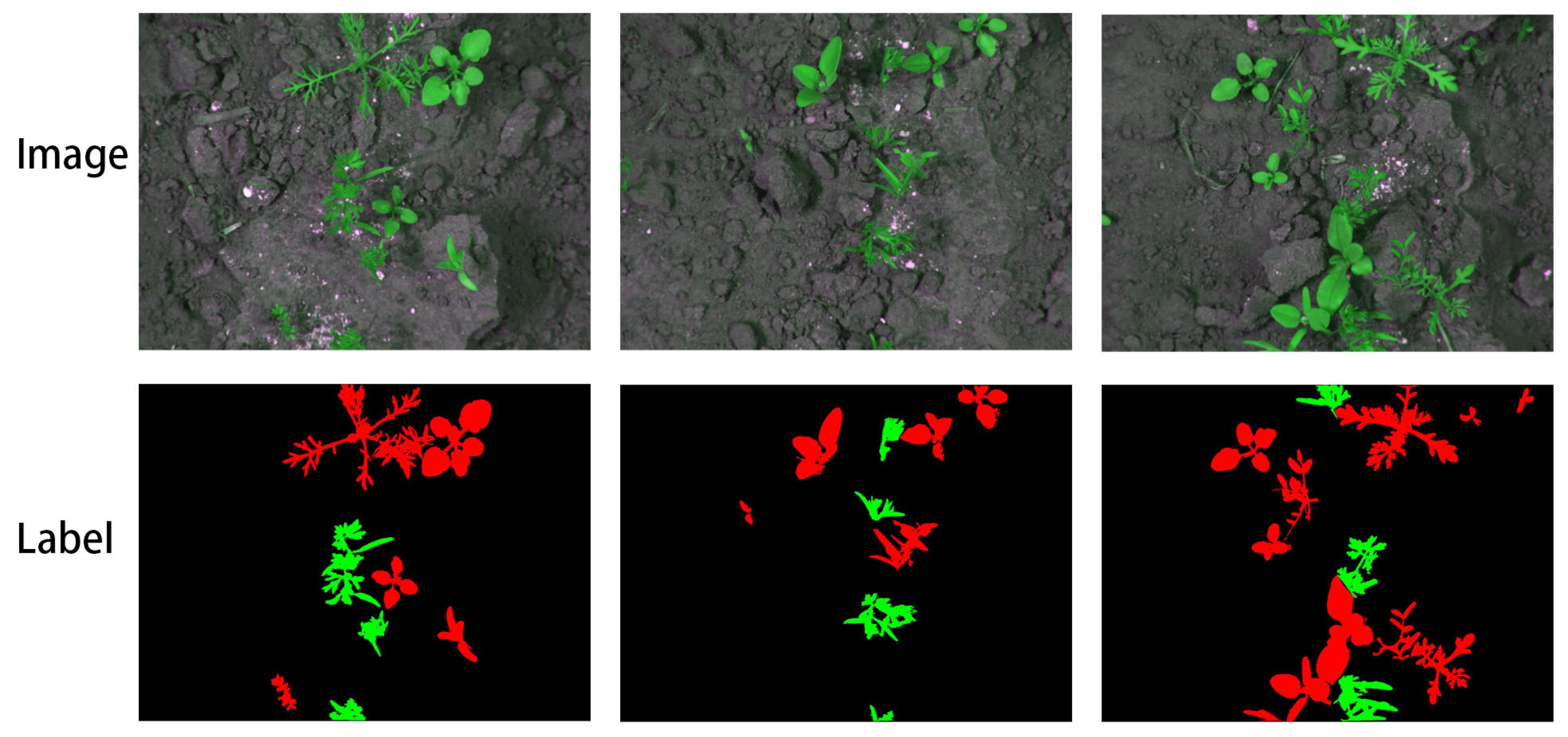
2.1.3. Carrot Dataset
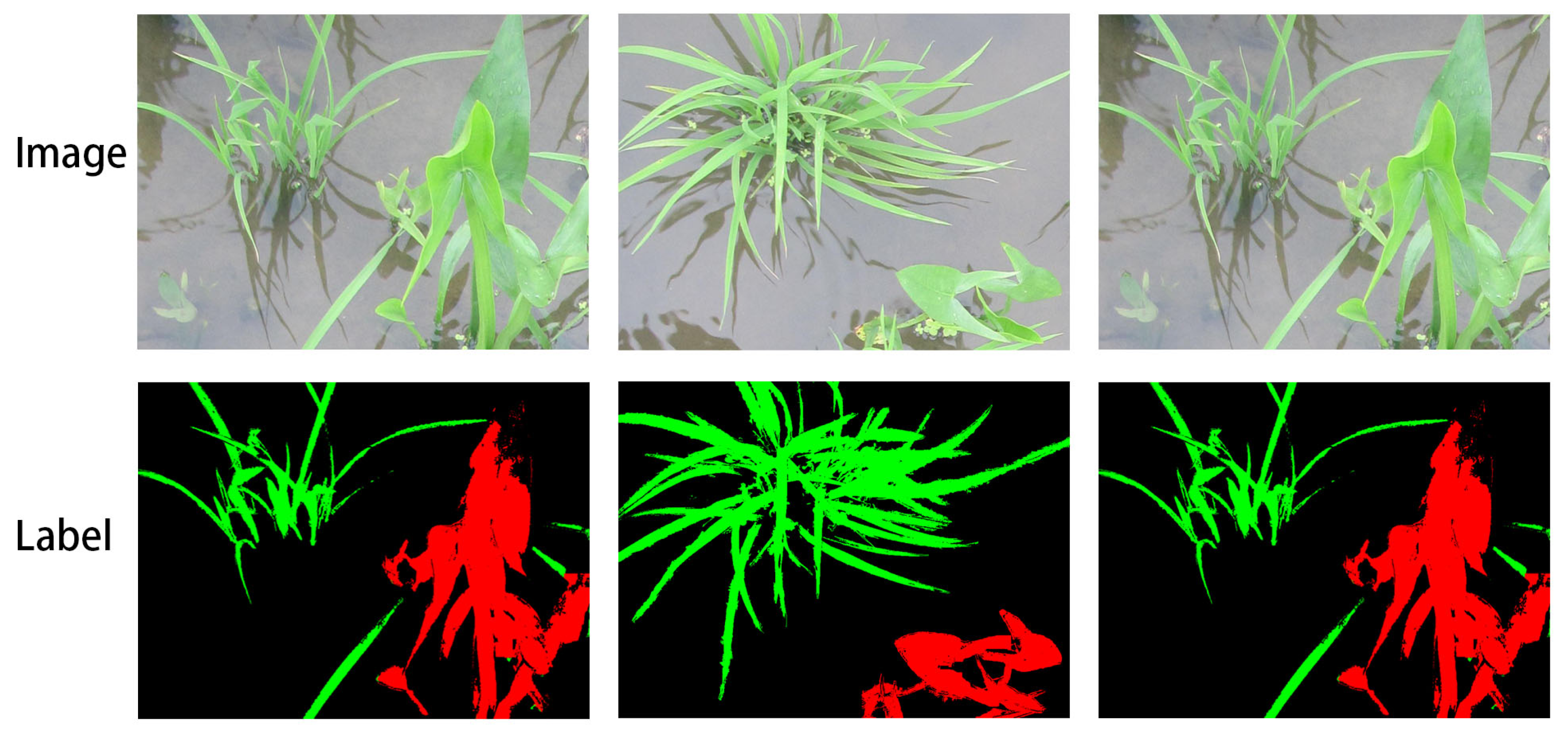
2.1.4. Rice Dataset
2.2. Segmentation Models
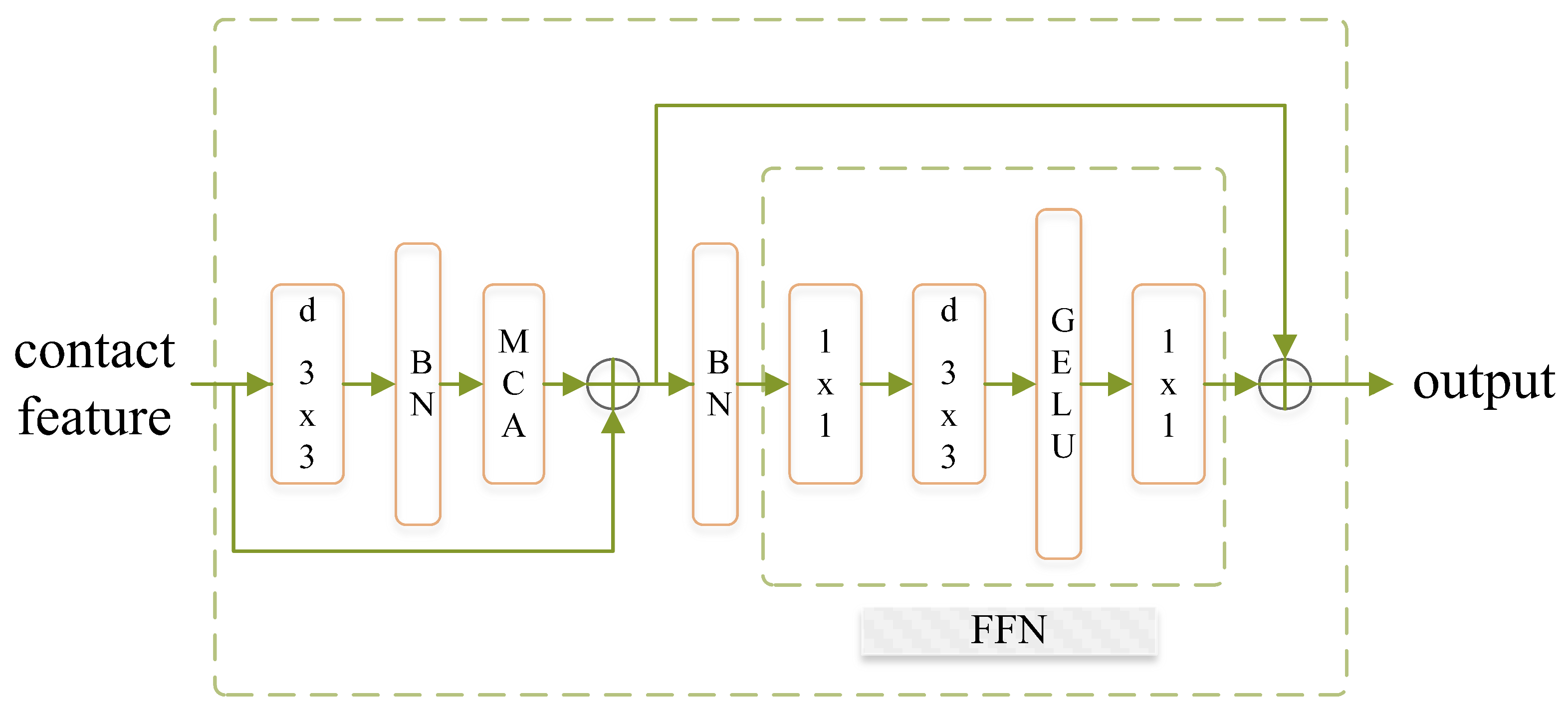
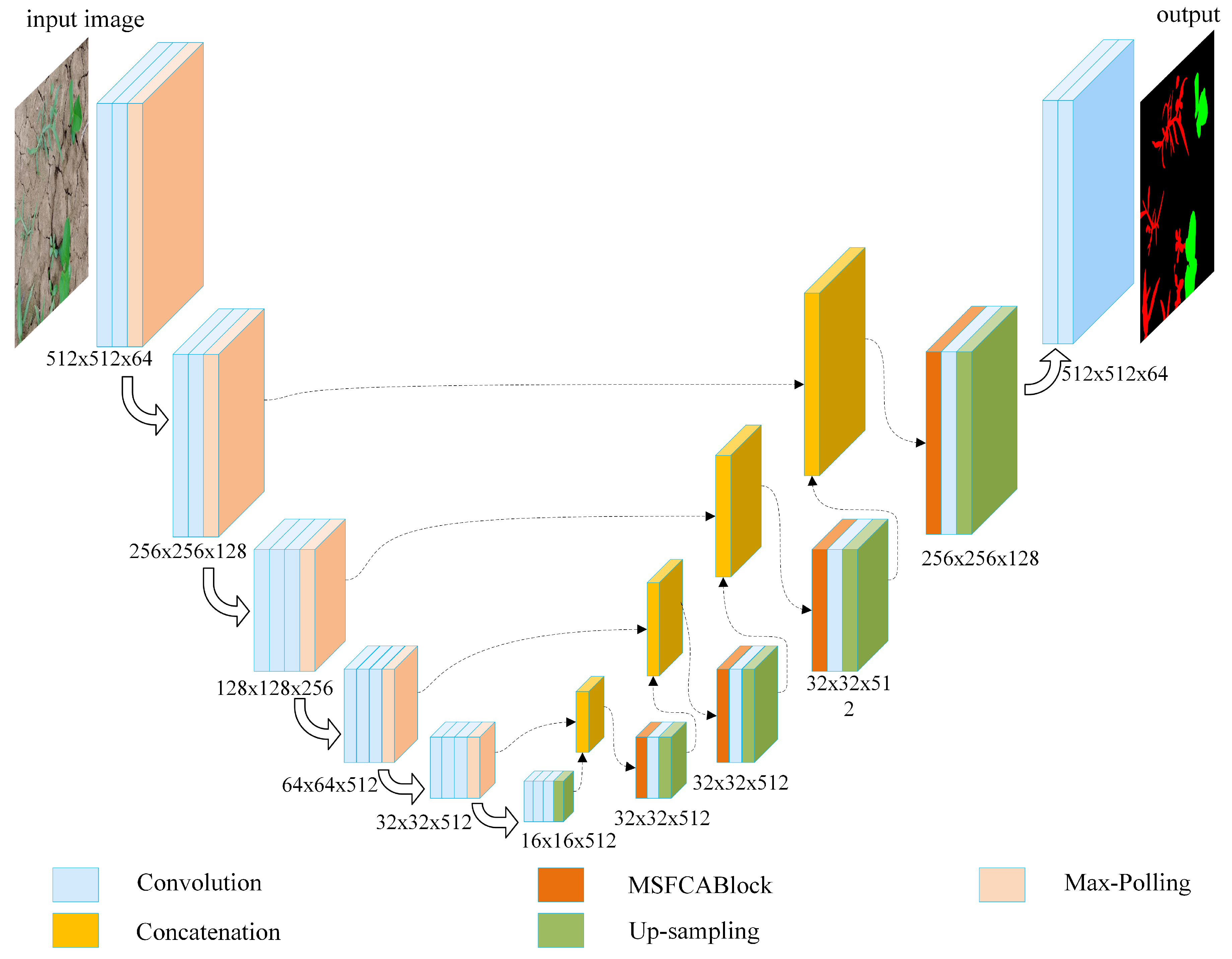
2.2.1. Model
2.2.2. Loss
2.2.3. Parameter Evaluation
3. Results
3.1. Model Training
3.2. Testing on the Soybean Dataset
3.3. Testing on the Sugar Beet Dataset
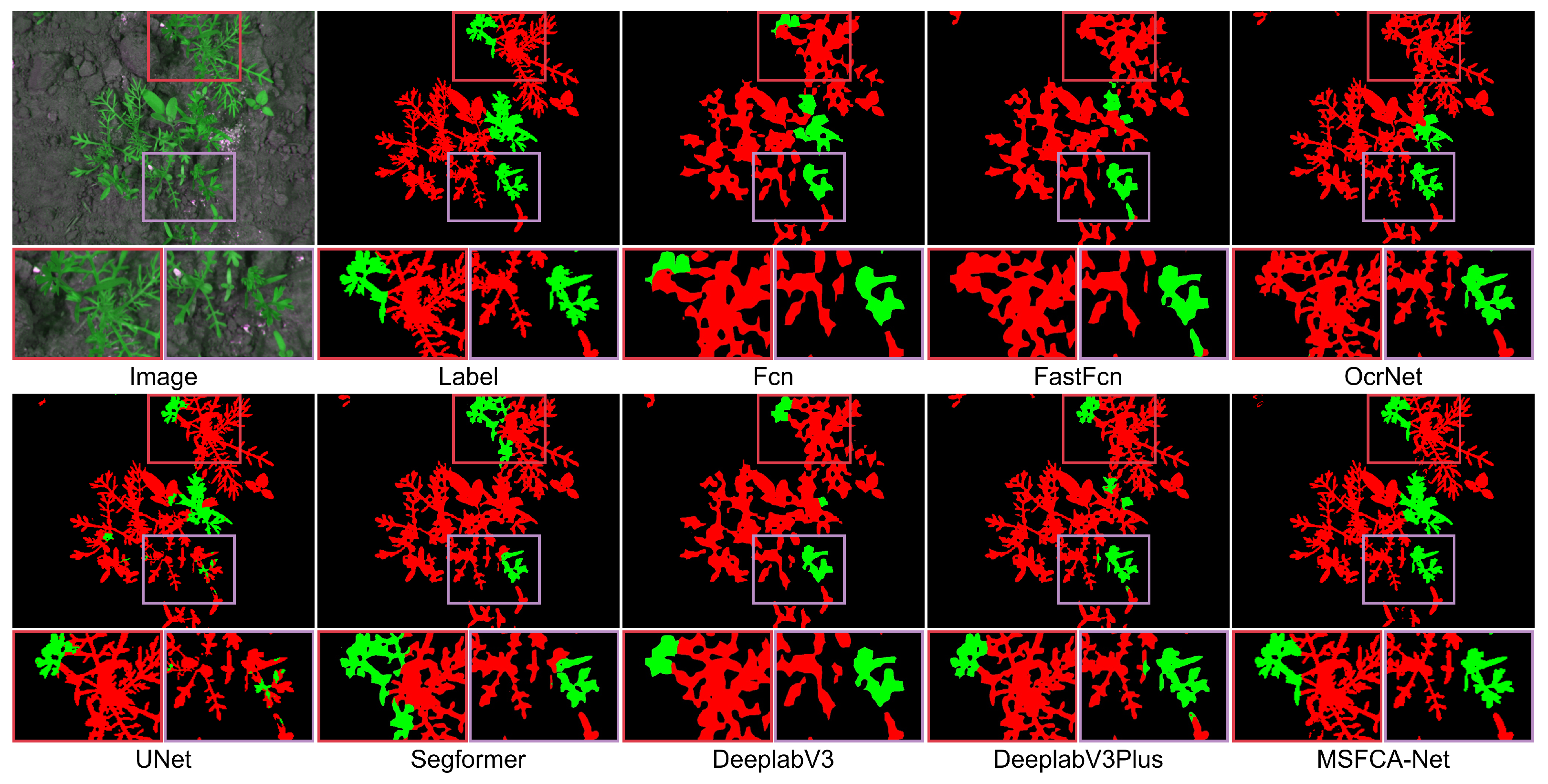
3.4. Testing on the Carrot Dataset
3.5. Testing on the Rice Dataset
3.6. Ablation Experiments
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhu, J.; Wang, J.; DiTommaso, A.; Zhang, C.; Zheng, G.; Liang, W.; Islam, F.; Yang, C.; Chen, X.; Zhou, W. Weed research status, challenges, and opportunities in China. Crop Prot. 2020, 134, 104449. [Google Scholar] [CrossRef]
- Tao, T.; Wei, X. A hybrid CNN-SVM classifier for weed recognition in winter rape field. Plant Methods 2022, 18, 29. [Google Scholar] [CrossRef] [PubMed]
- Harker, K.N.; O’Donovan, J.T. Recent weed control, weed management, and integrated weed management. Weed Technol. 2013, 27, 1–11. [Google Scholar] [CrossRef]
- Hamuda, E.; Glavin, M.; Jones, E. A survey of image processing techniques for plant extraction and segmentation in the field. Comput. Electron. Agric. 2016, 125, 184–199. [Google Scholar] [CrossRef]
- Rodrigo, M.; Oturan, N.; Oturan, M.A. Electrochemically assisted remediation of pesticides in soils and water: A review. Chem. Rev. 2014, 114, 8720–8745. [Google Scholar] [CrossRef]
- Gerhards, R.; Andujar Sanchez, D.; Hamouz, P.; Peteinatos, G.G.; Christensen, S.; Fernandez-Quintanilla, C. Advances in site-specific weed management in agriculture—A review. Weed Res. 2022, 62, 123–133. [Google Scholar] [CrossRef]
- Chen, Z.; Zhang, C.; Li, N.; Sun, Z.; Li, W.; Zhang, B. Study review and analysis of high performance intra-row weeding robot. Trans. Chin. Soc. Agric. Eng. 2015, 31, 1–8. [Google Scholar]
- Liu, C.; Lin, H.; Li, Y.; Gong, L.; Miao, Z. Analysis on status and development trend of intelligent control technology for agricultural equipment. Nongye Jixie Xuebao/Trans. Chin. Soc. Agric. Mach. 2020, 51. [Google Scholar]
- Michaels, A.; Haug, S.; Albert, A. Vision-based high-speed manipulation for robotic ultra-precise weed control. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 5498–5505. [Google Scholar]
- Quan, L.; Xiao, Y.; Wang, J. Study on pattern recognition method of intelligent weeding equipment. J. Northeast Agric. Univ. 2018, 49, 79–87. [Google Scholar]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine learning in agriculture: A review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef]
- Ahmed, F.; Al-Mamun, H.A.; Bari, A.H.; Hossain, E.; Kwan, P. Classification of crops and weeds from digital images: A support vector machine approach. Crop Prot. 2012, 40, 98–104. [Google Scholar] [CrossRef]
- Sabzi, S.; Abbaspour-Gilandeh, Y.; Arribas, J.I. An automatic visible-range video weed detection, segmentation and classification prototype in potato field. Heliyon 2020, 6, e03685. [Google Scholar] [CrossRef] [PubMed]
- Parra, L.; Marin, J.; Yousfi, S.; Rincón, G.; Mauri, P.V.; Lloret, J. Edge detection for weed recognition in lawns. Comput. Electron. Agric. 2020, 176, 105684. [Google Scholar] [CrossRef]
- Sánchez-Sastre, L.F.; Casterad, M.A.; Guillén, M.; Ruiz-Potosme, N.M.; Veiga, N.M.A.D.; Navas-Gracia, L.M.; Martín-Ramos, P. UAV Detection of Sinapis arvensis Infestation in Alfalfa Plots Using Simple Vegetation Indices from Conventional Digital Cameras. AgriEngineering 2020, 2, 206–212. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Yang, Q.; Shi, L.; Han, J.; Zha, Y.; Zhu, P. Deep convolutional neural networks for rice grain yield estimation at the ripening stage using UAV-based remotely sensed images. Field Crop Res. 2019, 235, 142–153. [Google Scholar] [CrossRef]
- Fuentes, A.; Yoon, S.; Kim, S.C.; Park, D.S. A robust deep-learning-based detector for real-time tomato plant diseases and pests recognition. Sensors 2017, 17, 2022. [Google Scholar] [CrossRef]
- Hall, D.; McCool, C.; Dayoub, F.; Sunderhauf, N.; Upcroft, B. Evaluation of features for leaf classification in challenging conditions. In Proceedings of the 2015 IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2015; pp. 797–804. [Google Scholar]
- Olsen, A.; Konovalov, D.A.; Philippa, B.; Ridd, P.; Wood, J.C.; Johns, J.; Banks, W.; Girgenti, B.; Kenny, O.; Whinney, J. DeepWeeds: A multiclass weed species image dataset for deep learning. Sci. Rep. 2019, 9, 2058. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. pp. 234–241. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Yuan, Y.; Chen, X.; Chen, X.; Wang, J. Segmentation transformer: Object-contextual representations for semantic segmentation. arXiv 2019, arXiv:1909.11065. [Google Scholar]
- Lateef, F.; Ruichek, Y. Survey on semantic segmentation using deep learning techniques. Neurocomputing 2019, 338, 321–348. [Google Scholar] [CrossRef]
- You, J.; Liu, W.; Lee, J. A DNN-based semantic segmentation for detecting weed and crop. Comput. Electron. Agric. 2020, 178, 105750. [Google Scholar] [CrossRef]
- Yu, J.; Sharpe, S.M.; Schumann, A.W.; Boyd, N.S. Deep learning for image-based weed detection in turfgrass. Eur. J. Agron. 2019, 104, 78–84. [Google Scholar] [CrossRef]
- Sun, J.; Tan, W.; Wu, X.; Shen, J.; Lu, B.; Dai, C. Real-time recognition of sugar beet and weeds in complex backgrounds using multi-channel depth-wise separable convolution model. Trans. Chin. Soc. Aric. Eng 2019, 35, 184–190. [Google Scholar]
- Zou, K.; Chen, X.; Wang, Y.; Zhang, C.; Zhang, F. A modified U-Net with a specific data argumentation method for semantic segmentation of weed images in the field. Comput. Electron. Agric. 2021, 187, 106242. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef] [PubMed]
- Chebrolu, N.; Lottes, P.; Schaefer, A.; Winterhalter, W.; Burgard, W.; Stachniss, C. Agricultural robot dataset for plant classification, localization and mapping on sugar beet fields. Int. J. Robot. Res. 2017, 36, 1045–1052. [Google Scholar] [CrossRef]
- Haug, S.; Ostermann, J. A crop/weed field image dataset for the evaluation of computer vision based precision agriculture tasks. In Proceedings of the Computer Vision-ECCV 2014 Workshops, Zurich, Switzerland, 6–7 and 12 September 2014; Proceedings, Part IV 13; 2015. pp. 105–116. [Google Scholar]
- Ma, X.; Deng, X.; Qi, L.; Jiang, Y.; Li, H.; Wang, Y.; Xing, X. Fully convolutional network for rice seedling and weed image segmentation at the seedling stage in paddy fields. PLoS ONE 2019, 14, e0215676. [Google Scholar] [CrossRef]
- Guo, M.-H.; Xu, T.-X.; Liu, J.-J.; Liu, Z.-N.; Jiang, P.-T.; Mu, T.-J.; Zhang, S.-H.; Martin, R.R.; Cheng, M.-M.; Hu, S.-M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. Adv. Neural Inf. Process. Syst. 2014, 27, 2204–2212. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.-S. Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5659–5667. [Google Scholar]
- Guo, M.-H.; Lu, C.-Z.; Liu, Z.-N.; Cheng, M.-M.; Hu, S.-M. Visual attention network. arXiv 2022, arXiv:2202.09741. [Google Scholar]
- Guo, M.-H.; Lu, C.-Z.; Hou, Q.; Liu, Z.; Cheng, M.-M.; Hu, S.-M. Segnext: Rethinking convolutional attention design for semantic segmentation. arXiv 2022, arXiv:2209.08575. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large kernel matters—Improve semantic segmentation by global convolutional network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4353–4361. [Google Scholar]
- Hou, Q.; Zhang, L.; Cheng, M.-M.; Feng, J. Strip pooling: Rethinking spatial pooling for scene parsing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4003–4012. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Guo, H.; Wang, S.; Lu, Y. Real-time segmentation of weeds in cornfields based on depthwise separable convolution residual network. Int. J. Comput. Sci. Eng. 2020, 23, 307–318. [Google Scholar] [CrossRef]
- Brilhador, A.; Gutoski, M.; Hattori, L.T.; de Souza Inácio, A.; Lazzaretti, A.E.; Lopes, H.S. Classification of weeds and crops at the pixel-level using convolutional neural networks and data augmentation. In Proceedings of the 2019 IEEE Latin American Conference on Computational Intelligence (LA-CCI), Guayaquil, Ecuador, 11–15 November 2019; pp. 1–6. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | MIoU (%) | Crop IoU (%) | Weed IoU (%) | Bg IoU * (%) | Recall (%) | Precision (%) | F1-Score (%) |
|---|---|---|---|---|---|---|---|
| FCN | 86.12 | 90.68 | 68.62 | 99.05 | 92.27 | 91.75 | 92.01 |
| FastFcn | 88.12 | 92.79 | 72.35 | 99.22 | 93.61 | 92.94 | 93.28 |
| OcrNet | 89.90 | 93.23 | 77.09 | 99.37 | 94.28 | 94.55 | 94.42 |
| UNet | 87.34 | 9012 | 72.54 | 99.67 | 92.94 | 92.89 | 92.91 |
| Segformer | 86.56 | 89.05 | 71.31 | 99.22 | 92.75 | 92.01 | 92.37 |
| DeeplabV3 | 88.25 | 92.92 | 72.59 | 99.23 | 93.68 | 93.04 | 93.35 |
| DeeplabV3Plus | 89.66 | 92.96 | 76.67 | 99.36 | 94.56 | 93.99 | 94.27 |
| MSFCA-Net | 92.64 | 95.34 | 82.97 | 99.62 | 99.57 | 99.54 | 99.55 |
| Model | MIoU (%) | Crop IoU (%) | Weed IoU (%) | Bg IoU * (%) | Recall (%) | Precision (%) | F1-Score (%) |
|---|---|---|---|---|---|---|---|
| FCN | 81.42 | 90.66 | 54.40 | 99.19 | 86.69 | 90.49 | 88.39 |
| FastFcn | 81.38 | 99.12 | 54.68 | 81.38 | 86.32 | 91.14 | 88.40 |
| OcrNet | 86.01 | 92.20 | 66.49 | 99.35 | 90.59 | 93.19 | 91.83 |
| UNet | 82.48 | 90.29 | 55.78 | 99.31 | 87.13 | 90.82 | 88.94 |
| Segformer | 75.01 | 86.09 | 39.73 | 99.21 | 80.98 | 86.38 | 83.01 |
| DeeplabV3 | 81.45 | 89.81 | 55.46 | 99.01 | 87.94 | 89.16 | 88.51 |
| DeeplabV3Plus | 84.72 | 91.20 | 63.68 | 99.29 | 90.00 | 91.99 | 90.95 |
| MSFCA-Net | 89.58 | 95.62 | 73.32 | 99.79 | 99.69 | 99.69 | 99.69 |
| Model | MIoU (%) | Crop IoU (%) | Weed IoU (%) | Bg IoU * (%) | Recall (%) | Precision (%) | F1-Score (%) |
|---|---|---|---|---|---|---|---|
| FCN | 70.40 | 50.83 | 63.49 | 96.89 | 83.85 | 78.81 | 81.16 |
| FastFcn | 70.59 | 50.52 | 64.40 | 96.86 | 82.84 | 80.39 | 81.29 |
| OcrNet | 75.19 | 58.73 | 69.12 | 97.64 | 85.38 | 85.42 | 85.38 |
| UNet | 73.89 | 53.46 | 70.02 | 98.18 | 83.84 | 82.64 | 85.08 |
| Segformer | 64.05 | 33.70 | 60.85 | 97.60 | 75.00 | 76.71 | 74.95 |
| DeeplabV3 | 71.22 | 53.31 | 63.45 | 96.91 | 84.28 | 79.90 | 81.87 |
| DeeplabV3Plus | 74.79 | 56.29 | 70.44 | 97.63 | 87.10 | 82.24 | 84.50 |
| MSFCA-Net | 79.34 | 59.84 | 79.57 | 98.62 | 98.25 | 98.56 | 98.41 |
| Model | MIoU (%) | Crop IoU (%) | Weed IoU (%) | Bg IoU * (%) | Recall/(%) | Precision (%) | F1-Score (%) |
|---|---|---|---|---|---|---|---|
| FCN | 72.86 | 58.19 | 68.62 | 91.78 | 83.81 | 83.64 | 83.56 |
| FastFcn | 74.23 | 60.73 | 69.54 | 92.40 | 84.59 | 84.84 | 84.55 |
| OcrNet | 74.16 | 61.16 | 68.63 | 92.69 | 84.34 | 84.92 | 84.50 |
| UNet | 74.14 | 63.64 | 65.56 | 97.79 | 84.56 | 84.65 | 84.61 |
| Segformer | 72.51 | 58.59 | 66.92 | 92.04 | 82.93 | 83.93 | 83.31 |
| DeeplabV3 | 74.07 | 60.01 | 69.96 | 92.24 | 84.83 | 84.30 | 84.43 |
| DeeplabV3Plus | 74.87 | 61.89 | 70.19 | 92.53 | 86.01 | 84.29 | 85.02 |
| MSFCA-Net | 78.12 | 67.56 | 68.70 | 98.12 | 96.41 | 95.47 | 95.93 |
| Model | MIoU (%) | Crop IoU (%) | Weed IoU (%) | Bg IoU * (%) | Recall (%) | Precision (%) | F1-Score (%) |
|---|---|---|---|---|---|---|---|
| BaseNet | 88.33 | 90.89 | 74.65 | 99.44 | 99.28 | 99.33 | 99.30 |
| BaseNet + BABlock | 89.09 | 91.32 | 76.42 | 99.53 | 99.38 | 99.39 | 99.38 |
| BaseNet + MSFCABlock | 91.72 | 94.29 | 81.28 | 99.60 | 99.48 | 99.53 | 99.50 |
| BaseNet + hybrid loss | 90.35 | 93.02 | 78.49 | 99.52 | 99.41 | 99.40 | 99.41 |
| BaseNet + BABlock + hybrid loss | 91.33 | 93.62 | 80.79 | 99.58 | 99.50 | 99.47 | 99.48 |
| MSFCA-Net | 92.64 | 95.34 | 82.97 | 99.62 | 99.57 | 99.54 | 99.55 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Q.; Ye, Y.; Gu, L.; Wu, Y. MSFCA-Net: A Multi-Scale Feature Convolutional Attention Network for Segmenting Crops and Weeds in the Field. Agriculture 2023, 13, 1176. https://doi.org/10.3390/agriculture13061176
Yang Q, Ye Y, Gu L, Wu Y. MSFCA-Net: A Multi-Scale Feature Convolutional Attention Network for Segmenting Crops and Weeds in the Field. Agriculture. 2023; 13(6):1176. https://doi.org/10.3390/agriculture13061176
Chicago/Turabian StyleYang, Qiangli, Yong Ye, Lichuan Gu, and Yuting Wu. 2023. "MSFCA-Net: A Multi-Scale Feature Convolutional Attention Network for Segmenting Crops and Weeds in the Field" Agriculture 13, no. 6: 1176. https://doi.org/10.3390/agriculture13061176
APA StyleYang, Q., Ye, Y., Gu, L., & Wu, Y. (2023). MSFCA-Net: A Multi-Scale Feature Convolutional Attention Network for Segmenting Crops and Weeds in the Field. Agriculture, 13(6), 1176. https://doi.org/10.3390/agriculture13061176