
BAG: A Linear-Nonlinear Hybrid Time Series Prediction Model for Soil Moisture


Abstract
:1. Introduction
2. Materials and Methods
2.1. Datasets
- (1)
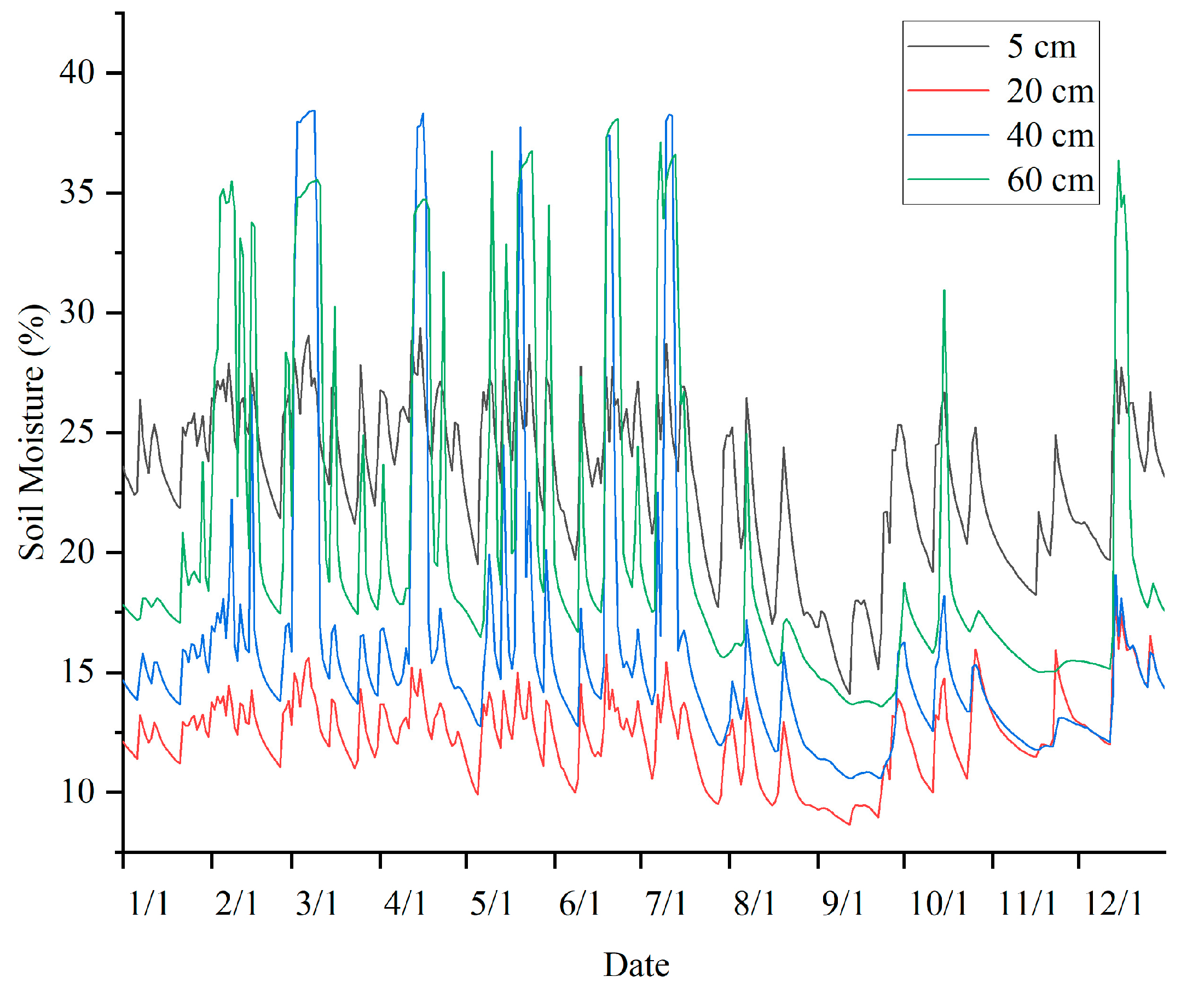
- Soil moisture variables include soil moisture at 5 cm, 20 cm, 40 cm, and 60 cm, where soil moisture data is the volumetric water content of the soil at different depths, i.e., units.
- (2)
- Other environmental variables refer to meteorological data and soil temperature data at different depths, where meteorological data include rainfall, atmospheric temperature, vegetation temperature, relative air humidity, wind speed, wind direction, sunshine duration, daily evaporation, and solar radiation intensity. Soil temperature data at different depths include soil temperature at 5 cm, 20 cm, 40 cm, and 60 cm.
2.2. Problem Definition
- t: The length of the time series, i.e., the number of rows of input data.
- m: The sum of soil moisture and the number of types of environmental factor data, i.e., the number of columns of input data.
- n: The sum of soil moisture and the number of types of environmental factor data actually used, i.e., the number of columns for the preprocessed data.
- S = {s1, s2, …, st}: The data of daily average soil moisture time series to be predicted for the next data.
- F = {{f1,1, f1,2, …, f1,t}, {f2,1, f2,2, …, f2,t}, …, {fn-1,1, fn-1,2, …, fn-1,t}, …, {fm-1,1, fm-1,2, …, fm-1,t}}: Denoted as the time series data of m-1 environmental factors.
- X = {x1, x2, …, xt}, : The actual values after the analyzed and processed time series data.
- : The denotation of soil moisture and multiple related environmental factors data using a multi-way delay embedding transform, i.e., the soil Hankel tensor.
- Y = {y1, y2, …, yt}, : The linear predicted result after BHT-ARIMA prediction.
- : The core tensor of the soil used the Hankel tensor of the soil obtained in the previous step and used Tucker decomposition to obtain a new identity.
- R = {r1, r2, …, rt}, : The residual series of the actual value X and the linear part of the predicted result Y after the analyzed and processed time series data.
2.3. BAG Model
2.3.1. Main Idea
- (1)
- The analysis and processing of time series data. The collected soil moisture data S and multi-environmental factor data F were analyzed for normality and correlation to comprehensively grasp the time series characteristics of soil moisture data. The input time series data were then processed to obtain the normalized data x1, …, xt, which reduces the problem of the large relative variability of the data due to the unit differences of different sample data.
- (2)
- The prediction of linear components of soil moisture. Linear features of soil moisture time series were extracted using a BHT-ARIMA. BHT-ARIMA uses a multiway delay embedding transform (MDT) [25,26] to represent soil moisture and multiple relevant environmental factor data, such as a soil higher-order Hankel tensor , …, . Tucker decomposition [27,28] can be applied to project the higher-order tensor onto the compressed soil core tensor ,…,. At the same time, the generalized tensor. The autoregressive integrated moving average (ARIMA) was explicitly used to predict a continuous core tensor to obtain the prediction of the linear part yt+1, which improved the intrinsic correlation between the soil moisture and several environmental factors.
- (3)
- Prediction of nonlinear components of soil moisture. A GRU network was established to model the residual series r1, …, rt between the predicted results y1, …, yt and the actual values x1, …, xt of the BHT-ARIMA to obtain the nonlinear part of the prediction result rt+1 to solve the nonlinear problem of soil moisture data.
2.3.2. Analysis and Processing of Time Series Data
- (1)
- Data outlier correction. As the acquisition system for data usually has coarse error data, outliers in the data need to be processed. Based on the fact that soil moisture data are fixed interval time series data, the mean value of the data before and after the time of the outliers is used to correct for outliers in the data and to maintain the integrity of the data.
- (2)
- Data dimensionality reduction includes two steps the normality test and correlation analysis. The correlation analysis of different data series was used to determine the association between the data of each dimension, and the data with a strong correlation was selected near subsequent processing. Among them, the larger the absolute value of the correlation coefficient, the stronger the correlation. The closer the correlation coefficient is to 1 or −1, the stronger the correlation is, and the closer the correlation coefficient is to 0, the weaker the correlation is. In order to express the correlation of the data, it is necessary to test the normality of the data and select corresponding correlation evaluation indicators according to whether the data are normal or not.
- (3)
- Data normalization. Because of the large range of relative variation in values between soil moisture and other environmental factor data, direct input is not conducive to model convergence, so the input data for soil moisture needs to be standardized.
- (1)
- Normality test
- (2)
- Correlation analysis
- (3)
- Data normalization
2.3.3. Prediction of Linear Components of Soil Moisture
- (1)
- Model parameters determination
- (2)
- BHT MDT. Soil moisture and multiple related environmental factors are transformed into higher-order multidimensional data along the time dimension using a multi-way delay embedding transform (MDT). The resulting higher-order multidimensional tensor is called “Block Hankel Tensor (BHT)”. Equation (6) is the formula for the MDT of time series data along the time dimension.
- (3)
- Tucker decomposition. The obtained Hankel tensor , …, of the soil block is used to obtain a new feature, called the core tensor , …, , using the Tucker decomposition [33], and the (p, d, q)-order classical ARIMA is extended to the tensor form so that it can directly deal with multiple environmental factors and better capture the correlation between the time series. Equation (7) is its main expression.
- (4)
- ARIMA predictor. The tensor ARIMA was trained using the soil core tensor , …, to predict the new core tensor , and then the predicted values yt+1 of all soil moisture and environmental factors were obtained simultaneously by Tucker’s inverse transform and MDT inverse transform, and the interrelationship between the soil moisture and multiple environmental factors time series was used in the model construction process to improve the prediction accuracy. Equation (8) is its expression.
2.3.4. Prediction of Nonlinear Components of Soil Moisture
2.4. Design of Experiments
2.4.1. Software and Hardware Configuration
2.4.2. Parameters of Experiments
2.4.3. Evaluation Metrics
2.4.4. Schemes of Experiments
- (1)
- Soil moisture prediction. Using the time series data of DataA~DataE, BAG, and several other prediction models such as Prophet [35], LSTM, DeepAR [36], XGBoost [37], and DeepState [38] were used to conduct the soil moisture prediction comparison experiments. For each prediction model, the average of the prediction results of five datasets was calculated, and the performance of each model was evaluated accordingly.
- (2)
- The effect of the input sequence length on prediction performance. In the process of moisture monitoring and prediction, reasonable sampling intervals are very important for data modeling. Therefore, DataA~DataE were selected to conduct comparisons between the prediction and their actual measured values for three-time spans. The data were sequentially divided according to continuous, every other day, and every two days, and the resulting amounts of data were 365, 182, and 121, respectively, which constitute the three sets of input data for BAG to predict the predicted results at different depths for these three sets of data.
- (3)
- The effect of the number of environmental factors on prediction performance. To verify the effects of different environmental factors on BAG, environmental factors within different correlation thresholds were selected for the comparative analysis of DataA~DataE time series data based on the correlation analysis results.
- (4)
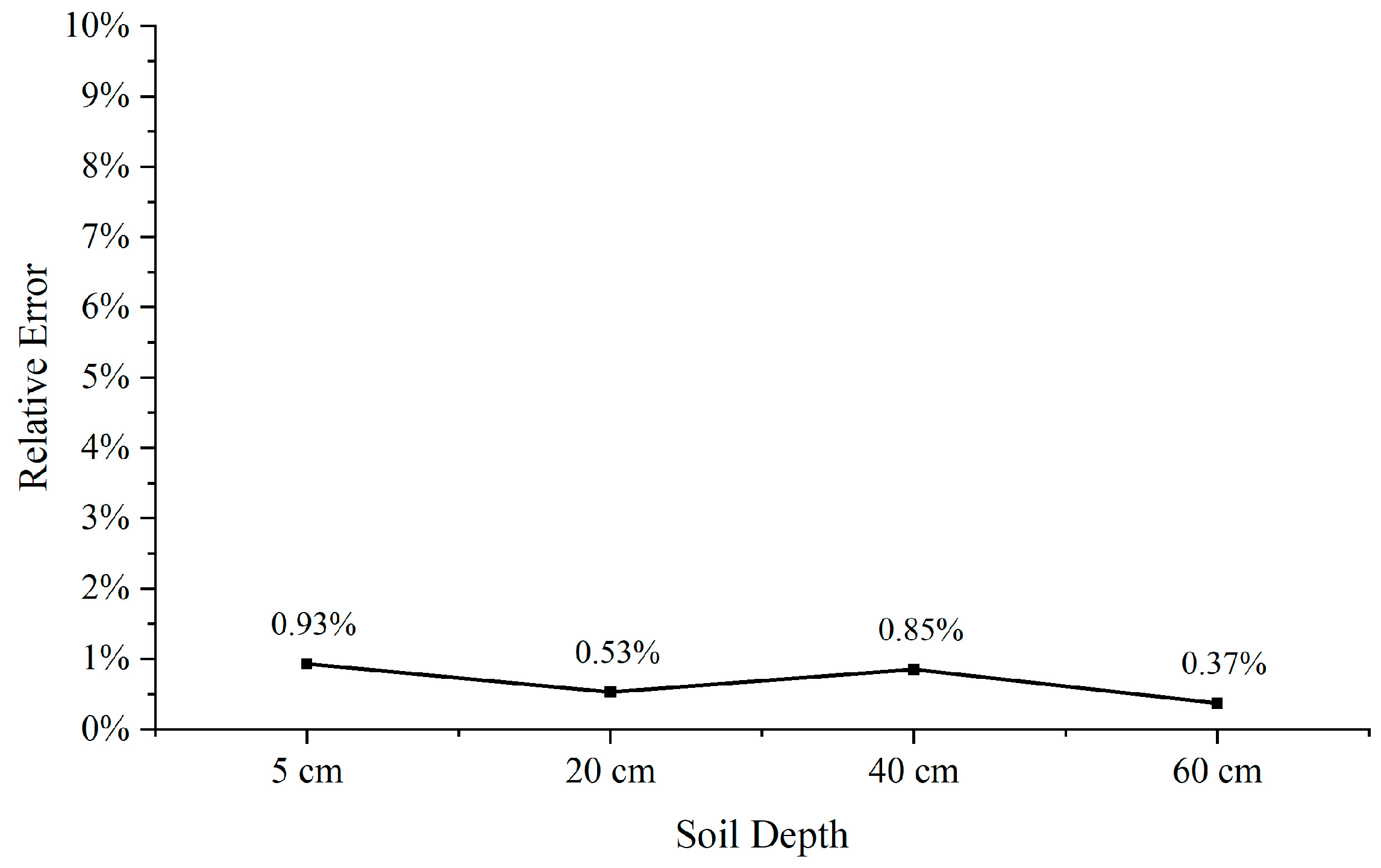
- Correlation between soil depth and performance of prediction. BAG was used to predict different depths of DataA~DataE to analyze the performance of the model at different depths. A total of 364 data items were used for all five data to predict soil moisture at different depths for the next time point.
- (5)
- Ablation experiments. The ablation experiment is one of the key factors for assessing the quality of the model. In this paper, we used DataA~DataE time series data to reduce the improvement features on BAG and verify the necessity of the corresponding improvement features.
3. Results and Discussion
3.1. Data Analysis and Processing
3.1.1. Normality Test
3.1.2. Correlation Analysis
3.2. Soil Moisture Prediction
3.3. Effect of Input Sequence Length on Prediction Performance
3.4. Effect of the Number of Environmental Factors on Prediction Performance
3.5. Correlation between Soil Depth and Performance of Prediction
3.6. Ablation Experiments
- A: Only ARIMA prediction was retained without the block Hankel tensor decomposition and prediction of nonlinear model GRU.
- G: Only the nonlinear part, i.e., the GRU neural network, was retained, and the linear part of BHT-ARIMA was not used for prediction.
- BA: Only the linear part, i.e., the BHT-ARIMA forecasting model, was retained, and no GRU nonlinear forecasts were used.
- AG: The linear part of the ARIMA prediction and the nonlinear part of the GRU neural network were retained without the block Hankel tensor decomposition.
- BAG-Pre: The linear part of BHT-ARIMA prediction and the nonlinear part of GRU neural network prediction were retained without the analysis and processing part of the data.
- BAG: The model in this paper used analysis and processing of data, the linear part of BHT-ARIMA forecasting, and the nonlinear part of GRU forecasting.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Halfond, W.; Orso, A. Improving Test Case Generation for Web Applications Using Automated Interface Discovery. In Proceedings of the the Joint Meeting of the European Software Engineering Conference & the Acm Sigsoft International Symposium on Foundations of Software Engineering, Dubrovnik, Croatia, 3–7 September 2007; pp. 145–154. [Google Scholar]
- Xie, Y.; Aiken, A. Static Detection of Security Vulnerabilities in Scripting Languages. Proc. Usenix Secur. Symp. 2006, 15, 179–192. [Google Scholar]
- Leroux, D.J.; Kerr, Y.H.; Wood, E.F.; Sahoo, A.K.; Bindlish, R.; Jackson, T.J. An approach to constructing a homogeneous time series of soil moisture using SMOS. IEEE Trans. Geosci. Remote Sens. 2013, 52, 393–405. [Google Scholar] [CrossRef]
- Al-Khaldi, M.M.; Johnson, J.T. Soil Moisture Retrievals Using CYGNSS Data in a Time-Series Ratio Method: Progress Update and Error Analysis. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Dahse, J.; Holz, T. Simulation of Built-in PHP Features for Precise Static Code Analysis. In Proceedings of the Network and Distributed System Security Symposium, San Diego, CA, USA, 23–26 February 2014. [Google Scholar]
- Dahse, J.; Holz, T. Static detection of second-order vulnerabilities in web applications. In Proceedings of the USENIX Security Symposium, San Diego, CA, USA, 20–24 August 2014. [Google Scholar]
- Pignotti, G.; Rathjens, H.; Chaubey, I.; Williams, M.; Crawford, M. Strong sensitivity of watershed-scale, ecohydrologic model predictions to soil moisture. Environ. Model. Softw. 2021, 144, 105162. [Google Scholar] [CrossRef]
- Figueroa, M.; Pope, C. Root System Water Consumption Pattern Identification on Time Series Data. Sensors 2017, 17, 1410. [Google Scholar] [CrossRef]
- Lee, J.H. Spatial-Scale Prediction of the SVAT Soil Hydraulic Variables Characterizing Stratified Soils on the Tibetan Plateau from an EnKF Analysis of SAR Soil Moisture. Vadose Zone J. 2014, 13, 11. [Google Scholar] [CrossRef]
- Cai, Y.; Zheng, W.; Zhang, X.; Zhangzhong, L.; Xue, X. Research on soil moisture prediction model based on deep learning. PLoS ONE 2019, 14, e0214508. [Google Scholar] [CrossRef]
- Guo, Z.; Zhao, J.; Zhang, W.; Wang, J. A corrected hybrid approach for wind speed prediction in Hexi Corridor of China. Energy 2011, 36, 1668–1679. [Google Scholar] [CrossRef]
- Peterson, T.J.; Western, A.W. Nonlinear time-seriesmodeling of unconfined groundwater head. Water Resour. Res. 2015, 50, 8330–8355. [Google Scholar] [CrossRef]
- Meißner, M.; Köhler, M.; Schwendenmann, L.; Hölscher, D.; Dyckmans, J. Soil water uptake by trees using water stable isotopes (delta H-2 and delta O-18)-a method test regarding soil moisture, texture and carbonate. Plant Soil 2014, 376, 327–335. [Google Scholar] [CrossRef]
- Shunjun, H.U.; Zhu, H.; Chen, Y. One-dimensional horizontal infiltration experiment for determining permeability coefficient of loamy sand. J. Arid. Land 2017, 9, 27–37. [Google Scholar]
- Wang, S.F.; Xu, C.; Song, H.Y. Analysis of the Effect of Moisture on Soil Organic Matter Determination and Anti-Moisture Interference Model Building Based on Vis-NIR Spectral Technology. Spectrosc. Spectr. Anal. 2016, 36, 3249–3253. [Google Scholar]
- Wu, D.; Wang, T.; Di, C.; Wang, L.; Chen, X. Investigation of controls on the regional soil moisture spatiotemporal patterns across different climate zones. Sci. Total Environ. 2020, 726, 138214. [Google Scholar] [CrossRef] [PubMed]
- Huang, X.; Shi, Z.H.; Zhu, H.D.; Zhang, H.Y.; Ai, L.; Yin, W. Soil moisture dynamics within soil profiles and associated environmental controls. Catena 2015, 136, 189–196. [Google Scholar] [CrossRef]
- Niu, H.; Meng, F.; Yue, H.; Yang, L.; Dong, J.; Zhang, X. Soil Moisture Prediction in Peri-urban Beijing, China: Gene Expression Programming Algorithm. Intell. Autom. Soft Comput. 2021, 28, 93–106. [Google Scholar] [CrossRef]
- Xiaolei, F.U.; Zhongbo, Y.U.; Tang, Y.; Ding, Y.; Lyu, H.; Zhang, B.; Jiang, X.; Ju, O. Evaluating Soil Moisture Predictions Based on Ensemble Kalman Filter and SiB2 Model. J. Meteorol. Res. 2019, 22, 190–205. [Google Scholar]
- Shi, Q.; Yin, J.; Cai, J.; Cichocki, A.; Yokota, T.; Chen, L.; Yuan, M.; Zwng, J. Block Hankel Tensor ARIMA for Multiple Short Time Series Forecasting. In Proceedings of the AAAI Conference on Artificial Intelligenc, Polo Alto, CA, USA, 22 February–1 March 2022. [Google Scholar]
- Ji, S.P.; Meng, Y.L.; Yan, L.; Dong, G.S.; Liu, D. GRU-corr Neural Network Optimized by Improved PSO Algorithm for Time Series Prediction. Int. J. Artif. Intell. Tools 2020, 29, 2040010. [Google Scholar] [CrossRef]
- Jeong, H.C.; Jung, J.; Kang, B.O. Development of ARIMA-based forecasting algorithms using meteorological indices for seasonal peak load. Trans. Korean Inst. Electr. Eng. 2018, 67, 1257–1264. [Google Scholar]
- Agarwal, A.; Amjad, M.J.; Shah, D.; Shen, D. Model Agnostic Time Series Analysis via Matrix Estimation. In Proceedings of the Acm on Measurement & Analysis of Computing Systems, New York, NY, USA, 13 June 2018; Volume 2, pp. 1–39. [Google Scholar]
- Araujo, M.; Ribeiro, P.; Faloutsos, C. TensorCast: Forecasting with Context Using Coupled Tensors. In Proceedings of the 2017 IEEE International Conference on Data Mining (ICDM), New Orleans, LA, USA, 18–21 November 2017. [Google Scholar]
- Yokota, T. Missing Slice Recovery for Tensors Using a Low-rank Model in Embedded Space. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Yokota, T.; Hontani, H. Tensor Completion with Shift-invariant Cosine Bases. In Proceedings of the 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Honolulu, HI, USA, 12–15 November 2018. [Google Scholar]
- Shi, Q.; Cheung, Y.M.; Zhao, Q.; Lu, H. Feature Extraction for Incomplete Data Via Low-Rank Tensor Decomposition With Feature Regularization. IEEE Trans. Neural Netw. Learn. Systems. 2018, 30, 1803–1817. [Google Scholar] [CrossRef]
- Yang, Z.; Cheung, Y.M. Bayesian Low-Tubal-Rank Robust Tensor Factorization with Multi-Rank Determination. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 62–76. [Google Scholar]
- Faloutsos, C.; Flunkert, V.; Gasthaus, J.; Januschowski, T.; Wang, Y. Forecasting Big Time Series: Theory and Practice. In Proceedings of the 25th ACM SIGKDD International Conference, Anchorage, AK, USA, 4–8 August; 2019. [Google Scholar]
- Ma, X.; Zhang, L.; Xu, L.; Liu, Z.; Chen, G.; Xiao, Z.; Wang, Y.; Wu, Z. Large-scale User Visits Understanding and Forecasting with Deep Spatial-Temporal Tensor Factorization Framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining; Association for Computing Machinery: New York, NY, USA, 2019; pp. 2403–2411. [Google Scholar]
- Ding, J.; Tarokh, V.; Yang, Y. Bridging AIC and BIC: A New Criterion for Autoregression. IEEE Trans. Inf. Theory 2018, 64, 4024–4043. [Google Scholar] [CrossRef]
- Selig, K.; Shaw, P.; Ankerst, D. Bayesian information criterion approximations to Bayes factors for univariate and multivariate logistic regression models. Int. J. Biostat. 2020, 17, 241–266. [Google Scholar] [CrossRef]
- Jing, P.; Su, Y.; Jin, X.; Zhang, C. High-Order Temporal Correlation Model Learning for Time-Series Prediction. IEEE Trans. Cybern. 2019, 49, 2385–2397. [Google Scholar] [CrossRef]
- Kumar, P.; Sihag, P.; Chaturvedi, P.; Uday, K.V.; Dutt, V. BS-LSTM: An Ensemble Recurrent Approach to Forecasting Soil Movements in the Real World. Front. Earth Sci. 2021, 9, 696792. [Google Scholar] [CrossRef]
- Taylor, S.J.; Letham, B. Forecasting at Scale. Am. Stat. 2018, 72, 37–45. [Google Scholar] [CrossRef]
- Flunkert, V.; Salinas, D.; Gasthaus, J. DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks. Int. J. Forecast. 2020, 36, 1181–1191. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. ACM: New York, NY, USA, 2016. [Google Scholar]
- Rangapuram, S.S.; Seeger, M.W.; Gasthaus, J.; Stella, L.; Wang, Y.; Januschowski, T. Deep State Space Models for Time Series Forecasting. In Proceedings of the Neural Information Processing Systems, Cambridge, MA, USA, 8–13 December 2018. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Position | Climate |
|---|---|---|
| DataA | 28°54′~29°29′ N, 118°01′~118°37′ E | Subtropical monsoon climate |
| DataB | 29°55′–30°15′ N, 121°38′–122°15′ E | Oceanic monsoon climate in the south margin of the north subtropical zone |
| DataC | 29°11′–30°02′ N, 118°20′–119°20′ E | Subtropical monsoon climate |
| DataD | 28.49′~29.19′ N, 120.17′~120.47′ E | Subtropical monsoon climate |
| DataE | 30°10′~30°16′ N, 120°4′~120°10′ E | Subtropical monsoon climate |
| Item | Detail |
|---|---|
| CPU | 11th Gen Intel® CoreTM i5-1135G7 @ 2.40 GHz |
| RAM | 16 GB |
| Operating system | 64-bit Windows 11 |
| CUDA | CUDA11.3 |
| Data processing | Python 3.6 |
| Parameter | Value | Meaning |
|---|---|---|
| taus | [12,5] | MDT tensorization |
| Rs | [5,5] | Tucker decomposition |
| K | 10 | Training iteration of BHT-ARIMA |
| GRU_D1 | 50 | The first layer GRU input dimension |
| GRU_D2 | 40 | The second layer GRU input dimension |
| Dropout | 20% | Random inactivation rate of neural nodes |
| Loss | RMSprop | Loss function of GRU |
| Optimizer | Adam | The optimizer algorithm of GRU |
| Learning rate | 0.01 | Controling the rate of parameter update |
| Batch-size | 32 | Batch size |
| epoch | 100 | Training iteration of GRU |
| Median | Average | Standard Deviation | Partial Degrees | Kurtosis | p-Value | |
|---|---|---|---|---|---|---|
| SM-5 cm (%) | 22.565 | 22.211 | 3.325 | −0.459 | −0.304 | 9.76 × 10−4 |
| SM-20 cm (%) | 13.295 | 13.288 | 1.971 | 0.291 | 0.969 | 9.87 × 10−4 |
| SM-40 cm (%) | 14.2 | 15.306 | 5.24 | 3.263 | 10.95 | 5.81 × 10−4 |
| SM-60 cm (%) | 17.515 | 19.72 | 6.159 | 1.75 | 1.902 | 7.26 × 10−4 |
| ST-5 cm (°C) | 18.43 | 17.748 | 7.275 | −0.09 | −1.293 | 9.41 × 10−4 |
| ST-20 cm (°C) | 18.305 | 17.565 | 6.629 | −0.073 | −1.316 | 9.38 × 10−4 |
| ST-40 cm (°C) | 18.275 | 17.469 | 5.981 | −0.067 | −1.345 | 9.34 × 10−4 |
| ST-60 cm (°C) | 18.185 | 17.608 | 5.41 | −0.054 | −1.367 | 9.32 × 10−4 |
| Atmospheric temperature (°C) | 17.405 | 16.438 | 8.549 | −0.193 | −1.153 | 9.53 × 10−4 |
| Rainfall (mm) | 0.05 | 5.003 | 12.311 | 4.841 | 37.366 | 4.58 × 10−4 |
| Wind Speed (m/s) | 0.05 | 0.077 | 0.088 | 1.706 | 3.63 | 8.18 × 10−4 |
| Wind direction (°) | 142.3 | 172.923 | 130.836 | 0.01 | −1.726 | 8.48 × 10−4 |
| Solar radiation intensity (kw/m2) | 0.1 | 0.109 | 0.07 | 0.361 | −0.959 | 9.48 × 10−4 |
| Vegetation temperature (°C) | 18.695 | 17.641 | 9.543 | −0.208 | −1.011 | 9.64 × 10−4 |
| Air Relative Humidity (%) | 80.5 | 80.28 | 10.078 | −0.581 | 0.576 | 9.7 × 10−4 |
| Daylight hours (h) | 2.73 | 2.918 | 2.693 | 0.219 | −1.518 | 8.55 × 10−4 |
| Daily evaporation (mm) | 0.91 | 10.922 | 21.946 | 2.931 | 11.203 | 5.66 × 10−4 |
| SM-5 cm | SM-20 cm | SM-40 cm | SM-60 cm | ST-5 cm | ST-20 cm | ST-40 cm | ST-60 cm | |
|---|---|---|---|---|---|---|---|---|
| SM-5 cm | 1 | 0.76 | 0.904 | 0.832 | −0.345 | −0.367 | −0.394 | −0.421 |
| SM-20 cm | 0.76 | 1 | 0.73 | 0.747 | −0.437 | −0.453 | −0.465 | −0.476 |
| SM-40 cm | 0.904 | 0.73 | 1 | 0.964 | −0.273 | −0.296 | −0.322 | −0.35 |
| SM-60 cm Average | 0.832 0.874 | 0.647 0.784 | 0.965 0.899 | 1 0.885 | −0.237 −0.323 | −0.265 −0.345 | −0.298 −0.369 | −0.332 −0.394 |
| Atmospheric Temperature | Rainfall | Wind Speed | WindDirection | Solar Radiation Intensity | Vegetation Temperature | Air RelativeHumidity | Daylight Hours | DailyEvaporation | |
|---|---|---|---|---|---|---|---|---|---|
| SM-5 cm | −0.345 | 0.497 | −0.087 | −0.07 | −0.446 | −0.362 | 0.468 | −0.442 | 0.121 |
| SM-20 cm | −0.43 | 0.328 | −0.213 | −0.042 | −0.395 | −0.43 | 0.282 | −0.304 | −0.367 |
| SM-40 cm | −0.266 | 0.378 | −0.096 | −0.055 | −0.303 | −0.275 | 0.349 | −0.316 | 0.076 |
| SM-60 cmAverage | −0.218 −0.314 | 0.331 0.383 | −0.091 −0.121 | −0.058 −0.056 | −0.222 −0.341 | −0.223 −0.322 | 0.278 0.344 | −0.253 −0.328 | 0.083 −0.021 |
| DataA | DataB | DataC | DataD | DataE | ||
|---|---|---|---|---|---|---|
| SM-5 cm | (p,d,q) | (1,1,1) | (1,1,1) | (0,1,2) | (0,1,1) | (1,1,1) |
| AIC | −1117.463 | −1250.764 | −1050.055 | −1164.823 | −1356.41 | |
| SM-20 cm | (p,d,q) | (1,1,1) | (2,1,3) | (1,1,1) | (2,1,1) | (1,1,1) |
| AIC | −1459.317 | −1452.934 | −1171.537 | −1086.214 | −1507.423 | |
| SM-40 cm | (p,d,q) | (2,1,1) | (1,1,1) | (1,1,1) | (0,1,1) | (0,1,1) |
| AIC | −718.706 | −1396.386 | −1217.633 | −1035.812 | −1404.259 | |
| SM-60 cm | (p,d,q) | (2,1,0) | (1,1,1) | (1,1,1) | (2,1,1) | (1,1,1) |
| AIC | −648.05 | −1537.424 | −1285.633 | −438.881 | −1487.736 |
| Prophet | LSTM | DeepAR | XGBoost | DeepState | BAG | ||
|---|---|---|---|---|---|---|---|
| SM-5 cm | Ground truth (%) | 23.16 | 23.16 | 23.16 | 23.16 | 23.16 | 23.16 |
| Prediction (%) | 22.139 | 22.323 | 23.772 | 24.704 | 23.990 | 23.442 | |
| RE (%) | −4.405 | −3.61 | 2.642 | 6.666 | 3.583 | 1.218 | |
| SM-20 cm | Ground truth (%) | 14.35 | 14.35 | 14.35 | 14.35 | 14.35 | 14.35 |
| Prediction (%) | 14.982 | 12.896 | 12.786 | 12.550 | 14.291 | 14.341 | |
| RE (%) | 4.405 | −10.13 | −10.895 | −12.541 | −0.411 | −0.060 | |
| SM-40 cm | Ground truth (%) | 14.34 | 14.34 | 14.34 | 14.34 | 14.34 | 14.34 |
| Prediction (%) | 13.060 | 15.851 | 14.004 | 16.339 | 14.526 | 14.319 | |
| RE (%) | −8.923 | 10.54 | −2.342 | 13.937 | 1.298 | −0.144 | |
| SM-60 cm | Ground truth (%) | 17.57 | 17.57 | 17.57 | 17.57 | 17.57 | 17.57 |
| Prediction (%) | 16.939 | 20.074 | 17.668 | 19.877 | 17.536 | 17.470 | |
| RE (%) | −3.590 | 14.25 | 0.556 | 13.128 | −0.196 | −0.569 |
| t = 364 | t = 182 | t = 121 | ||
|---|---|---|---|---|
| SM-5 cm | Ground truth (%) | 23.16 | 23.16 | 23.16 |
| Prediction (%) | 23.442 | 23.457 | 24.035 | |
| RE (%) | 1.218 | 1.281 | 3.778 | |
| SM-20 cm | Ground truth (%) | 14.35 | 14.35 | 14.35 |
| Prediction (%) | 14.341 | 14.389 | 15.218 | |
| RE (%) | −0.060 | 0.275 | 6.052 | |
| SM-40 cm | Ground truth (%) | 14.34 | 14.34 | 14.34 |
| Prediction (%) | 14.319 | 11.307 | 15.429 | |
| RE (%) | −0.144 | −21.148 | 7.591 | |
| SM-60 cm | Ground truth (%) | 17.57 | 17.57 | 17.57 |
| Prediction (%) | 17.470 | 17.125 | 14.989 | |
| RE (%) | −0.569 | −2.532 | −14.691 |
| n = 17 | n = 14 | n = 4 | ||
|---|---|---|---|---|
| SM-5 cm | Ground truth (%) | 23.16 | 23.16 | 23.16 |
| Prediction (%) | 23.018 | 23.442 | 23.259 | |
| RE (%) | −0.611 | 1.218 | 0.427 | |
| SM-20 cm | Ground truth (%) | 14.35 | 14.35 | 14.35 |
| Prediction (%) | 14.298 | 14.341 | 14.408 | |
| RE (%) | −0.363 | −0.060 | 0.402 | |
| SM-40 cm | Ground truth (%) | 14.34 | 14.34 | 14.34 |
| Prediction (%) | 10.259 | 14.319 | 13.853 | |
| RE (%) | −28.457 | −0.144 | −3.394 | |
| SM-60 cm | Ground truth (%) | 17.57 | 17.57 | 17.57 |
| Prediction (%) | 14.697 | 17.470 | 17.114 | |
| RE (%) | −16.352 | −0.569 | −2.595 |
| DataA | DataB | DataC | DataD | DataE | ||
|---|---|---|---|---|---|---|
| SM-5 cm | Ground truth (%) | 23.16 | 25.2 | 31.1 | 15.5 | 19.7 |
| Prediction (%) | 23.442 | 25.266 | 31.171 | 15.849 | 19.566 | |
| RE (%) | 1.218 | 0.263 | 0.227 | 2.254 | −0.679 | |
| SM-20 cm | Ground truth (%) | 14.35 | 24.2 | 25.5 | 39 | 18.83 |
| Prediction (%) | 14.341 | 24.134 | 25.491 | 38.361 | 18.951 | |
| RE (%) | −0.060 | −0.274 | −0.034 | −1.638 | 0.642 | |
| SM-40 cm | Ground truth (%) | 14.34 | 25.6 | 20 | 30 | 25.54 |
| Prediction (%) | 14.319 | 25.681 | 20.123 | 29.218 | 25.409 | |
| RE (%) | −0.144 | 0.371 | 0.615 | −2.608 | −0.515 | |
| SM-60 cm | Ground truth (%) | 17.57 | 20.2 | 20 | 42.5 | 32.85 |
| Prediction (%) | 17.470 | 20.281 | 20.013 | 42.273 | 32.943 | |
| RE (%) | −0.569 | 0.402 | 0.067 | −0.534 | 0.282 |
| A | G | BA | AG | BAG-Pre | BAG | ||
|---|---|---|---|---|---|---|---|
| SM-5 cm | Ground truth (%) | 23.16 | 23.16 | 23.16 | 23.16 | 23.16 | 23.16 |
| Prediction (%) | 24.291 | 24.520 | 22.586 | 24.196 | 23.317 | 23.442 | |
| RE (%) | 4.881 | 5.871 | −2.478 | 4.473 | 3.268 | 1.218 | |
| SM-20 cm | Ground truth (%) | 14.35 | 14.35 | 14.35 | 14.35 | 14.35 | 14.35 |
| Prediction (%) | 13.450 | 12.663 | 14.202 | 13.666 | 14.165 | 14.341 | |
| RE (%) | −6.274 | −11.758 | −1.030 | −4.768 | −1.287 | −0.060 | |
| SM-40 cm | Ground truth (%) | 14.34 | 14.34 | 14.34 | 14.34 | 14.34 | 14.34 |
| Prediction (%) | 16.327 | 21.390 | 13.765 | 17.0 | 10.633 | 14.319 | |
| RE (%) | 13.86 | 49.165 | −4.010 | 18.547 | −25.848 | −0.144 | |
| SM-60 cm | Ground truth (%) | 17.57 | 17.57 | 17.57 | 17.57 | 17.57 | 17.57 |
| Prediction (%) | 17.475 | 20.066 | 17.438 | 19.285 | 14.257 | 17.470 | |
| RE (%) | −0.540 | 14.208 | −0.752 | 9.760 | −18.859 | −0.569 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, G.; Zhuang, L.; Mo, L.; Yi, X.; Wu, P.; Wu, X. BAG: A Linear-Nonlinear Hybrid Time Series Prediction Model for Soil Moisture. Agriculture 2023, 13, 379. https://doi.org/10.3390/agriculture13020379
Wang G, Zhuang L, Mo L, Yi X, Wu P, Wu X. BAG: A Linear-Nonlinear Hybrid Time Series Prediction Model for Soil Moisture. Agriculture. 2023; 13(2):379. https://doi.org/10.3390/agriculture13020379
Chicago/Turabian StyleWang, Guoying, Lili Zhuang, Lufeng Mo, Xiaomei Yi, Peng Wu, and Xiaoping Wu. 2023. "BAG: A Linear-Nonlinear Hybrid Time Series Prediction Model for Soil Moisture" Agriculture 13, no. 2: 379. https://doi.org/10.3390/agriculture13020379
APA StyleWang, G., Zhuang, L., Mo, L., Yi, X., Wu, P., & Wu, X. (2023). BAG: A Linear-Nonlinear Hybrid Time Series Prediction Model for Soil Moisture. Agriculture, 13(2), 379. https://doi.org/10.3390/agriculture13020379