


Predicting Sugarcane Yield via the Use of an Improved Least Squares Support Vector Machine and Water Cycle Optimization Model


Abstract
:1. Introduction
2. Methodology
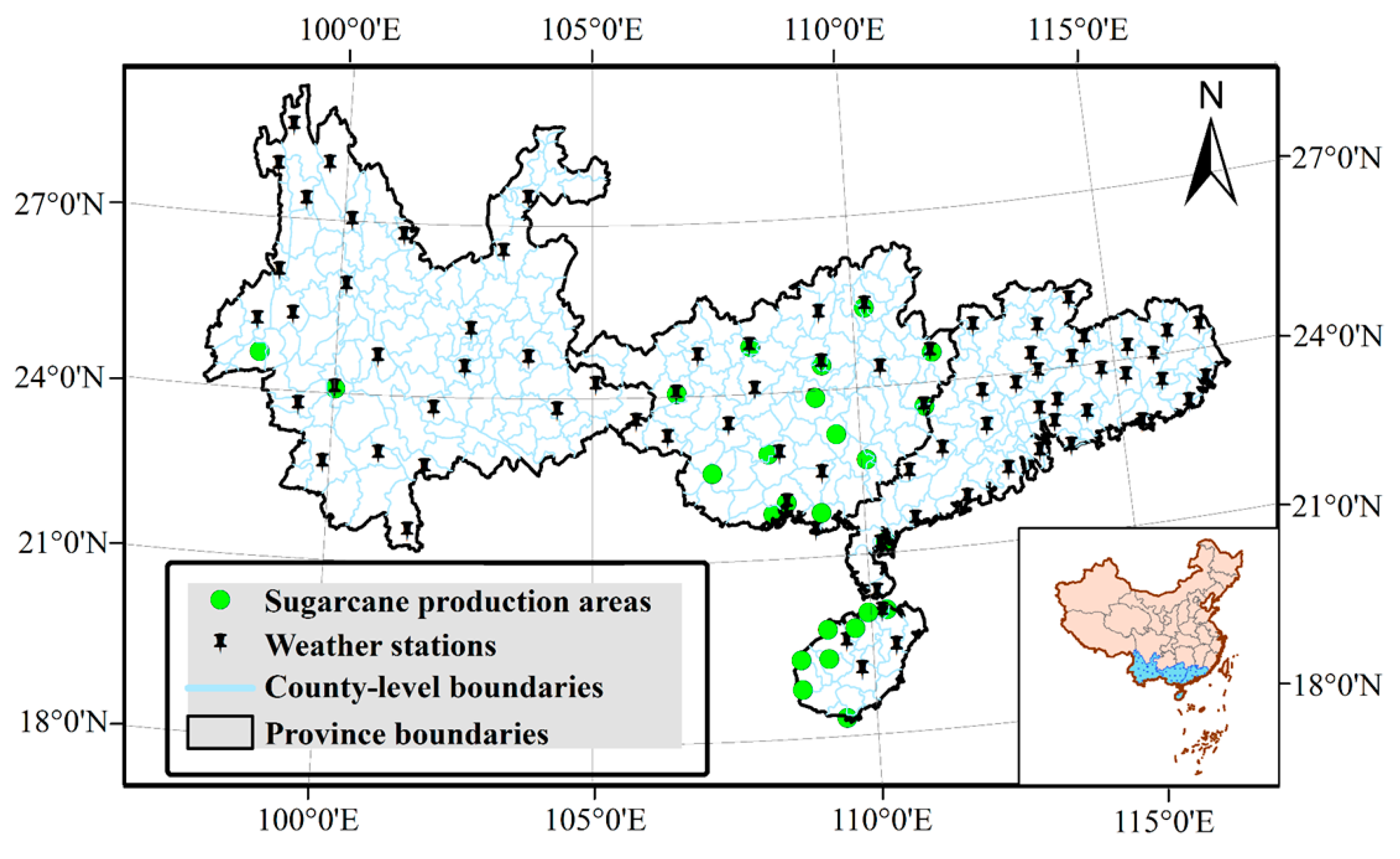
2.1. Sugarcane Study Area
2.2. Meteorological and Soil Data Collection
2.3. Model Descriptions
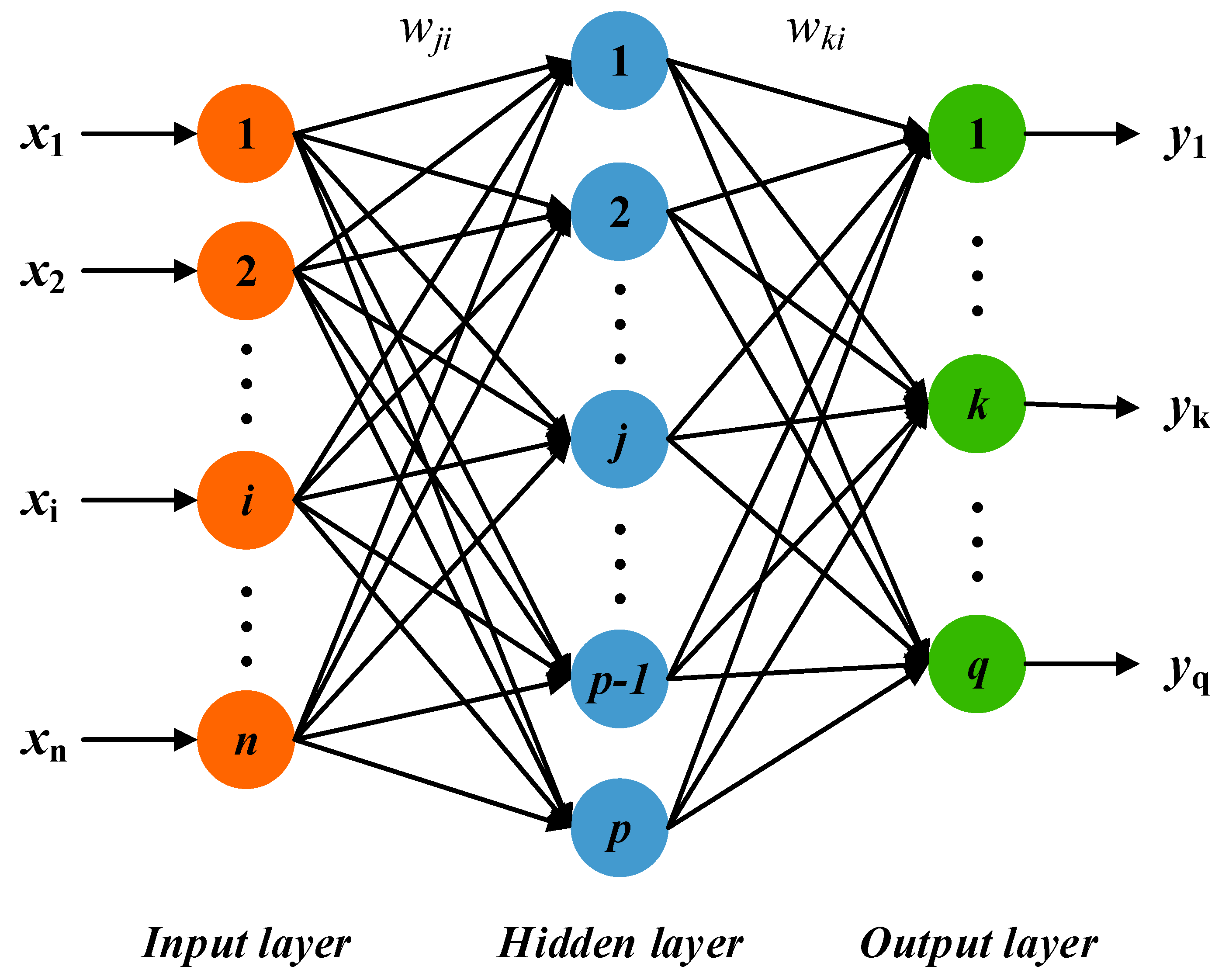
2.3.1. Back Propagation Neural Network (BPNN)
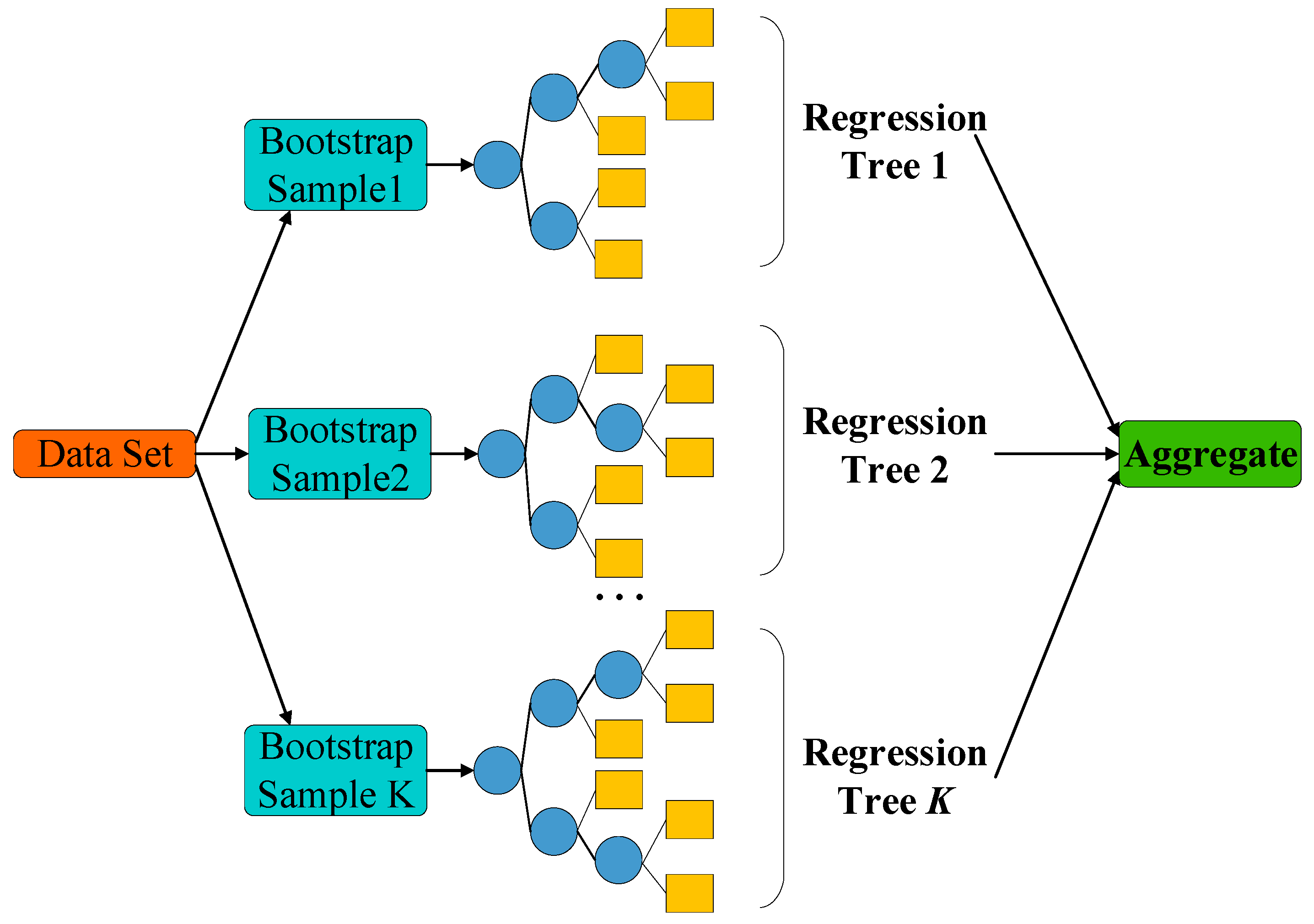
2.3.2. Random Forest (RF)
2.3.3. Least Squares Support Vector Machine (LSSVM)
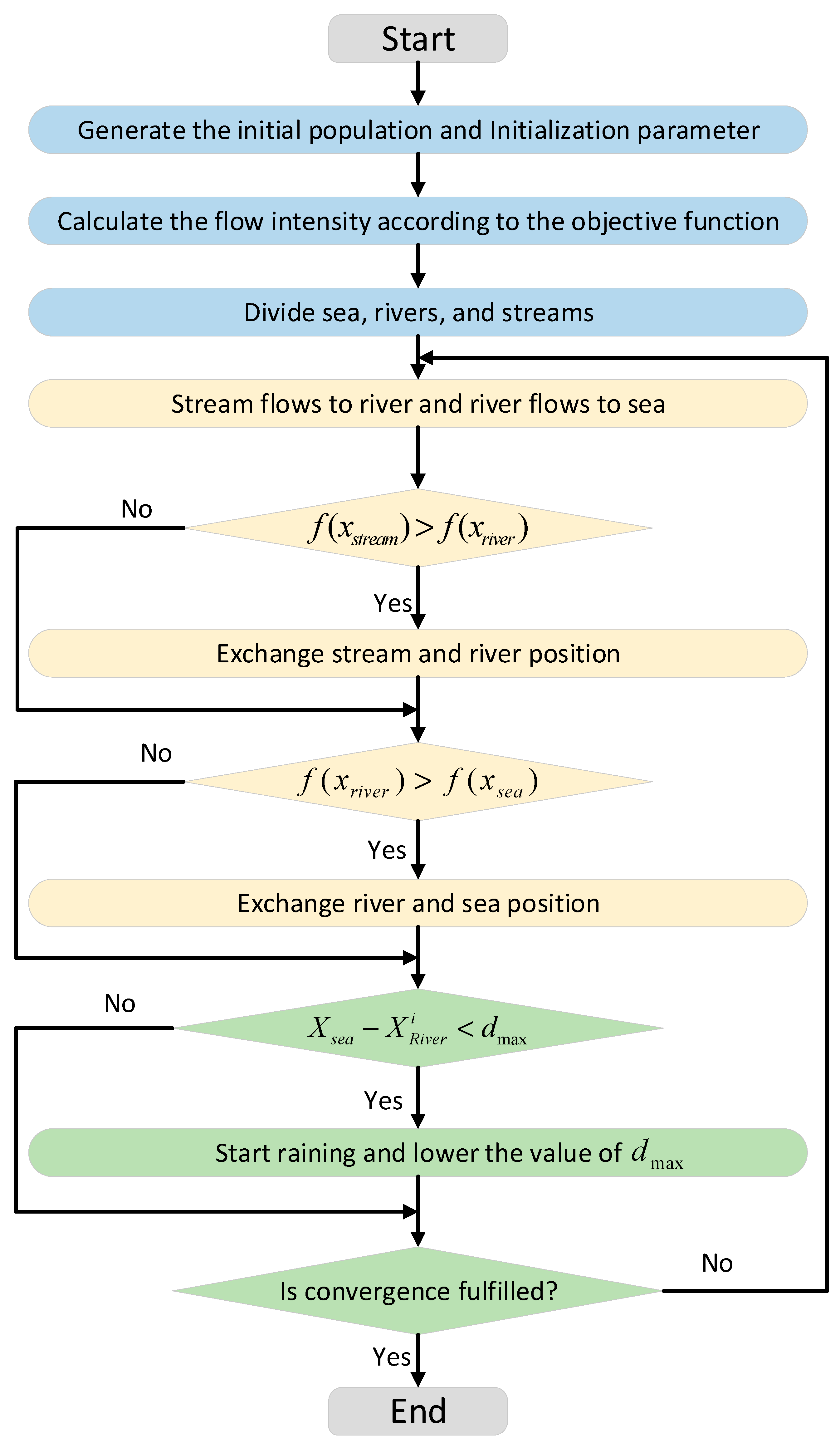
2.3.4. Water Cycle Algorithm (WCA)
| Algorithm 1 Pseudo-code of WCA |
| Initialize parameters: , , , ; |
| Randomly initialize the population by Equation (19); |
| Calculate the fitness value of the population by Equation (21); |
| Sort the population in ascending order by fitness value; |
| Divide the population into three categories: , , ; |
| Calculate the number of streams flowing into a river or ocean by Equation (24); |
| while do |
| Allocate streams moving to sea and generate new stream by Equation (27); |
| if then |
| Swap and ; |
| end if |
| Allocate streams moving to river and generate new stream by Equation (26); |
| if then |
| Swap and ; |
| end if |
| Allocate rivers moving to sea and generate new river by Equation (28); |
| if then |
| Swap and ; |
| end if |
| Check the evaporation to generate new streams by Equation (31); |
| Decrease by Equation (30); |
| end while |
| return |
2.3.5. Variance-Based Sensitivity Analysis
3. Result and Discussion
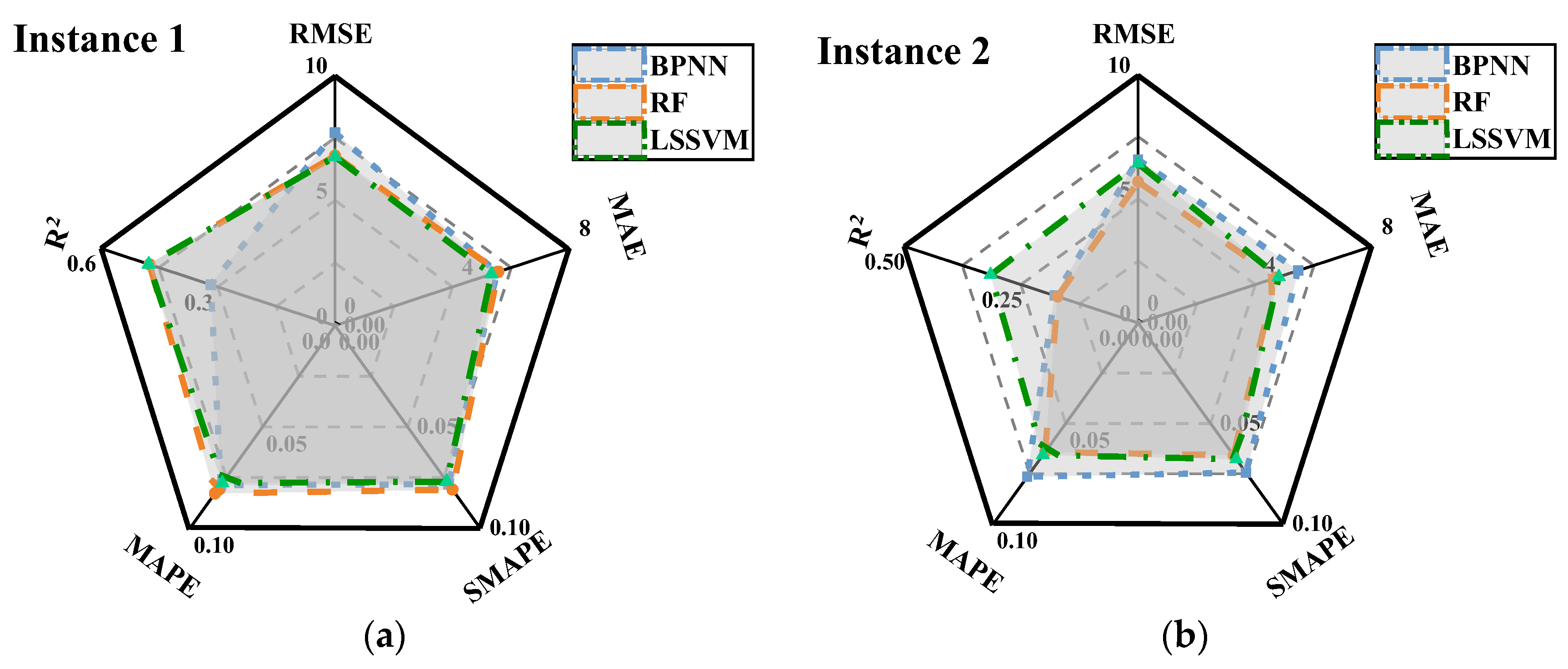
3.1. Models Performance
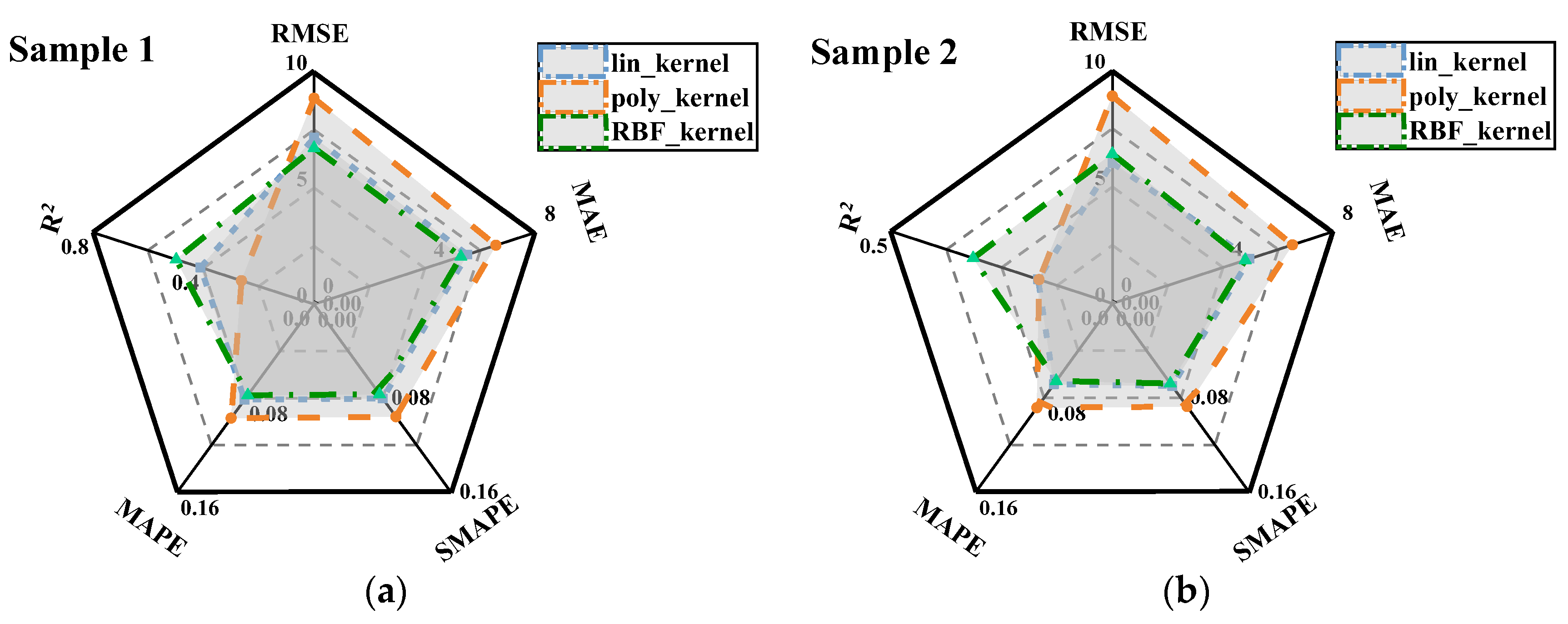
3.2. Comparison of LSSVM Models with Different Kernel Functions
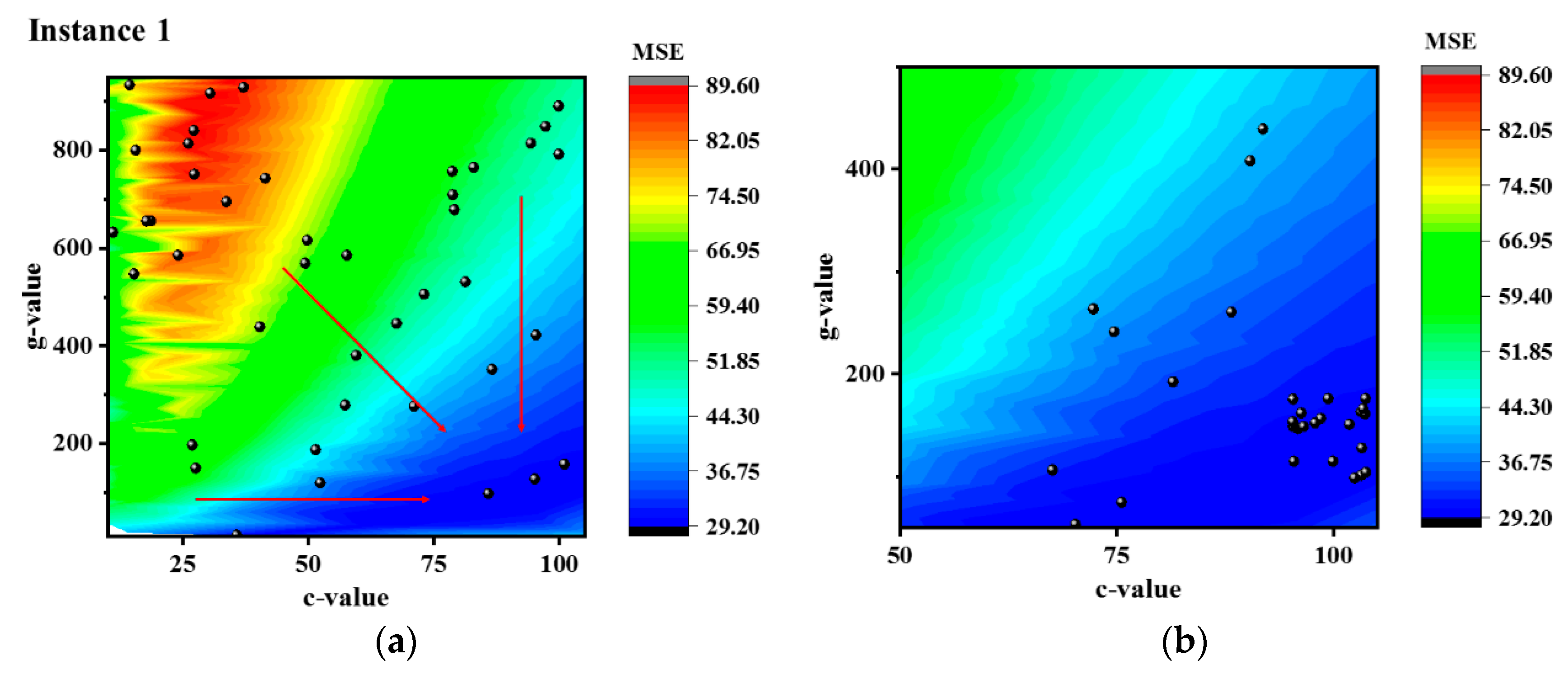
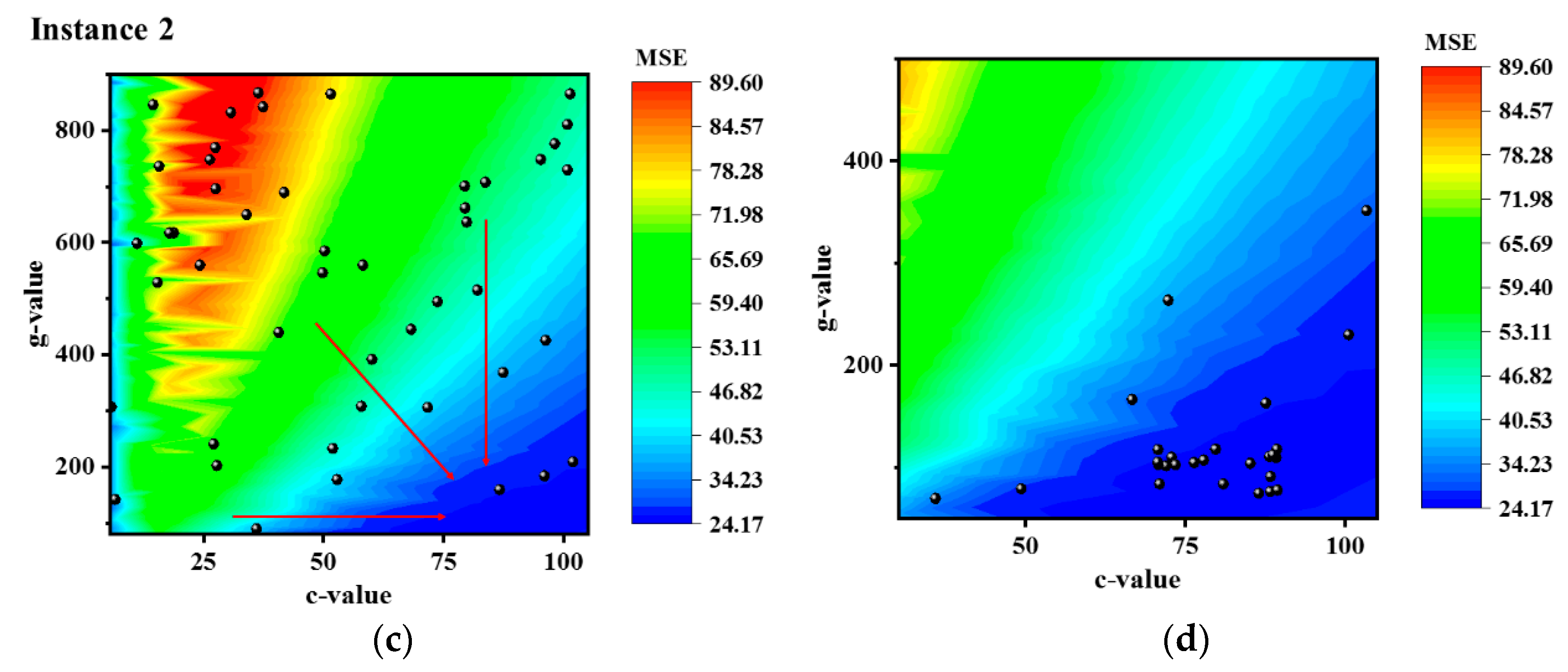
3.3. WCA Optimization Results
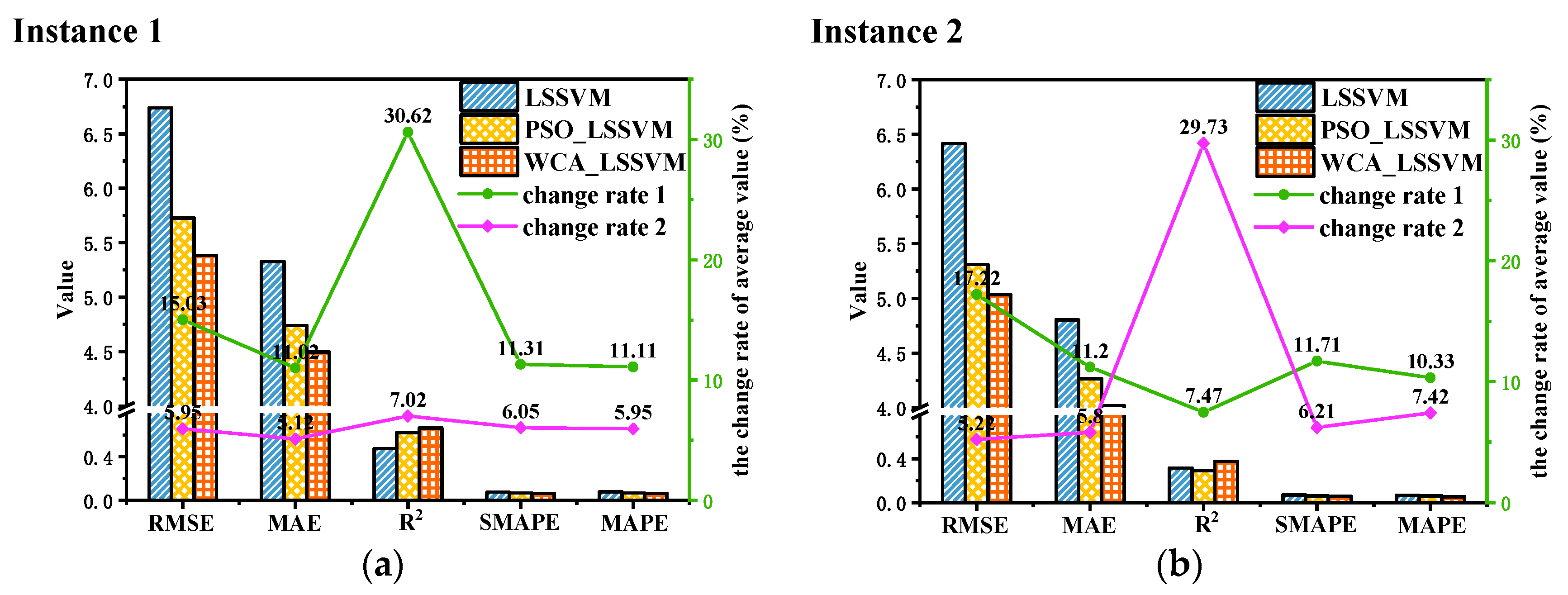
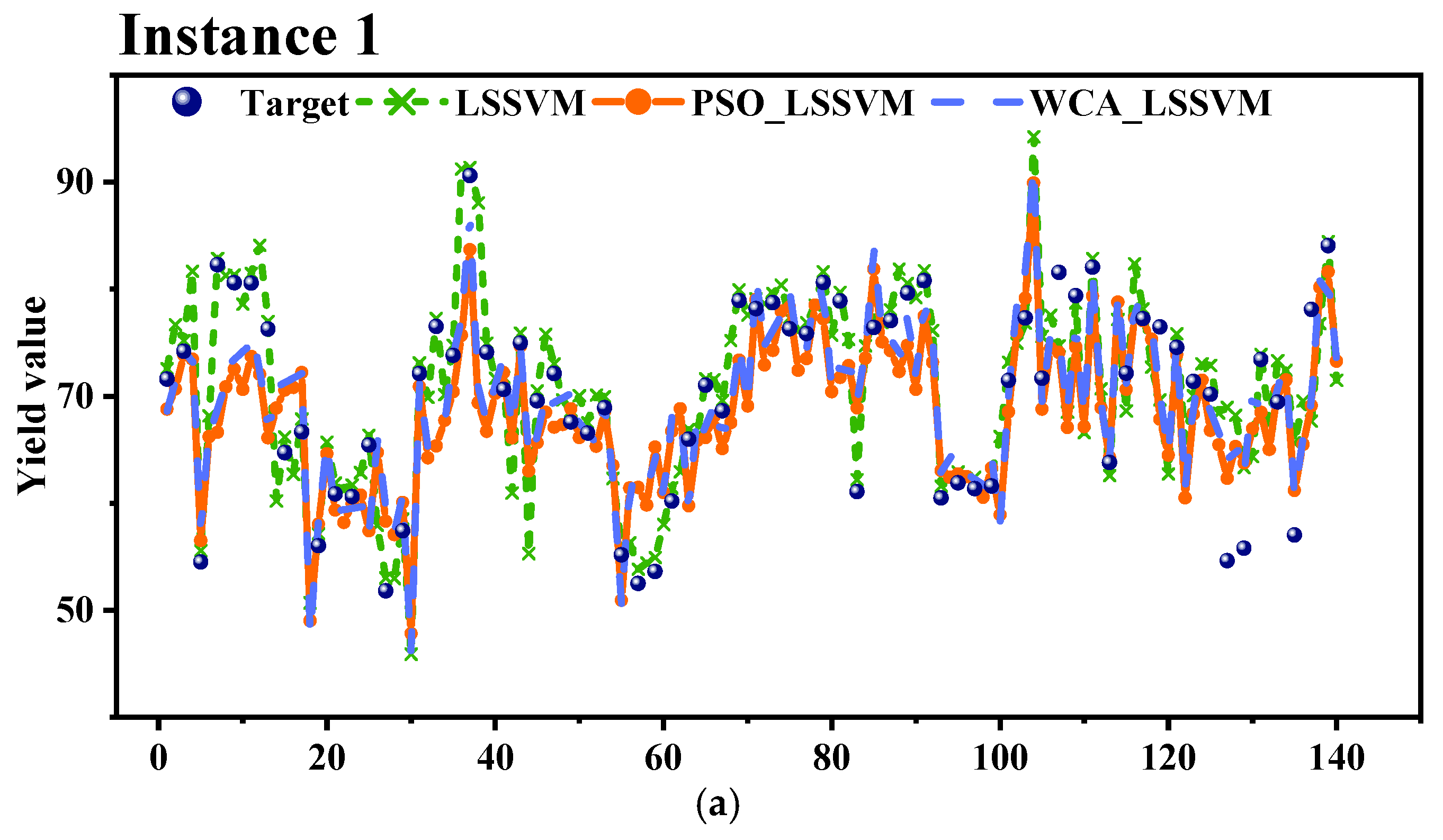
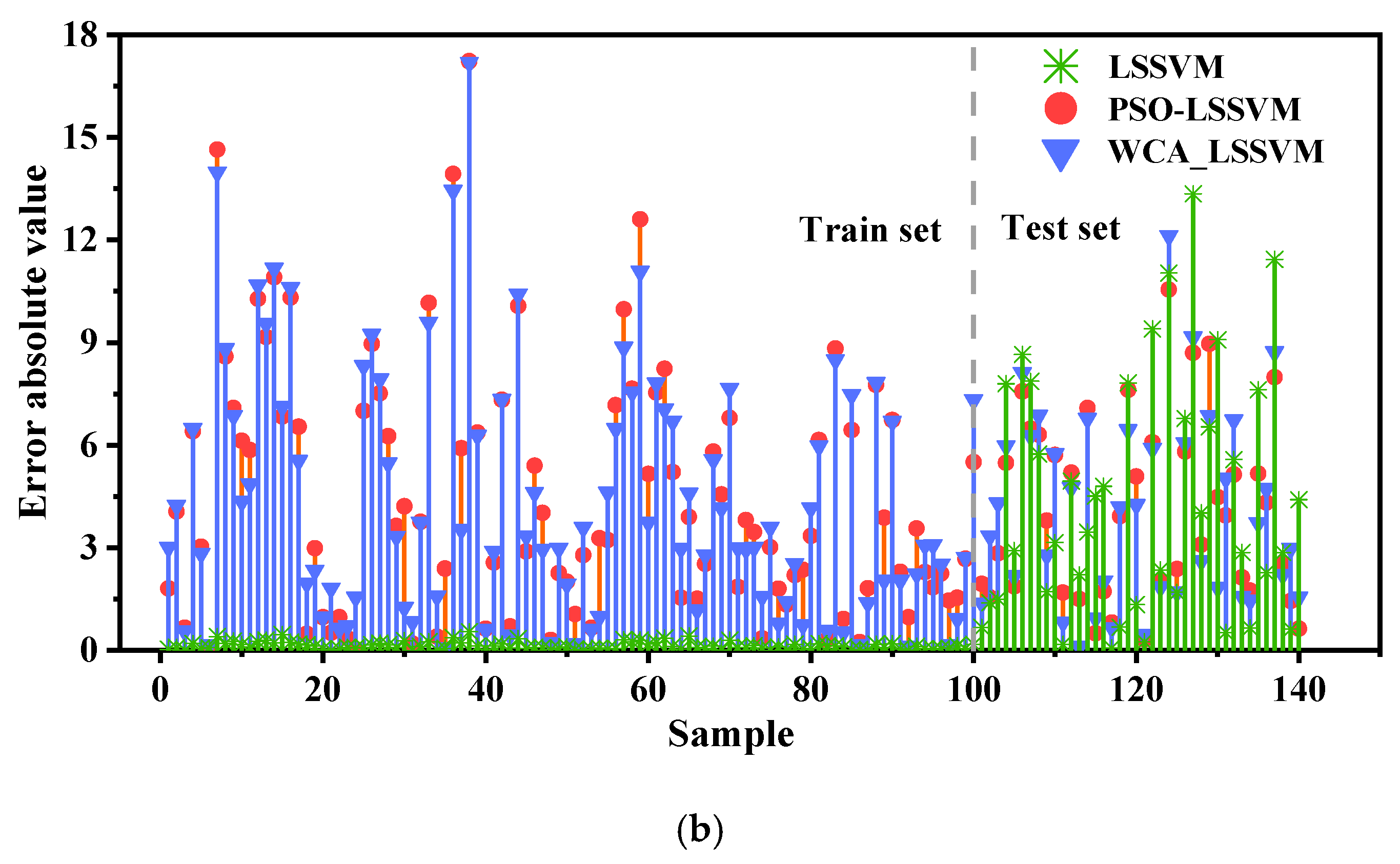
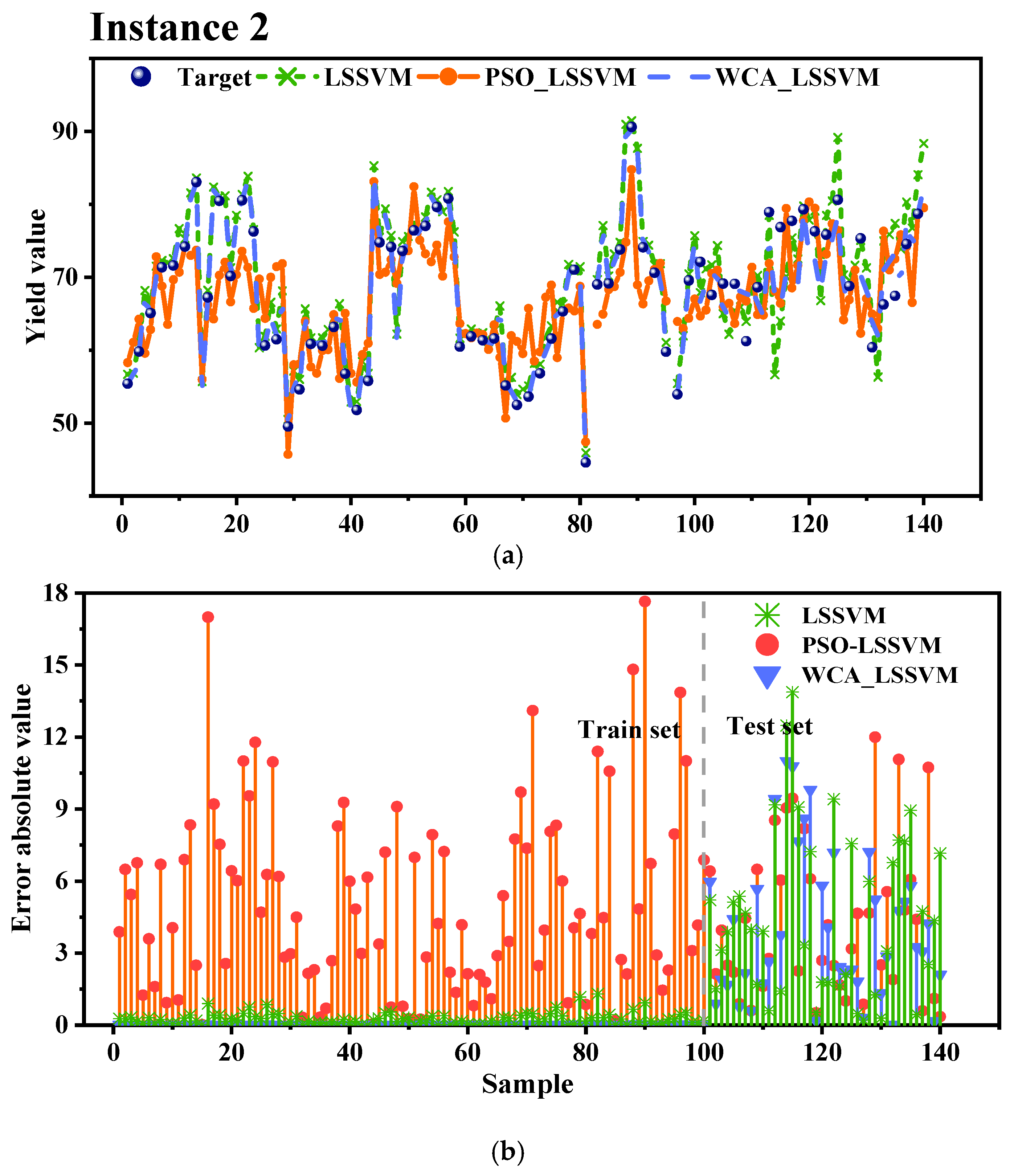
3.4. WCA-LSSVM Model Performance
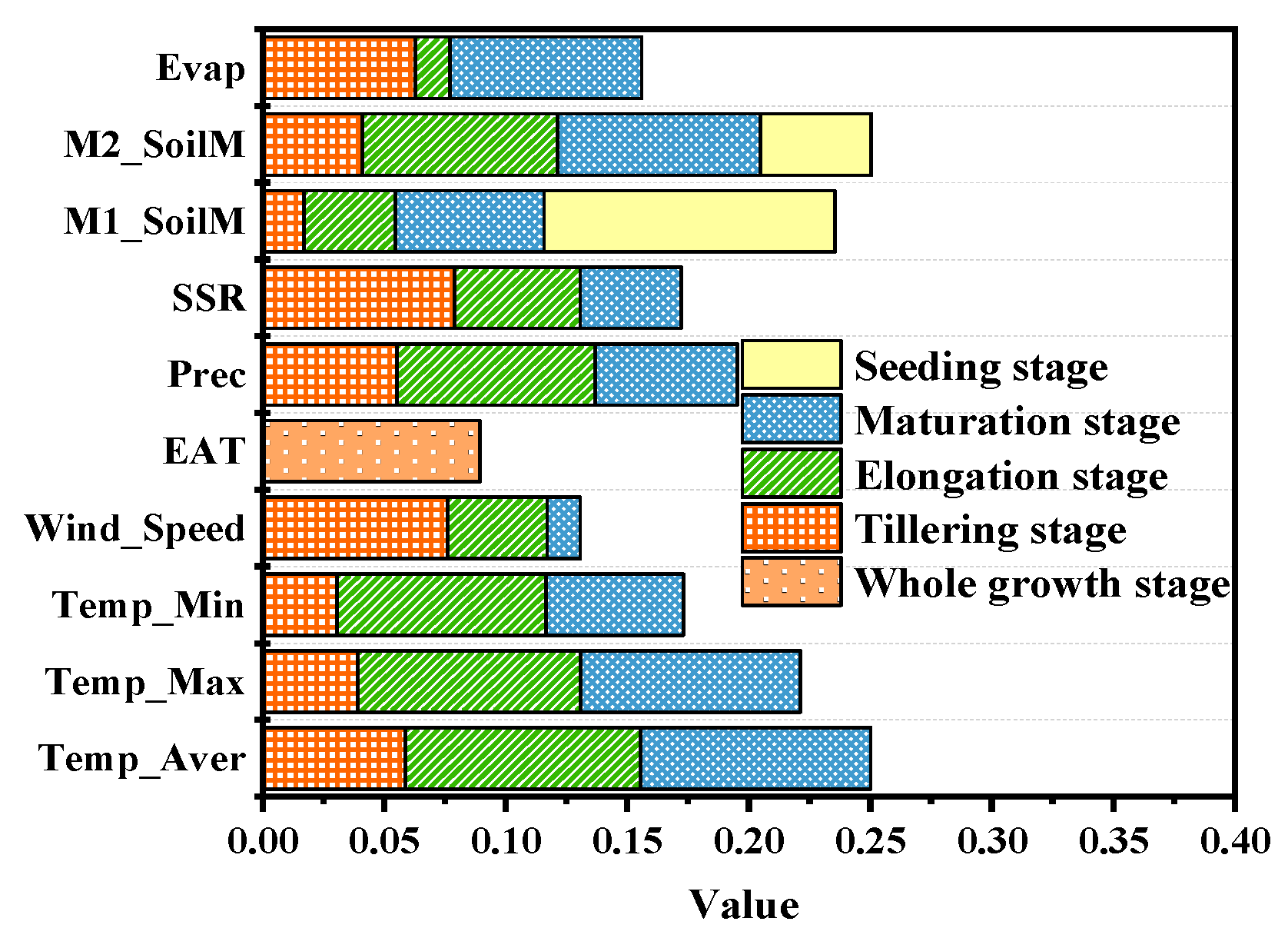
3.5. Sensitivity Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| R2 | Determination Coefficient |
| RMSE | Root Mean Square Error |
| MAE | Mean Absolute Error |
| MAPE | Mean Absolute Percentage Error |
| SMAPE | Symmetric Mean Absolute Percentage Error |
| NOAA | National Oceanic and Atmospheric Administration |
| NCEI | National Centers for Environmental Information |
| ECMWF | European Centre for Medium-Range Weather Forecasts |
| ERA5 | ECMWF Re-Analysis 5 |
| GLDAS | Global high-resolution Land Surface Simulation System |
| GSFC | Goddard Space Flight Center |
| NCEP | National Centers for Environmental Prediction |
| BPNN | Back Propagation Neural Network |
| RF | Random Forest |
| SVM | Support Vector Machine |
| ML | Machine Learning |
| WCA | Water cycle algorithm |
| LSSVM | Least squares support vector machine |
| PSO-LSSVM | Particle Warm Optimization of LSSVM |
| WCA_LSSVM | WCA of LSSVM |
References
- Sindhu, R.; Gnansounou, E.; Binod, P.; Pandey, A. Bioconversion of sugarcane crop residue for value added products—An overview. Renew. Energy 2016, 98, 203–215. [Google Scholar] [CrossRef]
- Jiang, H.; Li, D.; Jing, W.; Xu, J.; Huang, J.; Yang, J.; Chen, S. Early season mapping of sugarcane by applying machine learning algorithms to Sentinel-1A/2 time series data: A case study in Zhanjiang City, China. Remote Sens. 2019, 11, 861. [Google Scholar] [CrossRef]
- Zhao, Y.; Chen, M.; Zhao, Z.; Yu, S. The antibiotic activity and mechanisms of sugarcane (Saccharum officinarum L.) bagasse extract against food-borne pathogens. Food Chem. 2015, 185, 112–118. [Google Scholar] [CrossRef] [PubMed]
- Raheem, A.; Zhao, M.; Dastyar, W.; Channa, A.Q.; Ji, G.; Zhang, Y. Parametric gasification process of sugarcane bagasse for syngas production. Int. J. Hydrog. Energy 2019, 44, 16234–16247. [Google Scholar] [CrossRef]
- Algayyim, S.J.M.; Yusaf, T.; Hamza, N.H.; Wandel, A.P.; Fattah, I.R.; Laimon, M.; Rahman, S.A. Sugarcane Biomass as a Source of Biofuel for Internal Combustion Engines (Ethanol and Acetone-Butanol-Ethanol): A Review of Economic Challenges. Energies 2022, 15, 8644. [Google Scholar] [CrossRef]
- Viana, J.L.; de Souza, J.L.M.; Hoshide, A.K.; de Oliveira, R.A.; de Abreu, D.C.; da Silva, W.M. Estimating Sugarcane Yield in a Subtropical Climate Using Climatic Variables and Soil Water Storage. Sustainability 2023, 15, 4360. [Google Scholar] [CrossRef]
- Jiang, R.; Wang, T.T.; Jin, S.H.A.O.; Sheng, G.U.O.; Wei, Z.H.U.; Yu, Y.J.; Chen, S.L.; Hatano, R. Modeling the biomass of energy crops: Descriptions, strengths and prospective. J. Integr. Agric. 2017, 16, 1197–1210. [Google Scholar] [CrossRef]
- Hu, S.; Shi, L.; Huang, K.; Zha, Y.; Hu, X.; Ye, H.; Yang, Q. Improvement of sugarcane crop simulation by SWAP-WOFOST model via data assimilation. Field Crops Res. 2019, 232, 49–61. [Google Scholar] [CrossRef]
- Inman-Bamber, N.G. A growth model for sugar-cane based on a simple carbon balance and the CERES-Maize water balance. South Afr. J. Plant Soil 1991, 8, 93–99. [Google Scholar] [CrossRef]
- Jagtap, S.T.; Phasinam, K.; Kassanuk, T.; Jha, S.S.; Ghosh, T.; Thakar, C.M. Towards application of various machine learning techniques in agriculture. Mater. Today Proc. 2022, 51, 793–797. [Google Scholar] [CrossRef]
- Zhu, L.; Liu, X.; Wang, Z.; Tian, L. High-precision sugarcane yield prediction by integrating 10-m Sentinel-1 VOD and Sentinel-2 GRVI indexes. Eur. J. Agron. 2023, 149, 126889. [Google Scholar] [CrossRef]
- Saini, P.; Nagpal, B.; Garg, P.; Kumar, S. CNN-BI-LSTM-CYP: A deep learning approach for sugarcane yield prediction. Sustain. Energy Technol. Assess. 2023, 57, 103263. [Google Scholar] [CrossRef]
- Dos Santos Luciano, A.C.; Picoli, M.C.A.; Duft, D.G.; Rocha, J.V.; Leal, M.R.L.V.; Le Maire, G. Empirical model for forecasting sugarcane yield on a local scale in Brazil using Landsat imagery and random forest algorithm. Comput. Electron. Agric. 2021, 184, 106063. [Google Scholar] [CrossRef]
- Das, A.; Kumar, M.; Kushwaha, A.; Dave, R.; Dakhore, K.K.; Chaudhari, K.; Bhattacharya, B.K. Machine learning model ensemble for predicting sugarcane yield through synergy of optical and SAR remote sensing. Remote Sens. Appl. Soc. Environ. 2023, 30, 100962. [Google Scholar] [CrossRef]
- Ilyas, Q.M.; Ahmad, M.; Mehmood, A. Automated Estimation of Crop Yield Using Artificial Intelligence and Remote Sensing Technologies. Bioengineering 2023, 10, 125. [Google Scholar] [CrossRef]
- Priya, S.K.; Balambiga, R.K.; Mishra, P.; Das, S.S. Sugarcane yield forecast using weather based discriminant analysis. Smart Agric. Technol. 2023, 3, 100076. [Google Scholar] [CrossRef]
- Saini, P.; Nagpal, B.; Garg, P.; Kumar, S. Evaluation of Remote Sensing and Meteorological parameters for Yield Prediction of Sugarcane (Saccharum officinarum L.) Crop. Braz. Arch. Biol. Technol. 2023, 66, e23220781. [Google Scholar] [CrossRef]
- Chen, S.; Ye, H.; Nie, C.; Wang, H.; Wang, J. Research on the Assessment Method of Sugarcane Cultivation Suitability in Guangxi Province, China, Based on Multi-Source Data. Agriculture 2023, 13, 988. [Google Scholar] [CrossRef]
- Furrer, E.M.; Katz, R.W. Generalized linear modeling approach to stochastic weather generators. Clim. Res. 2007, 34, 129–144. [Google Scholar] [CrossRef]
- Apipattanavis, S.; Bert, F.; Podestá, G.; Rajagopalan, B. Linking weather generators and crop models for assessment of climate forecast outcomes. Agric. For. Meteorol. 2010, 150, 166–174. [Google Scholar] [CrossRef]
- Ines, A.V.M.; Hansen, J.W.; Robertson, A.W. Enhancing the utility of daily GCM rainfall for crop yield prediction. Int. J. Climatol. 2011, 31, 2168–2182. [Google Scholar] [CrossRef]
- Bhattacharyya, D.; Joshua ES, N.; Rao, N.T.; Kim, T.H. Hybrid CNN-SVM Classifier Approaches to Process Semi-Structured Data in Sugarcane Yield Forecasting Production. Agronomy 2023, 13, 1169. [Google Scholar] [CrossRef]
- Ye, J.; Xie, L.; Wang, H. A water cycle algorithm based on quadratic interpolation for high-dimensional global optimization problems. Appl. Intell. 2023, 53, 2825–2849. [Google Scholar] [CrossRef]
- Corbari, C.; Mancini, M. Irrigation efficiency optimization at multiple stakeholders’ levels based on remote sensing data and energy water balance modelling. Irrig. Sci. 2023, 41, 121–139. [Google Scholar] [CrossRef]
- Hersbach, H.; Bell, B.; Berrisford, P.; Biavati, G.; Horányi, A.; Muñoz Sabater, J.; Nicolas, J.; Peubey, C.; Radu, R.; Rozum, I.; et al. ERA5 monthly averaged data on single levels from 1979 to present. Copernic. Clim. Chang. Serv. Clim. Data Store 2019, 10, 252–266. [Google Scholar]
- Beaudoing, H.; Rodell, M. GLDAS Noah Land Surface Model L4 Monthly 0.25 × 0.25 Degree V2. 1; Goddard Earth Sciences Data and Information Services Center (GES DISC): Greenbelt, MD, USA, 2020. [Google Scholar]
- Yao, P.; Qian, L.; Wang, Z.; Meng, H.; Ju, X. Assessing Drought, Flood, and High Temperature Disasters during Sugarcane Growth Stages in Southern China. Agriculture 2022, 12, 2117. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Liu, Y.; Zhao, Q.; Yao, W.; Ma, X.; Yao, Y.; Liu, L. Short-term rainfall forecast model based on the improved BP–NN algorithm. Sci. Rep. 2019, 9, 19751. [Google Scholar] [CrossRef] [PubMed]
- Danladi, A.; Stephen, M.; Aliyu, B.M.; Gaya, G.K.; Silikwa, N.W.; Machael, Y. Assessing the influence of weather parameters on rainfall to forecast river discharge based on short-term. Alex. Eng. J. 2018, 57, 1157–1162. [Google Scholar] [CrossRef]
- Yuan, Q.; Xu, H.; Li, T.; Shen, H.; Zhang, L. Estimating surface soil moisture from satellite observations using a generalized regression neural network trained on sparse ground-based measurements in the continental US. J. Hydrol. 2020, 580, 124351. [Google Scholar] [CrossRef]
- Nassih, B.; Amine, A.; Ngadi, M.; Hmina, N. DCT and HOG feature sets combined with BPNN for Efficient Face Classification. Procedia Comput. Sci. 2019, 148, 116–125. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Chen, B.; Liu, Q.; Chen, H.; Wang, L.; Deng, T.; Zhang, L.; Wu, X. Multiobjective optimization of building energy consumption based on BIM-DB and LSSVM-NSGA-II. J. Clean. Prod. 2021, 294, 126153. [Google Scholar] [CrossRef]
- Verma, A.K.; Garg, P.K.; Prasad, K.H.; Dadhwal, V.K. Variety-specific sugarcane yield simulations and climate change impacts on sugarcane yield using DSSAT-CSM-CANEGRO model. Agric. Water Manag. 2023, 275, 108034. [Google Scholar] [CrossRef]
- Suykens, J.A.K.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Pelckmans, K.; Suykens, J.A.; Van Gestel, T.; De Brabanter, J.; Lukas, L.; Hamers, B.; De Moor, B.; Vandewalle, J. LS-SVMlab: A Matlab/C Toolbox for Least Squares Support Vector Machines. 2002, 142(1-2). Available online: https://www.academia.edu/download/33701891/lssvmlab_paper0.pdf (accessed on 5 October 2023).
- Eskandar, H.; Sadollah, A.; Bahreininejad, A.; Hamdi, M. Water cycle algorithm–A novel metaheuristic optimization method for solving constrained engineering optimization problems. Comput. Struct. 2012, 110, 151–166. [Google Scholar] [CrossRef]
- Sadollah, A.; Eskandar, H.; Kim, J.H. Water cycle algorithm for solving constrained multi-objective optimization problems. Appl. Soft Comput. 2015, 27, 279–298. [Google Scholar] [CrossRef]
- Shi, J.; Huang, W.; Fan, X.; Li, X.; Lu, Y.; Jiang, Z.; Wang, Z.; Luo, W.; Zhang, M. Yield Prediction Models in Guangxi Sugarcane Planting Regions Based on Machine Learning Methods. Smart Agric. 2023, 5, 82–92. [Google Scholar]
- Qin, N.; Lu, Q.; Fu, G.; Wang, J.; Fei, K.; Gao, L. Assessing the drought impact on sugarcane yield based on crop water requirements and standardized precipitation evapotranspiration index. Agric. Water Manag. 2023, 275, 108037. [Google Scholar] [CrossRef]
- Costa Neto, C.A.; Mesquita, M.; de Moraes, D.H.M.; de Oliveira, H.E.F.; Evangelista, A.W.P.; Flores, R.A.; Casaroli, D. Relationship Between Distribution of the Radicular System, Soil Moisture and Yield of Sugarcane Genotypes. Sugar Tech 2021, 23, 1157–1170. [Google Scholar] [CrossRef]
- Marin, F.R. Understanding Sugarcane Yield Gap and Bettering Crop Management through Crop Production Efficiency. In Crop Management—Cases and Tools for Higher Yield and Sustainability; Books on Demand: Norderstedt, Germany, 2012; p. 109. [Google Scholar]
- Mulianga, B.; Bégué, A.; Simoes, M.; Todoroff, P. Forecasting regional sugarcane yield based on time integral and spatial aggregation of MODIS NDVI. Remote Sens. 2013, 5, 2184–2199. [Google Scholar] [CrossRef]
- Da Silva, G.J.; Berg, E.C.; Calijuri, M.L.; dos Santos, V.J.; Lorentz, J.F.; do Carmo Alves, S. Aptitude of areas planned for sugarcane cultivation expansion in the state of São Paulo, Brazil: A study based on climate change effects. Agric. Ecosyst. Environ. 2021, 305, 107164. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Description | Units |
|---|---|---|
| Temp_Aver | The average temperature during a growth cycle. | °C |
| Temp_Max | The average daily maximum temperature during a growth cycle. | °C |
| Temp_Min | The average daily minimum temperature during a growth cycle. | °C |
| Wind_Speed | The average daily wind speed during a growth cycle. | m/s |
| EAT | Effective accumulative temperature. | °C |
| Prec | Total precipitation during a growth cycle. | mm |
| SSR | Total Surface solar radiation during a growth cycle. | MJ/m2 |
| M1_SoilM | The average soil moisture at 0–10 cm depth. | mm |
| M2_SoilM | The average soil moisture at 10–40 cm depth. | mm |
| Evap | Total evapotranspiration during a growth cycle. | kg/m3 |
| Input Variables | Seeding and Germination Tillering Stage | Elongation Stage | Maturation Stage | Units |
|---|---|---|---|---|
| Temp_Aver | (18.76–28.28) | (21.91–30.31) | (18.11–27.26) | °C |
| Temp_Max | (22.47–33.84) | (25.51–34.62) | (22.56–30.95) | °C |
| Temp_Min | (12.73–26.24) | (18.66–28.27) | (11.24–24.28) | °C |
| Wind_Speed | (1.27–4.64) | (0.99–5.23) | (0.99–5.25) | m/s |
| Prec | (28.70–768.1) | (273.3–1986.53) | (49.53–1417.07) | mm |
| SSR | (8.49–19.95) | (10.04–19.73) | (9.11–16.03) | MJ/m2 |
| M1_SoilM | (18.68–37.35) | (27.73–41.21) | (22.52–40.09) | mm |
| M2_SoilM | (56.74–113.33) | (84.25–124.03) | (69.23–120.84) | mm |
| Evap | (125.73–359.85) | (211.85–507.71) | (173.71–378.52) | kg/m3 |
| Type | Instance 1 | Instance 2 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | R2 | SMAPE | MAPE | RMSE | MAE | R2 | SMAPE | MAPE | |
| BPNN | 7.489 | 6.092 | 0.353 | 0.0885 | 0.0886 | 6.579 | 5.462 | 0.178 | 0.0744 | 0.0766 |
| RF | 6.724 | 5.496 | 0.478 | 0.0801 | 0.0817 | 5.685 | 4.708 | 0.172 | 0.0658 | 0.0641 |
| LSSVM | 6.716 | 5.301 | 0.497 | 0.0766 | 0.0774 | 6.414 | 4.803 | 0.315 | 0.0678 | 0.0657 |
| PSO_LSSVM | 5.726 | 4.738 | 0.622 | 0.0683 | 0.0691 | 5.310 | 4.265 | 0.291 | 0.0598 | 0.0589 |
| WCA_LSSVM | 5.385 | 4.496 | 0.665 | 0.0642 | 0.0649 | 5.032 | 4.017 | 0.378 | 0.0561 | 0.0545 |
| Instance | Type | Number | ||||
|---|---|---|---|---|---|---|
| RE < 5% | 5% ≤ RE <10% | 10% ≤ RE <15% | 15% ≤ RE <20% | RE ≥ 20% | ||
| Instance 1 | LSSVM | 15 | 14 | 5 | 2 | 1 |
| PSO_LSSVM | 17 | 14 | 7 | 2 | 0 | |
| WCA_LSSVM | 17 | 13 | 9 | 1 | 0 | |
| Instance 2 | LSSVM | 17 | 14 | 7 | 1 | 1 |
| PSO_LSSVM | 20 | 12 | 6 | 2 | 0 | |
| WCA_LSSVM | 22 | 13 | 5 | 0 | 0 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Y.; Pan, M.; Guan, W.; Fu, C.; Su, T. Predicting Sugarcane Yield via the Use of an Improved Least Squares Support Vector Machine and Water Cycle Optimization Model. Agriculture 2023, 13, 2115. https://doi.org/10.3390/agriculture13112115
Zhou Y, Pan M, Guan W, Fu C, Su T. Predicting Sugarcane Yield via the Use of an Improved Least Squares Support Vector Machine and Water Cycle Optimization Model. Agriculture. 2023; 13(11):2115. https://doi.org/10.3390/agriculture13112115
Chicago/Turabian StyleZhou, Yifang, Mingzhang Pan, Wei Guan, Changcheng Fu, and Tiecheng Su. 2023. "Predicting Sugarcane Yield via the Use of an Improved Least Squares Support Vector Machine and Water Cycle Optimization Model" Agriculture 13, no. 11: 2115. https://doi.org/10.3390/agriculture13112115
APA StyleZhou, Y., Pan, M., Guan, W., Fu, C., & Su, T. (2023). Predicting Sugarcane Yield via the Use of an Improved Least Squares Support Vector Machine and Water Cycle Optimization Model. Agriculture, 13(11), 2115. https://doi.org/10.3390/agriculture13112115