
Accuracy of Genomic Prediction of Yield and Sugar Traits in Saccharum spp. Hybrids


 , , and
, , and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Plant Materials
2.2. Data Collection
2.3. DNA Extraction and Genotyping
2.4. Heritability Calculation
2.5. Model Fitting Methods
2.5.1. Data Preparation
2.5.2. Model Fitting with Cross-Validation
2.6. Evaluating Model Performance
2.7. Trait-Assisted Genomic Selection
2.8. Investigating the Effect of Marker Density on Model Performance
2.9. Investigating the Effect of Population Size on Model Performance
3. Results
3.1. Trait Distribution and Heritability
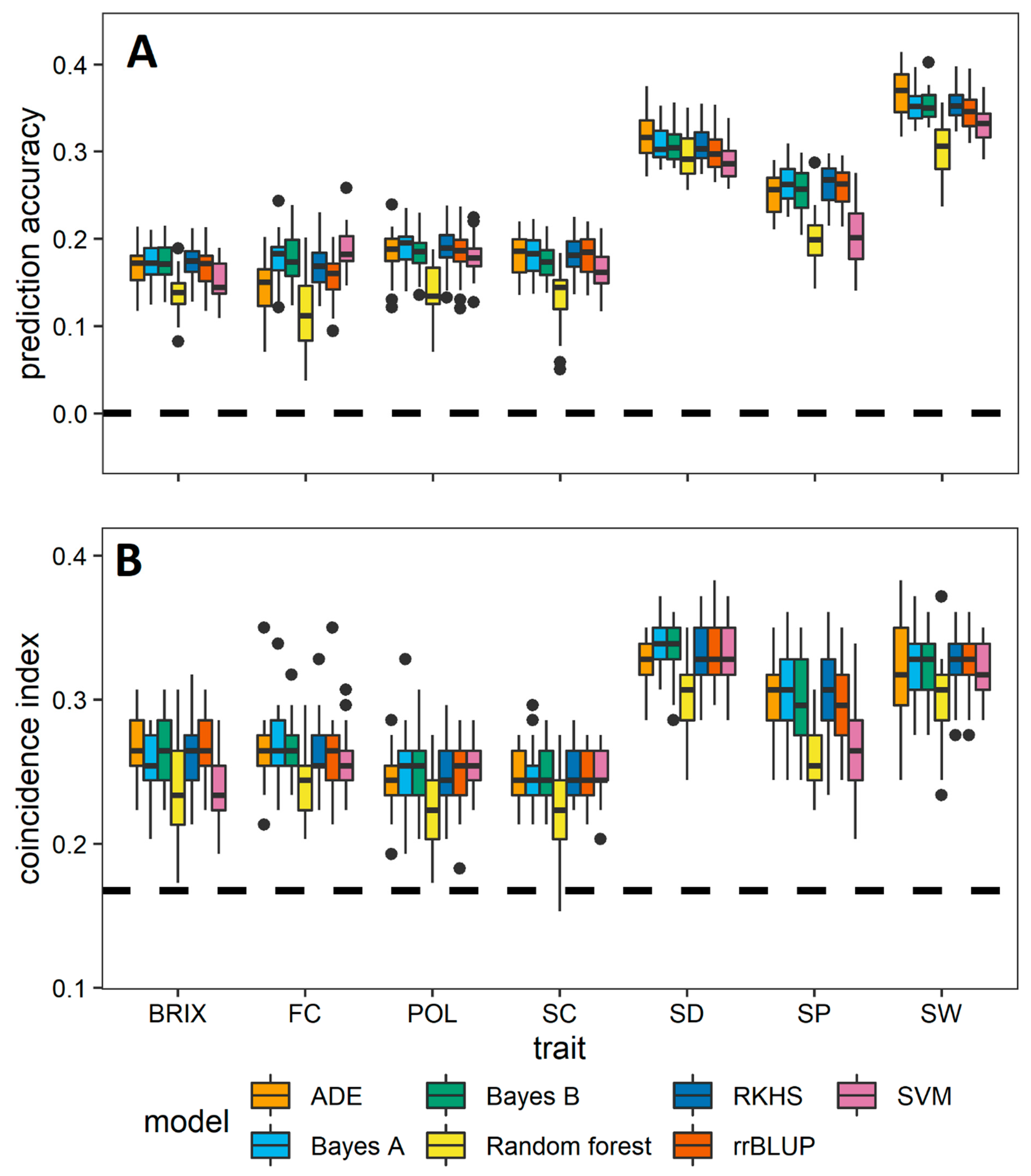
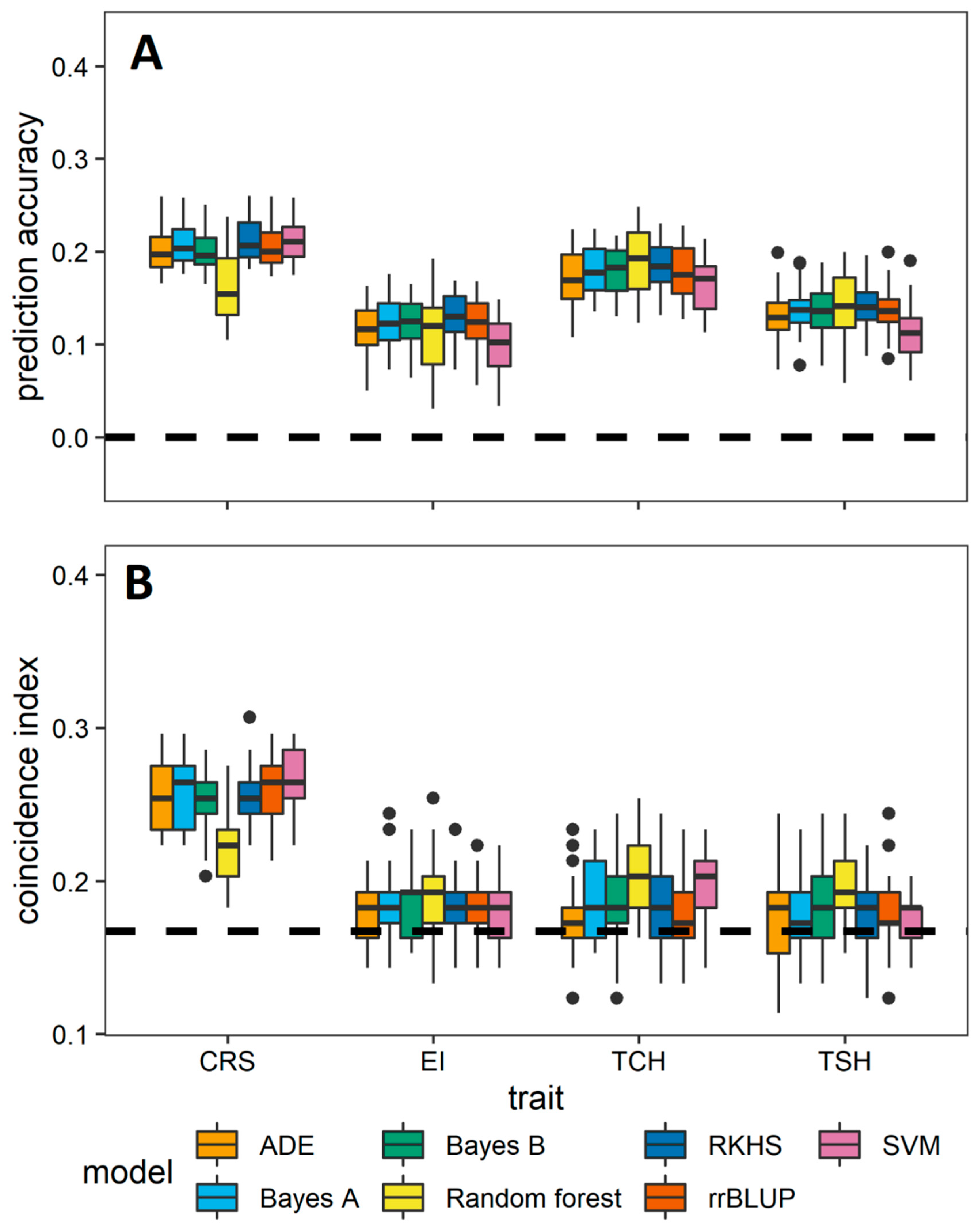
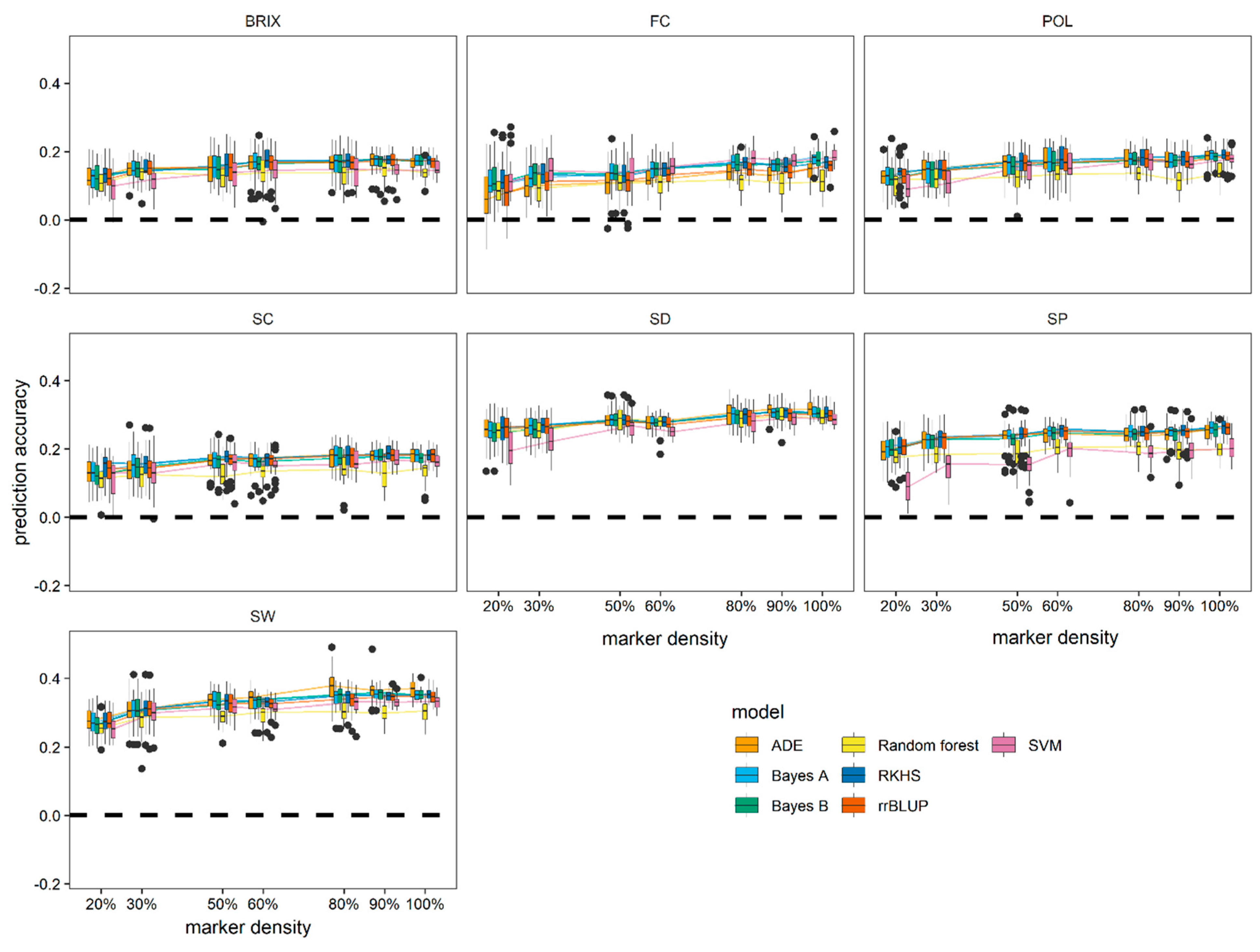
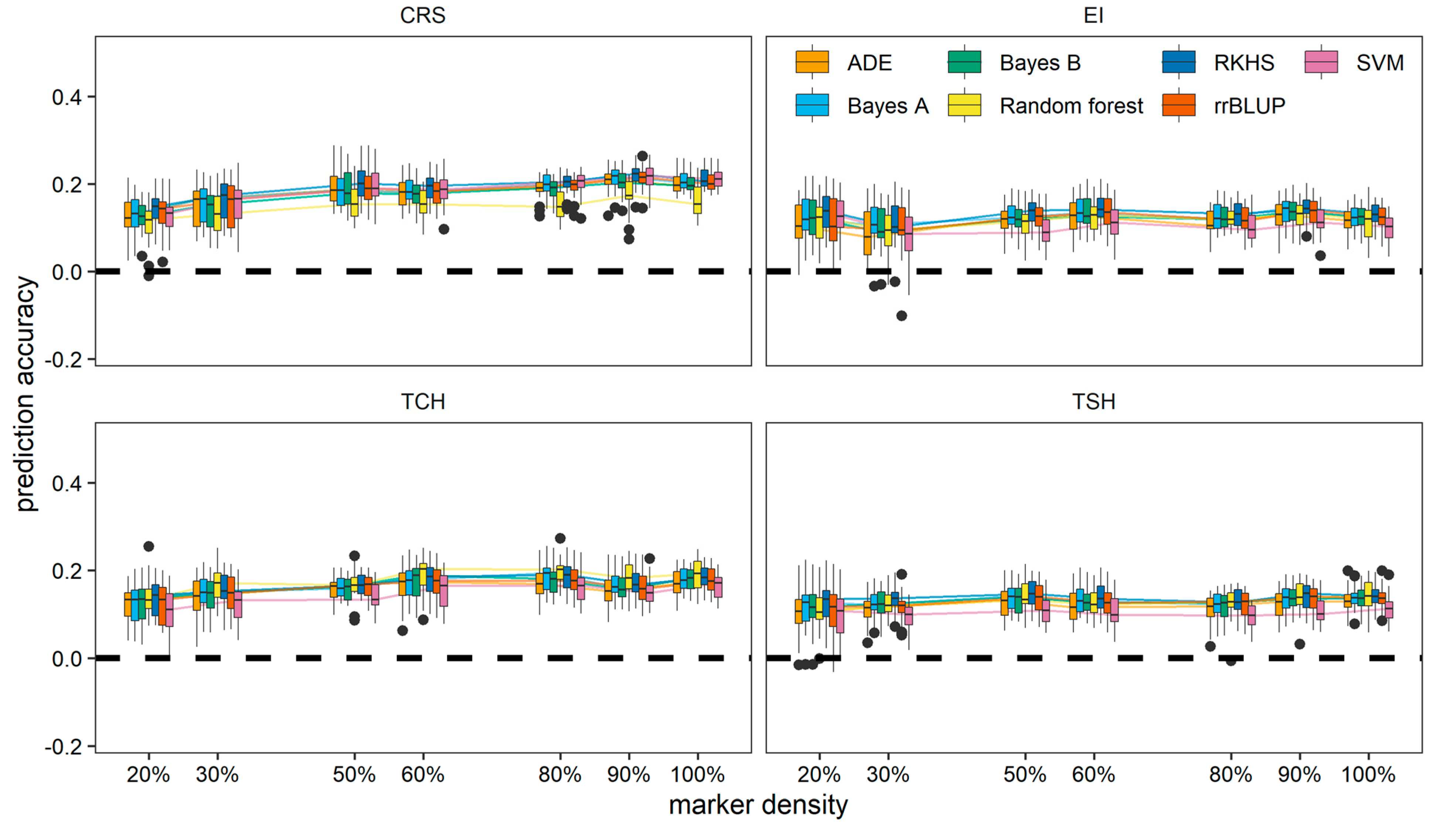
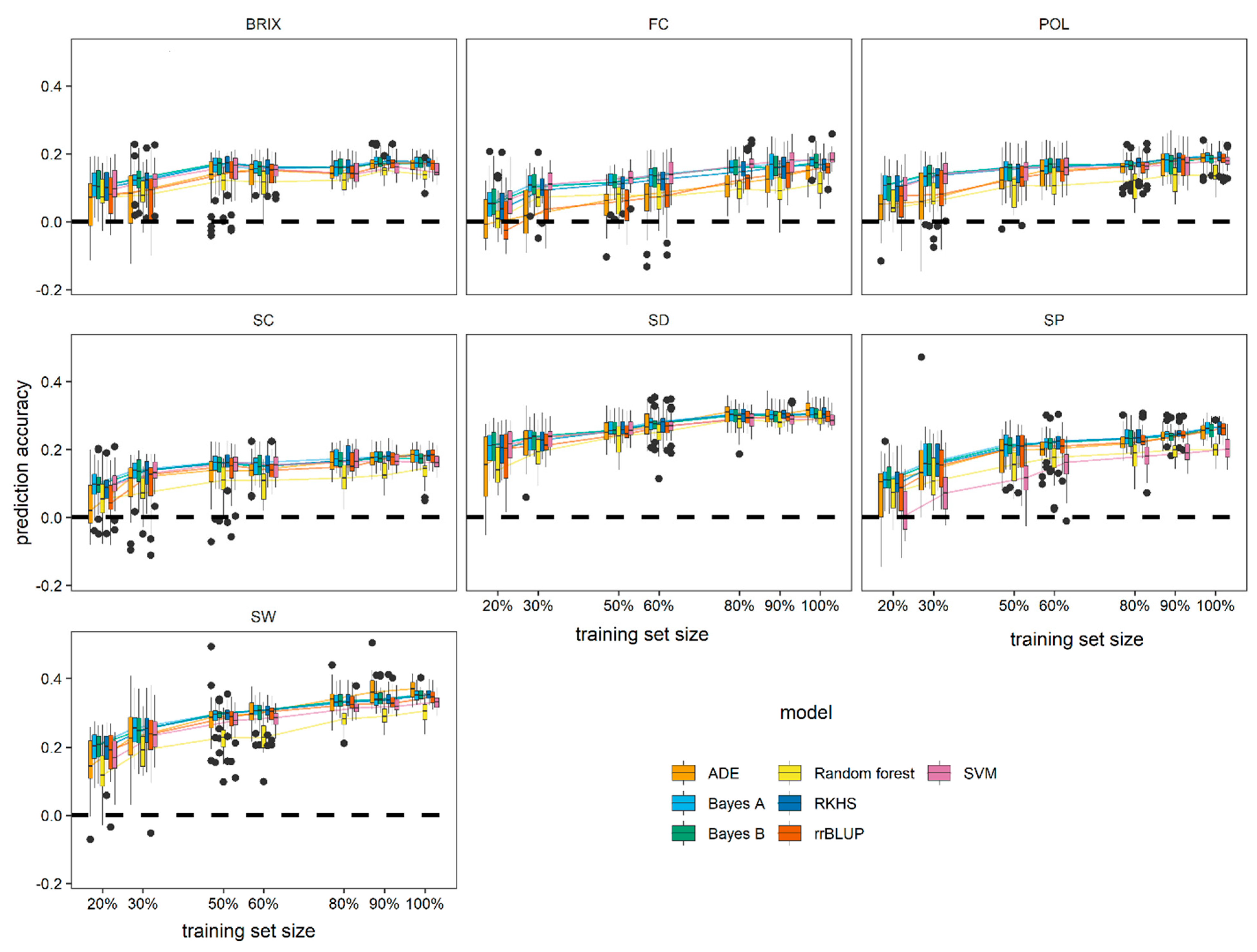
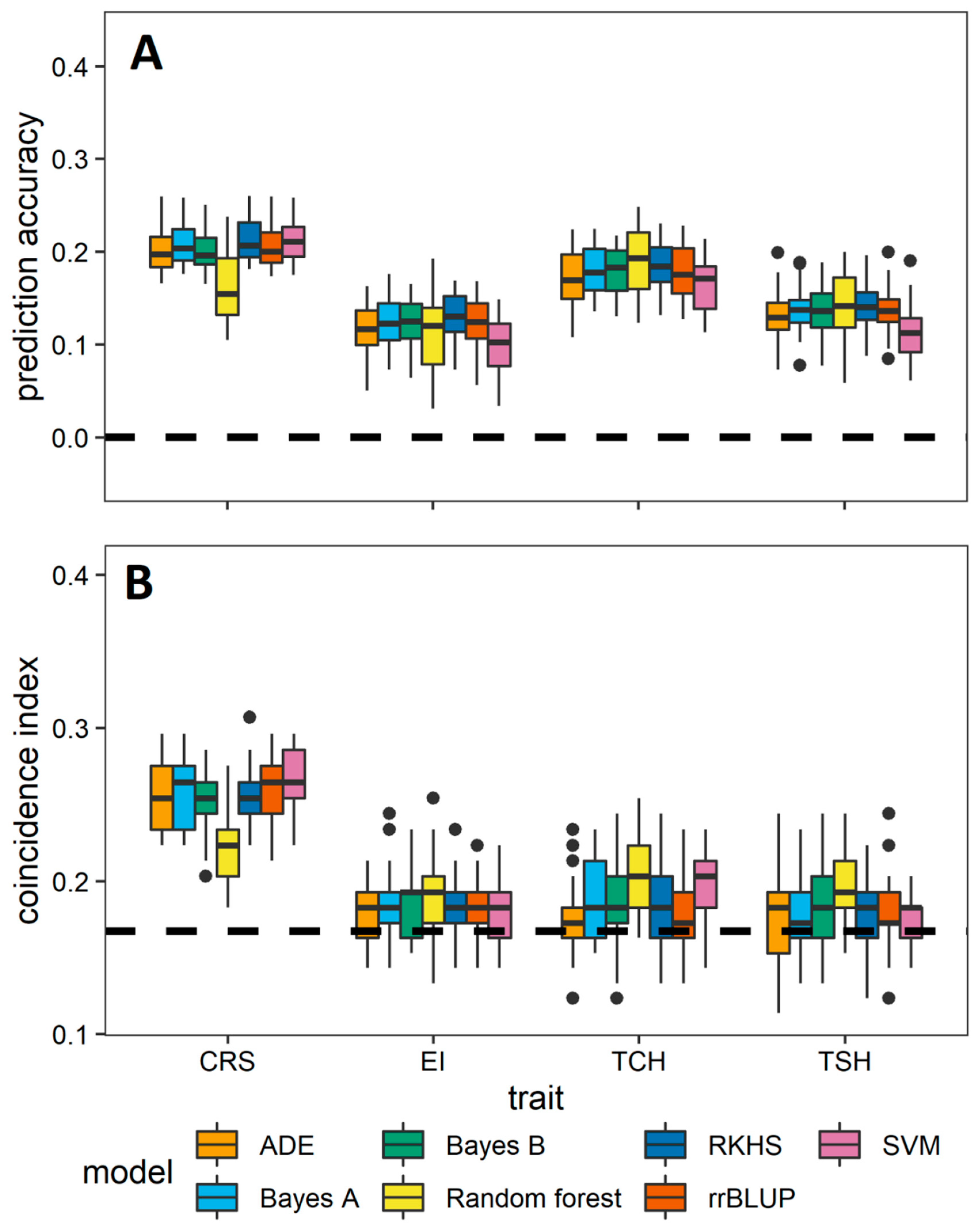
3.2. Comparative Evaluation of Different GS Methods
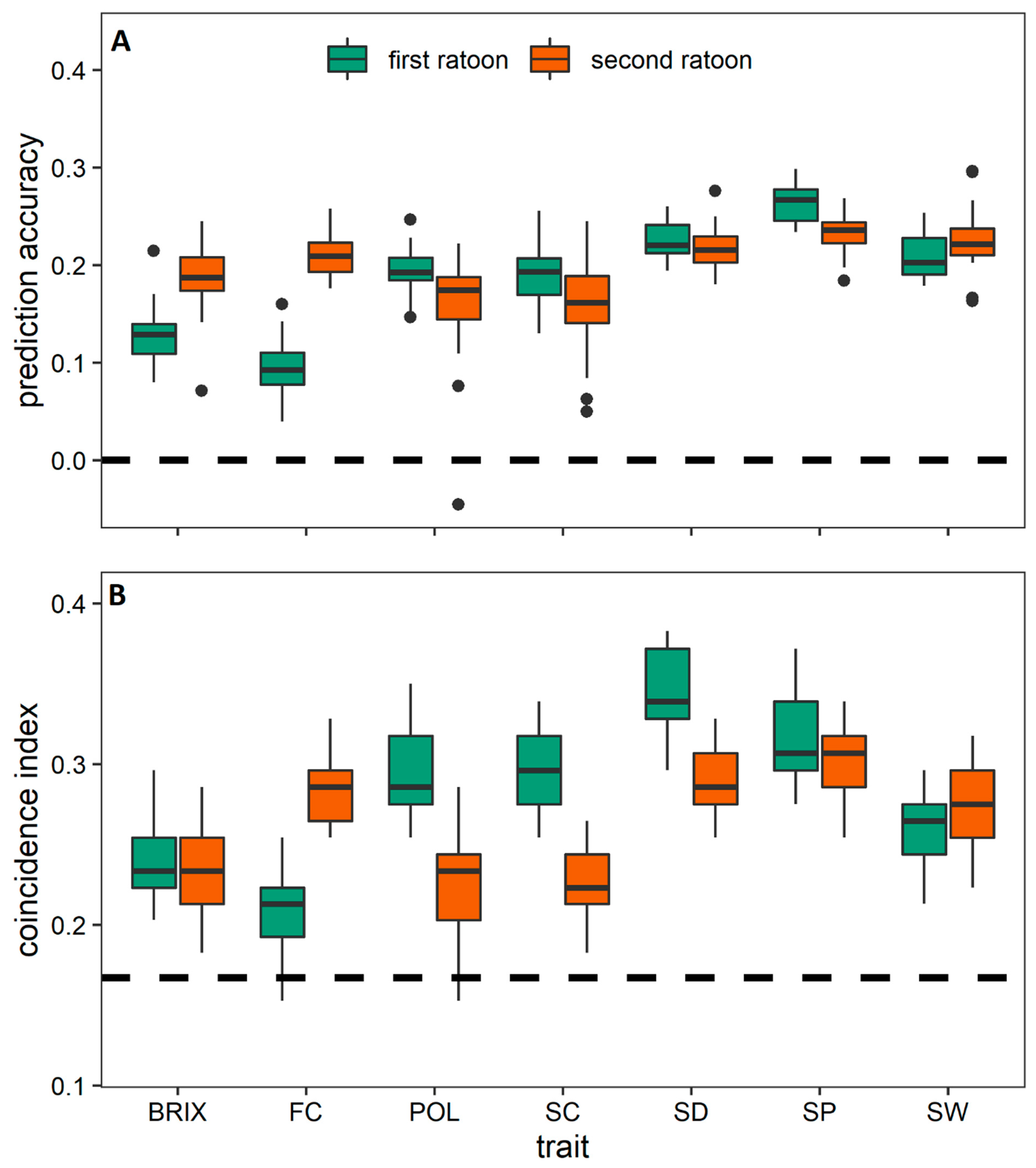
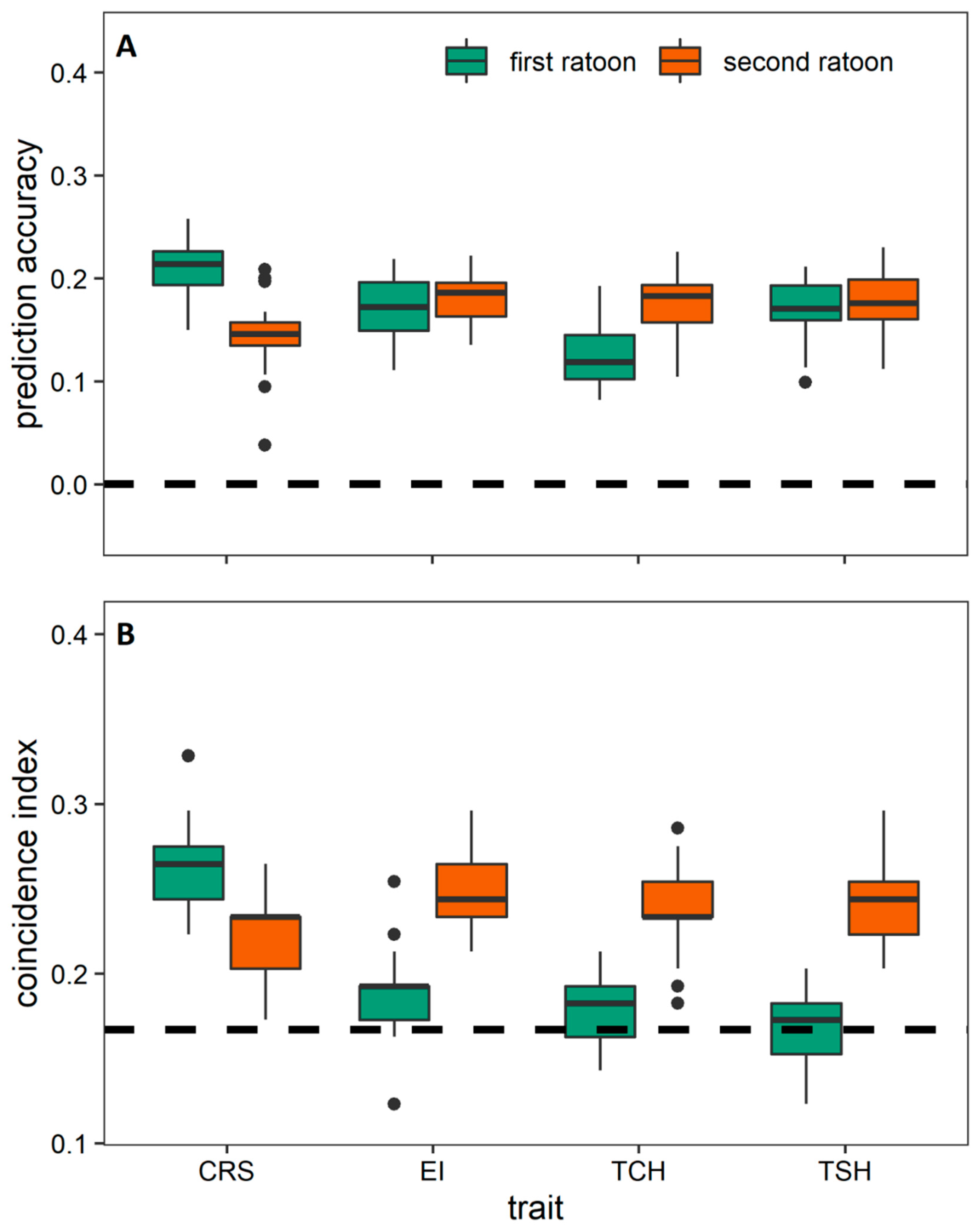
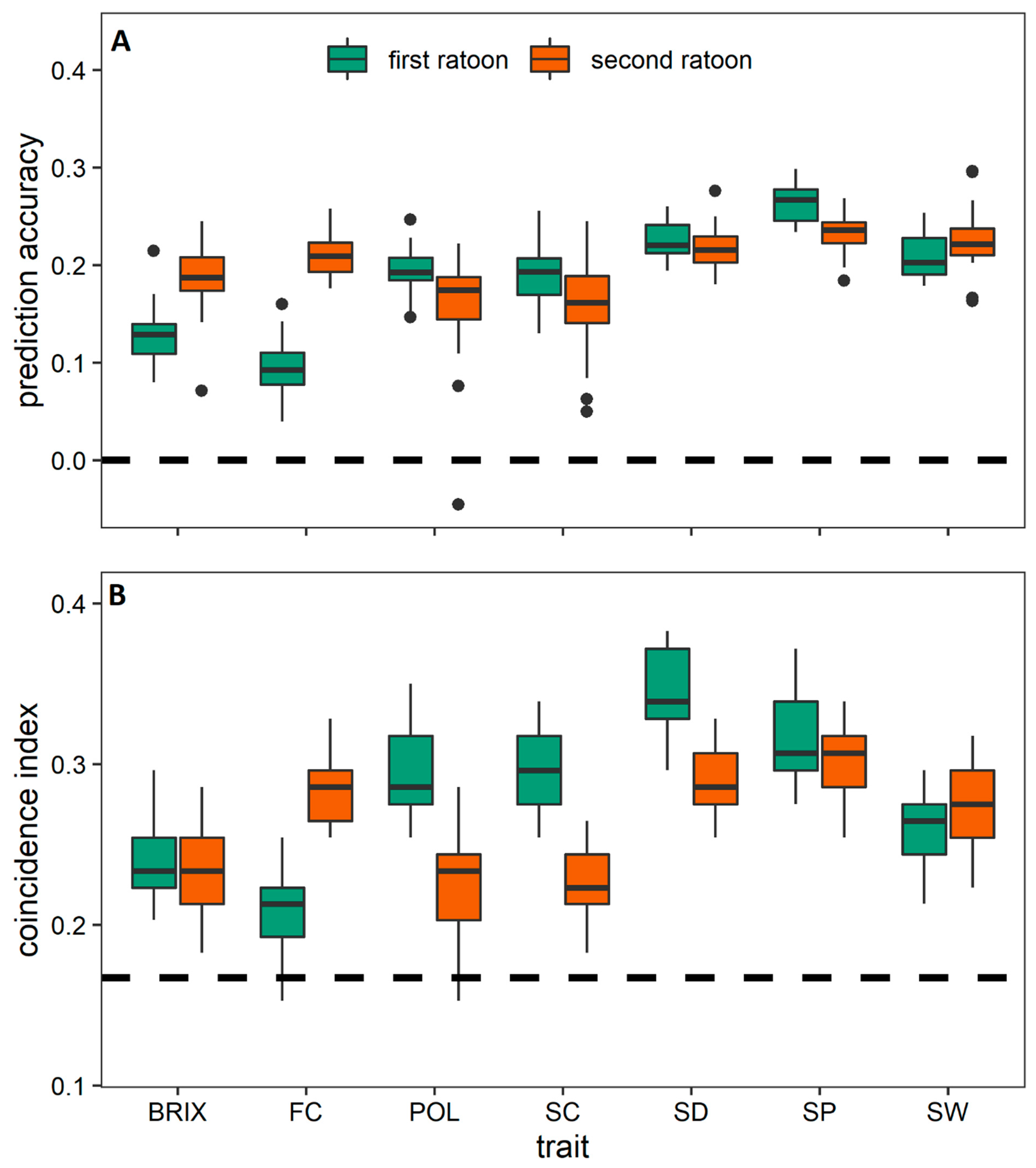
3.3. Prediction among the Crop Cycles through Trait-Assisted Prediction Model
3.4. Effect of Marker Density on Model Performance
3.5. Effect of Training Population (TP) Size on Model Performance
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- D’Hont, A. Unraveling the genome structure of polyploids using FISH and GISH; examples of sugarcane and banana. Cytogenet. Genome Res. 2005, 109, 27–33. [Google Scholar] [CrossRef] [PubMed]
- D’Hont, A.; Ison, D.; Alix, K.; Roux, C.; Glaszmann, J.C. Determination of basic chromosome numbers in the genus Saccharum by physical mapping of ribosomal RNA genes. Genome 1998, 41, 221–225. [Google Scholar] [CrossRef]
- Palhares, A.C.; Rodrigues-Morais, T.B.; Van Sluys, M.A.; Domingues, D.S.; Maccheroni, W., Jr.; Jordao, H., Jr.; Souza, A.P.; Marconi, T.G.; Mollinari, M.; Gazaffi, R.; et al. A novel linkage map of sugarcane with evidence for clustering of retrotransposon-based markers. BMC Genet. 2012, 13, 51. [Google Scholar] [CrossRef] [PubMed]
- Daniels, J.; Roach, B.T. Taxonomy and Evolution. In Sugarcane Improvement through Breeding; Heinz, D.J., Ed.; Elsevier Press: Amsterdam, The Netherlands, 1987; pp. 7–84. [Google Scholar]
- Irvine, J.E. Saccharum species as horticultural classes. Theor. Appl. Genet. 1999, 98, 186–194. [Google Scholar] [CrossRef]
- Islam, M.S.; Yang, X.; Sood, S.; Comstock, J.C.; Zan, F.; Wang, J. Molecular dissection of sugar related traits and it’s attributes in Saccharum spp. hybrids. Euphytica 2018, 214, 170. [Google Scholar] [CrossRef]
- Islam, M.S.; Fang, D.D.; Jenkins, J.N.; Guo, J.; McCarty, J.C.; Jones, D.C. Evaluation of genomic selection methods for predicting fiber quality traits in Upland cotton. Mol. Genet. Genom. 2020, 295, 67–79. [Google Scholar] [CrossRef]
- Gezan, S.A.; Osorio, L.F.; Verma, S.; Whitaker, V.M. An experimental validation of genomic selection in octoploid strawberry. Hortic. Res. 2017, 4, 16070. [Google Scholar] [CrossRef]
- Arruda, M.P.; Brown, P.J.; Lipka, A.E.; Krill, A.M.; Thurber, C.; Kolb, F.L. Genomic Selection for Predicting Fusarium Head Blight Resistance in a Wheat Breeding Program. Plant Genome 2015, 8, 1–12. [Google Scholar] [CrossRef]
- Spindel, J.; Begum, H.; Akdemir, D.; Virk, P.; Collard, B.; Redona, E.; Atlin, G.; Jannink, J.L.; McCouch, S.R. Genomic selection and association mapping in rice (Oryza sativa): Effect of trait genetic architecture, training population composition, marker number and statistical model on accuracy of rice genomic selection in elite, tropical rice breeding lines. PLoS Genet. 2015, 11, e1004982. [Google Scholar] [CrossRef]
- Daugrois, J.H.; Grivet, L.; Roques, D.; Hoarau, J.Y.; Lombard, H.; Glaszmann, J.C.; D’Hont, A. A putative major gene for rust resistance linked with a RFLP marker in sugarcane cultivar ‘R570’. Theor. Appl. Genet. 1996, 92, 1059–1064. [Google Scholar] [CrossRef]
- Raboin, L.M.; Oliveira, K.M.; Lecunff, L.; Telismart, H.; Roques, D.; Butterfield, M.; Hoarau, J.Y.; D’Hont, A. Genetic mapping in sugarcane, a high polyploid, using bi-parental progeny: Identification of a gene controlling stalk colour and a new rust resistance gene. Theor. Appl. Genet. 2006, 112, 1382–1391. [Google Scholar] [CrossRef] [PubMed]
- Costet, L.; Le Cunff, L.; Royaert, S.; Raboin, L.M.; Hervouet, C.; Toubi, L.; Telismart, H.; Garsmeur, O.; Rousselle, Y.; Pauquet, J.; et al. Haplotype structure around Bru1 reveals a narrow genetic basis for brown rust resistance in modern sugarcane cultivars. Theor. Appl. Genet. 2012, 125, 825–836. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Islam, M.S.; Sood, S.; Maya, S.; Hanson, E.A.; Comstock, J.; Wang, J. Identifying Quantitative Trait Loci (QTLs) and Developing Diagnostic Markers Linked to Orange Rust Resistance in Sugarcane (Saccharum spp.). Front. Plant Sci. 2018, 9, 350. [Google Scholar] [CrossRef] [PubMed]
- Meuwissen, T.H.; Hayes, B.J.; Goddard, M.E. Prediction of total genetic value using genome-wide dense marker maps. Genetics 2001, 157, 1819–1829. [Google Scholar] [CrossRef]
- Heffner, E.L.; Sorrells, M.E.; Jannink, J.L. Genomic selection for crop improvement. Crop Sci. 2009, 49, 1–12. [Google Scholar] [CrossRef]
- Lorenz, A.J.; Chao, S.; Asoro, F.G.; Heffner, E.L.; Hayashi, T.; Iwata, H.; Smith, K.P.; Sorrells, M.E.; Jannink, J.L. Genomic selection in plant breeding: Knowledge and prospects. Adv. Agron. 2011, 110, 77–123. [Google Scholar] [CrossRef]
- Gouy, M.; Rousselle, Y.; Bastianelli, D.; Lecomte, P.; Bonnal, L.; Roques, D.; Efile, J.C.; Rocher, S.; Daugrois, J.; Toubi, L.; et al. Experimental assessment of the accuracy of genomic selection in sugarcane. Theor. Appl. Genet. 2013, 126, 2575–2586. [Google Scholar] [CrossRef]
- Meuwissen, T.H. Accuracy of breeding values of ‘unrelated’ individuals predicted by dense SNP genotyping. Genet. Sel. Evol. 2009, 41, 35. [Google Scholar] [CrossRef]
- Jannink, J.L.; Lorenz, A.J.; Iwata, H. Genomic selection in plant breeding: From theory to practice. Brief. Funct. Genom. 2010, 9, 166–177. [Google Scholar] [CrossRef]
- Yadav, S.; Jackson, P.; Wei, X.; Ross, E.M.; Aitken, K.; Deomano, E.; Atkin, F.; Hayes, B.J.; Voss-Fels, K.P. Accelerating Genetic Gain in Sugarcane Breeding Using Genomic Selection. Agronomy 2020, 10, 585. [Google Scholar] [CrossRef] [Green Version]
- Gilbert, R.A.; Shine, J.M.; Miller, J.D.; Rice, R.W.; Rainbolt, C.R. The effect of genotype, environment and time of harvest on sugarcane yields in Florida, USA. Field. Crop Res. 2006, 95, 156–170. [Google Scholar] [CrossRef]
- Glaz, B.; Kang, M.S. Location Contributions Determined via GGE Biplot Analysis of Multienvironment Sugarcane Genotype-Performance Trials. Crop Sci. 2008, 48, 941–950. [Google Scholar] [CrossRef]
- Yadav, S.; Wei, X.; Joyce, P.; Atkin, F.; Deomano, E.; Sun, Y.; Nguyen, L.T.; Ross, E.M.; Cavallaro, T.; Aitken, K.S.; et al. Improved genomic prediction of clonal performance in sugarcane by exploiting non-additive genetic effects. Theor. Appl. Genet. 2021, 134, 2235–2252. [Google Scholar] [CrossRef] [PubMed]
- Jackson, P.; McRae, T.A. Selection of Sugarcane Clones in Small Plots: Effects of Plot Size and Selection Criteria. Crop Sci. 2001, 41, 315–322. [Google Scholar] [CrossRef]
- Aitken, K.S.; Jackson, P.A.; McIntyre, C.L. Quantitative trait loci identified for sugar related traits in a sugarcane (Saccharum spp.) cultivar x Saccharum officinarum population. Theor. Appl. Genet. 2006, 112, 1306–1317. [Google Scholar] [CrossRef] [PubMed]
- Heffner, E.L.; Jannink, J.-L.; Sorrells, M.E. Genomic Selection Accuracy using Multifamily Prediction Models in a Wheat Breeding Program. Plant Genome 2011, 4, 65–75. [Google Scholar] [CrossRef]
- Rutkoski, J.E.; Heffner, E.L.; Sorrells, M.E. Genomic selection for durable stem rust resistance in wheat. Euphytica 2010, 179, 161–173. [Google Scholar] [CrossRef]
- Bernal-Vasquez, A.M.; Gordillo, A.; Schmidt, M.; Piepho, H.P. Genomic prediction in early selection stages using multi-year data in a hybrid rye breeding program. BMC Genet. 2017, 18, 51. [Google Scholar] [CrossRef]
- Olatoye, M.O.; Clark, L.V.; Labonte, N.R.; Dong, H.; Dwiyanti, M.S.; Anzoua, K.G.; Brummer, J.E.; Ghimire, B.K.; Dzyubenko, E.; Dzyubenko, N.; et al. Training Population Optimization for Genomic Selection in Miscanthus. G3 Genes Genomes Genet. 2020, 10, 2465–2476. [Google Scholar] [CrossRef]
- Deomano, E.; Jackson, P.; Wei, X.; Aitken, K.; Kota, R.; Pérez-Rodríguez, P. Genomic prediction of sugar content and cane yield in sugar cane clones in different stages of selection in a breeding program, with and without pedigree information. Mol. Breed. 2020, 40, 38. [Google Scholar] [CrossRef]
- Olatoye, M.O.; Clark, L.V.; Wang, J.; Yang, X.; Yamada, T.; Sacks, E.J.; Lipka, A.E. Evaluation of genomic selection and marker-assisted selection in Miscanthus and energycane. Mol. Breed. 2019, 39, 171. [Google Scholar] [CrossRef]
- Hayes, B.J.; Wei, X.; Joyce, P.; Atkin, F.; Deomano, E.; Yue, J.; Nguyen, L.; Ross, E.M.; Cavallaro, T.; Aitken, K.S.; et al. Accuracy of genomic prediction of complex traits in sugarcane. Theor. Appl. Genet. 2021, 134, 1455–1462. [Google Scholar] [CrossRef] [PubMed]
- Islam, M.S.; McCord, P.H.; Olatoye, M.O.; Qin, L.; Sood, S.; Lipka, A.E.; Todd, J.R. Experimental evaluation of genomic selection prediction for rust resistance in sugarcane. Plant Genome 2021, 14, e20148. [Google Scholar] [CrossRef] [PubMed]
- Voss-Fels, K.P.; Wei, X.; Ross, E.M.; Frisch, M.; Aitken, K.S.; Cooper, M.; Hayes, B.J. Strategies and considerations for implementing genomic selection to improve traits with additive and non-additive genetic architectures in sugarcane breeding. Theor. Appl. Genet. 2021, 134, 1493–1511. [Google Scholar] [CrossRef] [PubMed]
- Legendre, B.L. The core/press method for predicting the sugar yield from cane for use in cane payment. Sugar J. 1992, 54, 2–7. [Google Scholar]
- Islam, M.S.; Sandhu, H.; Zhao, D.; Sood, S.; Momotaz, A.; Davidson, R.W.; Baltazar, M.; Gordon, V.S.; McCord, P.; Coto, O.A. Registration of ‘CP 13-1223’ sugarcane for Florida organic soils. J. Plant Regist. 2022, 16, 54–63. [Google Scholar] [CrossRef]
- Deren, C.W.; Alvarez, J.; Glaz, B. Use of economic criteria for selecting clones in a sugarcane breeding program. Proc. Int. Soc. Sugar Cane Technol. 1995, 21, 437–447. [Google Scholar]
- Paterson, A.H.; Bowers, J.E.; Bruggmann, R.; Dubchak, I.; Grimwood, J.; Gundlach, H.; Haberer, G.; Hellsten, U.; Mitros, T.; Poliakov, A.; et al. The Sorghum bicolor genome and the diversification of grasses. Nature 2009, 457, 551–556. [Google Scholar] [CrossRef]
- Lee, W.P.; Stromberg, M.P.; Ward, A.; Stewart, C.; Garrison, E.P.; Marth, G.T. MOSAIK: A hash-based algorithm for accurate next-generation sequencing short-read mapping. PLoS ONE 2014, 9, e90581. [Google Scholar] [CrossRef]
- Garrison, E.; Marth, G. Haplotype-based variant detection from short-read sequencing. arXiv 2012, arXiv:1207.3907. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Endelman, J.B.; Jannink, J.L. Shrinkage estimation of the realized relationship matrix. G3 Genes Genomes Genet. 2012, 2, 1405–1413. [Google Scholar] [CrossRef] [PubMed]
- Piepho, H.P.; Möhring, J.; Melchinger, A.E.; Büchse, A. BLUP for phenotypic selection in plant breeding and variety testing. Euphytica 2008, 161, 209–228. [Google Scholar] [CrossRef]
- Endelman, J.B. Ridge Regression and Other Kernels for Genomic Selection with R Package rrBLUP. Plant Genome 2011, 4. [Google Scholar] [CrossRef] [Green Version]
- Covarrubias-Pazaran, G. Genome-Assisted Prediction of Quantitative Traits Using the R Package sommer. PLoS ONE 2016, 11, e0156744. [Google Scholar] [CrossRef]
- Perez, P.; de los Campos, G. Genome-wide regression and prediction with the BGLR statistical package. Genetics 2014, 198, 483–495. [Google Scholar] [CrossRef]
- Meyer, D.; Dimitriadou, E.; Hornik, K.; Weingessel, A.; Leisch, F. e1071: Misc Functions of the Department of Statistics, Probability Theory Group (Formerly: E1071), TU Wien. R Package 2021, Version 1, 7–9. [Google Scholar]
- Liaw, A.; Wiener, M. Classification and Regression by RandomForest. R News 2002, 2, 18–22. [Google Scholar]
- Fernandes, S.B.; Dias, K.O.G.; Ferreira, D.F.; Brown, P.J. Efficiency of multi-trait, indirect, and trait-assisted genomic selection for improvement of biomass sorghum. Theor. Appl. Genet. 2018, 131, 747–755. [Google Scholar] [CrossRef]
- Heslot, N.; Rutkoski, J.; Poland, J.; Jannink, J.L.; Sorrells, M.E. Impact of marker ascertainment bias on genomic selection accuracy and estimates of genetic diversity. PLoS ONE 2013, 8, e74612. [Google Scholar] [CrossRef]
- Aitken, K.S.; Hermann, S.; Karno, K.; Bonnett, G.D.; McIntyre, L.C.; Jackson, P.A. Genetic control of yield related stalk traits in sugarcane. Theor. Appl. Genet. 2008, 117, 1191–1203. [Google Scholar] [CrossRef]
- Singh, R.K.; Singh, S.P.; Tiwari, D.K.; Srivastava, S.; Singh, S.B.; Sharma, M.L.; Singh, R.; Mohapatra, T.; Singh, N.K. Genetic mapping and QTL analysis for sugar yield-related traits in sugarcane. Euphytica 2013, 191, 333–353. [Google Scholar] [CrossRef]
- de Carvalho, M.P.; Gezan, S.A.; Peternelli, L.A.; Barbosa, M.H.P. Estimation of Additive and Nonadditive Genetic Components of Sugarcane Families Using Multitrait Analysis. Agron. J. 2014, 106, 800–808. [Google Scholar] [CrossRef]
- Bagyalakshmi, K.; Viswanathan, R.; Ravichandran, V. Impact of the viruses associated with mosaic and yellow leaf disease on varietal degeneration in sugarcane. Phytoparasitica 2019, 47, 591–604. [Google Scholar] [CrossRef]
- Singh, A.; Chauhan, S.S.; Singh, A.; Singh, S.B. Deterioration in sugarcane due to pokkah boeng disease. Sugar Technol. 2006, 8, 187–190. [Google Scholar] [CrossRef]
- Viswanathan, R. Varietal Degeneration in Sugarcane and its Management in India. Sugar Technol. 2016, 18, 1–7. [Google Scholar] [CrossRef]
- Young, A.J. Turning a Blind Eye to Ratoon Stunting Disease of Sugarcane in Australia. Plant Dis. 2018, 102, 473–482. [Google Scholar] [CrossRef]
- Desta, Z.A.; Ortiz, R. Genomic selection: Genome-wide prediction in plant improvement. Trends Plant Sci. 2014, 19, 592–601. [Google Scholar] [CrossRef]
- Heslot, N.; Jannink, J.-L.; Sorrells, M.E. Perspectives for Genomic Selection Applications and Research in Plants. Crop Sci. 2015, 55, 1–12. [Google Scholar] [CrossRef]
- Rutkoski, J.E.; Poland, J.; Jannink, J.L.; Sorrells, M.E. Imputation of unordered markers and the impact on genomic selection accuracy. G3 2013, 3, 427–439. [Google Scholar] [CrossRef]
- Zhong, S.; Dekkers, J.C.; Fernando, R.L.; Jannink, J.L. Factors affecting accuracy from genomic selection in populations derived from multiple inbred lines: A Barley case study. Genetics 2009, 182, 355–364. [Google Scholar] [CrossRef]
- Windhausen, V.S.; Atlin, G.N.; Hickey, J.M.; Crossa, J.; Jannink, J.L.; Sorrells, M.E.; Raman, B.; Cairns, J.E.; Tarekegne, A.; Semagn, K.; et al. Effectiveness of genomic prediction of maize hybrid performance in different breeding populations and environments. G3 Genes Genomes Genet. 2012, 2, 1427–1436. [Google Scholar] [CrossRef]
- Robert, P.; Le Gouis, J.; Rincent, R. The Breed Wheat Consortium Combining Crop Growth Modeling With Trait-Assisted Prediction Improved the Prediction of Genotype by Environment Interactions. Front. Plant Sci. 2020, 11, 827. [Google Scholar] [CrossRef] [PubMed]
- Shahi, D.; Guo, J.; Pradhan, S.; Khan, J.; Avci, M.; Khan, N.; McBreen, J.; Bai, G.; Reynolds, M.; Foulkes, J.; et al. Multi-trait genomic prediction using in-season physiological parameters increases prediction accuracy of complex traits in US wheat. BMC Genom. 2022, 23, 298. [Google Scholar] [CrossRef] [PubMed]
- Lado, B.; Vázquez, D.; Quincke, M.; Silva, P.; Aguilar, I.; Gutiérrez, L. Resource allocation optimization with multi-trait genomic prediction for bread wheat (Triticum aestivum L.) baking quality. Theor. Appl. Genet. 2018, 131, 2719–2731. [Google Scholar] [CrossRef] [PubMed]
- Asoro, F.G.; Newell, M.A.; Beavis, W.D.; Scott, M.P.; Jannink, J.L. Accuracy and Training Population Design for Genomic Selection on Quantitative Traits in Elite North American Oats. Plant Genome 2011, 4, 132–144. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Song, J.; Todd, J.; Peng, Z.; Paudel, D.; Luo, Z.; Ma, X.; You, Q.; Hanson, E.; Zhao, Z.; et al. Target enrichment sequencing of 307 germplasm accessions identified ancestry of ancient and modern hybrids and signatures of adaptation and selection in sugarcane (Saccharum spp.), a ‘sweet’ crop with ‘bitter’ genomes. Plant Biotechnol. J. 2019, 17, 488–498. [Google Scholar] [CrossRef]
- Crossa, J.; de los Campos, G.; Pérez, P.; Gianola, D.; Burgueño, J.; Araus, J.L.; Makumbi, D.; Singh, R.P.; Dreisigacker, S.; Yan, J.; et al. Prediction of Genetic Values of Quantitative Traits in Plant Breeding Using Pedigree and Molecular Markers. Genetics 2010, 186, 713–724. [Google Scholar] [CrossRef] [Green Version]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Trait | Plant Cane | First Ratoon | Second Ratoon | Combined | ||||
|---|---|---|---|---|---|---|---|---|
| h2 | H2 | h2 | H2 | h2 | H2 | h2 | H2 | |
| BRIX | 0.39 | 0.50 | 0.27 | 0.39 | 0.15 | 0.22 | 0.22 | 0.30 |
| FC | 0.64 | 0.72 | 0.43 | 0.54 | 0.33 | 0.43 | 0.39 | 0.49 |
| CRS | 0.39 | 0.51 | 0.35 | 0.47 | 0.25 | 0.35 | 0.30 | 0.39 |
| EI | 0.42 | 0.54 | 0.33 | 0.45 | 0.23 | 0.34 | 0.29 | 0.37 |
| POL | 0.42 | 0.53 | 0.34 | 0.47 | 0.22 | 0.31 | 0.29 | 0.38 |
| SC | 0.42 | 0.53 | 0.34 | 0.46 | 0.22 | 0.32 | 0.28 | 0.38 |
| SD | 0.81 | 0.87 | 0.35 | 0.47 | 0.21 | 0.31 | 0.35 | 0.46 |
| SP | 0.49 | 0.61 | 0.56 | 0.66 | 0.38 | 0.50 | 0.41 | 0.52 |
| SW | 0.65 | 0.76 | 0.40 | 0.52 | 0.30 | 0.40 | 0.33 | 0.45 |
| TCH | 0.43 | 0.56 | 0.39 | 0.51 | 0.26 | 0.36 | 0.31 | 0.40 |
| TSH | 0.42 | 0.55 | 0.34 | 0.47 | 0.23 | 0.34 | 0.29 | 0.38 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Islam, M.S.; McCord, P.; Read, Q.D.; Qin, L.; Lipka, A.E.; Sood, S.; Todd, J.; Olatoye, M. Accuracy of Genomic Prediction of Yield and Sugar Traits in Saccharum spp. Hybrids. Agriculture 2022, 12, 1436. https://doi.org/10.3390/agriculture12091436
Islam MS, McCord P, Read QD, Qin L, Lipka AE, Sood S, Todd J, Olatoye M. Accuracy of Genomic Prediction of Yield and Sugar Traits in Saccharum spp. Hybrids. Agriculture. 2022; 12(9):1436. https://doi.org/10.3390/agriculture12091436
Chicago/Turabian StyleIslam, Md. S., Per McCord, Quentin D. Read, Lifang Qin, Alexander E. Lipka, Sushma Sood, James Todd, and Marcus Olatoye. 2022. "Accuracy of Genomic Prediction of Yield and Sugar Traits in Saccharum spp. Hybrids" Agriculture 12, no. 9: 1436. https://doi.org/10.3390/agriculture12091436
APA StyleIslam, M. S., McCord, P., Read, Q. D., Qin, L., Lipka, A. E., Sood, S., Todd, J., & Olatoye, M. (2022). Accuracy of Genomic Prediction of Yield and Sugar Traits in Saccharum spp. Hybrids. Agriculture, 12(9), 1436. https://doi.org/10.3390/agriculture12091436