
Plant Disease Detection and Classification Method Based on the Optimized Lightweight YOLOv5 Model


Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
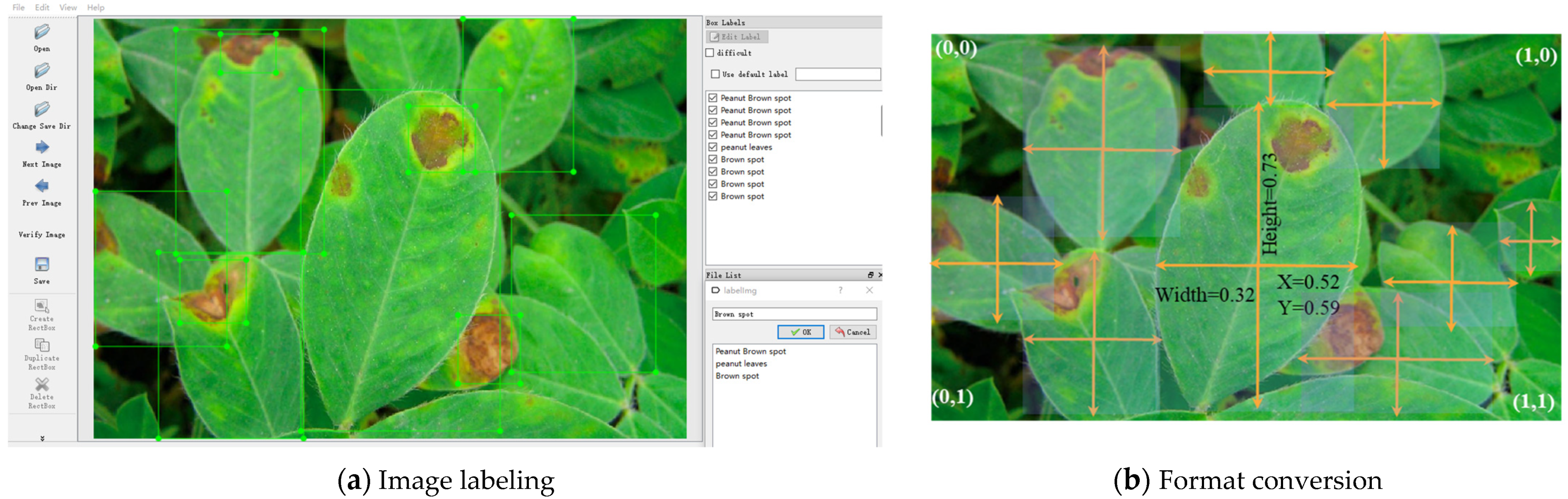
3.1. Dataset Acquisition
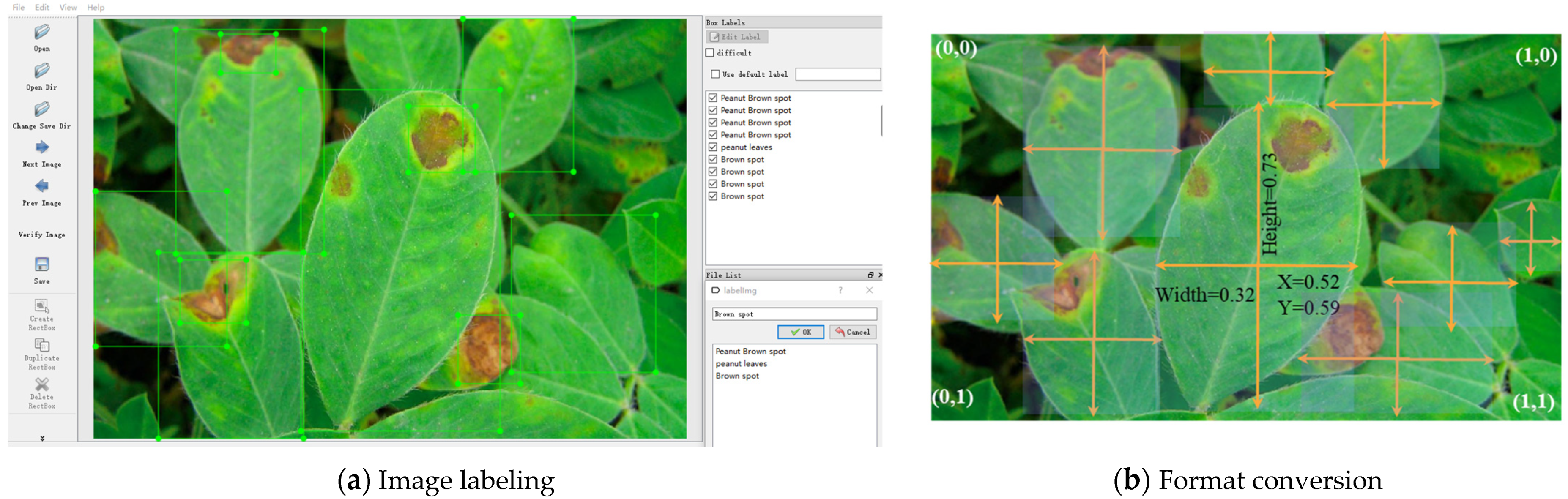
3.2. Image Preprocessing
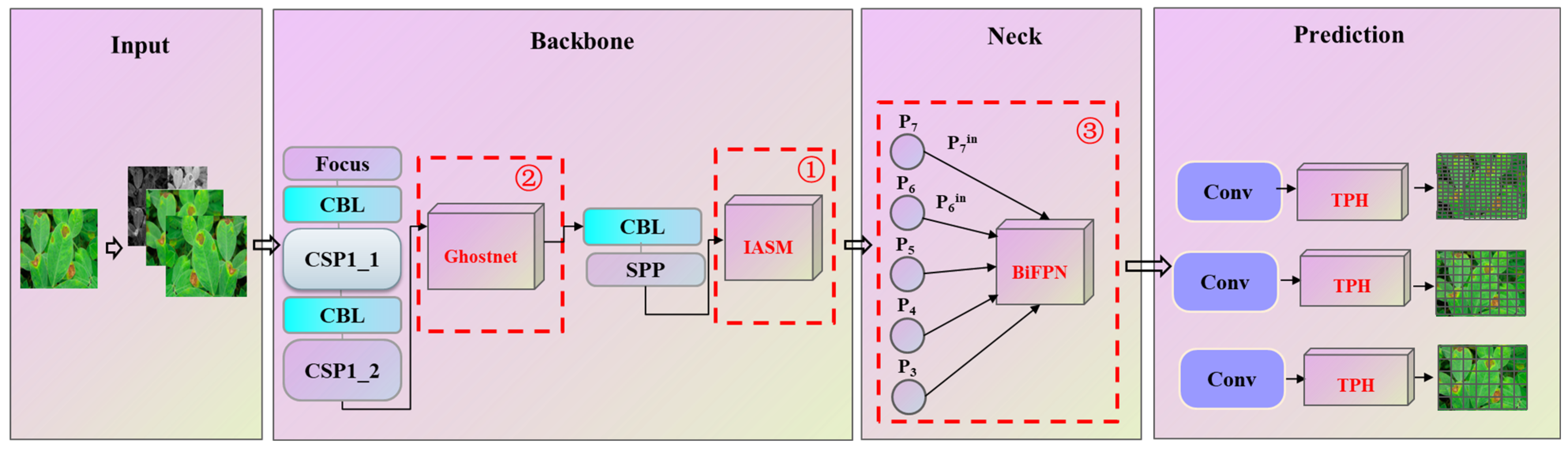
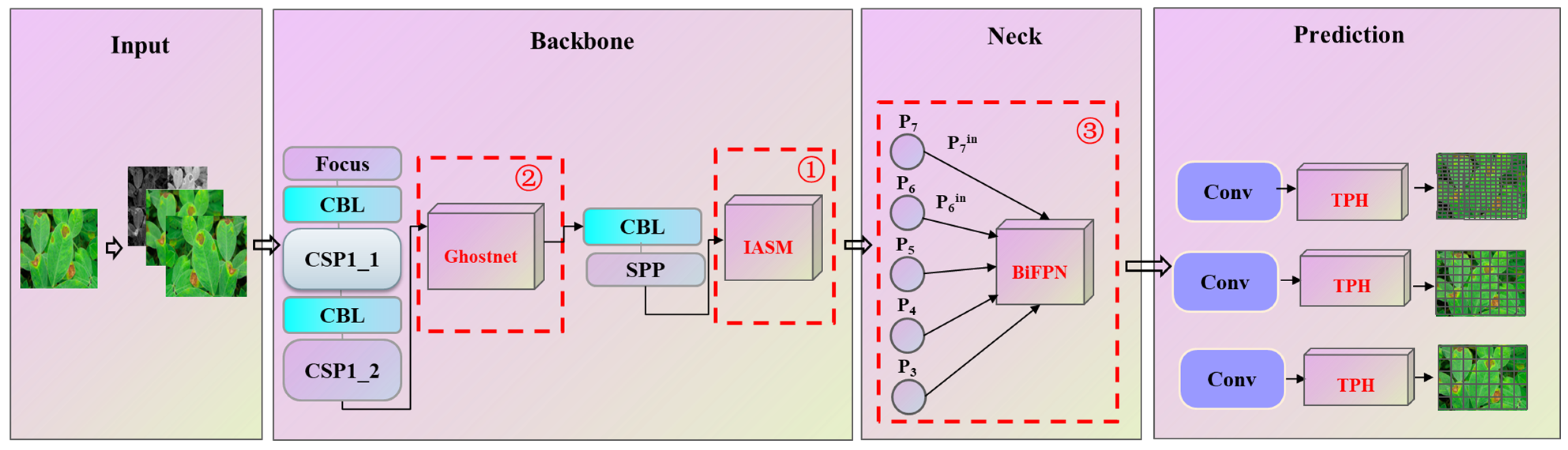
3.3. Plant Disease Detection and Classification Model
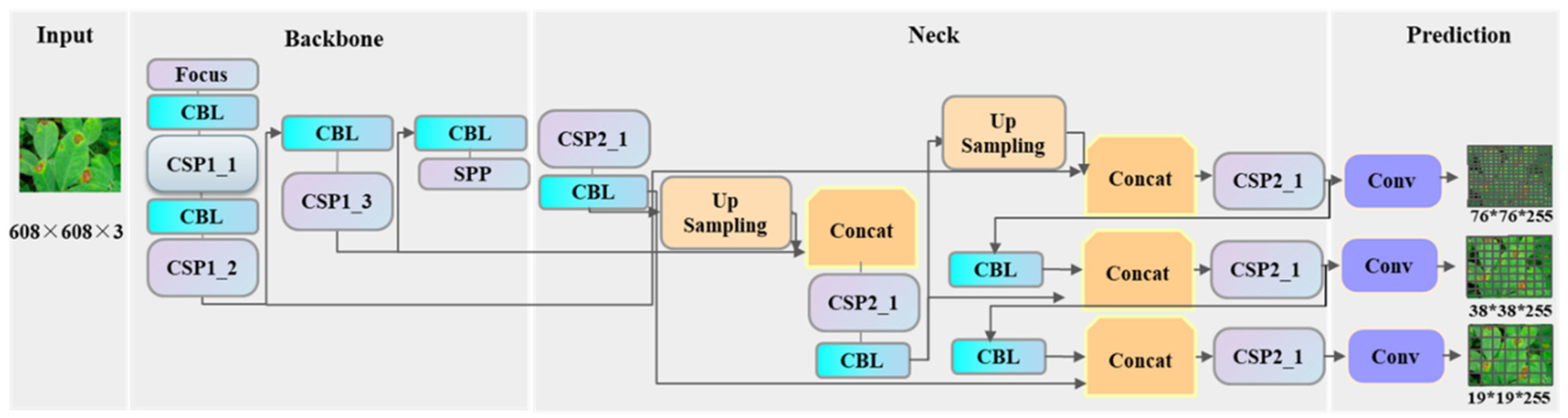
3.3.1. The Principle of the YOLOv5 Model
- (1)
- Input layer: based on the CutMix data enhancement method, the mosaic data enhancement method is proposed, which adaptively calculates the best anchor point frame according to the name of the dataset, and adaptively adds the least black border to the scaled image.
- (2)
- Backbone layer: the structure of the Focus benchmark network, CSPDarknet53, and SPP is used. The CSPDarknet53 structure is used. The first layer (Focus layer): pixels are periodically extracted from high-resolution images and reconstructed into low-resolution images to reduce loss of original information and computational redundancy. The second layer (CSP structure): includes two types of CSP structure with Resunit (2×CBL convolution + residual) and ordinary CBL CSP structure, which is applied to the backbone layer and the neck layer, respectively. It is worth noting that this layer enhances the gradient value of backpropagation between layers and the generalization ability of the model by increasing the residual structure. The third layer (SPP structure): extract features of different scales through a pooling of different kernel sizes, and then perform feature fusion through stacking.
- (3)
- Neck layer: the series FPN + PAN structure performs feature fusion and multi-scale prediction between different layers from bottom to top, strengthening the spread of semantic features and positioning information. The CBL module after the Concat operation is replaced by the CSP2_1 module, which helps to locate the pixels to form the mask.
- (4)
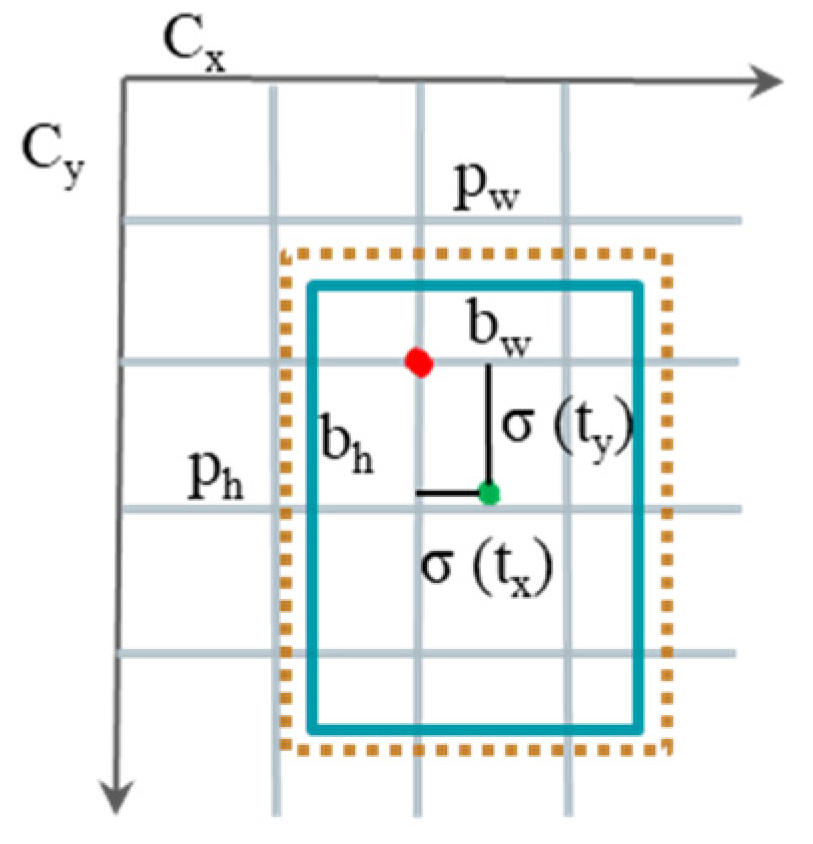
- Prediction layer: the YOLOv5 model uses GIOU_Loss as the loss function of the bounding box, increases the intersection scale, and uses the weighted NMS method to screen the target box, which has a better classification effect for occluded overlapping targets.
3.3.2. Model Improvement
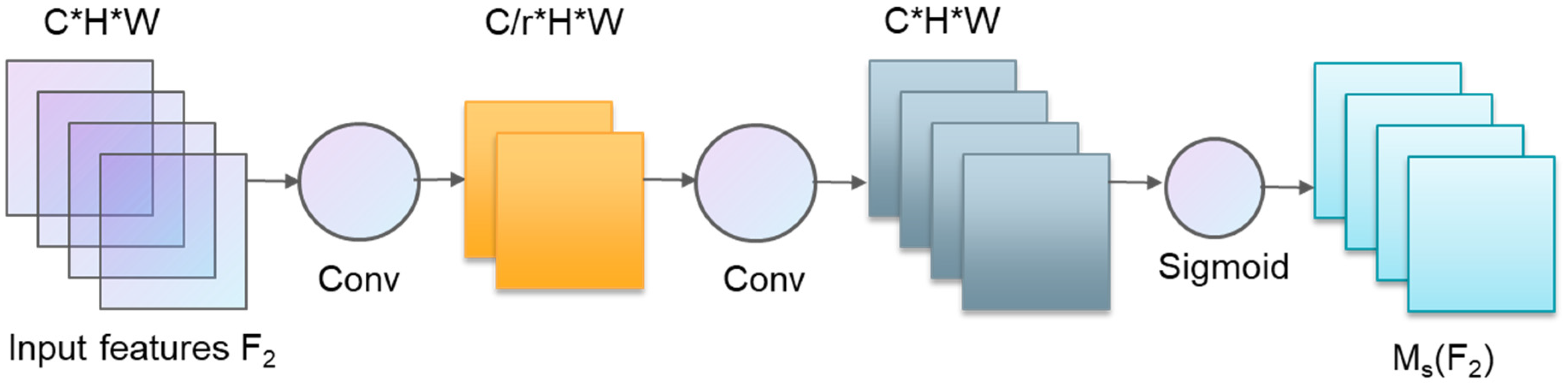
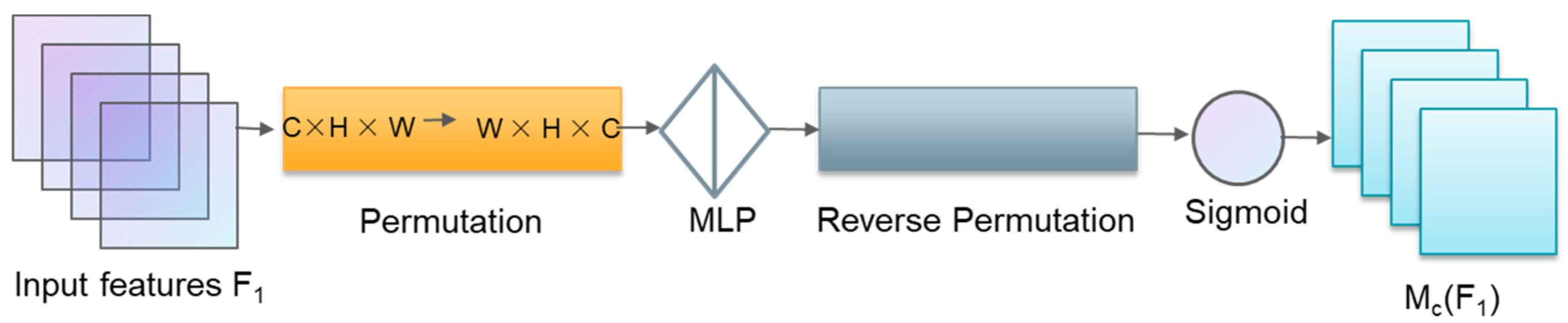
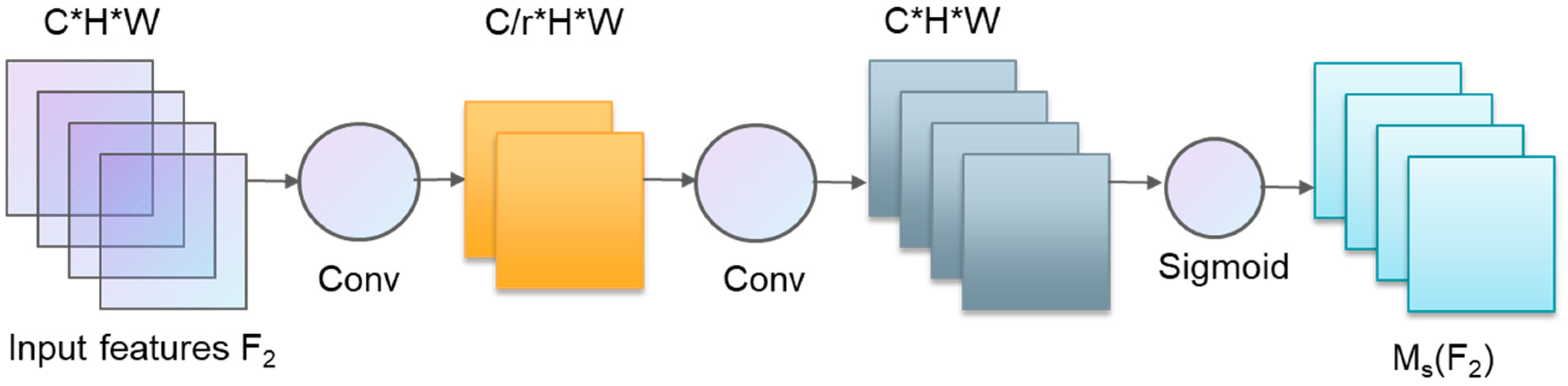
- The improved attention submodule (IASM)
- 2.
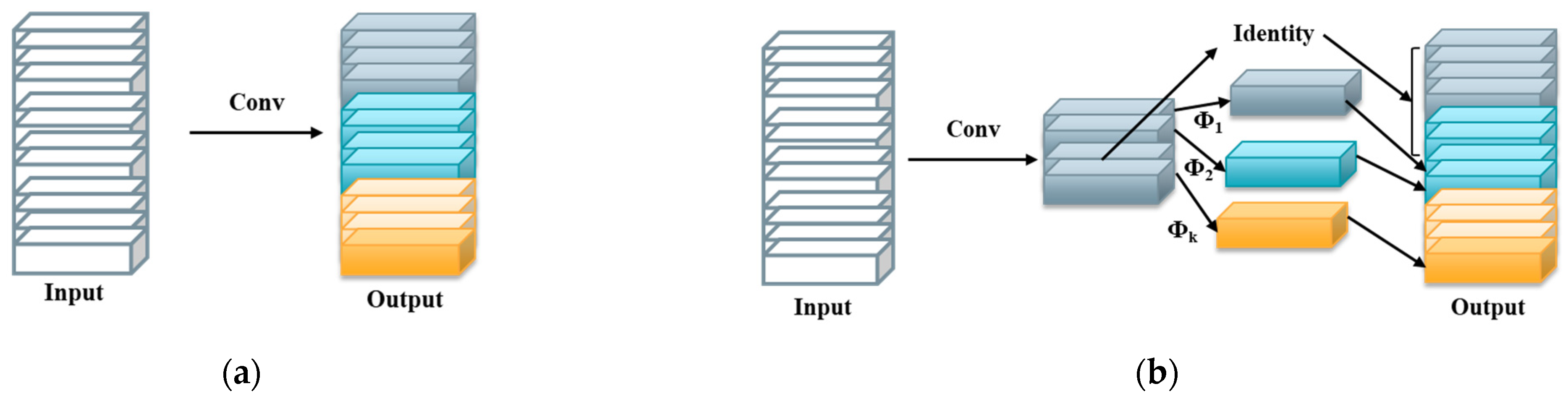
- Ghostnet
- 3.
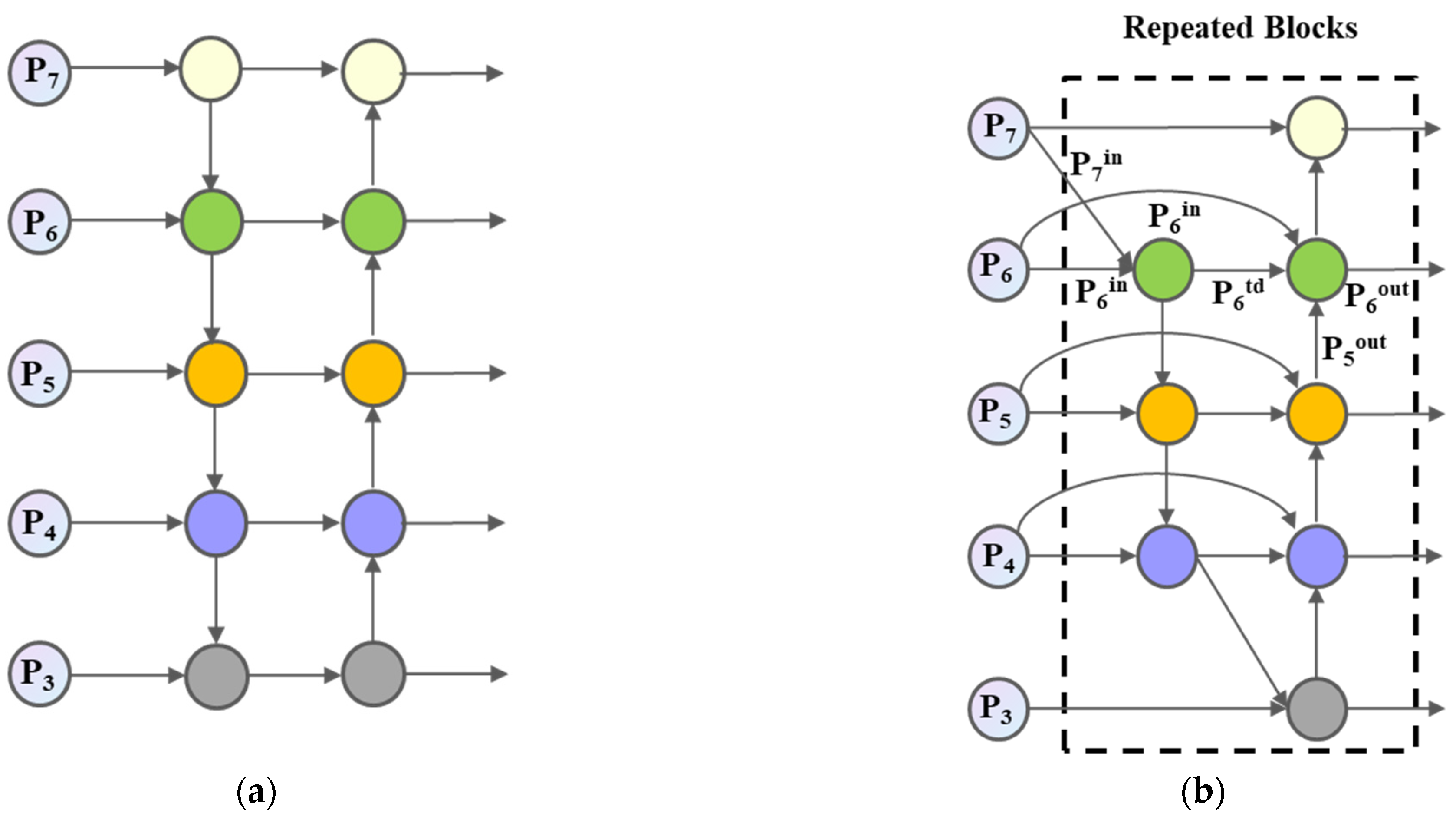
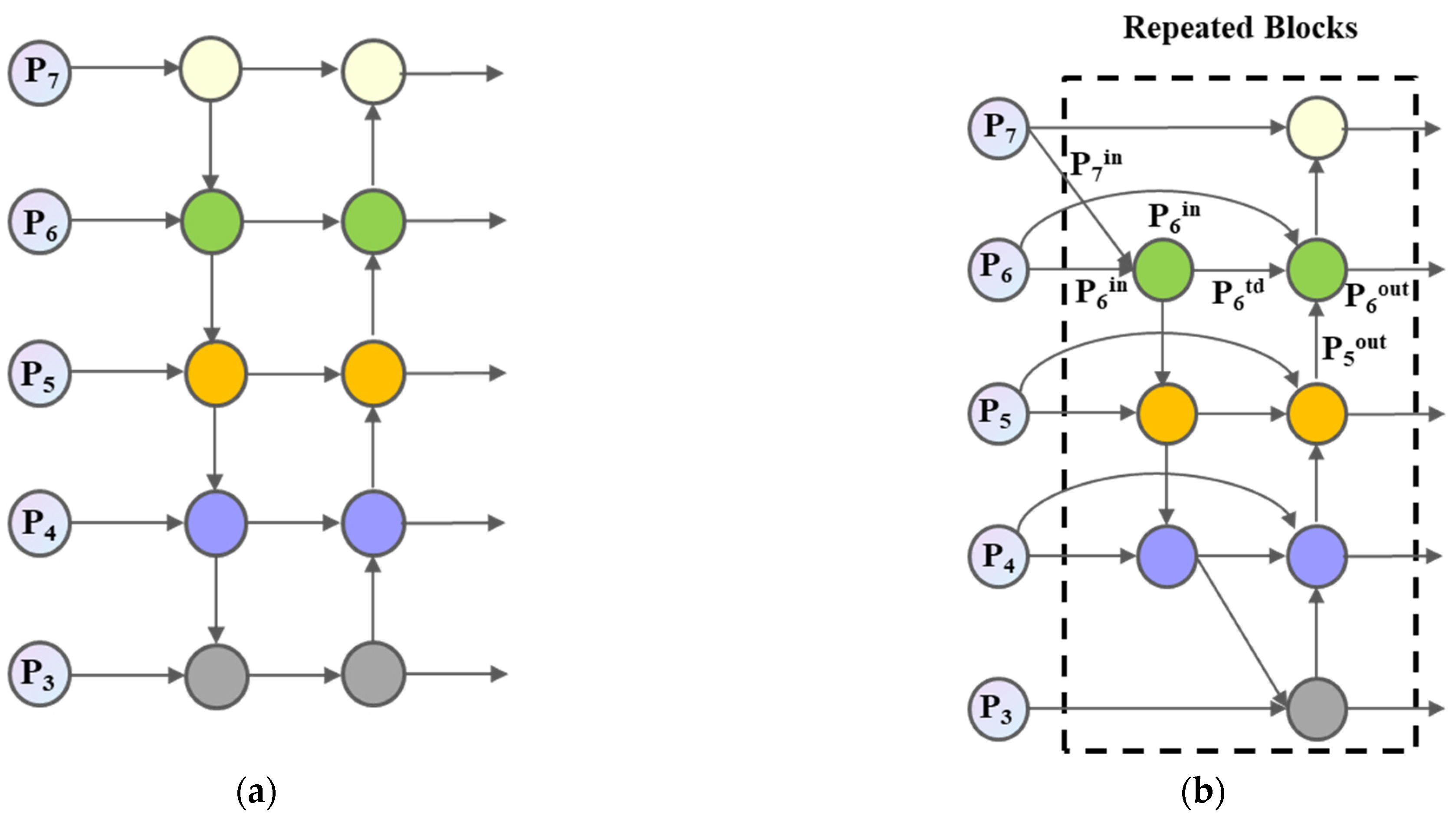
- The Bidirectional Feature Pyramid Network
3.3.3. Performance Indicators
- Accuracy and Precision
- 2.
- Loss function
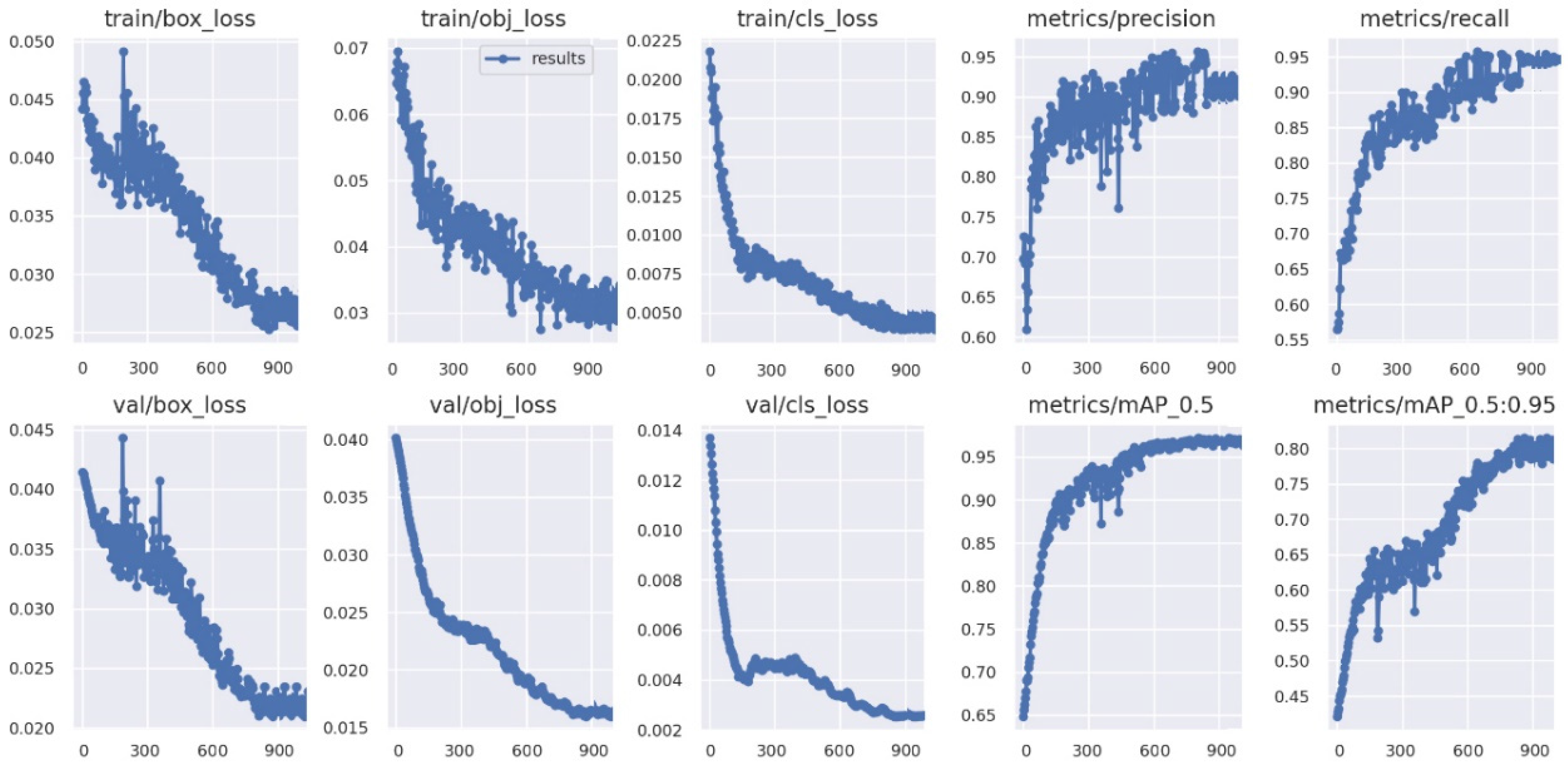
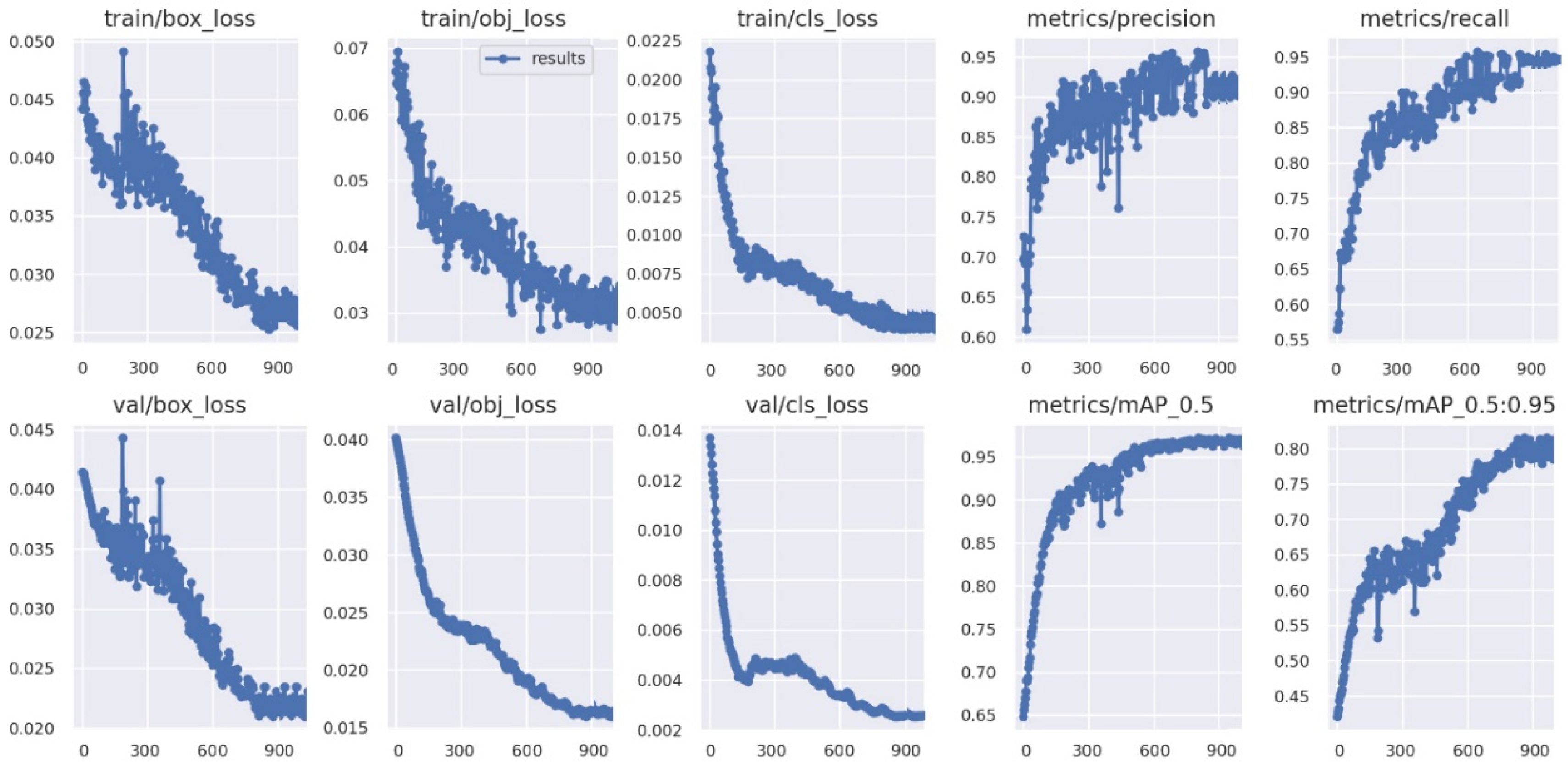
3.4. Model Training and Testing
4. Results and Analysis
4.1. Model Parameter Optimization
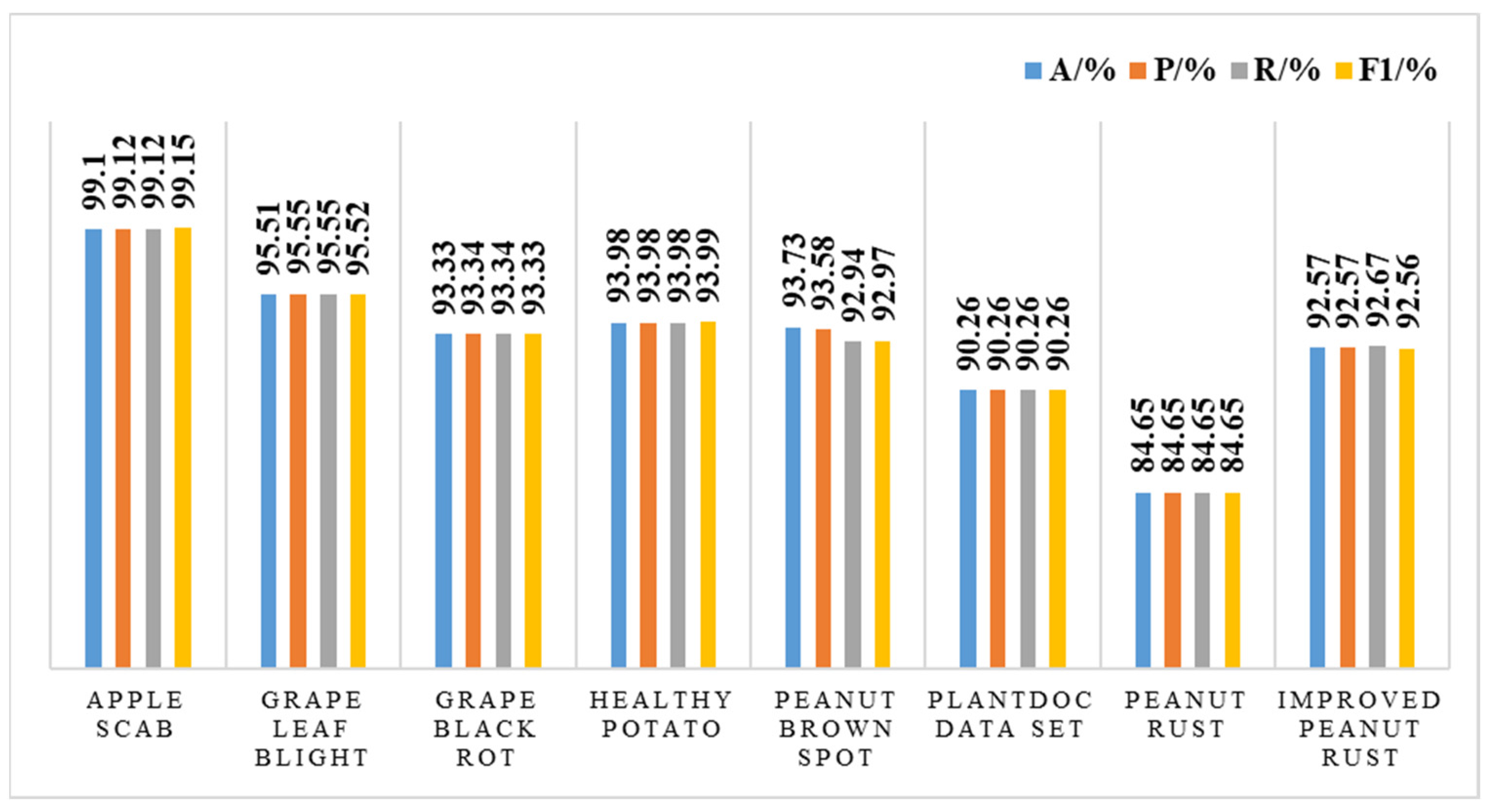
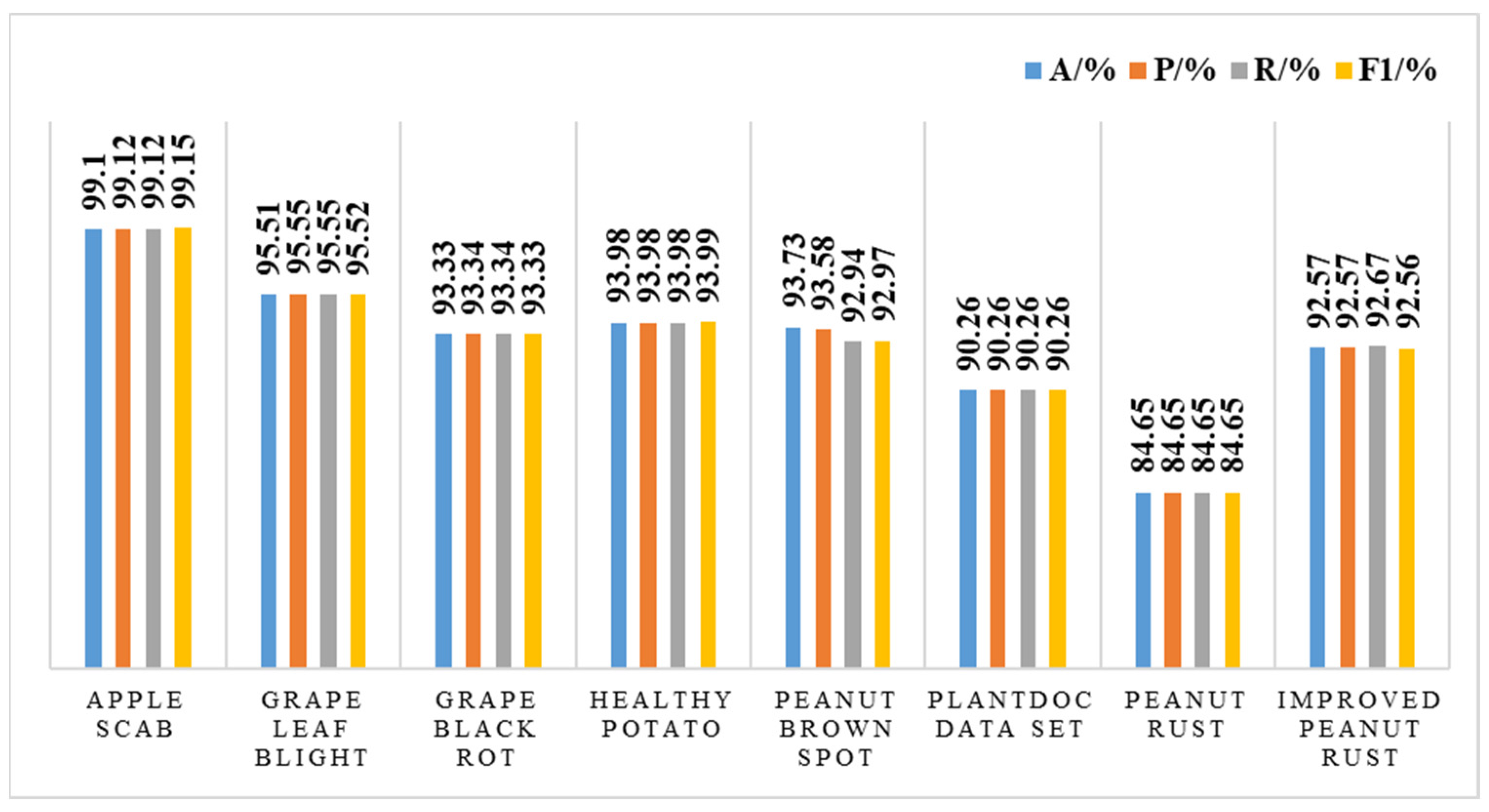
4.2. Analysis of Test Results
4.3. Ablation Experiment
4.4. Transfer Learning Experiments
5. Conclusions
- (1)
- To expand the application scope of the model, more datasets of plant diseases should be collected. Since there is still room for improvement in the quantity and quality of self-made datasets, the recognition rate of some images is low due to inconspicuous classification features. Further research is needed on image recognition with inconspicuous classification features. Therefore, the self-made dataset will be expanded next. It uses the transfer learning ability of the model to identify and detect more kinds of plant diseases and provides a faster and more efficient plant disease detection scheme for actual needs.
- (2)
- The loss function of the improved recognition method includes the positioning error of the detection frame, and the positioning error in the detection of small targets has a more significant impact on the loss function. Therefore, it is necessary to optimize and improve the model according to the characteristics of small target recognition to improve the accuracy further.
- (3)
- Further studies in other fields, such as soil science and tropical crop productivity, can be used to explore the relationship between the effects of plant diseases and expand the guiding role of model output results on agricultural production.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Singh, A.K.; Ganapathysubramanian, B.; Sarkar, S.; Singh, A. Deep learning for plant stress phenotyping: Trends and future perspectives. Trends Plant. Sci. 2018, 23, 883–898. [Google Scholar] [CrossRef] [Green Version]
- Zhou, J.; Li, J.; Wang, C.; Wu, H.; Teng, G. Crop disease identification and interpretation method based on multimodal deep learning. Comput. Electron. Agric. 2021, 189, 106408. [Google Scholar] [CrossRef]
- Lins, E.A.; Rodriguez, J.P.M.; Scoloski, S.I.; Pivato, J.; Lima, M.B.; Fernandes, J.M.C.; da Silva Pereira, P.R.V.; Lau, D.; Rieder, R. A method for counting and classifying aphids using computer vision. Comput. Electron. Agric. 2020, 169, 105200. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 27th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; IEEE: New York, NY, USA, 2014; pp. 580–587. [Google Scholar]
- Al Hiary, H.; Ahmad, S.B.; Reyalat, M.; Braik, M.; Alrahamneh, Z. Fast and accurate detection and classification of plant diseases. Int. J. Comput. Appl. 2011, 17, 31–38. [Google Scholar] [CrossRef]
- Mohan, K.J.; Balasubramanian, M.; Palanivel, S. Detection and recognition of diseases from paddy plant leaf images. Int. J. Comput. Appl. 2016, 144, 34–41. [Google Scholar]
- Zhou, C.; Yang, G.; Liang, D.; Hu, J.; Yang, H.; Yue, J.; Yan, R.; Han, L.; Huang, L.; Xu, L. Recognizing black point in wheat kernels and determining its extent using multidimensional feature extraction and a naive Bayes classifier. Comput. Electron. Agric. 2021, 180, 105919. [Google Scholar] [CrossRef]
- Amudhan, A.N.; Sudheer, A.P. Lightweight and computationally faster Hypermetropic Convolutional Neural Network for small size object detection. Image Vis. Comput. 2022, 119, 104396. [Google Scholar]
- Wosner, O.; Farjon, G.; Bar-Hillel, A. Object detection in agricultural contexts: A multiple resolution benchmark and comparison to human. Comput. Electron. Agric. 2021, 189, 106404. [Google Scholar] [CrossRef]
- Zheng, Q.; Chen, Y. Interactive multi-scale feature representation enhancement for small object detection. Image Vis. Comput. 2021, 108, 104128. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 6–12 June 2015; IEEE: New York, NY, USA, 2015; pp. 1–9. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern. Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Cheng-Yang, F.; Berg, A.C. SSD: Single Shot MulfiBox Detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Glenn, J. Yolov5. Git Code. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 1 February 2020).
- Madec, S.; Jin, X.; Lu, H.; De Solan, B.; Liu, S.; Duyme, F.; Heritier, E.; Baret, F. Ear density estimation from high resolution rgb imagery using deep learning technique. Agric. For. Meteorol. 2019, 264, 225–234. [Google Scholar] [CrossRef]
- Ngugi, L.C.; Abelwahab, M.; Abo-Zahhad, M. Recent advances in image processing techniques for automated leaf pest and disease recognition—A review. Agric. Inf. Processing (Engl.) 2021, 8, 25. [Google Scholar] [CrossRef]
- Jiao, L.; Dong, S.; Zhang, S.; Xie, C.; Wang, H. AF-RCNN: An anchor-free convolutional neural network for multi-categories agricultural pest detection. Comput. Electron. Agric. 2020, 174, 105522. [Google Scholar] [CrossRef]
- Li, X.; Pan, J.; Xie, F.; Zeng, J.; Li, Q.; Huang, X.; Liu, D.; Wang, X. Fast and accurate green pepper detection in complex backgrounds via an improved Yolov4-tiny model. Comput. Electron. Agric. 2021, 191, 106503. [Google Scholar] [CrossRef]
- Fu, L.; Wu, F.; Zou, X.; Jiang, Y.; Lin, J.; Yang, Z.; Duan, J. Fast detection of banana bunches and stalks in the natural environment based on deep learning. Comput. Electron. Agric. 2022, 194, 106800. [Google Scholar] [CrossRef]
- Wu, N.; Weng, S.; Chen, J.; Xiao, Q.; Zhang, C.; He, Y. Deep convolution neural network with weighted loss to detect rice seeds vigor based on hyperspectral imaging under the sample-imbalanced condition. Comput. Electron. Agric. 2022, 196, 106850. [Google Scholar] [CrossRef]
- DeChant, C.; Wiesner-Hanks, T.; Chen, S.; Stewart, E.L.; Yosinski, J.; Gore, M.A.; Nelson, R.J.; Lipson, H. Automated identification of northern leaf blight-infected maize plants from field imagery using deep learning. Phytopathology 2017, 107, 1426–1432. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.; Zhao, Y.; Sun, Y.; Yang, R.; Han, Z.; Li, J. Identification of winter jujubes with different maturity levels based on data balance deep learning. J. Agric. Mach. 2020, 51, 457–463+492. [Google Scholar]
- Picon, A.; Alvarez-Gila, A.; Seitz, M.; Ortiz-Barredo, A.; Echazarra, J.; Johannes, A. Deep convolutional neural networks for mobile capture device-based crop disease classification in the wild. Comput. Electron. Agri. 2018, 161, 280–290. [Google Scholar] [CrossRef]
- Xu, W.; Zhao, L.; Li, J.; Shang, S.; Ding, X.; Wang, T. Detection and classification of tea buds based on deep learning. Comput. Electron. Agric. 2022, 192, 106547. [Google Scholar] [CrossRef]
- Liu, B.; Zhang, Y.; He, D.; Li, Y. Identification of apple leaf diseases based on deep convolutional neural networks. Symmetry 2018, 10, 11. [Google Scholar] [CrossRef] [Green Version]
- Yu, Y.; Zhang, K.; Yang, L.; Zhang, D. Fruit detection for strawberry harvesting robot in a non-structural environment based on Mask-RCNN. Comput. Electron. Agric. 2019, 163, 104846. [Google Scholar] [CrossRef]
- Yang, G.F.; Yang, Y.; He, Z.K.; Zhang, X.Y.; He, Y. A rapid, low-cost deep learning system to classify strawberry disease based on cloud service. Chin. J. Agric. Sci. (Engl. Version) 2022, 21, 460–473. [Google Scholar] [CrossRef]
- Zhang, Y.; Yu, J.; Chen, Y.; Yang, W.; Zhang, W.; He, Y. Real-time strawberry detection using deep neural networks on embedded system (rtsd-net): An edge AI application. Comput. Electron. Agric. 2022, 192, 106586. [Google Scholar] [CrossRef]
- Santos, T.T.; de Souza, L.L.; dos Santos, A.A.; Avila, S. Grape detection, segmentation, and tracking using deep neural networks and three-dimensional association. Comput. Electron. Agric. 2020, 170, 105247. [Google Scholar] [CrossRef] [Green Version]
- Tian, Y.; Yang, G.; Wang, Z.; Wang, H.; Li, E.; Liang, Z. Apple detection during different growth stages in orchards using the improved YOLO-V3 model. Comput. Electron. Agric. 2019, 157, 417–426. [Google Scholar] [CrossRef]
- Kang, H.; Chen, C. Fast implementation of real-time fruit detection in apple orchards using deep learning. Comput. Electron. Agric. 2020, 168, 105108. [Google Scholar] [CrossRef]
- Wang, X.; Tang, J.; Whitty, M. DeepPhenology: Estimation of apple flower phenology distributions based on deep learning. Comput. Electron. Agric. 2021, 185, 106123. [Google Scholar] [CrossRef]
- Mathulaprangsan, S.; Lanthong, K.; Jetpipattanapong, D.; Sateanpattanakul, S.; Patarapuwadol, S. Rice Diseases Recognition Using Effective Deep Learning Models. In Proceedings of the 2020 Joint International Conference on Digital Arts, Media and Technology with ECTI Northern Section Conference on Electrical, Electronics, Computer and Telecommunications Engineering (ECTI DAMT & NCON), Pattaya, Thailand, 11–14 March 2020; pp. 386–389. [Google Scholar] [CrossRef]
- Temniranrat, P.; Kiratiratanapruk, K.; Kitvimonrat, A.; Sinthupinyo, W.; Patarapuwadol, S. A system for automatic rice disease detection from rice paddy images serviced via a Chatbot. Comput. Electron. Agric. 2021, 185, 106156. [Google Scholar] [CrossRef]
- Li, D.; Ahmed, F.; Wu, N.; Sethi, A.I. YOLO-JD: A Deep Learning Network for Jute Diseases and Pests Detection from Images. Plants 2022, 11, 937. [Google Scholar] [CrossRef]
- Islam, F.; Hoq, M.N.; Rahman, C.M. Application of transfer learning to detect potato disease from leaf image. In Proceedings of the IEEE International Conference on Robotics, Automation, Artificial-Intelligence and Internet-of-Things (RAAICON), Dhaka, Bangladesh, 29 November–1 December 2019; pp. 127–130. [Google Scholar] [CrossRef]
- Lee, T.Y.; Yu, J.Y.; Chang, Y.C.; Yang, J.M. Health Detection for Potato Leaf with Convolutional Neural Network. In Proceedings of the Indo-Taiwan 2nd International Conference on Computing, Analytics and Networks, Taiwan, China, 7–15 February 2020; pp. 289–293. Available online: https://doi.org/10.1109/Indo-TaiwanICAN48429.2020.9181312 (accessed on 1 January 2020).
- Rey, J.C.; Olivares, B.; Lobo, D.; Navas-Cortés, J.A.; Gómez, J.A.; Landa, B.B. Fusarium Wilt of Bananas: A Review of Agro-Environmental Factors in the Venezuelan Production System Affecting Its Development. Agronomy 2021, 11, 986. [Google Scholar] [CrossRef]
- Campos, O.F.; Paredes, J.; Rey, D.; Lobo, S.; Galvis-Causil, S. The relationship between the normalized difference vegetation index, rainfall, and potential evapotranspiration in a banana plantation of Venezuela. STJSSA 2021, 18, 58–64. [Google Scholar] [CrossRef]
- Orlando, O.; Araya-Alman, M.; Acevedo-Opazo, C.; Cañete-Salinas, P.; Rey, J.C.; Lobo, D.; Landa, B. Relationship between Soil Properties and Banana Productivity in the Two Main Cultivation Areas in Venezuela. J. Soil Sci. Plant Nutr. 2020, 20, 2512–2524. [Google Scholar] [CrossRef]
- Koirala, A.; Walsh, K.B.; Wang, Z.; McCarthy, C. Deep learning—Method overview and review of use for fruit detection and yield estimation. Comput. Electron. Agric. 2019, 162, 219–234. [Google Scholar] [CrossRef]
- Sa, I.; Popović, M.; Khanna, R.; Chen, Z.; Lottes, P.; Liebisch, F.; Nieto, J.; Stachniss, C.; Walter, A.; Siegwart, R. Weedmap: A large-scale semantic weed mapping framework using aerial multispectral imaging and deepneural network for precision farming. Remote Sens. 2018, 10, 1423. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Li, Y.; Yang, Y.; Guo, R.; Yang, J.; Yue, J.; Wang, Y. A high-precision detection method of hydroponic lettuce seedlings status based on improved Faster RCNN. Comput. Electron. Agric. 2021, 182, 106054. [Google Scholar] [CrossRef]
- Sun, J.; He, X.; Ge, X.; Wu, X.; Shen, J.; Song, Y. Detection of Key Organs in Tomato Based on Deep Migration Learning in a Complex Background. Agriculture 2018, 8, 196. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.; Zhao, L.; Li, B.; Liu, X.; Xu, W.; Li, J. Recognition and counting of typical apple pests based on deep learning. Ecol. Inform. 2022, 68, 101556. [Google Scholar] [CrossRef]
- Xu, W.; Zhu, Z.; Ge, F.; Han, Z.; Li, J. Analysis of Behavior Trajectory Based on Deep Learning in Ammonia Environment for Fish. Sensors 2020, 20, 4425. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Xu, C.; Jiang, L.; Xiao, Y.; Deng, L.; Han, Z. Detection and Analysis of Behavior Trajectory for Sea Cucumbers Based on Deep Learning. IEEE Access 2020, 8, 18832–18840. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Generation Time | Network-Level | Structural Features | Advantages and Limitations |
|---|---|---|---|---|
| LeNet | 1998 | 5 | Local connection and weight sharing | Poor processing power for larger image datasets |
| AlexNet | 2012 | 8 | Dropout was proposed to prevent overfitting | High requirements for GPU |
| GoogLeNet | 2014 | 22 | The Inception block was adopted as the base convolutional block | Too much computation |
| VGGNet | 2014 | 19 | Max pooling was used between layers | High memory usage |
| Faster R-CNN | 2016 | - | RPN candidate box generation algorithm | Low detection speed |
| YOLOv1 | 2015 | 26 | DarkNet was adopted for feature detection | Low positioning accuracy |
| YOLOv5 | 2020 | 640 | Hardwish activation function was added | Insufficient attention to small goals and key areas |
| Datasets | Classes | Train Images | Validation Images | Test Images | Size (Pixels) |
|---|---|---|---|---|---|
| PlantVillage | 61 | 31,718 | 4540 | 4514/4513 | 256 × 256 |
| PlantDoc | 27 | 2098 | 221 | 279 | 640 × 640 |
| Peanut Brown Spot | - | 2608 | 326 | 331 | 256 × 256 |
| Peanut Rust | - | 1088 | 136 | 142 | 256 × 256 |
| Index | Parameter |
|---|---|
| RAM | 8 G |
| CPU | Intel®Core™i5-7200 CPU@2.50 GHz |
| GPU | RTX 2070 (8 GB) |
| CUDA | 4.10.1 |
| Development Environment | Pytorch1.4 |
| Programing Language | Python1.8 |
| Model | YOLOv5 |
| Model | Layers | mAP | F1 | Speed (ms) | FPS | Params (M) | FLOPs (B) |
|---|---|---|---|---|---|---|---|
| YOLO v5s | 191 | 14.08 | 0.873 | 2.2 | 455 | 7.3 | 17.0 |
| YOLO v5m | 263 | 41.33 | 0.883 | 2.9 | 345 | 21.4 | 51.3 |
| YOLO v5l | 335 | 90.85 | 0.887 | 3.8 | 264 | 47.0 | 115.4 |
| YOLO v5x | 407 | 169.29 | 0.889 | 6.0 | 167 | 87.7 | 218.8 |
| Model | Model Size/MB | Iteration Number | Operation Time/ms | Loss | P/% | R/% | F1/% |
|---|---|---|---|---|---|---|---|
| Faster R-CNN | 165.0 | 1000 | 2.35 | 1.28 | 84.23 | 85.94 | 85.92 |
| VGG16 | 118.0 | 1000 | 1.58 | 1.56 | 86.66 | 85.85 | 84.18 |
| SSD | 90.5 | 1000 | 0.79 | 1.28 | 85.37 | 85.29 | 86.32 |
| EfficientDet | 52.0 | 1000 | 0.32 | 1.13 | 90.39 | 90.65 | 90.89 |
| YOLOv4 | 33.7 | 1000 | 0.24 | 1.04 | 86.59 | 87.20 | 87.74 |
| YOLOv5 | 14.6 | 1000 | 0.17 | 0.89 | 89.75 | 90.25 | 90.68 |
| Optimized YOLOv5 | 13.8 | 1000 | 0.15 | 0.56 | 93.73 | 92.94 | 92.97 |
| Model | Iteration Number | Learning Rate | Operation Time/s | Loss | P/% | R/% | F1/% |
|---|---|---|---|---|---|---|---|
| YOLOv5 | 1000 | 0.0001 | 0.18 | 0.89 | 89.75 | 90.25 | 91.68 |
| IASM + YOLOv5 | 1000 | 0.0001 | 0.16 | 0.65 | 91.80 | 92.68 | 92.38 |
| BiFPN + YOLOv5 | 1000 | 0.0001 | 0.17 | 0.62 | 92.56 | 90.98 | 92.07 |
| WBF + YOLOv5 | 1000 | 0.0001 | 0.15 | 0.79 | 91.31 | 91.78 | 91.50 |
| CAM + YOLOv5 | 1000 | 0.0001 | 0.19 | 0.69 | 89.98 | 88.91 | 91.87 |
| SAM + YOLOv5 | 1000 | 0.0001 | 0.17 | 0.76 | 90.59 | 90.63 | 92.01 |
| NMS + YOLOv5 | 1000 | 0.0001 | 0.17 | 0.82 | 90.57 | 90.85 | 90.97 |
| Optimized YOLOv5 | 1000 | 0.0001 | 0.15 | 0.56 | 93.73 | 92.94 | 92.97 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Shang, S.; Wang, D.; He, X.; Feng, K.; Zhu, H. Plant Disease Detection and Classification Method Based on the Optimized Lightweight YOLOv5 Model. Agriculture 2022, 12, 931. https://doi.org/10.3390/agriculture12070931
Wang H, Shang S, Wang D, He X, Feng K, Zhu H. Plant Disease Detection and Classification Method Based on the Optimized Lightweight YOLOv5 Model. Agriculture. 2022; 12(7):931. https://doi.org/10.3390/agriculture12070931
Chicago/Turabian StyleWang, Haiqing, Shuqi Shang, Dongwei Wang, Xiaoning He, Kai Feng, and Hao Zhu. 2022. "Plant Disease Detection and Classification Method Based on the Optimized Lightweight YOLOv5 Model" Agriculture 12, no. 7: 931. https://doi.org/10.3390/agriculture12070931
APA StyleWang, H., Shang, S., Wang, D., He, X., Feng, K., & Zhu, H. (2022). Plant Disease Detection and Classification Method Based on the Optimized Lightweight YOLOv5 Model. Agriculture, 12(7), 931. https://doi.org/10.3390/agriculture12070931