
LIFRNet: A Novel Lightweight Individual Fish Recognition Method Based on Deformable Convolution and Edge Feature Learning

Abstract
:1. Introduction
- Complex underwater environment: The primary difficulty of underwater recognition task is that individual fish recognition needs to deal with the complex and changeable underwater environment. Due to poor underwater lighting conditions, compared to the data obtained under normal conditions, the quality of underwater video and image data is not high. In addition, some water bodies have large chromatic aberration changes, turbid water quality and the interference of many non-fish targets such as algae. It brings difficulties to effectively obtaining the visual characteristics of fish, so it is a great challenge to accurately recognize individual fish.
- Serious occlusion between fish: The majority of underwater fish activity occurs in groups. Many fish swim fast and are small in size, and the individual fish shield each other. However, individual recognition needs to accurately separate individual fish from other individual fish and the surrounding environment, and then extract the visual feature information of its torso. Therefore, it is very difficult to effectively extract the visual feature information of a fish torso between severely occluded individual fish.
- There is a significant visual similarity between each fish. Different fish species have unique visual characteristics. However, the visual differences between individual fish are very small and the visual similarities are strong. Some individual fish are challenging to distinguish directly with the naked eye, so the recognition algorithm must precisely capture the tiny visual variations between the individuals.
- in the fish detection part, the CBAM attention mechanism module is added to greatly improve the accuracy of object detection at the cost of a small number of parameters by focusing on the two dimensions of channel and space;
- in the fish recognition part, we use the combination of 1 × 1 convolution and BN layer to learn the edge features of fish, use deformable convolution which is more suitable for the swimming posture of fish, and use the Mish activation function instead of Relu to obtain smaller intra class distance and larger inter-class distance;
- we collect and recognize the individual fish recognition dataset (DlouFish), which contains a total of 6950 images of 384 individual fish and is numbered by the individual, to facilitate the feature extraction, training and prediction of underwater individual fish using deep neural networks.
2. Related Work
3. The Proposed Work
3.1. Underwater Fish Detection Module
3.2. Individual Fish Recognition Module
3.2.1. Backbone Network
3.2.2. Deformable Convolution
3.2.3. Edge Feature Learning
3.2.4. Mish Activation Function
3.2.5. Loss Function
3.3. Real-Time Visualization Module
- (1)
- Cameras are installed on different sides of the water. Each camera only recognizes fish swimming in the same direction, and then summarizes the information to obtain accurate fish information.
- (2)
- Recode the individual fish information, and use the numbers 1 and 2 as the basis to distinguish different sides of the same fish. The individual fish information is obtained through only one camera.
4. Experiment Result and Discussion
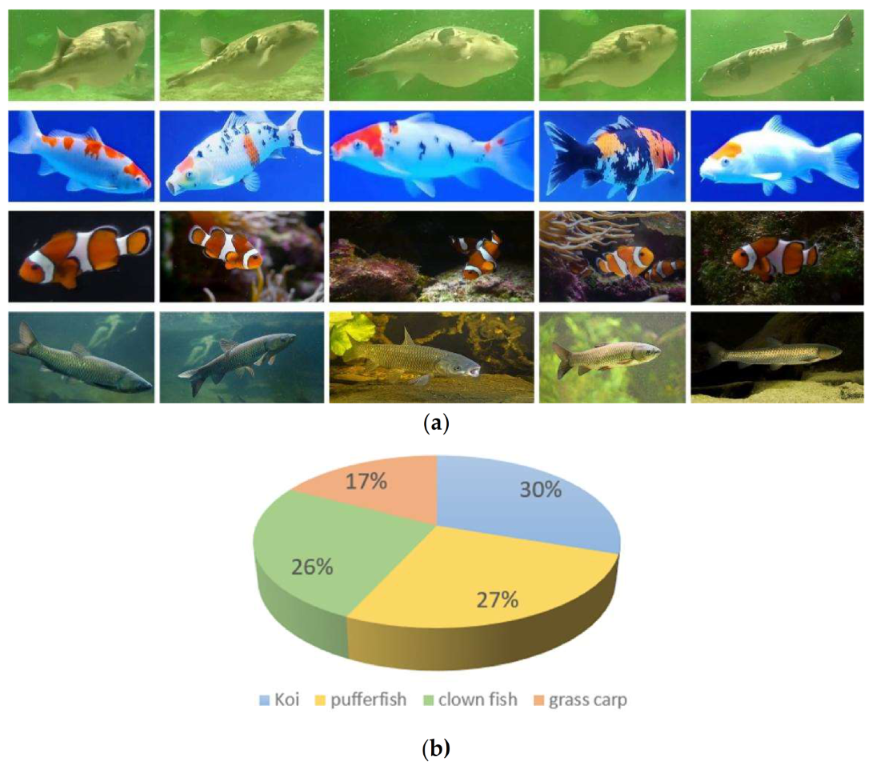
4.1. The Dataset
4.2. Experimental Setup
4.3. Performance Comparison of YOLOV4-Tiny Incorporating Different Attention Mechanisms
4.4. Performance Comparison and Analysis
4.4.1. Comparison and Analysis of Improved Network Performance
4.4.2. Analysis of Experimental Results of Adding Deformable Convolution Using Different Methods
- YOLOV4-Tiny with a fused CBAM attention mechanism is utilized for this purpose, instead of YOLOV4 for object detection, as our goal is to create a lightweight solution for individual fish recognition.
- While adding deformable convolution improves the effect, it is not particularly helpful for actual fish detection. The reason is that we artificially set a threshold value when the network returns a prediction result, and when the distance is larger than the threshold value, this predicted image is deleted from the list of alternatives, which does not affect the recognition accuracy.
- When recognizing the same fish, there is almost no difference in the effects of the two methods, which means that when the distance is less than the threshold value, the effect of the two methods on the recognition accuracy is equal.
4.4.3. Analysis of Experimental Results of Different Background Environment
4.4.4. Analysis of Experimental Results under Different Backbone Networks
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, S.; Li, J.; Tang, H.; Qian, R.; Lin, W. ATRW: A benchmark for Amur tiger re-identification in the wild. arXiv 2019, arXiv:1906.05586. [Google Scholar]
- Liu, C.; Zhang, R.; Guo, L. Part-pose guided amur tiger re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Xu, B.; Wang, W.; Guo, L.; Chen, G.; Li, Y.; Cao, Z.; Wu, S. CattleFaceNet: A cattle face identification approach based on RetinaFace and ArcFace loss. Comput. Electron. Agric. 2022, 193, 106675. [Google Scholar] [CrossRef]
- Li, W.; Ji, Z.; Wang, L.; Sun, C.; Yang, X. Automatic individual identification of Holstein dairy cows using tailhead images. Comput. Electron. Agric. 2017, 142, 622–631. [Google Scholar] [CrossRef]
- Ghosh, P.; Mustafi, S.; Mukherjee, K.; Dan, S.; Roy, K.; Mandal, S.N.; Banik, S. Image-Based Identification of Animal Breeds Using Deep Learning. In Deep Learning for Unmanned Systems; Springer: Cham, Switzerland, 2021; pp. 415–445. [Google Scholar] [CrossRef]
- Villon, S.; Chaumont, M.; Subsol, G.; Villéger, S.; Claverie, T.; Mouillot, D. Coral Reef Fish Detection and Recognition in Underwater Videos by Supervised Machine Learning: Comparison between Deep Learning and HOG+SVM Methods. In International Conference on Advanced Concepts for Intelligent Vision Systems; Springer: Cham, Switzerland, 2016; pp. 160–171. [Google Scholar] [CrossRef] [Green Version]
- Tamou, A.B.; Benzinou, A.; Nasreddine, K.; Ballihi, L. Transfer Learning with deep Convolutional Neural Network for Underwater Live Fish Recognition. In Proceedings of the 2018 IEEE International Conference on Image Processing, Applications and Systems (IPAS), Sophia Antipolis, France, 12–14 December 2018; pp. 204–209. [Google Scholar] [CrossRef]
- Blount, D.; Gero, S.; Van Oast, J.; Parham, J.; Kingen, C.; Scheiner, B.; Stere, T.; Fisher, M.; Minton, G.; Khan, C.; et al. Flukebook: An open-source AI platform for cetacean photo identification. Mamm. Biol. 2022, 1–19. [Google Scholar] [CrossRef]
- Zhao, Z.; Liu, Y.; Sun, X.; Liu, J.; Yang, X.; Zhou, C. Composited FishNet: Fish Detection and Species Recognition from Low-Quality Underwater Videos. IEEE Trans. Image Process. 2021, 30, 4719–4734. [Google Scholar] [CrossRef] [PubMed]
- Nixon, D. Computer vision neural network using YOLOv4 for underwater fish video detection in Roatan, Honduras. In Proceedings of the 2021 IEEE International Conference on Machine Learning and Applied Network Technologies (ICMLANT), Soyapango, El Salvador, 16–17 December 2021. [Google Scholar]
- Arzoumanian, Z.; Holmberg, J.; Norman, B. An astronomical pattern-matching algorithm for computer-aided identification of whale sharks Rhincodon typus. J. Appl. Ecol. 2005, 42, 999–1011. [Google Scholar] [CrossRef]
- Kaur, M.; Vijay, S. Underwater images quality improvement techniques for feature extraction based on comparative analysis for species classification. Multimedia Tools Appl. 2022, 81, 19445–19461. [Google Scholar] [CrossRef]
- Zhang, Z.; Du, X.; Jin, L.; Wang, S.; Wang, L.; Liu, X. Large-scale underwater fish recognition via deep adversarial learning. Knowl. Inf. Syst. 2022, 64, 353–379. [Google Scholar] [CrossRef]
- Deep, B.V.; Dash, R. Underwater fish species recognition using deep learning techniques. In Proceedings of the 2019 6th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 7–8 March 2019. [Google Scholar]
- Syreen, R.F.; Merriliance, K. Bi-Level Fish Detection Using novel Iterative Grouped Convolutional Neural Network. Des. Eng. 2021, 16652–16665. [Google Scholar]
- Villon, S.; Mouillot, D.; Chaumont, M.; Darling, E.S.; Subsol, G.; Claverie, T.; Villéger, S. A Deep learning method for accurate and fast identification of coral reef fishes in underwater images. Ecol. Inform. 2018, 48, 238–244. [Google Scholar] [CrossRef] [Green Version]
- Rauf, H.T.; Lali, M.I.U.; Zahoor, S.; Shah, S.Z.H.; Rehman, A.U.; Bukhari, S.A.C. Visual features based automated identification of fish species using deep convolutional neural networks. Comput. Electron. Agric. 2019, 167, 105075. [Google Scholar] [CrossRef]
- Xu, W.; Matzner, S. Underwater fish detection using deep learning for water power applications. In Proceedings of the 2018 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 12–14 December 2018. [Google Scholar]
- Petrellis, N. Fish morphological feature recognition based on deep learning techniques. In Proceedings of the 2021 10th International Conference on Modern Circuits and Systems Technologies (MOCAST), Thessaloniki, Greece, 5–7 July 2021. [Google Scholar]
- Rosales, M.A.; Palconit, M.G.B.; Almero, V.J.D.; Concepcion, R.S.; Magsumbol, J.-A.V.; Sybingco, E.; Bandala, A.A.; Dadios, E.P. Faster R-CNN based Fish Detector for Smart Aquaculture System. In Proceedings of the 2021 IEEE 13th International Conference on Humanoid, Nanotechnology, Information Technology, Communication and Control, Environment, and Management (HNICEM), Manila, Philippines, 28–30 November 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Jalal, A.; Salman, A.; Mian, A.; Shortis, M.; Shafait, F. Fish detection and species classification in underwater environments using deep learning with temporal information. Ecol. Inform. 2020, 57, 101088. [Google Scholar] [CrossRef]
- Hossain, E.; Alam, S.M.S.; Ali, A.A.; Amin, M.A. Fish activity tracking and species identification in underwater video. In Proceedings of the 2016 5th International Conference on Informatics, Electronics and Vision (ICIEV), Dhaka, Bangladesh, 13–14 May 2016; pp. 62–66. [Google Scholar] [CrossRef]
- Ben Tamou, A.; Benzinou, A.; Nasreddine, K. Targeted Data Augmentation and Hierarchical Classification with Deep Learning for Fish Species Identification in Underwater Images. J. Imaging 2022, 8, 214. [Google Scholar] [CrossRef] [PubMed]
- Ben Tamou, A.; Benzinou, A.; Nasreddine, K. Live Fish Species Classification in Underwater Images by Using Convolutional Neural Networks Based on Incremental Learning with Knowledge Distillation Loss. Mach. Learn. Knowl. Extr. 2022, 4, 753–767. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Chen, S.; Liu, Y.; Gao, X.; Han, Z. MobileFaceNets: Efficient CNNs for Accurate Real-Time Face Verification on Mobile Devices. In Chinese Conference on Biometric Recognition; Springer: Berlin/Heidelberg, Germany, 2018; pp. 428–438. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Misra, D. Mish: A self regularized non-monotonic neural activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Yang, M. Large-margin softmax loss for convolutional neural networks. arXiv 2016, arXiv:1612.02295. [Google Scholar]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. Supplementary material for ‘ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Duta, I.C.; Liu, L.; Zhu, F.; Shao, L. Improved residual networks for image and video recognition. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | YOLOV4-Tiny | YOLOV4-Tiny + SE | YOLOV4-Tiny + ECA | YOLOV4-Tiny + CBAM | YOLOV4 |
|---|---|---|---|---|---|
| mAP | 83.48 | 87.39 | 85.34 | 88.60 | 84.95 |
| Parameters | 5.87 M | 5.92 M | 5.87 M | 5.96 M | 63.9 M |
| Fish ID | Distance (Original Network) | Distance (Modification of Activation Function) | Distance (Modification of Activation Function + Average Pooling Layer) | Distance (Modification of Activation Function + Average Pooling Layer + Deformable Convolution) |
|---|---|---|---|---|
| 001403 001413 | 0.214 | 0.091 | 0.085 | 0.078 |
| 000102 000103 | 0.172 | 0.056 | 0.047 | 0.041 |
| 000401 000601 | 1.411 | 1.471 | 1.496 | 1.545 |
| 000103 000201 | 1.455 | 1.465 | 1.467 | 1.537 |
| 001804 001801 | 0.027 | 0.025 | 0.049 | 0.037 |
| 001804 002001 | 1.062 | 1.306 | 1.369 | 1.443 |
| Fish ID | Method 1 | Method 2 |
| 000601 000602 | 0.018 | 0.019 |
| 000103 000201 | 1.628 | 1.537 |
| 000401 000601 | 1.545 | 1.427 |
| Increased number of parameters | 2,359,296 | 0 |
| Category | Image | Resnet50 | Iresnet50 | Mobile- Facenet | MobilenetV2 | Our Method |
| The same fish distance | 001403 | 0.445 | 0.317 | 0.326 | 0.349 | 0.078 |
| 001413 | ||||||
| 000102 | 0.471 | 0.242 | 0.298 | 0.305 | 0.041 | |
| 000103 | ||||||
| The different fish distance | 001501 | 1.253 | 1.368 | 1.413 | 1.317 | 1.486 |
| 001601 | ||||||
| 001101 | 1.404 | 1.529 | 1.582 | 1.446 | 1.601 | |
| 001201 |
| Network | Parameter Quantity | Acc 1 |
|---|---|---|
| Resnet50 | 25.6 M | 91.94% |
| Iresnet50 | 25.56 M | 94.65% |
| Mobilefacenet | 0.99 M | 95.21% |
| MobileV2 | 3.4 M | 93.91% |
| Our method | 4.23 M | 97.8% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, J.; Wu, J.; Gao, C.; Jiang, Z. LIFRNet: A Novel Lightweight Individual Fish Recognition Method Based on Deformable Convolution and Edge Feature Learning. Agriculture 2022, 12, 1972. https://doi.org/10.3390/agriculture12121972
Yin J, Wu J, Gao C, Jiang Z. LIFRNet: A Novel Lightweight Individual Fish Recognition Method Based on Deformable Convolution and Edge Feature Learning. Agriculture. 2022; 12(12):1972. https://doi.org/10.3390/agriculture12121972
Chicago/Turabian StyleYin, Jianhao, Junfeng Wu, Chunqi Gao, and Zhongai Jiang. 2022. "LIFRNet: A Novel Lightweight Individual Fish Recognition Method Based on Deformable Convolution and Edge Feature Learning" Agriculture 12, no. 12: 1972. https://doi.org/10.3390/agriculture12121972
APA StyleYin, J., Wu, J., Gao, C., & Jiang, Z. (2022). LIFRNet: A Novel Lightweight Individual Fish Recognition Method Based on Deformable Convolution and Edge Feature Learning. Agriculture, 12(12), 1972. https://doi.org/10.3390/agriculture12121972