
Using Channel and Network Layer Pruning Based on Deep Learning for Real-Time Detection of Ginger Images

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
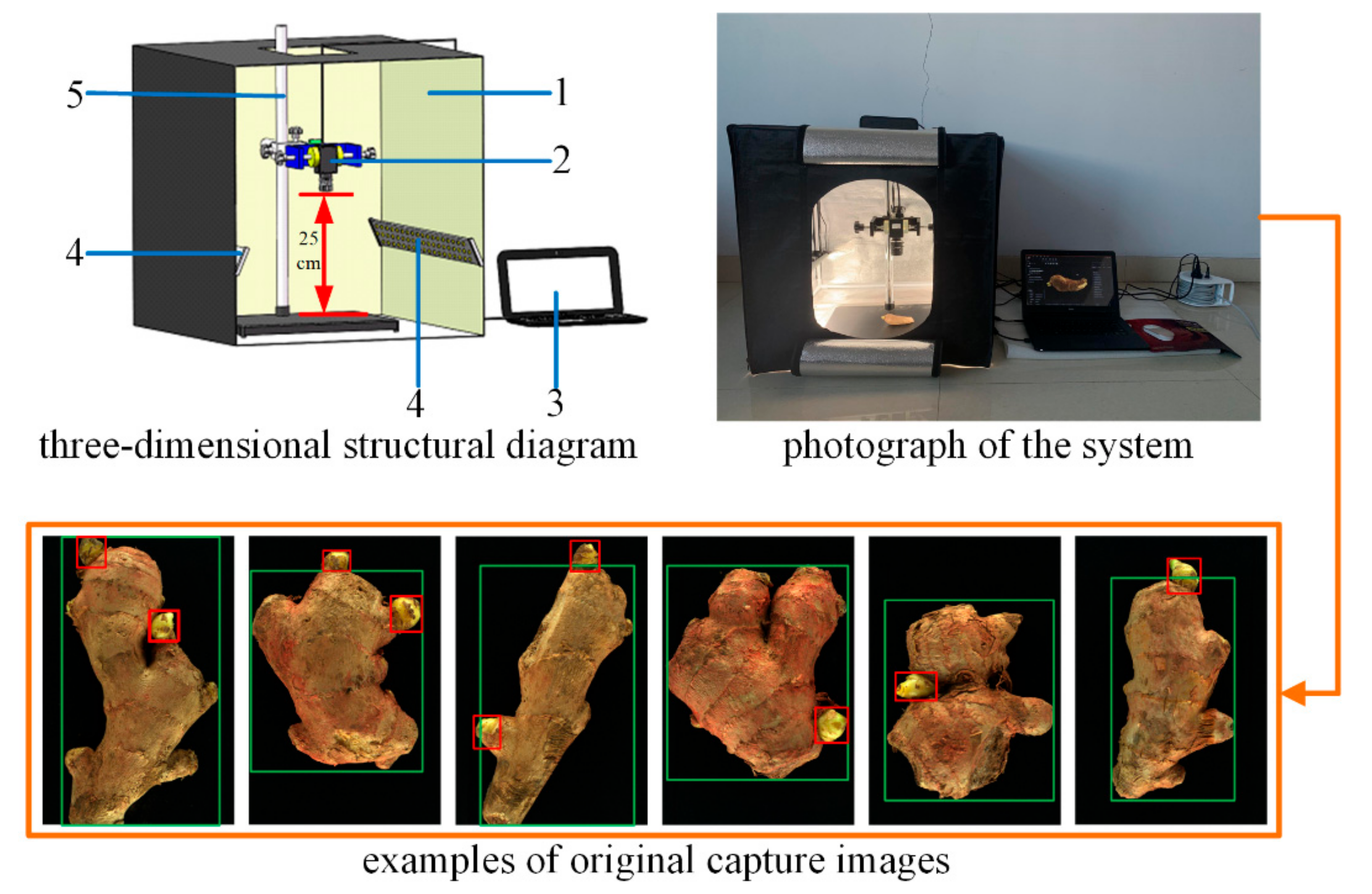
2.1. Image Acquisition System
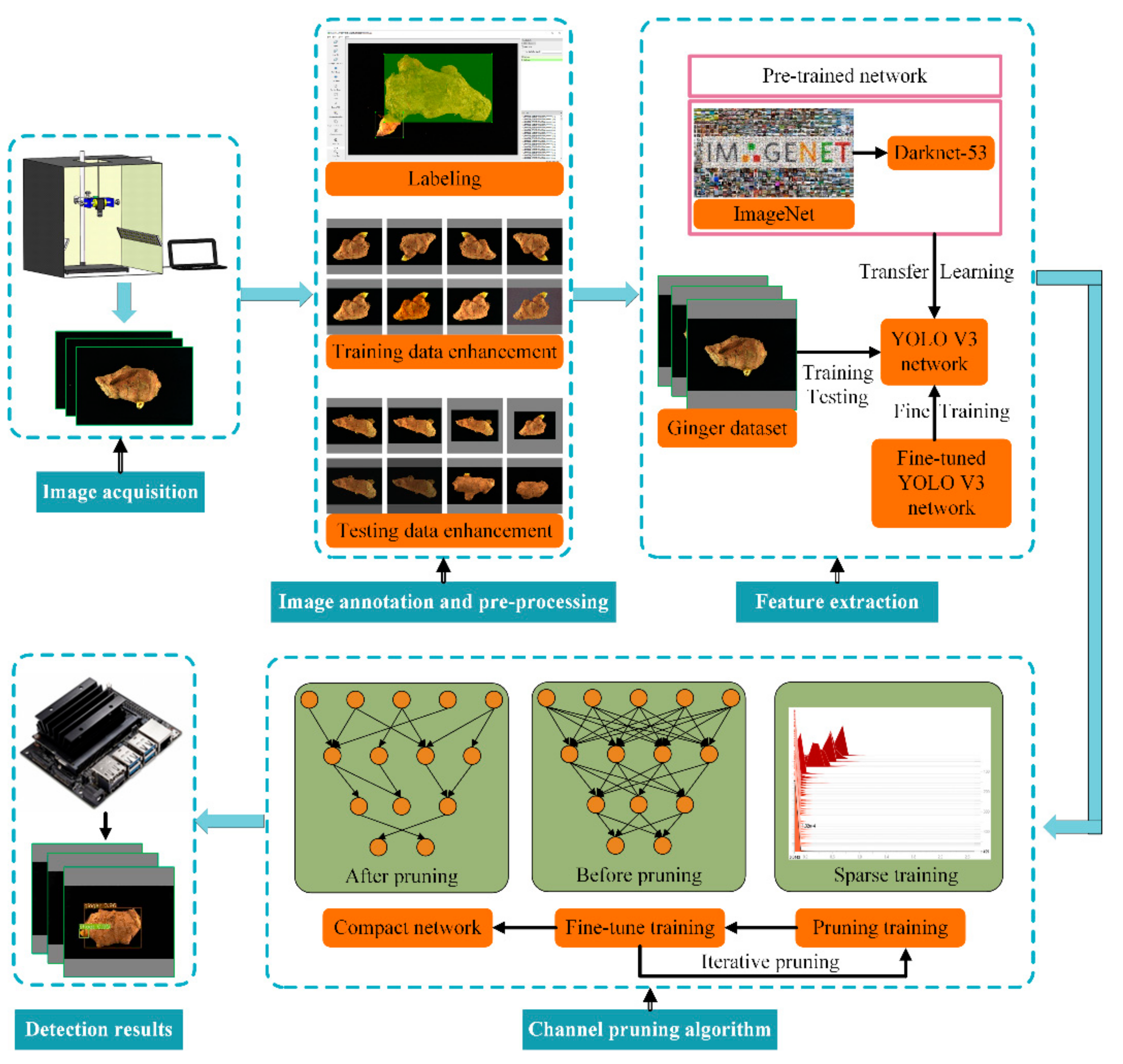
2.2. Overall Technical Route
2.3. Network Structure for Ginger Recognition Based on YOLO v3
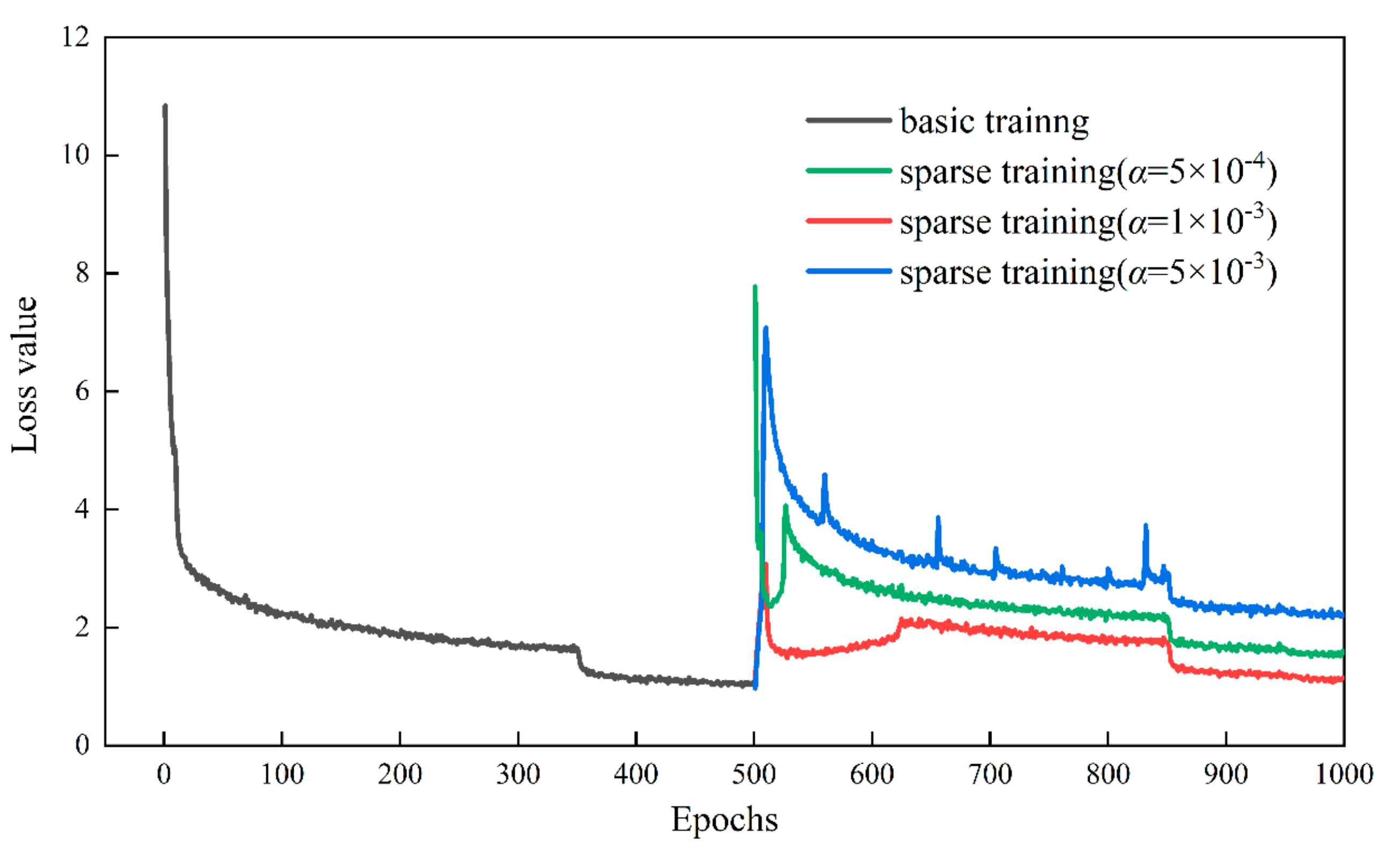
2.4. Sparse Training Based on Channel Importance Evaluation
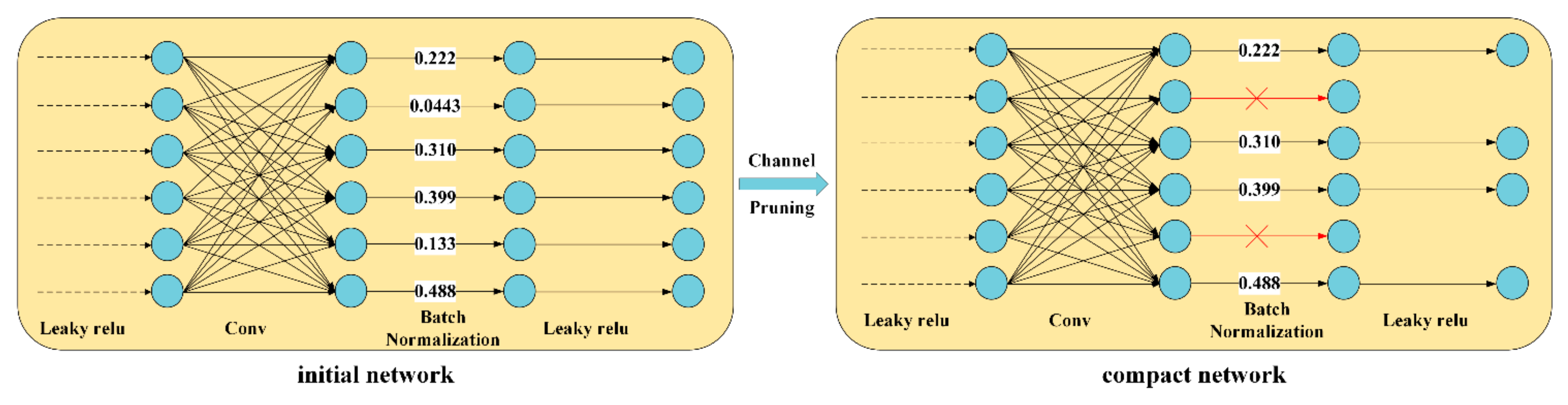
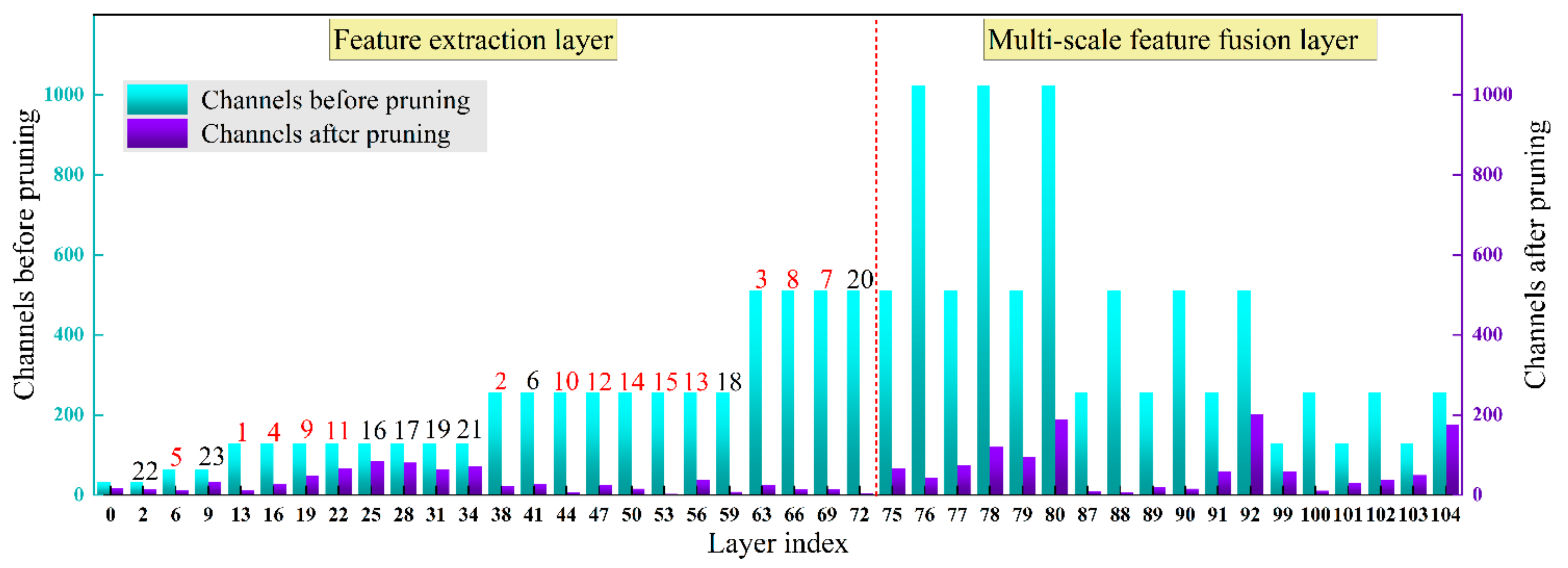
2.5. Channels and Network Layers Pruning Algorithms
2.6. Experimental Devices and Model Testing
2.7. Performance Evaluation Metrics
3. Results
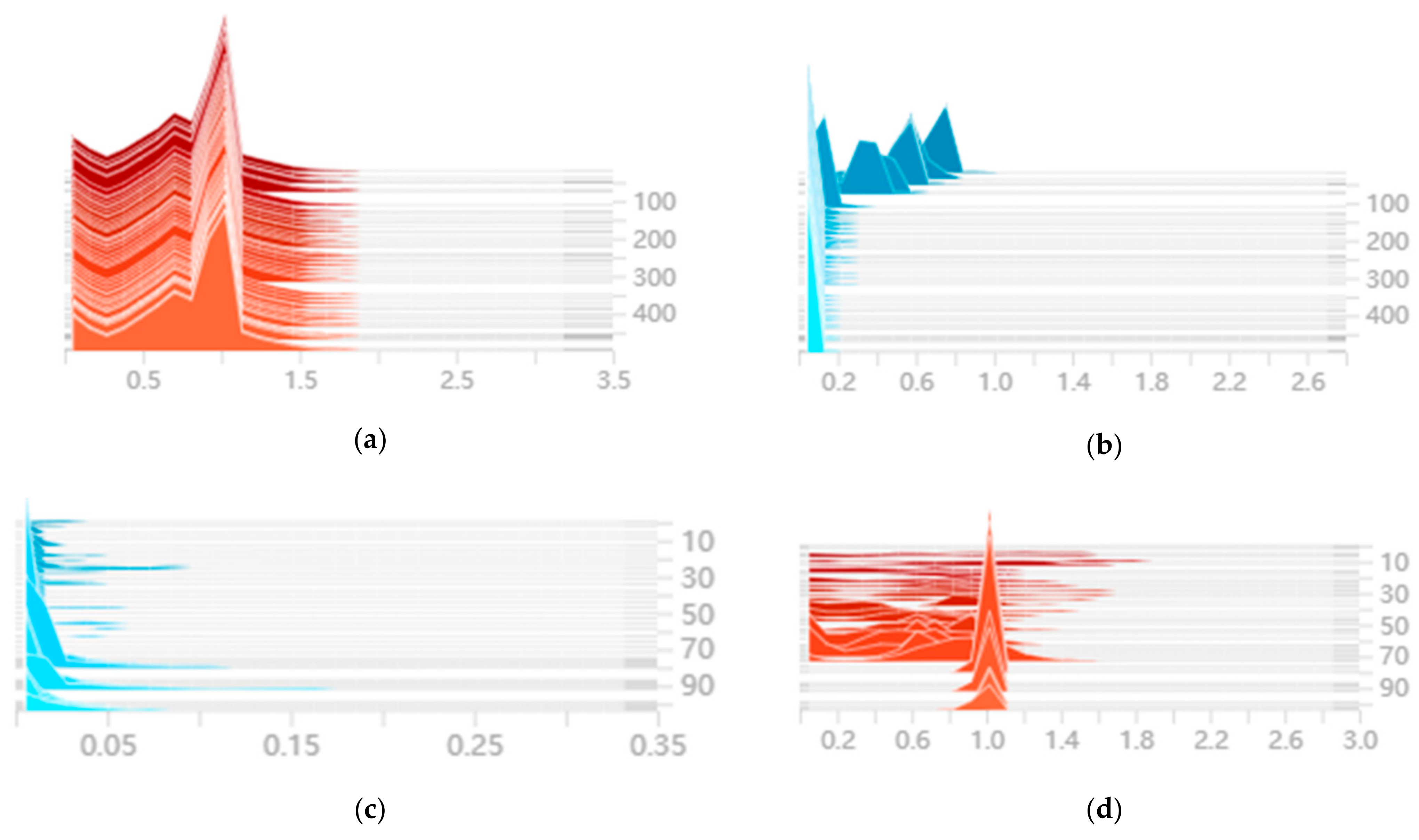
3.1. Parameter Selection for Sparse Training
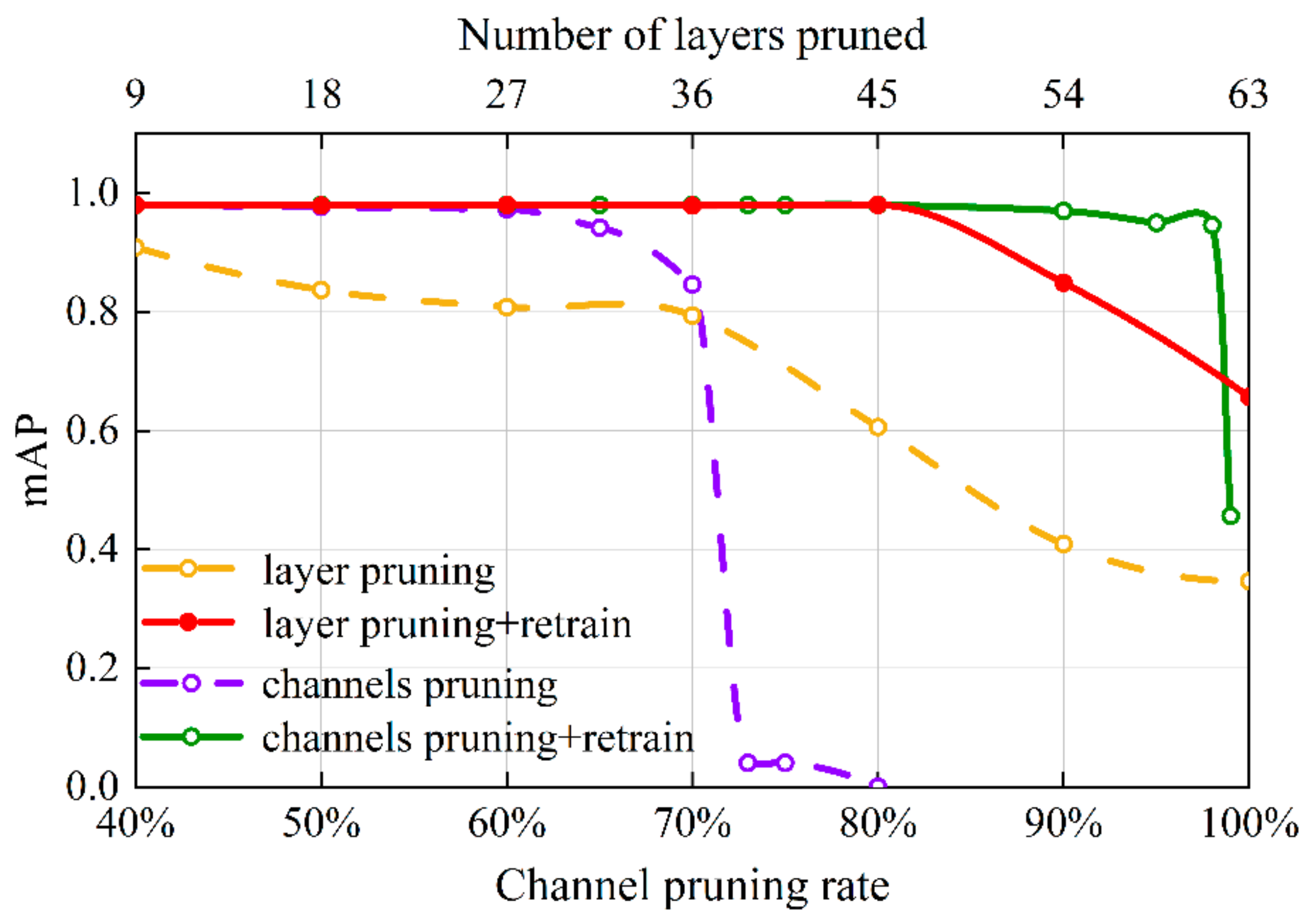
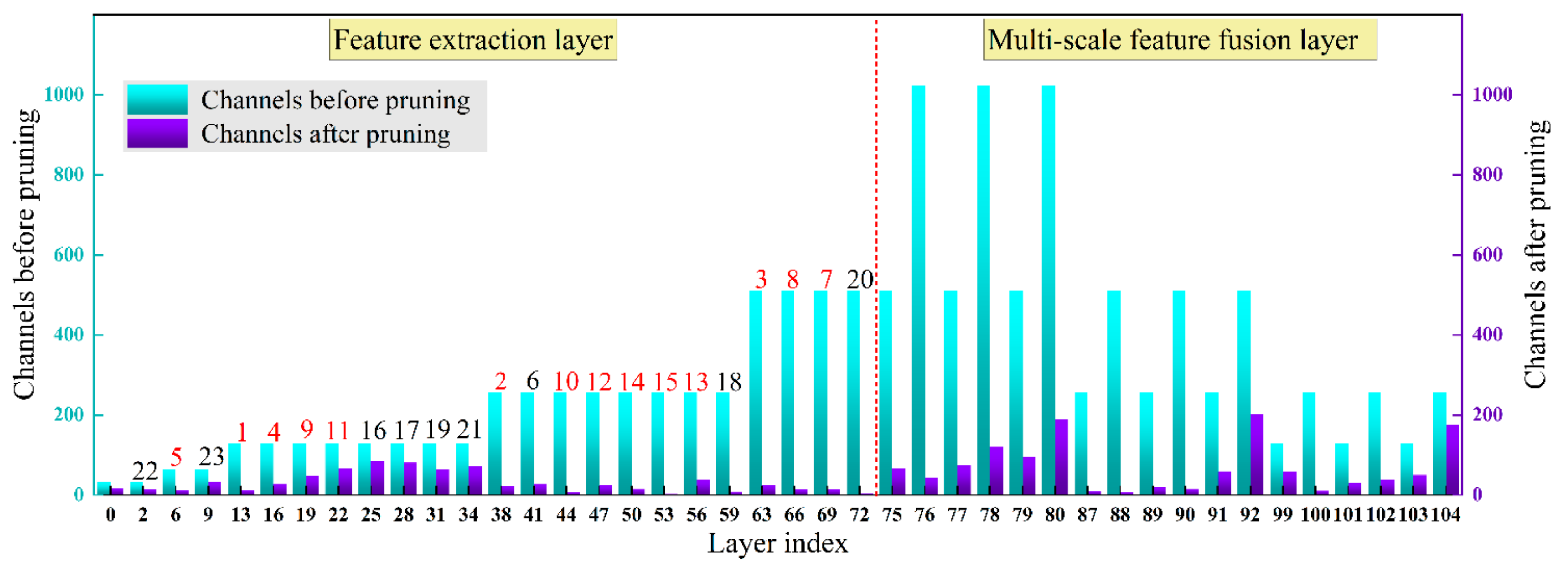
3.2. Parameter Selection for Pruning Process
3.3. Analysis of mAP Curves during the Training of a Ginger Recognition Mode
3.4. Parameter Selection for Sparse Training
3.5. Comparison of Different Object Detection Algorithms
4. Discussion
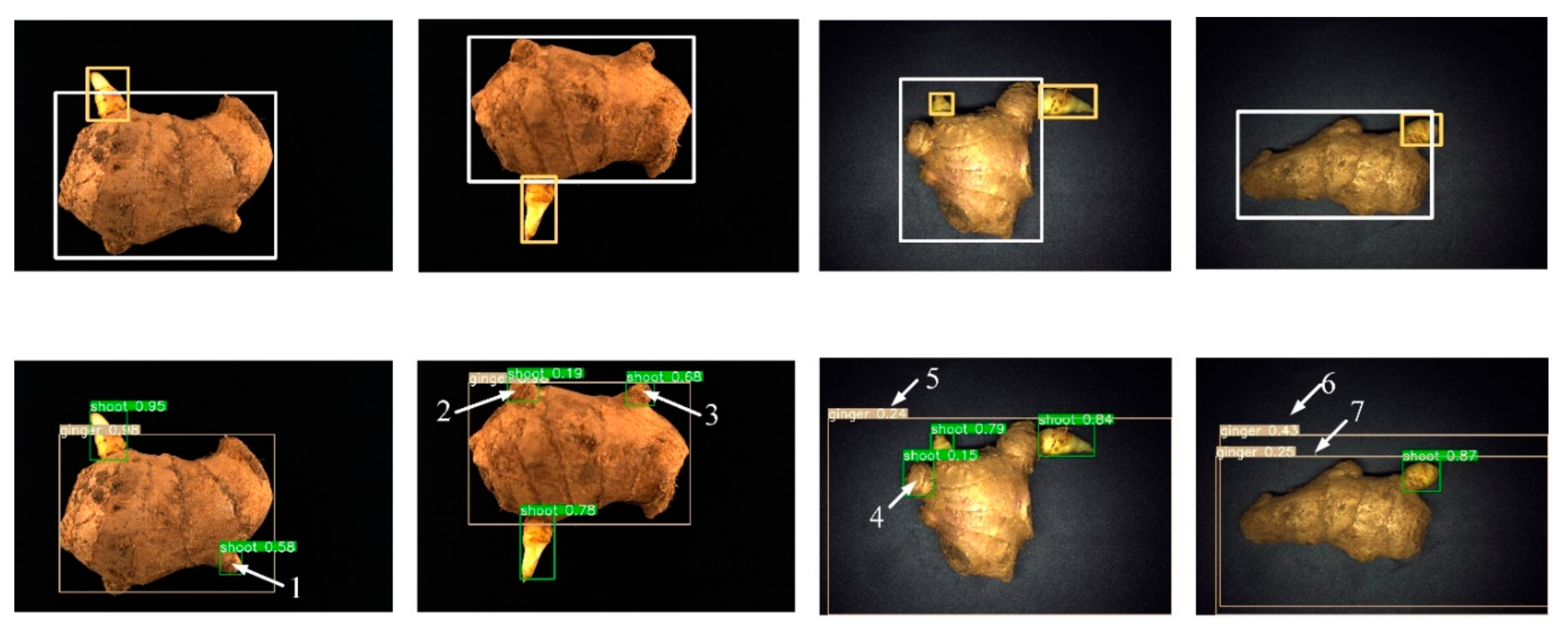
4.1. Analyzing Pre-Trained Network and the Shape of the Bounding Box
4.2. Analyzing False Recognition Results
4.3. Analysis of Practical Work Requirements
5. Conclusions
- Firstly, the ginger dataset is established, including image acquisition, data enhancement, and image annotation. Next, transfer learning and learning rate warm-up strategies are adopted to identify ginger shoots and seeds accurately. The experimental results reveal that the mAP and F1-score reach 98.1% and 95.4%, respectively, providing a reliable model compression basis.
- This study prunes the ginger recognition model’s redundant channels and network layers to reduce model parameters and inference time. First, the γ-values in the batch normalization layer are used to evaluate the channel importance, and the unimportant channels are pruned to accomplish the channel pruning. Then, the γ-values of the CBL module before the Shortcut layer are taken to evaluate the significance of the residual blocks, and the insignificant residual blocks are pruned to realize the pruning of the network layer.
- After channel and network layer pruning, the mAP and model size of the ginger recognition model reach 98.0% and 32.7 MB, respectively, which are reduced by 0.1% and 86.03% compared with the pre-pruning model. With the acceleration of the Tensor RT inference optimizer, the detection speed of a single 416 × 416 pixels ginger image on the Jetson Nano device can reach 20 frames·s−1. This study provides technical support for the future implementation of grasping ginger and adjusting the ginger shoot direction using end-effector devices.
- The detection of ginger images is only the first step in automated ginger seeding. In the future, the use of detection results for ginger grasping and ginger shoot orientation adjustment will be a hot research topic. Furthermore, our proposed pruning algorithm is not only beneficial for ginger detection, but it can also be applied to other crop detection tasks where computational resources are limited. Future work will focus on more efficient pruning methods and the acquisition of more ginger images under real-world operating conditions to further improve the accuracy of ginger detection.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, L.; Xun, K.; Li, X. Research status on breeding of ginger germplasm resource and prospect. China Veget. 2013, 16, 1–6. [Google Scholar]
- Hou, J.L.; Fang, L.F.; Wu, Y.Q.; Li, Y.H.; Xi, R. Rapid recognition and orientation determination of ginger shoots with deep learning. Trans. Chin. Soc. Agric. Eng. 2021, 37, 213–222. [Google Scholar]
- Chen, C.-H.; Kung, H.-Y.; Hwang, F.-J. Deep Learning Techniques for Agronomy Applications. Agronomy 2019, 9, 142. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Xiao, Z. Lychee Surface Defect Detection Based on Deep Convolutional Neural Networks with GAN-Based Data Augmentation. Agronomy 2021, 11, 1500. [Google Scholar] [CrossRef]
- Lu, C.-P.; Liaw, J.-J.; Wu, T.-C.; Hung, T.-F. Development of a Mushroom Growth Measurement System Applying Deep Learning for Image Recognition. Agronomy 2019, 9, 32. [Google Scholar] [CrossRef] [Green Version]
- Osman, Y.; Dennis, R.; Elgazzar, K. Yield Estimation and Visualization Solution for Precision Agriculture. Sensors 2021, 21, 6657. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.B.; Guo, R.H.; Li, M.; Chen, Y.; Li, G.Y. A review of computer vision technologies for plant phenotyping. Comput. Electron. Agric. 2020, 176, 105672. [Google Scholar] [CrossRef]
- Zhu, S.; Zhuo, J.; Huang, H.; Li, G. Wheat grain integrity image detection system based on CNN. Trans. Chin. Soc. Agric. Mach. 2020, 51, 36–42. [Google Scholar]
- Xiong, J.; Liu, Z.; Chen, S.; Liu, B.; Peng, H. Visual detection of green mangoes by an unmanned aerial vehicle in orchards based on a deep learning method. Biosyst. Eng. 2020, 194, 261–272. [Google Scholar] [CrossRef]
- Liang, C.; Xiong, J.; Zheng, Z.; Zhong, Z.; Li, Z. A visual detection method for nighttime litchi fruits and fruiting stems. Comput. Electron. Agric. 2020, 169, 105192. [Google Scholar] [CrossRef]
- Ahmad, A.; Saraswat, D.; Aggarwal, V.; Etienne, A.; Hancock, B. Performance of deep learning models for classifying and detecting common weeds in corn and soybean production systems. Comput. Electron. Agric. 2021, 184, 106081. [Google Scholar] [CrossRef]
- Yang, H.; Chen, L.; Chen, M.; Ma, Z.; Deng, F.; Li, M. Tender tea shoots recognition and positioning for picking robot using improved YOLO-v3 model. IEEE Access 2019, 7, 180998–181011. [Google Scholar] [CrossRef]
- Bazame, H.C.; Molin, J.P.; Althoff, D.; Martello, M. Detection, classification, and mapping of coffee fruits during harvest with computer vision. Comput. Electron. Agric. 2021, 183, 106066. [Google Scholar] [CrossRef]
- Hu, H.; Dai, B.; Shen, W.; Wei, X.; Sun, J.; Li, R.; Zhang, Y. Cow identification based on fusion of deep parts Features. Biosyst. Eng. 2020, 192, 245–256. [Google Scholar] [CrossRef]
- Shen, W.; Hu, H.; Dai, B.; Wei, X.; Sun, Y. Individual identification of dairy cows based on convolutional neural networks. Multimed. Tools Appl. 2020, 79, 14711–14724. [Google Scholar] [CrossRef]
- Wu, D.; Wu, Q.; Yin, X.; Jiang, B.; Song, H. Lameness detection of dairy cows based on the YOLOv3 deep learning algorithm and a relative step size characteristic vector. Biosyst. Eng. 2020, 189, 150–163. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-Time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Kuznetsova, A.; Maleva, T.; Soloviev, V. Using YOLOv3 Algorithm with Pre-and Post-Processing for Apple Detection in Fruit-Harvesting Robot. Agronomy 2020, 10, 1016. [Google Scholar] [CrossRef]
- Koirala, A.; Walsh, K.B.; Wang, Z.; Anderson, N. Deep Learning for Mango (Mangifera indica) Panicle Stage Classification. Agronomy 2020, 10, 143. [Google Scholar] [CrossRef] [Green Version]
- Qi, C.; Nyalala, I.; Chen, K. Detecting the Early Flowering Stage of Tea Chrysanthemum Using the F-YOLO Model. Agronomy 2021, 11, 834. [Google Scholar] [CrossRef]
- Han, S.; Pool, J.; Tran, J.; Dally, W. Learning both weights and connections for efficient neural networks. In Proceedings of the 2015 Twenty-Ninth Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015; pp. 1135–1143. [Google Scholar]
- Anwar, S.; Hwang, K.; Sung, W. Structured pruning of deep convolutional neural networks. ACM J. Emerg. Technol. Comput. Syst. 2015, 13, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Iida, M.; Suyama, T.; Suguri, M.; Masuda, R. Implementation of deep-Learning algorithm for obstacle detection and collision avoidance for robotic harvester. Comput. Electron. Agric. 2020, 174, 105499. [Google Scholar] [CrossRef]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning efficient convolutional networks through network slimming. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2755–2763. [Google Scholar]
- Prakosa, S.W.; Leu, J.S.; Chen, Z. Improving the accuracy of pruned network using knowledge distillation. Pattern Anal. Appl. 2020, 4, 1–12. [Google Scholar] [CrossRef]
- Wen, W.; Wu, C.; Wang, Y.; Chen, Y.; Li, H. Learning structured sparsity in deep neural networks. In Proceedings of the 2016 Thirtieth Conference and Workshop on Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016; pp. 2074–2082. [Google Scholar]
- Wu, D.; Lyu, S.; Jiang, M.; Song, H. Using channel pruning-based YOLO v4 deep learning algorithm for the real-time and accurate detection of apple flowers in natural environments. Comput. Electron. Agric. 2020, 178, 105742. [Google Scholar] [CrossRef]
- Shi, R.; Li, T.; Yamaguchi, Y. An attribution-based pruning method for real-time mango detection with YOLO network. Comput. Electron. Agric. 2020, 169, 105214. [Google Scholar] [CrossRef]
- Ni, J.; Li, J.; Deng, L.; Han, Z. Intelligent detection of appearance quality of carrot grade using knowledge distillation. Trans. Chin. Soc. Agric. Eng. 2020, 36, 181–187. [Google Scholar]
- Cao, S.; Zhao, D.; Liu, X.; Sun, Y. Real-time robust detector for underwater live crabs based on deep learning. Comput. Electron. Agric. 2020, 172, 105339. [Google Scholar] [CrossRef]
- Jordao, A.; Lie, M.; Schwartz, W.R. Discriminative layer pruning for convolutional neural networks. IEEE J. Sel. Top. Signal. Process. 2020, 14, 828–837. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Buslaev, A.; Parinov, A.; Khvedchenya, E.; Iglovikov, V.I.; Kalinin, A.A. Albumentations: Fast and flexible image augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef] [Green Version]
- Feng, A.; Zhou, J.; Vories, E.; Sudduth, K.A. Evaluation of cotton emergence using UAV-based imagery and deep learning. Comput. Electron. Agric. 2020, 177, 105711. [Google Scholar] [CrossRef]
- Kaya, A.; Keceli, A.S.; Catal, C.; Yalic, H.Y.; Temucin, H.; Tekinerdogan, B. Analysis of transfer learning for deep neural network based plant classification models. Comput. Electron. Agric. 2019, 158, 20–29. [Google Scholar] [CrossRef]
- Wen, L.; Gao, L.; Dong, Y.; Zhu, Z. A negative correlation ensemble transfer learning method for fault diagnosis based on convolutional neural network. Math. Biosci. Eng. 2019, 16, 3311–3330. [Google Scholar] [CrossRef] [PubMed]
- Cao, S.; Song, B. Visual attentional-Driven deep learning method for flower recognition. Biosci. Eng. 2021, 18, 1981–1991. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and better learning for bounding box regression. In Proceedings of the 35th AAAI Conference on Artificial Intelligence (AAAI) 2020, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Zheng, C.; Yang, X.; Zhu, X.; Chen, C.; Wang, L.; Tu, S.; Yang, A.; Xue, Y. Automatic posture change analysis of lactating sows by action localisation and tube optimisation from untrimmed depth videos. Biosyst. Eng. 2020, 194, 227–250. [Google Scholar] [CrossRef]
- Ma, N.; Zhang, X.; Zheng, H.; Sun, J. Shufflenet v2: Practical guidelines for efficient CNN architecture design. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 122–138. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobilenetV3. In Proceedings of the 2019 International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More features from cheap operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1577–1586. [Google Scholar]
- Elgendy, M.; Sik-Lanyi, C.; Kelemen, A. A novel marker detection system for people with visual impairment using the improved tiny-yolov3 model. Comput. Meth. Programs Biomed. 2021, 205, 106112. [Google Scholar] [CrossRef]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? In Proceedings of the 28th Conference on Neural Information Processing Systems (ICONIP), Montreal, QC, Canada, 8–13 December 2014; pp. 3320–3328. [Google Scholar]
- He, Z.; Xiong, J.; Chen, S.; Li, Z.; Chen, S.; Zhong, Z.; Yang, Z. A method of green citrus detection based on a deep bounding box regression forest. Biosyst. Eng. 2020, 193, 206–215. [Google Scholar] [CrossRef]
- Liu, G.; Nouaze, J.C.; Touko Mbouembe, P.L.; Kim, J.H. YOLO-Tomato: A Robust Algorithm for Tomato Detection Based on YOLOv3. Sensors 2020, 20, 2145. [Google Scholar] [CrossRef] [Green Version]
- Zhao, G.; Quan, L.; Li, H.; Feng, H.; Li, S.; Zhang, S.; Liu, R. Real-Time recognition system of soybean seed full-Surface defects based on deep learning. Comput. Electron. Agric. 2021, 187, 106230. [Google Scholar] [CrossRef]
- Amin, J.; Sharif, M.A.; Anjum, M.; Siddiqa, A.; Kadry, S.; Nam, Y.; Raza, M. 3d semantic deep learning networks for leukemia detection. CMC-Comput. Mat. Contin. 2021, 69, 785–799. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| YOLO v3 | Number of Network Layers | Type | Input Size |
|---|---|---|---|
| Darknet-53 without FC layer | 0 | CBL | 416 × 416 × 3 |
| 1~4 | Res | 416 × 416 × 32 | |
| 5~11 | 2Res | 208 × 208 × 64 | |
| 12~36 | 8Res | 104 × 104 × 128 | |
| 37~61 | 8Res | 52 × 52 × 256 | |
| 62~74 | 4Res | 26 × 26 × 512 | |
| Feature fusion layer and output layer | 75~80 | 6CBL | 13 × 13 × 521 |
| 81~82 | Conv + YOLO | 13 × 13 × 1024 | |
| 83 | Route | 13 × 13 × 521 | |
| 84 | CBL | 13 × 13 × 521 | |
| 85 | Up-sample | 13 × 13 × 256 | |
| 86 | Route | 26 × 26 × (256 + 512) | |
| 87~92 | 6CBL | 26 × 26 × 768 | |
| 93~94 | Conv + YOLO | 26 × 26 × 512 | |
| 95 | Route | 26 × 26 × 256 | |
| 96 | CBL | 26 × 26 × 256 | |
| 97 | Up-sample | 13 × 13 × 128 | |
| 98 | Route | 52 × 52 × (128 + 256) | |
| 99~104 | 6CBL | 52 × 52 × 384 | |
| 105~106 | Conv + YOLO | 52 × 52 × 128 |
| Algorithms | Backbone | P/% | R/% | mAP/% | F1-Score/% | Model Size/MB | Detection Speed/ Frame·s−1 |
|---|---|---|---|---|---|---|---|
| YOLO v3 | ShuffleNetv2 | 83.3 | 98.0 | 95.9 | 89.4 | 20.5 | 176 |
| MobileNetv3 | 85.1 | 97.6 | 96.9 | 90.4 | 95.4 | 200 | |
| Ghost-Net | 85.1 | 97.7 | 97.0 | 90.5 | 94.1 | 83 | |
| Darknet-19 | 88.8 | 96.3 | 97.3 | 92.3 | 69.4 | 231 | |
| Darknet-53 | 93.7 | 97.3 | 98.1 | 95.4 | 234 | 100 | |
| YOLO v4 | CSP-Darknet | 87.9 | 97.6 | 97.2 | 92.2 | 256.2 | 74 |
| Our model (test set A) | 90.8 | 98.2 | 98.0 | 94.2 | 32.7 | 185 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, L.; Wu, Y.; Li, Y.; Guo, H.; Zhang, H.; Wang, X.; Xi, R.; Hou, J. Using Channel and Network Layer Pruning Based on Deep Learning for Real-Time Detection of Ginger Images. Agriculture 2021, 11, 1190. https://doi.org/10.3390/agriculture11121190
Fang L, Wu Y, Li Y, Guo H, Zhang H, Wang X, Xi R, Hou J. Using Channel and Network Layer Pruning Based on Deep Learning for Real-Time Detection of Ginger Images. Agriculture. 2021; 11(12):1190. https://doi.org/10.3390/agriculture11121190
Chicago/Turabian StyleFang, Lifa, Yanqiang Wu, Yuhua Li, Hongen Guo, Hua Zhang, Xiaoyu Wang, Rui Xi, and Jialin Hou. 2021. "Using Channel and Network Layer Pruning Based on Deep Learning for Real-Time Detection of Ginger Images" Agriculture 11, no. 12: 1190. https://doi.org/10.3390/agriculture11121190
APA StyleFang, L., Wu, Y., Li, Y., Guo, H., Zhang, H., Wang, X., Xi, R., & Hou, J. (2021). Using Channel and Network Layer Pruning Based on Deep Learning for Real-Time Detection of Ginger Images. Agriculture, 11(12), 1190. https://doi.org/10.3390/agriculture11121190