1. Introduction
Grapes are one of the most favorite fruits in the world. The grape industry of China has the characteristics of a wide planting area, high yield, and large demand for freshness. Statistics show that China’s table grape production has steadily ranked the first in the world since 2011. By 2016, the area of viticulture has also become the world’s first, with a total table grape production of 9 million tons, accounting for 50% of the world’s production [
1].
Usually, the harvested grapes are used for winemaking or fresh food. For grapes used for winemaking, there is no need to consider the shedding of grape berries and the damage to the clusters during the picking process, which is more suitable for non-selective mechanized picking methods. Among them, the most mature application is to use the principle of vibration to transmit vibration to the grape berries through the vines, so that the berries can undergo multiple instantaneous changes in direction and overcome the connection with the fruit stem to achieve separation [
2,
3]. For the picking of table grapes, it is necessary to consider that there may be fruit loss and berries damaged during the picking process while completing the harvest of all mature grapes in the vineyard. Therefore, the large-scale non-selective mechanical picking method is not suitable for the harvest of table grapes. Usually, the harvesting of table grapes is often done manually, which is a labor-intensive and time-consuming work [
4]. However, the shortage of labor, the aging of the population, and the declining birthrate are not only the bottleneck encountered in the development of agriculture but also one of the difficulties faced by the development of all labor-intensive industries in the world. With the development of robot technology, the best strategy to solve this problem is to use robots instead of farmers to harvest table grapes manually.
For harvesting robots, fast accurate identification and positioning of the target fruit is the prerequisite and key technical step for successfully picking the fruit. Machine vision is one of the most effective methods and has been investigated extensively for fruit detection. In recent decades, many scholars from all over the world have proposed a large number of detection algorithms for different types of fruits, such as citrus [
5,
6], apples [
7,
8], and kiwifruit [
9,
10], and achieved remarkable results.
At present, the research on grape recognition mainly focuses on two aspects: (1) to classify and identify the grape varieties; (2) to segment and locate the grape in the image. EI-Mashharawi et al. [
11] carried out the research on grape variety recognition, and a machine learning-based method was proposed by them. A total of 6 varieties (each variety has different colors: black, crimson, yellow, dark blue, green, and pink), 4565 images (70% of the image for training and 30% for validation) were used for the AlexNet network. In order to reduce the degree of overfitting, image preprocessing technology and data enlargement technology were used. Finally, the trained model could achieve 100% accuracy for the classification of grape varieties. Bogdan Franczyk et al. [
12] developed a model which is a combination of deep learning ResNet classifier model with multi-layer perceptron for grape varieties identification. A well-known benchmark dataset named WGISD which provided the instances from five different grape varieties taken from the field was used for training and testing on the developed model. The test results showed that the classification accuracy of the model for different grape varieties can reach 99%. M. Türkoğlu et al. [
13] proposed a multi-class support vector machine classifier based on 9 different characteristics of grape leaves with a classification accuracy of 90.7% to classify grape tree species. In order to improve the classification performance, the preprocessing stage involves gray tone dial, median filtering, threshold holding, and morphological logical processes.
Compared with the identification of grape varieties, the accurate segmentation of grape clusters has also attracted the attention of many scholars and has been widely studied. Zernike moments and color information were applied by Chamelat et al. [
14] to develop an SVM classifier for detecting red grapes successfully but got a disappointing result for white grapes with less than 50% of correct classification. Reis et al. [
15] proposed a system for detecting bunches of grapes in color images, which could achieve 97% and 91% correct classifications for red and white grapes, respectively. The system mainly includes the following three steps to realize the detecting and locating of grape: color mapping, morphological dilation, black areas, and stem detection. In [
16] a detector named DeepGrapes was proposed to detect white grapes for low-resolution color photos. In order to greatly reduce the final number of weights of the detector, weave layers were used to replace the generally used combined layers in the classifier. The detector could reach an accuracy of 96.53% on the dataset created by the author. Liu et al. [
17] proposed an algorithm that utilized color and texture information as the feature to train an SVM classifier. The algorithm mainly includes three steps: image preprocessing, SVM classifier training, and image segmentation in the test set. Image preprocessing includes Otsu threshold segmentation, denoising, shape filtering, and further methods, which are not only used for the training set but also applied to the test set images. Experiments results demonstrate that the classifier could reach an accuracy of 88% and recall of 91.6% on two red grape datasets (Shiraz and Cabernet Sauvignon). In 2015, a Fuzzy C-Means Clustering method with an accuracy of 90.33% was proposed by [
18]. The H-channel of the HSV image is clustered by the Fuzzy C-Means Clustering algorithm to segment grape objects. The initial clustering center of the Fuzzy C-Means Clustering was optimized by the artificial bee colony algorithm to accelerate clustering speed and reduce iteration steps. In the next year, another paper by the same research team applied the AdaBoost framework to construct four weaker classifiers into a strong classifier to significantly improve the detection performance. In the test stage, after the test image was processed by the classifier, the region threshold method and morphology filtering were used to eliminate noise, and the final average detection accuracy was 96.56%.
As mentioned above, significant progress has been made in the research related to the identification of grape varieties and the segmentation of the grape cluster. However, for a grape picking robot, its work scenario is often as: the farmer places it in a vineyard, and then the robot picks the grapes in the area by itself. Generally, grape varieties in a single region are often the same, and varieties in different regions may be different. Therefore, if the vision system of the robot could work like human eyes, then it could segment grape clusters easily no matter what varieties (with different colors or shapes) it is. Consequently, the robot operator does not need to switch different recognition algorithms for different varieties of grapes, which will greatly enhance the robot’s intelligence and simplify its use. However, it is a pity that there is no relevant research on the above-mentioned issues has been found.
Faced with such a thorny problem that an algorithm could segment the cluster region of different varieties of grapes. Generally, two methods are mainly considered, i.e., conventional methods and deep learning-related methods. Conventional procedures for machine vision usually include image pre-processing, segmentation, feature extraction, and classification. The selection of handcrafted features has a crucial impact on the performance of conventional methods. However, handcrafted features are usually extracted from color, shape, spectrum, and texture which may be influenced by varying lighting conditions, occlusion or overlapping, and different growth stages of plants. The unstable handcrafted features may lead to poor robustness and low generalization capabilities of conventional methods. To be more important, there are hundreds of different varieties of grapes and usually have different colors, shapes, and textures. It is almost impossible to extract ideal handcrafted features based on color, shape, and texture to segment cluster accurately with different grapes varieties. Besides, the extraction of handcrafted features for so many different varieties of grapes is time-consuming work. Therefore, it seems that the conventional methods are not suited for the segmentation of grapes with different varieties.
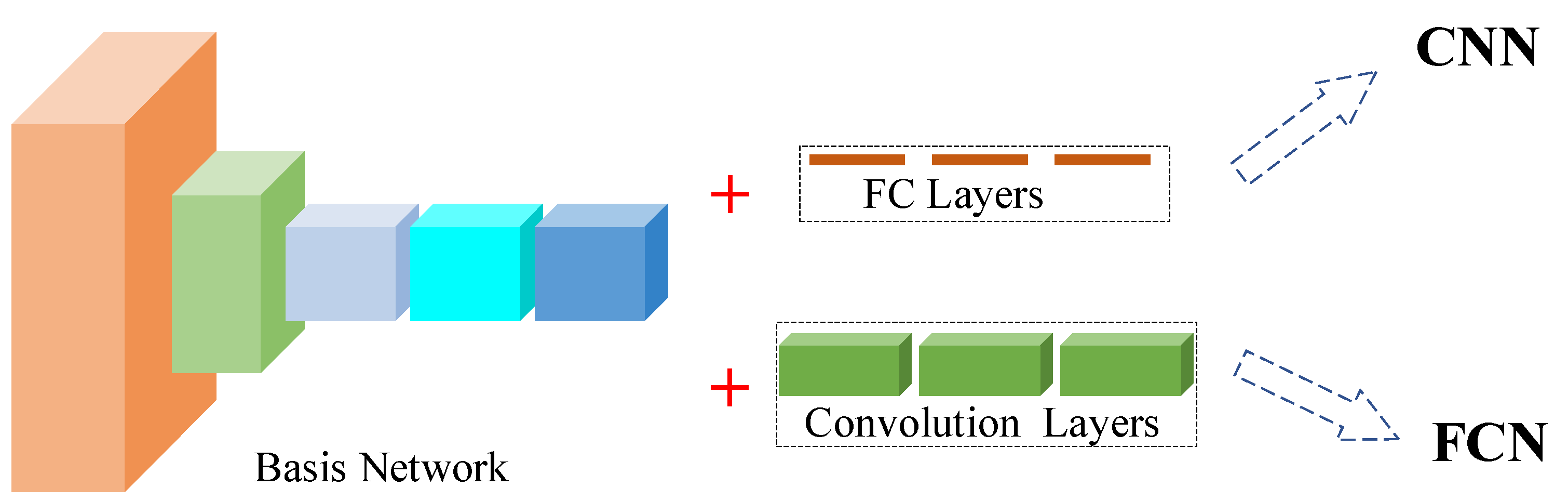
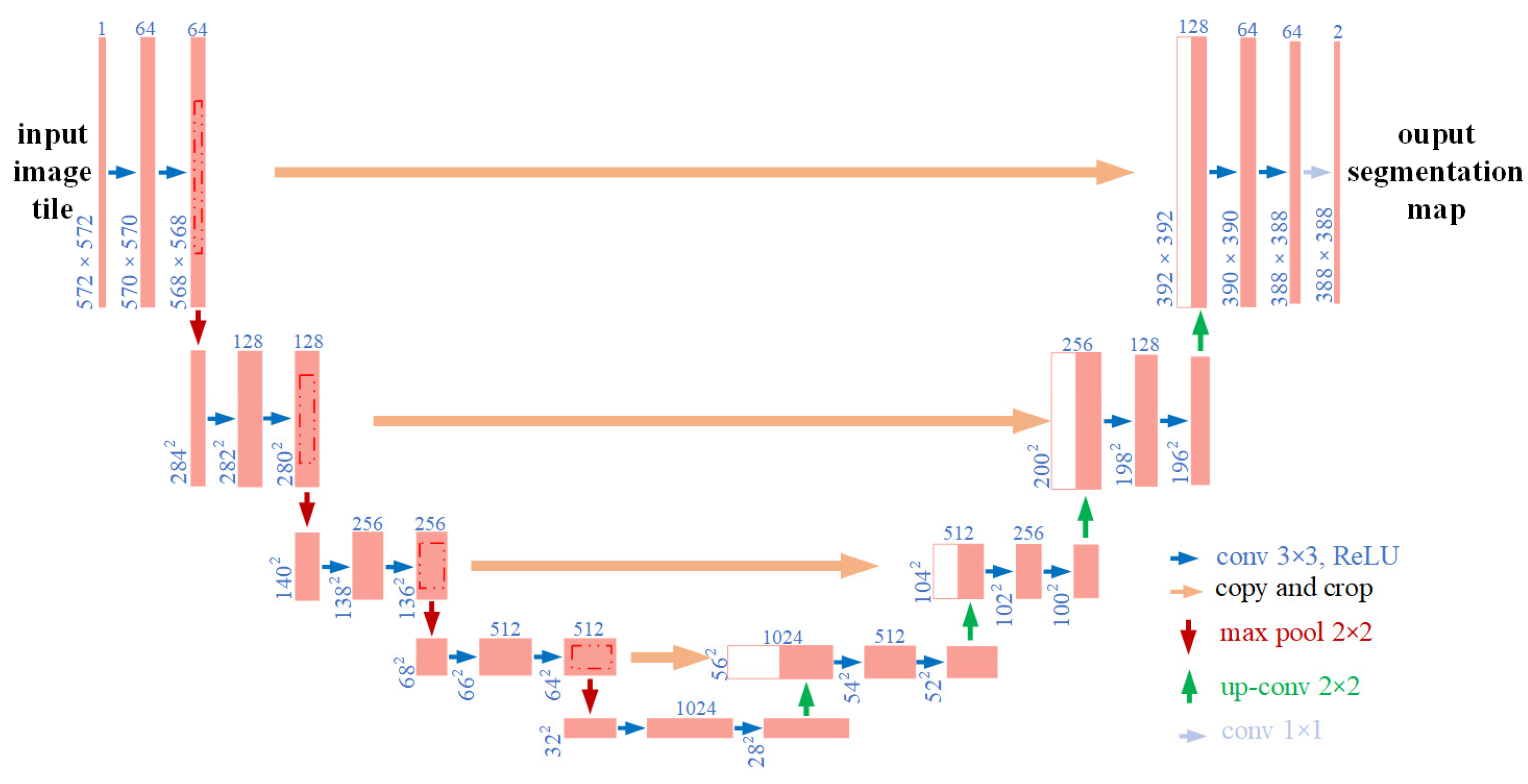
Compared with conventional machine learning methods, deep learning can automatically learn the hierarchical features expressed hidden deep into the images, avoiding the tedious procedures to extract and optimize handcrafted features [
19,
20]. Deep learning has been investigated extensively for image processing and applied in agriculture. Networks such as AlexNet and Inception (GoogLeNet) are often used for classification applications such as plant diseases and fruit varieties. Networks such as Mask R-CNN and YOLO are mainly used for target detection and have achieved good effect in the detection applications of mango [
21,
22], strawberry [
23], and apple [
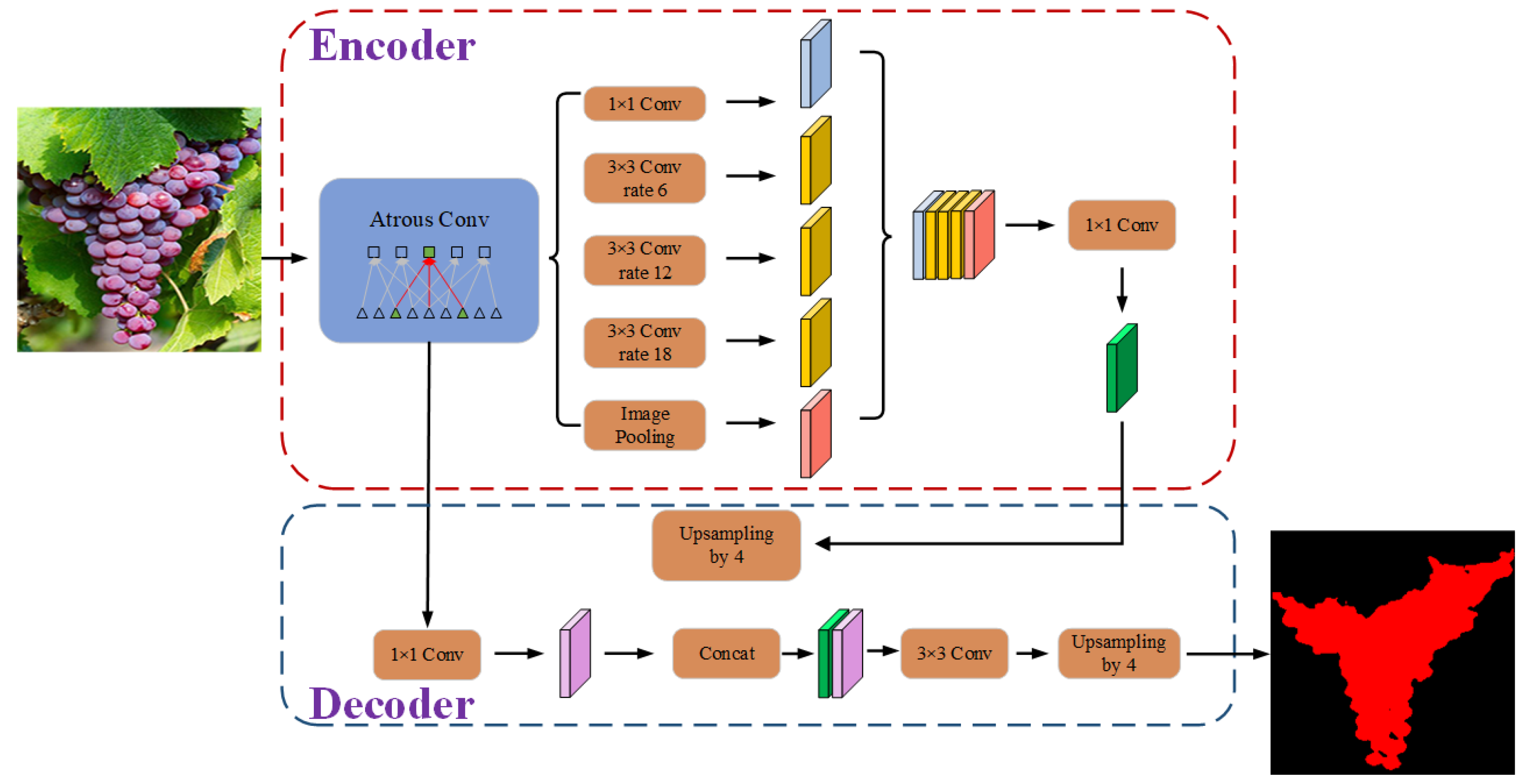
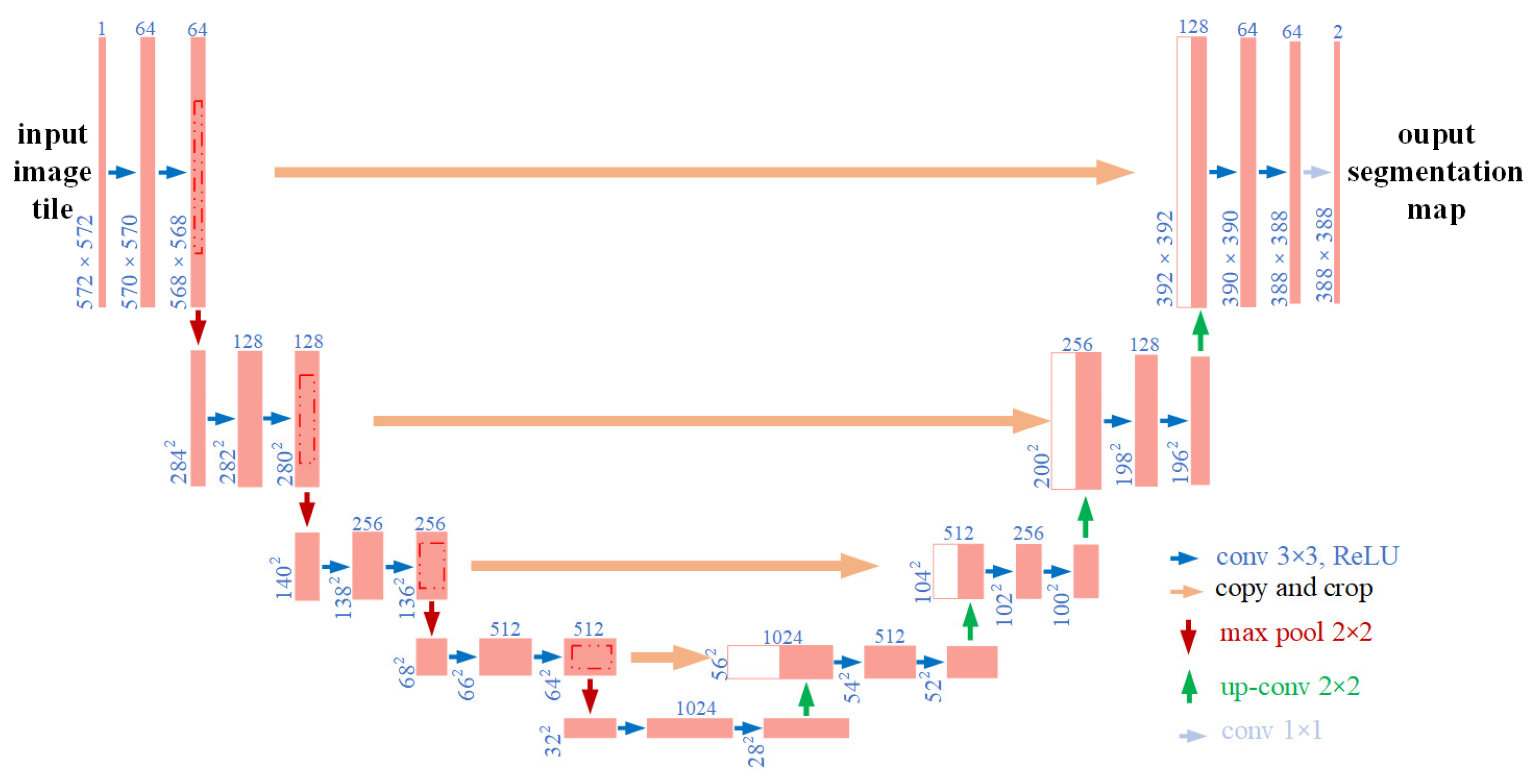
24]. Compared with classification and target detection, semantic segmentation can achieve pixel-level segmentation of targets, which is more suitable for our research goals. Commonly used semantic segmentation networks include the DeepLab series, U-Net, FCN, etc.
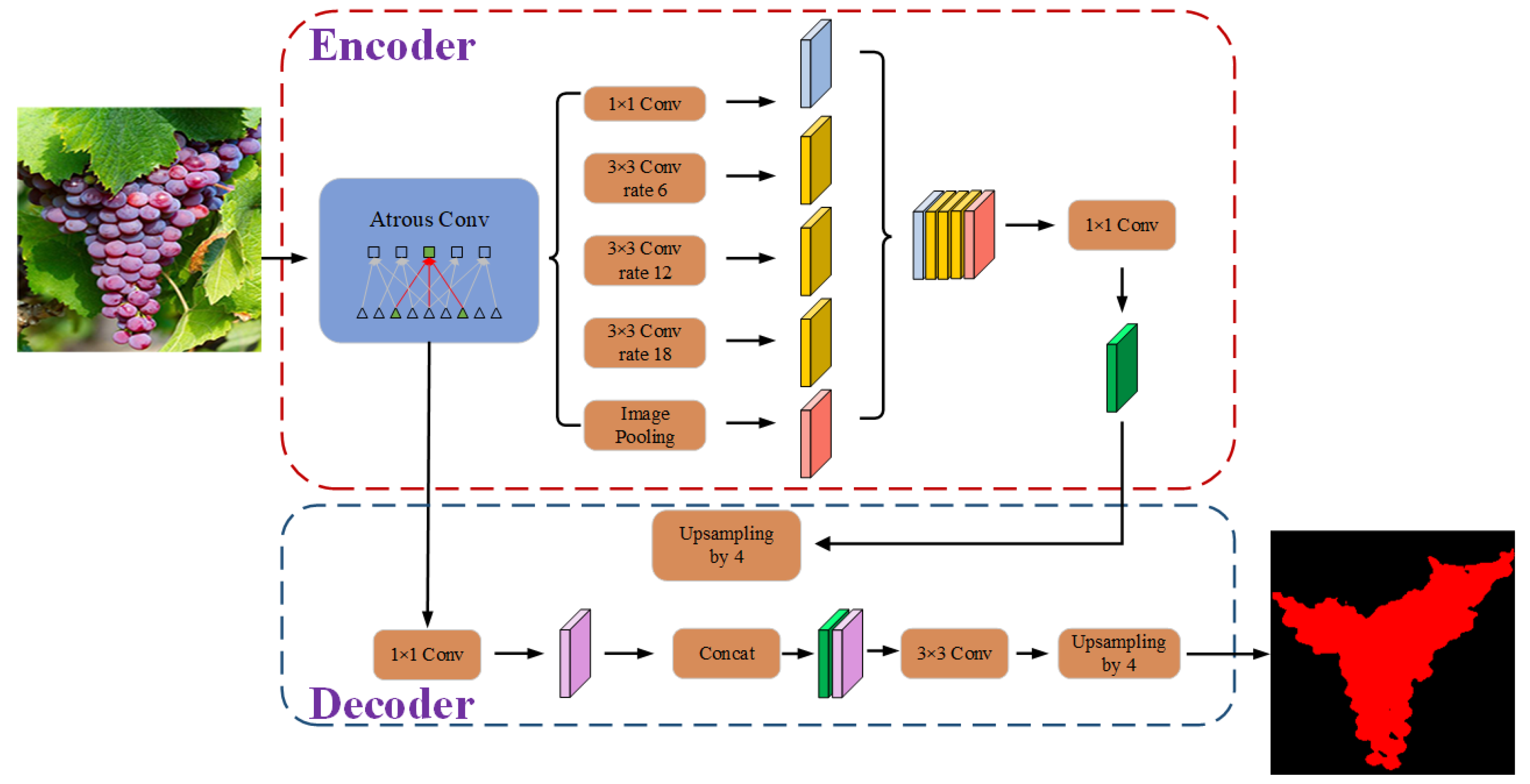
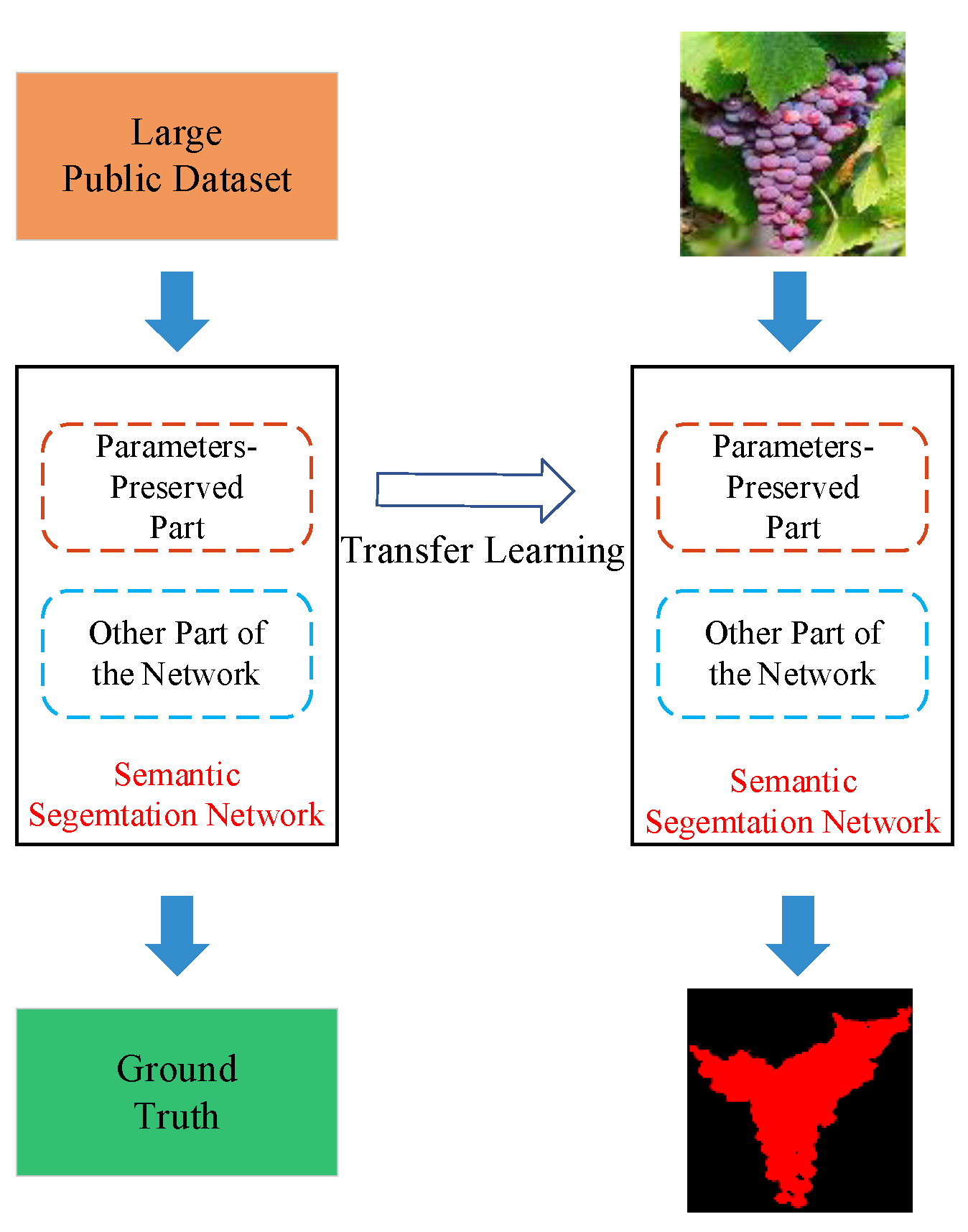
Given that the deep learning networks could extract and make use of hierarchical features. Moreover, some mature deep learning models could achieve pixel-level segmentation. Therefore, in this article, we will study the effect of pixel-level segmentation of different grape varieties by using 3 state-of-the-art semantic segmentation models and the factors that affect the performance. Specifically, (1) According to the constructed dataset (with different grape varieties), the segmentation performance was compared and analyzed with 3 art-of-the-state semantic segment models, i.e., FCN, U-Net, and DeepLabv3+; (2) Different input representations including different color space transformations and a constructed input representation, were compared to analyze the effect of input representations on the performance of the adopted network; (3) Model robustness with respect to lighting conditions was improved by image enhancement; (4) The influence of the distance between grapes clusters and camera on segmentation performance was also analyzed and discussed.
The remainder of this article is structured as follows. We start with a description of the materials and methods of the experiments in
Section 2. In
Section 3, experiment results with a detailed discussion about the experiment are given. Finally, the conclusions and future work are presented in
Section 4.
4. Conclusions
In this research, for the semantic segmentation of different varieties of grapes, 3 state-of-the-art semantic segmentation networks, i.e., Fully Convolutional Networks (FCN), U-Net, and DeepLabv3+ applied to six different datasets were studied. The effect of different semantic networks, different input representations, image enhancement, and the distance between grape clusters and camera on the segmentation performance were evaluated.
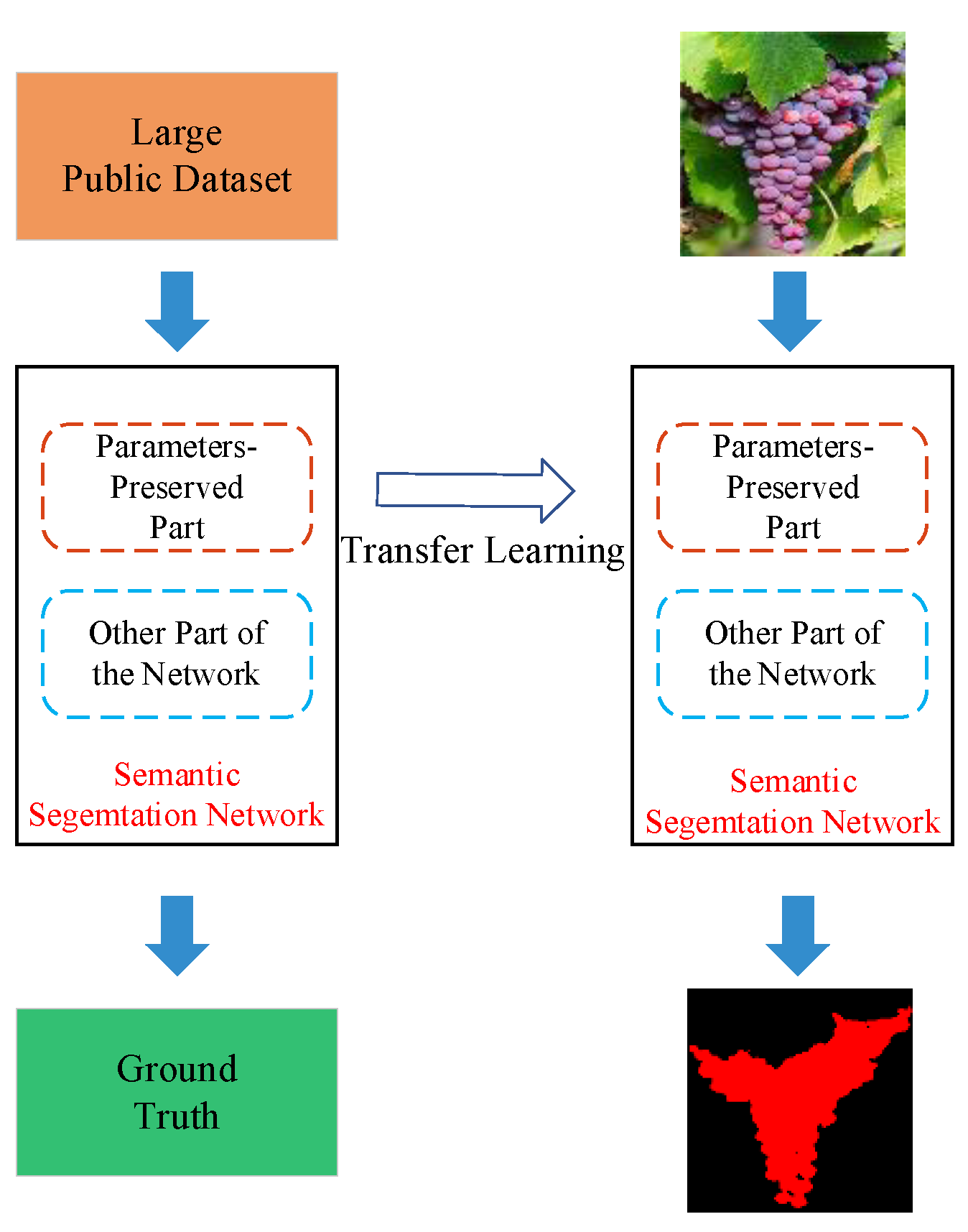
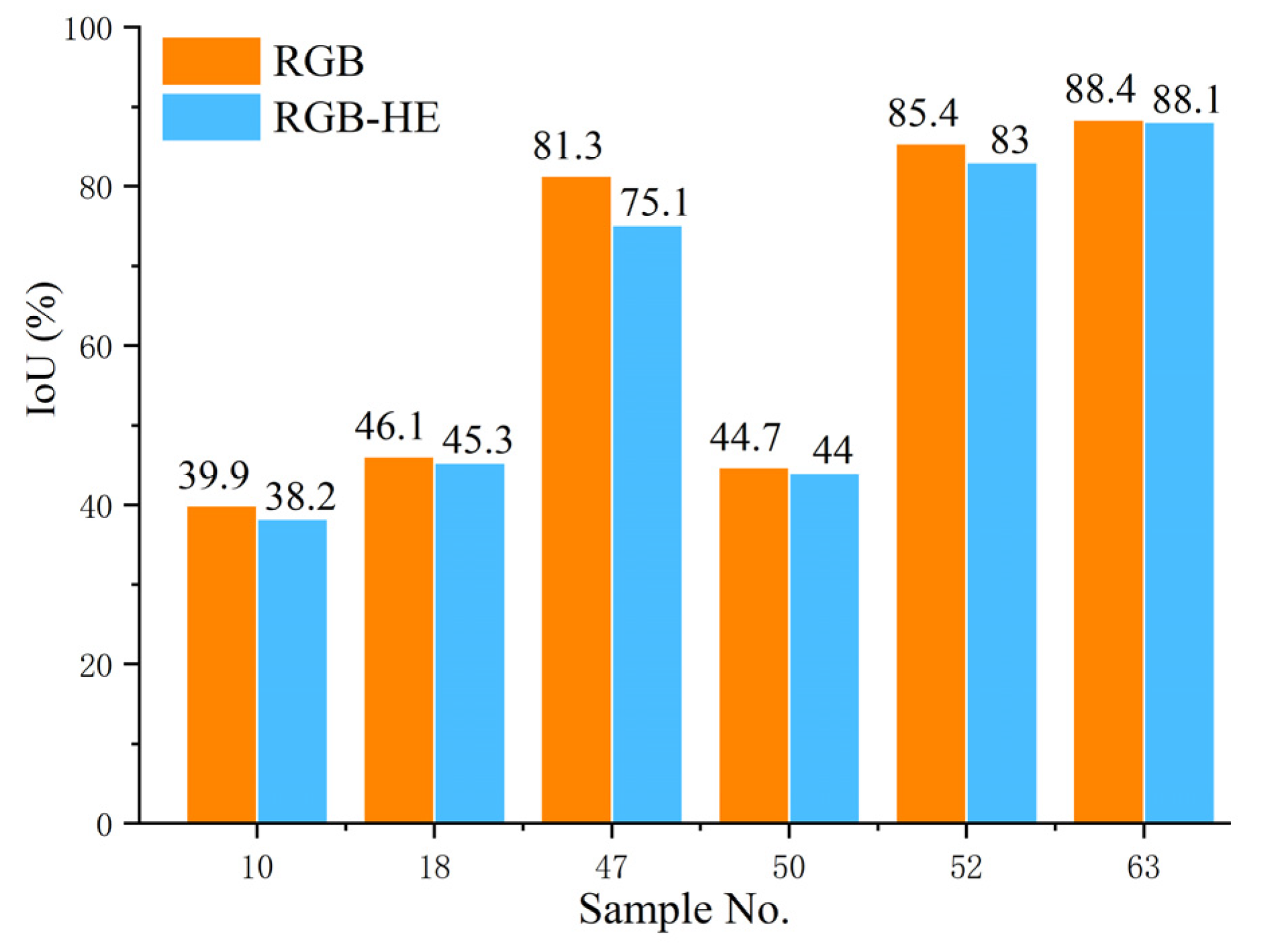
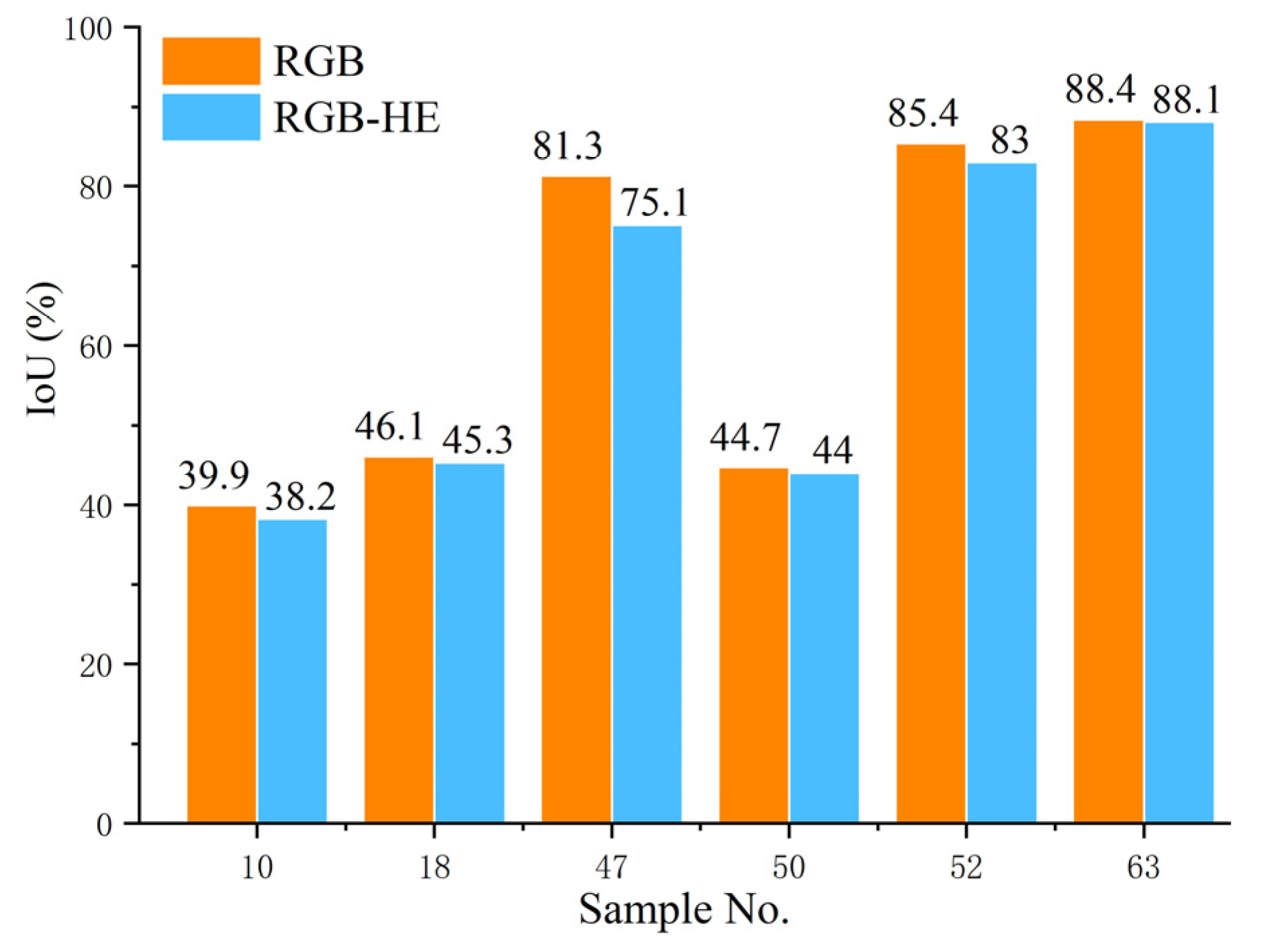
The experiment results show that the invested semantic segmentation models combined with transfer learning could identification grapes with different varieties and compared with U-Net and FCN, the DeepLabv3+ is more suitable. In addition, different input representations also affect the segmentation performance of the model, and the L*a*b dataset could obtain a more satisfactory performance. However, in actual applications, it is necessary to conduct in-depth research and select appropriate input representations for different fruits. Furthermore, the application of image enhancement methods can improve the influence of illumination, strengthen the contrast of the image, and have a positive effect on the segmentation performance of the studied model. Last but not least, the target distance also affects the performance of the studied model. Therefore, when collecting images, the camera should be as close to the target as possible to improve the segmentation performance.
In the future, we will deploy the model to a grape harvesting robot developed by our team to realize grapes robotic harvesting in real agricultural environment. Besides, the research on the performance improvement will continue, such as network architecture modification or dataset enhancement, i.e., collect more images from different vineyards with various condition, to further improve the identification performance.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}