
Mapping the Advanced-Stage Epithelial Ovarian Cancer Landscape Goes Beyond Words: Two Large Language Models, Eight Tasks, One Journey
 ,
,  , and
, and
Abstract
1. Introduction
2. Materials and Methods
2.1. Study Design and Population
2.2. Data Extraction and Processing
- Complete Cytoreduction: Whether the surgeon recorded no visible residual disease at the end of the procedure.
- Length of Stay: Whether the post-operative stay extended beyond 7 days (median), a clinically meaningful threshold to capture extended hospitalisation.
- Operative Time: Documented in minutes.
- Estimated Blood Loss: Documented in millilitres.
- Intensive Care Unit (ICU) Admission: Whether the patient required ICU admission in the immediate post-operative period.
- Clavien-Dindo Grade 3–5 post-operative complications: Complications that necessitated surgical, endoscopic, or radiological intervention (grade 3), that necessitate critical organ support (grade 4), or that resulted in death (grade 5) [13].
- Time between surgery and end of treatment: Indicating potential treatment delays.
- End-of-Treatment CA125: Whether the patient’s serum CA125, measured upon completion of chemotherapy or follow-up, remained elevated or not (≥35 U/mL).
2.3. Large Language Model Architectures
2.4. Performance Metrics and Statistical Analysis
3. Results
4. Discussion
4.1. Clinical Implications
4.2. Strengths and Novel Contributions
4.3. Limitations
4.4. Future Directions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Doufekas, K.; Olaitan, A. Clinical epidemiology of epithelial ovarian cancer in the UK. Int. J. Women’S Health 2014, 6, 537–545. [Google Scholar]
- du Bois, A.; Reuss, A.; Pujade-Lauraine, E.; Harter, P.; Ray-Coquard, I.; Pfisterer, J. Role of surgical outcome as prognostic factor in advanced epithelial ovarian cancer: A combined exploratory analysis of 3 prospectively randomized phase 3 multicenter trials. Cancer 2009, 115, 1234–1244. [Google Scholar] [CrossRef] [PubMed]
- Chi, D.S.; Franklin, C.C.; Levine, D.A.; Akselrod, F.; Sabbatini, P.; Jarnagin, W.R.; DeMatteo, R.; Poynor, E.A.; Abu-Rustum, N.R.; Barakat, R.R. Improved optimal cytoreduction rates for stages IIIC and IV epithelial ovarian, fallopian tube, and primary peritoneal cancer: A change in surgical approach. Gynecol. Oncol. 2004, 94, 650–654. [Google Scholar] [PubMed]
- Dagliati, A.; Malovini, A.; Tibollo, V.; Bellazzi, R. Health informatics and EHR to support clinical research in the COVID-19 pandemic: An overview. Brief. Bioinform. 2021, 22, 812–822. [Google Scholar] [CrossRef]
- Martin-Sanchez, F.; Verspoor, K. Big data in medicine is driving big changes. Yearb. Med. Inform. 2014, 23, 14–20. [Google Scholar]
- Khurana, D.; Koli, A.; Khatter, K.; Singh, S. Natural language processing: State of the art, current trends and challenges. Multimed. Tools Appl. 2023, 82, 3713–3744. [Google Scholar]
- Nassiri, K.; Akhloufi, M.A. Recent Advances in Large Language Models for Healthcare. BioMedInformatics 2024, 4, 1097–1143. [Google Scholar] [CrossRef]
- Yang, X.; Chen, A.; PourNejatian, N.; Shin, H.C.; Smith, K.E.; Parisien, C.; Compas, C.; Martin, C.; Flores, M.G.; Zhang, Y.; et al. GatorTron: A Large Clinical Language Model to Unlock Patient Information from Unstructured Electronic Health Records. arXiv 2022, arXiv:2203.03540. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Laios, A.; Kalampokis, E.; Mamalis, M.E.; Tarabanis, C.; Nugent, D.; Thangavelu, A.; Theophilou, G.; Jong, D.D. RoBERTa-Assisted Outcome Prediction in Ovarian Cancer Cytoreductive Surgery Using Operative Notes. Cancer Control 2023, 30, 10732748231209892. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Huang, J.; Xu, C.; Zheng, H.; Zhang, L.; Wan, J. Research on Named Entity Recognition of Electronic Medical Records Based on RoBERTa and Radical-Level Feature. Wirel. Commun. Mob. Comput. 2021, 2021, 2489754. [Google Scholar] [CrossRef]
- Newsham, A.C.; Johnston, C.; Hall, G.; Leahy, M.G.; Smith, A.B.; Vikram, A.; Donnelly, A.M.; Velikova, G.; Selby, P.J.; Fisher, S.E. Development of an advanced database for clinical trials integrated with an electronic patient record system. Comput. Biol. Med. 2011, 41, 575–586. [Google Scholar] [CrossRef] [PubMed]
- Clavien, P.A.; Barkun, J.; de Oliveira, M.L.; Vauthey, J.N.; Dindo, D.; Schulick, R.D.; de Santibañes, E.; Pekolj, J.; Slankamenac, K.; Bassi, C.; et al. The Clavien-Dindo classification of surgical complications: Five-year experience. Ann. Surg. 2009, 250, 187–196. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Bian, J.; Hogan, W.R.; Wu, Y. Clinical concept extraction using transformers. J. Am. Med. Inform. Assoc. 2020, 27, 1935–1942. [Google Scholar] [CrossRef] [PubMed]
- van Es, B.; Reteig, L.C.; Tan, S.C.; Schraagen, M.; Hemker, M.M.; Arends, S.R.S.; Rios, M.A.R.; Haitjema, S. Negation detection in Dutch clinical texts: An evaluation of rule-based and machine learning methods. BMC Bioinform. 2023, 24, 10. [Google Scholar] [CrossRef]
- Laios, A.; Kalampokis, E.; Mamalis, M.E.; Thangavelu, A.; Hutson, R.; Broadhead, T.; Nugent, D.; De Jong, D. Exploring the Potential Role of Upper Abdominal Peritonectomy in Advanced Ovarian Cancer Cytoreductive Surgery Using Explainable Artificial Intelligence. Cancers 2023, 15, 5386. [Google Scholar] [CrossRef]
- Querleu, D.; Planchamp, F.; Chiva, L.; Fotopoulou, C.; Barton, D.; Cibula, D.; Aletti, G.; Carinelli, S.; Creutzberg, C.; Davidson, B.; et al. European Society of Gynaecological Oncology (ESGO) Guidelines for Ovarian Cancer Surgery. Int. J. Gynecol. Cancer Off. J. Int. Gynecol. Cancer Soc. 2017, 27, 1534–1542. [Google Scholar] [CrossRef]
- Yang, S.; Yang, X.; Lyu, T.; Huang, J.L.; Chen, A.; He, X.; Braithwaite, D.; Mehta, H.J.; Wu, Y.; Guo, Y.; et al. Extracting Pulmonary Nodules and Nodule Characteristics from Radiology Reports of Lung Cancer Screening Patients Using Transformer Models. J. Healthc. Inform. Res. 2024, 8, 463–477. [Google Scholar] [CrossRef]
- Klug, K.; Beckh, K.; Antweiler, D.; Chakraborty, N.; Baldini, G.; Laue, K.; Hosch, R.; Nensa, F.; Schuler, M.; Giesselbach, S. From admission to discharge: A systematic review of clinical natural language processing along the patient journey. BMC Med. Inform. Decis. Mak. 2024, 24, 238. [Google Scholar] [CrossRef]
- Sheikh, A.; Jha, A.; Cresswell, K.; Greaves, F.; Bates, D.W. Adoption of electronic health records in UK hospitals: Lessons from the USA. Lancet 2014, 384, 8–9. [Google Scholar] [CrossRef]
- Laios, A.; Kalampokis, E.; Mamalis, M.E.; Thangavelu, A.; Tan, Y.S.; Hutson, R.; Munot, S.; Broadhead, T.; Nugent, D.; Theophilou, G.; et al. Explaining the Elusive Nature of a Well-Defined Threshold for Blood Transfusion in Advanced Epithelial Ovarian Cancer Cytoreductive Surgery. Diagnostics 2024, 14, 94. [Google Scholar] [CrossRef]
- Chen, K.; Xu, W.; Li, X. The Potential of Gemini and GPTs for Structured Report Generation based on Free-Text 18F-FDG PET/CT Breast Cancer Reports. Acad. Radiol. 2024, 32, 624–633. [Google Scholar] [CrossRef] [PubMed]
- Banegas-Luna, A.J.; Peña-García, J.; Iftene, A.; Guadagni, F.; Ferroni, P.; Scarpato, N.; Zanzotto, F.M.; Bueno-Crespo, A.; Pérez-Sánchez, H. Towards the Interpretability of Machine Learning Predictions for Medical Applications Targeting Personalised Therapies: A Cancer Case Survey. Int. J. Mol. Sci. 2021, 22, 4394. [Google Scholar] [CrossRef] [PubMed]
- Siglen, E.; Vetti, H.H.; Lunde, A.B.F.; Hatlebrekke, T.A.; Strømsvik, N.; Hamang, A.; Hovland, S.T.; Rettberg, J.W.; Steen, V.M.; Bjorvatn, C. Ask Rosa – The making of a digital genetic conversation tool, a chatbot, about hereditary breast and ovarian cancer. Patient Educ. Couns. 2022, 105, 1488–1494. [Google Scholar] [CrossRef] [PubMed]
- Finch, L.; Broach, V.; Feinberg, J.; Al-Niaimi, A.; Abu-Rustum, N.R.; Zhou, Q.; Iasonos, A.; Chi, D.S. ChatGPT compared to national guidelines for management of ovarian cancer: Did ChatGPT get it right?—A Memorial Sloan Kettering Cancer Center Team Ovary study. Gynecol. Oncol. 2024, 189, 75–79. [Google Scholar] [CrossRef]

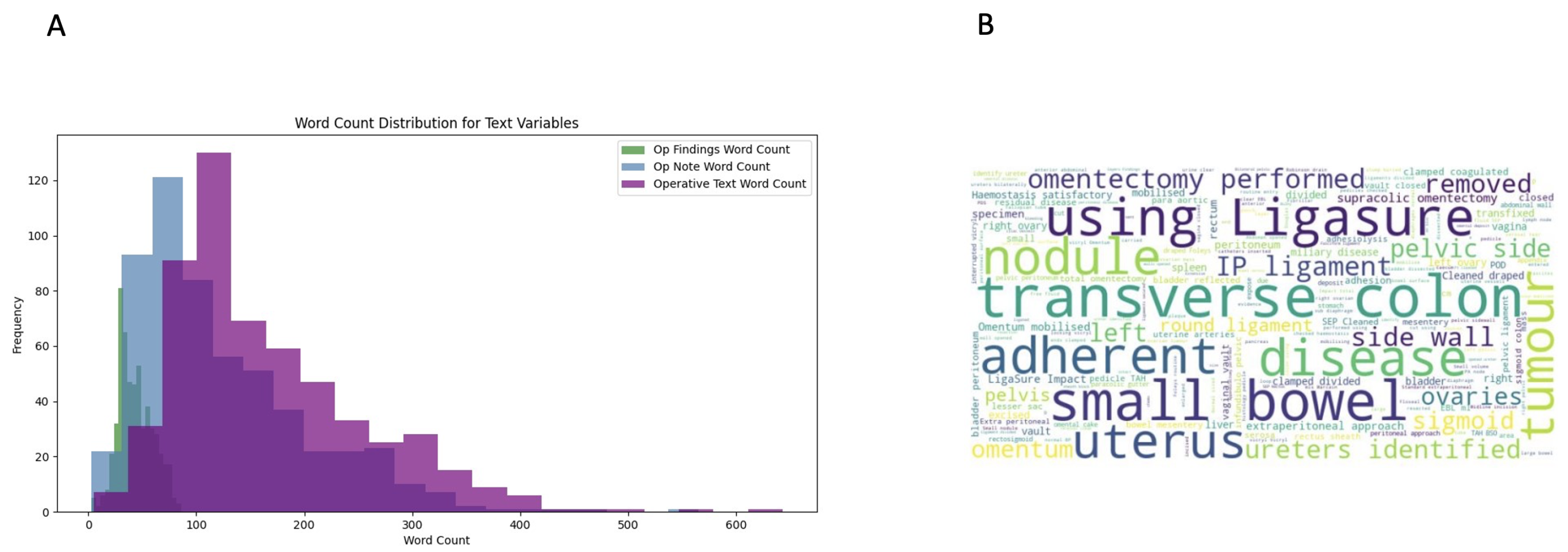

{kind=link}
{kind=link}
{kind=link}
| Text Fields | Patient Characteristics | Original Data Type |
|---|---|---|
| Operative Notes (Op Note) | Time procedure (minutes) | Binary |
| Operative Findings (Op Findings) | Length of stay (days) | Binary |
| Time between surgery and end of treatment | Binary | |
| Intensive Care Admission (after surgery) | Integer | |
| Estimated Blood Loss (EBL) | Integer | |
| End of Treatment CA125 | Integer | |
| Complete cytoreduction vs non-complete cytoreduction | Integer | |
| Major post-operative complications Clavien Dindo (CD) (3–5) | Integer |
| RoBERTa | GatorTron | |
|---|---|---|
| Epochs | 40, 60 | 40 |
| Learning Rate | (default), , | (default) |
| Loss Function | Cross-entropy loss | Cross-entropy loss |
| Time Procedure (Minutes) | Length of Stay (Days) | Time Between Surgery and End of Treatment | Estimated Blood Loss (EBL) | End of Treatment CA125 | |
|---|---|---|---|---|---|
| Count | 560 | 560 | 540 | 560 | 559 |
| Mean | 170.39 | 8.32 | 91.25 | 524.50 | 61.57 |
| Median | 150 | 7 | 73 | 425 | 13 |
| Std | 77.55 | 8.65 | 85.14 | 387.78 | 347.40 |
| Min | 30 | 2 | 0 | 50 | 2 |
| 25% | 115 | 6 | 58 | 300 | 8 |
| 75% | 205 | 9 | 119.5 | 600 | 23 |
| Max | 600 | 174 | 1325 | 4500 | 5646 |
| Operative Text | Operative Findings | Operative Note | |
|---|---|---|---|
| Count | 560 | 560 | 560 |
| Mean | 165.12 | 43.12 | 122.98 |
| Median | 139.5 | 41 | 99 |
| Std | 90.84 | 16.44 | 80.44 |
| Min | 0 | 0 | 0 |
| 25% | 101 | 31.75 | 64 |
| 75% | 214 | 54.25 | 165 |
| Max | 643 | 86 | 565 |
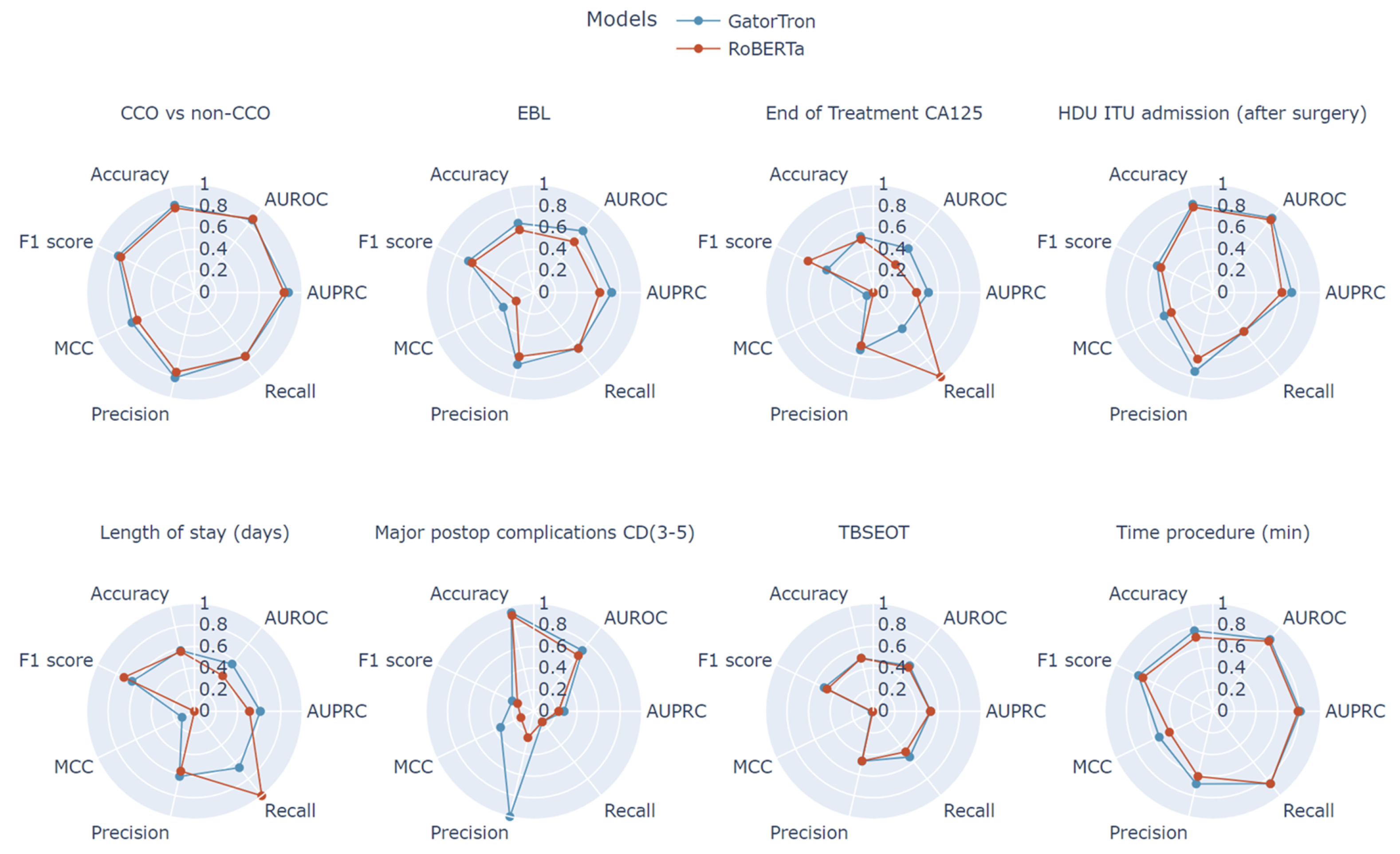
| Target Field | Accuracy | Recall | Precision | F1-Score | AUPRC | AUROC | MCC |
|---|---|---|---|---|---|---|---|
| CCO vs. non-CCO | 0.802 | 0.756 | 0.756 | 0.756 | 0.83 | 0.87 | 0.589 |
| EBL | 0.595 | 0.661 | 0.609 | 0.634 | 0.61 | 0.60 | 0.182 |
| End of treatment CA125 | 0.505 | 1.000 | 0.505 | 0.671 | 0.40 | 0.33 | 0.000 |
| Length of stay | 0.568 | 1.000 | 0.568 | 0.724 | 0.51 | 0.42 | 0.000 |
| Time between surgery and end of treatment | 0.505 | 0.480 | 0.471 | 0.475 | 0.53 | 0.52 | 0.006 |
| Time procedure | 0.703 | 0.857 | 0.618 | 0.718 | 0.79 | 0.83 | 0.446 |
| HDU/ITU admission | 0.811 | 0.462 | 0.632 | 0.533 | 0.64 | 0.86 | 0.426 |
| Major postop complications | 0.910 | 0.125 | 0.250 | 0.167 | 0.23 | 0.66 | 0.133 |
| Target Field | Accuracy | Recall | Precision | F1-Score | AUPRC | AUROC | MCC |
|---|---|---|---|---|---|---|---|
| Time procedure | 0.766 | 0.857 | 0.689 | 0.764 | 0.81 | 0.85 | 0.550 |
| Length of stay | 0.577 | 0.667 | 0.618 | 0.641 | 0.61 | 0.56 | 0.127 |
| Time between surgery and end of treatment | 0.505 | 0.540 | 0.474 | 0.505 | 0.53 | 0.54 | 0.014 |
| HDU/ITU admission | 0.838 | 0.462 | 0.750 | 0.571 | 0.73 | 0.88 | 0.500 |
| EBL | 0.658 | 0.661 | 0.684 | 0.672 | 0.72 | 0.73 | 0.314 |
| End of treatment CA125 | 0.532 | 0.429 | 0.545 | 0.480 | 0.51 | 0.52 | 0.066 |
| CCO vs. non-CCO | 0.829 | 0.756 | 0.810 | 0.782 | 0.87 | 0.86 | 0.642 |
| Major postop complications CD (3–5) | 0.937 | 0.125 | 1.000 | 0.222 | 0.28 | 0.72 | 0.342 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Quaranta, M.; Laios, A.; Rogers, C.; Mavromatidou, A.I.; Thangavelu, A.; Theophilou, G.; Nugent, D.; DeJong, D.; Kalampokis, E. Mapping the Advanced-Stage Epithelial Ovarian Cancer Landscape Goes Beyond Words: Two Large Language Models, Eight Tasks, One Journey. J. Clin. Med. 2025, 14, 2223. https://doi.org/10.3390/jcm14072223
Quaranta M, Laios A, Rogers C, Mavromatidou AI, Thangavelu A, Theophilou G, Nugent D, DeJong D, Kalampokis E. Mapping the Advanced-Stage Epithelial Ovarian Cancer Landscape Goes Beyond Words: Two Large Language Models, Eight Tasks, One Journey. Journal of Clinical Medicine. 2025; 14(7):2223. https://doi.org/10.3390/jcm14072223
Chicago/Turabian StyleQuaranta, Michela, Alexandros Laios, Charlie Rogers, Anastasia Ioanna Mavromatidou, Amudha Thangavelu, Georgios Theophilou, David Nugent, Diederick DeJong, and Evangelos Kalampokis. 2025. "Mapping the Advanced-Stage Epithelial Ovarian Cancer Landscape Goes Beyond Words: Two Large Language Models, Eight Tasks, One Journey" Journal of Clinical Medicine 14, no. 7: 2223. https://doi.org/10.3390/jcm14072223
APA StyleQuaranta, M., Laios, A., Rogers, C., Mavromatidou, A. I., Thangavelu, A., Theophilou, G., Nugent, D., DeJong, D., & Kalampokis, E. (2025). Mapping the Advanced-Stage Epithelial Ovarian Cancer Landscape Goes Beyond Words: Two Large Language Models, Eight Tasks, One Journey. Journal of Clinical Medicine, 14(7), 2223. https://doi.org/10.3390/jcm14072223