1. Introduction
Retinal vein occlusion (RVO) is the second most common retinal vascular disorder after diabetic retinopathy and is a significant cause of visual loss and visual disability. RVO occurs due to the obstruction of the retinal venous system by thrombus formation, leading to increased capillary pressure, fluid leakage, and macular edema, which are primary contributors to vision impairment in these patients [
1,
2].
Approximately 16 million people worldwide are affected by RVO, with its prevalence influenced by factors such as age, gender, and underlying health conditions. The incidence of RVO increases with age, particularly affecting individuals over 60 [
3].
RVO is broadly classified into branch RVO (BRVO) and central RVO (CRVO) based on the site of occlusion. BRVO typically occurs at arteriovenous crossings, whereas CRVO occurs at or near the lamina cribrosa of the optic nerve. The compression by adjacent atherosclerotic retinal arteries is the most common etiological factor. CRVO is characterized by disc edema, increased dilatation and tortuosity of retinal veins, widespread hemorrhages, cotton wool spots, macular edema, and capillary non-perfusion across the retina. BRVO exhibits similar features but is confined to the area drained by the affected vein. Visual acuity loss primarily results from macular edema but can also arise from macular ischemia or neovascular complications such as vitreous hemorrhage and neovascular glaucoma [
1].
Optical coherence tomography (OCT) is a non-invasive imaging technique that provides detailed cross-sectional images of retinal structures, facilitating the diagnosis of macular edema secondary to RVO, hereafter mentioned solely as RVO. OCT typically uses near-infrared (IR) light, which has a penetration depth of several hundred microns in tissue. The interferometric setup reconstructs the depth profile of the retina, providing high-resolution images. Combining OCT with confocal scanning laser ophthalmoscopy (cSLO) allows for motion tracking and precise re-examination of specific retinal regions. Advances in functional OCT now permit imaging of retinal blood flow, tissue polarization, and mechanical properties such as elasticity. The SPECTRALIS device by Heidelberg Engineering integrates cSLO and OCT, providing versatile imaging capabilities including reflectance imaging in various wavelengths. This system’s motion tracking and high-resolution imaging are particularly beneficial for diagnosing and monitoring RVO. These include cSLO reflectance imaging in the near IR. OCT is usually combined with IR confocal imaging, though other combinations are possible as well. Confocal imaging creates a transversal image of the retina corresponding to the en-face plane of OCT. The SPECTRALIS system utilizes the IR cSLO scans for automatic motion tracking [
4].
Computer-assisted diagnosis (CAD) with artificial intelligence (AI) has demonstrated promising diagnostic performance in image recognition, achieving robust results across various medical specialties, including ophthalmology. In particular, AI can be utilized to screen OCT scans for disease detection, helping to mitigate factors such as human bias, fatigue, and mindset [
5].
Early approaches to CAD involved the extraction of relevant features, which required domain expertise and varied with the dataset. These features could include texture or structural information of the image. Texture features could be created using techniques such as local binary pattern and filtered using principal component analysis or k-means clustering, although they were more susceptible to noise. Structural features, on the other hand, were more device-independent and thus provided more reliable classifications [
6].
More recently, deep learning (DL) models have been employed to classify OCT scans and the development of convolutional neural networks (CNN) has improved the performance of image classification, significantly improving the performance of image classification [
7,
8].
CNNs utilize convolutional operators to extract features directly from image pixels, making them highly effective for image classification tasks. The images are processed through convolutional, pooling, and activation layers to extract features, and then fully connected layers are used to classify the image [
9]. These models have been applied to classify multiple diseases simultaneously, which is more practical for real-world disease screening. For example, Kermany et al. [
10] developed a DL model capable of distinguishing eyes with choroidal neovascularization (CNV) or diabetic macular edema (DME) from eyes with drusen or healthy eyes. The authors of this work made the used dataset publicly available, which has been used in further research. One example is the study from Li et al. [
11], which achieved excellent results using the VGG16 network with an accuracy of 98.6%.
However, there is a research gap in differentiating RVO from DME. Most published works that address the classification between these two retinal pathologies rely on fundus images. For example, Choi et al. [
12] used random forest transfer learning (TL) based on the VGG-19 architecture to classify fundus images between diabetic retinopathy (DR) and RVO, with an accuracy of 74.7%. Abitbol et al. [
13] developed a DL model to distinguish widefield color fundus images of patients with RVO and DR, with an accuracy of 85.2% for DR and 88.4% for RVO. Other works focused only on the distinction between different types of RVO and healthy eyes on fundus images [
14,
15].
Previous studies, such as the one from Li et al. [
11], have achieved high accuracy in classifying the OCT images from Kermany dataset [
16]. However, these models often fail to incorporate additional patient data, such as diabetes diagnosis, which can significantly enhance classification accuracy. Regarding OCT images, there is limited research on the classification of patients with RVO and this exam is the preferred imaging modality for non-invasive diagnosis. Therefore, the development of a model that classifies RVO with this exam has tremendous potential in clinical applicability.
Pin et al. [
17] proposed an ensemble of two TL models, MobileNetV3Large and ResNet50, to classify OCT images between RVO, age-related macular degeneration (AMD), central serous chorioretinopathy (CSCR), and DME with an overall accuracy of 91.69%. Khan et al. [
18] modified three pre-trained models and extracted features via TL. The best features were selected using ant colony optimization and passed to the k-nearest neighbors and support vector machine algorithms to classify OCT images between AMD, RVO, CSCR and DME with an accuracy of 99.1% with ant colony optimization and 97.4% without it. Recently, Kulyabin et al. [
19] tested the performance of VGG16 and ResNet50 on an open-access dataset [
20] of OCT images, achieving an overall accuracy of 89.5% with VGG16. This dataset included AMD, DME, Epiretinal Membrane, Retinal Artery Occlusion, RVO, and Vitreomacular Interface Disease.
This study aims to develop a DL-based method to classify specific retinal conditions involving edema, namely DME, RVO-associated edema, and generic disease, using OCT and infrared imaging.
4. Discussion
The use of AI in the diagnosis of retinal diseases can significantly enhance the capabilities of ophthalmologists, enabling them to deliver faster and more accurate diagnoses. This efficiency gain not only improves patient outcomes by allowing earlier detection and treatment of retinal diseases but also increases the number of medical appointments that ophthalmologists can handle, thereby extending their reach and impact.
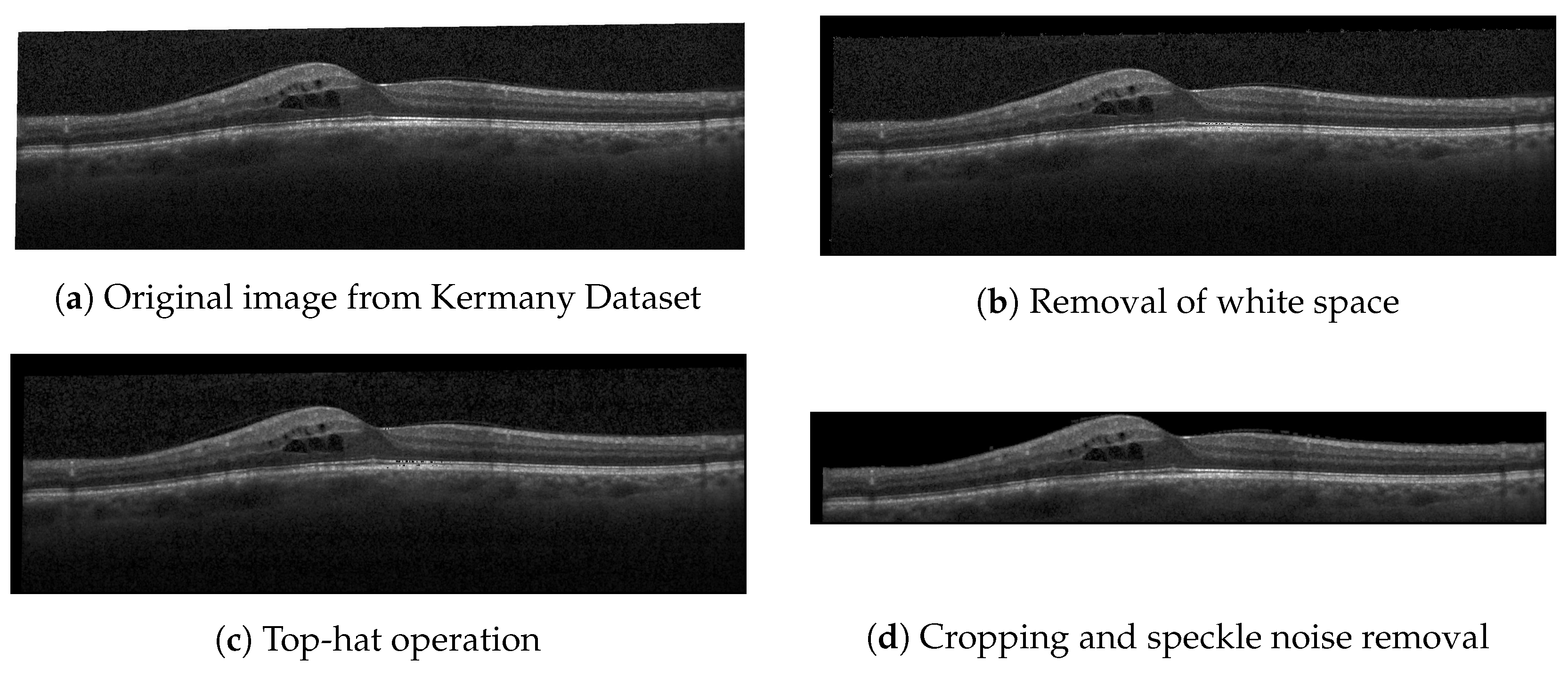
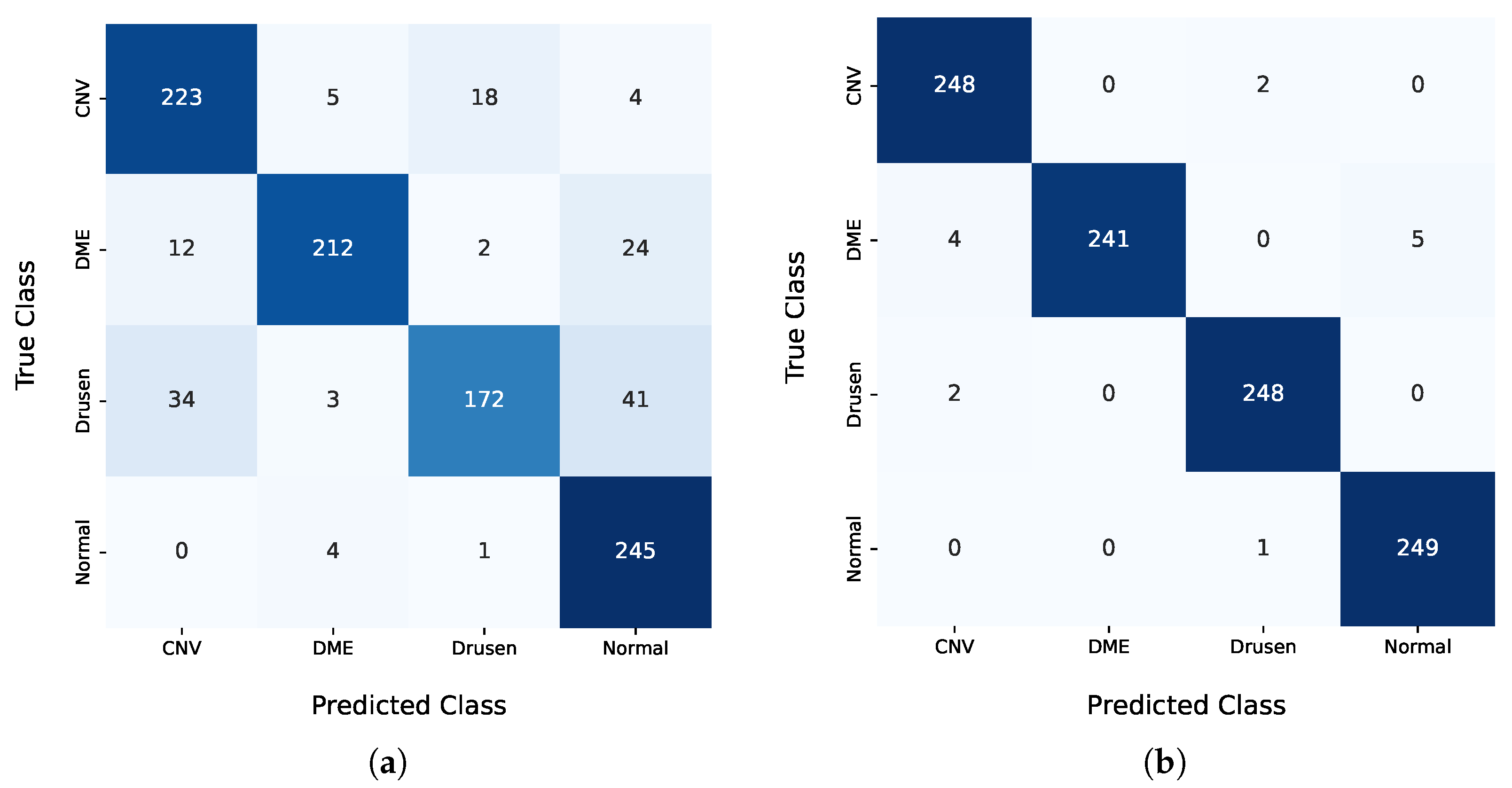
In the pre-training step, the results obtained with the public dataset from Kermany et al. [
16] were significantly below the state-of-the-art results. The F
0.5 score of 85.52% achieved by the proposed model lagged more than 10 percentage points behind the results from Li et al. [
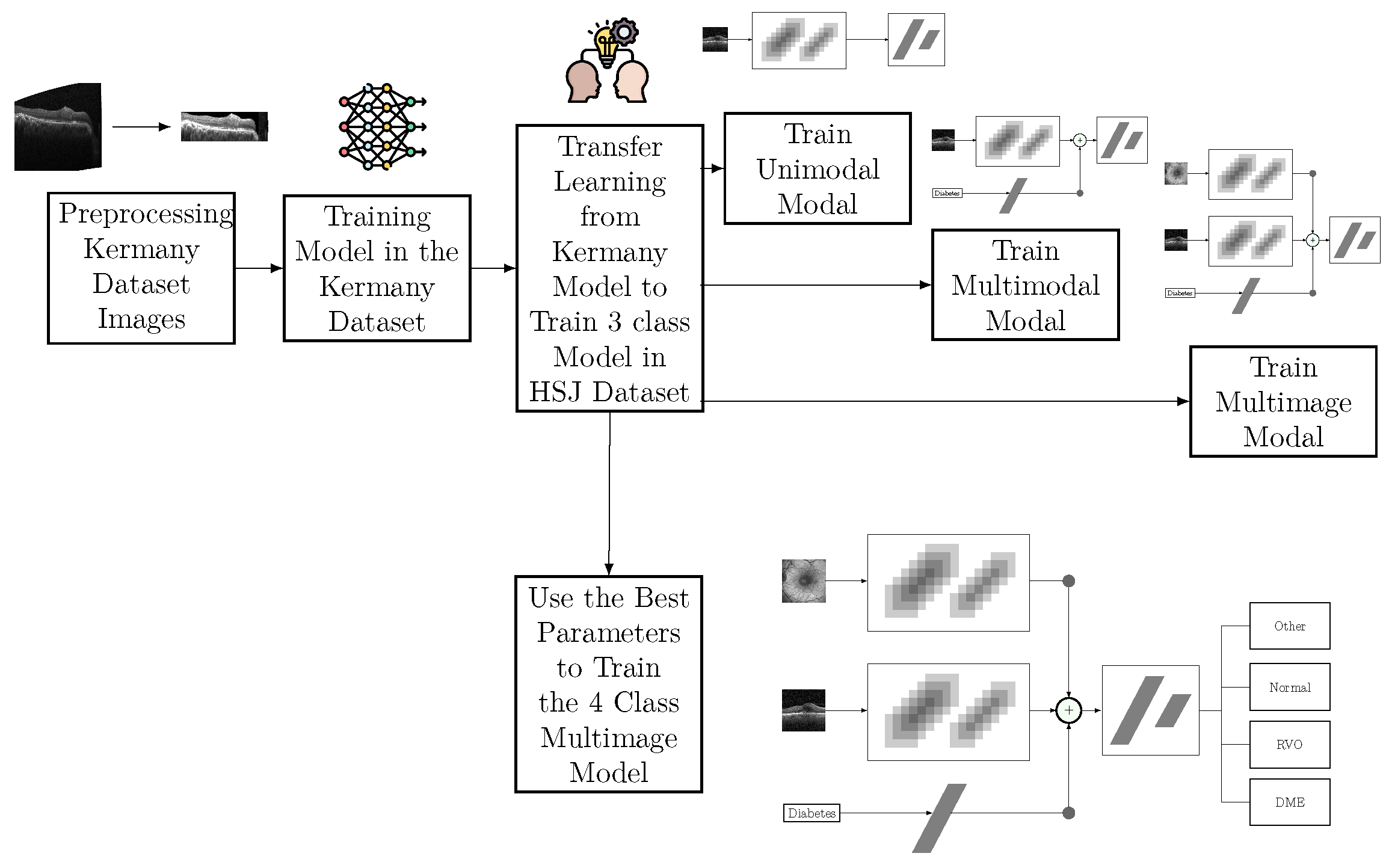
11]. Nonetheless, this model was only used to initialize the weights of the classification model. The decision to use the weights of the Kermany model as a starting point for the multimodal and multi-image models was based on the benefits of TL, even when the pre-trained model was developed using a single modality, in this case, OCT images. TL is a widely adopted approach in DL, where models pre-trained on related tasks provide a better initialization for new tasks, thereby accelerating convergence and potentially improving the model performance. While IR images were not present in the Kermany dataset, the features learned from OCT images contributed to the model’s ability to generalize better during training. Hyperparameter optimization demonstrated that models initialized with Kermany weights and subsequently fine-tuned on our dataset outperformed models trained from scratch. This highlights the importance of leveraging domain-relevant pre-training even when modalities differ slightly. However, the results also underline the need for further research into pre-training strategies that simultaneously address multimodal inputs, as the inclusion of IR images and clinical features poses unique challenges and opportunities for developing robust AI systems.
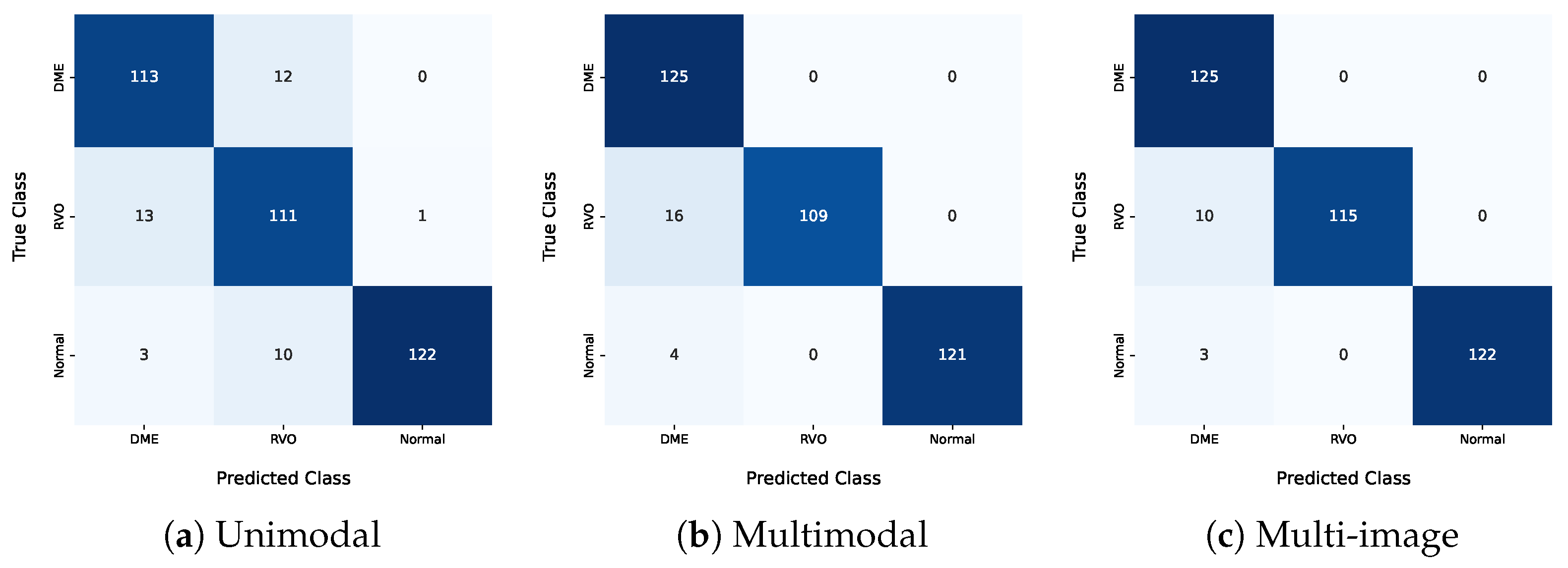
Regarding the HSJ model used for classification, three different architectures were analyzed: unimodal, multimodal, and multi-image models. The best unimodal model only misclassified one pathological eye as healthy, specifically categorizing one healthy eye as RVO. This is particularly significant and promising for disease diagnosis, since false positives should be minimized. Additionally, this model misclassified DME eyes as RVO and vice versa, indicating that these two classes have similar features, which aligns with the clinical challenge of distinguishing between DME and RVO.
The best multimodal model, which included additional input about the patient’s diabetes diagnosis, demonstrated the value of this information. This model correctly classified all DME images and showed overall better results for every metric presented, underscoring the benefits of using diabetes-related information. Furthermore, this model did not produce any false positives but still had difficulty differentiating RVO from DME, misclassifying 16 eyes with RVO as DME. The integration of the diabetes diagnosis and IR imaging increased the model accuracy. This approach can potentially be extended to other retinal diseases and integrated into clinical workflows.
The unimodal model misclassified three normal eyes as DME, and these patients did not have diabetes. In the multimodal model, this error would not occur since a non-diabetic patient’s entry would never be classified as DME. Only eyes from diabetic patients were classified as DME in the multimodal model, including the misclassified ones. The higher number of false DME positives indicates that the diabetes information introduced some bias, causing the model to classify more eyes as DME.
The multi-image model achieved the best results among the three approaches in the three-class analysis. This approach had better differentiation between the DME and RVO classes, with only ten misclassified eyes between these two classes. All the evaluation metrics were higher for this approach, highlighting the positive impact of including an IR image as an input. The IR image also helped mitigate the bias mentioned earlier. These results highlight the value of multi-modal approaches in enhancing classification accuracy.
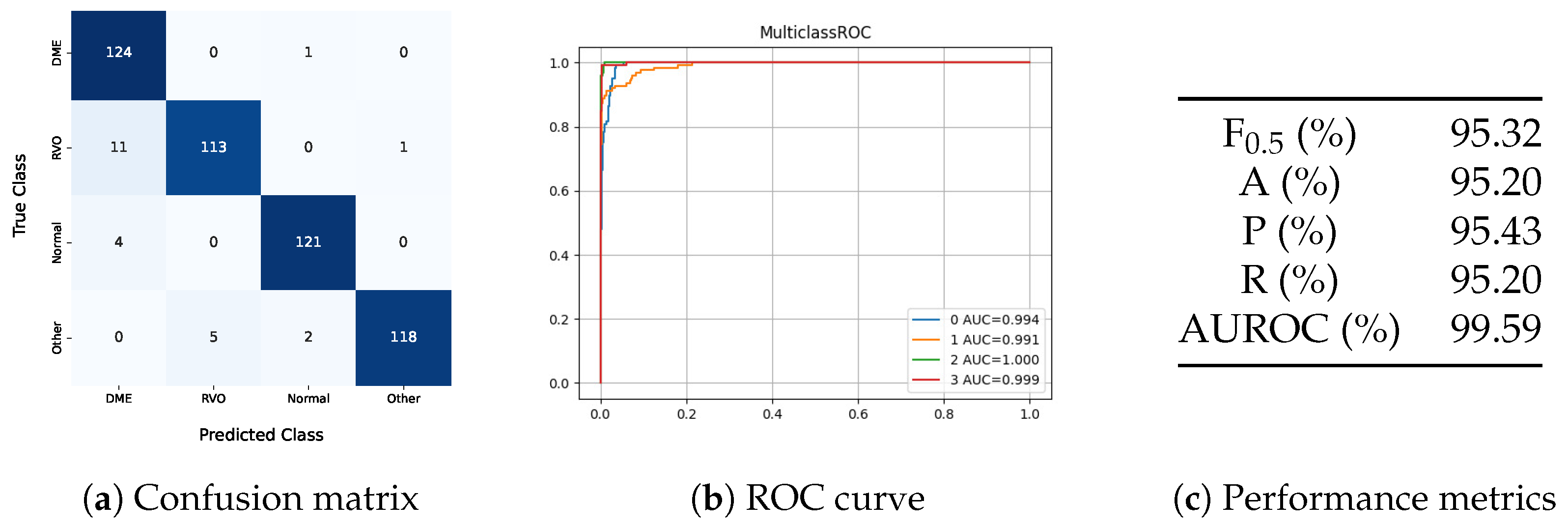
The four-class model showed better results than the unimodal and multimodal models in the three-class problem. However, its performance fell short of the multi-image model in the three-class problem, indicating that the added class increased the complexity of the task. In this model, all eyes classified as DME had diabetes or lacked diabetes diagnostic information, demonstrating that the model understood that only diabetic patients can have DME. One DME eye was misclassified as normal, showing that the model does not automatically classify all diabetes-related images as DME. Besides this false negative, the model also predicted two eyes with other pathologies as normal. Regarding the distinction between DME and RVO, the model misclassified eleven RVO eyes as DME.
Despite the increased complexity of the four-class model, which includes a class for other pathologies, the method demonstrates promising clinical applicability. The inclusion of this additional class is crucial, as it aligns better with real-world scenarios where multiple pathologies may be present. While the ‘Other’ class does not provide a specific diagnosis, it prevents the model from misclassifying non-edematous retinal pathologies as healthy or as edema secondary to RVO or DME. This design ensures that the model serves as a robust preliminary screening tool, prompting clinicians to conduct further evaluations for conditions beyond the scope of the current classification framework.
In the testing set, images of eyes with diabetes appeared in all classes, as shown in
Table 4, and these were correctly classified, indicating that the model did not classify all eyes from diabetic patients as DME.
Class-wise metrics were calculated to properly compare the proposed work with existing studies, since state-of-the-art models have a different number of classes than those used in this work.
Table 8 presents the class-wise and overall metric results for the proposed models and their comparison to the state of the art. The state-of-the-art models listed have more classes than those in
Table 8, but the comparison focuses on DME and RVO.
Section 1 details the specific classes used in each study.
The overall metrics were calculated based on the weighted average of all classes. For better comparison with other published works, the metrics from those works were inferred from their confusion matrices. Consequently, the results presented in their papers might differ from those reported here due to different average metric calculations. The RVO class-wise metric for the reviewed state-of-the-art models was based on the mean results for CRVO and BRVO. The proposed model achieves higher overall accuracy than those by Abitbol et al. [
13], Pin et al. [
17], and Kulyabin et al. [
19], falling short only of Khan et al. [
18], who reported an accuracy of 99.17%. However, the proposed work used a dataset with more patients and images, and the use of a class for other pathologies increased the classification task’s complexity.
Regarding the class-wise metrics, the proposed model achieved a higher accuracy and recall for DME and RVO than all the works, except for Khan et al. [
18], which had higher accuracy and recall for RVO only. The model uses additional inputs compared to the current literature, accounting for an enriching innovative step that justifies the better results achieved. Regardless of this additional input, the unimodal model application still achieves better results than the current state of the art, with the exception of Khan et al. [
18]. This comparison demonstrates the proposed model’s strong performance relative to the existing literature. Only works that used some OCT scans of each patient are part of the current literature state-of-the-art comparison. Works that used the whole volume of a patient were excluded.
The proposed model offers a clinically applicable approach to distinguishing between RVO and DME and enhances the need to include multimodality imaging and clinical information in the training of AI algorithms. The inclusion of an additional class for other pathologies enhances clinical applicability and differentiates this work. The model’s efficiency is evidenced by its accurate differentiation of eyes in the dataset.
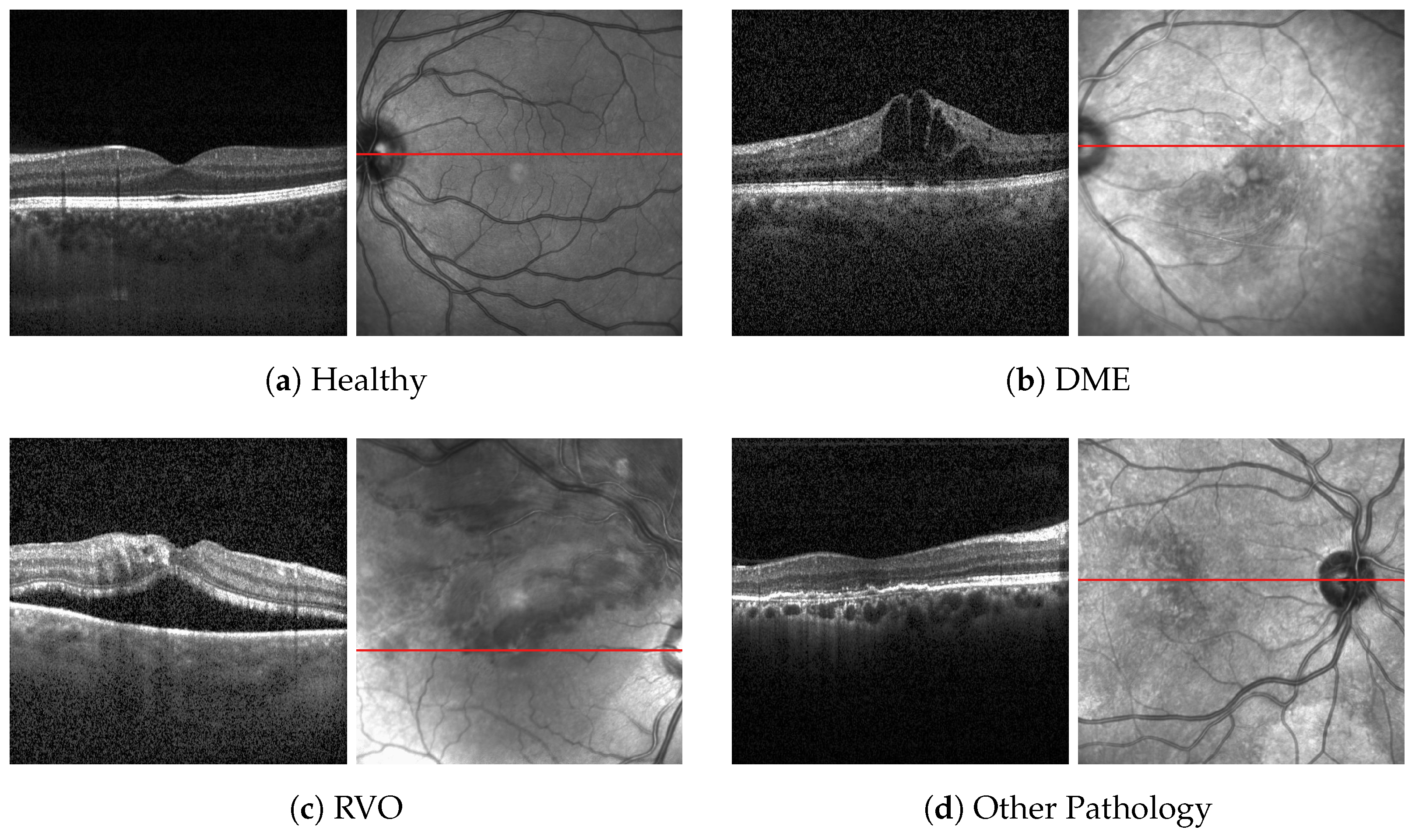
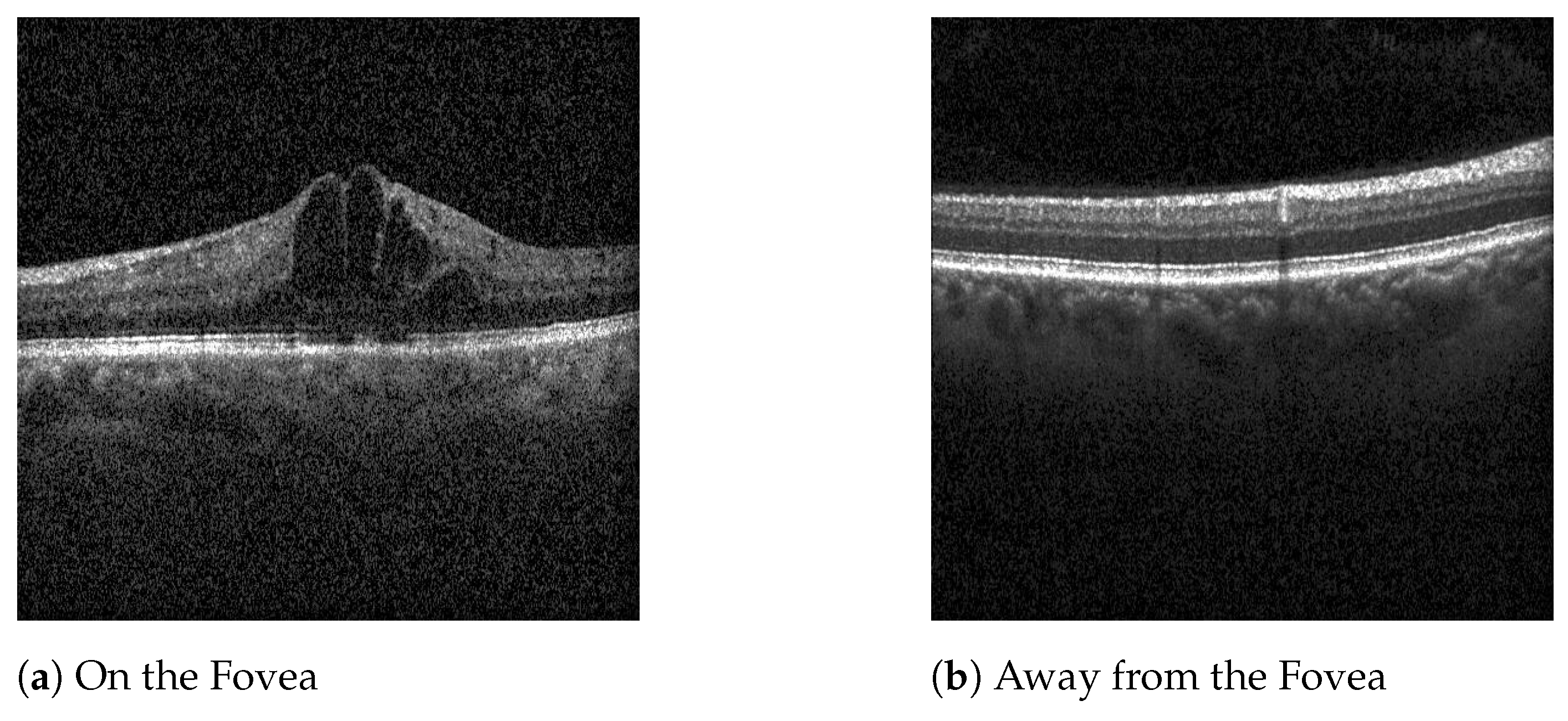
Even though DME or BRVO-related edema can manifest outside the central foveal scans, the dataset used focuses on the five scans nearest the fovea. This decision was motivated by the fact that the central region of the retina is critical for visual acuity, and diseases that impact these regions often require treatment. Macular diseases occurring outside the central region frequently do not necessitate immediate treatment. Therefore, by focusing on the central scans, the model is useful as a screening tool for retinal diseases that impact visual outcomes, confirming disease presence within the central foveal and parafoveal regions. This targeted approach ensures that only patients with treatable conditions affecting vision are flagged for further evaluation, optimizing the screening process and minimizing over-referrals.
However, the work has some limitations. The use of images from a single device may reduce the model’s clinical applicability to other devices, and in the future, it would be important to test the model on images from other devices and consider the incorporation of images from other devices on model training. The model can tell if a patient is healthy or classify them with DME, RVO, or other pathology. In case of a classification with other pathology, the clinicians still need to provide a more accurate diagnosis and identify the pathology. Thus, in future works, it will be necessary to increase the number of classes and specify more retinal diseases.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}