
Evaluating ChatGPT-4 for the Interpretation of Images from Several Diagnostic Techniques in Gastroenterology

 , , , , , , , ,
, , , , , , , , 
Abstract
1. Introduction
2. Methods
2.1. Study Design
2.1.1. Capsule Endoscopy
2.1.2. Device-Assisted Enteroscopy
2.1.3. Endoscopic Ultrasound
2.1.4. Digital Single-Operator Cholangioscopy
2.1.5. High-Resolution Anoscopy
2.2. Prompt Construction
2.3. Statistical Analysis
3. Results
3.1. General Description
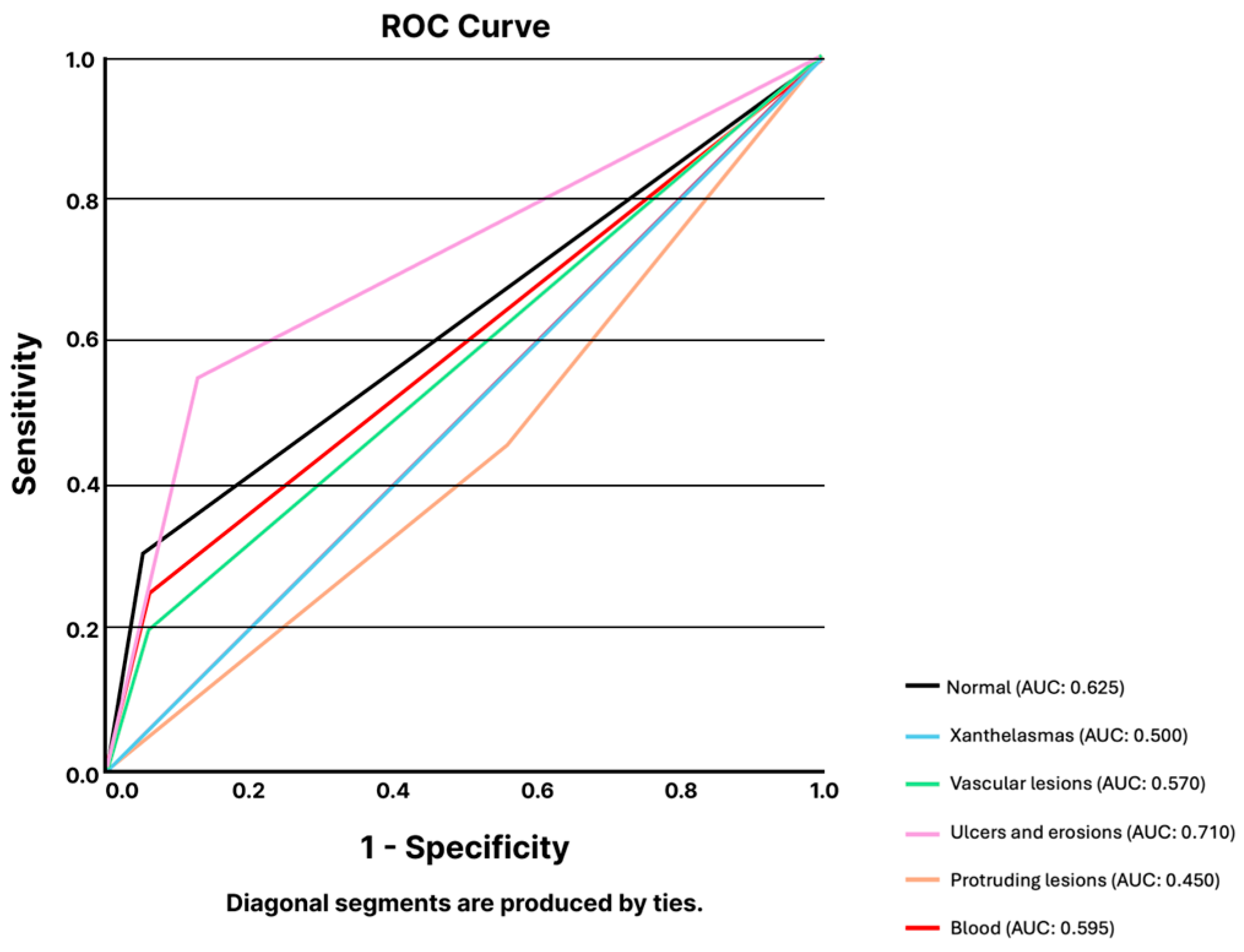
3.1.1. Capsule Endoscopy
Esophagus
Stomach
Small Bowel
Colon
3.1.2. Device-Assisted Enteroscopy
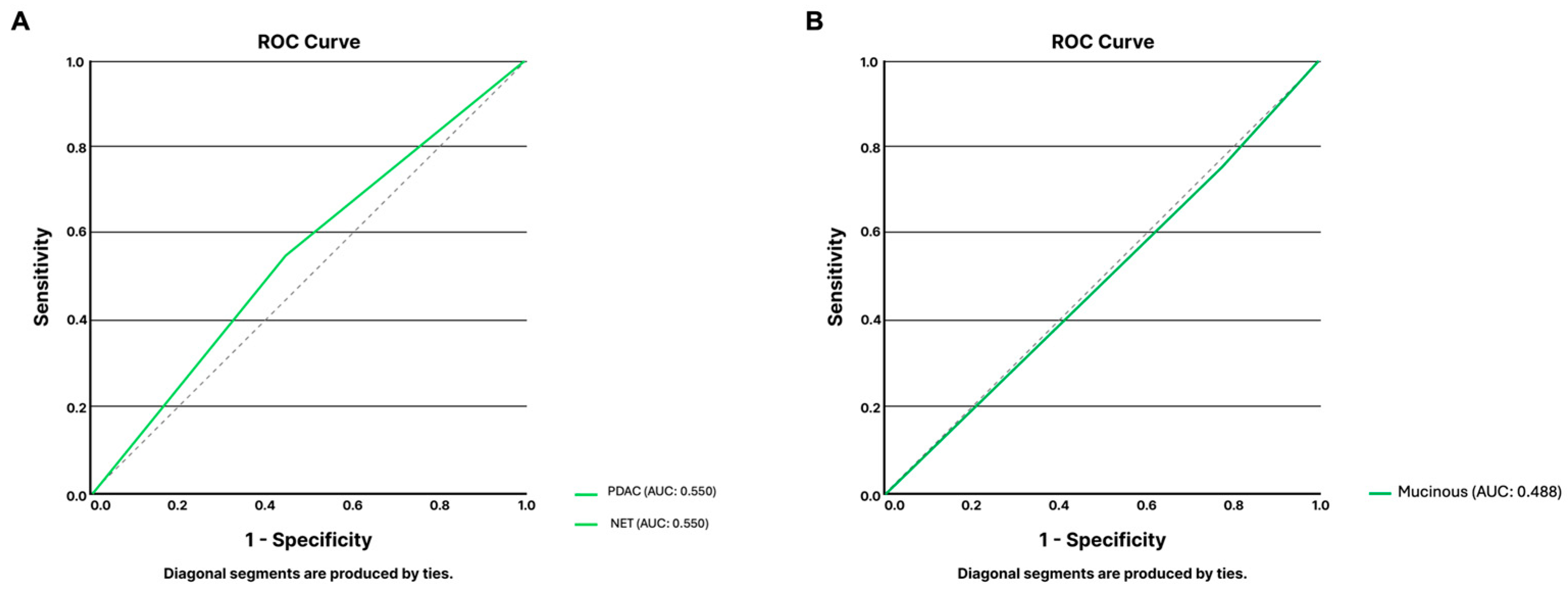
3.1.3. Endoscopic Ultrasound
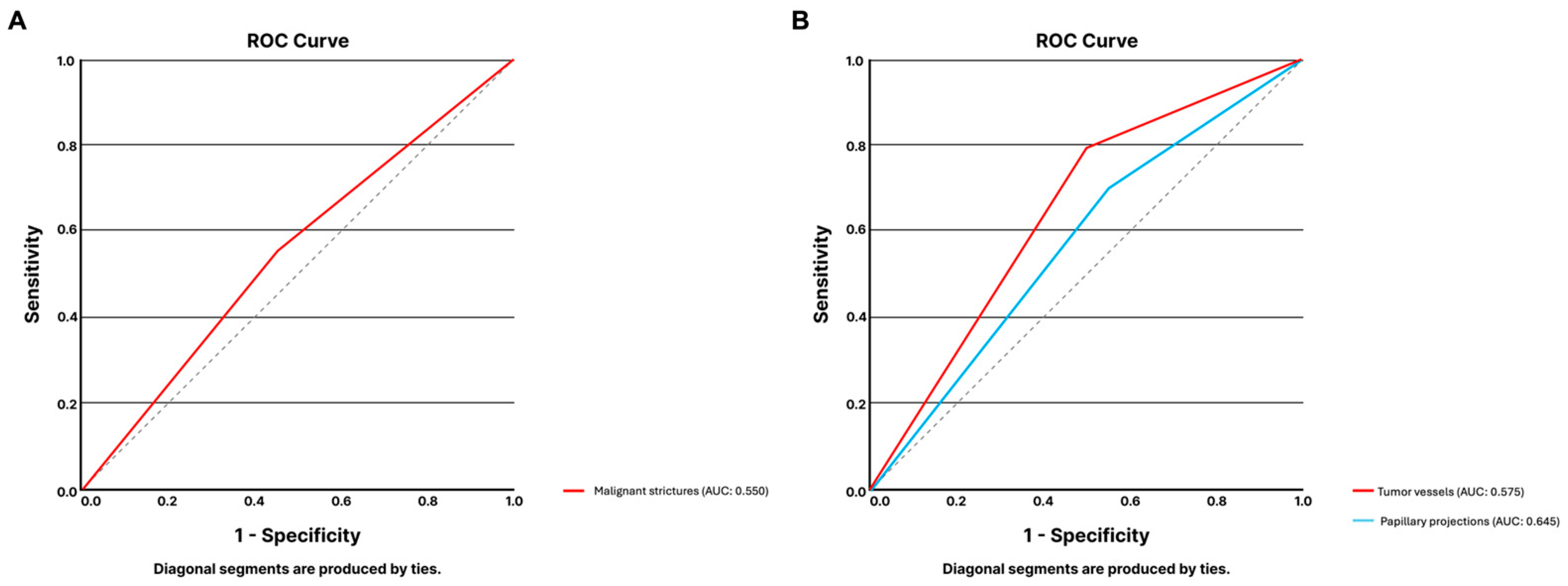
3.1.4. Digital Single-Operator Cholangioscopy
3.1.5. High-Resolution Anoscopy
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Palenzuela, D.L.; Mullen, J.T.; Phitayakorn, R. AI Versus MD: Evaluating the surgical decision-making accuracy of ChatGPT-4. Surgery 2024, 176, 241–245. [Google Scholar] [CrossRef]
- Sonoda, Y.; Kurokawa, R.; Nakamura, Y.; Kanzawa, J.; Kurokawa, M.; Ohizumi, Y.; Gonoi, W.; Abe, O. Diagnostic performances of GPT-4o, Claude 3 Opus, and Gemini 1.5 Pro in “Diagnosis Please” cases. Jpn. J. Radiol. 2024, 42, 1231–1235. [Google Scholar] [CrossRef] [PubMed]
- Lahat, A.; Shachar, E.; Avidan, B.; Shatz, Z.; Glicksberg, B.S.; Klang, E. Evaluating the use of large language model in identifying top research questions in gastroenterology. Sci. Rep. 2023, 13, 4164. [Google Scholar] [CrossRef]
- Koga, S.; Du, W. From text to image: Challenges in integrating vision into ChatGPT for medical image interpretation. Neural Regen. Res. 2025, 20, 487–488. [Google Scholar] [CrossRef] [PubMed]
- Tian, D.; Jiang, S.; Zhang, L.; Lu, X.; Xu, Y. The role of large language models in medical image processing: A narrative review. Quant. Imaging Med. Surg. 2024, 14, 1108–1121. [Google Scholar] [CrossRef] [PubMed]
- AlSaad, R.; Abd-Alrazaq, A.; Boughorbel, S.; Ahmed, A.; Renault, M.A.; Damseh, R.; Sheikh, J. Multimodal Large Language Models in Health Care: Applications, Challenges, and Future Outlook. J. Med. Internet Res. 2024, 26, e59505. [Google Scholar] [CrossRef]
- Lee, T.C.; Staller, K.; Botoman, V.; Pathipati, M.P.; Varma, S.; Kuo, B. ChatGPT Answers Common Patient Questions About Colonoscopy. Gastroenterology 2023, 165, 509–511.e7. [Google Scholar] [CrossRef]
- Henson, J.B.; Glissen Brown, J.R.; Lee, J.P.; Patel, A.; Leiman, D.A. Evaluation of the Potential Utility of an Artificial Intelligence Chatbot in Gastroesophageal Reflux Disease Management. Am. J. Gastroenterol. 2023, 118, 2276–2279. [Google Scholar] [CrossRef] [PubMed]
- Soffer, S.; Klang, E.; Shimon, O.; Nachmias, N.; Eliakim, R.; Ben-Horin, S.; Kopylov, U.; Barash, Y. Deep learning for wireless capsule endoscopy: A systematic review and meta-analysis. Gastrointest. Endosc. 2020, 92, 831–839. [Google Scholar] [CrossRef]
- Dong, Z.; Wang, J.; Li, Y.; Deng, Y.; Zhou, W.; Zeng, X.; Gong, D.; Liu, J.; Pan, J.; Shang, R.; et al. Explainable artificial intelligence incorporated with domain knowledge diagnosing early gastric neoplasms under white light endoscopy. NPJ Digit. Med. 2023, 6, 64. [Google Scholar] [CrossRef] [PubMed]
- Ge, J.; Chen, I.Y.; Pletcher, M.J.; Lai, J.C. Prompt Engineering for Generative Artificial Intelligence in Gastroenterology and Hepatology. Am. J. Gastroenterol. 2024, 119, 1709–1713. [Google Scholar] [CrossRef] [PubMed]
- Dang, F.; Samarasena, J.B. Generative Artificial Intelligence for Gastroenterology: Neither Friend nor Foe. Am. J. Gastroenterol. 2023, 118, 2146–2147. [Google Scholar] [CrossRef]
- Le Berre, C.; Sandborn, W.J.; Aridhi, S.; Devignes, M.D.; Fournier, L.; Smail-Tabbone, M.; Danese, S.; Peyrin-Biroulet, L. Application of Artificial Intelligence to Gastroenterology and Hepatology. Gastroenterology 2020, 158, 76–94.e2. [Google Scholar] [CrossRef]
- Javan, R.; Kim, T.; Mostaghni, N. GPT-4 Vision: Multi-Modal Evolution of ChatGPT and Potential Role in Radiology. Cureus 2024, 16, e68298. [Google Scholar] [CrossRef] [PubMed]
- Hirosawa, T.; Harada, Y.; Tokumasu, K.; Ito, T.; Suzuki, T.; Shimizu, T. Evaluating ChatGPT-4’s Diagnostic Accuracy: Impact of Visual Data Integration. JMIR Med. Inform. 2024, 12, e55627. [Google Scholar] [CrossRef]
- Hirosawa, T.; Kawamura, R.; Harada, Y.; Mizuta, K.; Tokumasu, K.; Kaji, Y.; Suzuki, T.; Shimizu, T. ChatGPT-Generated Differential Diagnosis Lists for Complex Case-Derived Clinical Vignettes: Diagnostic Accuracy Evaluation. JMIR Med. Inform. 2023, 11, e48808. [Google Scholar] [CrossRef] [PubMed]
- Gorelik, Y.; Ghersin, I.; Arraf, T.; Ben-Ishay, O.; Klein, A.; Khamaysi, I. Using a customized GPT to provide guideline-based recommendations for management of pancreatic cystic lesions. Endosc. Int. Open 2024, 12, E600–E603. [Google Scholar] [CrossRef] [PubMed]
- Dehdab, R.; Brendlin, A.; Werner, S.; Almansour, H.; Gassenmaier, S.; Brendel, J.M.; Nikolaou, K.; Afat, S. Evaluating ChatGPT-4V in chest CT diagnostics: A critical image interpretation assessment. Jpn. J. Radiol. 2024, 42, 1168–1177. [Google Scholar] [CrossRef]
- Shifai, N.; van Doorn, R.; Malvehy, J.; Sangers, T.E. Can ChatGPT vision diagnose melanoma? An exploratory diagnostic accuracy study. J. Am. Acad. Dermatol. 2024, 90, 1057–1059. [Google Scholar] [CrossRef]
- Mascarenhas Saraiva, M.J.; Afonso, J.; Ribeiro, T.; Ferreira, J.; Cardoso, H.; Andrade, A.P.; Parente, M.; Natal, R.; Mascarenhas Saraiva, M.; Macedo, G. Deep learning and capsule endoscopy: Automatic identification and differentiation of small bowel lesions with distinct haemorrhagic potential using a convolutional neural network. BMJ Open Gastroenterol. 2021, 8, e000753. [Google Scholar] [CrossRef] [PubMed]
- Ding, Z.; Shi, H.; Zhang, H.; Meng, L.; Fan, M.; Han, C.; Zhang, K.; Ming, F.; Xie, X.; Liu, H.; et al. Gastroenterologist-Level Identification of Small-Bowel Diseases and Normal Variants by Capsule Endoscopy Using a Deep-Learning Model. Gastroenterology 2019, 157, 1044–1054. [Google Scholar] [CrossRef]
- Vilas-Boas, F.; Ribeiro, T.; Afonso, J.; Cardoso, H.; Lopes, S.; Moutinho-Ribeiro, P.; Ferreira, J.; Mascarenhas-Saraiva, M.; Macedo, G. Deep Learning for Automatic Differentiation of Mucinous versus Non-Mucinous Pancreatic Cystic Lesions: A Pilot Study. Diagnostics 2022, 12, 2041. [Google Scholar] [CrossRef]
- Robles-Medranda, C.; Baquerizo-Burgos, J.; Alcivar-Vasquez, J.; Kahaleh, M.; Raijman, I.; Kunda, R.; Puga-Tejada, M.; Egas-Izquierdo, M.; Arevalo-Mora, M.; Mendez, J.C.; et al. Artificial intelligence for diagnosing neoplasia on digital cholangioscopy: Development and multicenter validation of a convolutional neural network model. Endoscopy 2023, 55, 719–727. [Google Scholar] [CrossRef] [PubMed]
- Marya, N.B.; Powers, P.D.; Petersen, B.T.; Law, R.; Storm, A.; Abusaleh, R.R.; Rau, P.; Stead, C.; Levy, M.J.; Martin, J.; et al. Identification of patients with malignant biliary strictures using a cholangioscopy-based deep learning artificial intelligence (with video). Gastrointest. Endosc. 2023, 97, 268–278.e1. [Google Scholar] [CrossRef]
- Zhang, X.; Tang, D.; Zhou, J.D.; Ni, M.; Yan, P.; Zhang, Z.; Yu, T.; Zhan, Q.; Shen, Y.; Zhou, L.; et al. A real-time interpretable artificial intelligence model for the cholangioscopic diagnosis of malignant biliary stricture (with videos). Gastrointest. Endosc. 2023, 98, 199–210.e110. [Google Scholar] [CrossRef] [PubMed]
- Saraiva, M.M.; Ribeiro, T.; Ferreira, J.P.S.; Boas, F.V.; Afonso, J.; Santos, A.L.; Parente, M.P.L.; Jorge, R.N.; Pereira, P.; Macedo, G. Artificial intelligence for automatic diagnosis of biliary stricture malignancy status in single-operator cholangioscopy: A pilot study. Gastrointest. Endosc. 2022, 95, 339–348. [Google Scholar] [CrossRef] [PubMed]
- Saraiva, M.M.; Spindler, L.; Fathallah, N.; Beaussier, H.; Mamma, C.; Quesnee, M.; Ribeiro, T.; Afonso, J.; Carvalho, M.; Moura, R.; et al. Artificial intelligence and high-resolution anoscopy: Automatic identification of anal squamous cell carcinoma precursors using a convolutional neural network. Tech. Coloproctol. 2022, 26, 893–900. [Google Scholar] [CrossRef] [PubMed]
- Mascarenhas Saraiva, M.; Spindler, L.; Fathallah, N.; Beaussier, H.; Mamma, C.; Ribeiro, T.; Afonso, J.; Carvalho, M.; Moura, R.; Cardoso, P.; et al. Deep Learning in High-Resolution Anoscopy: Assessing the Impact of Staining and Therapeutic Manipulation on Automated Detection of Anal Cancer Precursors. Clin. Transl. Gastroenterol. 2024, 15, e00681. [Google Scholar] [CrossRef] [PubMed]
- Saraiva, M.M.; Spindler, L.; Manzione, T.; Ribeiro, T.; Fathallah, N.; Martins, M.; Cardoso, P.; Mendes, F.; Fernandes, J.; Ferreira, J.; et al. Deep Learning and High-Resolution Anoscopy: Development of an Interoperable Algorithm for the Detection and Differentiation of Anal Squamous Cell Carcinoma Precursors-A Multicentric Study. Cancers 2024, 16, 1909. [Google Scholar] [CrossRef]
- Zondag, A.G.M.; Rozestraten, R.; Grimmelikhuijsen, S.G.; Jongsma, K.R.; van Solinge, W.W.; Bots, M.L.; Vernooij, R.W.M.; Haitjema, S. The Effect of Artificial Intelligence on Patient-Physician Trust: Cross-Sectional Vignette Study. J. Med. Internet Res. 2024, 26, e50853. [Google Scholar] [CrossRef]
- Shevtsova, D.; Ahmed, A.; Boot, I.W.A.; Sanges, C.; Hudecek, M.; Jacobs, J.J.L.; Hort, S.; Vrijhoef, H.J.M. Trust in and Acceptance of Artificial Intelligence Applications in Medicine: Mixed Methods Study. JMIR Hum. Factors 2024, 11, e47031. [Google Scholar] [CrossRef] [PubMed]
- Meskó, B. Prompt Engineering as an Important Emerging Skill for Medical Professionals: Tutorial. J. Med. Internet Res. 2023, 25, e50638. [Google Scholar] [CrossRef]
- Goh, E.; Gallo, R.; Hom, J.; Strong, E.; Weng, Y.; Kerman, H.; Cool, J.A.; Kanjee, Z.; Parsons, A.S.; Ahuja, N.; et al. Large Language Model Influence on Diagnostic Reasoning: A Randomized Clinical Trial. JAMA Netw. Open 2024, 7, e2440969. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensitivity | Specificity | PPV | NPV | Accuracy | |
|---|---|---|---|---|---|
| X/L vs. N, % | 0.0 | 100.0 | - | 85.7 | 85.7 |
| V vs. N, % | 66.7 | 85.7 | 80.0 | 75.0 | 76.9 |
| U/E vs. N, % | 100.0 | 85.7 | 91.7 | 100.0 | 94.4 |
| PR vs. N, % | 81.8 | 40.0 | 50.0 | 75.0 | 57.7 |
| Blood vs. N, % | 100.0 | 66.7 | 62.5 | 100.0 | 78.6 |
| V vs. X/L, % | 100.0 | 0.0 | 57.1 | - | 57.1 |
| U/E vs. X/L, % | 100.0 | - | 100.0 | - | 100.0 |
| PR vs. X/L, % | 100.0 | 0.0 | 36.0 | - | 36.0 |
| Blood vs. X/L, % | 100.0 | - | 100.0 | - | 100.0 |
| U/E vs. V, % | 91.7 | 66.7 | 84.6 | 80.0 | 83.3 |
| PR vs. V, % | 90.0 | 28.6 | 47.4 | 80.0 | 54.2 |
| Blood vs. V, % | 100.0 | 66.7 | 71.4 | 100.0 | 81.8 |
| PR vs. U/E, % | 56.3 | 57.9 | 52.9 | 61.1 | 57.1 |
| Blood vs. U/E, % | 62.5 | 100.0 | 100.0 | 78.6 | 84.2 |
| Blood vs. PR, % | 41.7 | 90.0 | 83.3 | 42.9 | 51.9 |
| N vs. All, % | 30.0 | 95.0 | 54.5 | 87.2 | 84.2 |
| X/L vs. All, % | 0.0 | 100.0 | - | 83.3 | 83.3 |
| V vs. All, % | 20.0 | 94.0 | 40.0 | 85.5 | 81.7 |
| U/E vs. All, % | 55.0 | 87.0 | 48.5 | 90.6 | 81.7 |
| PR vs. All, % | 45.0 | 45.0 | 14.1 | 80.4 | 45.0 |
| Blood vs. All, % | 33.3 | 94.0 | 45.5 | 86.2 | 82.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saraiva, M.M.; Ribeiro, T.; Agudo, B.; Afonso, J.; Mendes, F.; Martins, M.; Cardoso, P.; Mota, J.; Almeida, M.J.; Costa, A.; et al. Evaluating ChatGPT-4 for the Interpretation of Images from Several Diagnostic Techniques in Gastroenterology. J. Clin. Med. 2025, 14, 572. https://doi.org/10.3390/jcm14020572
Saraiva MM, Ribeiro T, Agudo B, Afonso J, Mendes F, Martins M, Cardoso P, Mota J, Almeida MJ, Costa A, et al. Evaluating ChatGPT-4 for the Interpretation of Images from Several Diagnostic Techniques in Gastroenterology. Journal of Clinical Medicine. 2025; 14(2):572. https://doi.org/10.3390/jcm14020572
Chicago/Turabian StyleSaraiva, Miguel Mascarenhas, Tiago Ribeiro, Belén Agudo, João Afonso, Francisco Mendes, Miguel Martins, Pedro Cardoso, Joana Mota, Maria Joao Almeida, António Costa, and et al. 2025. "Evaluating ChatGPT-4 for the Interpretation of Images from Several Diagnostic Techniques in Gastroenterology" Journal of Clinical Medicine 14, no. 2: 572. https://doi.org/10.3390/jcm14020572
APA StyleSaraiva, M. M., Ribeiro, T., Agudo, B., Afonso, J., Mendes, F., Martins, M., Cardoso, P., Mota, J., Almeida, M. J., Costa, A., Gonzalez Haba Ruiz, M., Widmer, J., Moura, E., Javed, A., Manzione, T., Nadal, S., Barroso, L. F., de Parades, V., Ferreira, J., & Macedo, G. (2025). Evaluating ChatGPT-4 for the Interpretation of Images from Several Diagnostic Techniques in Gastroenterology. Journal of Clinical Medicine, 14(2), 572. https://doi.org/10.3390/jcm14020572