
Assessing the Accuracy and Readability of Large Language Model Guidance for Patients on Breast Cancer Surgery Preparation and Recovery

 ,
,  and
and 
Abstract
1. Introduction
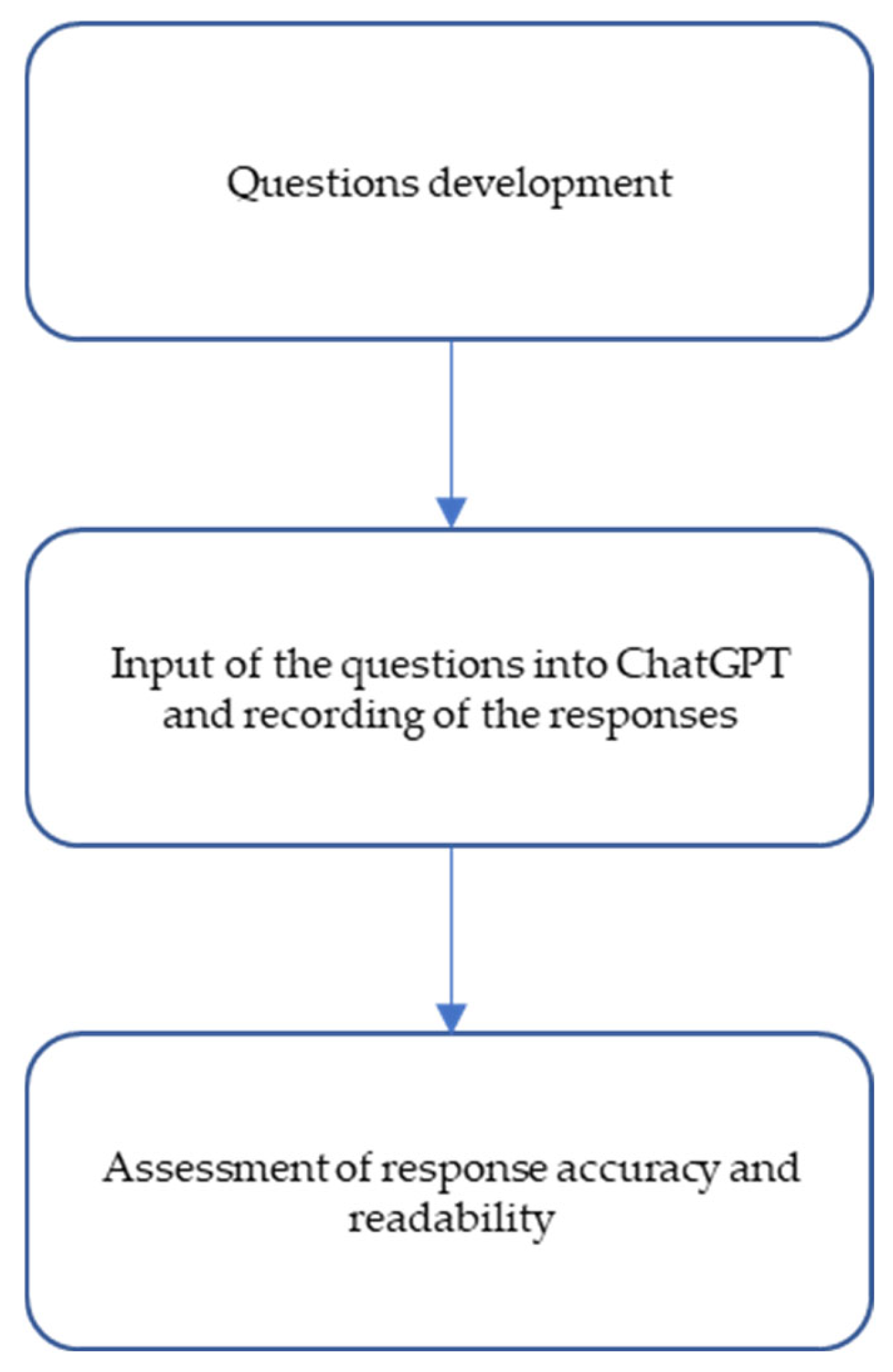
2. Materials and Methods
2.1. Questions
2.2. ChatGPT and Response Generation
2.3. Grading: Accuracy and Readability
- A numerical score reflecting the minimum level of schooling required to understand the text.
- A qualitative classification describing the degree of reading difficulty.
- The corresponding educational level (e.g., elementary school, university) within the U.S. school system [16].
2.4. Statistical Analysis
3. Results
4. Discussion
4.1. Future Directions
4.2. Implications for Clinical Practice
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Loibl, S.; André, F.; Bachelot, T.; Barrios, C.; Bergh, J.; Burstein, H.; Cardoso, M.; Carey, L.; Dawood, S.; Del Mastro, L.; et al. Early Breast Cancer: ESMO Clinical Practice Guideline for Diagnosis, Treatment and Follow-Up☆. Ann. Oncol. 2024, 35, 159–182. [Google Scholar] [CrossRef]
- European Commission, Joint Research Centre. Breast Cancer Factsheet—ECIS 2022; European Cancer Information System: Ispra, Italy, 2023. [Google Scholar]
- Bogdan, R.-G.; Helgiu, A.; Cimpean, A.-M.; Ichim, C.; Todor, S.B.; Iliescu-Glaja, M.; Bodea, I.C.; Crainiceanu, Z.P. Assessing Fat Grafting in Breast Surgery: A Narrative Review of Evaluation Techniques. J. Clin. Med. 2024, 13, 7209. [Google Scholar] [CrossRef]
- Ilie, G.; Knapp, G.; Davidson, A.; Snow, S.; Dahn, H.M.; MacDonald, C.; Tsirigotis, M.; Rutledge, R.D.H. The Cancer Patient Empowerment Program: A Comprehensive Approach to Reducing Psychological Distress in Cancer Survivors, with Insights from a Mixed-Model Analysis, Including Implications for Breast Cancer Patients. Cancers 2024, 16, 3373. [Google Scholar] [CrossRef] [PubMed]
- Marzban, S.; Najafi, M.; Agolli, A.; Ashrafi, E. Impact of Patient Engagement on Healthcare Quality: A Scoping Review. J. Patient Exp. 2022, 9, 23743735221125439. [Google Scholar] [CrossRef] [PubMed]
- Xie, Y.; Seth, I.; Rozen, W.M.; Hunter-Smith, D.J. Evaluation of the Artificial Intelligence Chatbot on Breast Reconstruction and Its Efficacy in Surgical Research: A Case Study. Aesthetic Plast. Surg. 2023, 47, 2360–2369. [Google Scholar] [CrossRef] [PubMed]
- Gummadi, R.; Dasari, N.; Kumar, D.S.; Pindiprolu, S.K.S. Evaluating the Accuracy of Large Language Model (ChatGPT) in Providing Information on Metastatic Breast Cancer. Adv. Pharm. Bull. 2024, 14, 499. [Google Scholar] [CrossRef]
- Braithwaite, D.; Karanth, S.D.; Divaker, J.; Schoenborn, N.; Lin, K.; Richman, I.; Hochhegger, B.; O’Neill, S.; Schonberg, M. Evaluating ChatGPT’s Accuracy in Providing Screening Mammography Recommendations among Older Women: Artificial Intelligence and Cancer Communication. J. Am. Geriatr. Soc. 2024, 72, 2237–2240. [Google Scholar] [CrossRef]
- Shao, C.; Li, H.; Liu, X.; Li, C.; Yang, L.; Zhang, Y.; Luo, J.; Zhao, J. Appropriateness and Comprehensiveness of Using ChatGPT for Perioperative Patient Education in Thoracic Surgery in Different Language Contexts: Survey Study. Interact. J. Med. Res. 2023, 12, e46900. [Google Scholar] [CrossRef]
- Garg, R.K.; Urs, V.L.; Agarwal, A.A.; Chaudhary, S.K.; Paliwal, V.; Kar, S.K. Exploring the Role of ChatGPT in Patient Care (Diagnosis and Treatment) and Medical Research: A Systematic Review. Health Promot. Perspect. 2023, 13, 183. [Google Scholar] [CrossRef]
- Park, K.U.; Lipsitz, S.; Dominici, L.S.; Lynce, F.; Minami, C.A.; Nakhlis, F.; Waks, A.G.; Warren, L.E.; Eidman, N.; Frazier, J.; et al. Generative Artificial Intelligence as a Source of Breast Cancer Information for Patients: Proceed with Caution. Cancer 2025, 131, e35521. [Google Scholar] [CrossRef]
- Snee, I.; Lava, C.X.; Li, K.R.; Del Corral, G. The Utility of ChatGPT in Gender-Affirming Mastectomy Education. J. Plast. Reconstr. Aesthetic Surg. 2024, 99, 432–435. [Google Scholar] [CrossRef]
- Yeo, Y.H.; Samaan, J.S.; Ng, W.H.; Ting, P.-S.; Trivedi, H.; Vipani, A.; Ayoub, W.; Yang, J.D.; Liran, O.; Spiegel, B.; et al. Assessing the Performance of ChatGPT in Answering Questions Regarding Cirrhosis and Hepatocellular Carcinoma. Clin. Mol. Hepatol. 2023, 29, 721. [Google Scholar] [CrossRef]
- Fatima, A.; Shafique, M.A.; Alam, K.; Ahmed, T.K.F.; Mustafa, M.S. ChatGPT in Medicine: A Cross-Disciplinary Systematic Review of ChatGPT’s (Artificial Intelligence) Role in Research, Clinical Practice, Education, and Patient Interaction. Medicine 2024, 103, e39250. [Google Scholar] [CrossRef] [PubMed]
- Yalamanchili, A.; Sengupta, B.; Song, J.; Lim, S.; Thomas, T.O.; Mittal, B.B.; Abazeed, M.E.; Teo, P.T. Quality of Large Language Model Responses to Radiation Oncology Patient Care Questions. JAMA Netw. Open 2024, 7, e244630. [Google Scholar] [CrossRef] [PubMed]
- Flesch, R. A New Readability Yardstick. J. Appl. Psychol. 1948, 32, 221. [Google Scholar] [CrossRef]
- Flesch Reading Ease and the Flesch Kincaid Grade Level. Available online: https://Readable.Com/Readability/Flesch-Reading-Ease-Flesch-Kincaid-Grade-Level/ (accessed on 25 November 2024).
- Moazzam, Z.; Cloyd, J.; Lima, H.A.; Pawlik, T.M. Quality of ChatGPT Responses to Questions Related to Pancreatic Cancer and Its Surgical Care. Ann. Surg. Oncol. 2023, 30, 6284–6286. [Google Scholar] [CrossRef]
- Haver, H.L.; Ambinder, E.B.; Bahl, M.; Oluyemi, E.T.; Jeudy, J.; Yi, P.H. Appropriateness of Breast Cancer Prevention and Screening Recommendations Provided by ChatGPT. Radiology 2023, 307, e230424. [Google Scholar] [CrossRef]
- Haver, H.L.; Gupta, A.K.; Ambinder, E.B.; Bahl, M.; Oluyemi, E.T.; Jeudy, J.; Yi, P.H. Evaluating the Use of ChatGPT to Accurately Simplify Patient-Centered Information about Breast Cancer Prevention and Screening. Radiol. Imaging Cancer 2024, 6, e230086. [Google Scholar] [CrossRef]
- Liu, H.Y.; Bonetti, M.A.; Jeong, T.; Pandya, S.; Nguyen, V.T.; Egro, F.M. Dr. ChatGPT Will See You Now: How Do Google and ChatGPT Compare in Answering Patient Questions on Breast Reconstruction? J. Plast. Reconstr. Aesthetic Surg. 2023, 85, 488–497. [Google Scholar] [CrossRef]
- Liu, H.Y.; Alessandri Bonetti, M.; De Lorenzi, F.; Gimbel, M.L.; Nguyen, V.T.; Egro, F.M. Consulting the Digital Doctor: Google versus ChatGPT as Sources of Information on Breast Implant-Associated Anaplastic Large Cell Lymphoma and Breast Implant Illness. Aesthetic Plast. Surg. 2024, 48, 590–607. [Google Scholar] [CrossRef]
- Pan, A.; Musheyev, D.; Bockelman, D.; Loeb, S.; Kabarriti, A.E. Assessment of Artificial Intelligence Chatbot Responses to Top Searched Queries about Cancer. JAMA Oncol. 2023, 9, 1437–1440. [Google Scholar] [CrossRef]
- Bayley, E.M.; Liu, H.Y.; Bonetti, M.A.; Egro, F.M.; Diego, E.J. ChatGPT as Valuable Patient Education Resource in Breast Cancer Care. Ann. Surg. Oncol. 2025, 32, 653–655. [Google Scholar] [CrossRef]
- Ye, Z.; Zhang, B.; Zhang, K.; Méndez, M.J.G.; Yan, H.; Wu, T.; Qu, Y.; Jiang, Y.; Xue, P.; Qiao, Y. An Assessment of ChatGPT’s Responses to Frequently Asked Questions about Cervical and Breast Cancer. BMC Women’s Health 2024, 24, 482. [Google Scholar] [CrossRef]
- Nabieva, N.; Brucker, S.Y.; Gmeiner, B. ChatGPT’s Agreement with the Recommendations from the 18th St. Gallen International Consensus Conference on the Treatment of Early Breast Cancer. Cancers 2024, 16, 4163. [Google Scholar] [CrossRef] [PubMed]
- Stalp, J.L.; Denecke, A.; Jentschke, M.; Hillemanns, P.; Klapdor, R. Quality of chatGPT-Generated Therapy Recommendations for Breast Cancer Treatment in Gynecology. Curr. Oncol. 2024, 31, 3845–3854. [Google Scholar] [CrossRef] [PubMed]
- Namkoong, K.; Shah, D.V.; Han, J.Y.; Kim, S.C.; Yoo, W.; Fan, D.; McTavish, F.M.; Gustafson, D.H. Expression and Reception of Treatment Information in Breast Cancer Support Groups: How Health Self-Efficacy Moderates Effects on Emotional Well-Being. Patient Educ. Couns. 2010, 81, S41–S47. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
| Flesch-Kincaid Score | Reading Level | School Level |
|---|---|---|
| 0–3 | Basic | Kindergarten/Elementary |
| 3–6 | Basic | Elementary |
| 6–9 | Average | Middle School |
| 9–12 | Average | High School |
| 12–15 | Advanced | College |
| 15–18 | Advanced | Post-grad |
| N | ChatGPT-4o (N = 15) | |
|---|---|---|
| FKGL | 15 | 11.2 (10.0, 11.8) |
| Accuracy | 15 | |
| Comprehensive | 11 (73%) | |
| Correct but incomplete | 4 (27%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Palmarin, E.; Lando, S.; Marchet, A.; Saibene, T.; Michieletto, S.; Cagol, M.; Milardi, F.; Gregori, D.; Lorenzoni, G. Assessing the Accuracy and Readability of Large Language Model Guidance for Patients on Breast Cancer Surgery Preparation and Recovery. J. Clin. Med. 2025, 14, 5411. https://doi.org/10.3390/jcm14155411
Palmarin E, Lando S, Marchet A, Saibene T, Michieletto S, Cagol M, Milardi F, Gregori D, Lorenzoni G. Assessing the Accuracy and Readability of Large Language Model Guidance for Patients on Breast Cancer Surgery Preparation and Recovery. Journal of Clinical Medicine. 2025; 14(15):5411. https://doi.org/10.3390/jcm14155411
Chicago/Turabian StylePalmarin, Elena, Stefania Lando, Alberto Marchet, Tania Saibene, Silvia Michieletto, Matteo Cagol, Francesco Milardi, Dario Gregori, and Giulia Lorenzoni. 2025. "Assessing the Accuracy and Readability of Large Language Model Guidance for Patients on Breast Cancer Surgery Preparation and Recovery" Journal of Clinical Medicine 14, no. 15: 5411. https://doi.org/10.3390/jcm14155411
APA StylePalmarin, E., Lando, S., Marchet, A., Saibene, T., Michieletto, S., Cagol, M., Milardi, F., Gregori, D., & Lorenzoni, G. (2025). Assessing the Accuracy and Readability of Large Language Model Guidance for Patients on Breast Cancer Surgery Preparation and Recovery. Journal of Clinical Medicine, 14(15), 5411. https://doi.org/10.3390/jcm14155411