
Associations Between DNA Repair Gene Polymorphisms and Breast Cancer Histopathological Subtypes: A Preliminary Study

 ,
,
Abstract
1. Introduction
1.1. Histopathological Types of Breast Cancer
1.2. DNA Repair Pathways in Breast Cancer: Roles of XRCC1, XPD, and CHEK2
1.3. Study Objectives and Scope
2. Materials and Methods
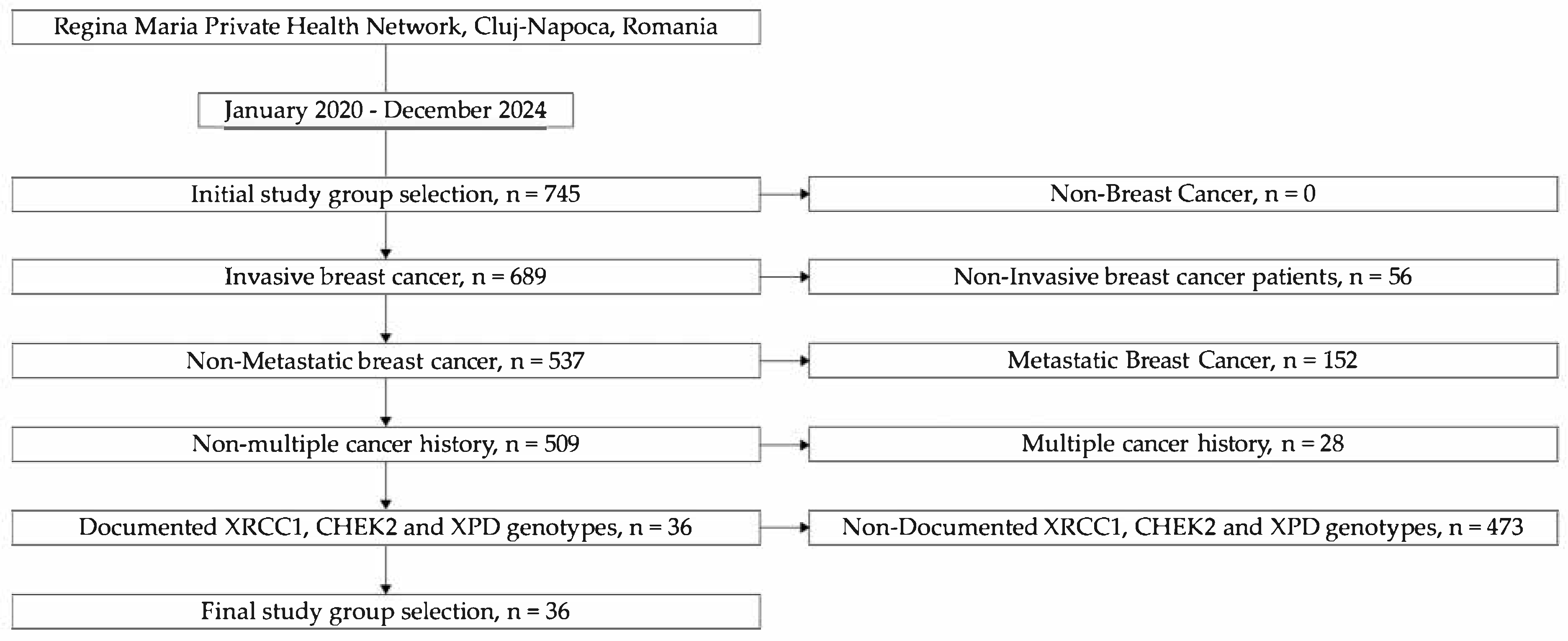
2.1. Patient Selection and Study Design
2.2. Genetic Testing
2.3. Applied Statistical Methods
3. Results
3.1. Descriptive Statistical Analysis
3.2. Genetic Dependency Analysis
3.3. Multinomial Analysis of Genetic Markers in Breast Cancer Histopathological Subtypes
4. Discussion
4.1. Genetic and Clinical Characteristics of the Study Cohort and Interpolymorphism Associations
4.2. Multinomial Logistic Regression Analysis of Breast Cancer Subtypes
4.2.1. Distinct Genotypic and Phenotypic Profiles of CDI TNB vs. CDI LB
4.2.2. Limited Genetic Differentiation Between Luminal Subtypes: CDI LA vs. CDI LB
4.2.3. Reaffirming Triple-Negative Distinctiveness: CDI TNB vs. CDI LA
4.2.4. Interpretation and Translational Relevance
4.3. Implications of DNA Repair Polymorphisms in Breast Cancer
5. Future Directions and Implications
6. Limitations
- Small Sample Size (N = 36): This limits the power to detect subtle associations and increases the likelihood of statistical errors, especially for rare genotypes or subgroup analyses.
- Limited Population Diversity: This study includes only female breast cancer patients from a single geographic region, which may limit applicability to broader populations with different genetic or environmental backgrounds.
- Risk of Overfitting: With a small sample and uneven genotype frequencies, the statistical models (e.g., logistic regression) may overfit the data, leading to inflated or misleading associations.
- Cross-Sectional Design: Data were collected at a single time point, preventing the analysis of cause-and-effect relationships between genotypes and clinical outcomes.
- Narrow Genetic Scope: Only three SNPs (XRCC1, CHEK2, XPD) were studied, which captures only a small part of the genetic landscape involved in breast cancer.
- No Functional Validation: This study relies on statistical associations without experimental data (e.g., gene expression or protein function) to support biological relevance.
- Incomplete Clinical Data: Key clinical variables such as hormonal status, treatment response, and family history were not included, as these details were not consistently available in the records, thereby limiting the depth of clinical interpretation.
- No Healthy Control Group: The absence of a cancer-free comparison group limits this study to within-case analyses, not risk prediction.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
| No. Crt. | Age | BMI | XRCC1 (rs.1799782) | CHEK2 (rs17879961) | XPD (rs238406) | Histopathological Type |
|---|---|---|---|---|---|---|
| 1. | 48 | 20.06 | AT | TC | CA | CDI LB |
| 2. | 77 | 29.78 | AA | CC | AA | CDI TNB |
| 3. | 63 | 29.74 | AT | CC | CA | CDI LB |
| 4. | 39 | 18.87 | TT | TC | CA | CDI LB |
| 5. | 50 | 37.11 | AA | CC | CA | CDI LB |
| 6. | 61 | 35.89 | AA | CC | CA | CDI LB |
| 7. | 57 | 32.51 | AT | TC | CA | CDI LA |
| 8. | 75 | 25.22 | TT | TT | CA | CDI LA |
| 9. | 71 | 31.64 | AA | TC | CC | CDI LB |
| 10. | 68 | 46.61 | AA | CC | AA | CDI LB |
| 11. | 46 | 22.49 | AT | TT | CA | CDI TNB |
| 12. | 61 | 35.94 | AA | CC | CA | CDI LA |
| 13. | 60 | 27.25 | AA | TC | CC | CDI LB |
| 14. | 68 | 28.58 | AT | TT | AA | CDI TNB |
| 15. | 66 | 28.34 | AA | TC | CC | CDI LB |
| 16. | 59 | 37.47 | AT | CC | CA | CDI LB |
| 17. | 64 | 32.89 | TT | TC | CC | CDI LB |
| 18. | 74 | 33.73 | AA | CC | CA | CDI LB |
| 19. | 75 | 29.36 | AA | TC | CC | CDI LB |
| 20. | 52 | 26.78 | AT | CC | CA | CDI LA |
| 21. | 55 | 26.03 | TT | TT | CC | CDI LA |
| 22. | 51 | 27.18 | AA | CC | AA | CDI LB |
| 23. | 61 | 21.23 | AA | TT | CA | CDI LA |
| 24. | 51 | 30.47 | AT | TC | AA | CDI LA |
| 25. | 72 | 29.38 | AA | TT | CA | CDI LA |
| 26. | 67 | 36.06 | AA | CC | AA | CDI LA |
| 27. | 75 | 18.20 | AA | TC | CA | CDI LB |
| 28. | 66 | 20.55 | AA | TC | CC | CDI LB |
| 29. | 38 | 25.30 | AT | TC | CA | CDI LB |
| 30. | 81 | 23.71 | AA | TC | CA | CDI LB |
| 31. | 68 | 26.18 | AA | TT | AA | CDI LB |
| 32. | 52 | 30.11 | AT | CC | CA | CDI LA |
| 33. | 65 | 21.46 | AT | TT | CC | CDI LA |
| 34. | 63 | 27.10 | AA | TC | AA | CDI LA |
| 35. | 56 | 25.64 | AA | TT | AA | CDI LA |
| 36. | 82 | 33.69 | AT | CC | CA | CDI TNB |
References
- Camargo-Herrera, V.; Castellanos, G.; Rangel, N.; Jiménez-Tobón, G.A.; Martínez-Agüero, M.; Rondón-Lagos, M. Patterns of chromosomal instability and clonal heterogeneity in luminal B breast cancer: A pilot study. Int. J. Mol. Sci. 2024, 25, 4478. [Google Scholar] [CrossRef] [PubMed]
- Mehrgou, A.; Akouchekian, M. The Importance of BRCA1 and BRCA2 Genes Mutations in Breast Cancer Development. Med. J. Islam. Repub. Iran. 2016, 30, 369. [Google Scholar] [PubMed]
- Arnold, M.; Morgan, E.; Rumgay, H.; Mafra, A.; Singh, D.; Laversanne, M.; Vignat, J.; Gralow, J.R.; Cardoso, F.; Siesling, S.; et al. Current and future burden of breast cancer: Global statistics for 2020 and 2040. Breast 2022, 66, 15–23. [Google Scholar] [CrossRef] [PubMed]
- Yoshida, R. Hereditary breast and ovarian cancer (HBOC): Review of its molecular characteristics, screening, treatment, and prognosis. Breast Cancer 2020, 28, 1167–1180. [Google Scholar] [CrossRef]
- Muhammad, N.; Hanif, M.; Yang, P. Beyond cisplatin: New frontiers in metallodrugs for hard-to-treat triple negative breast cancer. Coord. Chem. Rev. 2023, 499, 215507. [Google Scholar] [CrossRef]
- Haibe-Kains, B.; Desmedt, C.; Loi, S.; Culhane, A.C.; Bontempi, G.; Quackenbush, J.; Sotiriou, C. A Three-Gene Model to Robustly Identify Breast Cancer Molecular Subtypes. JNCI J. Natl. Cancer Inst. 2012, 104, 311–325. [Google Scholar] [CrossRef]
- Harbeck, N.; Penault-Llorca, F.; Cortes, J.; Gnant, M.; Houssami, N.; Poortmans, P.; Ruddy, K.; Tsang, J.; Cardoso, F. Breast Cancer. Nat. Rev. Dis. Primers 2019, 5, 66. [Google Scholar] [CrossRef]
- Yoshitake, R.; Mori, H.; Ha, D.; Wu, X.; Wang, J.; Wang, X.; Saeki, K.; Chang, G.; Shim, H.J.; Chan, Y.; et al. Molecular features of luminal breast cancer defined through spatial and single-cell transcriptomics. Clin. Transl. Med. 2024, 14, e1548. [Google Scholar] [CrossRef]
- Sørlie, T.; Perou, C.M.; Tibshirani, R.; Aas, T.; Geisler, S.; Johnsen, H.; Hastie, T.; Eisen, M.B.; Van De Rijn, M.; Jeffrey, S.S.; et al. Gene expression patterns of breast carcinomas distinguish tumor subclasses with clinical implications. Proc. Natl. Acad. Sci. USA 2001, 98, 10869–10874. [Google Scholar] [CrossRef]
- Koboldt, D.C.; Fulton, R.S.; McLellan, M.D.; Schmidt, H.; Kalicki-Veizer, J.; McMichael, J.F.; Fulton, L.L.; Dooling, D.J.; Ding, L.; Mardis, E.R.; et al. Comprehensive molecular portraits of human breast tumours. Nature 2012, 490, 61–70. [Google Scholar] [CrossRef]
- Allred, D.C.; Carlson, R.W.; Berry, D.A.; Burstein, H.J.; Edge, S.B.; Goldstein, L.J.; Gown, A.; Hammond, M.E.; Iglehart, J.D.; Moench, S.; et al. NCCN Task Force Report: Estrogen receptor and progesterone receptor testing in breast Cancer by Immunohistochemistry. J. Natl. Compr. Cancer Netw. 2009, 7 (Suppl. 6), S1–S21. [Google Scholar] [CrossRef]
- Gnant, M.; Harbeck, N.; Thomssen, C. St. Gallen 2011: Summary of the Consensus Discussion. Breast Care 2011, 6, 136–141. [Google Scholar] [CrossRef] [PubMed]
- Bidany-Mizrahi, T.; Shweiki, A.; Maroun, K.; Abu-Tair, L.; Mali, B.; Aqeilan, R.I. Unveiling the relationship between WWOX and BRCA1 in mammary tumorigenicity and in DNA repair pathway selection. Cell Death Discov. 2024, 10, 145. [Google Scholar] [CrossRef]
- Chapman, J.R.; Taylor, M.R.G.; Boulton, S.J. Playing the end game: DNA Double-Strand Break Repair Pathway choice. Mol. Cell 2012, 47, 497–510. [Google Scholar] [CrossRef]
- Liu, C.; Srihari, S.; Cao, K.-A.L.; Chenevix-Trench, G.; Simpson, P.T.; Ragan, M.A.; Khanna, K.K. A fine-scale dissection of the DNA double-strand break repair machinery and its implications for breast cancer therapy. Nucleic Acids Res. 2014, 42, 6106–6127. [Google Scholar] [CrossRef] [PubMed]
- Timofeeva, A.A.; Minina, V.I.; Torgunakova, A.V.; Soboleva, O.A.; Titov, R.A.; Zakharova, Y.A.; Bakanova, M.L.; Glushkov, A.N. Polymorphic variants of the hOGG1, APEX1, XPD, SOD2, and CAT genes involved in DNA repair processes and antioxidant defense and their association with breast cancer risk. Vavilov J. Genet. Breed. 2024, 28, 424–432. [Google Scholar] [CrossRef]
- Gohil, D.; Roy, R. Beyond nucleotide excision repair: The importance of XPF in base excision repair and its impact on cancer, inflammation, and aging. Int. J. Mol. Sci. 2024, 25, 13616. [Google Scholar] [CrossRef] [PubMed]
- Duan, M.; Speer, R.M.; Ulibarri, J.; Liu, K.J.; Mao, P. Transcription-coupled nucleotide excision repair: New insights revealed by genomic approaches. DNA Repair 2021, 103, 103126. [Google Scholar] [CrossRef]
- Petruseva, I.O.; Evdokimov, A.N.; Lavrik, O.I. Molecular mechanism of global genome nucleotide excision repair. Acta Naturae 2014, 6, 23–34. [Google Scholar] [CrossRef]
- Matsunaga, T.; Park, C.H.; Bessho, T.; Mu, D.; Sancar, A. Replication protein A confers structure-specific endonuclease activities to the XPF-ERCC1 and XPG subunits of human DNA repair excision nuclease. J. Biol. Chem. 1996, 271, 11047–11050. [Google Scholar] [CrossRef]
- Scharer, O.D. Nucleotide excision repair in eukaryotes. Cold Spring Harb. Perspect. Biol. 2013, 5, a012609. [Google Scholar] [CrossRef] [PubMed]
- Woodrick, J.; Gupta, S.; Camacho, S.; Parvathaneni, S.; Choudhury, S.; Cheema, A.; Bai, Y.; Khatkar, P.; Erkizan, H.V.; Sami, F.; et al. A new sub-pathway of long-patch base excision repair involving 5′ gap formation. EMBO J. 2017, 36, 1605–1622. [Google Scholar] [CrossRef] [PubMed]
- Fisher, L.A.; Samson, L.; Bessho, T. Removal of reactive oxygen species-induced 3′-blocked ends by XPF-ERCC1. Chem. Res. Toxicol. 2011, 24, 1876–1881. [Google Scholar] [CrossRef]
- Zannini, L.; Delia, D.; Buscemi, G. CHK2 kinase in the DNA damage response and beyond. J. Mol. Cell Biol. 2014, 6, 442–457. [Google Scholar] [CrossRef]
- Dorling, L.; Carvalho, S.; Allen, J.; González-Neira, A.; Luccarini, C.; Wahlström, C.; Pooley, K.A.; Parsons, M.T.; Fortuno, C.; Wang, Q.; et al. Breast Cancer Risk Genes—Association Analysis in More than 113,000 Women. New Engl. J. Med. 2021, 384, 428–439. [Google Scholar] [CrossRef] [PubMed]
- Hu, C.; Hart, S.N.; Gnanaolivu, R.; Huang, H.; Lee, K.Y.; Na, J.; Gao, C.; Lilyquist, J.; Yadav, S.; Boddicker, N.J.; et al. A Population-Based study of genes previously implicated in breast cancer. N. Engl. J. Med. 2021, 384, 440–451. [Google Scholar] [CrossRef]
- Huszno, J.; Budryk, M.; Kołosza, Z.; Tęcza, K.; Piłat, J.P.; Nowara, E.; Grzybowska, E. A Comparison between CHEK2*1100delC/I157T Mutation Carrier and Noncarrier Breast Cancer Patients: A Clinicopathological Analysis. Oncology 2016, 90, 193–198. [Google Scholar] [CrossRef]
- Francis, P.A.; Pagani, O.; Fleming, G.F.; Walley, B.A.; Colleoni, M.; Láng, I.; Gómez, H.L.; Tondini, C.; Ciruelos, E.; Burstein, H.J.; et al. Tailoring adjuvant endocrine therapy for premenopausal breast cancer. N. Engl. J. Med. 2018, 379, 122–137. [Google Scholar] [CrossRef]
- Cybulski, C.; Wokołorczyk, D.; Jakubowska, A.; Huzarski, T.; Byrski, T.; Gronwald, J.; Masojć, B.; Dębniak, T.; Górski, B.; Blecharz, P.; et al. Risk of breast cancer in women with a CHEK2 mutation with and without a family history of breast cancer. J. Clin. Oncol. 2011, 29, 3747–3752. [Google Scholar] [CrossRef]
- Roberts, E.; Howell, S.; Evans, D.G. Polygenic risk scores and breast cancer risk prediction. Breast 2023, 67, 71–77. [Google Scholar] [CrossRef]
- Yiangou, K.; Mavaddat, N.; Dennis, J.; Zanti, M.; Wang, Q.; Bolla, M.K.; Abubakar, M.; Ahearn, T.U.; Andrulis, I.L.; Anton-Culver, H.; et al. Polygenic score distribution differences across European ancestry populations: Implications for breast cancer risk prediction. Breast Cancer Res. 2024, 26, 189. [Google Scholar] [CrossRef] [PubMed]
- Abdel-Rahman, S.Z.; Soliman, A.S.; Bondy, M.L.; Omar, S.; El-Badawy, S.A.; Khaled, H.M.; Seifeldin, I.A.; Levin, B. Inheritance of the 194Trp and the 399Gln variant alleles of the DNA repair gene XRCC1 are associated with increased risk of early-onset colorectal carcinoma in Egypt. Cancer Lett. 2000, 159, 79–86. [Google Scholar] [CrossRef] [PubMed]
- Shao, J.; Gu, M.; Xu, Z.; Hu, Q.; Qian, L. Polymorphisms of the DNA gene XPD and risk of bladder cancer in a Southeastern Chinese population. Cancer Genet. Cytogenet. 2007, 177, 30–36. [Google Scholar] [CrossRef]
- Näslund-Koch, C.; Nordestgaard, B.G.; Bojesen, S.E. Increased risk for other cancers in addition to breast cancer for CHEK2*1100DELC heterozygotes estimated from the Copenhagen General Population Study. J. Clin. Oncol. 2016, 34, 1208–1216. [Google Scholar] [CrossRef]
- Cătană, A.; Trifa, A.P.; Achimas-Cadariu, P.A.; Bolba-Morar, G.; Lisencu, C.; Kutasi, E.; Chelaru, V.F.; Muntean, M.; Martin, D.L.; Antone, N.Z.; et al. Hereditary breast cancer in Romania—Molecular particularities and genetic counseling challenges in an Eastern European country. Biomedicines 2023, 11, 1386. [Google Scholar] [CrossRef] [PubMed]
- Hughes, E.; Tshiaba, P.; Gallagher, S.; Wagner, S.; Judkins, T.; Roa, B.; Rosenthal, E.; Domchek, S.; Garber, J.; Lancaster, J.; et al. Development and validation of a clinical polygenic risk score to predict breast cancer risk. JCO Precis. Oncol. 2020, 4, 585–592. [Google Scholar] [CrossRef]
- Mavaddat, N.; Michailidou, K.; Dennis, J.; Lush, M.; Fachal, L.; Lee, A.; Tyrer, J.P.; Chen, T.-H.; Wang, Q.; Bolla, M.K.; et al. Polygenic risk scores for prediction of breast cancer and breast cancer subtypes. Am. J. Hum. Genet. 2018, 104, 21–34. [Google Scholar] [CrossRef]
- Qu, Y.; Qin, S.; Yang, Z.; Li, Z.; Liang, Q.; Long, T.; Wang, W.; Zeng, D.; Zhao, Q.; Dai, Z.; et al. Targeting the DNA repair pathway for breast cancer therapy: Beyond the molecular subtypes. Biomed. Pharmacother. 2023, 169, 115877. [Google Scholar] [CrossRef]
- Dizdar, O.; Arslan, C.; Altundag, K. Advances in PARP inhibitors for the treatment of breast cancer. Expert Opin. Pharmacother. 2015, 16, 2751–2758. [Google Scholar] [CrossRef]
- Sunada, S.; Nakanishi, A.; Miki, Y. Crosstalk of DNA double-strand break repair pathways in poly(ADP-ribose) polymerase inhibitor treatment of breast cancer susceptibility gene 1/2-mutated cancer. Cancer Sci. 2018, 109, 893–899. [Google Scholar] [CrossRef]
- Lynce, F.; Robson, M. Clinical use of PARP inhibitors in BRCA mutant and Non-BRCA mutant breast cancer. Cancer Treat. Res. 2023, 186, 91–102. [Google Scholar] [CrossRef] [PubMed]
- Wolfson, M.; Gribble, S.; Pashayan, N.; Easton, D.F.; Antoniou, A.C.; Lee, A.; Van Katwyk, S.; Simard, J. Potential of polygenic risk scores for improving population estimates of women’s breast cancer genetic risks. Genet. Med. 2021, 23, 2114–2121. [Google Scholar] [CrossRef] [PubMed]
| Mean | SE | 95% CI | Median | SD | Minimum | Maximum | Shapiro–Wilk | |||
|---|---|---|---|---|---|---|---|---|---|---|
| Lower | Upper | W | p | |||||||
| Age | 62.1 | 1.84 | 58.4 | 65.9 | 63 | 11.04 | 38 | 82 | 0.98 | 0.735 |
| BMI | 28.7 | 1.02 | 26.6 | 30.7 | 28.5 | 6.1 | 18.2 | 46.6 | 0.97 | 0.418 |
| XRCC1 (rs.1799782) | CHEK2 (rs17879961) | Total | ||
|---|---|---|---|---|
| TC | CC | TT | ||
| AT | 4 | 5 | 3 | 12 |
| AA | 8 | 8 | 4 | 20 |
| TT | 2 | 0 | 2 | 4 |
| Total | 14 | 13 | 9 | 36 |
| XRCC1 (rs.1799782) | XPD (rs238406) | Total | ||
|---|---|---|---|---|
| CA | AA | CC | ||
| AT | 9 | 2 | 1 | 12 |
| AA | 8 | 7 | 5 | 20 |
| TT | 2 | 0 | 2 | 4 |
| Total | 19 | 9 | 8 | 36 |
| XPD (rs238406) | CHEK2 (rs17879961) | Total | ||
|---|---|---|---|---|
| TC | CC | TT | ||
| CA | 6 | 9 | 4 | 19 |
| AA | 2 | 4 | 3 | 9 |
| CC | 6 | 0 | 2 | 8 |
| Total | 14 | 13 | 9 | 36 |
| HP | Predictor | Estimate | SE | Z | p | OR | 95% CI | |
|---|---|---|---|---|---|---|---|---|
| Lower | Upper | |||||||
| CDI TNB–CDI LB | Intercept | −512.39147 | 2.624 | −195.2720 | <0.001 | 2.96e−223 | 1.73 × 10−225 | 5.07 × 10−221 |
| XRCC1 (rs.1799782): | ||||||||
| AA–AT | −823.94469 | 1.7262 | −477.3045 | <0.001 | 0.000 | 0.0000 | 0.00 | |
| TT–AT | −1212.58863 | 5.85 × 10−13 | −2.07 × 10−15 | <0.001 | 0.000 | 0.0000 | 0.00 | |
| XPD (rs238406): | ||||||||
| AA–CA | 451.74345 | 1.7262 | 261.6913 | <0.001 | 1.55 × 10196 | 5.25 × 10194 | 4.56 × 10197 | |
| CC–CA | −963.01555 | 7.92 × 10−14 | −1.22 × 10−16 | <0.001 | 0.000 | NaN | NaN | |
| CHEK2 (rs17879961): | ||||||||
| CC–TC | 784.00225 | 11.7413 | 66.7730 | <0.001 | Inf | Inf | Inf | |
| TT–TC | 777.40846 | 14.3553 | 54.1548 | <0.001 | Inf | Inf | Inf | |
| BMI | −68.01547 | 4.4690 | −15.2194 | <0.001 | 2.89 × 10−60 | 4.54 × 10−68 | 1.84 × 10−52 | |
| Age | 27.70229 | 1.8797 | 14.7376 | <0.001 | 1.07 × 1024 | 2.70 × 1020 | 4.28 × 1026 | |
| CDI LA–CDI LB | Intercept | −1.34957 | 3.4198 | −0.3946 | 0.693 | 0.259 | 3.18 × 10−12 | 211.28 |
| XRCC1 (rs.1799782): | ||||||||
| AA–AT | −1.82255 | 1.2414 | −1.4682 | 0.142 | 0.162 | 0.0142 | 1.84 | |
| TT–AT | −0.89443 | 1.7996 | −0.4970 | 0.619 | 0.409 | 0.0120 | 13.91 | |
| XPD (rs238406): | ||||||||
| AA–CA | 1.03707 | 1.2343 | 0.8402 | 0.401 | 2.821 | 0.2511 | 31.70 | |
| CC–CA | −1.06826 | 1.6772 | −0.6369 | 0.524 | 0.344 | 0.0128 | 9.20 | |
| CHEK2 (rs17879961): | ||||||||
| CC–TC | 0.18311 | 1.2977 | 0.1411 | 0.888 | 1.201 | 0.0944 | 15.28 | |
| TT–TC | 3.48527 | 1.4635 | 2.3814 | 0.017 | 32.631 | 1.8530 | 574.63 | |
| BMI | 0.03907 | 0.0998 | 0.3916 | 0.695 | 1.040 | 0.8552 | 1.26 | |
| Age | 0.00114 | 0.0599 | 0.0191 | 0.985 | 1.001 | 0.8902 | 1.13 | |
| CDI TNB–CDI LA | Intercept | −217.26075 | 6.2112 | −34.9788 | <0.001 | 4.41 × 10−190 | 2.28 × 10−100 | 8.55 × 10−180 |
| XRCC1 (rs.1799782): | ||||||||
| AA–AT | −598.77619 | 4.1008 | −146.0137 | <0.001 | 9.01 × 10−261 | 2.91 × 10−264 | 2.79 × 10−257 | |
| TT–AT | −907.53428 | 2.64 × 10−24 | −3.43 × 10−26 | <0.001 | 0.0000 | NaN | NaN | |
| XPD (rs238406): | ||||||||
| AA–CA | 331.17660 | 4.1008 | 80.7586 | <0.001 | 6.73 × 10143 | 2.18 × 10140 | 2.08 × 10147 | |
| CC–CA | −880.68313 | 0.0000 | −Inf | <0.001 | 0.0000 | 0.00000 | 0.000 | |
| CHEK2 (rs17879961): | ||||||||
| CC–TC | 529.19332 | 27.9455 | 18.9366 | <0.001 | 6.69 × 10229 | 1.09 × 10206 | 4.10 × 10253 | |
| TT–TC | 500.99770 | 34.1327 | 14.6779 | <0.001 | 3.81 × 10217 | 3.36 × 10188 | 4.31 × 10246 | |
| BMI | −54.16329 | 10.6606 | −5.0807 | <0.001 | 3.00 × 10−48 | 2.53 × 10−66 | 3.56 × 10−30 | |
| Age | 20.49428 | 4.4769 | 4.5778 | <0.001 | 7.95 × 1024 | 122972.76617 | 5.14 × 1024 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Filip, C.I.; Cătană, A.; Pîrlog, L.-M.; Pătrășcanu, A.-A.; Militaru, M.S.; Iordănescu, I.; Dindelegan, G.C. Associations Between DNA Repair Gene Polymorphisms and Breast Cancer Histopathological Subtypes: A Preliminary Study. J. Clin. Med. 2025, 14, 3764. https://doi.org/10.3390/jcm14113764
Filip CI, Cătană A, Pîrlog L-M, Pătrășcanu A-A, Militaru MS, Iordănescu I, Dindelegan GC. Associations Between DNA Repair Gene Polymorphisms and Breast Cancer Histopathological Subtypes: A Preliminary Study. Journal of Clinical Medicine. 2025; 14(11):3764. https://doi.org/10.3390/jcm14113764
Chicago/Turabian StyleFilip, Claudiu Ioan, Andreea Cătană, Lorin-Manuel Pîrlog, Andrada-Adelaida Pătrășcanu, Mariela Sanda Militaru, Irina Iordănescu, and George Călin Dindelegan. 2025. "Associations Between DNA Repair Gene Polymorphisms and Breast Cancer Histopathological Subtypes: A Preliminary Study" Journal of Clinical Medicine 14, no. 11: 3764. https://doi.org/10.3390/jcm14113764
APA StyleFilip, C. I., Cătană, A., Pîrlog, L.-M., Pătrășcanu, A.-A., Militaru, M. S., Iordănescu, I., & Dindelegan, G. C. (2025). Associations Between DNA Repair Gene Polymorphisms and Breast Cancer Histopathological Subtypes: A Preliminary Study. Journal of Clinical Medicine, 14(11), 3764. https://doi.org/10.3390/jcm14113764