
Facial Analysis for Plastic Surgery in the Era of Artificial Intelligence: A Comparative Evaluation of Multimodal Large Language Models

 , , and
, , and 
Abstract
:1. Introduction
2. Methods
2.1. Image Dataset
2.2. Assessment Forms
- Qualitative Facial Analysis Form: This form comprised 14 questions assessing various aspects of facial features relevant to plastic surgery, inquiries on key aspects such as skin type and texture identification, the assessment of facial symmetry, and the evaluation of volume and fat distribution. The full form is provided in Table 1.
- Quantitative Ratios Form: This form comprised 15 questions, centering on neoclassical canons and golden ratio calculations to assess the MLLMs’ ability to measure facial proportions and feature relationships. This form specifically focused on evaluating key ratios such as the vertical fifths of the face, the equality of facial thirds, and the relationship between interocular distance and nose width. The full form is provided in Table 2.
2.3. Prompting Protocol
2.4. Validation Process
- Expert Validation (Qualitative Data): Two experienced plastic surgeons independently analyzed each image and completed the qualitative facial analysis form. Serving as the control group, their independent assessments were compared to the MLLM responses. Discrepancies between the two surgeons’ initial evaluations were resolved by consulting a third plastic surgeon, whose evaluation served as the final, gold standard for the form.
- Manual Measurement Validation (Quantitative Data): For the facial ratios form, two researchers independently performed manual measurements of facial ratios in each image using ImageJ Software (v1.54), the standardized measurement technique. The mean of these measurements served as the gold standard for validating the MLLMs’ quantitative responses.
2.5. Data Analysis
- Accuracy: Calculated as the percentage of correct classifications for both categorical and ordinal data.
- Cohen’s Kappa: Used to assess inter-rater reliability between MLLMs and plastic surgeons/manual measurements for categorical data.
- Weighted Cohen’s Kappa: Employed to account for the degree of disagreement in ordered categories for ordinal data.
2.6. Statistical Analysis
3. Results
3.1. The Qualitative Form (General Facial Analysis)
3.1.1. Inter-Model Performance in Qualitative Analysis
3.1.2. Question Difficulty Analysis for Qualitative Form
3.1.3. Facial Image Difficulty Analysis in Qualitative Form
3.2. The Quantitative Form (Facial Ratios and Adherence to Golden Ratio)
3.2.1. Inter-Model Performance in Quantitative Analysis
3.2.2. Question Difficulty Analysis for Quantitative Form
3.2.3. Facial Image Difficulty Analysis in Quantitative Form
3.3. Inter-Rater Reliability of MLLMs
- Qualitative Assessment: Reliability varied considerably. High agreement (κ > 0.7) was observed for some models on questions like “Volume and Fat Distribution in Cheeks”, “Presence of Rhytids”, and “Overall balance and harmony of the face”. However, other questions, notably “Visibility of Platysmal Bands”, and “Fat Herniation of Eyelid” showed consistently poor agreement across all models.
- Quantitative Assessment: Inter-rater reliability was substantially lower than in the qualitative assessment. Most Kappa values were near or below zero, indicating poor agreement between the MLLMs and manual measurements. No question reached substantial levels of agreement.
4. Discussion
4.1. Limitations
4.2. Ethical Considerations
4.3. Future Research Directions
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| MLLM | Multimodal Large Language Model |
| GAN | Generative Adversarial Network |
| ICC | Intraclass Correlation Coefficient |
| ANOVA | Analysis of Variance |
| PHI | Protected Health Information |
References
- Jack, R.E.; Schyns, P.G. The Human Face as a Dynamic Tool for Social Communication. Curr. Biol. 2015, 25, R621–R634. [Google Scholar] [CrossRef] [PubMed]
- Harrar, H.; Myers, S.; Ghanem, A.M. Art or science? An evidence-based approach to human facial beauty a quantitative analysis towards an informed clinical aesthetic practice. Aesthetic Plast. Surg. 2018, 42, 137–146. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.V.; Rieder, E.A.; Schoenberg, E.; Zachary, C.B.; Saedi, N. Patient perception of beauty on social media: Professional and bioethical obligations in esthetics. J. Cosmet. Dermatol. 2020, 19, 1129–1130. [Google Scholar] [CrossRef]
- Loucas, R.; Sauter, B.; Loucas, M.; Leitsch, S.; Haroon, O.; Macek, A.; Graul, S.; Kobler, A.; Holzbach, T. Is There An “Ideal Instagram Face” for Caucasian Female Influencers? A Cross-Sectional Observational Study of Facial Proportions in 100 Top Beauty Influencers. Aesthetic Surg. J. Open Forum 2024, 6, ojae085. [Google Scholar] [CrossRef] [PubMed]
- Miller, L.E.; Kozin, E.D.; Lee, L.N. Reframing Our Approach to Facial Analysis. Otolaryngol. Head Neck Surg. 2020, 162, 595–596. [Google Scholar] [CrossRef]
- Thaller, S.R.; Cohen, M.N. A Comprehensive Guide to Male Aesthetic and Reconstructive Plastic Surgery; Springer Nature: Berlin/Heidelberg, Germany, 2024. [Google Scholar]
- Hom, D.B.; Marentette, L.J. A practical methodology to analyze facial deformities. Otolaryngol. Head Neck Surg. 1993, 109, 826–838. [Google Scholar] [CrossRef]
- Zojaji, R.; Sobhani, E.; Keshavarzmanesh, M.; Dehghan, P.; Meshkat, M. The Association Between Facial Proportions and Patient Satisfaction After Rhinoplasty: A Prospective Study. Plast. Surg. 2019, 27, 167–172. [Google Scholar] [CrossRef]
- Rousseau, M.; Retrouvey, J.M. pfla: A Python Package for Dental Facial Analysis using Computer Vision and Statistical Shape Analysis. J. Open Source Softw. 2018, 3, 855. [Google Scholar] [CrossRef]
- Cook, M.K.; Kaszycki, M.A.; Richardson, I.; Taylor, S.L.; Feldman, S.R. Comparison of two devices for facial skin analysis. J. Cosmet. Dermatol. 2022, 21, 7001–7006. [Google Scholar] [CrossRef]
- Rousseau, M.; Retrouvey, J.-M. Machine learning in orthodontics: Automated facial analysis of vertical dimension for increased precision and efficiency. Am. J. Orthod. Dentofac. Orthop. 2022, 161, 445–450. [Google Scholar] [CrossRef]
- Haider, S.A.; Ho, O.A.; Borna, S.; Gomez-Cabello, C.A.; Pressman, S.M.; Cole, D.; Sehgal, A.; Leibovich, B.C.; Forte, A.J. Use of Multimodal Artificial Intelligence in Surgical Instrument Recognition. Bioengineering 2025, 12, 72. [Google Scholar] [CrossRef] [PubMed]
- Genovese, A.; Borna, S.; Gomez-Cabello, C.A.; Haider, S.A.; Prabha, S.; Trabilsy, M.; Forte, A.J. From Promise to Practice: Harnessing AI’s Power to Transform Medicine. J. Clin. Med. 2025, 14, 1225. [Google Scholar] [CrossRef]
- Lei, C.; Dang, K.; Song, S.; Wang, Z.; Chew, S.P.; Bian, R.; Yang, X.; Guan, Z.; de Abreu Lopes, C.I.M.; Wang, M.H.; et al. AI-assisted facial analysis in healthcare: From disease detection to comprehensive management. Patterns 2025, 6, 101175. [Google Scholar] [CrossRef] [PubMed]
- Kimura, T.; Narita, K.; Oyamada, K.; Ogura, M.; Ito, T.; Okada, T.; Takushima, A. Fine-tuning on AI-driven Video Analysis through Machine Learning; development of an automated evaluation tool of facial palsy. Plast. Reconstr. Surg. 2024. [Google Scholar] [CrossRef]
- Ravelo, V.; Acero, J.; Fuentes-Zambrano, J.; García Guevara, H.; Olate, S. Artificial Intelligence Used for Diagnosis in Facial Deformities: A Systematic Review. J. Pers. Med. 2024, 14, 647. [Google Scholar] [CrossRef]
- Tomášik, J.; Zsoldos, M.; Oravcová, Ľ.; Lifková, M.; Pavleová, G.; Strunga, M.; Thurzo, A. AI and face-driven orthodontics: A scoping review of digital advances in diagnosis and treatment planning. AI 2024, 5, 158–176. [Google Scholar] [CrossRef]
- Kováč, P.; Jackuliak, P.; Bražinová, A.; Varga, I.; Aláč, M.; Smatana, M.; Lovich, D.; Thurzo, A. Artificial Intelligence-Driven Facial Image Analysis for the Early Detection of Rare Diseases: Legal, Ethical, Forensic, and Cybersecurity Considerations. AI 2024, 5, 990–1010. [Google Scholar] [CrossRef]
- AlSaad, R.; Abd-Alrazaq, A.; Boughorbel, S.; Ahmed, A.; Renault, M.A.; Damseh, R.; Sheikh, J. Multimodal Large Language Models in Health Care: Applications, Challenges, and Future Outlook. J. Med. Internet Res. 2024, 26, e59505. [Google Scholar] [CrossRef]
- Salinas, A.; Haim, A.; Nyarko, J. What’s in a name? Auditing large language models for race and gender bias. arXiv 2024, arXiv:240214875. [Google Scholar]
- Fang, X.; Che, S.; Mao, M.; Zhang, H.; Zhao, M.; Zhao, X. Bias of AI-generated content: An examination of news produced by large language models. Sci. Rep. 2024, 14, 5224. [Google Scholar] [CrossRef]
- Chhua, K.; Wen, Z.; Hathalia, V.; Zhu, K.; O’Brien, S. From Bias to Balance: Detecting Facial Expression Recognition Biases in Large Multimodal Foundation Models. arXiv 2024, arXiv:240814842. [Google Scholar]
- Pavlic, A.; Zrinski, M.T.; Katic, V.; Spalj, S. Neoclassical canons of facial beauty: Do we see the deviations? J. Cranio Maxillofac. Surg. 2017, 45, 741–747. [Google Scholar] [CrossRef] [PubMed]
- Hwang, K.; Park, C.Y. The Divine Proportion: Origins and Usage in Plastic Surgery. Plast. Reconstr. Surg. Glob. Open 2021, 9, e3419. [Google Scholar] [CrossRef] [PubMed]
- Vincent, J. ThisPersonDoesNotExist. com Uses AI to Generate Endless Fake Faces; The Verge: Lower Manhattan, NY, USA, 2019; p. 15. [Google Scholar]
- Generator TPDNE-RF. Thispersondoesnotexist.com. 2024. Available online: www.thispersondoesnotexist.com (accessed on 28 June 2024).
- Davison, S.P. Essentials of Plastic Surgery. Plast. Reconstr. Surg. 2007, 120, 2112. [Google Scholar] [CrossRef]
- Jamuar, S.; Palmer, R.; Dawkins, H.; Lee, D.-W.; Helmholz, P.; Baynam, G. 3D facial analysis for rare disease diagnosis and treatment monitoring: Proof-of-concept plan for hereditary angioedema. PLoS Digit. Health 2023, 2, e0000090. [Google Scholar] [CrossRef]
- Zhang, M.M.; Di, W.J.; Song, T.; Yin, N.B.; Wang, Y.Q. Exploring artificial intelligence from a clinical perspective: A comparison and application analysis of two facial age predictors trained on a large-scale Chinese cosmetic patient database. Ski. Res. Technol. 2023, 29, e13402. [Google Scholar] [CrossRef]
- Amirgaliyev, B.; Mussabek, M.; Rakhimzhanova, T.; Zhumadillayeva, A. A Review of Machine Learning and Deep Learning Methods for Person Detection, Tracking and Identification, and Face Recognition with Applications. Sensors 2025, 25, 1410. [Google Scholar] [CrossRef]
- Ali, R.; Cui, H. Artificial Intelligence in Facial Measurement: A New Era of Symmetry and Proportions Analysis. Aesthetic Plast. Surg. 2025, 1–13. [Google Scholar] [CrossRef]
- Ali, R.; Cui, H. Leveraging ChatGPT for enhanced aesthetic evaluations in minimally invasive facial procedures. Aesthetic Plast. Surg. 2024, 49, 950–961. [Google Scholar] [CrossRef]
- Parra-Dominguez, G.S.; Garcia-Capulin, C.H.; Sanchez-Yanez, R.E. Automatic facial palsy diagnosis as a classification problem using regional information extracted from a photograph. Diagnostics 2022, 12, 1528. [Google Scholar] [CrossRef]
- Arora, A.; Zaeem, J.M.; Garg, V.; Jayal, A.; Akhtar, Z. A Deep Learning Approach for Early Detection of Facial Palsy in Video Using Convolutional Neural Networks: A Computational Study. Computers 2024, 13, 200. [Google Scholar] [CrossRef]
- Elyoseph, Z.; Refoua, E.; Asraf, K.; Lvovsky, M.; Shimoni, Y.; Hadar-Shoval, D. Capacity of generative AI to interpret human emotions from visual and textual data: Pilot evaluation study. JMIR Ment. Health 2024, 11, e54369. [Google Scholar] [CrossRef] [PubMed]
- Moridani, M.K.; Jamiee, N.; Saghafi, S. Human-like evaluation by facial attractiveness intelligent machine. Int. J. Cogn. Comput. Eng. 2023, 4, 160–169. [Google Scholar] [CrossRef]
- Arık, S.Ö.; Ibragimov, B.; Xing, L. Fully automated quantitative cephalometry using convolutional neural networks. J. Med. Imaging 2017, 4, 14501. [Google Scholar] [CrossRef]
- Ma, L.; Han, J.; Wang, Z.; Zhang, D. Cephgpt-4: An interactive multimodal cephalometric measurement and diagnostic system with visual large language model. arXiv 2023, arXiv:230707518. [Google Scholar]
- Salinas, C.A.; Liu, A.; Sharaf, B.A. Facial Morphometrics in Black Celebrities: Contemporary Facial Analysis Using an Artificial Intelligence Platform. J. Clin. Med. 2023, 12, 4499. [Google Scholar] [CrossRef]
- Sumon, M.S.I.; Islam, K.R.; Hossain, S.A.; Rafique, T.; Ghosh, R.; Hassan, G.S.; Podder, K.K.; Barhom, N.; Tamimi, F.; Chowdhury, M.E. Self-CephaloNet: A two-stage novel framework using operational neural network for cephalometric analysis. Neural Comput. Appl. 2025, 1–29. [Google Scholar] [CrossRef]
- Maniega-Mañes, I.; Monterde-Hernández, M.; Mora-Barrios, K.; Boquete-Castro, A. Use of a Novel Artificial Intelligence Approach for a Faster and More Precise Computerized Facial Evaluation in Aesthetic Dentistry. J. Esthet. Restor. Dent. 2025, 37, 346–351. [Google Scholar] [CrossRef] [PubMed]
- Pressman, S.M.; Borna, S.; Gomez-Cabello, C.A.; Haider, S.A.; Haider, C.; Forte, A.J. AI and ethics: A systematic review of the ethical considerations of large language model use in surgery research. Healthcare 2024, 12, 825. [Google Scholar] [CrossRef]
- Haider, S.A.; Borna, S.; Gomez-Cabello, C.A.; Pressman, S.M.; Haider, C.R.; Forte, A.J. The Algorithmic Divide: A Systematic Review on AI-Driven Racial Disparities in Healthcare. J. Racial Ethn. Health Disparities 2024, 1–30. [Google Scholar] [CrossRef]
- Yadav, N.; Pandey, S.; Gupta, A.; Dudani, P.; Gupta, S.; Rangarajan, K. Data privacy in healthcare: In the era of artificial intelligence. Indian Dermatol. Online J. 2023, 14, 788–792. [Google Scholar] [CrossRef]
- Zuo, Z.; Watson, M.; Budgen, D.; Hall, R.; Kennelly, C.; Al Moubayed, N. Data anonymization for pervasive health care: Systematic literature mapping study. JMIR Med. Inform. 2021, 9, e29871. [Google Scholar] [CrossRef]
- Khoshab, N.; Donnelly, M.R.; Sayadi, L.R.; Vyas, R.M.; Banyard, D.A. Historical tools of anthropometric facial assessment: A systematic raw data analysis on the applicability of the neoclassical canons and golden ratio. Aesthetic Surg. J. 2022, 42, NP1–NP10. [Google Scholar] [CrossRef] [PubMed]
- Zwahlen, R.A.; Tang, A.T.; Leung, W.K.; Tan, S.K. Does 3-dimensional facial attractiveness relate to golden ratio, neoclassical canons,‘ideal’ratios and ‘ideal’angles? Maxillofac. Plast. Reconstr. Surg. 2022, 44, 28. [Google Scholar] [CrossRef] [PubMed]
- Rossetti, A.; De Menezes, M.; Rosati, R.; Ferrario, V.F.; Sforza, C. The role of the golden proportion in the evaluation of facial esthetics. Angle Orthod. 2013, 83, 801–808. [Google Scholar] [CrossRef] [PubMed]
- Chong, C.; Zelcer, B. Symmetry in Nature and Faces: The Relationship of Beauty Perception and the Role of the Golden Ratio. J. Stud. Res. 2024, 13, 1–10. [Google Scholar] [CrossRef]
- Obermeyer, Z.; Powers, B.; Vogeli, C.; Mullainathan, S. Dissecting racial bias in an algorithm used to manage the health of populations. Science 2019, 366, 447–453. [Google Scholar] [CrossRef]
- Muhammad, D.; Bendechache, M. Unveiling the black box: A systematic review of Explainable Artificial Intelligence in medical image analysis. Comput. Struct. Biotechnol. J. 2024, 24, 542–560. [Google Scholar] [CrossRef]
- Miao, J.; Thongprayoon, C.; Suppadungsuk, S.; Krisanapan, P.; Radhakrishnan, Y.; Cheungpasitporn, W. Chain of Thought Utilization in Large Language Models and Application in Nephrology. Medicina 2024, 60, 148. [Google Scholar] [CrossRef]
- Herruer, J.M.; Prins, J.B.; van Heerbeek, N.; Verhage-Damen, G.W.; Ingels, K.J. Negative predictors for satisfaction in patients seeking facial cosmetic surgery: A systematic review. Plast. Reconstr. Surg. 2015, 135, 1596–1605. [Google Scholar] [CrossRef]
- Kiwan, O.; Al-Kalbani, M.; Rafie, A.; Hijazi, Y. Artificial intelligence in plastic surgery, where do we stand? JPRAS Open 2024, 42, 234–243. [Google Scholar] [CrossRef] [PubMed]
- Berends, B.; Bielevelt, F.; Schreurs, R.; Vinayahalingam, S.; Maal, T.; de Jong, G. Fully automated landmarking and facial segmentation on 3D photographs. Sci. Rep. 2024, 14, 6463. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Question | Options |
|---|---|---|
| 1 | Identify the skin type | Normal, Oily, Dry |
| 2 | Comment on the skin texture | Smooth, Rough, Presence of acne, Scarred |
| 3 | Volume and Fat Distribution in Cheeks | Well-distributed, youthful volume, Slight sagging or descent, Moderate sagging or descent, Severe sagging or loss of volume |
| 4 | How would you rate the overall tone of the skin? | Excellent, Good, Fair, Poor |
| 5 | Presence of Rhytids (Wrinkles) in the face: | No visible wrinkles, Shallow wrinkles, Moderate wrinkles, Deep wrinkles |
| 6 | Using the Glogau classification, determine the degree of photoaging | Glogau Type I: Mild wrinkles, no keratoses, early photoaging, Glogau Type II: Moderate wrinkles, early actinic keratoses, early to moderate photoaging, Glogau Type III: Advanced wrinkles, actinic keratoses, advanced photoaging, Glogau Type IV: Severe wrinkles, actinic keratoses and skin cancers, severe photoaging |
| 7 | Assess the Overall balance and harmony of the face. | Excellent, Good, Fair, Poor |
| 8 | Overall Proportions and Symmetry of the Nose | Proportions and symmetry ideal, Slight disproportion or asymmetry, Moderate disproportion or asymmetry, Severe disproportion or asymmetry |
| 9 | Assess the symmetry of the nasolabial folds | Perfectly symmetrical, Slightly asymmetrical, Moderately asymmetrical, Highly asymmetrical |
| 10 | Assess the depth of the nasolabial folds | Very shallow, Moderately shallow, Moderately deep, Very deep |
| 11 | Extent of Jowls | No jowls, Slight jowls, Moderate jowls, Severe jowls affecting facial contour |
| 12 | Visibility of Platysmal Bands: | No visible banding, Slightly visible bands, Clearly visible bands, Prominently visible bands |
| 13 | Compensated Brow Ptosis | No signs of brow ptosis, Slight compensated brow ptosis, Moderate compensated brow ptosis, Severe compensated brow ptosis |
| 14 | Fat Herniation of Eyelid | No herniation, Slight herniation, Moderate herniation, Severe herniation |
| # | Question | Options |
|---|---|---|
| 1 | Can the face be divided into equal vertical fifths? | Yes, No |
| 2 | Are the Upper 1/3rd, Middle 1/3rd, and Lower 1/3rd of the face equal? | Yes, No |
| 3 | Is the length of an ear equal to the length of the nose? | Yes, No |
| 4 | Is the interocular distance equal to nose width? | Yes, No |
| 5 | Is the interocular distance equal to the width of one eye (right or left eye fissure width)? | Yes, No |
| 6 | Is the mouth width 1.5 times the nose width? | Yes, No |
| 7 | Is the face width equal to 4 times the nose width? | Yes, No |
| 8 | Can the lower face be divided into equal thirds? | Yes, No |
| 9 | Is the width of the face at the malar level equal to the distance from the brows to the menton? | Yes, No |
| 10 | The length of the face is 1.618 times the width of the face? | Ratio significantly less (Ratio less than 1.46), Ratio slightly less (Ratio 1.46–1.53), Ratio is ideal (Approximately 1.618), Ratio slightly more (Ratio 1.68–1.77), Ratio significantly more (Ratio greater than 1.77) |
| 11 | Ear length to nose width ratio | Ratio significantly less (Ratio less than 1.46), Ratio slightly less (Ratio 1.46–1.53), Ratio is ideal (Approximately 1.618), Ratio slightly more (Ratio 1.68–1.77), Ratio significantly more (Ratio greater than 1.77) |
| 12 | Mouth width to interocular distance | Ratio significantly less (Ratio less than 1.46), Ratio slightly less (Ratio 1.46–1.53), Ratio is ideal (Approximately 1.618), Ratio slightly more (Ratio 1.68–1.77), Ratio significantly more (Ratio greater than 1.77) |
| 13 | Mouth width to nose width | Ratio significantly less (Ratio less than 1.46), Ratio slightly less (Ratio 1.46–1.53), Ratio is ideal (Approximately 1.618), Ratio slightly more (Ratio 1.68–1.77), Ratio significantly more (Ratio greater than 1.77) |
| 14 | Lips-chin distance to interocular distance | Ratio significantly less (Ratio less than 1.46), Ratio slightly less (Ratio 1.46–1.53), Ratio is ideal (Approximately 1.618), Ratio slightly more (Ratio 1.68–1.77), Ratio significantly more (Ratio greater than 1.77) |
| 15 | Lips-chin distance to nose width | Ratio significantly less (Ratio less than 1.46), Ratio slightly less (Ratio 1.46–1.53), Ratio is ideal (Approximately 1.618), Ratio slightly more (Ratio 1.68–1.77), Ratio significantly more (Ratio greater than 1.77) |
| Rank | MLLM (Mean Accuracy) | Rank | Question (Mean Accuracy) | Rank | Face (Mean Accuracy) |
|---|---|---|---|---|---|
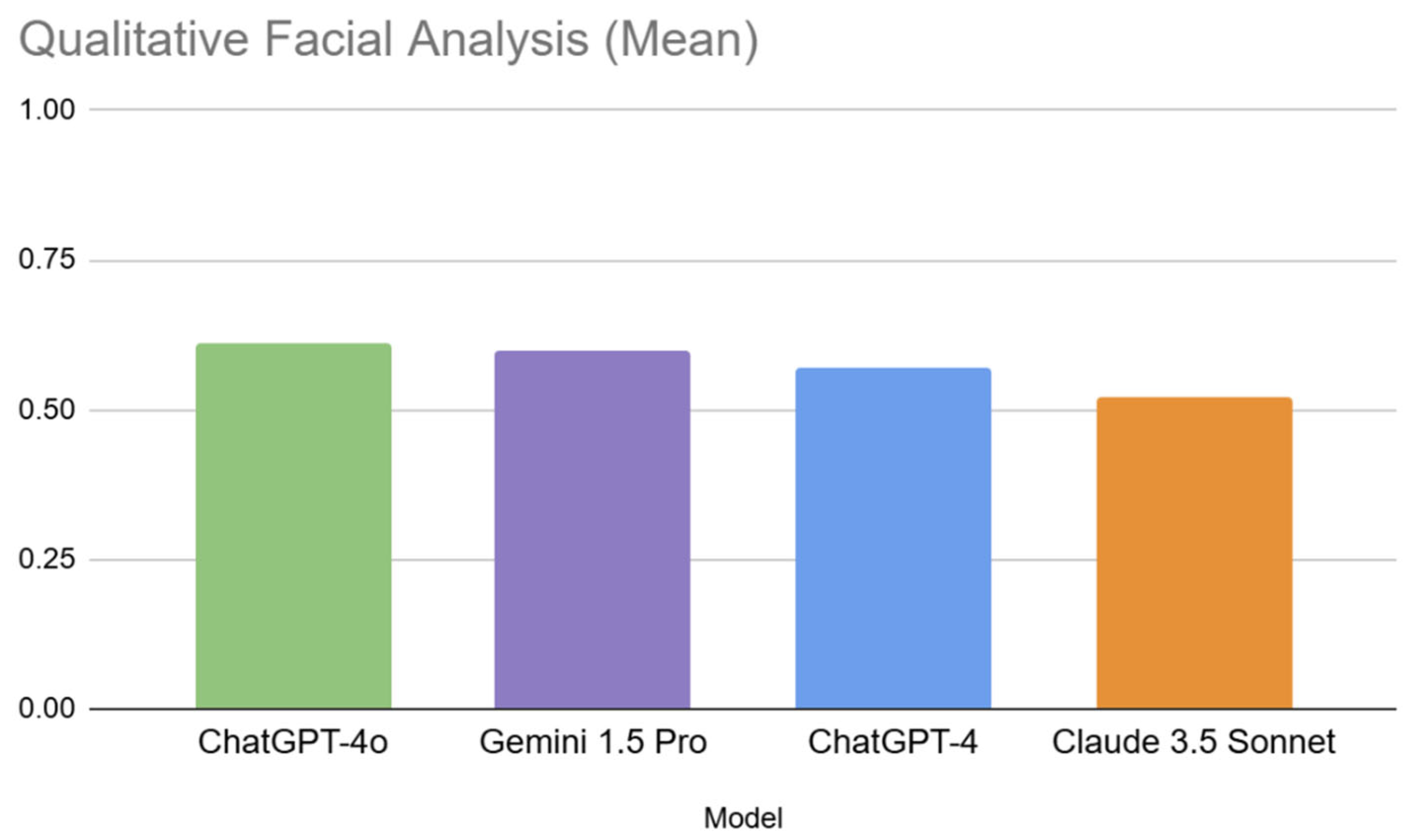
| 1 | ChatGPT-4o (0.61) | 1 | 3. Volume/Fat Distribution in Cheeks (0.82) | 1 | 4 (0.80) |
| 2 | Gemini 1.5 Pro (0.60) | 2 | 11. Extent of Jowls (0.73) | 2 | 2 (0.77) |
| 3 | ChatGPT-4 (0.57) | 3 | 12. Visibility of Platysmal Bands (0.73) | 3 | 9 (0.71) |
| 4 | Claude 3.5 Sonnet (0.52) | 4 | 7. Balance/Harmony of Face (0.70) | 4 | 7 (0.70) |
| 5 | 13. Compensated Brow Ptosis (0.68) | 5 | 14 (0.70) | ||
| 6 | 4. Overall tone of the skin (0.68) | 6 | 15 (0.68) | ||
| 7 | 5. Presence of Rhytids (Wrinkles) (0.65) | 7 | 1 (0.59) | ||
| 8 | 14. Fat Herniation of Eyelid (0.65) | 8 | 11 (0.62) | ||
| 9 | 1. Identify the skin type (0.55) | 9 | 5 (0.64) | ||
| 10 | 10. Depth of nasolabial folds (0.55) | 10 | 10 (0.46) | ||
| 11 | 2. Skin Texture (0.50) | 11 | 3, 12, 13, (0.45) | ||
| 12 | 8. Nose Proportions/Symmetry (0.50) | 12 | 6 (0.36) | ||
| 13 | 9. Symmetry of nasolabial folds (0.27) | ||||
| 14 | 6. Glogau Classification (0.02) |
| Ranking | MLLM (Mean Accuracy) | Rank | Question (Mean Accuracy) | Rank | Face (Mean Accuracy) |
|---|---|---|---|---|---|
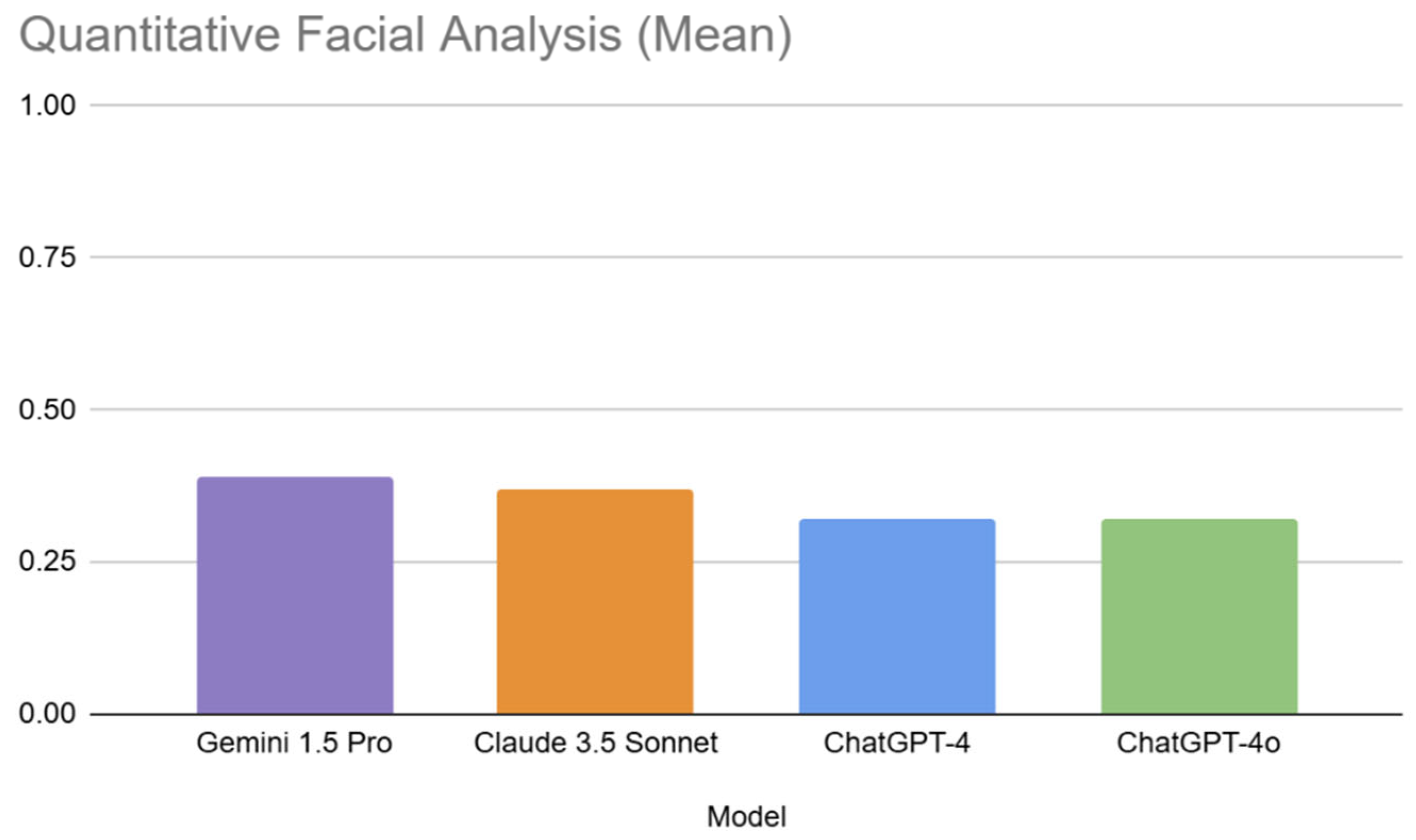
| 1 | Gemini 1.5 Pro (0.39) | 1 | 9. Malar Width = Brow to Menton Distance (0.75) | 1 | 8 (0.50) |
| 2 | Claude 3.5 Sonnet (0.37) | 2 | 8. Lower Face Division into Thirds (0.70) | 2 | 10 (0.47) |
| 3 | ChatGPT-4 (0.32) | 3 | 5. Interocular Distance = Eye Fissure Width (0.53) | 3 | 13 (0.43) |
| 4 | ChatGPT-4o (0.32) | 4 | 6. Mouth Width = 1.5 × Nose Width (0.52) | 4 | 12 (0.42) |
| 5 | 4. Interocular Distance = Nose Width (0.50) | 5 | 7 (0.40) | ||
| 6 | 2. Upper/Middle/Lower Thirds Equality (0.48) | 6 | 1 (0.37) | ||
| 7 | 7. Face Width = 4 × Nose Width (0.48) | 7 | 6 (0.37) | ||
| 8 | 1. Vertical Fifths Equality (0.43) | 8 | 9 (0.35) | ||
| 9 | 3. Ear Length = Nose Length (0.38) | 9 | 5, 11 (0.33) | ||
| 10 | 14. Lips-Chin Distance to Interocular Distance (0.18) | 10 | 3 (0.28) | ||
| 11 | 13. Mouth width to nose width (0.15) | 11 | 2 (0.27) | ||
| 12 | 12. Mouth Width to Interocular Distance (0.12) | 12 | 1, 14, 15 (0.25) | ||
| 13 | 11. Ear Length to Nose Width Ratio (0.020) | ||||
| 14 | 15. Lips-Chin Distance to Nose Width (0.020) | ||||
| 15 | 10. Face Length = 1.618 × Face Width (0.00) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Haider, S.A.; Prabha, S.; Gomez-Cabello, C.A.; Borna, S.; Genovese, A.; Trabilsy, M.; Elegbede, A.; Yang, J.F.; Galvao, A.; Tao, C.; et al. Facial Analysis for Plastic Surgery in the Era of Artificial Intelligence: A Comparative Evaluation of Multimodal Large Language Models. J. Clin. Med. 2025, 14, 3484. https://doi.org/10.3390/jcm14103484
Haider SA, Prabha S, Gomez-Cabello CA, Borna S, Genovese A, Trabilsy M, Elegbede A, Yang JF, Galvao A, Tao C, et al. Facial Analysis for Plastic Surgery in the Era of Artificial Intelligence: A Comparative Evaluation of Multimodal Large Language Models. Journal of Clinical Medicine. 2025; 14(10):3484. https://doi.org/10.3390/jcm14103484
Chicago/Turabian StyleHaider, Syed Ali, Srinivasagam Prabha, Cesar A. Gomez-Cabello, Sahar Borna, Ariana Genovese, Maissa Trabilsy, Adekunle Elegbede, Jenny Fei Yang, Andrea Galvao, Cui Tao, and et al. 2025. "Facial Analysis for Plastic Surgery in the Era of Artificial Intelligence: A Comparative Evaluation of Multimodal Large Language Models" Journal of Clinical Medicine 14, no. 10: 3484. https://doi.org/10.3390/jcm14103484
APA StyleHaider, S. A., Prabha, S., Gomez-Cabello, C. A., Borna, S., Genovese, A., Trabilsy, M., Elegbede, A., Yang, J. F., Galvao, A., Tao, C., & Forte, A. J. (2025). Facial Analysis for Plastic Surgery in the Era of Artificial Intelligence: A Comparative Evaluation of Multimodal Large Language Models. Journal of Clinical Medicine, 14(10), 3484. https://doi.org/10.3390/jcm14103484