
Assessing the Accuracy of Artificial Intelligence Models in Scoliosis Classification and Suggested Therapeutic Approaches

 , ,
, ,
Abstract
1. Introduction
2. Materials and Methods
2.1. Manual Measurements
2.2. AI System Evaluation Methodology
2.3. PMC-LLaMA Methodology
- Treatment scenario prompt
- Cobb angle severity prompt
2.4. Statistical Analysis
3. Results
3.1. Characteristics of the Sample
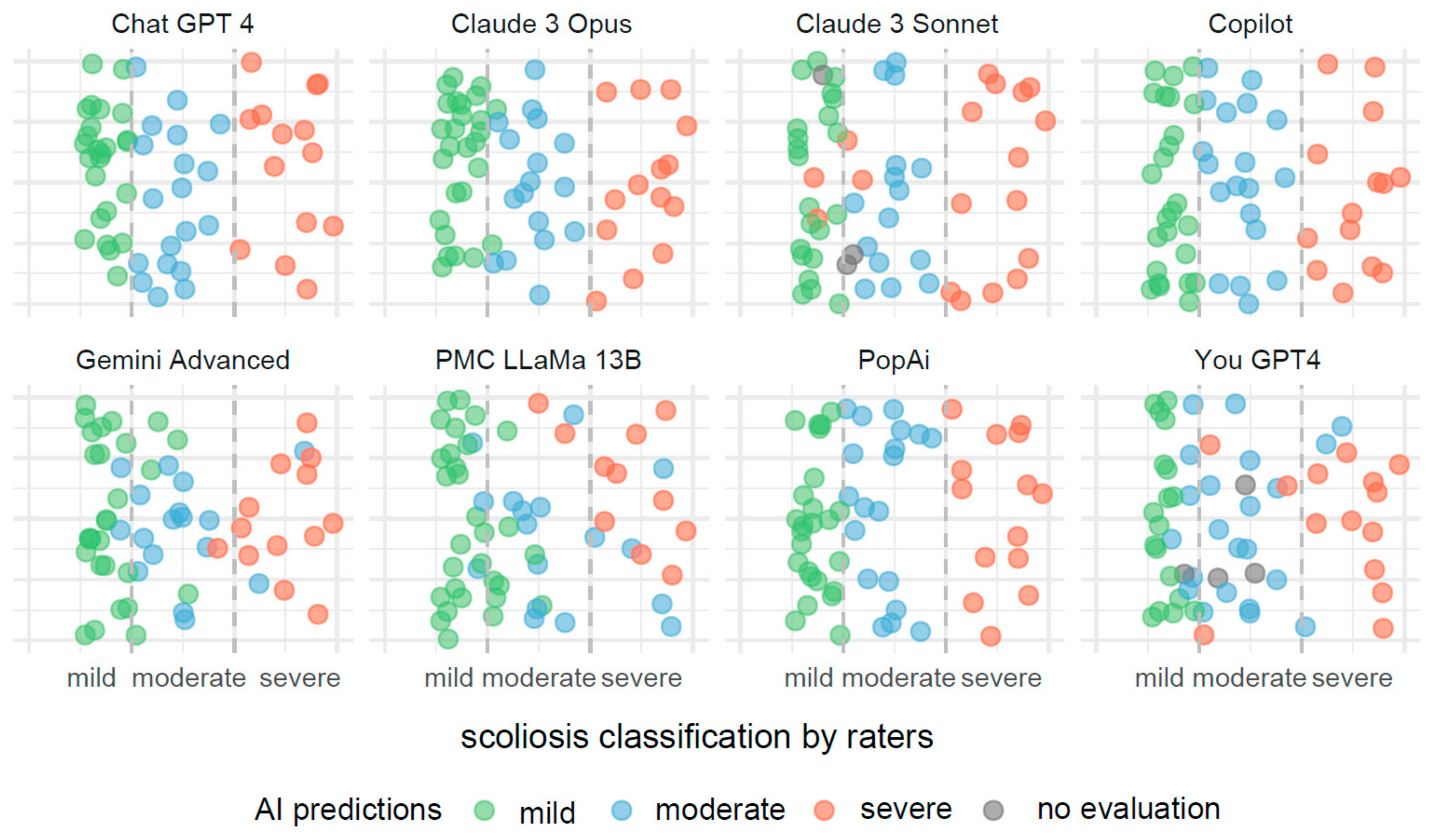
3.2. Alignment and Coherence Analysis of AI Systems for Scoliosis Management
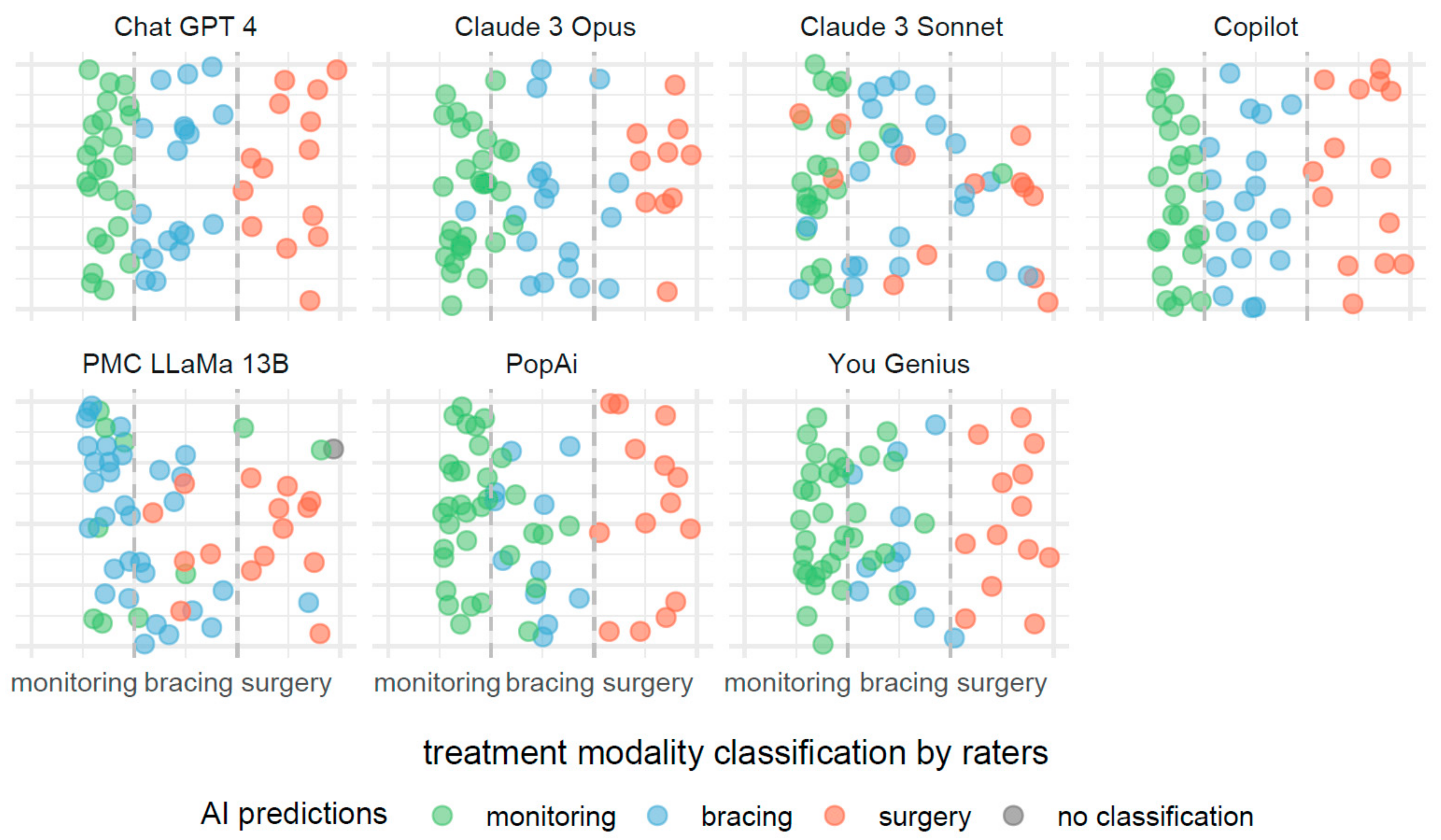
3.3. Comparative Performances of AI Systems in Scoliosis Severity and Treatment Modality Classifications
3.4. Performance Metrics and Confusion Matrix Analysis for Scoliosis Severity Classifications
3.5. Performance Metrics and Confusion Matrix Analysis for Treatment Modality Classifications
4. Discussion
4.1. Analysis of Results and Hypotheses
4.2. Analysis of AI Systems’ Alignments with Reference Classification Standards
4.3. Evaluation of AI Systems’ Treatment Modality Recommendations against Established Clinical Guidelines
4.4. Comparative Analysis of AI Systems’ Internal Coherences across Severity Classifications and Treatment Recommendations
4.5. Overall Conclusions
4.6. Training Data and Domain Specialization
4.7. Model Architecture and Complexity
4.8. Transformer Models and Advanced Architectures
4.9. Impact on Medical Applications
4.10. Prompt Engineering and Model Instructions—Impact of Prompt Engineering
4.11. Model-Specific Improvements
4.12. Model Sensitivity and Threshold Adjustments
4.13. Threshold and Sensitivity Adjustments
4.14. False Positives and Clinical Benefits
4.15. Clinical Decision Support Systems
4.16. Internal Coherence and Algorithm Calibration
4.17. Implications for Clinical Practice
- Adoption of High-Performing Models: Models like ChatGPT 4, Copilot, and PopAi, which demonstrated high alignment with reference standards, could be adopted more readily in clinical settings. Their reliability and consistency make them suitable for aiding healthcare professionals in diagnostic and therapeutic decision-making processes;
- Need for Continuous Model Evaluation and Calibration: Continuous evaluation and recalibration of AI models are essential to maintain their clinical relevance and accuracy. Models like PMC-LLaMA 13B, which showed lower performance, need ongoing refinement, incorporating more diverse and representative training data to enhance their predictive capabilities;
- Tailoring AI to Specific Clinical Needs: Different clinical scenarios might require different AI capabilities. For instance, models with lower thresholds for detecting mild scoliosis could be preferred in preventive care settings, while those with stricter thresholds might be more suitable for specialized surgical planning;
- Ethical Considerations and Bias Mitigation: Ensuring that AI models do not propagate biases present in their training data is crucial. Diverse and representative training datasets, coupled with robust ethical guidelines, are necessary to develop AI systems that provide equitable and unbiased healthcare recommendations.
4.18. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Uppalapati, V.K.; Nag, D.S. A Comparative Analysis of AI Models in Complex Medical Decision-Making Scenarios: Evaluating ChatGPT, Claude AI, Bard, and Perplexity. Cureus 2024, 16, e52485. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Huang, C.; Wang, D.; Li, K.; Han, X.; Chen, X.; Li, Z. Artificial Intelligence in Scoliosis: Current Applications and Future Directions. J. Clin. Med. 2023, 12, 7382. [Google Scholar] [CrossRef] [PubMed]
- Zong, H.; Li, J.; Wu, E.; Wu, R.; Lu, J.; Shen, B. Performance of ChatGPT on Chinese national medical licensing examinations: A five-year examination evaluation study for physicians, pharmacists and nurses. BMC Med. Educ. 2024, 24, 143. [Google Scholar] [CrossRef]
- Saravia-Rojas, M.Á.; Camarena-Fonseca, A.R.; León-Manco, R.; Geng-Vivanco, R. Artificial intelligence: ChatGPT as a disruptive didactic strategy in dental education. J. Dent. Educ. 2024, 88, 872–876. [Google Scholar] [CrossRef]
- Pradhan, F.; Fiedler, A.; Samson, K.; Olivera-Martinez, M.; Manatsathit, W.; Peeraphatdit, T. Artificial intelligence compared with human-derived patient educational materials on cirrhosis. Hepatol. Commun. 2024, 8, e0367. [Google Scholar] [CrossRef] [PubMed]
- Masalkhi, M.; Ong, J.; Waisberg, E.; Lee, A.G. Google DeepMind’s gemini AI versus ChatGPT: A comparative analysis in ophthalmology. Eye 2024, 38, 1412–1417. [Google Scholar] [CrossRef] [PubMed]
- Maniaci, A.; Fakhry, N.; Chiesa-Estomba, C.; Lechien, J.R.; Lavalle, S. Synergizing ChatGPT and general AI for enhanced medical diagnostic processes in head and neck imaging. Eur. Arch. Otorhinolaryngol. 2024, 281, 3297–3298. [Google Scholar] [CrossRef] [PubMed]
- Morreel, S.; Verhoeven, V.; Mathysen, D. Microsoft Bing outperforms five other generative artificial intelligence chatbots in the Antwerp University multiple choice medical license exam. PLoS Digit Health 2024, 3, e0000349. [Google Scholar] [CrossRef]
- Zakka, C.; Shad, R.; Chaurasia, A.; Dalal, A.R.; Kim, J.L.; Moor, M.; Fong, R.; Phillips, C.; Alexander, K.; Ashley, E.; et al. Almanac—Retrieval-Augmented Language Models for Clinical Medicine. NEJM AI 2024, 1. [Google Scholar] [CrossRef]
- Aiumtrakul, N.; Thongprayoon, C.; Arayangkool, C.; Vo, K.B.; Wannaphut, C.; Suppadungsuk, S.; Krisanapan, P.; Garcia Valencia, O.A.; Qureshi, F.; Miao, J.; et al. Personalized Medicine in Urolithiasis: AI Chatbot-Assisted Dietary Management of Oxalate for Kidney Stone Prevention. J. Pers. Med. 2024, 14, 107. [Google Scholar] [CrossRef]
- Kassab, J.; Hadi El Hajjar, A.; Wardrop, R.M., 3rd; Brateanu, A. Accuracy of Online Artificial Intelligence Models in Primary Care Settings. Am. J. Prev. Med. 2024, 66, 1054–1059. [Google Scholar] [CrossRef]
- Noda, R.; Izaki, Y.; Kitano, F.; Komatsu, J.; Ichikawa, D.; Shibagaki, Y. Performance of ChatGPT and Bard in self-assessment questions for nephrology board renewal. Clin. Exp. Nephrol. 2024, 28, 465–469. [Google Scholar] [CrossRef] [PubMed]
- Abdullahi, T.; Singh, R.; Eickhoff, C. Learning to Make Rare and Complex Diagnoses with Generative AI Assistance: Qualitative Study of Popular Large Language Models. JMIR Med. Educ. 2024, 10, e51391. [Google Scholar] [CrossRef] [PubMed]
- Google Gemini AI. The Future of Artificial Intelligence. Available online: https://digitalfloats.com/google-gemini-the-future-of-440artificial-intelligence/ (accessed on 10 April 2024).
- Gemini. Available online: https://gemini.google.com/advanced?utm_source=deepmind&utm_medium=owned&utm_cam-442paign=gdmsite_learn (accessed on 10 April 2024).
- You Chat: What Is You Chat? Available online: https://about.you.com/introducing-youchat-the-ai-search-assistant-that-lives-in-your-search-engine-eff7badcd655/ (accessed on 10 April 2024).
- Albagieh, H.; Alzeer, Z.O.; Alasmari, O.N.; Alkadhi, A.A.; Naitah, A.N.; Almasaad, K.F.; Alshahrani, T.S.; Alshahrani, K.S.; Almahmoud, M.I. Comparing Artificial Intelligence and Senior Residents in Oral Lesion Diagnosis: A Comparative Study. Cureus 2024, 16, e51584. [Google Scholar] [CrossRef]
- Constitutional AI: Harmlessness from AI Feedback. Available online: https://www.anthropic.com/news/constitutional-ai-harmlessness-from-ai-feedback (accessed on 10 April 2024).
- Rokhshad, R.; Zhang, P.; Mohammad-Rahimi, H.; Pitchika, V.; Entezari, N.; Schwendicke, F. Accuracy and consistency of chatbots versus clinicians for answering pediatric dentistry questions: A pilot study. J. Dent. 2024, 144, 104938. [Google Scholar] [CrossRef] [PubMed]
- Elyoseph, Z.; Levkovich, I. Comparing the Perspectives of Generative AI, Mental Health Experts, and the General Public on Schizophrenia Recovery: Case Vignette Study. JMIR Ment. Health 2024, 11, e53043. [Google Scholar] [CrossRef]
- Wright, B.M.; Bodnar, M.S.; Moore, A.D.; Maseda, M.C.; Kucharik, M.P.; Diaz, C.C.; Schmidt, C.M.; Mir, H.R. Is ChatGPT a trusted source of information for total hip and knee arthroplasty patients? Bone Jt. Open 2024, 5, 139–146. [Google Scholar] [CrossRef] [PubMed]
- Wu, C.; Lin, W.; Zhang, X.; Zhang, Y.; Xie, W.; Wang, Y. PMC-LLaMA: Toward building open-source language models for medicine. J. Am. Med. Inform. Assoc. 2024, ocae045. [Google Scholar] [CrossRef]
- Hopkins, B.S.; Nguyen, V.N.; Dallas, J.; Texakalidis, P.; Yang, M.; Renn, A.; Guerra, G.; Kashif, Z.; Cheok, S.; Zada, G.; et al. ChatGPT versus the neurosurgical written boards: A comparative analysis of artificial intelligence/machine learning performance on neurosurgical board-style questions. J. Neurosurg. 2023, 139, 904–911. [Google Scholar] [CrossRef]
- Yang, S.; Chang, M.C. The assessment of the validity, safety, and utility of ChatGPT for patients with herniated lumbar disc: A preliminary study. Medicine 2024, 103, e38445. [Google Scholar] [CrossRef]
- Roman, A.; Al-Sharif, L.; Al Gharyani, M. The Expanding Role of ChatGPT (Chat-Generative Pre-Trained Transformer) in Neurosurgery: A Systematic Review of Literature and Conceptual Framework. Cureus 2023, 15, e43502. [Google Scholar] [CrossRef] [PubMed]
- Maharathi, S.; Iyengar, R.; Chandrasekhar, P. Biomechanically designed Curve Specific Corrective Exercise for Adolescent Idiopathic Scoliosis gives significant outcomes in an Adult: A case report. Front. Rehabil. Sci. 2023, 4, 1127222. [Google Scholar] [CrossRef] [PubMed]
- Yang, F.; He, Y.; Deng, Z.S.; Yan, A. Improvement of automated image stitching system for DR X-ray images. Comput. Biol. Med. 2016, 71, 108–114. [Google Scholar] [CrossRef] [PubMed]
- Hwang, Y.S.; Lai, P.L.; Tsai, H.Y.; Kung, Y.C.; Lin, Y.Y.; He, R.J.; Wu, C.T. Radiation dose for pediatric scoliosis patients undergoing whole spine radiography: Effect of the radiographic length in an auto-stitching digital radiography system. Eur. J. Radiol. 2018, 108, 99–106. [Google Scholar] [CrossRef] [PubMed]
- Hey, H.W.D.; Ramos, M.R.D.; Lau, E.T.; Tan, J.H.J.; Tay, H.W.; Liu, G.; Wong, H.K. Risk Factors Predicting C-Versus S-shaped Sagittal Spine Profiles in Natural, Relaxed Sitting: An Important Aspect in Spinal Realignment Surgery. Spine 2020, 45, 1704–1712. [Google Scholar] [CrossRef] [PubMed]
- Horng, M.H.; Kuok, C.P.; Fu, M.J.; Lin, C.J.; Sun, Y.N. Cobb Angle Measurement of Spine from X-Ray Images Using Convolutional Neural Network. Comput. Math. Methods Med. 2019, 2019, 6357171. [Google Scholar] [CrossRef] [PubMed]
- Patient Examination AO Surgery Reference. Available online: https://surgeryreference.aofoundation.org/spine/deformities/adolescent-idiopathic-scoliosis/further-reading/patient-examination (accessed on 10 April 2024).
- Fabijan, A.; Polis, B.; Fabijan, R.; Zakrzewski, K.; Nowosławska, E.; Zawadzka-Fabijan, A. Artificial Intelligence in Scoliosis Classification: An Investigation of Language-Based Models. J. Pers. Med. 2023, 13, 1695. [Google Scholar] [CrossRef] [PubMed]
- Fabijan, A.; Fabijan, R.; Zawadzka-Fabijan, A.; Nowosławska, E.; Zakrzewski, K.; Polis, B. Evaluating Scoliosis Severity Based on Posturographic X-ray Images Using a Contrastive Language–Image Pretraining Model. Diagnostics 2023, 13, 2142. [Google Scholar] [CrossRef]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. [Google Scholar] [CrossRef]
- Llama-Precise Parameters Guidelines. Available online: https://github.com/oobabooga/text-generation-webui/wiki/03-%E2%80%90-Parameters-Tab (accessed on 10 April 2024).
- PMC-LLaMA Prompt Schema. Available online: https://github.com/chaoyi-wu/pmc-llama (accessed on 10 April 2024).
- Conger, A.J. Integration and generalization of kappas for multiple raters. Psychol. Bull. 1980, 88, 322–328. [Google Scholar] [CrossRef]
- Fleiss, J.L. Measuring nominal scale agreement among many raters. Psychol. Bull. 1971, 76, 378–382. [Google Scholar] [CrossRef]
- Fleiss, J.L.; Levin, B.; Paik, M.C. Statistical Methods for Rates and Proportions, 3rd ed.; John Wiley & Sons: New York, NY, USA, 2003; ISBN 978-0-471-52629-2. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021; Available online: https://www.R-project.org/ (accessed on 2 April 2024).
- Gamer, M.; Lemon, J.; Singh, P. irr: Various Coefficients of Interrater Reliability and Agreement, R Package Version 0.84.1, irr. 2019. Available online: https://CRAN.R-project.org/package=irr (accessed on 10 April 2024).
- Kuhn, M. Building Predictive Models in R Using the caret Package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef]
- Sarkar, D. lattice: Multivariate Data Visualization with R; Springer: New York, NY, USA, 2008; ISBN 978-0-387-75968-5. [Google Scholar]
- Makowski, D.; Lüdecke, D.; Patil, I.; Thériault, R.; Ben-Shachar, M.; Wiernik, B. Automated Results Reporting as a Practical Tool to Improve Reproducibility and Methodological Best Practices Adoption. CRAN. 2023. Available online: https://easystats.github.io/report/ (accessed on 10 April 2024).
- Sjoberg, D.; Whiting, K.; Curry, M.; Lavery, J.; Larmarange, J. Reproducible Summary Tables with the gtsummary Package. R J. 2021, 13, 570–580. [Google Scholar] [CrossRef]
- Wickham, H. ggplot2: Elegant Graphics for Data Analysis; Springer: New York, NY, USA, 2016; ISBN 978-3-319-24277-4. [Google Scholar]
- Chung, H.; Park, C.; Kang, W.S.; Lee, J. Gender Bias in Artificial Intelligence: Severity Prediction at an Early Stage of COVID-19. Front. Physiol. 2021, 12, 778720. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Sun, J.; Zhou, X. Comparison of ResNet-50 and vision transformer models for trash classification. In Proceedings of the Third International Conference on Artificial Intelligence and Computer Engineering (ICAICE 2022), Wuhan, China, 11–13 November 2022; Volume 12610. [Google Scholar]
- He, Z.; Lin, M.; Xu, Z.; Yao, Z.; Chen, H.; Alhudhaif, A.; Alenezi, F. Deconv-transformer (DecT): A histopathological image classification model for breast cancer based on color deconvolution and transformer architecture. Inf. Sci. 2022, 608, 1093–1112. [Google Scholar] [CrossRef]
- Nuobu, G. Transformer model: Explainability and prospectiveness. Appl. Comput. Eng. 2023, 20, 88–99. [Google Scholar] [CrossRef]
- Kanca, E.; Ayas, S.; Kablan, E.B.; Ekinci, M. Performance Comparison of Vision Transformer-Based Models in Medical Image Classification. In Proceedings of the 2023 31st Signal Processing and Communications Applications Conference (SIU), Istanbul, Turkiye, 5–8 July 2023; pp. 1–4. [Google Scholar] [CrossRef]
- Niu, X.; Bai, B.; Deng, L.; Han, W. Beyond Scaling Laws: Understanding Transformer Performance with Associative Memory. arXiv 2024, arXiv:2405.08707v1. [Google Scholar] [CrossRef]
- Gholami, S.; Omar, M. Do Generative Large Language Models need billions of parameters? arXiv 2023, arXiv:2309.06589v1, 6589v1. [Google Scholar] [CrossRef]
- Pursnani, V.; Sermet, Y.; Demir, I. Performance of ChatGPT on the US Fundamentals of Engineering Exam: Comprehensive Assessment of Proficiency and Potential Implications for Professional Environmental Engineering Practice. Comput. Educ. Artif. Intell. 2023, 5, 100183. [Google Scholar] [CrossRef]
- Heston, T.F.; Khun, C. Prompt Engineering in Medical Education. Int. Med. Educ. 2023, 2, 198–205. [Google Scholar] [CrossRef]
- Chen, L.; Tophel, A.; Hettiyadura, U.; Kodikara, J. An Investigation into the Utility of Large Language Models in Geotechnical Education and Problem Solving. Geotechnics 2024, 4, 470–498. [Google Scholar] [CrossRef]
- Murugan, M.; Yuan, B.; Venner, E.; Ballantyne, C.M.; Robinson, K.M.; Coons, J.C.; Wang, L.; Empey, P.E.; Gibbs, R.A. Empowering Personalized Pharmacogenomics with Generative AI Solutions. J. Am. Med. Inform. Assoc. 2024, 31, 1356–1366. [Google Scholar] [CrossRef] [PubMed]
- Feijen, M.; Egorova, A.D.; Beeres, S.L.M.A.; Treskes, R.W. Early Detection of Fluid Retention in Patients with Advanced Heart Failure: A Review of a Novel Multisensory Algorithm, HeartLogicTM. Sensors 2021, 21, 1361. [Google Scholar] [CrossRef] [PubMed]
- Luan, Y.; Zhong, G.; Li, S.; Wu, W.; Liu, X.; Zhu, D.; Feng, Y.; Zhang, Y.; Duan, C.; Mao, M. A panel of seven protein tumour markers for effective and affordable multi-cancer early detection by artificial intelligence: A large-scale and multicentre case-control study. EClinicalMedicine 2023, 61, 102041. [Google Scholar] [CrossRef] [PubMed]
- Witowski, J.; Heacock, L.; Reig, B.; Kang, S.K.; Lewin, A.; Pysarenko, K.; Patel, S.; Samreen, N.; Rudnicki, W.; Łuczyńska, E.; et al. Improving breast cancer diagnostics with deep learning for MRI. Sci. Transl. Med. 2022, 14, eabo4802. [Google Scholar] [CrossRef]
- Handler, S.M.; Kane-Gill, S.L.; Kellum, J.A. Optimal and early detection of acute kidney injury requires effective clinical decision support systems. Nephrol. Dial. Transplant. 2014, 29, 1802–1803. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, S.; Singh, M.; Doherty, B.; Ramlan, E.; Harkin, K.; Coyle, D. Multiple Severity-Level Classifications for IT Incident Risk Prediction. In Proceedings of the 2022 9th International Conference on Soft Computing & Machine Intelligence (ISCMI), Toronto, ON, Canada, 26–27 November 2022; pp. 270–274. [Google Scholar] [CrossRef]
- Shakhovska, N.; Yakovyna, V.; Chopyak, V. A new hybrid ensemble machine-learning model for severity risk assessment and post-COVID prediction system. Math. Biosci. Eng. 2022, 19, 6102–6123. [Google Scholar] [CrossRef]
- Lange, T.; Stiermaier, T.; Backhaus, S.; Boom, P.; Kutty, S.; Bigalke, B.; Hasenfuß, G.; Thiele, H.; Eitel, I.; Schuster, A. Abstract 15535: Automated Artificial Intelligence-based Myocardial Scar Quantification for Risk Assessment Following Myocardial Infarction. Circulation 2020, 142 (Suppl. S3), A15535. [Google Scholar] [CrossRef]
- Zhu, S.; Wang, K.; Li, C. Crash Injury Severity Prediction Using an Ordinal Classification Machine Learning Approach. Int. J. Environ. Res. Public Health 2021, 18, 11564. [Google Scholar] [CrossRef]
- Huo, B.; Calabrese, E.; Sylla, P.; Kumar, S.; Ignacio, R.C.; Oviedo, R.; Hassan, I.; Slater, B.J.; Kaiser, A.; Walsh, D.S.; et al. The performance of artificial intelligence large language model-linked chatbots in surgical decision-making for gastroesophageal reflux disease. Surg. Endosc. 2024, 38, 2320–2330. [Google Scholar] [CrossRef] [PubMed]
- Kochanek, K.; Skarzynski, H.; Jedrzejczak, W.W. Accuracy and Repeatability of ChatGPT Based on a Set of Multiple-Choice Questions on Objective Tests of Hearing. Cureus 2024, 16, e59857. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| max_new_tokens | 512 |
| temperature | 0.7 |
| top_p | 0.1 |
| min_p | 0 |
| top_k | 40 |
| repetition_penalty | 1.18 |
| presence_penalty | 0 |
| frequency_penalty | 0 |
| repetition_penalty_range | 1024 |
| typical_p | 1 |
| tfs | 1 |
| top_a | 0 |
| epsilon_cutoff | 0 |
| eta_cutoff | 0 |
| guidance_scale | 1 |
| minostat_mode | 0 |
| minostat_tau | 5 |
| minostat_eta | 0.1 |
| smoothing_factor | 0 |
| smoothing_curve | 1 |
| dynamic_temperature | do_sample |
| num_beams | 1 |
| max_tokens/prompt | 2048 |
| Characteristic | N | Distribution |
|---|---|---|
| Cobb angle | 72 | 29.50 (16.75, 54.25) a |
| Severity of disease 1: | 72 | |
| mild | 25.00 (34.72%) b | |
| moderate | 19.00 (26.39%) b | |
| severe | 28.00 (38.89%) b |
| AI System | Severity of Disease | Treatment Modality | ||||
|---|---|---|---|---|---|---|
| Mild | Moderate | Severe | Monitoring | Bracing | Surgery | |
| Reference level | <20 | 20–40 | >40 | <20 | 20–40 | >40 |
| ChatGPT 4 | <20 | 20–40 | >40 | <20 | 20–40 | >40 |
| Copilot | <20 | 20–40 | >40 | <20 | 20–40 | >40 |
| Gemini | 10–25 | 25–40 | >40 | Did not undertake classification | ||
| Gemini Advanced | 10–25 | 25–45 | >45 | Did not undertake classification | ||
| PopAi | <20 | 20–40 | >40 | <20 | 20–40 | >40 |
| You Research | 10–24 | 25–39 | ≥40 | 10–24 | 25–45 | >45 |
| You GPT 4 | 10–20 | 21–40 | >40 | 10–24 | 25–39 | ≥40 |
| You Genius | 10–24 | 25–39 | ≥40 | 10–24 | 25–45 | >45 |
| Claude 3 Opus | 10–20 | 21–40 | >40 | <25 | 25–45 | >45 |
| Claude 3 Sonnet | 10–25 | 25–40 | ≥40 | <20 | 20–50 | >50 |
| PMC-LLaMA 13B | 10–20 | 20–50 | >50 | 10–20 | 20–50 | >50 |
| AI System | Overall Sample | Category-Wise | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Severity Classification | Treatment Classification | |||||||||||||||
| SC | ST | CC | CT | Mild | Moderate | Severe | Monitoring | Bracing | Surgery | |||||||
| SC | ST | SC | ST | SC | ST | CC | CT | CC | CT | CC | CT | |||||
| Chat GPT 4 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| Copilot | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| Gemini | n/a | n/a | n/a | n/a | n/a | n/a | n/a | n/a | n/a | n/a | n/a | n/a | n/a | n/a | n/a | n/a |
| Gemini Advanced | 0.77 | 0.68 | n/a | n/a | 0.79 | 0.74 | 0.60 | 0.43 | 0.88 | 0.82 | n/a | n/a | n/a | n/a | n/a | n/a |
| PopAi | 1.00 | 1.00 | 0.83 | 0.83 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.66 | 0.66 | 0.77 | 0.77 | 1.00 | 1.00 |
| You Research | n/a | n/a | n/a | n/a | n/a | n/a | n/a | n/a | n/a | n/a | n/a | n/a | n/a | n/a | n/a | n/a |
| You GPT 4 | 0.67 | 0.67 | n/a | n/a | 0.77 | 0.77 | 0.49 | 0.49 | 0.83 | 0.83 | n/a | n/a | n/a | n/a | n/a | n/a |
| You Genius | n/a | n/a | 0.78 | n/a | n/a | n/a | n/a | n/a | n/a | n/a | 0.58 | n/a | 0.74 | n/a | 0.97 | n/a |
| Claude 3 Opus | 0.96 | 0.96 | 0.77 | 0.98 | 0.94 | 0.94 | 0.93 | 0.93 | 1.00 | 1.00 | 0.60 | 0.97 | 0.79 | 0.96 | 0.88 | 1.00 |
| Claude 3 Sonnet | 0.85 | 0.81 | 0.50 | 0.58 | 0.91 | 0.73 | 0.85 | 0.91 | 0.89 | 0.89 | 0.45 | 0.67 | 0.67 | 0.58 | 0.38 | 0.49 |
| PMC LLaMA 13B | 0.55 | 0.49 | 0.37 | 0.24 | 0.68 | 0.68 | 0.33 | 0.30 | 0.66 | 0.53 | 0.13 * | 0.13 * | 0.18 * | 0.02 * | 0.74 | 0.57 |
| AI System | Overall Accuracy | Severity Class | Sensitivity | Specificity | Positive Predictive Value | Negative Predictive Value | Precision | Recall | F1 | Prevalence | Detection Rate | Detection Prevalence | Balanced Accuracy |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ChatGPT 4; Copilot; PopAi | 1.00 | Mild | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.35 | 0.35 | 0.35 | 1.00 |
| Moderate | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.26 | 0.26 | 0.26 | 1.00 | ||
| Severe | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.39 | 0.39 | 0.39 | 1.00 | ||
| Gemini Advanced | 0.85 | Mild | 0.92 | 0.89 | 0.82 | 0.95 | 0.82 | 0.92 | 0.87 | 0.35 | 0.32 | 0.39 | 0.91 |
| Moderate | 0.68 | 0.91 | 0.72 | 0.89 | 0.72 | 0.68 | 0.70 | 0.26 | 0.18 | 0.25 | 0.79 | ||
| Severe | 0.89 | 0.98 | 0.96 | 0.93 | 0.96 | 0.89 | 0.92 | 0.39 | 0.35 | 0.36 | 0.94 | ||
| You GPT 4 | 0.82 | Mild | 0.75 | 1.00 | 1.00 | 0.88 | 1.00 | 0.75 | 0.86 | 0.35 | 0.26 | 0.26 | 0.88 |
| Moderate | 0.81 | 0.83 | 0.59 | 0.93 | 0.59 | 0.81 | 0.68 | 0.24 | 0.19 | 0.32 | 0.82 | ||
| Severe | 0.89 | 0.93 | 0.89 | 0.93 | 0.89 | 0.89 | 0.89 | 0.41 | 0.37 | 0.41 | 0.91 | ||
| Claude 3 Opus | 0.97 | Mild | 1.00 | 0.96 | 0.93 | 1.00 | 0.93 | 1.00 | 0.96 | 0.35 | 0.35 | 0.38 | 0.98 |
| Moderate | 0.90 | 1.00 | 1.00 | 0.96 | 1.00 | 0.89 | 0.94 | 0.26 | 0.24 | 0.24 | 0.95 | ||
| Severe | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.39 | 0.39 | 0.39 | 1.00 | ||
| Claude 3 Sonnet | 0.94 | Mild | 0.92 | 1.00 | 1.00 | 0.96 | 1.00 | 0.92 | 0.96 | 0.35 | 0.32 | 0.32 | 0.96 |
| Moderate | 0.88 | 1.00 | 1.00 | 0.96 | 1.00 | 0.88 | 0.94 | 0.25 | 0.22 | 0.22 | 0.94 | ||
| Severe | 1.00 | 0.90 | 0.88 | 1.00 | 0.88 | 1.00 | 0.93 | 0.41 | 0.41 | 0.46 | 0.95 | ||
| PMC-LLaMa 13B | 0.73 | Mild | 0.88 | 0.81 | 0.73 | 0.92 | 0.73 | 0.88 | 0.80 | 0.37 | 0.32 | 0.44 | 0.85 |
| Moderate | 0.47 | 0.84 | 0.53 | 0.80 | 0.53 | 0.47 | 0.50 | 0.27 | 0.13 | 0.25 | 0.66 | ||
| Severe | 0.79 | 0.95 | 0.90 | 0.89 | 0.90 | 0.79 | 0.84 | 0.35 | 0.28 | 0.31 | 0.87 |
| AI System | Overall Accuracy | Severity Class | Sensitivity | Specificity | Positive Predictive Value | Negative Predictive Value | Precision | Recall | F1 | Prevalence | Detection Rate | Detection Prevalence | Balanced Accuracy |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ChatGPT 4; Copilot | 1.00 | Monitoring | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.35 | 0.35 | 0.35 | 1.00 |
| Bracing | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.26 | 0.26 | 0.26 | 1.00 | ||
| Surgery | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.39 | 0.39 | 0.39 | 1.00 | ||
| PopAi | 0.89 | Monitoring | 1.00 | 0.83 | 0.76 | 1.00 | 0.76 | 1.00 | 0.86 | 0.35 | 0.35 | 0.46 | 0.91 |
| Bracing | 0.58 | 1.00 | 1.00 | 0.87 | 1.00 | 0.58 | 0.73 | 0.26 | 0.15 | 0.15 | 0.79 | ||
| Surgery | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.39 | 0.39 | 0.39 | 1.00 | ||
| You Genius | 0.86 | Monitoring | 1.00 | 0.81 | 0.74 | 1.00 | 0.74 | 1.00 | 0.85 | 0.35 | 0.35 | 0.47 | 0.90 |
| Bracing | 0.52 | 0.98 | 0.91 | 0.85 | 0.91 | 0.53 | 0.67 | 0.26 | 0.14 | 0.15 | 0.75 | ||
| Surgery | 0.96 | 1.00 | 1.00 | 0.98 | 1.00 | 0.96 | 0.98 | 0.39 | 0.38 | 0.38 | 0.98 | ||
| Claude 3 Opus | 0.85 | Monitoring | 0.96 | 0.87 | 0.80 | 0.98 | 0.80 | 0.96 | 0.87 | 0.35 | 0.33 | 0.42 | 0.92 |
| Bracing | 0.68 | 0.91 | 0.72 | 0.89 | 0.72 | 0.68 | 0.70 | 0.26 | 0.18 | 0.25 | 0.79 | ||
| Surgery | 0.86 | 1.00 | 1.00 | 0.92 | 1.00 | 0.86 | 0.92 | 0.39 | 0.33 | 0.33 | 0.93 | ||
| Claude 3 Sonnet | 0.67 | Monitoring | 0.80 | 0.87 | 0.77 | 0.89 | 0.77 | 0.80 | 0.78 | 0.35 | 0.28 | 0.36 | 0.84 |
| Bracing | 0.74 | 0.77 | 0.54 | 0.89 | 0.54 | 0.74 | 0.62 | 0.26 | 0.19 | 0.36 | 0.76 | ||
| Surgery | 0.50 | 0.86 | 0.70 | 0.73 | 0.70 | 0.50 | 0.58 | 0.39 | 0.19 | 0.28 | 0.68 | ||
| PMC-LLaMa 13B | 0.59 | Monitoring | 0.24 | 0.91 | 0.60 | 0.69 | 0.60 | 0.24 | 0.34 | 0.35 | 0.08 | 0.14 | 0.58 |
| Bracing | 0.63 | 0.62 | 0.38 | 0.82 | 0.38 | 0.63 | 0.47 | 0.27 | 0.17 | 0.45 | 0.62 | ||
| Surgery | 0.89 | 0.89 | 0.83 | 0.93 | 0.83 | 0.89 | 0.86 | 0.38 | 0.34 | 0.41 | 0.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fabijan, A.; Zawadzka-Fabijan, A.; Fabijan, R.; Zakrzewski, K.; Nowosławska, E.; Polis, B. Assessing the Accuracy of Artificial Intelligence Models in Scoliosis Classification and Suggested Therapeutic Approaches. J. Clin. Med. 2024, 13, 4013. https://doi.org/10.3390/jcm13144013
Fabijan A, Zawadzka-Fabijan A, Fabijan R, Zakrzewski K, Nowosławska E, Polis B. Assessing the Accuracy of Artificial Intelligence Models in Scoliosis Classification and Suggested Therapeutic Approaches. Journal of Clinical Medicine. 2024; 13(14):4013. https://doi.org/10.3390/jcm13144013
Chicago/Turabian StyleFabijan, Artur, Agnieszka Zawadzka-Fabijan, Robert Fabijan, Krzysztof Zakrzewski, Emilia Nowosławska, and Bartosz Polis. 2024. "Assessing the Accuracy of Artificial Intelligence Models in Scoliosis Classification and Suggested Therapeutic Approaches" Journal of Clinical Medicine 13, no. 14: 4013. https://doi.org/10.3390/jcm13144013
APA StyleFabijan, A., Zawadzka-Fabijan, A., Fabijan, R., Zakrzewski, K., Nowosławska, E., & Polis, B. (2024). Assessing the Accuracy of Artificial Intelligence Models in Scoliosis Classification and Suggested Therapeutic Approaches. Journal of Clinical Medicine, 13(14), 4013. https://doi.org/10.3390/jcm13144013