
Evaluating a Deep Learning Diabetic Retinopathy Grading System Developed on Mydriatic Retinal Images When Applied to Non-Mydriatic Community Screening

 , , , ,
, , , , 
Abstract
1. Introduction
2. Materials and Methods
2.1. Study Settings
2.2. Image Grading by Graders (Reference Standard)
2.3. Imaging Grading by Automated Algorithm (Index Test)
2.4. Outcomes
- At least one referable image derived in a referable patient eye;
- Non-referable and ungradable (if any) images derived in a non-referable patient eye;
- Two or more ungradable images derived in an ungradable patient eye.
2.5. Statistical Analysis
3. Results
Grader and Model Assessment
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ting, D.S.W.; Cheung, G.C.M.; Wong, T.Y. Diabetic retinopathy: Global prevalence, major risk factors, screening practices and public health challenges: A review. Clin. Exp. Ophthalmol. 2016, 44, 260–277. [Google Scholar] [CrossRef] [PubMed]
- International Diabetes Federation. IDF Diabetes Atlas, 9th ed.; International Diabetes Federation: Brussels, Belgium, 2019. [Google Scholar]
- Squirrell, D.M.; Talbot, J.F. Screening for diabetic retinopathy. J. R. Soc. Med. 2003, 96, 273–276. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Chakrabarti, R.; Harper, C.A.; Keeffe, J.E. Diabetic retinopathy management guidelines. Expert Rev. Ophthalmol. 2012, 7, 417–439. [Google Scholar] [CrossRef]
- Scanlon, P.H.; Aldington, S.J.; Leal, J.; Luengo-Fernandez, R.; Oke, J.; Sivaprasad, S.; Gazis, A.; Stratton, I.M. Development of a cost-effectiveness model for optimisation of the screening interval in diabetic retinopathy screening. Health Technol. Assess. 2015, 19, 1–116. [Google Scholar] [CrossRef] [PubMed]
- Fenner, B.J.; Wong, R.L.M.; Lam, W.-C.; Tan, G.S.W.; Cheung, G.C.M. Advances in retinal imaging and applications in diabetic retinopathy screening: A review. Ophthalmol. Ther. 2018, 7, 333–346. [Google Scholar] [CrossRef]
- Jain, M.; Devan, S.; Jaisankar, D.; Swaminathan, G.; Pardhan, S.; Raman, R. Pupillary abnormalities with varying severity of diabetic retinopathy. Sci. Rep. 2018, 8, 5636. [Google Scholar] [CrossRef]
- Yu, K.-H.; Beam, A.L.; Kohane, I.S. Artificial intelligence in healthcare. Nat. Biomed. Eng. 2018, 2, 719–731. [Google Scholar] [CrossRef]
- De Fauw, J.; Ledsam, J.R.; Romera-Paredes, B.; Nikolov, S.; Tomasev, N.; Blackwell, S.; Askham, H.; Glorot, X.; O’Donoghue, B.; Visentin, D.; et al. Clinically applicable deep learning for diagnosis and referral in retinal disease. Nat. Med. 2018, 24, 1342–1350. [Google Scholar] [CrossRef]
- Nunezdo Rio, J.M.; Sen, P.; Rasheed, R.; Bagchi, A.; Nicholson, L.; Dubis, A.M.; Bergeles, C.; Sivaprasad, S. Deep learning-based segmentation and quantification of retinal capillary non-perfusion on ultra-wide-field retinal fluorescein angiography. J. Clin. Med. 2020, 9, 2537. [Google Scholar] [CrossRef]
- Stolte, S.; Fang, R. A Survey on Medical Image Analysis in Diabetic Retinopathy. Med. Image Anal. 2020, 64, 101742. [Google Scholar] [CrossRef]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J.; et al. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA 2016, 316, 2402–2410. [Google Scholar] [CrossRef] [PubMed]
- Ting, D.S.W.; Cheung, C.Y.-L.; Lim, G.; Tan, G.S.W.; Quang, N.D.; Gan, A.; Hamzah, H.; Garcia-Franco, R.; SanYeo, I.Y.; Lee, S.Y.; et al. Development and Validation of a Deep Learning System for Diabetic Retinopathy and Related Eye Diseases Using Retinal Images from Multiethnic Populations with Diabetes. JAMA 2017, 318, 2211–2223. [Google Scholar] [CrossRef] [PubMed]
- Gargeya, R.; Leng, T. Automated identification of diabetic retinopathy using deep learning. Ophthalmology 2017, 124, 962–969. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Pang, T.; Xiong, B.; Liu, W.; Liang, P.; Wang, T. Convolutional neural networks based transfer learning for diabetic retinopathy fundus image classification. In Proceedings of the 2017 10th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Shanghai, China, 14–16 October 2017; pp. 1–11. [Google Scholar]
- Faes, L.; Wagner, S.K.; Fu, D.J.; Liu, X.; Korot, E.; Ledsam, J.R.; Back, T.; Chopra, R.; Pontikos, N.; Kern, C. Automated deep learning design for medical image classification by health-care professionals with no coding experience: A feasibility study. Lancet Digit. Health 2019, 1, e232–e242. [Google Scholar] [CrossRef]
- Gulshan, V.; Rajan, R.P.; Widner, K.; Wu, D.; Wubbels, P.; Rhodes, T.; Whitehouse, K.; Coram, M.; Corrado, G.; Ramasamy, K.; et al. Performance of a deep-learning algorithm vs manual grading for detecting diabetic retinopathy in India. JAMA Ophthalmol. 2019, 137, 987–993. [Google Scholar] [CrossRef]
- Wilkinson, C.P.; FerrisIII, F.L.; Klein, R.E.; Lee, P.P.; Agardh, C.D.; Davis, M.; Dills, D.; Kampik, A.; Pararajasegaram, R.; Verdaguer, J.T. Proposed international clinical diabetic retinopathy and diabetic macular edema disease severity scales. Ophthalmology 2003, 110, 1677–1682. [Google Scholar] [CrossRef]
- Haneda, S.; Yamashita, H. International clinical diabetic retinopathy disease severity scale. Nihon Rinsho 2010, 68, 228. [Google Scholar]
- Rajalakshmi, R.; Subashini, R.; Anjana, R.M.; Mohan, V. Automated diabetic retinopathy detection in smartphone-based fundus photography using artificial intelligence. Eye 2018, 32, 1138–1144. [Google Scholar] [CrossRef]
- Natarajan, S.; Jain, A.; Krishnan, R.; Rogye, A.; Sivaprasad, S. Diagnostic accuracy of community-based diabetic retinopathy screening with an offline artificial intelligence system on a smartphone. JAMA Ophthalmol. 2019, 137, 1182–1188. [Google Scholar] [CrossRef]
- Sivaprasad, S.; Raman, R.; Rajalakshmi, R.; Mohan, V.; Deepa, M.; Das, T.; Ramasamy, K.; Prevost, A.T.; Wittenberg, R.; Netuveli, G. Protocol on a multicentre statistical and economic modelling study of risk-based stratified and personalised screening for diabetes and its complications in India (SMART India). BMJ Open 2020, 10, e039657. [Google Scholar] [CrossRef]
- Gregori, N.Z.; Feuer, W.; Rosenfeld, P.J. Novel method for analyzing Snellen visual acuity measurements. Retina 2010, 30, 1046–1050. [Google Scholar] [CrossRef] [PubMed]
- Decencière, E.; Zhang, X.; Cazuguel, G.; Lay, B.; Cochener, B.; Trone, C.; Gain, P.; Ordonez, R.; Massin, P.; Erginay, A.; et al. Feedback on a publicly distributed image database: The Messidor database. Image Anal. Stereol. 2014, 33, 231–234. [Google Scholar] [CrossRef]
- Hutchinson, A.; McIntosh, A.; Peters, J.; O’keeffe, C.; Khunti, K.; Baker, R.; Booth, A. Effectiveness of screening and monitoring tests for diabetic retinopathy–a systematic review. Diabet. Med. 2000, 17, 495–506. [Google Scholar] [CrossRef] [PubMed]
- The National Institute for Clinical Excellence. Diabetic Retinopathy–Early Management and Screening; The National Institute for Clinical Excellence: London, UK, 2001. [Google Scholar]
- Khan, T.; Bertram, M.Y.; Jina, R.; Mash, B.; Levitt, N.; Hofman, K. Preventing diabetes blindness: Cost effectiveness of a screening programme using digital non-mydriatic fundus photography for diabetic retinopathy in a primary health care setting in South Africa. Diabetes Res. Clin. Pract. 2013, 101, 170–176. [Google Scholar] [CrossRef]
- Kuo, H.-K.; Hsieh, H.-H.; Liu, R.-T. Screening for diabetic retinopathy by one-field, non-mydriatic, 45 digital photography is inadequate. Ophthalmologica 2005, 219, 292–296. [Google Scholar] [CrossRef]
- Vujosevic, S.; Benetti, E.; Massignan, F.; Pilotto, E.; Varano, M.; Cavarzeran, F.; Avogaro, A.; Midena, E. Screening for diabetic retinopathy: 1 and 3 nonmydriatic 45-degree digital fundus photographs vs 7 standard early treatment diabetic retinopathy study fields. Am. J. Ophthalmol. 2009, 148, 111–118. [Google Scholar] [CrossRef]
- Srihatrai, P.; Hlowchitsieng, T. The diagnostic accuracy of single-and five-field fundus photography in diabetic retinopathy screening by primary care physicians. Indian J. Ophthalmol. 2018, 66, 94. [Google Scholar] [CrossRef]
- Silva, P.S.; Salongcay, R.P.; Aquino, L.A.; Salva, C.; Sun, J.K.; Peto, T.; Aiello, L.P. Intergrader Agreement for Diabetic Retinopathy (DR) using Hand-Held Retinal Imaging. Investig. Ophthalmol. Vis. Sci. 2021, 62, 1896. [Google Scholar]
- Salongcay, R.P.; Aquino, L.A.; Salva, C.M.G.; Saunar, A.V.; Alog, G.P.; Rageh, A.; Sun, J.K.; Peto, T.; Aiello, L.P.; Silva, P.S. Comparison of Mydriatic Handheld Retinal Imaging with Early Treatment Diabetic Retinopathy Study (ETDRS) 7-Standard Field Photography for Diabetic Retinopathy (DR) and Diabetic Macular Edema (DME). Investig. Ophthalmol. Vis. Sci. 2021, 62, 1084. [Google Scholar]
- Nderitu, P.; Do Rio, J.M.N.; Rasheed, R.; Raman, R.; Rajalakshmi, R.; Bergeles, C.; Sivaprasad, S. Deep learning for gradability classification of handheld, non-mydriatic retinal images. Sci. Rep. 2021, 11, 9469. [Google Scholar] [CrossRef]


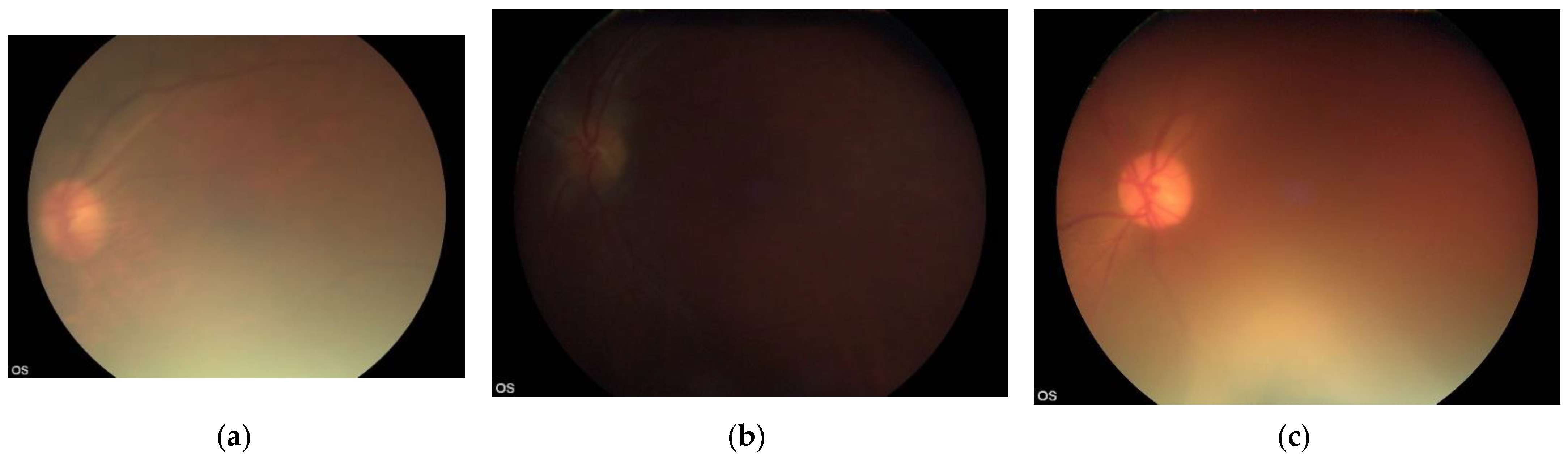{kind=link}
| Sites | Images, Total No. (%) a | Images per Patient Eye, Mean (SD) b | Patients, Total No. (%) a | Age, Mean (SD) b | Male, Total No. (%) b | Female, Total No. (%) b | Patient Eyes, Total No. (%) a | Referable, Total No. (%) b | Non-Referable, Total No. (%) b | Ungradable, Total No. (%) b |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2408 (8.1) | 1.5 (0.7) | 836 (7.5) | 54.2 (10.3) | 402 (48.1) | 434 (51.9) | 1576 (7.7) | 23 (1.5) | 1404 (89.1) | 149 (9.5) |
| 2 | 2268 (7.6) | 1.2 (0.5) | 994 (8.9) | 54.1 (10.0) | 537 (54.0) | 456 (45.9) | 1829 (8.9) | 108 (5.9) | 1513 (82.7) | 208 (11.4) |
| 3 | 730 (2.5) | 1.3 (0.5) | 436 (3.9) | 55.4 (10.7) | 166 (38.1) | 270 (61.9) | 576 (2.8) | 12 (2.1) | 354 (61.5) | 210 (36.5) |
| 4 | 1308 (4.4) | 1.3 (0.5) | 549 (4.9) | 55.5 (11.1) | 304 (55.4) | 245 (44.6) | 1036 (5.1) | 14 (1.4) | 906 (87.5) | 116 (11.2) |
| 5 | 338 (1.1) | 1.4 (0.6) | 170 (1.5) | 54.2 (10.8) | 109 (64.1) | 59 (34.7) | 231 (1.1) | 4 (1.7) | 193 (83.5) | 34 (14.7) |
| 6 | 1315 (4.4) | 1.3 (0.5) | 557 (5.0) | 55.1 (10.1) | 315 (56.6) | 242 (43.4) | 1024 (5.0) | 50 (4.9) | 880 (85.9) | 94 (9.2) |
| 7 | 1225 (4.1) | 1.1 (0.4) | 569 (5.1) | 56.4 (11.5) | 355 (62.4) | 214 (37.6) | 1075 (5.2) | 91 (8.5) | 845 (78.6) | 139 (12.9) |
| 8 | 2110 (7.1) | 1.2 (0.4) | 943 (8.4) | 61.9 (9.8) | 369 (39.1) | 571 (60.6) | 1812 (8.8) | 125 (6.9) | 1475 (81.4) | 212 (11.7) |
| 9 | 2952 (10.0) | 2.1 (0.9) | 752 (6.7) | 57.4 (10.1) | 260 (34.6) | 492 (65.4) | 1436 (7.0) | 22 (1.5) | 1096 (76.3) | 318 (22.1) |
| 10 | 3635 (12.3) | 1.9 (0.4) | 1066 (9.5) | 62.9 (10.5) | 416 (39.0) | 650 (61.0) | 1946 (9.5) | 49 (2.5) | 1141 (58.6) | 756 (38.8) |
| 11 | 714 (2.4) | 1.9 (1.0) | 212 (1.9) | 56.7 (9.5) | 90 (42.5) | 122 (57.5) | 368 (1.8) | 21 (5.7) | 275 (74.7) | 72 (19.6) |
| 12 | 1668 (5.6) | 1.2 (0.4) | 757 (6.8) | 58.4 (11.4) | 389 (51.4) | 367 (48.5) | 1427 (7.0) | 12 (0.8) | 1145 (80.2) | 270 (18.9) |
| 13 | 751 (2.5) | 1.3 (0.5) | 318 (2.8) | 54.4 (10.4) | 133 (41.8) | 185 (58.2) | 591 (2.9) | 20 (3.4) | 523 (88.5) | 48 (8.1) |
| 14 | 703 (2.4) | 1.2 (0.5) | 327 (2.9) | 53.7 (8.1) | 232 (70.9) | 94 (28.7) | 585 (2.9) | 22 (3.8) | 549 (93.8) | 14 (2.4) |
| 15 | 662 (2.2) | 1.4 (0.6) | 286 (2.6) | 55.8 (10.4) | 170 (59.4) | 116 (40.6) | 480 (2.3) | 10 (2.1) | 384 (80.0) | 86 (17.9) |
| 16 | 647 (2.2) | 1.1 (0.4) | 336 (3.0) | 56.3 (9.4) | 184 (54.8) | 151 (44.9) | 587 (2.9) | 17 (2.9) | 557 (94.9) | 13 (2.2) |
| 17 | 1486 (5.0) | 2.0 (0.5) | 380 (3.4) | 57.1 (11.2) | 181 (47.6) | 198 (52.1) | 725 (3.5) | 36 (5.0) | 612 (84.4) | 77 (10.6) |
| 18 | 1092 (3.7) | 1.0 (0.2) | 586 (5.2) | 66.7 (12.3) | 92 (15.7) | 494 (84.3) | 1044 (5.1) | 17 (1.6) | 685 (65.6) | 342 (32.8) |
| 19 | 2149 (7.2) | 2.9 (1.2) | 377 (3.4) | 54.5 (9.0) | 235 (62.3) | 142 (37.7) | 731 (3.6) | 27 (3.7) | 693 (94.8) | 11 (1.5) |
| 20 | 1495 (5.0) | 1.1 (0.2) | 748 (6.7) | 59.9 (11.2) | 426 (57.0) | 322 (43.0) | 1410 (6.9) | 92 (6.5) | 1204 (85.4) | 114 (8.1) |
| Total | 29,656 | 1.4 (0.7) | 11,199 | 57.7 (11.1) | 5365 (47.9) | 5824 (52.0) | 20,489 | 772 (3.8) | 16,434 (80.2) | 3283 (16.0) |
| Precision | Recall | F-Score | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Referable | Non-Referable | Ungradable | Referable | Non-Referable | Ungradable | Referable | Non-Referable | Ungradable | |
| 1 | 19.30 (10.05–31.91) | 99.70 (99.13–99.94) | 28.32 (24.48–32.41) | 47.83 (26.82–69.41) | 71.01 (68.56–73.37) | 98.66 (95.24–99.84) | 27.50 (18.10–38.62) | 82.95 (81.38–84.43) | 44.01 (40.21–47.87) |
| 2 | 54.05 (44.33–63.55) | 96.09 (94.91–97.06) | 52.89 (47.61–58.12) | 55.56 (45.68–65.12) | 86.05 (84.21–87.76) | 92.31 (87.81–95.54) | 54.79 (47.95–61.51) | 90.79 (89.68–91.83) | 67.25 (63.23–71.09) |
| 3 | 19.05 (5.45–41.91) | 87.96 (83.50–91.56) | 61.92 (55.96–67.62) | 33.33 (9.92–65.11) | 68.08 (62.95–72.91) | 82.86 (77.07–87.7) | 24.24 (11.09–42.26) | 76.75 (73.25–80.00) | 70.88 (66.64–74.86) |
| 4 | 23.26 (11.76–38.63) | 96.84 (95.47–97.89) | 79.25 (70.28–86.51) | 71.43 (41.90–91.61) | 94.81 (93.16–96.16) | 72.41 (63.34–80.3) | 35.09 (22.91–48.87) | 95.82 (94.78–96.70) | 75.68 (69.48–81.17) |
| 5 | 18.18 (2.28–51.78) | 96.23 (91.97–98.60) | 47.54 (34.60–60.73) | 50.00 (6.76–93.24) | 79.27 (72.87–84.76) | 85.29 (68.94–95.05) | 26.67 (7.79–55.10) | 86.93 (82.96–90.27) | 61.05 (50.50–70.89) |
| 6 | 32.18 (22.56–43.06) | 97.44 (96.03–98.45) | 45.64 (38.51–52.91) | 56.00 (41.25–70.01) | 82.16 (79.47–84.63) | 94.68 (88.02–98.25) | 40.88 (32.56–49.60) | 89.15 (87.53–90.62) | 61.59 (55.72–67.23) |
| 7 | 61.90 (51.91–71.21) | 92.87 (90.94–94.51) | 83.33 (75.20–89.66) | 71.43 (61.00–80.41) | 94.08 (92.27–95.58) | 68.35 (59.92–75.97) | 66.33 (59.25–72.90) | 93.47 (92.19–94.60) | 75.10 (69.30–80.30) |
| 8 | 40.66 (33.45–48.17) | 97.25 (96.14–98.11) | 41.54 (37.03–46.16) | 59.20 (50.05–67.90) | 76.68 (74.43–78.82) | 91.51 (86.91–94.89) | 48.21 (42.50–53.95) | 85.75 (84.35–87.06) | 57.14 (53.32–60.90) |
| 9 | 13.48 (8.31–20.24) | 90.37 (88.45–92.06) | 83.26 (77.58–87.99) | 86.36 (65.09–97.09) | 89.05 (87.05–90.84) | 56.29 (50.64–61.82) | 23.31 (17.06–30.57) | 89.71 (88.35–90.95) | 67.17 (63.00–71.14) |
| 10 | 22.73 (16.37–30.16) | 73.65 (71.25–75.95) | 86.85 (83.15–89.99) | 71.43 (56.74–83.42) | 89.66 (87.74–91.36) | 46.3 (42.70–49.93) | 34.48 (27.97–41.46) | 80.87 (79.28–82.39) | 60.4 (57.51–63.23) |
| 11 | 44.19 (29.08–60.12) | 96.79 (93.77–98.60) | 77.63 (66.62–86.40) | 90.48 (69.62–98.83) | 87.64 (83.15–91.28) | 81.94 (71.11–90.02) | 59.38 (46.37–71.49) | 91.98 (89.32–94.16) | 79.73 (72.34–85.89) |
| 12 | 9.16 (4.82–15.45) | 90.55 (88.74–92.16) | 93.39 (87.39–97.10) | 100.0 (73.54–100.0) | 92.93 (91.28–94.34) | 41.85 (35.90–47.98) | 16.78 (11.06–23.94) | 91.72 (90.53–92.81) | 57.80 (52.73–62.75) |
| 13 | 20.69 (11.17–33.35) | 94.33 (91.91–96.20) | 58.97 (42.10–74.43) | 60.00 (36.05–80.88) | 89.10 (86.11–91.64) | 47.92 (33.29–62.81) | 30.77 (20.81–42.24) | 91.64 (89.77–93.27) | 52.87 (41.87–63.67) |
| 14 | 28.33 (17.45–41.44) | 99.17 (97.89–99.77) | 25.58 (13.52–41.17) | 77.27 (54.63–92.18) | 87.07 (83.97–89.76) | 78.57 (49.20–95.34) | 41.46 (30.68–52.88) | 92.73 (90.97–94.24) | 38.60 (26.00–52.43) |
| 15 | 28.57 (13.22–48.67) | 88.03 (84.44–91.04) | 72.55 (58.26–84.11) | 80.00 (44.39–97.48) | 91.93 (88.74–94.45) | 43.02 (32.39–54.15) | 42.11 (26.31–59.18) | 89.94 (87.62–91.95) | 54.01 (45.30–62.56) |
| 16 | 19.70 (10.93–31.32) | 99.16 (97.87–99.77) | 25.58 (13.52–41.17) | 76.47 (50.10–93.19) | 85.10 (81.87–87.95) | 84.62 (54.55–98.08) | 31.33 (21.59–42.44) | 91.59 (89.73–93.21) | 39.29 (26.50–53.25) |
| 17 | 32.63 (23.36–43.02) | 92.98 (90.62–94.89) | 93.75 (79.19–99.23) | 86.11 (70.5–95.33) | 90.85 (88.28–93.01) | 38.96 (28.05–50.75) | 47.33 (38.55–56.23) | 91.90 (90.22–93.38) | 55.05 (45.22–64.59) |
| 18 | 20.00 (11.65–30.83) | 84.59 (81.73–87.16) | 83.53 (78.40–87.86) | 88.24 (63.56–98.54) | 88.18 (85.52–90.5) | 62.28 (56.91–67.44) | 32.61 (23.20–43.18) | 86.35 (84.44–88.10) | 71.36 (67.55–74.95) |
| 19 | 27.17 (18.42–37.45) | 99.67 (98.83–99.96) | 40.00 (21.13–61.33) | 92.59 (75.71–99.09) | 88.31 (85.68–90.61) | 90.91 (58.72–99.77) | 42.02 (33.03–51.41) | 93.65 (92.19–94.91) | 55.56 (38.10–72.06) |
| 20 | 32.00 (21.69–43.78) | 93.62 (92.01–95.00) | 40.51 (34.20–47.05) | 26.09 (17.48–36.29) | 85.38 (83.26–87.33) | 84.21 (76.2–90.37) | 28.74 (22.01–36.24) | 89.31 (87.98–90.55) | 54.70 (49.33–59.99) |
| Total | 29.6 (27.40–31.88) | 92.56 (92.13–92.97) | 58.58 (56.97–60.19) | 62.69 (59.17–66.12) | 85.65 (85.11–86.18) | 65.06 (63.40–66.69) | 40.22 (38.25–42.21) | 88.97 (88.62–89.31) | 61.65 (60.50–62.80) |
| Gradability | Hospital-Referable | ||||
|---|---|---|---|---|---|
| Sensitivity (95% CI) | Specificity (95% CI) | Sensitivity (95% CI) | Specificity (95% CI) | ||
| Site | 1 | 73.93 (71.57–76.19) | 98.66 (95.24–99.84) | 98.26 (94.99–99.64) | 71.01 (68.56–73.37) |
| 2 | 89.45 (87.85–90.9) | 92.31 (87.81–95.54) | 83.23 (78.64–87.18) | 86.05 (84.21–87.76) | |
| 3 | 70.77 (65.81–75.38) | 82.86 (77.07–87.7) | 85.14 (79.76–89.54) | 68.08 (62.95–72.91) | |
| 4 | 97.61 (96.4–98.5) | 72.41 (63.34–80.3) | 78.46 (70.4–85.19) | 94.81 (93.16–96.16) | |
| 5 | 83.76 (77.85–88.62) | 85.29 (68.94–95.05) | 84.21 (68.75–93.98) | 79.27 (72.87–84.76) | |
| 6 | 88.6 (86.38–90.57) | 94.68 (88.02–98.25) | 86.81 (80.16–91.87) | 82.16 (79.47–84.63) | |
| 7 | 97.97 (96.85–98.77) | 68.35 (59.92–75.97) | 73.48 (67.28–79.06) | 94.08 (92.27–95.58) | |
| 8 | 82.94 (81.0–84.75) | 91.51 (86.91–94.89) | 90.5 (86.86–93.41) | 76.68 (74.43–78.82) | |
| 9 | 96.78 (95.57–97.73) | 56.29 (50.64–61.82) | 69.41 (64.21–74.27) | 89.05 (87.05–90.84) | |
| 10 | 95.55 (94.21–96.65) | 46.3 (42.7–49.93) | 54.53 (51.02–58.01) | 89.66 (87.74–91.36) | |
| 11 | 94.26 (90.96–96.62) | 81.94 (71.11–90.02) | 91.4 (83.75–96.21) | 87.64 (83.15–91.28) | |
| 12 | 99.31 (98.64–99.7) | 41.85 (35.9–47.98) | 60.64 (54.67–66.38) | 92.93 (91.28–94.34) | |
| 13 | 97.05 (95.26–98.31) | 47.92 (33.29–62.81) | 58.82 (46.23–70.63) | 89.10 (86.11–91.64) | |
| 14 | 94.4 (92.18–96.14) | 78.57 (49.2–95.34) | 88.89 (73.94–96.89) | 87.07 (83.97–89.76) | |
| 15 | 96.45 (94.11–98.04) | 43.02 (32.39–54.15) | 50.00 (39.62–60.38) | 91.93 (88.74–94.45) | |
| 16 | 94.43 (92.22–96.16) | 84.62 (54.55–98.08) | 86.67 (69.28–96.24) | 85.1 (81.87–87.95) | |
| 17 | 99.69 (98.89–99.96) | 38.96 (28.05–50.75) | 62.83 (53.24–71.74) | 90.85 (88.28–93.01) | |
| 18 | 94.02 (92.0–95.65) | 62.28 (56.91–67.44) | 69.36 (64.31–74.09) | 88.18 (85.52–90.5) | |
| 19 | 97.92 (96.59–98.83) | 90.91 (58.72–99.77) | 94.74 (82.25–99.36) | 88.31 (85.68–90.61) | |
| 20 | 89.12 (87.3–90.76) | 84.21 (76.2–90.37) | 66.02 (59.11–72.46) | 85.38 (83.26–87.33) | |
| Age | ≤40 | 91.61 (88.57–94.05) | 66.67 (34.89–90.08) | 63.64 (40.66–82.8) | 91.41 (88.3–93.91) |
| 41–60 | 93.13 (92.64–93.59) | 61.36 (58.51–64.15) | 69.57 (67.28–71.79) | 89.21 (88.6–89.79) | |
| 61–70 | 88.14 (87.11–89.12) | 65.41 (62.57–68.17) | 72.72 (70.28–75.06) | 80.09 (78.79–81.35) | |
| >70 | 86.35 (84.64–87.93) | 69.30 (66.26–72.23) | 75.44 (72.68–78.06) | 74.61 (72.45–76.68) | |
| Visual Acuity | Normal | 91.41 (90.93–91.87) | 62.15 (60.06–64.21) | 69.39 (67.61–71.12) | 86.73 (86.14–87.3) |
| VI | 90.71 (89.59–91.74) | 67.95 (64.81–70.98) | 75.27 (72.62–77.79) | 81.56 (80.04–83.01) | |
| Severe VI | 82.46 (74.21–88.94) | 80.82 (69.92–89.1) | 87.06 (78.02–93.36) | 71.57 (61.78–80.06) | |
| Blind | 78.79 (70.82–85.42) | 81.43 (73.98–87.5) | 86.84 (80.41–91.77) | 65.00 (55.76–73.48) | |
| All data | 91.22 (90.79–91.64) | 65.06 (63.40–66.69) | 72.08 (70.68–73.46) | 85.65 (85.11–86.18) | |
| Quadratic Weighted K (95% CI) | |||
|---|---|---|---|
| Referable DR | Gradability | Hospital Referable | |
| Primary vs. Secondary | 0.60 (0.57, 0.63) | 0.60 (0.58, 0.61) | 0.60 (0.58, 0.61) |
| Final grade (GT) vs. Primary | 0.66 (0.64, 0.69) | 0.67 (0.65, 0.68) | 0.67 (0.66, 0.69) |
| Final grade (GT) vs. Secondary | 0.84 (0.83, 0.86) | 0.84 (0.83, 0.85) | 0.84 (0.84, 0.85) |
| VISUHEALTH-AI DR vs. GT | 0.47 (0.44, 0.50) | 0.54 (0.52, 0.56) | 0.51 (0.50, 0.53) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nunez do Rio, J.M.; Nderitu, P.; Bergeles, C.; Sivaprasad, S.; Tan, G.S.W.; Raman, R. Evaluating a Deep Learning Diabetic Retinopathy Grading System Developed on Mydriatic Retinal Images When Applied to Non-Mydriatic Community Screening. J. Clin. Med. 2022, 11, 614. https://doi.org/10.3390/jcm11030614
Nunez do Rio JM, Nderitu P, Bergeles C, Sivaprasad S, Tan GSW, Raman R. Evaluating a Deep Learning Diabetic Retinopathy Grading System Developed on Mydriatic Retinal Images When Applied to Non-Mydriatic Community Screening. Journal of Clinical Medicine. 2022; 11(3):614. https://doi.org/10.3390/jcm11030614
Chicago/Turabian StyleNunez do Rio, Joan M., Paul Nderitu, Christos Bergeles, Sobha Sivaprasad, Gavin S. W. Tan, and Rajiv Raman. 2022. "Evaluating a Deep Learning Diabetic Retinopathy Grading System Developed on Mydriatic Retinal Images When Applied to Non-Mydriatic Community Screening" Journal of Clinical Medicine 11, no. 3: 614. https://doi.org/10.3390/jcm11030614
APA StyleNunez do Rio, J. M., Nderitu, P., Bergeles, C., Sivaprasad, S., Tan, G. S. W., & Raman, R. (2022). Evaluating a Deep Learning Diabetic Retinopathy Grading System Developed on Mydriatic Retinal Images When Applied to Non-Mydriatic Community Screening. Journal of Clinical Medicine, 11(3), 614. https://doi.org/10.3390/jcm11030614