
Natural Language Processing for Information Extraction of Gastric Diseases and Its Application in Large-Scale Clinical Research

 , , , and
, , , and
Abstract
:1. Introduction
Background
2. Materials and Methods
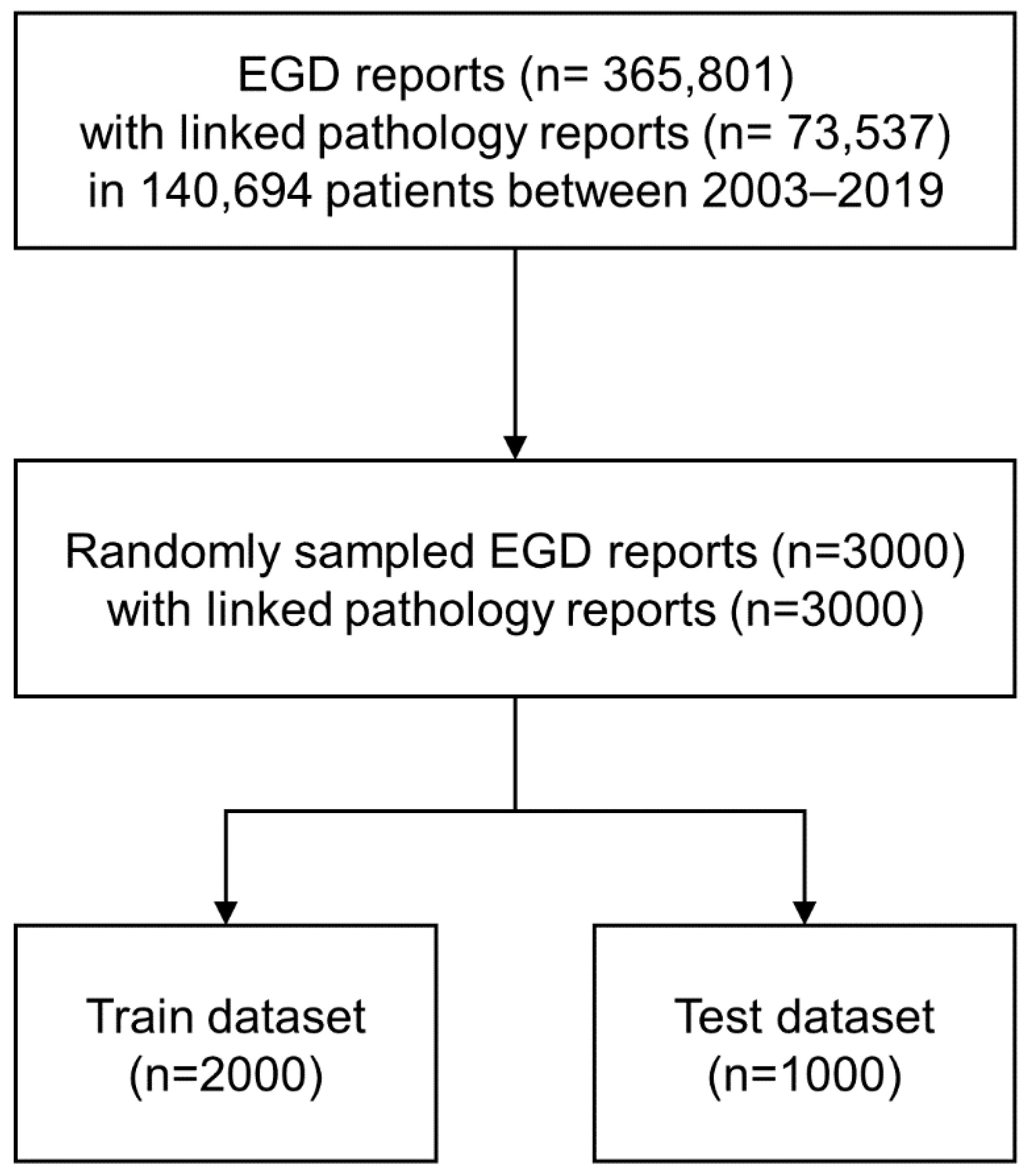
2.1. Study Design and Setting
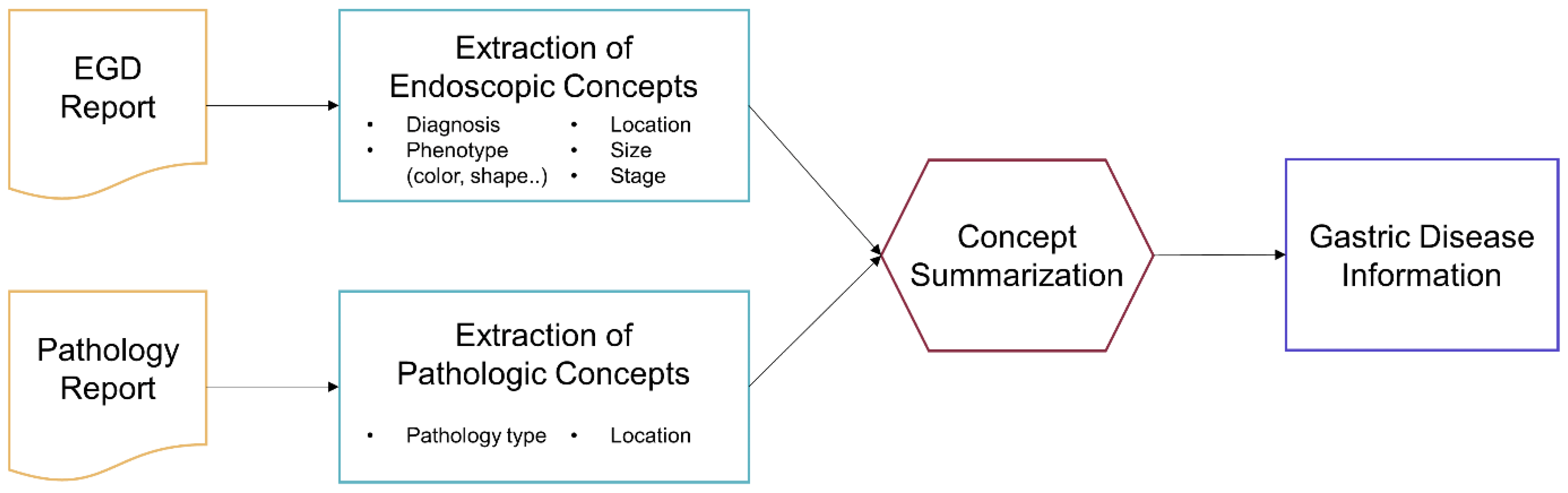
2.2. Target Variables for Information Extraction
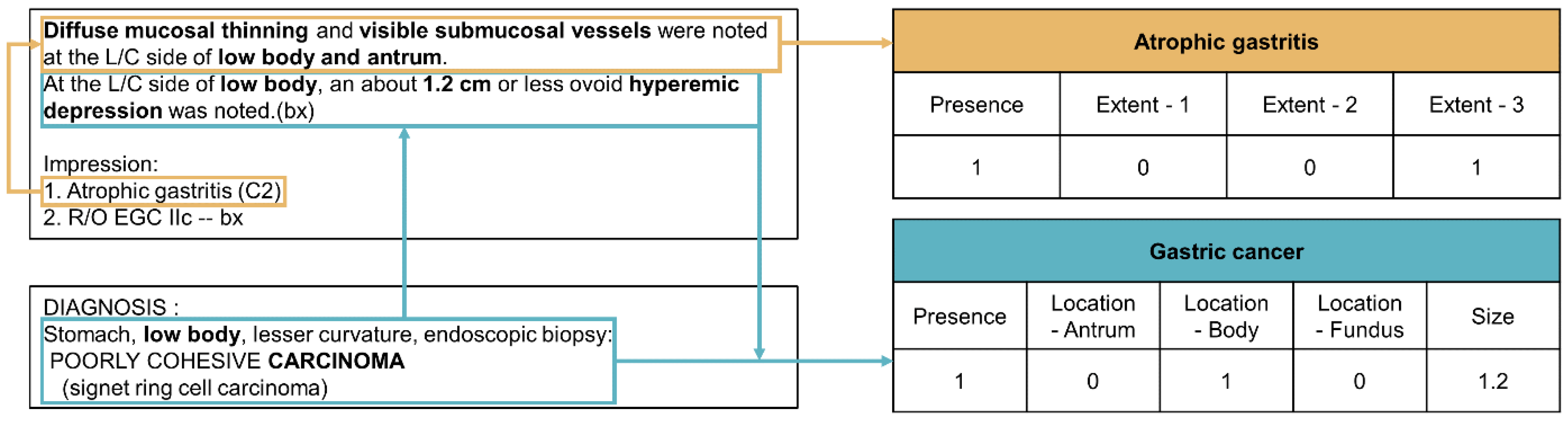
2.3. NLP Pipeline Development
2.4. Application of the NLP Pipeline
2.5. Statistical Analysis and Performance Evaluation
3. Results
3.1. Performance for Information Extraction of 10 Gastric Disease
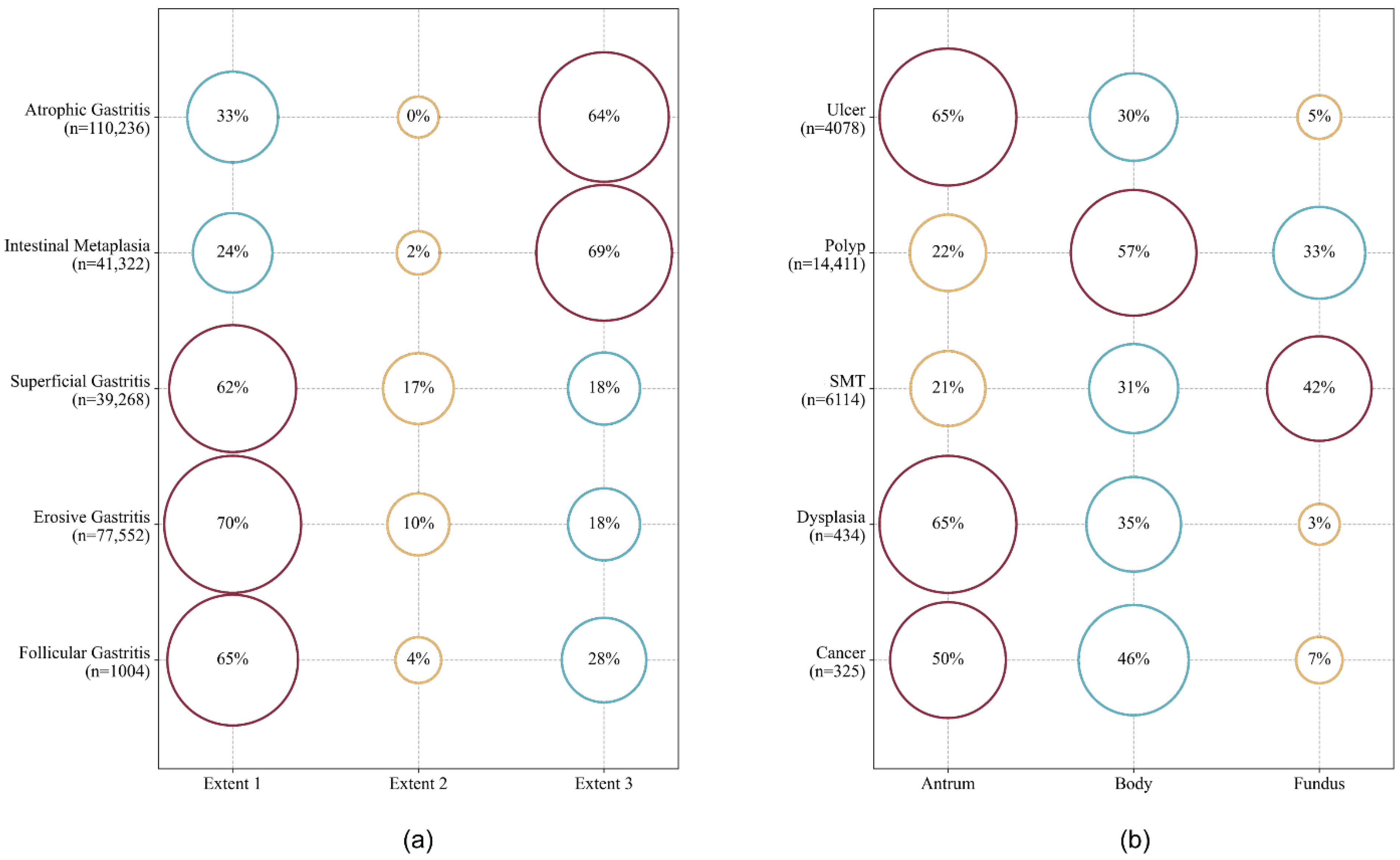
3.2. Demographics of Gastric Diseases Based on the 10-Year EGD Data
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hong, S.; Won, Y.J.; Lee, J.J.; Jung, K.W.; Kong, H.J.; Im, J.S.; Hong, G.S.; Community of Population-Based Regional Cancer Registries. Cancer statistics in Korea: Incidence, mortality, survival, and prevalence in 2018. Cancer Res. Treat. 2021, 53, 301–315. [Google Scholar] [CrossRef] [PubMed]
- Rawla, P.; Barsouk, A. Epidemiology of gastric cancer: Global trends, risk factors and prevention. Gastroenterol. Rev. 2019, 14, 26–38. [Google Scholar] [CrossRef] [PubMed]
- National Health Insurance Service. National Health Screening Statistical Yearbook; National Health Insurance Service: Wonju, Korea, 2020.
- Harkema, H.; Chapman, W.W.; Saul, M.; Dellon, E.S.; Schoen, R.E.; Mehrotra, A. Developing a natural language processing application for measuring the quality of colonoscopy procedures. J. Am. Med. Inform. Assoc. 2011, 18, i150–i156. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Savova, G.K.; Kipper-Schuler, K.C.; Hurdle, J.F.; Meystre, S.M. Extracting Information from Textual Documents in the Electronic Health Record: A Review of Recent Research. Yearb. Med. Inform. 2008, 17, 128–144. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2019, 36, 1234–1240. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Liu, Y.; Qian, M.; Guan, C.; Yuan, X. Information Extraction from Electronic Medical Records Using Multitask Recurrent Neural Network with Contextual Word Embedding. Appl. Sci. 2019, 9, 3658. [Google Scholar] [CrossRef] [Green Version]
- Kormilitzin, A.; Vaci, N.; Liu, Q.; Nevado-Holgado, A. Med7: A transferable clinical natural language processing model for electronic health records. Artif. Intell. Med. 2021, 118, 102086. [Google Scholar] [CrossRef] [PubMed]
- Do, R.K.G.; Lupton, K.; Andrieu, P.I.C.; Luthra, A.; Taya, M.; Batch, K.; Nguyen, H.; Rahurkar, P.; Gazit, L.; Nicholas, K.; et al. Patterns of Metastatic Disease in Patients with Cancer Derived from Natural Language Processing of Structured CT Radiology Reports over a 10-year Period. Radiology 2021, 301, 115–122. [Google Scholar] [CrossRef] [PubMed]
- Bae, J.H.; Han, H.W.; Yang, S.Y.; Song, G.; Sa, S.; Chung, G.E.; Seo, J.Y.; Jin, E.H.; Kim, H.; An, D. Natural Language Processing for Assessing Quality Indicators in Free-Text Colonoscopy and Pathology Reports: Development and Usability Study. JMIR Med. Inform. 2022, 10, e35257. [Google Scholar] [CrossRef] [PubMed]
- Fevrier, H.B.; Liu, L.; Herrinton, L.J.; Li, D. A Transparent and Adaptable Method to Extract Colonoscopy and Pathology Data Using Natural Language Processing. J. Med. Syst. 2020, 44, 151. [Google Scholar] [CrossRef] [PubMed]
- Imler, T.D.; Morea, J.; Kahi, C.; Imperiale, T.F. Natural Language Processing Accurately Categorizes Findings from Colonoscopy and Pathology Reports. Clin. Gastroenterol. Hepatol. 2013, 11, 689–694. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nehme, F.; Feldman, K. Evolving Role and Future Directions of Natural Language Processing in Gastroenterology. Am. J. Dig. Dis. 2020, 66, 29–40. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Mehrabi, S.; Sohn, S.; Atkinson, E.J.; Amin, S.; Liu, H. Natural language processing of radiology reports for identification of skeletal site-specific fractures. BMC Med. Inform. Decis. Mak. 2019, 19 (Suppl. 3), 73. [Google Scholar] [CrossRef] [Green Version]
- Wyles, C.C.; Tibbo, M.E.; Fu, S.; Wang, Y.; Sohn, S.; Kremers, W.K.; Berry, D.J.; Lewallen, D.G.; Maradit-Kremers, H. Use of Natural Language Processing Algorithms to Identify Common Data Elements in Operative Notes for Total Hip Arthroplasty. J. Bone Jt. Surg. 2019, 101, 1931–1938. [Google Scholar] [CrossRef]
- Van Rossum, G. The Python Library Reference, Release 3.7.10; Python Software Foundation: Wilmington, DE, USA, 2020. [Google Scholar]
- Korean Medical Association. Medical Terminology, 6th ed.; Koonja Publishing Inc.: Seoul, Korea, 2020. [Google Scholar]
- Song, G.A.; Kim, S.H.; Kim, T.O.; Kang, D.H. Guide of Gastroenterological Endoscopy in Clinical Practice; Korean Society of Gastrointestinal Endoscopy: Seoul, Korea, 2013.
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0 Contributors. SciPy 1.0 Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [Green Version]
- Kim, Y.; Jernite, Y.; Sontag, D.; Rush, A.M. Character-aware neural language models. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 5 March 2016. [Google Scholar]
- Mitra, B.; Craswell, N. Neural text embeddings for information retrieval. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 813–814. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural machine translation of rare words with subword units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Train Dataset (n = 2000) | Test Dataset (n = 1000) | p-Value | |
|---|---|---|---|---|
| Age, n (%) | 0.548 | |||
| <30 | 48 (2.4) | 19 (1.9) | ||
| 30–49 | 761 (38.0) | 395 (39.5) | ||
| 50–69 | 1091 (54.6) | 529 (52.9) | ||
| ≥70 | 100 (5.0) | 57 (5.7) | ||
| Sex, n (%) | 0.643 | |||
| Male | 1229 (61.4) | 605 (60.5) | ||
| Female | 771 (38.6) | 395 (39.5) | ||
| Chronic gastritis, n (%) | ||||
| Atrophic gastritis | 880 (44.0) | 415 (41.5) | 0.206 | |
| Intestinal metaplasia | 491 (24.6) | 223 (22.3) | 0.187 | |
| Superficial gastritis | 225 (11.2) | 97 (9.7) | 0.228 | |
| Erosive gastritis | 1195 (59.8) | 597 (59.7) | 0.989 | |
| Follicular gastritis | 5 (0.2) | 5 (0.5) | 0.433 | |
| Other gastric diseases, n (%) | ||||
| Ulcer | 163 (8.2) | 86 (8.6) | 0.726 | |
| Polyp | 404 (20.2) | 224 (22.4) | 0.177 | |
| SMT | 80 (4.0) | 36 (3.6) | 0.663 | |
| Dysplasia * | 22 (1.1) | 8 (0.8) | 0.559 | |
| Cancer † | 9 (0.4) | 8 (0.8) | 0.344 | |
| Variables | Sensitivity | PPV | Accuracy | F1-Score | ||
|---|---|---|---|---|---|---|
| Atrophic Gastritis | ||||||
| Presence | 0.993 | 1.000 | 0.997 | 0.996 | ||
| Extent * | ||||||
| 1 | 0.952 | 1.000 | 0.993 | 0.945 | ||
| 2 | 1.000 | 0.800 | 0.999 | 0.889 | ||
| 3 | 0.992 | 0.988 | 0.995 | 0.990 | ||
| Intestinal Metaplasia | ||||||
| Presence | 1.000 | 1.000 | 1.000 | 1.000 | ||
| Extent * | ||||||
| 1 | 0.959 | 0.973 | 0.995 | 0.966 | ||
| 2 | 1.000 | 1.000 | 1.000 | 1.000 | ||
| 3 | 0.985 | 0.978 | 0.995 | 0.981 | ||
| Superficial Gastritis | ||||||
| Presence | 0.979 | 0.990 | 0.997 | 0.984 | ||
| Extent * | ||||||
| 1 | 0.984 | 1.000 | 0.999 | 0.992 | ||
| 2 | 0.885 | 1.000 | 0.997 | 0.939 | ||
| 3 | 1.000 | 0.900 | 0.999 | 0.974 | ||
| Erosive Gastritis | ||||||
| Presence | 0.990 | 0.998 | 0.993 | 0.994 | ||
| Extent * | ||||||
| 1 | 0.963 | 1.000 | 0.984 | 0.981 | ||
| 2 | 0.929 | 0.988 | 0.993 | 0.958 | ||
| 3 | 0.986 | 0.862 | 0.988 | 0.920 | ||
| Follicular Gastritis | ||||||
| Presence | 1.000 | 1.000 | 1.000 | 1.000 | ||
| Extent * | ||||||
| 1 | 0.750 | 1.000 | 0.999 | 0.857 | ||
| 2 | N/A | N/A | 1.000 | N/A | ||
| 3 | 1.000 | 1.000 | 1.000 | 1.000 | ||
| Overall | 0.966 | 0.972 | 0.996 | 0.967 | ||
| Variables | Sensitivity | PPV | Accuracy | F1-Score | ||
|---|---|---|---|---|---|---|
| Ulcer | ||||||
| Presence | 0.988 | 0.977 | 0.997 | 0.983 | ||
| Location | ||||||
| Antrum | 0.956 | 0.985 | 0.996 | 0.970 | ||
| Body | 1.000 | 0.952 | 0.999 | 0.976 | ||
| Fundus | 1.000 | 1.000 | 1.000 | 1.000 | ||
| Stages | ||||||
| Active | 1.000 | 1.000 | 1.000 | 1.000 | ||
| Healing | 1.000 | 1.000 | 1.000 | 1.000 | ||
| Scar | 0.977 | 0.956 | 0.997 | 0.966 | ||
| Size | N/A | N/A | 0.999 | N/A | ||
| Polyp | ||||||
| Presence | 0.991 | 1.000 | 0.998 | 0.996 | ||
| Location | ||||||
| Antrum | 1.000 | 0.964 | 0.997 | 0.982 | ||
| Body | 0.991 | 0.973 | 0.996 | 0.982 | ||
| Fundus | 0.983 | 1.000 | 0.999 | 0.991 | ||
| Size | N/A | N/A | 1.000 | N/A | ||
| SMT | ||||||
| Presence | 0.972 | 0.972 | 0.998 | 0.972 | ||
| Location | ||||||
| Antrum | 0.750 | 0.818 | 0.995 | 0.783 | ||
| Body | 1.000 | 1.000 | 1.000 | 1.000 | ||
| Fundus | 0.833 | 1.000 | 0.998 | 0.909 | ||
| Size | N/A | N/A | 0.999 | N/A | ||
| Dysplasia * | ||||||
| Presence | 1.000 | 1.000 | 1.000 | 1.000 | ||
| Location | ||||||
| Antrum | 1.000 | 1.000 | 1.000 | 1.000 | ||
| Body | 1.000 | 1.000 | 1.000 | 1.000 | ||
| Fundus | N/A | N/A | 1.000 | N/A | ||
| Size | N/A | N/A | 0.999 | N/A | ||
| Cancer † | ||||||
| Presence | 1.000 | 1.000 | 1.000 | 1.000 | ||
| Location | ||||||
| Antrum | 1.000 | 1.000 | 1.000 | 1.000 | ||
| Body | 1.000 | 1.000 | 1.000 | 1.000 | ||
| Fundus | 1.000 | 1.000 | 1.000 | 1.000 | ||
| Size | N/A | N/A | 1.000 | N/A | ||
| Overall | 0.975 | 0.982 | 0.999 | 0.978 | ||
| Gastritis | Gastric Ulcer, Polypoid Lesions, and Neoplastic Diseases | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Variables | Atrophic Gastritis | Intestinal Metaplasia | Superficial Gastritis | Erosive Gastritis | Follicular Gastritis | Ulcer | Polyp | SMT | Dysplasia * | Cancer † | |
| Sex, n (%) | |||||||||||
| Male, n = 136,184 | 68,719 (50.49) | 29,081 (21.36) | 19,906 (14.62) | 47,792 (35.11) | 308 (0.23) | 3002 (2.21) | 6050 (4.44) | 3050 (2.24) | 324 (0.24) | 230 (0.17) | |
| Female, n = 112,782 | 41,517 (36.82) | 12,241 (10.86) | 19,362 (17.17) | 29,760 (26.39) | 696 (0.62) | 1076 (0.95) | 8361 (7.42) | 3064 (2.72) | 110 (0.10) | 95 (0.08) | |
| Age group, n (%) | |||||||||||
| 18–19, n = 284 | 2 (0.70) | 1 (0.35) | 27 (9.51) | 45 (15.84) | 3 (1.06) | 0 (0.00) | 5 (1.76) | 4 (1.41) | 0 (0.00) | 0 (0.00) | |
| 20–29, n = 7888 | 276 (3.50) | 38 (0.48) | 1179 (14.95) | 1425 (18.06) | 121 (1.53) | 38 (0.48) | 320 (4.06) | 74 (0.94) | 0 (0.00) | 4 (0.05) | |
| 30–39, n = 32,028 | 3455 (10.79) | 619 (1.93) | 5904 (18.43) | 7440 (23.23) | 358 (1.12) | 224 (0.70) | 1874 (5.85) | 366 (1.14) | 4 (0.01) | 11 (0.03) | |
| 40–49, n = 71,049 | 21,996 (30.96) | 5999 (8.44) | 13,164 (18.53) | 21,012 (29.57) | 314 (0.44) | 794 (1.12) | 4329 (6.09) | 1215 (1.71) | 42 (0.06) | 52 (0.07) | |
| 50–59, n = 85,248 | 46,125 (54.11) | 16,735 (19.63) | 13,134 (15.41) | 29,084 (34.12) | 176 (0.21) | 1572 (1.84) | 4626 (5.43) | 2243 (2.63) | 152 (0.18) | 119 (0.14) | |
| 60–69, n = 39,513 | 27,937 (70.70) | 12,386 (31.35) | 4766 (12.06) | 14,064 (35.59) | 31 (0.08) | 996 (2.52) | 2366 (5.99) | 1560 (3.95) | 155 (0.39) | 88 (0.22) | |
| 70–79, n = 11,841 | 9519 (80.39) | 4998 (42.21) | 996 (8.41) | 4093 (34.57) | 1 (0.01) | 392 (3.31) | 798 (6.74) | 586 (4.95) | 63 (0.53) | 49 (0.41) | |
| ≥80, n = 1115 | 926 (83.05) | 546 (48.97) | 98 (8.79) | 389 (34.89) | 0 (0.00) | 62 (5.56) | 93 (8.34) | 66 (5.92) | 18 (1.61) | 2 (0.18) | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, G.; Chung, S.J.; Seo, J.Y.; Yang, S.Y.; Jin, E.H.; Chung, G.E.; Shim, S.R.; Sa, S.; Hong, M.S.; Kim, K.H.; et al. Natural Language Processing for Information Extraction of Gastric Diseases and Its Application in Large-Scale Clinical Research. J. Clin. Med. 2022, 11, 2967. https://doi.org/10.3390/jcm11112967
Song G, Chung SJ, Seo JY, Yang SY, Jin EH, Chung GE, Shim SR, Sa S, Hong MS, Kim KH, et al. Natural Language Processing for Information Extraction of Gastric Diseases and Its Application in Large-Scale Clinical Research. Journal of Clinical Medicine. 2022; 11(11):2967. https://doi.org/10.3390/jcm11112967
Chicago/Turabian StyleSong, Gyuseon, Su Jin Chung, Ji Yeon Seo, Sun Young Yang, Eun Hyo Jin, Goh Eun Chung, Sung Ryul Shim, Soonok Sa, Moongi Simon Hong, Kang Hyun Kim, and et al. 2022. "Natural Language Processing for Information Extraction of Gastric Diseases and Its Application in Large-Scale Clinical Research" Journal of Clinical Medicine 11, no. 11: 2967. https://doi.org/10.3390/jcm11112967
APA StyleSong, G., Chung, S. J., Seo, J. Y., Yang, S. Y., Jin, E. H., Chung, G. E., Shim, S. R., Sa, S., Hong, M. S., Kim, K. H., Jang, E., Lee, C. W., Bae, J. H., & Han, H. W. (2022). Natural Language Processing for Information Extraction of Gastric Diseases and Its Application in Large-Scale Clinical Research. Journal of Clinical Medicine, 11(11), 2967. https://doi.org/10.3390/jcm11112967