
Diagnosing Neurally Mediated Syncope Using Classification Techniques


Abstract
:1. Introduction
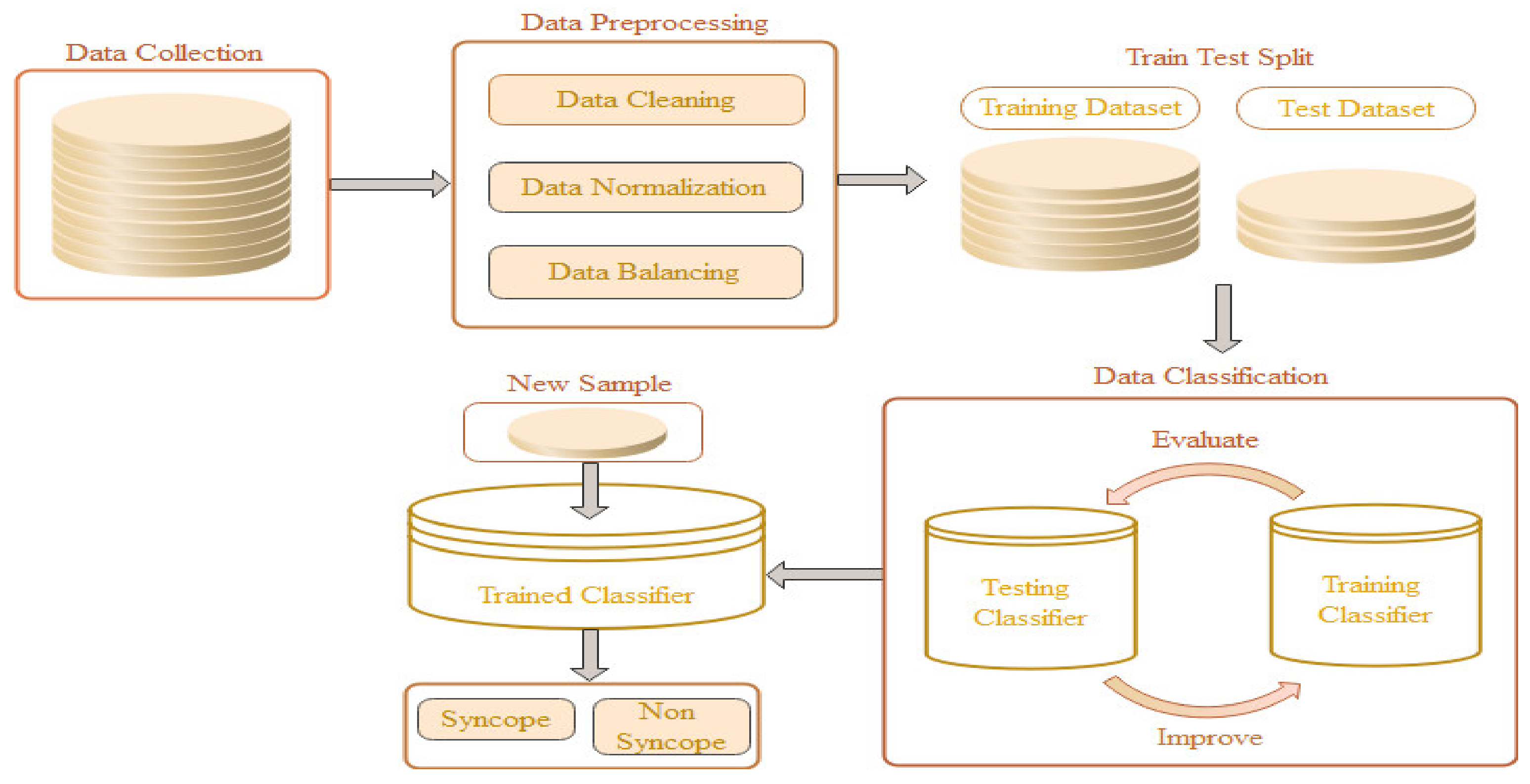
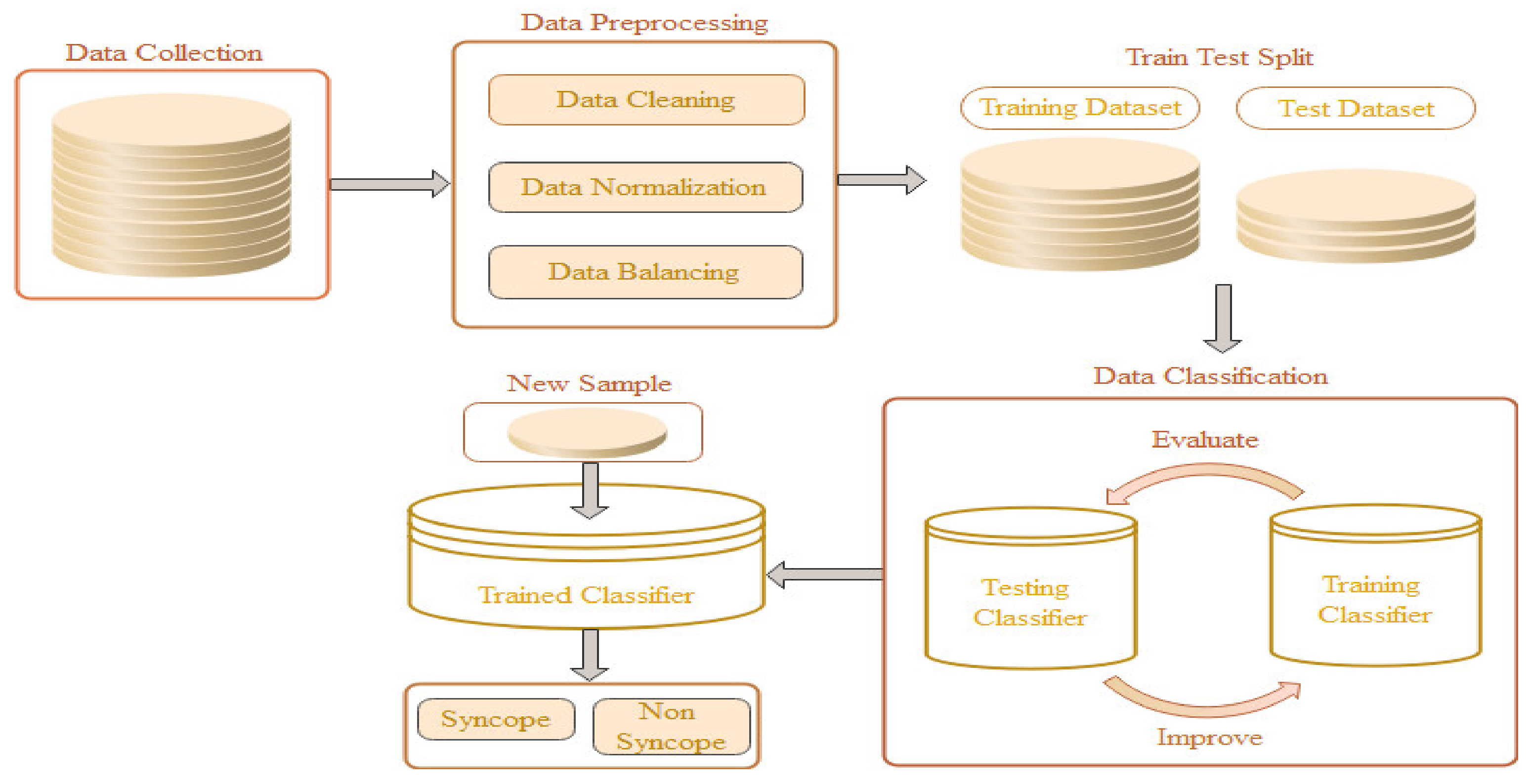
2. Syncope Classification Model
2.1. Data Collection
2.1.1. HUT Test
2.1.2. Physiological Indicators
2.2. Data Preprocessing
2.3. Data Classification
2.4. Performance Metrics
3. Experimental Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
| BeatStats | ||
|---|---|---|
| Acronym | Definition | Units |
| HR | Heart Rate | Beats/min |
| SV | Stroke Volume | Liter/beat |
| CO | Cardiac Output | Liter/min |
| CI | Cardiac Index | Liter/min/m2 |
| SI | Stroke Index | Ml/beat/m2 |
| RRI | RR Interval | Seconds |
| TPR | Total Peripheral Resistance | Pa·sec/m3 |
| TPRI | Total Peripheral Resistance Index | Pa·sec/m5 |
| dBP | Diastolic Blood Pressure | mmHg |
| mBp | Mean Blood Pressure | mmHg |
| sBP | Systolic Blood Pressure | mmHg |
| Cardiac BeatStats | ||
| ACI | Acceleration Index | m/s2 |
| CI | Cardiac Index | Liter/min/m2 |
| EDI | End-Diastolic Index | |
| HR | Heart Rate | Beats/min |
| IC | Index of Contractility | Seconds |
| LVET | Left Ventricular Primitive Ejection Time | Milliseconds |
| LVWI | Left Ventricular Stroke Work Index | Pa.ml/beat/m2 |
| SI | Stroke Index | Ml/beat/m2 |
| TFC | Thoracic Fluid Content | Liter |
| TPRI | Total Peripheral Resistance Index | Pa·sec/m5 |
| dBP | Diastolic Blood Pressure | mmHg |
| mBp | Mean Blood Pressure | mmHg |
| sBP | Systolic Blood Pressure | mmHg |
| HRV Stats | ||
| HF_RRI | High-Frequency RR Interval | Hz |
| HFnu_RRI | Normalized High-Frequency RR Interval | |
| LF_HF | Difference Between Low and High Frequency of RR Interval | Hz |
| LF_HF_RRI | The ratio of Low and High Frequency of RR Interval | |
| LF_RRI | Low-Frequency RR Interval | Hz |
| LFnu_RRI | Normalized Low-Frequency RR Interval | |
| PSD_RRI | Power Spectral Density of RR Interval | W/Hz |
| VLF_RRI | Very Low Frequency of RR Interval | Hz |
| dBPV Stats | ||
| HF_dBP | High-Frequency dBP | Hz |
| HFnu_dBP | Normalized High-Frequency dBP | |
| LF_HF | Difference Between Low and High Frequency of dBP | Hz |
| LF_HF_dBP | Ratio of Low and High Frequency of dBP | |
| LF_dBP | Low-Frequency dBP | Hz |
| LFnu_dBP | Normalized Low-Frequency dBP | |
| PSD_dBP | Power Spectral Density of dBP | W/Hz |
| VLF_dBP | Very Low Frequency of dBP | Hz |
| sBPV Stats | ||
| HF_sBP | High-Frequency sBP | Hz |
| HFnu_sBP | Normalized High-Frequency sBP | |
| LF_HF | Difference Between Low and High Frequency of sBP | Hz |
| LF_HF_sBP | Ratio of Low and High Frequency of sBP | |
| LF_sBP | Low-Frequency sBP | Hz |
| LFnu_sBP | Normalized Low-Frequency sBP | |
| PSD_sBP | Power Spectral Density of sBP | W/Hz |
| VLF_sBP | Very Low Frequency of sBP | Hz |
Appendix B
Appendix C
Appendix D
| Hardware | Specifications | Software | Specifications |
|---|---|---|---|
| Processor | Core i5 | Windows | 64-bit Windows 10 |
| Processor Clock Speed | 1.8 GHz | Scikit learn | 0.20.3 |
| Number of Cores | 4 | Pandas | 0.23.4 |
| RAM | 8 GB | NumPy | 1.14.3 |
| Cache Memory | 6 MB | Matplotlib | 3.0.2 |
| Processor Architecture | 64 bit | Seaborn | 0.11.1 |
| Processor Variant | 8265U | imblearn | 0.00 |
Appendix E
| SVM Parameters | |||||||
| Parameter | Value | Parameter | Value | Parameter | Value | Parameter | Value |
| C | 2 | kernal | Linear | degree | 3 | gamma | Auto |
| coef0 | 0.0 | shrinking | True | probability | False | tol | 0.001 |
| cache_ size | 200 | class_ weight | None | verbose | False | max_iter | −1 |
| decision_ function_ shape | ovr | break_ties | False | random_ state | None | ||
| LR Parameters | |||||||
| Parameter | Value | Parameter | Value | Parameter | Value | Parameter | Value |
| penalty | l2 | tol | 0.0001 | C | 1.0 | fit_intercept | True |
| dual | False | intercept_ scaling | 1 | class_weight | None | solver | Liblinear |
| max_iter | 100 | multi_class | Auto | verbose | 0 | random_ state | None |
| KNN Parameters | |||||||
| Parameter | Value | Parameter | Value | Parameter | Value | Parameter | Value |
| n_neighbor | 5 | weight | Uniform | algorithm | Auto | leaf_ size | 30 |
| p | 2 | metric | Minkowski | metric_ param | None | n_jobs | None |
| MNB Parameter | |||||||
| Parameter | Value | Parameter | Value | Parameter | Value | Parameter | Value |
| alpha | 1.0 | fit_prior | True | class_prior | None | alpha | 1.0 |
| GNB Parameter | |||||||
| Parameter | Value | Parameter | Value | Parameter | Value | Parameter | Value |
| priors | None | var_smoothing | 1 × 10−9 | priors | None | var_smoothing | 1 × 10−9 |
| DT Parameter | |||||||
| Parameter | Value | Parameter | Value | Parameter | Value | Parameter | Value |
| max_depth | 8 | max_features | None | max_leaf_node | None | min_sample_leaf | 10 |
| min_sample_split | 2 | random_state | 11 | splitter | Best | ||
References
- Moya, A.; Sutton, R.; Ammirati, F.; Blanc, J.-J.; Brignole, M.; Dahm, J.B.; Deharo, J.-C.; Gajek, J.; Gjesdal, K.; Krahn, A.; et al. The Task Force for the Diagnosis and Management of Syncope of the European Society of Cardiology (ESC). Guidelines for the diagnosis and management of syncope (version 2009). Eur. Heart J. 2009, 30, 2631–2671. [Google Scholar] [PubMed] [Green Version]
- Cvirn, G.; Schlagenhauf, A.; Leschnik, B.; Koestenberger, M.; Roessler, A.; Jantscher, A.; Vrecko, K.; Juergens, G.; Hinghofer-Szalkay, H.; Goswami, N. Coagulation changes during presyncope and recovery. PLoS ONE 2012, 7, e42221. [Google Scholar] [CrossRef] [PubMed]
- Goswami, N.; Blaber, A.P.; Hinghofer-Szalkay, H.; Convertino, V.A. Lower body negative pressure: Physiological effects, applications, and implementation. Physiol. Rev. 2019, 99, 807–851. [Google Scholar] [CrossRef] [PubMed]
- Brignole, M.; Moya, A.; de Lange, F.J.; Deharo, J.C.; Elliott, P.M.; Fanciulli, A.; Fedorowski, A.; Furlan, R.; Kenny, R.A.; Martín, A.; et al. 2018 ESC Guidelines for the diagnosis and management of syncope. Eur. Heart J. 2018, 39, 1883–1948. [Google Scholar] [CrossRef]
- Blaber, A.P.; Goswami, N.; Bondar, R.L.; Kassam, M.S. Impairment of cerebral blood flow regulation in astronauts with post flight orthostatic intolerance. Stroke 2011, 42, 1844–1850. [Google Scholar] [CrossRef] [Green Version]
- Brignole, M.; Moya, A.; de Lange, F.J.; Deharo, J.C.; Elliott, P.M.; Fanciulli, A.; Fedorowski, A.; Furlan, R.; Kenny, R.A.; Martín, A.; et al. Practical Instructions for the 2018 ESC Guidelines for the diagnosis and management of syncope. Eur. Heart J. 2018, 39, 43–80. [Google Scholar] [CrossRef]
- Puppala, V.K.; Dickinson, O.; Benditt, D.G. Syncope: Classification and risk stratification. J. Cardiol. 2014, 63, 171–177. [Google Scholar] [CrossRef] [Green Version]
- Sutton, R. Clinical classification of syncope. Prog. Cardiovasc. 2013, 55, 339–344. [Google Scholar] [CrossRef]
- Thanavaro, J.L. Evaluation and management of syncope. Clin. Sch. Rev. 2009, 2, 65–77. [Google Scholar] [CrossRef]
- Jayaraman, P.P.; Forkan, A.R.M.; Morshed, A.; Haghighi, P.D.; Kang, Y.B. Healthcare 4.0: A review of frontiers in digital health. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 10, e1350. [Google Scholar] [CrossRef]
- Dolley, S. Big data’s role in precision public health. Front. Public Health 2018, 6, 68. [Google Scholar] [CrossRef]
- Kumar, V.; Recupero, D.R.; Riboni, D.; Helaoui, R. Ensembling Classical Machine Learning and Deep Learning Approaches for Morbidity Identification from Clinical Notes. IEEE Access 2020, 9, 7107–7126. [Google Scholar] [CrossRef]
- Li, J.P.; Haq, A.U.; Din, S.U.; Khan, J.; Khan, A.; Saboor, A. Heart Disease Identification Method Using Machine Learning Classification in E-Healthcare. IEEE Access 2020, 8, 107562–107582. [Google Scholar] [CrossRef]
- Wiens, J.; Shenoy, E.S. Machine learning for healthcare: On the verge of a major shift in healthcare epidemiology. Clin. Infect. Dis. 2018, 66, 149–153. [Google Scholar] [CrossRef] [Green Version]
- Yuvaraj, N.; SriPreethaa, K.R. Diabetes prediction in healthcare systems using machine learning algorithms on Hadoop cluster. Clust. Comput. 2019, 22, 1–9. [Google Scholar] [CrossRef]
- Hussain, S.; Raza, Z.; Giacomini, G.; Goswami, N. Support Vector Machine-Based Classification of Vasovagal Syncope Using Head-Up Tilt Test. Biology 2021, 10, 1029. [Google Scholar] [CrossRef]
- Parry, S.W.; Kenny, R.A. Tilt table testing in the diagnosis of unexplained syncope. QJM Int. J. Med. 1999, 92, 623–629. [Google Scholar] [CrossRef] [Green Version]
- Sutton, R.; Bloomfield, D.M. Indications, methodology, and classification of results of tilt-table testing. Am. J. Cardiol. 1999, 84, 10–19. [Google Scholar] [CrossRef]
- Goswami, N.; Lackner, H.K.; Papousek, I.; Montani, J.-P.; Jezova, D.; Hinghofer-Szalkay, H.G. Does mental arithmetic before head up tilt have an effect on the orthostatic cardiovascular and hormonal responses? Acta Astronaut. 2011, 68, 1589–1594. [Google Scholar] [CrossRef] [Green Version]
- Roessler, A.; Goswami, N.; Haditsch, B.; Loeppky, J.; Luft, F.; Hinghofer-Szalkay, H. Volume regulating hormone responses to repeated head-up tilt and lower body negative pressure. Eur. J. Clin. Investig. 2011, 41, 863–869. [Google Scholar] [CrossRef]
- Patel, K.; Rössler, A.; Lackner, H.K.; Trozic, I.; Laing, C.; Lorr, D.; Green, D.A.; Hinghofer-Szalkay, H.; Goswami, N. Effect of postural changes on cardiovascular parameters across gender. Medicine 2016, 95, 4149. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Goutte, C.; Gaussier, E. A probabilistic interpretation of precision recall and F-score, with implication for evaluation. In European Conference on Information Retrieval; Springer: Berlin/Heidelberg, Germany, 2005; pp. 345–359. [Google Scholar]
- Metz, C.E. Basic principles of ROC analysis. Semin. Nucl. Med. 1978, 8, 283–298. [Google Scholar] [CrossRef]
- Hart, J.; Mehlsen, J.; Olsen, C.H.; Olufsen, M.S.; Gremaud, P. Classification of syncope through data analytics. J. Latex Cl. Files 2016, arXiv:1609.02049v114, 1–7. [Google Scholar]
- Clarke, B.; Fokoue, E.; Zhang, H.H. Principles and Theory for Data Mining and Machine Learning; Springer Science & Business Media: Springer: New York, NY, USA, 2009; pp. 231–306. [Google Scholar]
- Brignole, M. Diagnosis and treatment of syncope. Heart 2007, 93, 130–136. [Google Scholar] [CrossRef] [Green Version]
- Mehlsen, J.; Kaijer, M.N.; Mehlsen, A.B. Autonomic and electrocardiographic changes in cardioinhibitory syncope. Europace 2008, 10, 91–95. [Google Scholar] [CrossRef]
- Van Dijk, J.G.; Thijs, R.D.; Benditt, D.G.; Wieling, W. A guide to disorders causing transient loss of consciousness: Focus on syncope. Nat. Rev. Neurol. 2009, 5, 438–448. [Google Scholar] [CrossRef]
- Wardrope, A.; Jamnadas-Khoda, J.; Broadhurst, M.; Grünewald, R.A.; Heaton, T.J.; Howell, S.J.; Koepp, M.; Parry, S.W.; Sisodiya, S.; Walker, M.C.; et al. Machine learning as a diagnostic decision aid for patients with transient loss of consciousness. Neurology: Clin. Pract. 2020, 10, 96–105. [Google Scholar] [CrossRef]
- Khodor, N.; Carrault, G.; Matelot, D.; Amoud, H.; Khalil, M.; du Boullay, N.T.; Carre, F.; Hernández, A. Early syncope detection during head up tilt test by analyzing interactions between cardio-vascular signals. Digit. Signal Process. 2016, 49, 86–94. [Google Scholar] [CrossRef]
- Dipaola, F.; Gatti, M.; Pacetti, V.; Bottaccioli, A.G.; Shiffer, D.; Minonzio, M.; Menè, R.; Giaj Levra, A.; Solbiati, M.; Costantino, G.; et al. Artificial intelligence algorithms and natural language processing for the recognition of syncope patients on emergency department medical records. J. Clin. Med. 2019, 8, 1677. [Google Scholar] [CrossRef] [Green Version]
- Rodriguez, J.; Blaber, A.P.; Kneihsl, M.; Trozic, I.; Ruedl, R.; Green, D.A.; Broadbent, J.; Xu, D.; Rössler, A.; Hinghofer-Szalkay, H.; et al. Poststroke alterations in heart rate variability during orthostatic challenge. Medicine 2017, 96, 5989. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Blain, H.; Masud, T.; Dargent-Molina, P.; Martin, F.C.; Rosendahl, E.; van der Velde, N.; Bousquet, J.; Benetos, A.; Cooper, C.; Kanis, J.A.; et al. A comprehensive fracture prevention strategy in older adults: The European Union Geriatric Medicine Society (EUGMS) statement. J. Nutr. Health Aging 2016, 20, 647–652. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bousquet, J.; Bewick, M.; Cano, A.; Eklund, P.; Fico, G.; Goswami, N.; Guldemond, N.A.; Henderson, D.; Hinkema, M.J.; Liotta, G.; et al. Building bridges for innovation in ageing: Synergies between action groups of the EIP on AHA. J. Nutr. Health Aging 2017, 21, 92–104. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goswami, N. Falls and fall-prevention in older persons: Geriatrics meets spaceflight! Front. Physiol. 2017, 8, 603. [Google Scholar] [CrossRef] [Green Version]
- Goswami, N.; Blaber, A.P.; Hinghofer-Szalkay, H.; Montani, J.P. Orthostatic intolerance in older persons: Etiology and countermeasures. Front. Physiol. 2017, 8, 803. [Google Scholar] [CrossRef] [Green Version]
- Batzel, J.J.; Goswami, N.; Lackner, H.K.; Roessler, A.; Bachar, M.; Kappel, F.; Hinghofer-Szalkay, H. Patterns of cardiovascular control during repeated tests of orthostatic loading. Cardiovasc. Eng. 2009, 9, 134. [Google Scholar] [CrossRef]
- Evans, J.M.; Knapp, C.F.; Goswami, N. Artificial gravity as a countermeasure to the cardiovascular deconditioning of spaceflight: Gender perspectives. Front. Physiol. 2018, 9, 716. [Google Scholar] [CrossRef]
- Goswami, N.; Reichmuth, J.; Di Mise, A.; Brix, B.; Roessler, A.; Centrone, M.; Ranieri, M.; Russo, A.; De Santo, N.G.; Tamma, G.; et al. Comparison between men and women of volume regulating hormones and aquaporin-2 excretion following graded central hypovolemia. Eur. J. Appl. Physiol. 2019, 119, 633–643. [Google Scholar] [CrossRef]
- Sachse, C.; Trozic, I.; Brix, B.; Roessler, A.; Goswami, N. Sex differences in cardiovascular responses to orthostatic challenge in healthy older persons: A pilot study. Physiol. Int. 2019, 106, 236–249. [Google Scholar] [CrossRef]
- Goswami, N.; Abulafia, C.; Vigo, D.; Moser, M.; Cornelissen, G.; Cardinali, D. Falls risk, circadian rhythms and melatonin: Current perspectives. Clin. Interv. Aging 2020, 15, 2165–2174. [Google Scholar] [CrossRef]
- Goswami, N.; Lackner, H.; Grasser, E.; Hinghofer-Szalkay, H. Individual stability of orthostatic tolerance response. Acta Physiol. Hung. 2009, 96, 157–166. [Google Scholar] [CrossRef]
- Frith, J.; Zalewski, P.; Klawe, J.J.; Pairman, J.; Bitner, A.; Tafil-Klawe, M.; Newton, J.L. Impaired blood pressure variability in chronic fatigue syndrome—a potential biomarker. QJM Int. J. Med. 2012, 105, 831–838. [Google Scholar] [CrossRef] [Green Version]
- Heathers, J.A. Everything Hertz: Methodological issues in short-term frequency-domain HRV. Front. Physiol. 2014, 5, 177. [Google Scholar] [CrossRef] [Green Version]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Kibriya, A.M.; Frank, E.; Pfahringer, B.; Holmes, G. Multinomial naive bayes for text categorization revisited. In AI 2004: Advances in Artificial Intelligence, Proceedings of the 17th Australian Joint Conference on Artificial Intelligence, Cairns, Australia, 4–6 December 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 488–499. [Google Scholar]
- Cheeseman, P.; Kelly, J.; Self, M.; Stutz, J.; Taylor, W.; Freeman, D. AutoClass: A Bayesian classification system. In Machine Learning Proceedings 1988, Proceedings of the Fifth International Conference on Machine Learning, Ann Arbor, MI, USA, 12–14 June 1988; University of Michigan: Ann Arbor, MI, USA, 1988; pp. 54–64. [Google Scholar]
- Duda, R.O.; Hart, P.E. Pattern Classification and Scene Analysis; Wiley: New York, NY, USA, 1973; Volume 3, pp. 731–739. [Google Scholar]
- Weston, J.; Watkins, C. Support vector machines for multi-class pattern recognition. In Proceedings of the Uropean Symposium on Artificial Neural Networks, Bruges, Belgium, 21–23 April 1999; Volume 99, pp. 219–224. [Google Scholar]
- Kleinbaum, D.G.; Dietz, K.; Gail, M.; Klein, M.; Klein, M. Logistic Regression: Statistics for Biology and Health; Springer: New York, NY, USA, 2002. [Google Scholar]
| Actual Value | |||
|---|---|---|---|
| Predicted Value | Positive | Negative | |
| Positive | TP | FP | |
| Negative | FN | TN | |
| Classifiers | Min | Max | Mean | SD |
|---|---|---|---|---|
| Decision Tree | 0.956521 | 1.00 | 0.978197 | 0.012331 |
| Gaussian Naïve Bayes | 0.927536 | 0.985507 | 0.959292 | 0.019032 |
| k-Nearest Neighbors | 0.855073 | 0.970588 | 0.914258 | 0.036931 |
| Multinomial Naïve Bayes | 0.397059 | 0.985507 | 0.575234 | 0.156069 |
| Support Vector Machine | 0.955882 | 1.00 | 0.975256 | 0.013813 |
| Logistic Regression | 0.970588 | 1.00 | 0.989812 | 0.013814 |
| Classifiers | Min | Max | Mean | SD |
|---|---|---|---|---|
| Decision Tree | 0.833333 | 1.00 | 0.953081 | 0.065427 |
| Gaussian Naïve Bayes | 0.60 | 1.00 | 0.792345 | 0.114308 |
| k-Nearest Neighbors | 0.875 | 1.00 | 0.959230 | 0.054528 |
| Multinomial Naïve Bayes | 0.333333 | 1.00 | 0.525029 | 0.183290 |
| Support Vector Machine | 0.75 | 1.00 | 0.899626 | 0.087672 |
| Logistic Regression | 0.75 | 1.00 | 0.922723 | 0.094551 |
| Classifiers | Min | Max | Mean | SD |
|---|---|---|---|---|
| Decision Tree | 0.60 | 1.00 | 0.866866 | 0.130834 |
| Gaussian Naïve Bayes | 0.80 | 1.00 | 0.939061 | 0.064175 |
| k-Nearest Neighbors | 0.20 | 0.70 | 0.431945 | 0.174117 |
| Multinomial Naïve Bayes | 0.80 | 1.00 | 0.977658 | 0.062855 |
| Support Vector Machine | 0.80 | 1.00 | 0.909733 | 0.077714 |
| Logistic Regression | 0.80 | 1.00 | 0.976079 | 0.063083 |
| Classifiers | Min | Max | Mean | SD |
|---|---|---|---|---|
| Decision Tree | 0.75 | 1.00 | 0.900775 | 0.076146 |
| Gaussian Naïve Bayes | 0.727273 | 0.96 | 0.858069 | 0.072367 |
| k-Nearest Neighbors | 0.333333 | 0.823529 | 0.574271 | 0.176757 |
| Multinomial Naïve Bayes | 0.235294 | 0.888889 | 0.434743 | 0.175213 |
| Support Vector Machine | 0.80 | 1.00 | 0.902410 | 0.062612 |
| Logistic Regression | 0.80 | 1.00 | 0.949312 | 0.070388 |
| Classifiers | Min | Max | Mean | SD |
|---|---|---|---|---|
| Decision Tree | 0.80 | 1.00 | 0.928496 | 0.062632 |
| Gaussian Naïve Bayes | 0.884375 | 0.982142 | 0.948923 | 0.028553 |
| k-Nearest Neighbors | 0.60 | 0.85 | 0.712434 | 0.086574 |
| Multinomial Naïve Bayes | 0.627119 | 0.90 | 0.710141 | 0.076134 |
| Support Vector Machine | 0.891379 | 1.00 | 0.949001 | 0.038459 |
| Logistic Regression | 0.892188 | 1.00 | 0.983263 | 0.032924 |
| Measures | Max (Min) | Max (Max) | Max (Mean) | Min (SD) |
|---|---|---|---|---|
| Accuracy | LR | DT, SVM, LR | LR | DT |
| Precision | k-NN | DT, GNB, k-NN, MNB, SVM, LR | k-NN | k-NN |
| Recall | k-NN | DT, GNB, MNB, SVM, LR | MNB, LR | MNB |
| F1-score | SVM, LR | DT, SVM, LR | LR | SVM |
| AUC-ROC | SVM, LR | DT, SVM, LR | LR | GNB |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hussain, S.; Raza, Z.; Kumar, T.V.V.; Goswami, N. Diagnosing Neurally Mediated Syncope Using Classification Techniques. J. Clin. Med. 2021, 10, 5016. https://doi.org/10.3390/jcm10215016
Hussain S, Raza Z, Kumar TVV, Goswami N. Diagnosing Neurally Mediated Syncope Using Classification Techniques. Journal of Clinical Medicine. 2021; 10(21):5016. https://doi.org/10.3390/jcm10215016
Chicago/Turabian StyleHussain, Shahadat, Zahid Raza, T V Vijay Kumar, and Nandu Goswami. 2021. "Diagnosing Neurally Mediated Syncope Using Classification Techniques" Journal of Clinical Medicine 10, no. 21: 5016. https://doi.org/10.3390/jcm10215016
APA StyleHussain, S., Raza, Z., Kumar, T. V. V., & Goswami, N. (2021). Diagnosing Neurally Mediated Syncope Using Classification Techniques. Journal of Clinical Medicine, 10(21), 5016. https://doi.org/10.3390/jcm10215016