
Unveiling Vaccine Hesitancy on Twitter: Analyzing Trends and Reasons during the Emergence of COVID-19 Delta and Omicron Variants

 ,
, 
 ,
,
Abstract
:1. Introduction
2. Literature Review
2.1. Twitter as a Source of Data in COVID-19 Context
2.2. Stance Detection
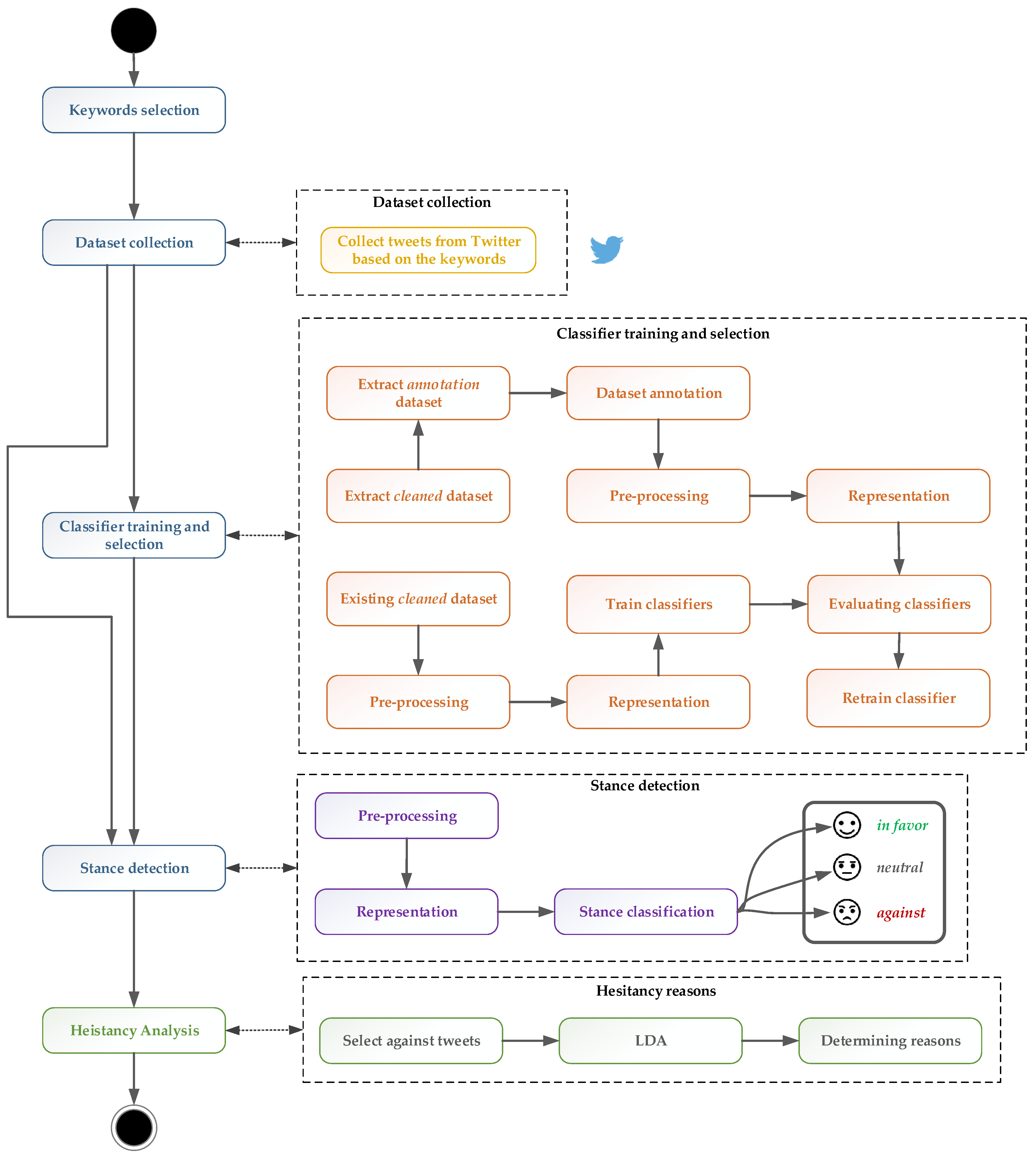
3. Methodology
3.1. Keyword Selection
3.2. Dataset Collection
3.3. Stance Detection
3.4. Hesitancy Analysis
4. Results
4.1. Extracting the Tweets
4.2. Selecting the Best Classifier
4.3. Comparative Analysis of Delta-Omicron Datasets
4.3.1. Entire Datasets
- 7 April 2021: Medicines and Healthcare Products Regulatory Agency announces that there might be a possible link between COVID-19 vaccine AstraZeneca and extremely rare, unlikely to occur blood clots [70]—supporting n-grams: “uk government” (1380 times), “side effects” (326 times), “astrazeneca vaccine” (281 times), “experts warn” (166 times), “medical experts” (164 times), “blood clots” (98), “people got” (88 times).
- 13 April 2021: The Centers for Disease Control and Prevention and the Food & Drug Administration have released a joint statement pausing the administration of the Johnson & Johnson vaccine due to extremely rare cases of blood clots [71]—supporting n-grams: “johnson & johnson” (315 times), “side effects” (153 times), “pause johnson & johnson” (80 times), “cdc fda” (64 times), “vaccine blood clot” (56 times).
- 19 April 2021: All US adults become eligible to receive COVID-19 vaccines [72]—supporting n-grams: “side effects” (197 times), “mass vaccination” (194 times).
- 27 April 2021: A Miami private school warns that it will no longer hire teachers who get the COVID-19 vaccine [73]—supporting n-grams: “miami private school” (59 times), “employ anyone receiving covid” (18 times).
- 3 May 2021: An expert expresses worries that vaccine side effects are not sufficiently monitored [74]—supporting n-grams: “potential risks” (774 times), “side effect” (113 times).
- 1 December 2021: News regarding the introduction of vaccine passports [75]—supporting n-grams: “passports” (462 times), “vaccine passports” (378 times), “passports impact” (328 times).
- 8 December 2021: Pfizer CEO declares that a fourth vaccine dose could be needed sooner than initially expected [76]—supporting n-grams: “pfizer” (7087 times), “pfizer covid” (3424 times), “double vaccinated” (2904 times), “funds pfizer” (2851).
- 14 December 2021: NHS introduces vaccination passes for children between 12 and 15 years old [77]—supporting n-grams: “children” (1026), “vaccination children” (882), “vaccination children unforgivable” (881 times).
- 21 December 2021: Sarah Palin, former Alaska governor, opposes vaccination [78]—supporting n-grams: “sarah palin” (663 time), “dead body” (660 time); “sarah palin getting vaccinated” (580 times).
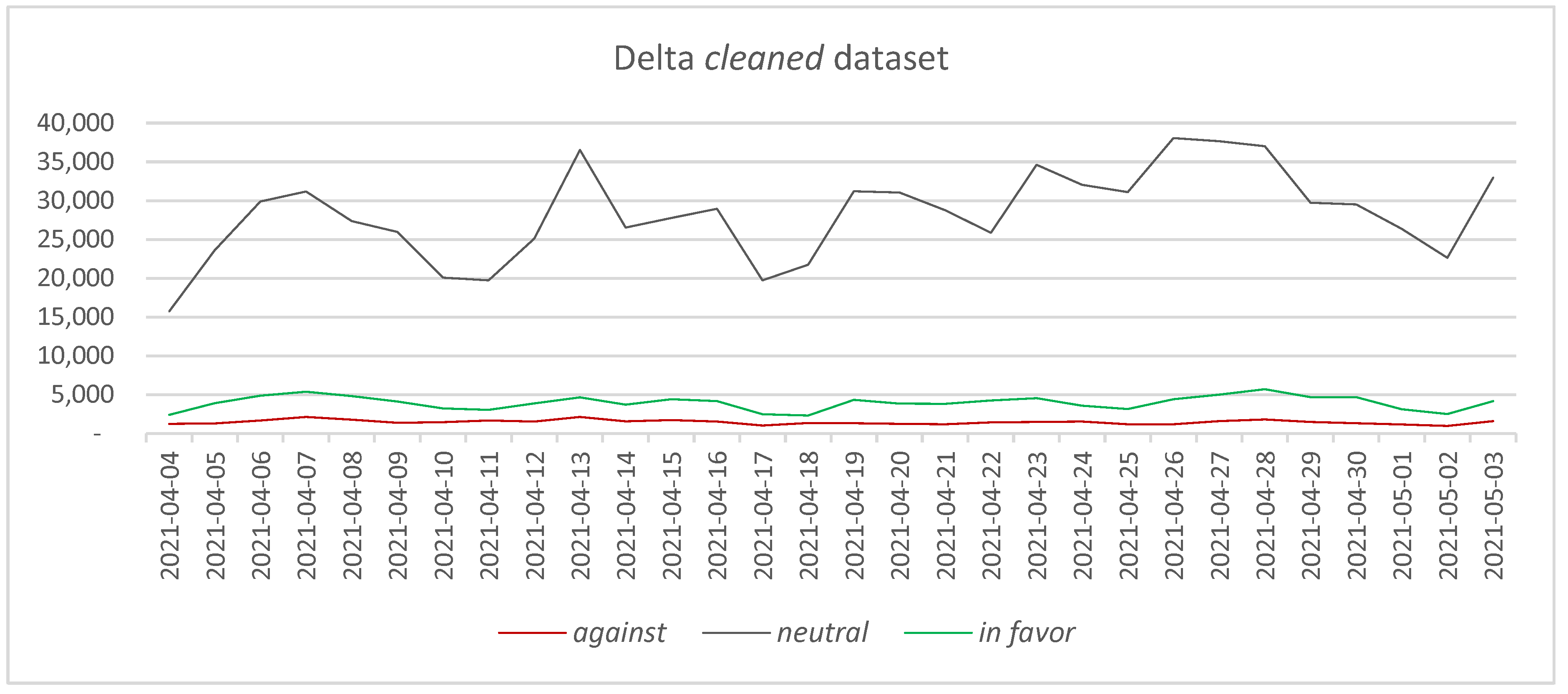
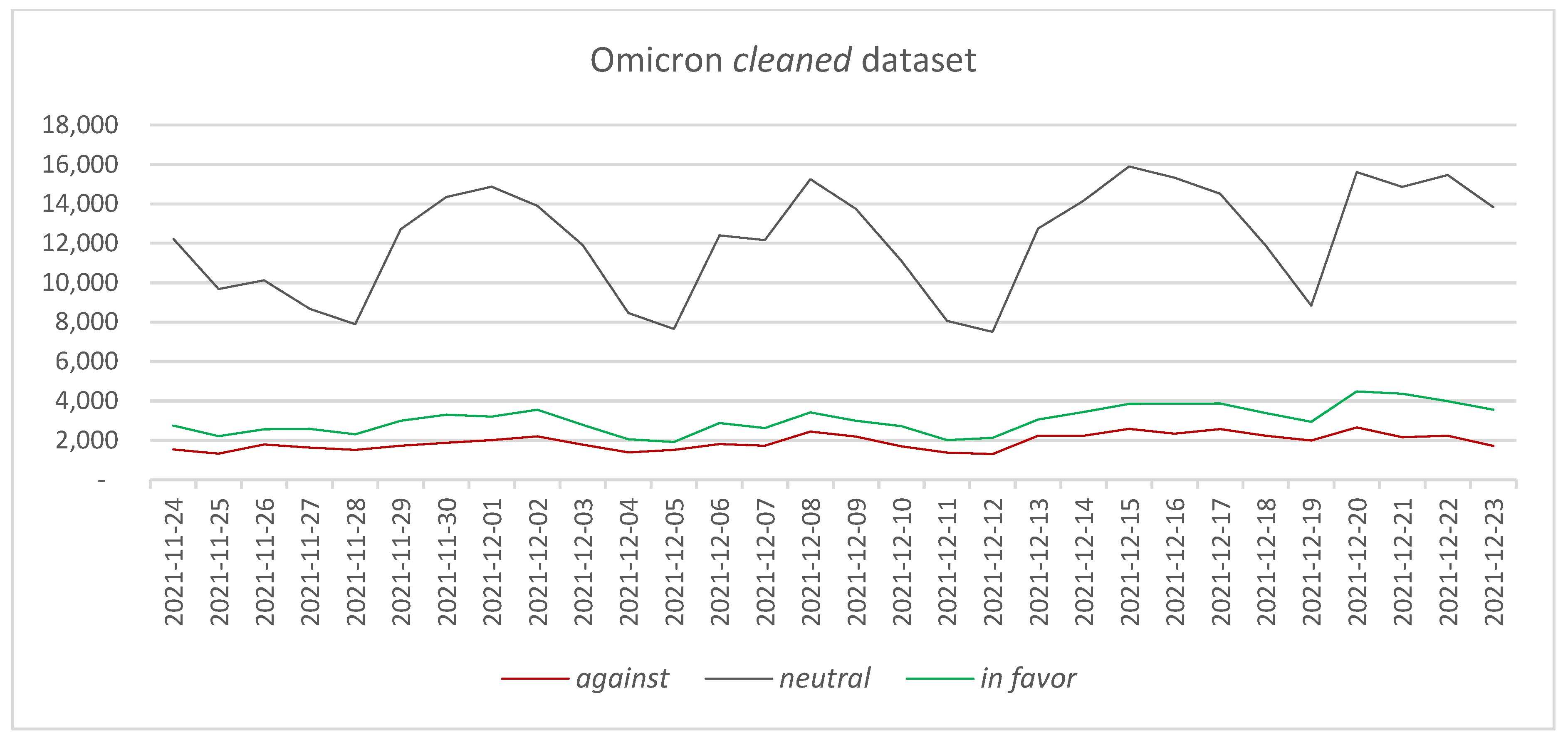
4.3.2. Cleaned Datasets
4.4. Comparative Analysis of Delta-Omicron Hesitancy Tweets
4.4.1. Entire Datasets
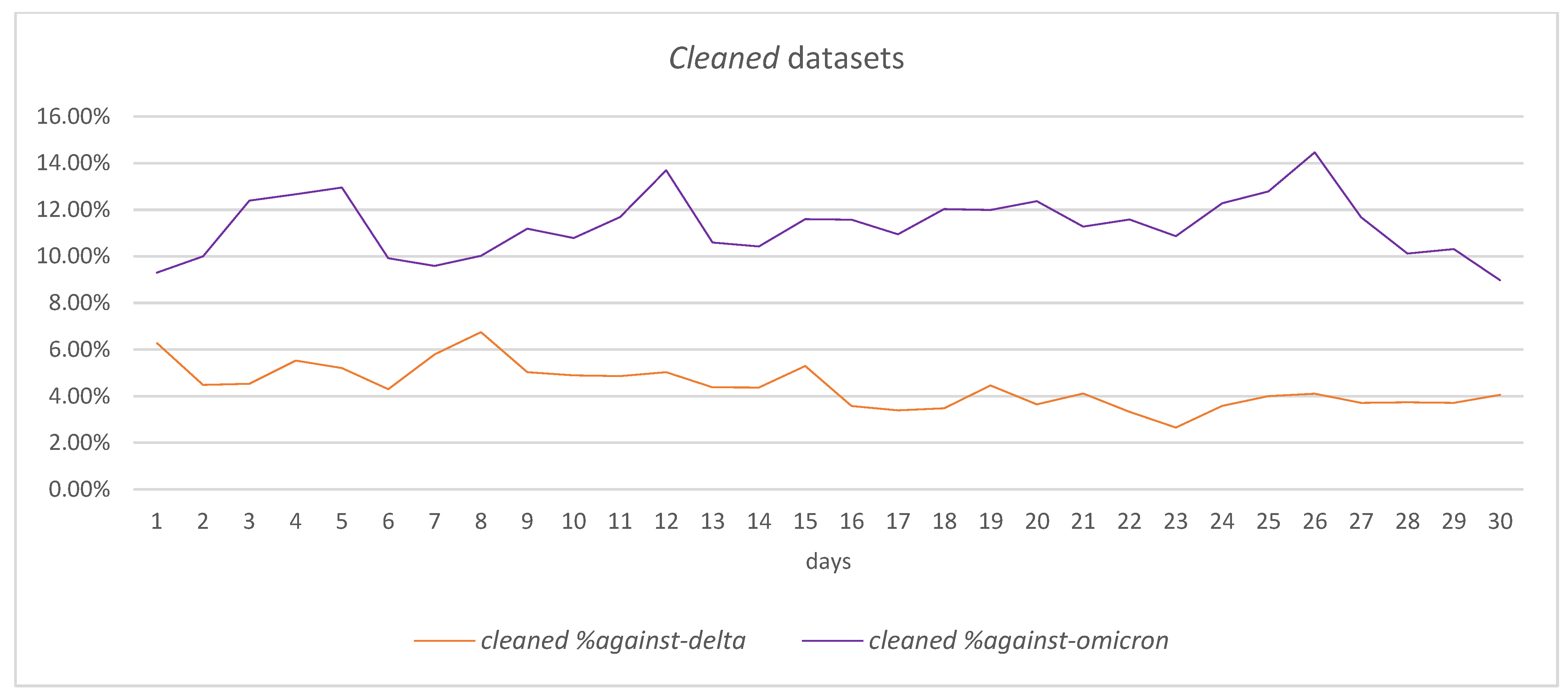
4.4.2. Cleaned Datasets
4.5. Hesitancy Analysis
4.5.1. Latent Dirichlet Allocation
- Topic 1—Side effects: die, spread, immunity, people, protect, fully, experimental, population;
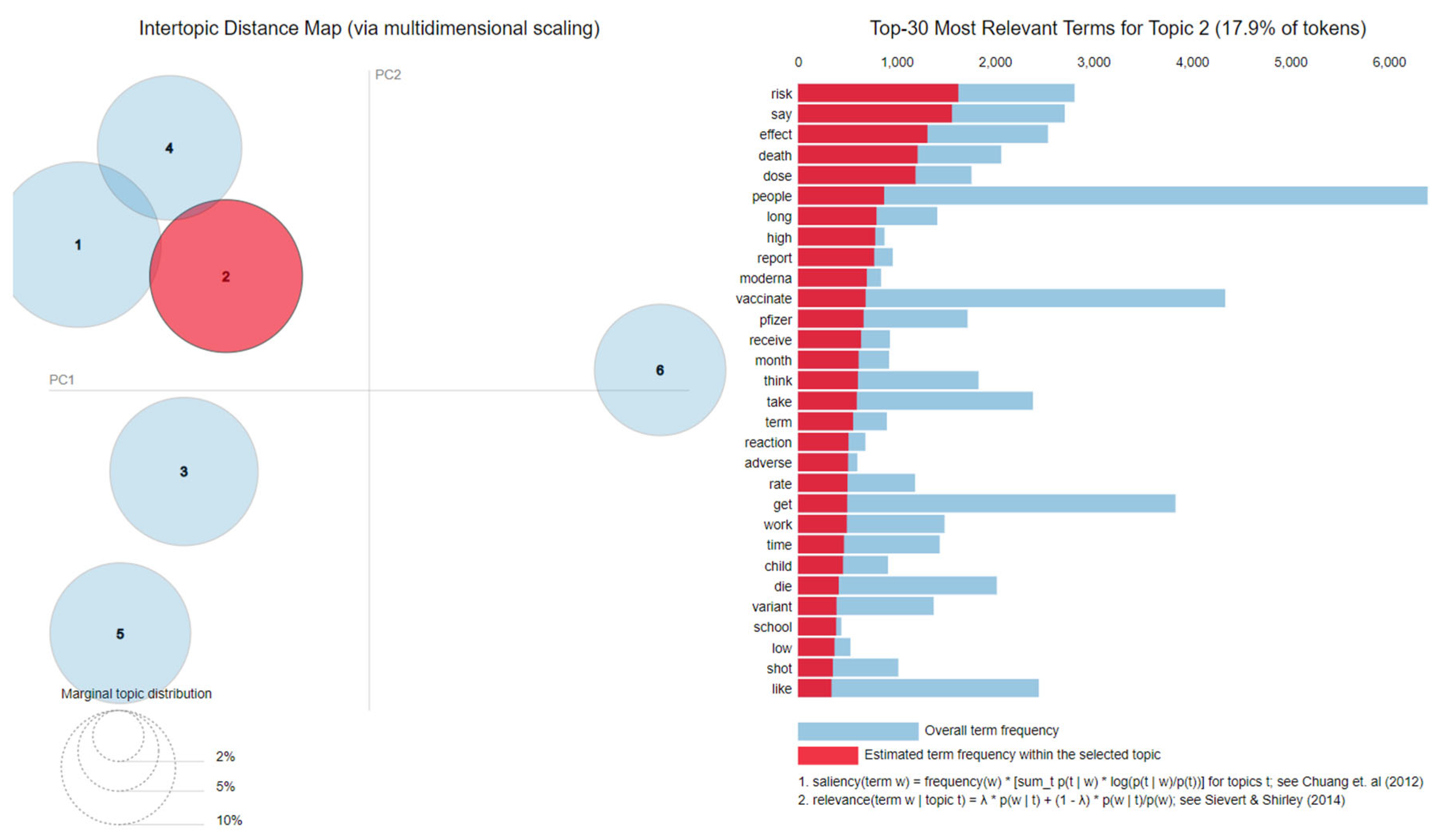
- Topic 2—Side effects: risk, effect, death, long, term, reaction, adverse, die;
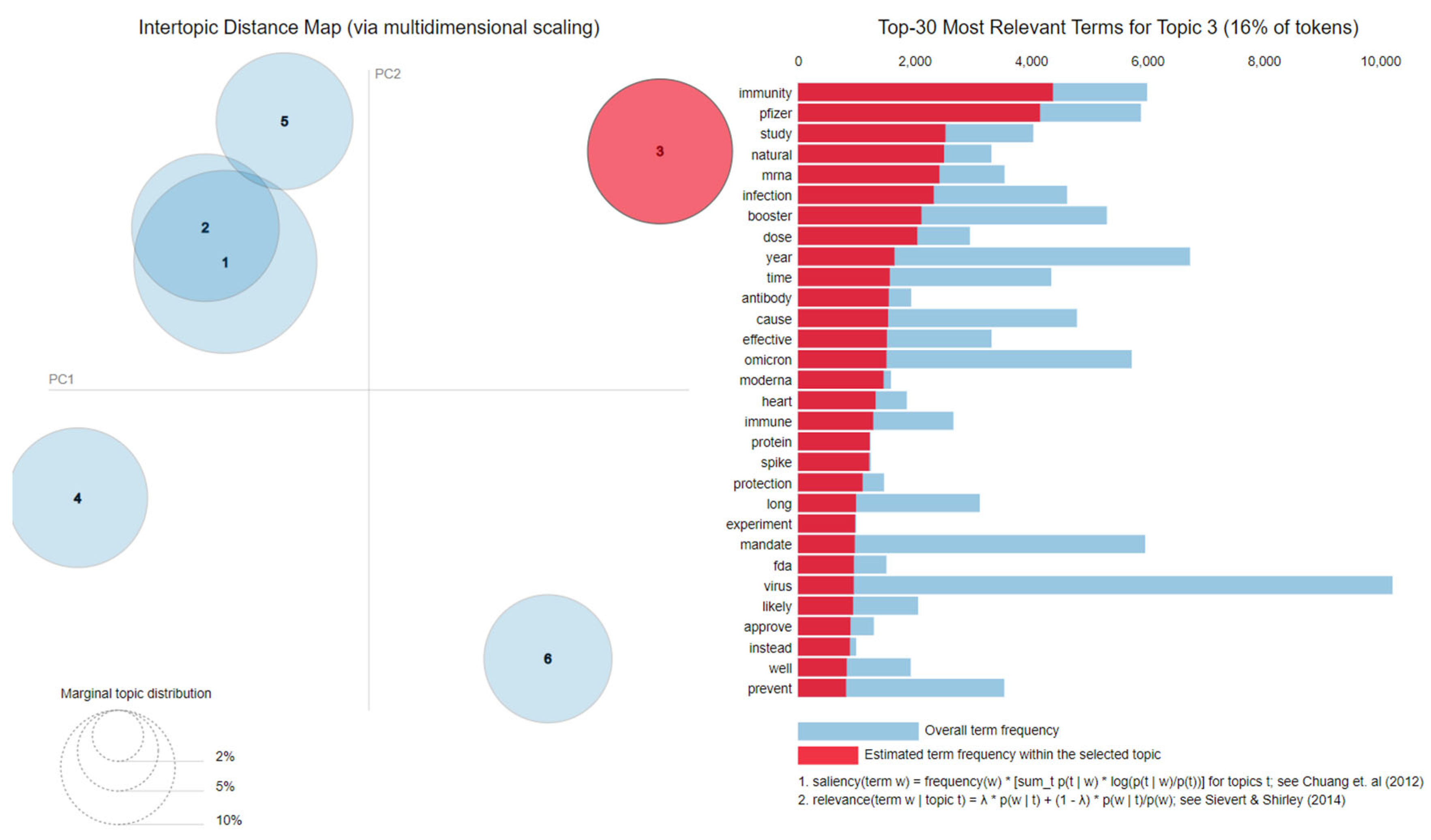
- Topic 3—Scam and Freedom: passport, right, government, monkey, company, money, mandate;
- Topic 4—Existence of alternatives: prevent, mask, antibody, wear, drug, risk;
- Topic 5—Mistrust: guinea, pig, death, million, die, rate;
- Topic 6—Scam, Hiding relevant information, and Side effects: blood, clot, control, ccp, bombshell, ccpvirus, takedowntheccp, mile, guo, warn, getterantidote, medical, study.
- Topic 1—Side effects: die, death, kill, body, protect, people;
- Topic 2—Side effects: myocarditis, blood, clot, die, death, people, cause, stop, rate, injury;
- Topic 3—Existence of alternatives: immunity, natural, infection, antibody, effective, immune, fda, prevent;
- Topic 4—Mistrust: test, trial, mandate, child, year, old, force, kid, refuse;
- Topic 5—Side effects: effect, long, term, transmission, autoimmune, infection, spread;
- Topic 6—Hiding relevant information and Side effects: science, evidence, report, adverse, Pfizer, medical, research, article, reaction, safe, review.
4.5.2. Hesitancy Reasons Dynamics
5. Limitations
6. Discussions and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bokaee Nezhad, Z.; Deihimi, M.A. Twitter Sentiment Analysis from Iran about COVID 19 Vaccine. Diabetes Metab. Syndr. Clin. Res. Rev. 2022, 16, 102367. [Google Scholar] [CrossRef] [PubMed]
- Yousefinaghani, S.; Dara, R.; Mubareka, S.; Papadopoulos, A.; Sharif, S. An Analysis of COVID-19 Vaccine Sentiments and Opinions on Twitter. Int. J. Infect. Dis. 2021, 108, 256–262. [Google Scholar] [CrossRef] [PubMed]
- D’Andrea, E.; Ducange, P.; Bechini, A.; Renda, A.; Marcelloni, F. Monitoring the Public Opinion about the Vaccination Topic from Tweets Analysis. Expert Syst. Appl. 2019, 116, 209–226. [Google Scholar] [CrossRef]
- Cinelli, M.; Quattrociocchi, W.; Galeazzi, A.; Valensise, C.M.; Brugnoli, E.; Schmidt, A.L.; Zola, P.; Zollo, F.; Scala, A. The COVID-19 Social Media Infodemic. Sci. Rep. 2020, 10, 16598. [Google Scholar] [CrossRef] [PubMed]
- Lopreite, M.; Panzarasa, P.; Puliga, M.; Riccaboni, M. Early Warnings of COVID-19 Outbreaks across Europe from Social Media. Sci. Rep. 2021, 11, 2147. [Google Scholar] [CrossRef] [PubMed]
- Turiel, J.; Fernandez-Reyes, D.; Aste, T. Wisdom of Crowds Detects COVID-19 Severity Ahead of Officially Available Data. Sci. Rep. 2021, 11, 13678. [Google Scholar] [CrossRef]
- Cheng, I.K.; Heyl, J.; Lad, N.; Facini, G.; Grout, Z. Evaluation of Twitter Data for an Emerging Crisis: An Application to the First Wave of COVID-19 in the UK. Sci. Rep. 2021, 11, 19009. [Google Scholar] [CrossRef]
- Cotfas, L.-A.; Delcea, C.; Gherai, R. COVID-19 Vaccine Hesitancy in the Month Following the Start of the Vaccination Process. Int. J. Environ. Res. Public Health 2021, 18, 10438. [Google Scholar] [CrossRef]
- Soares, P.; Rocha, J.V.; Moniz, M.; Gama, A.; Laires, P.A.; Pedro, A.R.; Dias, S.; Leite, A.; Nunes, C. Factors Associated with COVID-19 Vaccine Hesitancy. Vaccines 2021, 9, 300. [Google Scholar] [CrossRef]
- Biasio, L.R.; Bonaccorsi, G.; Lorini, C.; Mazzini, D.; Pecorelli, S. Italian Adults’ Likelihood of Getting COVID-19 Vaccine: A Second Online Survey. Vaccines 2021, 9, 268. [Google Scholar] [CrossRef]
- Detoc, M.; Bruel, S.; Frappe, P.; Tardy, B.; Botelho-Nevers, E.; Gagneux-Brunon, A. Intention to Participate in a COVID-19 Vaccine Clinical Trial and to Get Vaccinated against COVID-19 in France during the Pandemic. Vaccine 2020, 38, 7002–7006. [Google Scholar] [CrossRef] [PubMed]
- Salmon, D.A.; Dudley, M.Z.; Brewer, J.; Kan, L.; Gerber, J.E.; Budigan, H.; Proveaux, T.M.; Bernier, R.; Rimal, R.; Schwartz, B. COVID-19 Vaccination Attitudes, Values and Intentions among United States Adults Prior to Emergency Use Authorization. Vaccine 2021, 39, 2698–2711. [Google Scholar] [CrossRef] [PubMed]
- Latkin, C.A.; Dayton, L.; Yi, G.; Konstantopoulos, A.; Boodram, B. Trust in a COVID-19 Vaccine in the U.S.: A Social-Ecological Perspective. Social. Sci. Med. 2021, 270, 113684. [Google Scholar] [CrossRef] [PubMed]
- Malik, A.A.; McFadden, S.M.; Elharake, J.; Omer, S.B. Determinants of COVID-19 Vaccine Acceptance in the US. eClinicalMedicine 2020, 26, 100495. [Google Scholar] [CrossRef]
- Reiter, P.L.; Pennell, M.L.; Katz, M.L. Acceptability of a COVID-19 Vaccine among Adults in the United States: How Many People Would Get Vaccinated? Vaccine 2020, 38, 6500–6507. [Google Scholar] [CrossRef]
- Benis, A.; Seidmann, A.; Ashkenazi, S. Reasons for Taking the COVID-19 Vaccine by US Social Media Users. Vaccines 2021, 9, 315. [Google Scholar] [CrossRef]
- Lazarus, J.V.; Ratzan, S.C.; Palayew, A.; Gostin, L.O.; Larson, H.J.; Rabin, K.; Kimball, S.; El-Mohandes, A. A Global Survey of Potential Acceptance of a COVID-19 Vaccine. Nat. Med. 2021, 27, 225–228. [Google Scholar] [CrossRef]
- Borriello, A.; Master, D.; Pellegrini, A.; Rose, J.M. Preferences for a COVID-19 Vaccine in Australia. Vaccine 2021, 39, 473–479. [Google Scholar] [CrossRef]
- Dodd, R.H.; Cvejic, E.; Bonner, C.; Pickles, K.; McCaffery, K.J.; Ayre, J.; Batcup, C.; Copp, T.; Cornell, S.; Dakin, T.; et al. Willingness to Vaccinate against COVID-19 in Australia. Lancet Infect. Dis. 2021, 21, 318–319. [Google Scholar] [CrossRef]
- Wang, C.; Han, B.; Zhao, T.; Liu, H.; Liu, B.; Chen, L.; Xie, M.; Liu, J.; Zheng, H.; Zhang, S.; et al. Vaccination Willingness, Vaccine Hesitancy, and Estimated Coverage at the First Round of COVID-19 Vaccination in China: A National Cross-Sectional Study. Vaccine 2021, 39, 2833–2842. [Google Scholar] [CrossRef]
- Roshchina, Y.; Roshchin, S.; Rozhkova, K. Determinants of COVID-19 Vaccine Hesitancy and Resistance in Russia; Social Science Research Network: Rochester, NY, USA, 2021. [Google Scholar]
- Iliyasu, Z.; Umar, A.A.; Abdullahi, H.M.; Kwaku, A.A.; Amole, T.G.; Tsiga-Ahmed, F.I.; Garba, R.M.; Salihu, H.M.; Aliyu, M.H. “They Have Produced a Vaccine, but We Doubt If COVID-19 Exists”: Correlates of COVID-19 Vaccine Acceptability among Adults in Kano, Nigeria. Hum. Vaccines Immunother. 2021, 17, 4057–4064. [Google Scholar] [CrossRef] [PubMed]
- Robertson, E.; Reeve, K.S.; Niedzwiedz, C.L.; Moore, J.; Blake, M.; Green, M.; Katikireddi, S.V.; Benzeval, M.J. Predictors of COVID-19 Vaccine Hesitancy in the UK Household Longitudinal Study. Brain Behav. Immun. 2021, 94, 41–50. [Google Scholar] [CrossRef] [PubMed]
- Alley, S.J.; Stanton, R.; Browne, M.; To, Q.G.; Khalesi, S.; Williams, S.L.; Thwaite, T.L.; Fenning, A.S.; Vandelanotte, C. As the Pandemic Progresses, How Does Willingness to Vaccinate against COVID-19 Evolve? Int. J. Environ. Res. Public Health 2021, 18, 797. [Google Scholar] [CrossRef] [PubMed]
- Bell, S.; Clarke, R.; Mounier-Jack, S.; Walker, J.L.; Paterson, P. Parents’ and Guardians’ Views on the Acceptability of a Future COVID-19 Vaccine: A Multi-Methods Study in England. Vaccine 2020, 38, 7789–7798. [Google Scholar] [CrossRef]
- Shacham, M.; Greenblatt-Kimron, L.; Hamama-Raz, Y.; Martin, L.R.; Peleg, O.; Ben-Ezra, M.; Mijiritsky, E. Increased COVID-19 Vaccination Hesitancy and Health Awareness amid COVID-19 Vaccinations Programs in Israel. Int. J. Environ. Res. Public Health 2021, 18, 3804. [Google Scholar] [CrossRef]
- Alfageeh, E.I.; Alshareef, N.; Angawi, K.; Alhazmi, F.; Chirwa, G.C. Acceptability of a COVID-19 Vaccine among the Saudi Population. Vaccines 2021, 9, 226. [Google Scholar] [CrossRef]
- MacDonald, N.E. Vaccine Hesitancy: Definition, Scope and Determinants. Vaccine 2015, 33, 4161–4164. [Google Scholar] [CrossRef]
- Peretti-Watel, P.; Larson, H.J.; Ward, J.K.; Schulz, W.S.; Verger, P. Vaccine Hesitancy: Clarifying a Theoretical Framework for an Ambiguous Notion. PLoS Curr. 2015, 7. [Google Scholar] [CrossRef]
- Dube, K.; Nhamo, G.; Chikodzi, D. COVID-19 Pandemic and Prospects for Recovery of the Global Aviation Industry. J. Air Transp. Manag. 2021, 92, 102022. [Google Scholar] [CrossRef]
- Pullan, S.; Dey, M. Vaccine Hesitancy and Anti-Vaccination in the Time of COVID-19: A Google Trends Analysis. Vaccine 2021, 39, 1877–1881. [Google Scholar] [CrossRef]
- Gowda, C.; Schaffer, S.E.; Kopec, K.; Markel, A.; Dempsey, A.F. Does the Relative Importance of MMR Vaccine Concerns Differ by Degree of Parental Vaccine Hesitancy?: An Exploratory Study. Hum. Vaccines Immunother. 2013, 9, 430–436. [Google Scholar] [CrossRef]
- Healy, C.M.; Pickering, L.K. How to Communicate With Vaccine-Hesitant Parents. Pediatrics 2011, 127, S127–S133. [Google Scholar] [CrossRef] [PubMed]
- Jacobson, M.J.; Kim, B.; Pathak, S.; Zhang, B. To Guide or Not to Guide: Issues in the Sequencing of Pedagogical Structure in Computational Model-Based Learning. Interact. Learn. Environ. 2015, 23, 715–730. [Google Scholar] [CrossRef]
- WHO. Ten Health Issues WHO Will Tackle This Year. Available online: https://www.who.int/news-room/spotlight/ten-threats-to-global-health-in-2019 (accessed on 26 March 2021).
- Cotfas, L.-A.; Delcea, C.; Roxin, I.; Ioanas, C.; Gherai, D.S.; Tajariol, F. The Longest Month: Analyzing COVID-19 Vaccination Opinions Dynamics From Tweets in the Month Following the First Vaccine Announcement. IEEE Access 2021, 9, 33203–33223. [Google Scholar] [CrossRef] [PubMed]
- Mohamed Ridhwan, K.; Hargreaves, C.A. Leveraging Twitter Data to Understand Public Sentiment for the COVID-19 Outbreak in Singapore. Int. J. Inf. Manag. Data Insights 2021, 1, 100021. [Google Scholar] [CrossRef]
- Fazel, S.; Zhang, L.; Javid, B.; Brikell, I.; Chang, Z. Harnessing Twitter Data to Survey Public Attention and Attitudes towards COVID-19 Vaccines in the UK. Sci. Rep. 2021, 11, 23402. [Google Scholar] [CrossRef]
- Cristescu, M.P.; Nerisanu, R.A.; Mara, D.A.; Oprea, S.-V. Using Market News Sentiment Analysis for Stock Market Prediction. Mathematics 2022, 10, 4255. [Google Scholar] [CrossRef]
- Kovacs, E.-R.; Cotfas, L.-A.; Delcea, C. From Unhealthy Online Conversation to Political Violence: The Case of the January 6th Events at the Capitol. In Advances in Computational Collective Intelligence; Bădică, C., Treur, J., Benslimane, D., Hnatkowska, B., Krótkiewicz, M., Eds.; Communications in Computer and Information Science; Springer International Publishing: Cham, Switzerland, 2022; Volume 1653, pp. 3–15. ISBN 978-3-031-16209-1. [Google Scholar]
- Tatar, M.; Faraji, M.R.; Montazeri Shoorekchali, J.; Pagán, J.A.; Wilson, F.A. The Role of Good Governance in the Race for Global Vaccination during the COVID-19 Pandemic. Sci. Rep. 2021, 11, 22440. [Google Scholar] [CrossRef]
- Delcea, C.; Cotfas, L.-A.; Crăciun, L.; Molănescu, A.G. New Wave of COVID-19 Vaccine Opinions in the Month the 3rd Booster Dose Arrived. Vaccines 2022, 10, 881. [Google Scholar] [CrossRef]
- Daghriri, T.; Proctor, M.; Matthews, S.; Bashiri, A.H. Modeling Behavior and Vaccine Hesitancy Using Twitter-Derived US Population Sentiment during the COVID-19 Pandemic to Predict Daily Vaccination Inoculations. Vaccines 2023, 11, 709. [Google Scholar] [CrossRef]
- Delcea, C.; Cotfas, L.-A. Public Opinion Assessment Through Grey Relational Analysis Approach. In Advancements of Grey Systems Theory in Economics and Social Sciences; Series on Grey System; Springer Nature: Singapore, 2023; pp. 179–199. ISBN 978-981-19993-1-4. [Google Scholar]
- Kovacs, E.-R.; Cotfas, L.-A.; Delcea, C. COVID-19 Vaccination Opinions in Education-Related Tweets. In Eurasian Business and Economics Perspectives; Bilgin, M.H., Danis, H., Demir, E., Eds.; Eurasian Studies in Business and Economics; Springer International Publishing: Cham, Switzerland, 2022; Volume 24, pp. 21–41. ISBN 978-3-031-15530-7. [Google Scholar]
- Cambria, E. ALLEGET Keynote Remarks: Emerging Topics in Sentiment Analysis. In Workshop Proceedings of the 19th International Conference on Intelligent Environments (IE2023); IOS Press: Amsterdam, The Netherlands, 2023; pp. 51–52. [Google Scholar]
- Lanyi, K.; Green, R.; Craig, D.; Marshall, C. COVID-19 Vaccine Hesitancy: Analysing Twitter to Identify Barriers to Vaccination in a Low Uptake Region of the UK. Front. Digit. Health 2022, 3, 804855. [Google Scholar] [CrossRef] [PubMed]
- Burel, G.; Farrell, T.; Alani, H. Demographics and Topics Impact on the Co-Spread of COVID-19 Misinformation and Fact-Checks on Twitter. Inf. Process. Manag. 2021, 58, 102732. [Google Scholar] [CrossRef]
- Feng, Y.; Zhou, W. Work from Home during the COVID-19 Pandemic: An Observational Study Based on a Large Geo-Tagged COVID-19 Twitter Dataset (UsaGeoCov19). Inf. Process. Manag. 2022, 59, 102820. [Google Scholar] [CrossRef] [PubMed]
- Bonifazi, G.; Breve, B.; Cirillo, S.; Corradini, E.; Virgili, L. Investigating the COVID-19 Vaccine Discussions on Twitter through a Multilayer Network-Based Approach. Inf. Process. Manag. 2022, 59, 103095. [Google Scholar] [CrossRef] [PubMed]
- Cambria, E.; Liu, Q.; Decherchi, S.; Xing, F.; Kwok, K. SenticNet 7: A Commonsense-Based Neurosymbolic AI Framework for Explainable Sentiment Analysis. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, Marseille, France, 20–25 June 2022; European Language Resources Association: Marseille, France; pp. 3829–3839. [Google Scholar]
- Cui, J.; Wang, Z.; Ho, S.-B.; Cambria, E. Survey on Sentiment Analysis: Evolution of Research Methods and Topics. Artif. Intell. Rev. 2023, 56, 8469–8510. [Google Scholar] [CrossRef] [PubMed]
- Torregrosa, J.; D’Antonio-Maceiras, S.; Villar-Rodríguez, G.; Hussain, A.; Cambria, E.; Camacho, D. A Mixed Approach for Aggressive Political Discourse Analysis on Twitter. Cogn. Comput. 2023, 15, 440–465. [Google Scholar] [CrossRef]
- Martínez, R.Y.; Blanco, G.; Lourenço, A. Spanish Corpora of Tweets about COVID-19 Vaccination for Automatic Stance Detection. Inf. Process. Manag. 2023, 60, 103294. [Google Scholar] [CrossRef]
- Aloufi, S.; Saddik, A.E. Sentiment Identification in Football-Specific Tweets. IEEE Access 2018, 6, 78609–78621. [Google Scholar] [CrossRef]
- Baziotis, C.; Pelekis, N.; Doulkeridis, C. DataStories at SemEval-2017 Task 4: Deep LSTM with Attention for Message-Level and Topic-Based Sentiment Analysis. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), Vancouver, BC, Canada, 3–4 August 2017; Association for Computational Linguistics: Vancouver, BC, Canada, 2017; pp. 747–754. [Google Scholar]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit, 1st ed.; O’Reilly Media: Beijing, China, 2009; ISBN 978-0-596-51649-9. [Google Scholar]
- Kovacs, E.-R.; Cotfas, L.-A.; Delcea, C.; Florescu, M.-S. 1000 Days of COVID-19: A Gender-Based Long-Term Investigation into Attitudes With Regards to Vaccination. IEEE Access 2023, 11, 25351–25371. [Google Scholar] [CrossRef]
- Zhang, M.-L.; Pena, J.M.; Robles, V. Feature Selection for Multi-Label Naive Bayes Classification. Inf. Sci. 2009, 179, 3218–3229. [Google Scholar] [CrossRef]
- Misra, S.; Li, H. Noninvasive Fracture Characterization Based on the Classification of Sonic Wave Travel Times. In Machine Learning for Subsurface Characterization; Misra, S., Li, H., He, J., Eds.; Gulf Professional Publishing: Houston, TX, USA, 2020; pp. 243–287. ISBN 978-0-12-817736-5. [Google Scholar]
- Mohammadi, V.; Minaei, S. Artificial Intelligence in the Production Process. In Engineering Tools in the Beverage Industry; Grumezescu, A.M., Holban, A.M., Eds.; The Science of Beverages; Woodhead Publishing: Sawston, UK, 2019; pp. 27–63. ISBN 978-0-12-815258-4. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; Volume 1 (Long and Short Papers), pp. 4171–4186. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations. arXiv 2020, arXiv:1909.11942. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Rehurek, R.; Sojka, P. Software Framework for Topic Modelling with Large Corpora. In Proceedings of the Lrec 2010 Workshop on New Challenges for Nlp Frameworks, Valletta, Malta, 22 May 2010; pp. 45–50. [Google Scholar]
- Chuang, J.; Manning, C.D.; Heer, J. Termite: Visualization Techniques for Assessing Textual Topic Models. In Proceedings of the International Working Conference on Advanced Visual Interfaces, Capri Island, Italy, 21–25 May 2012; Association for Computing Machinery: New York, NY, USA; pp. 74–77. [Google Scholar]
- Tracking SARS-CoV-2 Variants. Available online: https://www.who.int/activities/tracking-SARS-CoV-2-variants (accessed on 17 November 2022).
- Cotfas, L.-A.; Delcea, C.; Gherai, R.; Roxin, I. Unmasking People’s Opinions behind Mask-Wearing during COVID-19 Pandemic—A Twitter Stance Analysis. Symmetry 2021, 13, 1995. [Google Scholar] [CrossRef]
- UK Government. MHRA Issues New Advice, Concluding a Possible Link between COVID-19 Vaccine AstraZeneca and Extremely Rare, Unlikely to Occur Blood Clots. Available online: https://www.gov.uk/government/news/mhra-issues-new-advice-concluding-a-possible-link-between-covid-19-vaccine-astrazeneca-and-extremely-rare-unlikely-to-occur-blood-clots (accessed on 19 November 2022).
- FDA. Joint CDC and FDA Statement on Johnson & Johnson COVID-19 Vaccine. Available online: https://www.fda.gov/news-events/press-announcements/joint-cdc-and-fda-statement-johnson-johnson-covid-19-vaccine (accessed on 19 November 2022).
- Schumaker, E. All US Adults Now Eligible for COVID-19 Vaccines—ABC News. Available online: https://abcnews.go.com/Health/adults-now-eligible-covid-19-vaccines/story?id=77163212 (accessed on 19 November 2022).
- Razek, R.; Scottie, A. Miami Private School Asks Teachers Not to Get COVID-19 Vaccine or They Won’t Be Allowed to Return next Year—CNN. Available online: https://edition.cnn.com/2021/04/27/us/miami-school-warns-against-covid-vaccine-trnd/index.html (accessed on 19 November 2022).
- JoNel, A. Covid Vaccine Safety System Has Gaps That May Miss Unexpected Side Effects, Experts Say. Available online: https://www.nbcnews.com/health/health-news/covid-vaccine-safety-system-has-gaps-may-miss-unexpected-side-n1265986 (accessed on 19 November 2022).
- NBC Boston Massachusetts Vaccine Passport Close to Reality, But Gov. Charlie Baker Opposes Mandate—NBC Boston. Available online: https://www.nbcboston.com/news/local/with-vaccine-passports-near-baker-voices-opposition-to-mandate/2578500/ (accessed on 20 November 2022).
- Kimball, S. Pfizer CEO Says Fourth Covid Vaccine Doses May Be Needed Sooner than Expected Due to Omicron. Available online: https://www.cnbc.com/2021/12/08/omicron-pfizer-ceo-says-we-may-need-fourth-covid-vaccine-doses-sooner-than-expected.html (accessed on 20 November 2022).
- UK Government. NHS COVID Pass for 12 to 15 Year Olds for International Travel. Available online: https://www.gov.uk/government/news/nhs-covid-pass-for-12-15-year-olds-for-international-travel (accessed on 20 November 2022).
- Colson, T. Sarah Palin Gave a Speech Opposing Vaccination, and Said She Would Get a Shot “over My Dead Body”. Available online: https://www.businessinsider.com/sarah-palin-opposes-vaccination-shot-over-dead-body-2021-12 (accessed on 20 November 2022).
- Worldometers Coronavirus Graphs: Worldwide Cases and Deaths—Worldometer. Available online: https://www.worldometers.info/coronavirus/worldwide-graphs/ (accessed on 17 November 2022).
- Chuang, J.; Manning, C.D.; Heer, J. “Without the Clutter of Unimportant Words”: Descriptive Keyphrases for Text Visualization. ACM Trans. Comput.-Hum. Interact. 2012, 19, 1–29. [Google Scholar] [CrossRef]
- Sievert, C.; Shirley, K. LDAvis: A Method for Visualizing and Interpreting Topics. In Proceedings of the Workshop on Interactive Language Learning, Visualization, and Interfaces, Baltimore, MD, USA, 27 June 2014; pp. 63–70. [Google Scholar]
- Abdalla, S.M.; Mohamed, E.Y.; Elsabagh, H.M.; Ahmad, M.S.; Shaik, R.A.; Mehta, V.; Mathur, A.; Ghatge, S.B. COVID-19 Vaccine Hesitancy among the General Population: A Cross-Sectional Study. Vaccines 2023, 11, 1125. [Google Scholar] [CrossRef]
- Leung, J.; Price, D.; McClure-Thomas, C.; Bonsaksen, T.; Ruffolo, M.; Kabelenga, I.; Lamph, G.; Geirdal, A.Ø. Motivation and Hesitancies in Obtaining the COVID-19 Vaccine—A Cross-Sectional Study in Norway, USA, UK, and Australia. Vaccines 2023, 11, 1086. [Google Scholar] [CrossRef]
- Muluneh, M.D.; Negash, K.; Tsegaye, S.; Abera, Y.; Tadesse, D.; Abebe, S.; Vaughan, C.; Stulz, V. COVID-19 Knowledge, Attitudes, and Vaccine Hesitancy in Ethiopia: A Community-Based Cross-Sectional Study. Vaccines 2023, 11, 774. [Google Scholar] [CrossRef]
- Sun, Y.; Li, X.; Guo, D. COVID-19 Vaccine Hesitancy in China: An Analysis of Reasons through Mixed Methods. Vaccines 2023, 11, 712. [Google Scholar] [CrossRef]
- Gołębiowska, J.; Zimny-Zając, A.; Dróżdż, M.; Makuch, S.; Dudek, K.; Mazur, G.; Agrawal, S. Evaluation of the Approach towards Vaccination against COVID-19 among the Polish Population—In Relation to Sociodemographic Factors and Physical and Mental Health. Vaccines 2023, 11, 700. [Google Scholar] [CrossRef]
- WHO. WHO Chief Declares End to COVID-19 as a Global Health Emergency|UN News. Available online: https://news.un.org/en/story/2023/05/1136367 (accessed on 28 July 2023).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier | Class | Precision | Recall | F-Score | Accuracy |
|---|---|---|---|---|---|
| SVM | against | 0.81 | 0.64 | 0.71 | 71.97% |
| neutral | 0.71 | 0.83 | 0.77 | ||
| in favor | 0.66 | 0.69 | 0.68 | ||
| MNB | against | 0.77 | 0.70 | 0.73 | 72.56% |
| neutral | 0.71 | 0.88 | 0.78 | ||
| in favor | 0.71 | 0.60 | 0.65 | ||
| RF | against | 0.73 | 0.70 | 0.71 | 71.68% |
| neutral | 0.69 | 0.91 | 0.78 | ||
| in favor | 0.75 | 0.54 | 0.63 | ||
| BERT-base-cased | against | 0.83 | 0.78 | 0.80 | 82.30% |
| neutral | 0.80 | 0.94 | 0.86 | ||
| in favor | 0.85 | 0.75 | 0.80 | ||
| BERT-base-uncased | against | 0.90 | 0.84 | 0.87 | 85.84% |
| neutral | 0.81 | 0.96 | 0.88 | ||
| in favor | 0.88 | 0.78 | 0.83 | ||
| ALBERT-base-v2 | against | 0.82 | 0.88 | 0.85 | 86.13% |
| neutral | 0.86 | 0.94 | 0.90 | ||
| in favor | 0.91 | 0.77 | 0.83 | ||
| RoBERTa-base | against | 0.89 | 0.99 | 0.94 | 95.57% |
| neutral | 1.00 | 0.97 | 0.99 | ||
| in favor | 0.99 | 0.90 | 0.94 |
| COVID-19 Vaccine Hesitancy Reasons | Event | |||
|---|---|---|---|---|
| E1: Start of the Vaccination Campaign [8] | E2: Delta (This Study) | E3: Third Vaccine Booster [42] | E4: Omicron (This Study) | |
| Period | ||||
| 8 December 2020–7 January 2021 | 4 April 2021–3 May 2021 | 12 July 2021–11 August 2021 | 24 November 2021–23 December 2021 | |
| Percentage of Against Tweets (Entire/Cleaned Datasets) | ||||
| 4.40%/6.78% | 4.47%/4.41% | 4.89%/7.44% | 8.71%/11.33% | |
| Side effects | ✔ | ✔ | ✔ | ✔ |
| Existence of alternatives | ✔ | ✔ | ✔ | ✔ |
| Hiding relevant information | ✔ | ✔ | ✔ | ✔ |
| Mistrust | ✔ | ✔ | ✔ | ✔ |
| Scam | ✔ | ✔ | ✔ | |
| Inefficiency | ✔ | |||
| Freedom | ✔ | ✔ | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cotfas, L.-A.; Crăciun, L.; Delcea, C.; Florescu, M.S.; Kovacs, E.-R.; Molănescu, A.G.; Orzan, M. Unveiling Vaccine Hesitancy on Twitter: Analyzing Trends and Reasons during the Emergence of COVID-19 Delta and Omicron Variants. Vaccines 2023, 11, 1381. https://doi.org/10.3390/vaccines11081381
Cotfas L-A, Crăciun L, Delcea C, Florescu MS, Kovacs E-R, Molănescu AG, Orzan M. Unveiling Vaccine Hesitancy on Twitter: Analyzing Trends and Reasons during the Emergence of COVID-19 Delta and Omicron Variants. Vaccines. 2023; 11(8):1381. https://doi.org/10.3390/vaccines11081381
Chicago/Turabian StyleCotfas, Liviu-Adrian, Liliana Crăciun, Camelia Delcea, Margareta Stela Florescu, Erik-Robert Kovacs, Anca Gabriela Molănescu, and Mihai Orzan. 2023. "Unveiling Vaccine Hesitancy on Twitter: Analyzing Trends and Reasons during the Emergence of COVID-19 Delta and Omicron Variants" Vaccines 11, no. 8: 1381. https://doi.org/10.3390/vaccines11081381
APA StyleCotfas, L.-A., Crăciun, L., Delcea, C., Florescu, M. S., Kovacs, E.-R., Molănescu, A. G., & Orzan, M. (2023). Unveiling Vaccine Hesitancy on Twitter: Analyzing Trends and Reasons during the Emergence of COVID-19 Delta and Omicron Variants. Vaccines, 11(8), 1381. https://doi.org/10.3390/vaccines11081381