Using a Machine Learning Approach to Monitor COVID-19 Vaccine Adverse Events (VAE) from Twitter Data


Abstract
:1. Introduction
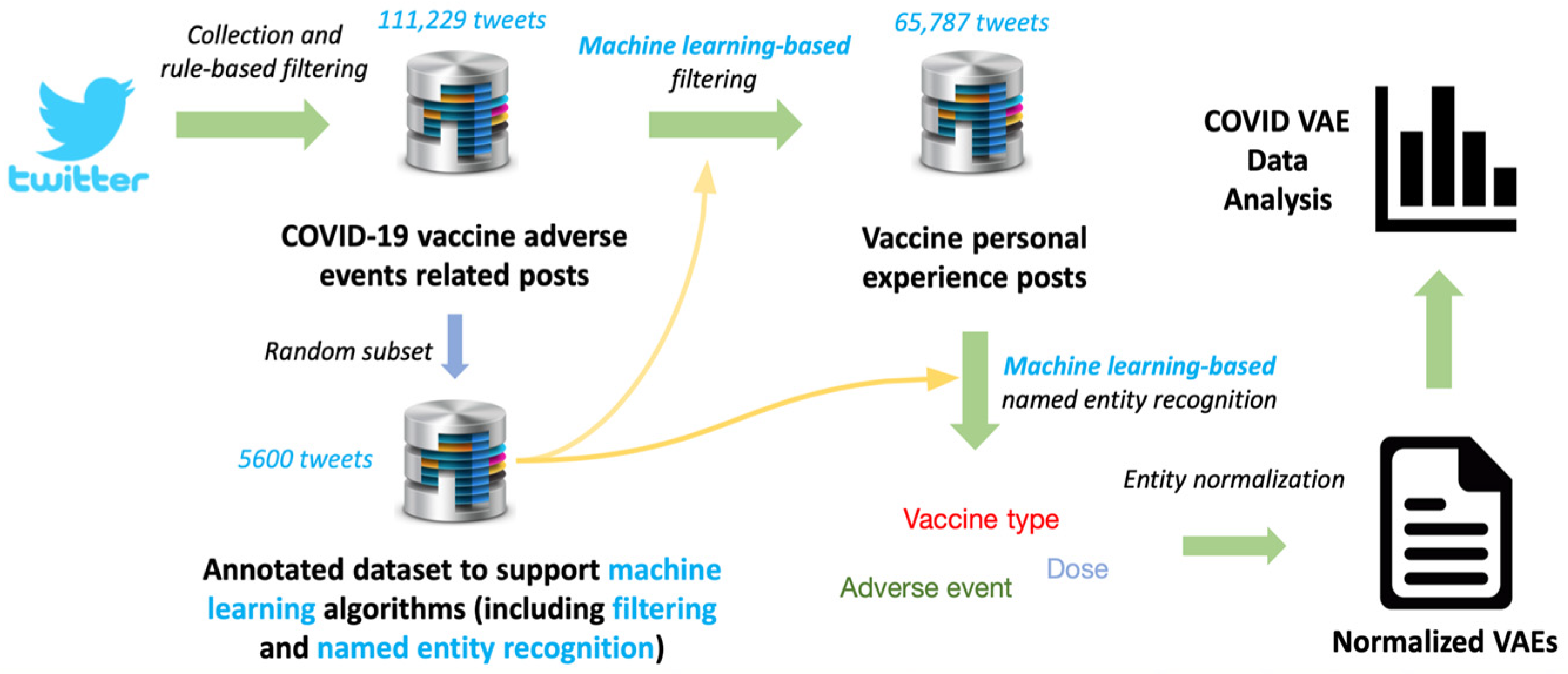
2. Materials and Methods
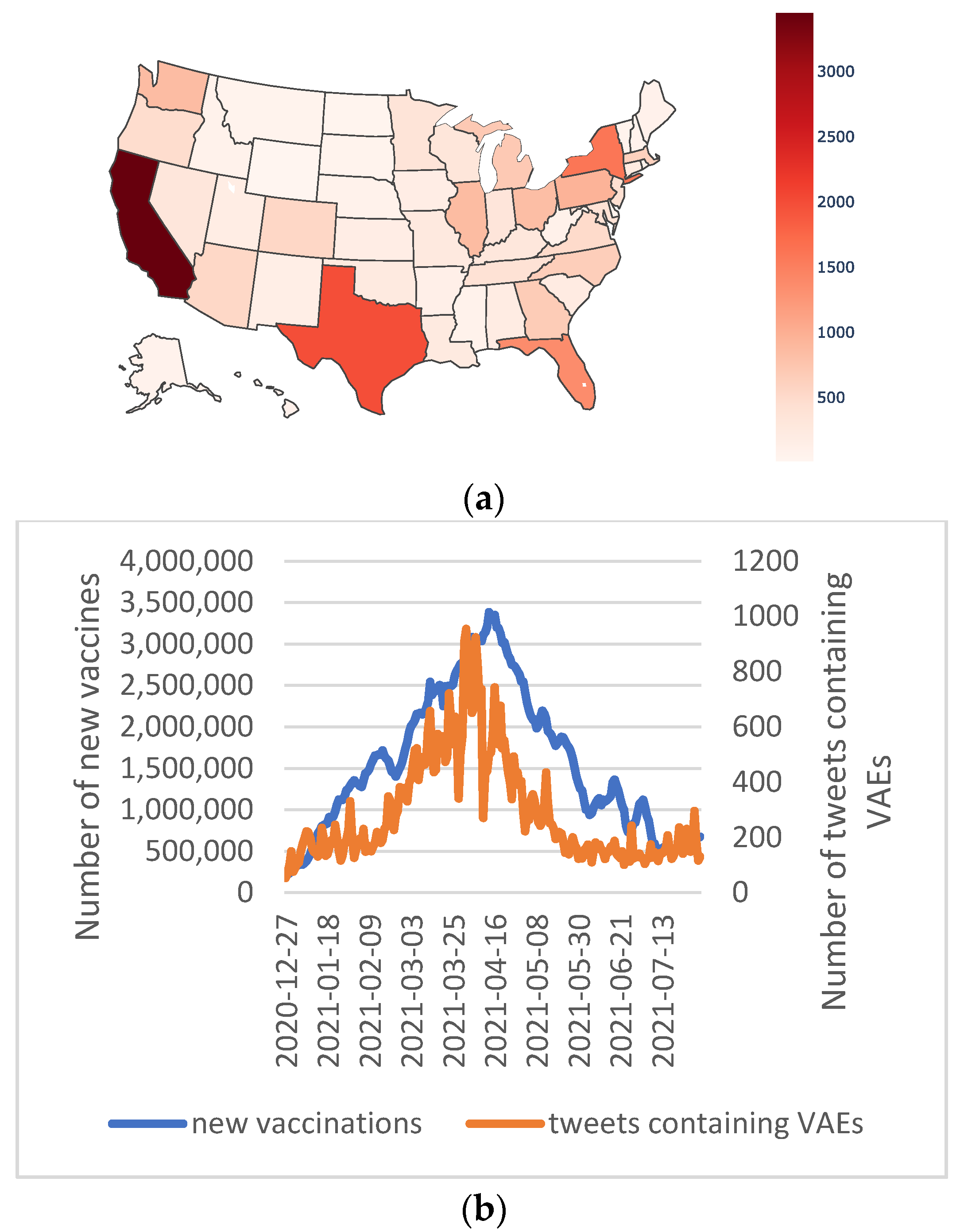
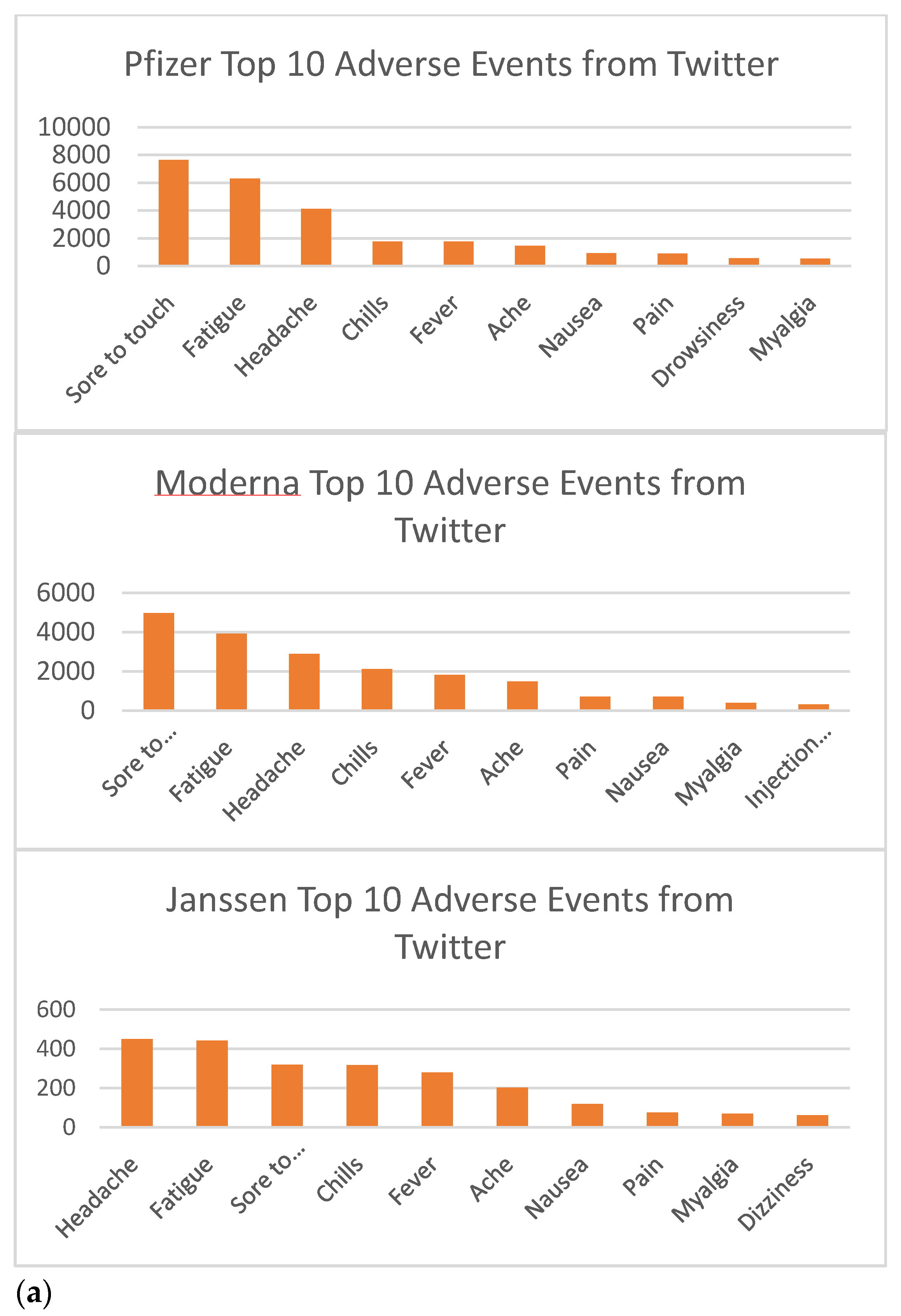
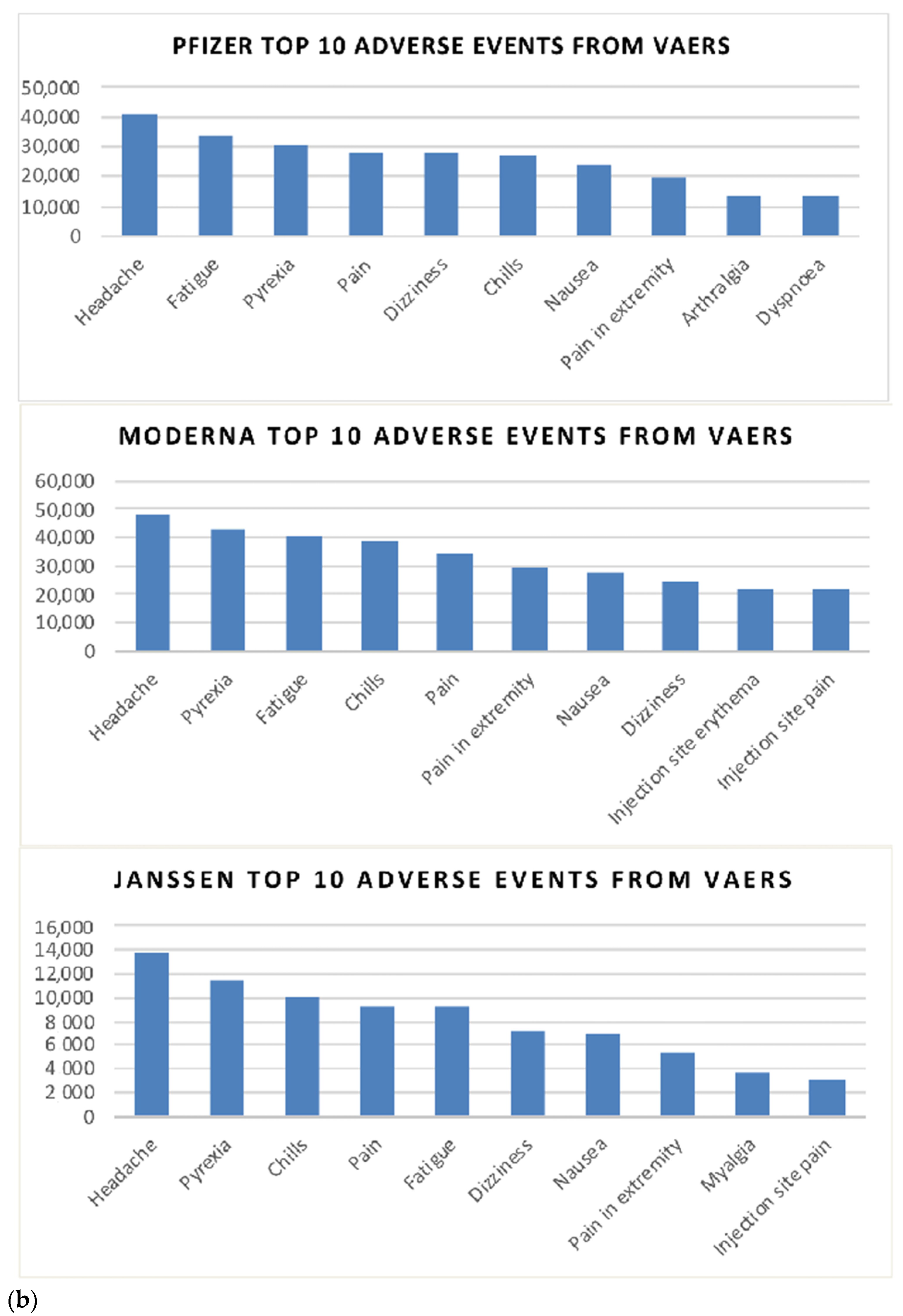
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ritchie, H.; Mathieu, E.; Rodés-Guirao, L.; Appel, C.; Giattino, C.; Ortiz-Ospina, E.; Hasell, J.; Macdonald, B.; Beltekian, D.; Dattani, S.; et al. Coronavirus Pandemic (COVID-19). Our World in Data. 2021. Available online: https://ourworldindata.org/coronavirus (accessed on 3 January 2022).
- CDC. CDC Ensuring COVID-19 Vaccines Work. 2021. Available online: https://www.cdc.gov/coronavirus/2019-ncov/vaccines/effectiveness/work.html (accessed on 3 January 2022).
- Reis, B.Y.; Barda, N.; Leshchinsky, M.; Kepten, E.; Hernan, M.A.; Lipsitch, M.; Daga, N.; Balicer, R.D. Effectiveness of BNT162b2 Vaccine against Delta Variant in Adolescents. N. Engl. J. Med. 2021, 385, 2101–2103. [Google Scholar] [CrossRef] [PubMed]
- Collie, S.; Champion, J.; Moultrie, H.; Bekker, L.-G.; Gray, G. Effectiveness of BNT162b2 Vaccine against Omicron Variant in South Africa. N. Engl. J. Med. 2021. [Google Scholar] [CrossRef]
- U.S. Food & Drug Administration. COVID-19 Vaccine Safety Surveillance. 2021. Available online: https://www.fda.gov/vaccines-blood-biologics/safety-availability-biologics/covid-19-vaccine-safety-surveillance (accessed on 3 January 2022).
- Gupta, A.; Katarya, R. Social media based surveillance systems for healthcare using machine learning: A systematic review. J. Biomed. Inform. 2020, 108, 103500. [Google Scholar] [CrossRef] [PubMed]
- Eysenbach, G. Infodemiology: Tracking flu-related searches on the web for syndromic surveillance. AMIA Annu. Symp. Proc. 2006, 2006, 244–248. [Google Scholar]
- Hossain, L.; Kam, D.; Kong, F.; Wigand, R.T.; Bossomaier, T. Social media in Ebola outbreak. Epidemiol. Infect. 2016, 144, 2136–2143. [Google Scholar] [CrossRef] [PubMed]
- Abouzahra, M.; Tan, J. Twitter vs. Zika—The role of social media in epidemic outbreaks surveillance. Health Policy Technol. 2021, 10, 174–181. [Google Scholar] [CrossRef]
- Masri, S.; Jia, J.; Li, C.; Zhou, G.; Lee, M.-C.; Yan, G.; Wu, J. Use of Twitter data to improve Zika virus surveillance in the United States during the 2016 epi-demic. BMC Public Health 2019, 19, 761. [Google Scholar] [CrossRef]
- Carlos, M.A.; Nogueira, M.; Machado, R.J. Analysis of dengue outbreaks using big data analytics and social networks. In Proceedings of the 2017 4th International Conference on Systems and Informatics (ICSAI), Hangzhou, China, 11–13 November 2017; pp. 1592–1597. [Google Scholar]
- Li, J.; Xu, Q.; Cuomo, R.; Purushothaman, V.; Mackey, T. Data mining and content analysis of the Chinese social media plat-form Weibo during the early COVID-19 outbreak: Retrospective observational infoveillance study. JMIR Public Health Sur-Veill. 2020, 6, e18700. [Google Scholar] [CrossRef] [Green Version]
- Shen, C.; Chen, A.; Luo, C.; Zhang, J.; Feng, B.; Liao, W. Using Reports of Symptoms and Diagnoses on Social Media to Predict COVID-19 Case Counts in Mainland China: Observational Infoveillance Study. J. Med. Internet Res. 2020, 22, e19421. [Google Scholar] [CrossRef]
- Chen, J.; Wang, Y. Social Media Use for Health Purposes: Systematic Review. J. Med. Internet Res. 2021, 23, e17917. [Google Scholar] [CrossRef]
- Aiello, A.E.; Renson, A.; Zivich, P.N. Social Media– and Internet-Based Disease Surveillance for Public Health. Annu. Rev. Public Health 2020, 41, 101–118. [Google Scholar] [CrossRef] [Green Version]
- Nikfarjam, A.; Gonzalez, G.H. Pattern mining for extraction of mentions of adverse drug reactions from user comments. AMIA Annu. Symp. Proc. 2011, 2011, 1019–1026. [Google Scholar] [PubMed]
- World Health Organisation. Safety of Medicines—A Guide to Detecting and Reporting Adverse Drug Reactions-Why Health Professionals Need to Take Action; World Health Organisation: Geneva, Switzerland, 2002. [Google Scholar]
- Pappa, D.; Stergioula, L.K. Harnessing social media data for pharmacovigilance: A review of current state of the art, challenges and future directions. Int. J. Data Sci. Anal. 2019, 8, 113–135. [Google Scholar] [CrossRef] [Green Version]
- Tricco, A.C.; Zarin, W.; Lillie, E.; Jeblee, S.; Warren, R.; Khan, P.A.; Robson, R.; Pham, B.; Hirst, G.; Straus, S.E. Utility of social media and crowd-intelligence data for pharmacovigilance: A scoping review. BMC Med. Inform. Decis. Mak. 2018, 18, 38. [Google Scholar] [CrossRef] [Green Version]
- Chou, W.-Y.S.; Gaysynsky, A.; Trivedi, H.; Vanderpool, R.C. Using Social Media for Health: National Data from HINTS 2019. J. Health Commun. 2021, 26, 184–193. [Google Scholar] [CrossRef]
- Paul, M.M.; Sarker, A.; Brownstein, J.S.; Nikfarjam, A.; Scotch, M.; Smith, K.L.; Gonzalez, G. Social media mining for public health monitoring and surveillance. In Pacific Symposium on Biocomputing 2016; World Scientific Publishing: Big Island, HI, USA, 2016; pp. 468–479. [Google Scholar]
- Jones, I.; Roy, P. Sputnik V COVID-19 vaccine candidate appears safe and effective. Lancet 2021, 397, 671. [Google Scholar] [CrossRef]
- Taylor, L. Why Cuba developed its own covid vaccine—And what happened next. BMJ 2021, 374, n1912. [Google Scholar] [CrossRef]
- World Health Organisation. Coronavirus Disease (COVID-19): Vaccines. 2021. Available online: https://www.who.int/news-room/questions-and-answers/item/coronavirus-disease-(covid-19)-vaccines?gclid=CjwKCAiAh_GNBhAHEiwAjOh3ZJ1mu-mpXy9QnPivLAUOmBwM9c8PRANGjjtHJydxTOWdzQQQUTPs4RoCEqEQAvD_BwE&topicsurvey=v8kj13 (accessed on 3 January 2022).
- Soysal, E.; Wang, J.; Jiang, M.; Wu, Y.; Pakhomov, S.; Liu, H.; Xu, H. CLAMP—A toolkit for efficiently building customized clinical natural language processing pipelines. J. Am. Med. Inform. Assoc. 2018, 25, 331–336. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Crawford, E. Introducing Super Follows. 2021. Available online: https://blog.twitter.com/en_us/topics/product/2021/introducing-super-follows (accessed on 3 January 2022).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Medical Dictionary for Regulatory Activities. Available online: https://www.meddra.org/ (accessed on 1 October 2021).
- McHugh, M.L. Interrater reliability: The kappa statistic. Biochem. Med. 2012, 22, 276–282. [Google Scholar] [CrossRef]
- Auxier, B.; Anderson, M. Social Media Use in 2021; Pew Research Center: Washington, DC, USA, 2021. [Google Scholar]
- Tang, L.; Bie, B.; Park, E.S.; Zhi, D. Social media and outbreaks of emerging infectious diseases: A systematic review of literature. Am. J. Infect. Control 2018, 46, 962–972. [Google Scholar] [CrossRef]
- Mayo Clinic. U.S. COVID-19 Vaccine Tracker: See Your State’s Progress. Available online: https://www.mayoclinic.org/coronavirus-covid-19/vaccine-tracker (accessed on 1 October 2021).
- Wojcik, S.; Hughes, A. Sizing Up Twitter Users; Pew Research Center: Washington, DC, USA, 2019. [Google Scholar]
- Rief, W. Fear of adverse effects and COVID-19 vaccine hesitancy: Recommendations of the treatment expectation expert group. JAMA Health Forum 2021, 2, e210804. [Google Scholar] [CrossRef]
- Du, J.; Tang, L.; Xiang, Y.; Zhi, D.; Xu, J.; Song, H.; Tao, C. Public Perception Analysis of Tweets During the 2015 Measles Outbreak: Comparative Study Using Convolutional Neural Network Models. J. Med. Internet Res. 2018, 20, e236. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Penţa, M.A.; Băban, A. Message Framing in Vaccine Communication: A Systematic Review of Published Literature. Health Commun. 2018, 33, 299–314. [Google Scholar] [CrossRef] [PubMed]
- Chou, W.-Y.S.; Budenz, A. Considering Emotion in COVID-19 Vaccine Communication: Addressing Vaccine Hesitancy and Fostering Vaccine Confidence. Health Commun. 2020, 35, 1718–1722. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | SVM | Extra Trees | Random Forest | Logistic Regression | Gradient Boosting | |
|---|---|---|---|---|---|---|
| Precision | Included | 0.896 | 0.904 | 0.906 | 0.927 * | 0.921 |
| Excluded | 0.898 | 0.852 | 0.910 * | 0.878 | 0.850 | |
| Recall | Included | 0.940 | 0.905 | 0.946 * | 0.921 | 0.901 |
| Excluded | 0.830 | 0.850 | 0.847 | 0.886 * | 0.879 | |
| F-1 | Included | 0.918 | 0.905 | 0.926 * | 0.924 | 0.911 |
| Excluded | 0.863 | 0.850 | 0.877 | 0.882 * | 0.864 | |
| Accuracy | 0.897 | 0.884 | 0.908 * | 0.908 * | 0.892 | |
| Entity | Vaccine | Dose | Adverse Event |
|---|---|---|---|
| Precision | 0.856 | 0.851 | 0.784 |
| Recall | 0.846 | 0.862 | 0.755 |
| F-1 | 0.851 | 0.857 | 0.770 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lian, A.T.; Du, J.; Tang, L. Using a Machine Learning Approach to Monitor COVID-19 Vaccine Adverse Events (VAE) from Twitter Data. Vaccines 2022, 10, 103. https://doi.org/10.3390/vaccines10010103
Lian AT, Du J, Tang L. Using a Machine Learning Approach to Monitor COVID-19 Vaccine Adverse Events (VAE) from Twitter Data. Vaccines. 2022; 10(1):103. https://doi.org/10.3390/vaccines10010103
Chicago/Turabian StyleLian, Andrew T., Jingcheng Du, and Lu Tang. 2022. "Using a Machine Learning Approach to Monitor COVID-19 Vaccine Adverse Events (VAE) from Twitter Data" Vaccines 10, no. 1: 103. https://doi.org/10.3390/vaccines10010103
APA StyleLian, A. T., Du, J., & Tang, L. (2022). Using a Machine Learning Approach to Monitor COVID-19 Vaccine Adverse Events (VAE) from Twitter Data. Vaccines, 10(1), 103. https://doi.org/10.3390/vaccines10010103