Classification of Alzheimer’s Disease with and without Imagery Using Gradient Boosted Machines and ResNet-50



Abstract
1. Introduction
1.1. Background
1.2. Related Research
2. Materials and Methods
2.1. Data and Software
2.2. Dependent Variable
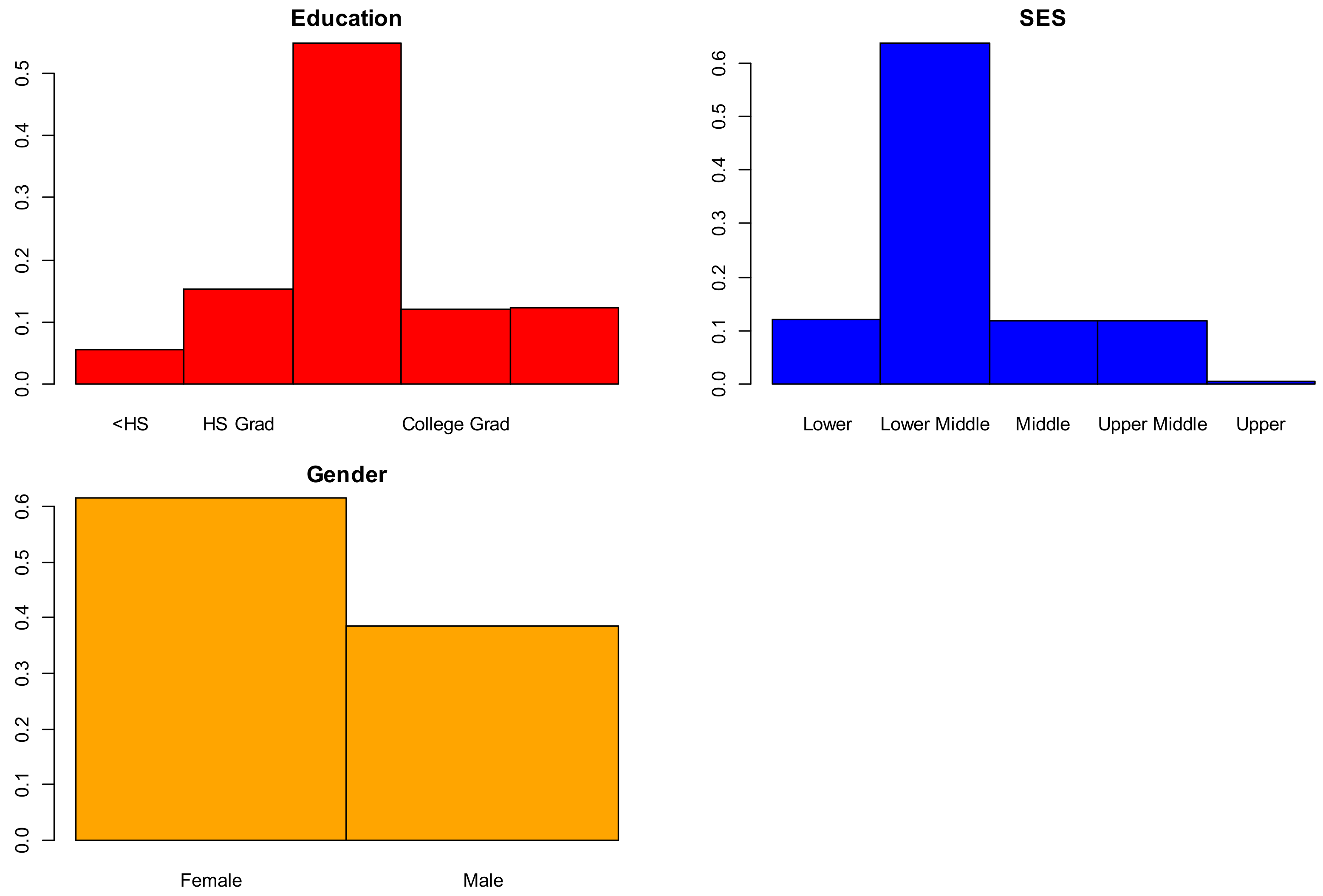
2.2.1. Socio-Demographic Predictor Variables, Non-Imagery Data
- Gender: {0 = Female, 1 = Male}, 100% complete (416 of 416);
- Age: (18, 96) years of age, 100% complete (416 of 416);
- Education: {1 < high school (HS), 2 = HS Graduate, 3 = Some College, 4 = College Graduate, 5 = Beyond College Graduate}, 56% complete (235 of 416);
- Socioeconomic Status (SES): (1 = lower, 2 = lower middle, 3 = middle, 4 = upper middle, 5 = upper), 52% complete (216 of 416).
2.2.2. Clinical Predictor Variables, Non-Imagery Data
- Estimated total intracranial volume (eTIV): (1132–1992) mm3 [24]. The eTIV variable estimates intracranial brain volume. This variable was 100% complete (416 of 416).
- Normalized whole brain volume (nWBV): (0.64–0.90) mg (observed). This variable measures the volume of the whole brain. This variable was 100% complete (416 of 416).
2.2.3. Imagery Variables
2.3. Non-Imagery Models
2.3.1. Imputation, Cross Validation, and Pseudo-Random Seeds
2.3.2. Gradient Boosted Tree Ensembles (Gradient Boosting)
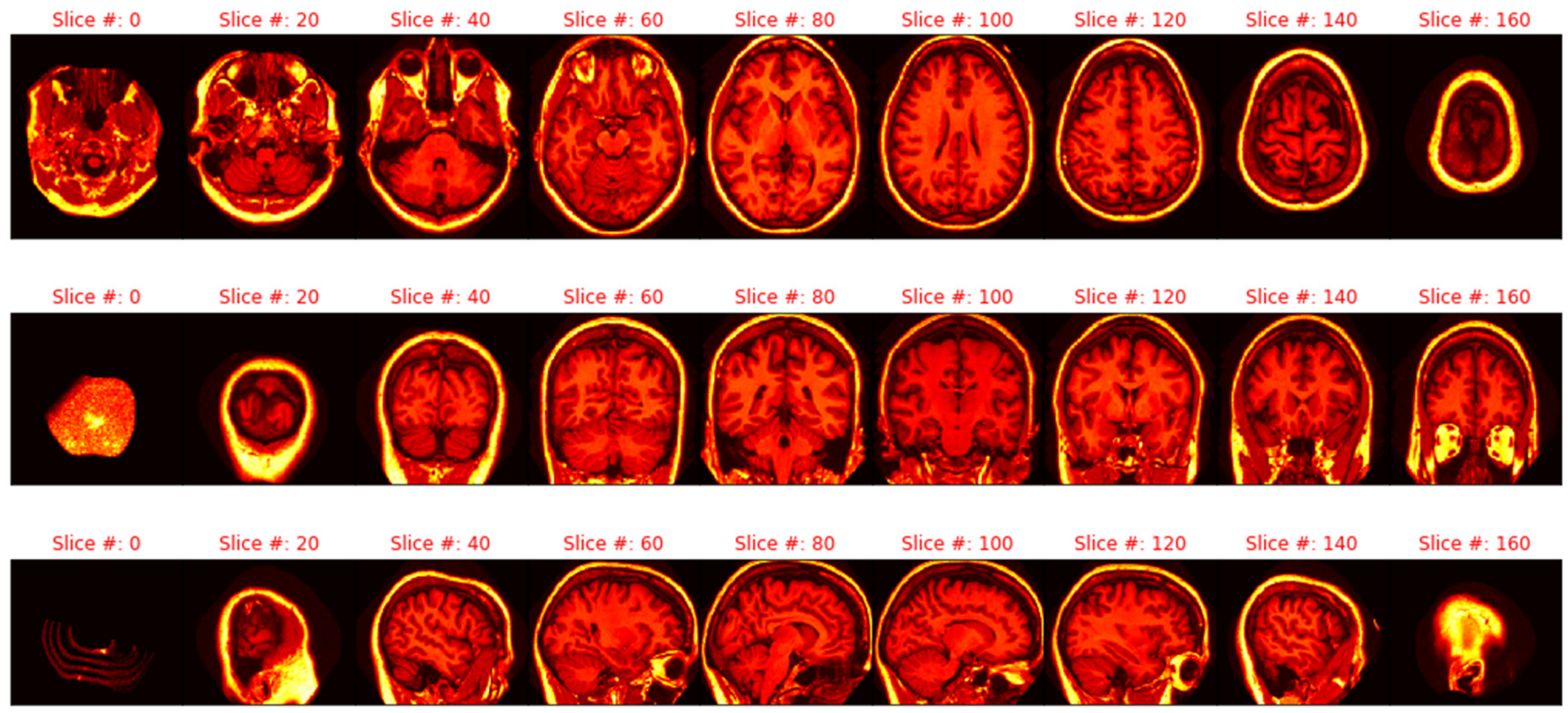
2.4. Imagery Data
2.4.1. Pre-processing: Min–Max Scaling, PCA Investigation, and Pseudo-Random Seeds
2.4.2. Extraction and Manipulation of Individual Images
2.4.3. Flow from the Dataframe, Training and Validation Set, and Training Image Generation
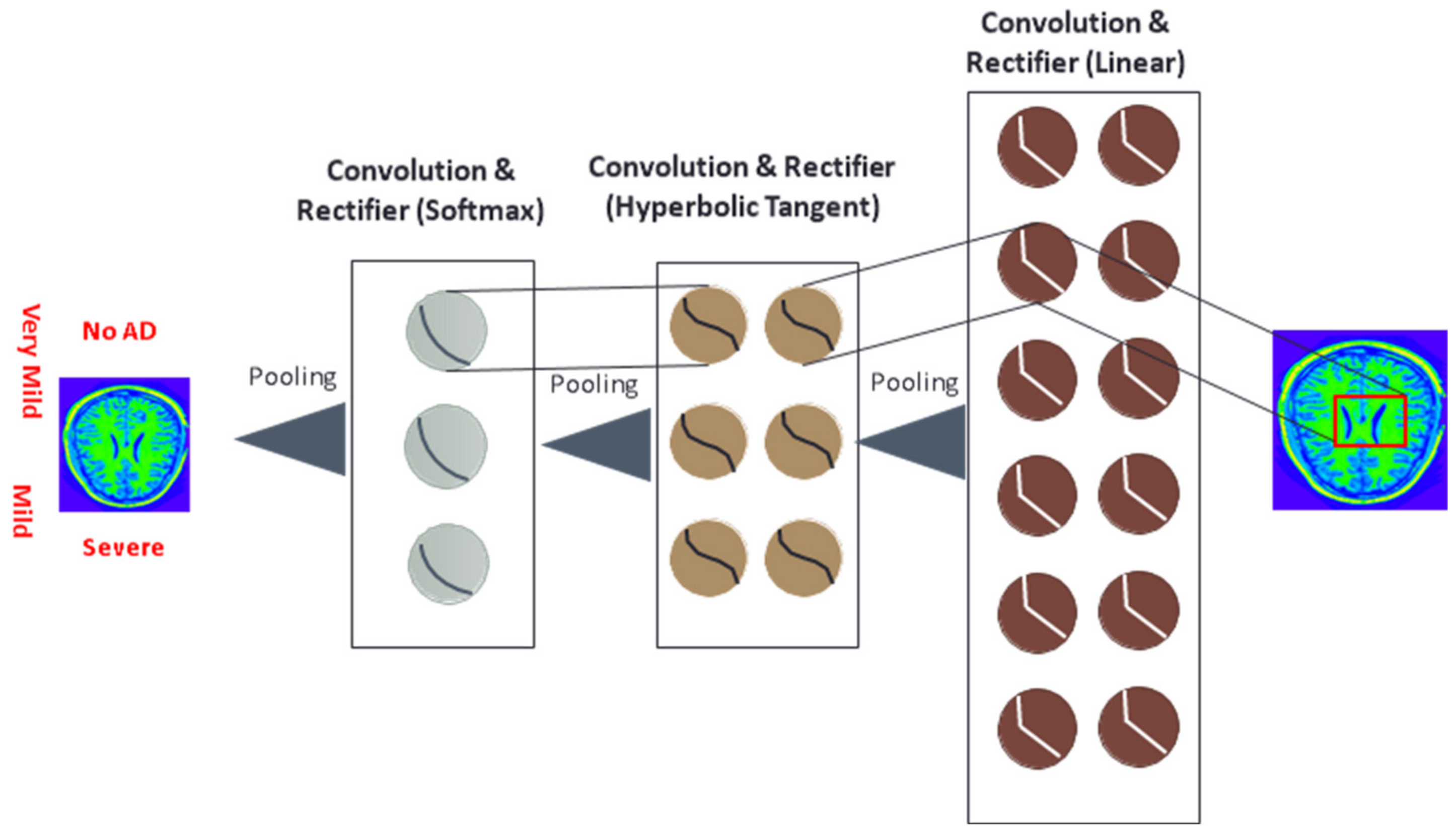
2.4.4. Deep Learning with Residual Networks (ResNet-50), and Imagery Data
3. Results
3.1. Descriptive Statistics
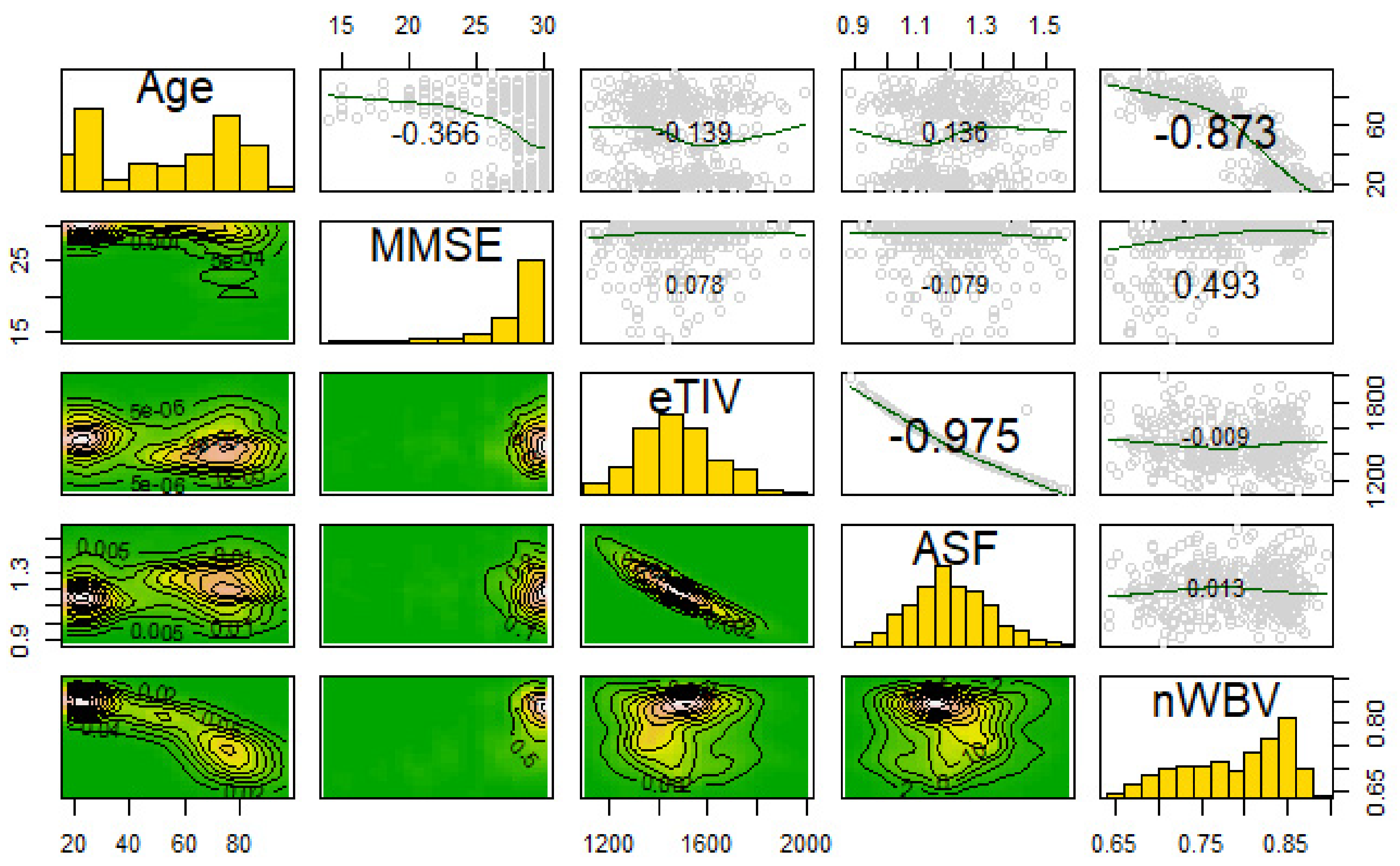
3.2. Correlations and Variable Transformations
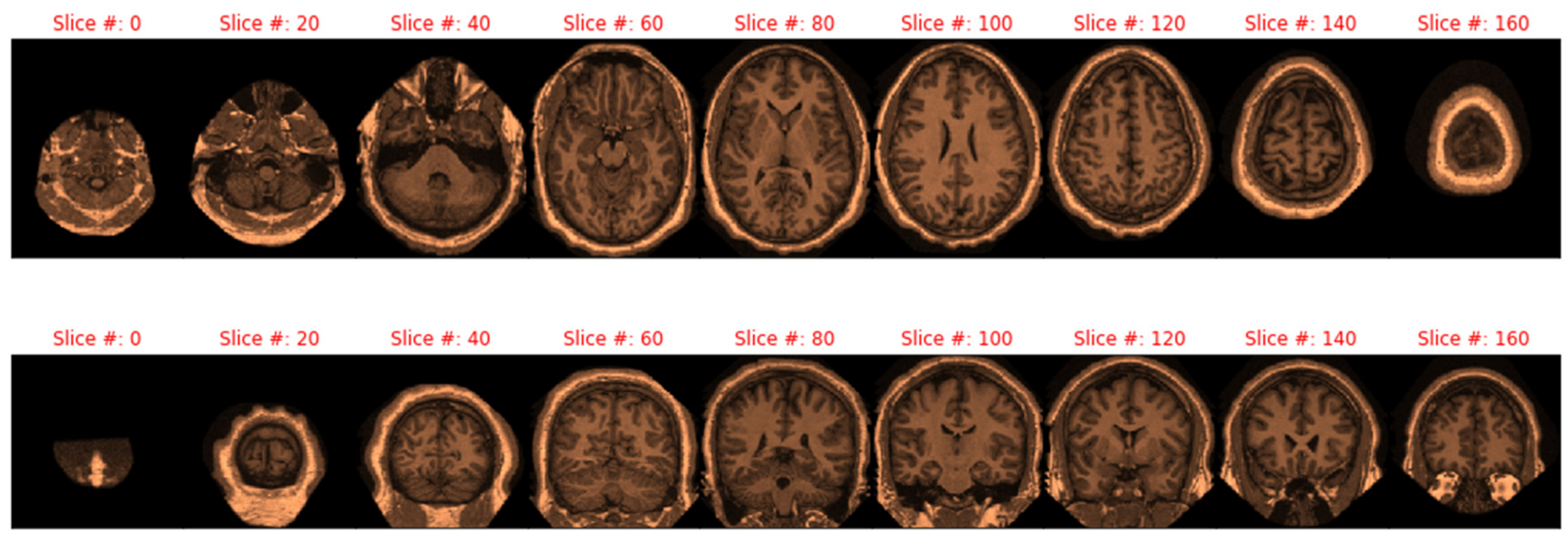
3.3. Transformation of MRIs and Eigenbrain Development
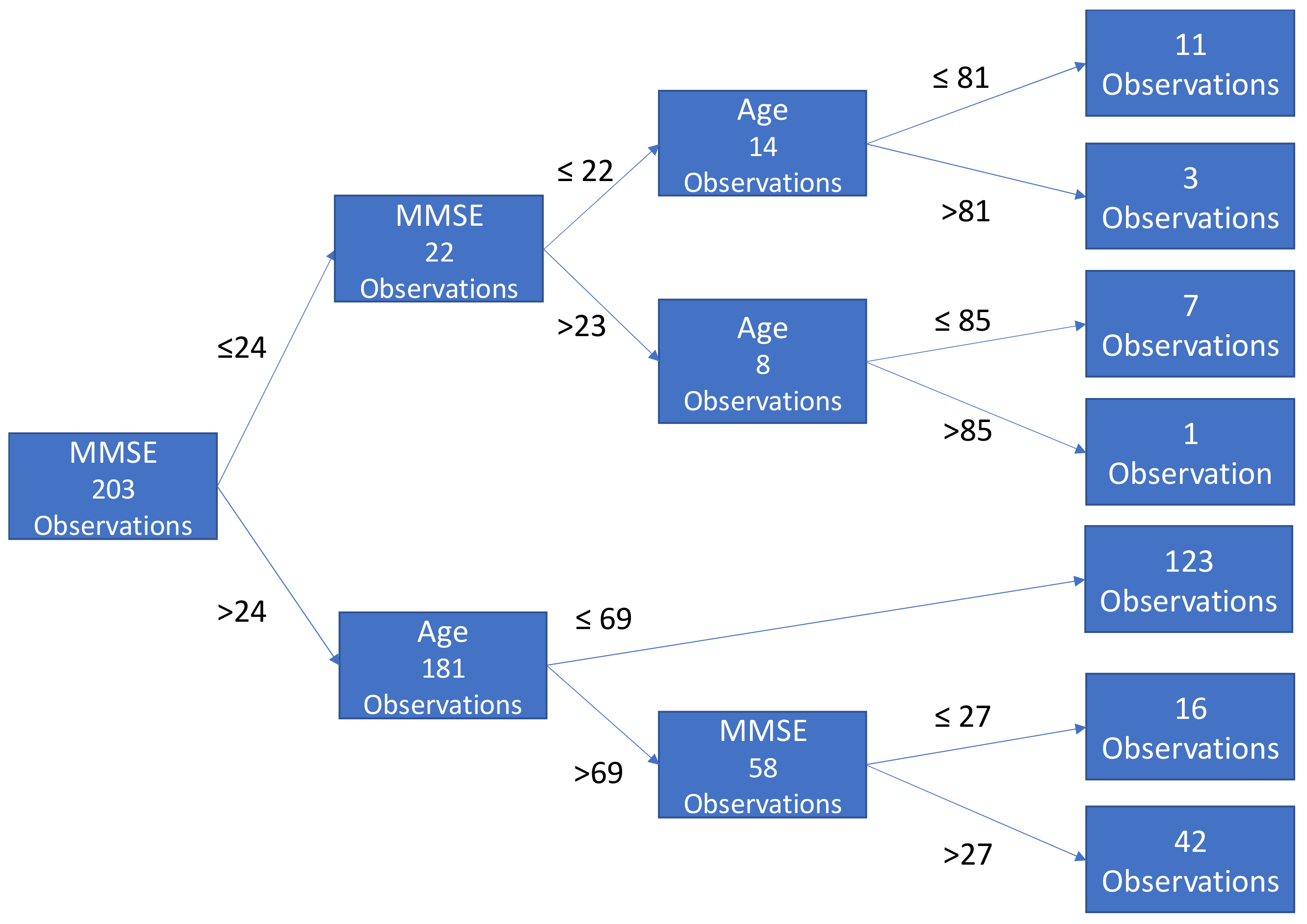
3.4. Gradient Boosting with XGBoost and No Imagery
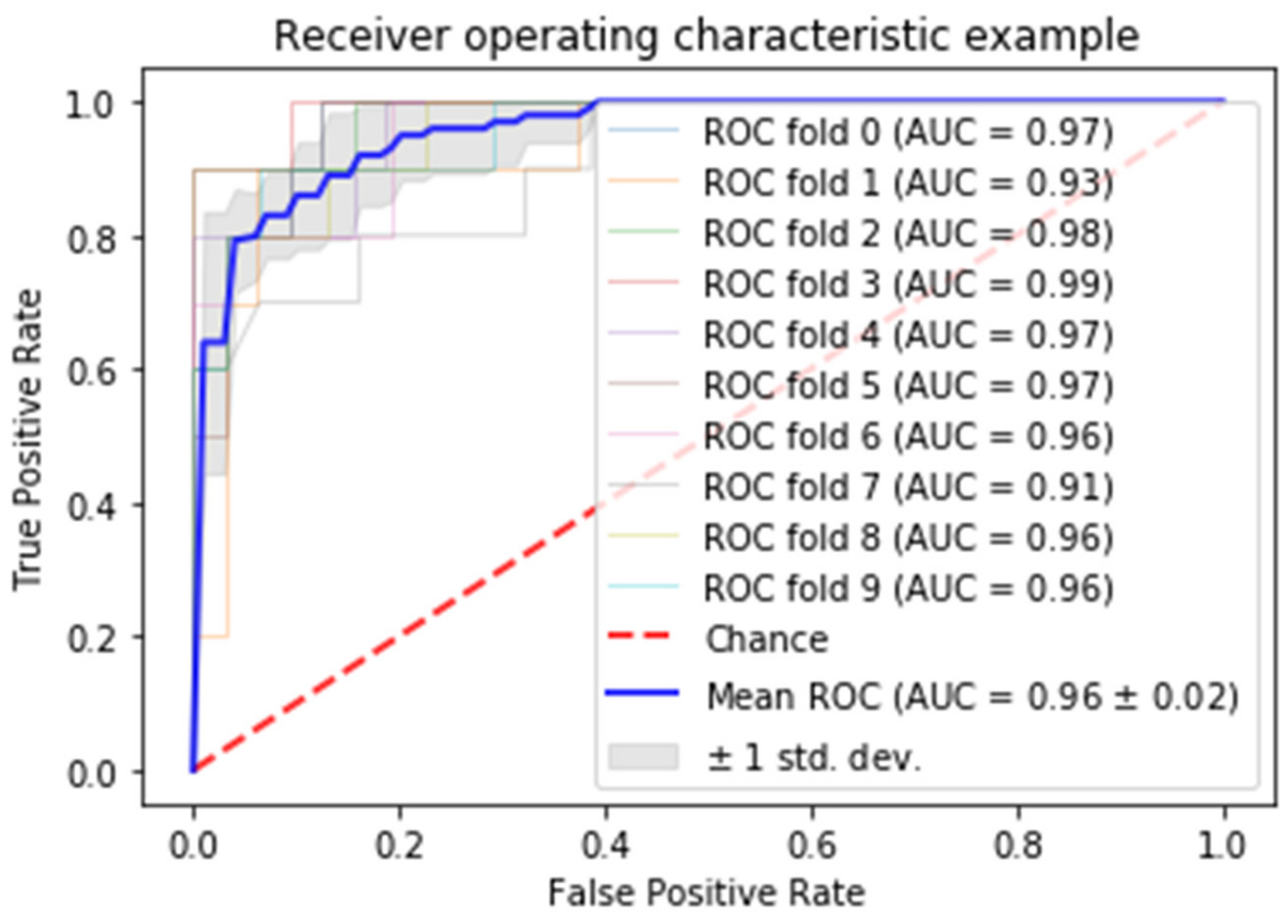
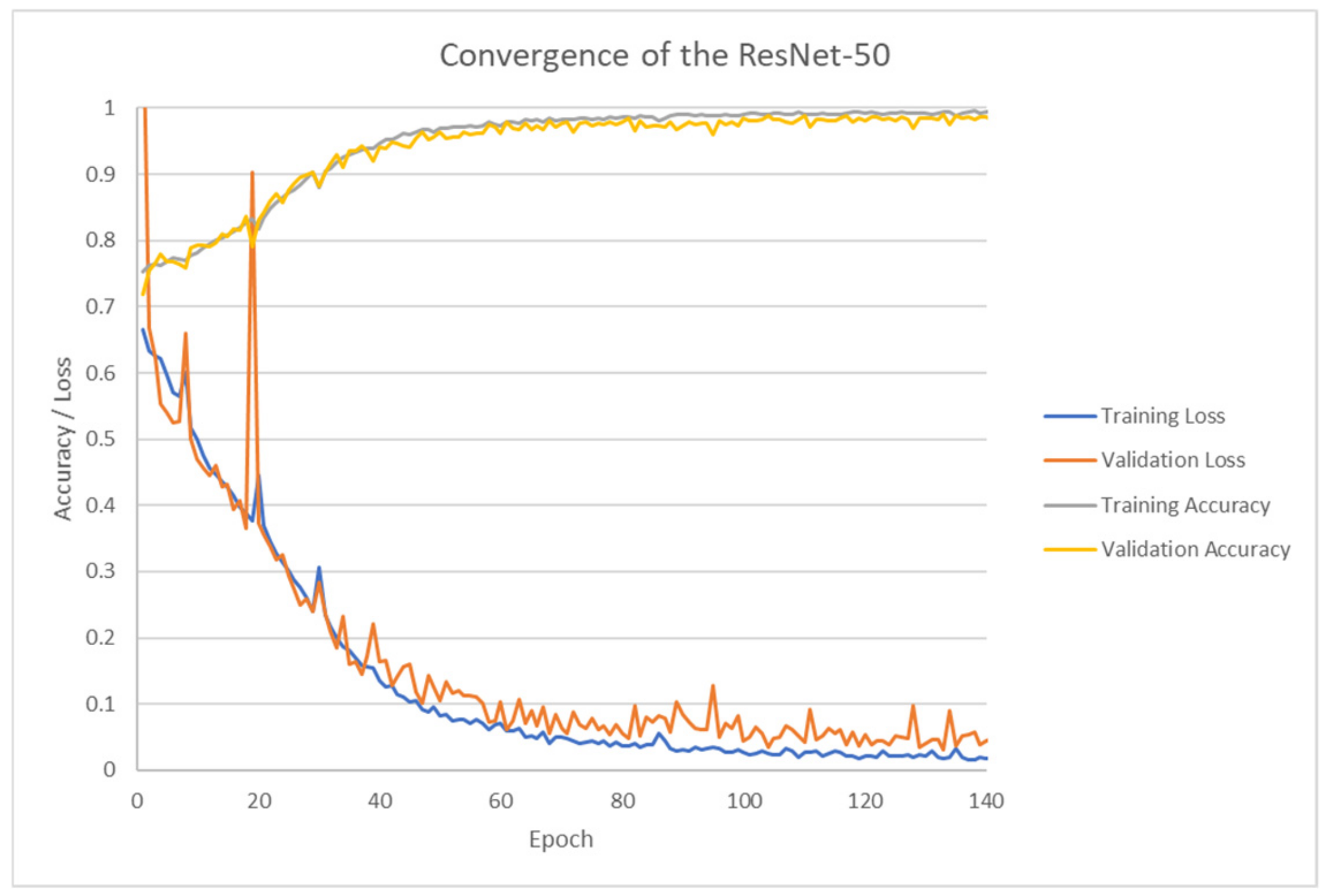
3.5. ResNet-50 (Deep Learning) with Keras
4. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mayeux, R.; Sano, M. Treatment of Alzheimer’s disease. N. Engl. J. Med. 1999, 341, 1670–1679. [Google Scholar] [CrossRef] [PubMed]
- Alzheimer’s Association. Facts and Figures. Available online: https://www.alz.org/alzheimers-dementia/facts-figures (accessed on 15 October 2018).
- VanMeter, K.; Hubert, R.J. Gould’s Pathophysiology for the Health Professions, 6th ed.; Elsevier: St. Louis, MO, USA, 2017. [Google Scholar]
- Bhagwat, N.; Viviano, J.D.; Voineskos, A.N.; Chakravart, M.M. Modeling and prediction of clinical symptom trajectories in Alzheimer’s disease using longitudinal data. PLoS Comput. Biol. 2018, 14, 1–25. [Google Scholar] [CrossRef]
- Amino. Brain MRI Costs. Available online: https://amino.com/blog/brain-mri-cost (accessed on 15 October 2018).
- Driscoll, I.; Troncoso, J. Asymptomatic Alzheimerʼs Disease: A Prodrome or a State of Resilience? Curr. Alzheimer Res. 2011, 8, 330–335. [Google Scholar] [CrossRef] [PubMed]
- Rubin, E.H.; Storandt, M.; Miller, J.P.; Kinscherf, D.A.; Grant, E.A.; Morris, J.C.; Berg, L. A prospective study of cognitive function and onset of dementia in cognitively healthy elders. Arch. Neurol. 1998, 55, 395–401. [Google Scholar] [CrossRef] [PubMed]
- Aljondi, R.; Szoeke, C.; Steward, C. A decade of changes in brain volume and cognition. Brain Imaging Behav. 2018, 13, 554–563. [Google Scholar] [CrossRef]
- Huang, L.; Jin, Y.; Gao, Y.; Thung, K.H.; Shen, D. Longitudinal clinical score prediction in Alzheimer’s disease with soft-split sparse regression based random forest. Neurobiol. Aging 2016, 46, 180–191. [Google Scholar] [CrossRef]
- Small, B.; Backman, L. Longitudinal trajectories of cognitive change in preclinical Alzheimer’s disease: A growth mixture modeling analysis. Cortex 2007, 43, 826–834. [Google Scholar] [CrossRef]
- Zhang, Y.; Dong, Z.; Phillips, P.; Wang, S.; Ji, G.; Yang, J.; Yuan, T. Detection of subjects and brain regions related to Alzheimer’s disease using 3D MRI scans based on Eigenbrain and machine learning. Front. Comput. Neurosci. 2015, 9, 1–13. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, S.; Phillips, P.; Yang, J.; Yuan, T. Three-Dimensional Eigenbrain for the Detection of Subjects and Brain Regions Related with Alzheimer’s Disease. J. Alzheimer’s Dis. 2016, 50, 1163–1179. [Google Scholar] [CrossRef]
- Bansal, D.; Chhikara, R.; Khanna, K.; Gupta, P. Comparative Analysis of Various Machine Learning Algorithms for Detecting Dementia. Procedia Comput. Sci. 2018, 132, 1497–1502. [Google Scholar] [CrossRef]
- Bhagwat, N.; Pipitone, J.; Voineskos, A.; Chakravarty, M. An artificial neural network model for clinical score prediction in Alzheimer disease using structural neuroimaging measures. J. Psychiatry Neurosci. 2019, 5, 1–15. [Google Scholar] [CrossRef]
- Collij, L.E.; Heeman, F.; Kuijer, J.P.A.; Sanz-Arigita, E.J.; Van Berckel, B.N.M.; Barkhof, F.; Wink, A.M.; Ossenkoppele, R.; Benedictus, M.R.; Möller, C.; et al. Application of machine learning to arterial spin labeling in mild cognitive impairment and Alzheimer disease. Radiology 2016, 281, 865–875. [Google Scholar] [CrossRef] [PubMed]
- Lahmiri, S. Image characterization by fractal descriptors in variational mode decomposition domain: Application to brain magnetic resonance. Phys. A 2016, 456, 235–243. [Google Scholar] [CrossRef]
- Lahmiri, S.; Schmuel, A. Performance of machine learning methods applied to structural MRI and ADAS cognitive scores in diagnosing Alzheimer’s disease. Biomed. Signal Process. Control 2019, 52, 414–419. [Google Scholar] [CrossRef]
- Lahmiri, S.; Boukadoum, M. New approach for automatic classification of Alzheimer’s disease, mild cognitive impairment and healthy brain magnetic resonance images. Healthc. Technol. Lett. 2014, 1, 32–36. [Google Scholar] [CrossRef] [PubMed]
- Open Access Series of Imaging Studies (OASIS). Available online: http://www.oasis-brains.org/ (accessed on 25 April 2019).
- Marcus, D.S.; Wang, T.H.; Parker, J.; Csernansky, J.G.; Morris, J.C.; Buckner, R.L. Open Access Series of Imaging Studies (OASIS): Cross-sectional MRI data in young, middle aged, nondemented, and demented older adults. J. Cogn. Neurosci. 2007, 19, 1498–1507. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Core Team: Vienna, Austria, 2016. [Google Scholar]
- Python Software Foundation. Python Language Reference; Version 3.6; Python Software Foundation: Wilmington, DE, USA, 2015. [Google Scholar]
- Morris, J.C. The Clinical Dementia Rating (CDR): Current version and scoring rules. Neurology 1993, 43, 2412–2414. [Google Scholar] [CrossRef] [PubMed]
- Buckner, R.L.; Head, D.; Parker, J.; Fotenos, A.F.; Marcus, D.; Morris, J.C.; Snyder, A.Z. A unified approach for morphometric and functional data analysis in young, old, and demented adults using automated atlas-based head size normalization: Reliability and validation against manual measurement of total intracranial volume. Neuroimage 2004, 23, 724–738. [Google Scholar] [CrossRef] [PubMed]
- Zujun, H. A Review on MR Image Intensity Inhomogeneity Correction. Int. J. Biomed. Imaging 2006, 2006, 1–11. [Google Scholar] [CrossRef]
- Talairach, J.; Tournoux, P. Co-Planar Stereotaxic Atlas of the Human Brain; Thieme: New York, NY, USA, 1988. [Google Scholar]
- The Talairach Project. Talairach Coordinate Space. Available online: http://www.talairach.org/about.html (accessed on 8 January 2019).
- Cao, J.; Su, Z.; Yu, L.; Chang, D.; Li, X.; Ma, Z. Softmax Cross Entropy Loss with Unbiased Decision Boundary for Image Classification. In Proceedings of the 2018 Chinese Automation Congress (CAC), Xi’an, China, 30 November–2 December 2018; p. 2028. [Google Scholar] [CrossRef]
- Zhang, Y.; Yao, J. Gini objective functions for three-way classifications. Int. J. Approx. Reason. 2017, 81, 103–114. [Google Scholar] [CrossRef]
- Sakata, R.; Ohama, I.; Taniguchi, T. An Extension of Gradient Boosted Decision Tree Incorporating Statistical Tests. In Proceedings of the 2018 IEEE International Conference on Data Mining Workshops (ICDMW), Singapore, 17–20 November 2018; p. 964. [Google Scholar] [CrossRef]
- Chen, L. Basic Ensemble Learning (Random Forest, AdaBoost, Gradient Boosting)- Step by Step Explaineds. 2019. Available online: https://towardsdatascience.com/basic-ensemble-learning-random-forest-adaboost-gradient-boosting-step-by-step-explained-95d49d1e2725 (accessed on 8 January 2019).
- Tianqi, C.; Tong, H.; Michael, B.; Vadim, K.; Yuan, T.; Hyunsu, C.; Kailong, C.; Rory, M.; Ignacio, C.; Tianyi, Z.; et al. Xgboost: Extreme Gradient Boosting. R Package Version 0.82.1. Available online: https://CRAN.R-project.org/package=xgboost (accessed on 15 October 2018).
- Álvarez, I.; Górriz, J.M.; Ramírez, J.; Salas-Gonzalez, D.; López, M.; Segovia, F.; Puntonet, C.G. Alzheimer’s diagnosis using Eigenbrains and support vector machines. Electron. Lett. 2009, 45, 342–343. [Google Scholar] [CrossRef]
- Poli, R.; Citi, L.; Salvaris, M.; Cinel, C.; Sepulveda, F. Eigenbrains: The free vibrational modes of the brain as a new representation for EEG. Conf. Proc. IEEE Eng. Med. Biol. Soc. 2010, 2010, 6011–6014. [Google Scholar] [PubMed]
- Francois, C. Keras Tensorflow; GitHub Repository: San Francisco, CA, USA, 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; p. 770. [Google Scholar] [CrossRef]
- Fung, V. An Overview of ResNet and its Variants. 2017. Available online: https://towardsdatascience.com/an-overview-of-resnet-and-its-variants-5281e2f56035 (accessed on 8 January 2019).
- Qiu, A.; Younes, L.; Miller, M.I. Principal Component Based Diffeomorphic Surface Mapping. IEEE Trans. Med. Imaging 2012, 31, 302. [Google Scholar] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Non-Demented | Demented | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Age | N | n | Mean | Male | Female | n | Mean | Male | Female | CDR 0.5/1/2 |
| <20 | 19 | 19 | 18.53 | 10 | 9 | 0 | 0 | 0 | 0 | 0/0/0 |
| [20, 30) | 119 | 119 | 22.82 | 51 | 68 | 0 | 0 | 0 | 0 | 0/0/0 |
| [30, 40) | 16 | 16 | 33.38 | 11 | 5 | 0 | 0 | 0 | 0 | 0/0/0 |
| [40, 50) | 31 | 31 | 45.58 | 10 | 21 | 0 | 0 | 0 | 0 | 0/0/0 |
| [50, 60) | 33 | 33 | 54.36 | 11 | 22 | 0 | 0 | 0 | 0 | 0/0/0 |
| [60, 70) | 40 | 25 | 64.88 | 7 | 18 | 15 | 66.13 | 6 | 9 | 12/3/0 |
| [70, 80) | 83 | 35 | 73.37 | 10 | 25 | 48 | 74.42 | 20 | 28 | 32/15/1 |
| [80, 90) | 62 | 30 | 84.07 | 8 | 22 | 32 | 82.88 | 13 | 19 | 22/9/1 |
| [90, 100) | 13 | 8 | 91.00 | 1 | 7 | 5 | 92.00 | 2 | 3 | 4/1/0 |
| Total | 416 | 316 | n/a | 119 | 197 | 100 | n/a | 41 | 59 | 70/28/2 |
| CDR = 0, No Dementia | CDR = 0.5, Very Mild Dementia | CDR = 1, Mild Dementia | CDR = 2, Moderate Dementia | |
|---|---|---|---|---|
| Male | 119 | 31 | 9 | 1 |
| Female | 197 | 39 | 19 | 1 |
| Total | 316 | 70 | 28 | 2 |
| Variable | Mean | SD | Median | Min | Max |
|---|---|---|---|---|---|
| Age | 52.70 | 25.08 | 56 | 18 | 96 |
| Mini-Mental State Exam | 27.50 | 3.13 | 29 | 14 | 30 |
| eTIV (Intracranial Volume) | 1480.53 | 158.34 | 1475 | 1123 | 1992 |
| nWBV (Brain Volume) | 0.79 | 0.06 | 0.8 | 0.64 | 0.89 |
| ASF (Atlas Scaling Factor) | 1.2 | 0.13 | 1.19 | 0.88 | 1.56 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fulton, L.V.; Dolezel, D.; Harrop, J.; Yan, Y.; Fulton, C.P. Classification of Alzheimer’s Disease with and without Imagery Using Gradient Boosted Machines and ResNet-50. Brain Sci. 2019, 9, 212. https://doi.org/10.3390/brainsci9090212
Fulton LV, Dolezel D, Harrop J, Yan Y, Fulton CP. Classification of Alzheimer’s Disease with and without Imagery Using Gradient Boosted Machines and ResNet-50. Brain Sciences. 2019; 9(9):212. https://doi.org/10.3390/brainsci9090212
Chicago/Turabian StyleFulton, Lawrence V., Diane Dolezel, Jordan Harrop, Yan Yan, and Christopher P. Fulton. 2019. "Classification of Alzheimer’s Disease with and without Imagery Using Gradient Boosted Machines and ResNet-50" Brain Sciences 9, no. 9: 212. https://doi.org/10.3390/brainsci9090212
APA StyleFulton, L. V., Dolezel, D., Harrop, J., Yan, Y., & Fulton, C. P. (2019). Classification of Alzheimer’s Disease with and without Imagery Using Gradient Boosted Machines and ResNet-50. Brain Sciences, 9(9), 212. https://doi.org/10.3390/brainsci9090212