
Prediction of Parkinson Disease Using Long-Term, Short-Term Acoustic Features Based on Machine Learning
 , , , ,
, , , ,  ,
,  ,
, 
Abstract
1. Introduction
1.1. Background
1.2. Related Work
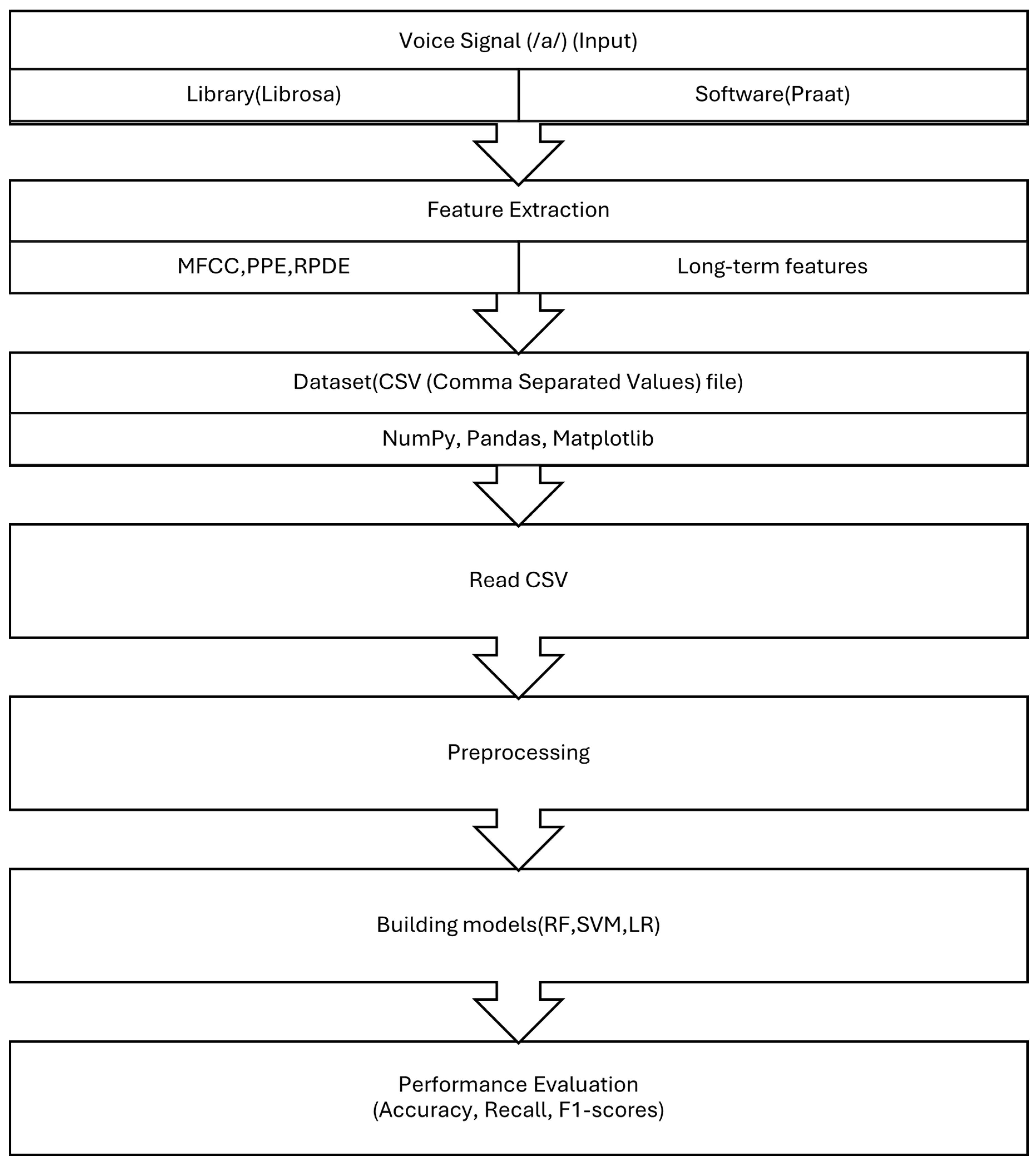
2. Materials and Methods
2.1. Dataset Preparation
2.2. Acoustic Signal Features
2.2.1. Long Term Features
2.2.2. Pitch Period Entropy (PPE)
2.2.3. The Recurrence Period Density Entropy (RPDE)
2.2.4. Short Term Feature (Mel Frequency Cepstral Coefficients)
2.3. Classification Algorithms
2.3.1. Random Forest (RF)
2.3.2. Logistic Regression (LR)
2.3.3. Naive Bayes (NB)
2.3.4. Decision Tree
2.3.5. K-Nearest Neighbor (KNN Classifier)
2.3.6. Support Vector Machine (SVM)
2.4. Cross Validation
2.5. Evaluation Criteria
3. Results
- x is the original data point;
- µ is the mean of the data;
- σ is the standard deviation of the data.
4. Discussion
5. Limitation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| PD | Parkinson’s disease |
| HS | Directory of open access journals |
| CPPS | Smoothed cepstral peak prominence |
| PPE | Pitch Period Entropy |
| RPDE | Recurrence period density entropy |
| MFCCs | Mel-frequency cepstral coefficients |
| RF | Random Forest |
| KNN | K-nearest neighbors |
| ML | Machine Learning |
| NB | Naïve Bayes |
| SVM | Support vector machines |
| LR | Logistic Regression |
| ROC | Receiver-operating characteristic curve |
| AUC | Area under the curve |
| RBD | REM sleep behavior disorder |
| REM | Rapid Eye Movement |
| Eq | equation |
| TP | True Positive |
| FP | False Positive |
| TN | True Negative |
| FN | False Negative |
| MSE | Mean Squared Error |
| CV | Cross Validation |
| UPDRS | Unified Parkinson’s Disease Rating Scale |
| PIGD | Postural Instability and Gait Disorders |
| CPP | Cepstral Peak Prominence |
References
- Yang, K.; Wu, Z.; Long, J.; Li, W.; Wang, X.; Hu, N.; Zhao, X.; Sun, T. White matter changes in Parkinson’s disease. NPJ Park. Dis. 2023, 9, 150. [Google Scholar] [CrossRef] [PubMed]
- Dorsey, E.R.; Sherer, T.; Okun, M.S.; Bloem, B.R. The emerging evidence of the Parkinson pandemic. J. Park. Dis. 2018, 8, S3–S8. [Google Scholar] [CrossRef] [PubMed]
- Chaudhuri, K.R.; Azulay, J.P.; Odin, P.; Lindvall, S.; Domingos, J.; Alobaidi, A.; Kandukuri, P.L.; Chaudhari, V.S.; Parra, J.C.; Yamazaki, T.; et al. Economic Burden of Parkinson’s Disease: A Multinational, Real-World, Cost-of-Illness Study. Drugs Real World Outcomes 2024, 11, 1–11. [Google Scholar] [CrossRef]
- Mallamaci, R.; Musarò, D.; Greco, M.; Caponio, A.; Castellani, S.; Munir, A.; Guerra, L.; Damato, M.; Fracchiolla, G.; Coppola, C.; et al. Dopamine- and Grape-Seed-Extract-Loaded Solid Lipid Nanoparticles: Interaction Studies between Particles and Differentiated SH-SY5Y Neuronal Cell Model of Parkinson’s Disease. Molecules 2024, 29, 1774. [Google Scholar] [CrossRef] [PubMed]
- Poewe, W.; Seppi, K.; Tanner, C.M.; Halliday, G.M.; Brundin, P.; Volkmann, J.; Schrag, A.E.; Lang, A.E. Parkinson disease. Nat. Rev. Dis. Prim. 2017, 3, 1–21. [Google Scholar] [CrossRef]
- Etoom, M.; Alwardat, M.; Aburub, A.S.; Lena, F.; Fabbrizo, R.; Modugno, N.; Centonze, D. Therapeutic interventions for Pisa syndrome in idiopathic Parkinson’s disease. A Scoping Systematic Review. Clin. Neurol. Neurosurg. 2020, 198, 106242. [Google Scholar] [CrossRef]
- Magrinelli, F.; Picelli, A.; Tocco, P.; Federico, A.; Roncari, L.; Smania, N.; Zanette, G.; Tamburin, S. Pathophysiology of Motor Dysfunction in Parkinson’s Disease as the Rationale for Drug Treatment and Rehabilitation. Park. Dis. 2016, 2016, 9832839. [Google Scholar] [CrossRef]
- Mantri, S.; Morley, J.F. Prodromal and early Parkinson’s disease diagnosis. Pract. Neurol. 2018, 35, 28–31. [Google Scholar]
- Brabenec, L.; Mekyska, J.; Galaz, Z.; Rektorova, I. Speech disorders in Parkinson’s disease: Early diagnostics and effects of medication and brain stimulation. J. Neural Transm. 2017, 124, 303–334. [Google Scholar] [CrossRef]
- Ansari, K.A.; Johnson, A. Olfactory Function in Patients with Parkinson’s Disease. J. Cbron Dis. 1975, 28, 493–497. [Google Scholar] [CrossRef]
- Ramig, L.O.; Fox, C.; Sapir, S. Speech treatment for Parkinson’s disease. Expert Rev. Neurother. 2008, 8, 297–309. [Google Scholar] [CrossRef] [PubMed]
- Goetz, C.G.; Poewe, W.; Rascol, O.; Sampaio, C.; Stebbins, G.T.; Counsell, C.; Giladi, N.; Holloway, R.G.; Moore, C.G.; Wenning, G.K.; et al. Movement Disorder Society Task Force report on the Hoehn and Yahr staging scale: Status and recommendations. Mov. Disorders. 2004, 19, 1020–1028. [Google Scholar] [CrossRef] [PubMed]
- Weil, R.S.; Morris, H.R. REM sleep behaviour disorder: An early window for prevention in neurodegeneration? Brain 2019, 142, 498–501. [Google Scholar] [CrossRef]
- Doty, R.L. Olfactory dysfunction in neurodegenerative diseases: Is there a common pathological substrate? Lancet Neurol. 2017, 16, 478–488. [Google Scholar] [CrossRef]
- AnnalesD997Jokinen. Available online: https://www.utupub.fi/bitstream/handle/10024/72567/AnnalesD997Jokinen.pdf?sequence=1&isAllowed=y (accessed on 7 July 2025).
- O’Sullivan, S.B.; Schmitz, T.J. Physical Rehabilitation, 5th ed.; Davis Company: Philadelphia, PA, USA, 2007. [Google Scholar]
- Ahn, S.; Springer, K.; Gibson, J.S. Social withdrawal in Parkinson’s disease: A scoping review. Geriatr. Nurs. 2022, 48, 258–268. [Google Scholar] [CrossRef]
- Ma, A.; Lau, K.K.; Thyagarajan, D. Voice changes in Parkinson’s disease: What are they telling us? J. Clin. Neurosci. 2020, 72, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Harel, B.; Cannizzaro, M.; Snyder, P.J. Variability in fundamental frequency during speech in prodromal and incipient Parkinson’s disease: A longitudinal case study. Brain Cogn. 2004, 56, 24–29. [Google Scholar] [CrossRef]
- Rusz, J.; Krupička, R.; Vítečková, S.; Tykalová, T.; Novotný, M.; Novák, J.; Dušek, P.; Růžička, E. Speech and gait abnormalities in motor subtypes of de-novo Parkinson’s disease. CNS Neurosci Ther. 2023, 29, 2101–2110. [Google Scholar] [CrossRef]
- Skorvanek, M.; Martinez-Martin, P.; Kovacs, N.; Rodriguez-Violante, M.; Corvol, J.C.; Taba, P.; Seppi, K.; Levin, O.; Schrag, A.; Foltynie, T.; et al. Differences in MDS-UPDRS Scores Based on Hoehn and Yahr Stage and Disease Duration. Mov. Disord. Clin. Pract. 2017, 4, 536–544. [Google Scholar] [CrossRef]
- Naranjo, L.; Pérez, C.J.; Martín, J.; Campos-Roca, Y. A two-stage variable selection and classification approach for Parkinson’s disease detection by using voice recording replications. Comput. Methods Programs Biomed. 2017, 142, 147–156. [Google Scholar] [CrossRef]
- Di Cesare, M.G.; Perpetuini, D.; Cardone, D.; Merla, A. Assessment of Voice Disorders Using Machine Learning and Vocal Analysis of Voice Samples Recorded through Smartphones. BioMedInformatics 2024, 4, 549–565. [Google Scholar] [CrossRef]
- Géron, A. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2022. [Google Scholar]
- Zewoudie, A.W.; Luque, J.; Hernando, J. The use of long-term features for GMM- and i-vector-based speaker diarization systems. EURASIP J. Audio Speech Music. Process. 2018, 2018, 14. [Google Scholar] [CrossRef]
- Little, M.; McSharry, P.; Hunter, E.; Spielman, J.; Ramig, L. Suitability of dysphonia measurements for telemonitoring of Parkinson’s disease. IEEE Trans. Biomed. Eng. 2008, 56, 1015–1022. [Google Scholar] [CrossRef]
- Jeancolas, L.; Benali, H.; Benkelfat, B.-E.; Mangone, G.; Corvol, J.-C.; Vidailhet, M. Automatic detection of early stages of Parkinson’s disease through acoustic voice analysis with mel-frequency cepstral coefficients. In Proceedings of the 2017 International Conference on Advanced Technologies for Signal and Image Processing (ATSIP), Fez, Morocco, 22–24 May 2017; pp. 1–6. [Google Scholar]
- Convey, R.B.; Laukkanen, A.M.; Ylinen, S.; Penttilä, N. Analysis of Voice in Parkinson’s Disease Utilizing the Acoustic Voice Quality Index. J. Voice 2024, 1–10. [Google Scholar] [CrossRef]
- Hawi, S.; Alhozami, J.; AlQahtani, R.; AlSafran, D.; Alqarni, M.; El Sahmarany, L. Automatic Parkinson’s disease detection based on the combination of long-term acoustic features and Mel frequency cepstral coefficients (MFCC). Biomed. Signal Process. Control. 2022, 78, 104013. [Google Scholar] [CrossRef]
- Tracey, B.; Volfson, D.; Glass, J.; Haulcy, R.; Kostrzebski, M.; Adams, J.; Kangarloo, T.; Brodtmann, A.; Dorsey, E.R.; Vogel, A. Towards interpretable speech biomarkers: Exploring MFCCs. Sci. Rep. 2023, 13, 22787. [Google Scholar] [CrossRef] [PubMed]
- Kotsiantis, S.B.; Zaharakis, I.D.; Pintelas, P.E. Machine learning: A review of classification and combining techniques. Artif. Intell. Rev. 2006, 26, 159–190. [Google Scholar] [CrossRef]
- Berrar, D. Cross-validation. In Encyclopedia of Bioinformatics and Computational Biology: ABC of Bioinformatics; Elsevier: Amsterdam, The Netherlands, 2018; Volumes 1–3, pp. 542–545. [Google Scholar]
- Dao, S.V.; Yu, Z.; Tran, L.V.; Phan, P.N.; Huynh, T.T.; Le, T.M. An Analysis of Vocal Features for Parkinson’s Disease Classification Using Evolutionary Algorithms. Diagnostics 2022, 12, 1980. [Google Scholar] [CrossRef]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Christen, P.; Hand, D.J.; Kirielle, N. A review of the F-measure: Its history, properties, criticism, and alternatives. ACM Comput. Surv. 2023, 56, 1–24. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R.; Taylor, J. An Introduction to Statistical Learning with Application in Python, Springer Texts in Statistics (STS). 2023. Available online: https://www.statlearning.com/ (accessed on 7 July 2025).
- Demiroglu, C.; Si, D.; Atkins, D.C.; Ghomi, R.H.; Wroge, T.J.; Ozkanca, Y. Parkinson’s Disease Diagnosis Using Machine Learning and Voice. In Proceedings of the 2018 IEEE Signal Processing in Medicine and Biology Symposium (SPMB), Philadelphia, PA, USA, 1 December 2018; IEEE: New York, NY, USA, 2018; pp. 1–7. [Google Scholar]
- Iyer, A.; Kemp, A.; Rahmatallah, Y.; Pillai, L.; Glover, A.; Prior, F.; Larson-Prior, L.; Virmani, T. A machine learning method to process voice samples for identification of Parkinson’s disease. Sci. Rep. 2023, 13, 20615. [Google Scholar] [CrossRef]
- Suppa, A.; Costantini, G.; Asci, F.; Di Leo, P.; Al-Wardat, M.S.; Di Lazzaro, G.; Scalise, S.; Pisani, A.; Saggio, G. Voice in Parkinson’s Disease: A Machine Learning Study. Front. Neurol. 2022, 13, 831428. [Google Scholar] [CrossRef]
- Prior, F.; Virmani, T.; Iyer, A.; Larson-Prior, L.; Kemp, A.; Rahmatallah, Y.; Pillai, L.; Glover, A. Voice Samples for Patients with Parkinson’s Disease and Healthy Controls. Available online: https://figshare.com/articles/dataset/Voice_Samples_for_Patients_with_Parkinson_s_Disease_and_Healthy_Controls/23849127 (accessed on 7 July 2025).
- Dejonckere, P.H.; Bradley, P.; Clemente, P.; Cornut, G.; Friedrich, G.; Van De Heyning, P. A basic protocol for functional assessment of voice pathology, especially for investigating the efficacy of (phonosurgical) treatments and evaluating new assessment techniques: Guideline elaborated by the Committee on Phoniatrics of the European Laryngological Society (ELS). Eur. Arch. Oto-Rhino-Laryngol. 2001, 258, 77–82. [Google Scholar]
- Boersma, P.; van Heuven, V. Speak and unSpeak with Praat. Glot Int. 2001, 5, 341–347. [Google Scholar]
- Gorriz, J.M.; Segovia, F.; Ramirez, J.; Ortiz, A.; Suckling, J. Is K-fold cross validation the best model selection method for Machine Learning? arXiv 2024, arXiv:2401.16407. [Google Scholar]
- Oganian, Y.; Bhaya-Grossman, I.; Johnson, K.; Chang, E.F. Vowel and formant representation in the human auditory speech cortex. Neuron 2023, 111, 2105–2118.e4. [Google Scholar] [CrossRef]
- Little, M.; McSharry, P.; Roberts, S.; Costello, D.; Moroz, I. Exploiting nonlinear recurrence and fractal scaling properties for voice disorder detection. BioMed. Eng. OnLine 2007, 6, 23. [Google Scholar] [CrossRef]
- Davis, S.; Mermelstein, P. Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Trans. Acoust. 1980, 28, 357–366. [Google Scholar] [CrossRef]
- Tsanas, A.; Little, M.A.; McSharry, P.E.; Spielman, J.; Ramig, L.O. Novel speech signal processing algorithms for high-accuracy classification of Parkinson’s disease. IEEE Trans. Biomed. Eng. 2012, 59, 1264–1271. [Google Scholar] [CrossRef]
- Jin, Z.; Shang, J.; Zhu, Q.; Ling, C.; Xie, W.; Qiang, B. RFRSF: Employee Turnover Prediction Based on Random Forests and Survival Analysis. In Web Information Systems Engineering–WISE 2020: Proceedings of the 21st International Conference, Part II 21, Amsterdam, The Netherlands, 20–24 October 2020; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; Volume 12343, pp. 503–515. [Google Scholar]
- Peretz, O.; Koren, M.; Koren, O. Naive Bayes classifier—An ensemble procedure for recall and precision enrichment. Eng. Appl. Artif. Intell. 2024, 136, 108972. [Google Scholar] [CrossRef]
- Alalayah, K.M.; Senan, E.M.; Atlam, H.F.; Ahmed, I.A.; Shatnawi, H.S.A. Automatic and Early Detection of Parkinson’s Disease by Analyzing Acoustic Signals Using Classification Algorithms Based on Recursive Feature Elimination Method. Diagnostics 2023, 13, 1924. [Google Scholar] [CrossRef]
- Evgeniou, T.; Pontil, M. Support vector machines: Theory and applications. In Advanced Course on Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 1999; pp. 249–257. [Google Scholar]
- Grossi, E.; Buscema, M. Introduction to artificial neural networks. Eur. J. Gastroenterol. Hepatol. 2007, 19, 1046–1054. [Google Scholar] [CrossRef]
- Vakili, M.; Ghamsari, M.; Rezaei, M. Performance Analysis and Comparison of Machine and Deep Learning Algorithms for IoT Data Classification. arXiv 2020, arXiv:2001.09636. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Das, R. A comparison of multiple classification methods for diagnosis of Parkinson disease. Expert Syst. Appl. 2010, 37, 1568–1572. [Google Scholar] [CrossRef]
- Wright, H.; Postema, M.; Aharonson, V. Towards a voice-based severity scale for Parkinson’s disease monitoring. Curr. Dir. Biomed. Eng. 2024, 10, 2024–2168. [Google Scholar] [CrossRef]
- Hossain, M.A.; Amenta, F. Machine Learning-Based Classification of Parkinson’s Disease Patients Using Speech Biomarkers. J. Park. Dis. 2024, 14, 95–109. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Features | Number of Features | Description |
|---|---|---|
| Jitter | 2 | Measures variability in vocal fold vibration frequency |
| Shimmer | 5 | Measures amplitude fluctuations in vocal cycles |
| NHR | 1 | Noise-to-harmonics ratio |
| HNR | 1 | Harmonics-to-noise ratio |
| Pitch | 1 | Fundamental frequency of vocal fold vibration |
| Intensity | 1 | Overall loudness of the voice |
| Formant | 4 | Resonant frequencies of the vocal tract |
| CPPS | 1 | Measures prominence of spectral peaks |
| PPE | 1 | Measures irregularity in speech pitch to distinguish between natural variations and pathological speech |
| RPDE | 1 | Measures regularity of voice signal |
| MFCC | 12 | Represents spectral envelope of the signal, useful for voice quality analysis |
| Metrics | Formula | Description |
|---|---|---|
| Accuracy | Proportion of correctly classified instances | |
| Recall | Proportion of actual positives correctly identified | |
| Precision | Proportion of predicted positives that are actually positive | |
| F1-Score | Harmonic means precision and recall | |
| ROC-AUC | - | Area under the receiver operating characteristic curve. |
| MSE | Mean squared error between predicted and actual values |
| Resource | Details |
|---|---|
| CPU | i5 Gen6 |
| RAM | 12.67 GB |
| GPU | 4 GB Tesla T4, 15,360 MiB |
| Software | Python 3.10.12 and 3.12.8 |
| Algorithm | Accuracy | Recall | Precision | F1-Score | ROC-AUC |
|---|---|---|---|---|---|
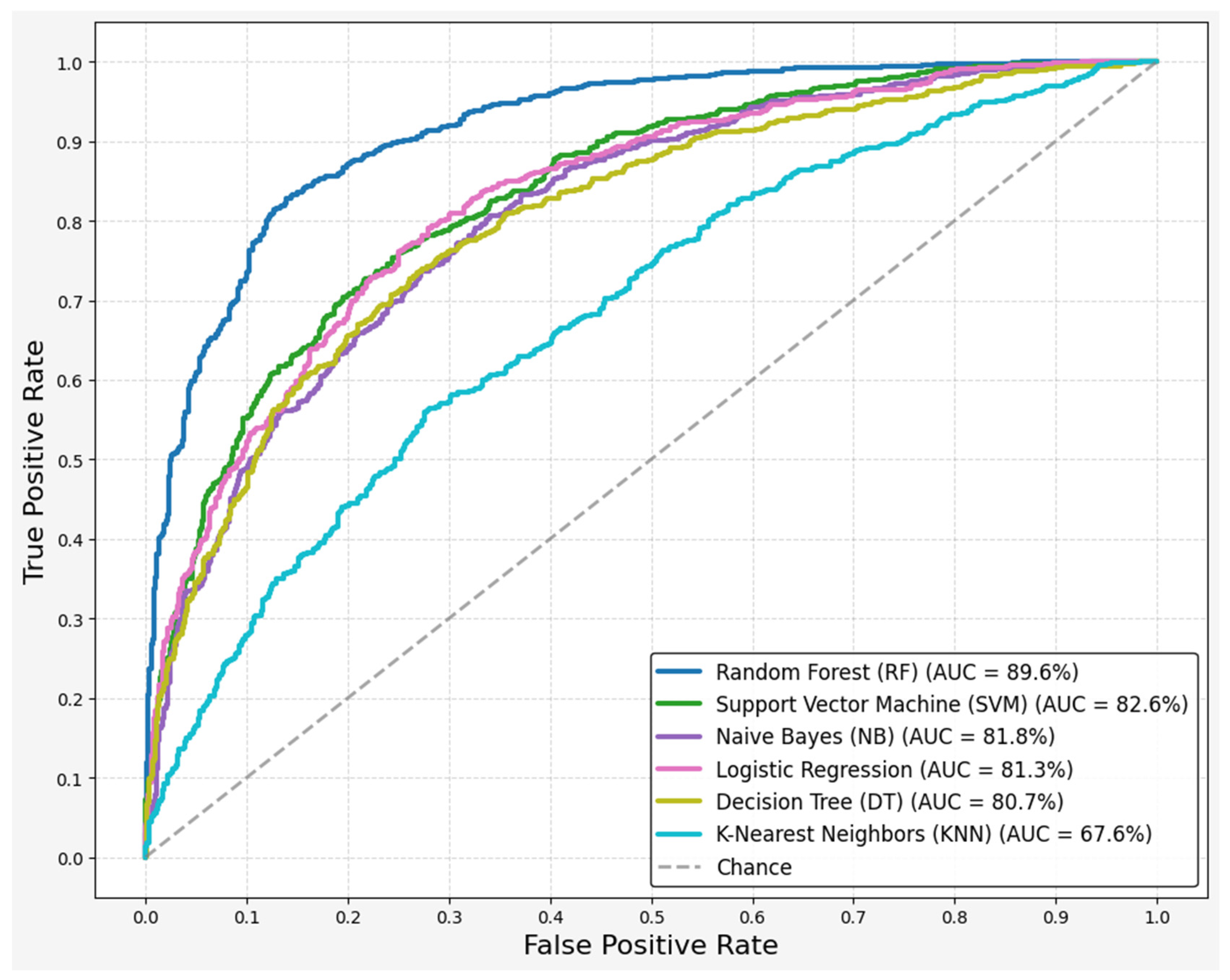
| Random Forest (RF) | 0.8272 ± 0.10 | 0.7500 ± 0.15 | 0.8257 ± 0.14 | 0.8251 ± 0.1 | 0.8965 ± 0.07 |
| Logistic Regression (LR) | 0.7529 ± 0.06 | 0.7750 ± 0.09 | 0.7467 ± 0.12 | 0.7487 ± 0.07 | 0.8132 ± 0.09 |
| Support Vector Machine (SVM) | 0.7529 ± 0.06 | 0.7750 ± 0.04 | 0.7529 ± 0.09 | 0.7487 ± 0.04 | 0.8263 ± 0.09 |
| Naive Bayes (NB) | 0.7397 ± 0.15 | 0.8250 ± 0.18 | 0.7312 ± 0.16 | 0.7578 ± 0.14 | 0.8181 ± 0.13 |
| Decision Tree (DT) | 0.6801 ± 0.16 | 0.7750 ± 0.09 | 0.7871 ± 0.16 | 0.6589 ± 0.09 | 0.8071 ± 0.11 |
| K-Nearest Neighbors (KNN) | 0.6301 ± 0.1 | 0.7000 ± 0.15 | 0.6222 ± 0.11 | 0.6493 ± 0.09 | 0.6760 ± 0.06 |
| Study | Featured Used | Machine Learning Models | Best Performance |
|---|---|---|---|
| Our research | Long-term features, short-term features, PPE, RPDE | RF, SVM, NB | 89.65% (ROC-AUC), 82.63% (ROC-AUC) 82.50% (Recall) |
| Fred Prior [41] | Long term and short-term features | RF, LR, CNN | 78% (AUC), 78% (AUC), 97% (AUC) |
| Max little [26] | Long-term features, non-standard measurement | SVM | 90.4% (accuracy) |
| Wroge [38] | GeMaps features | Gradient Boosted Decision Tree | 82% (accuracy), 65% (recall) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rashidi, M.; Arima, S.; Stetco, A.C.; Coppola, C.; Musarò, D.; Greco, M.; Damato, M.; My, F.; Lupo, A.; Lorenzo, M.; et al. Prediction of Parkinson Disease Using Long-Term, Short-Term Acoustic Features Based on Machine Learning. Brain Sci. 2025, 15, 739. https://doi.org/10.3390/brainsci15070739
Rashidi M, Arima S, Stetco AC, Coppola C, Musarò D, Greco M, Damato M, My F, Lupo A, Lorenzo M, et al. Prediction of Parkinson Disease Using Long-Term, Short-Term Acoustic Features Based on Machine Learning. Brain Sciences. 2025; 15(7):739. https://doi.org/10.3390/brainsci15070739
Chicago/Turabian StyleRashidi, Mehdi, Serena Arima, Andrea Claudio Stetco, Chiara Coppola, Debora Musarò, Marco Greco, Marina Damato, Filomena My, Angela Lupo, Marta Lorenzo, and et al. 2025. "Prediction of Parkinson Disease Using Long-Term, Short-Term Acoustic Features Based on Machine Learning" Brain Sciences 15, no. 7: 739. https://doi.org/10.3390/brainsci15070739
APA StyleRashidi, M., Arima, S., Stetco, A. C., Coppola, C., Musarò, D., Greco, M., Damato, M., My, F., Lupo, A., Lorenzo, M., Danieli, A., Maruccio, G., Argentiero, A., Buccoliero, A., Donzella, M. D., & Maffia, M. (2025). Prediction of Parkinson Disease Using Long-Term, Short-Term Acoustic Features Based on Machine Learning. Brain Sciences, 15(7), 739. https://doi.org/10.3390/brainsci15070739