
DysDiTect: Dyslexia Identification Using CNN-Positional-LSTM-Attention Modeling with Chinese Dictation Task


Abstract
1. Introduction
1.1. Technological Advancement of Chinese Handwriting and Performance Evaluation
1.2. Transforming Dyslexia Identification: Transitioning from Human-Delivered Behavioral Tests to Machine Learning-Assisted Automatic Detection
1.3. Predictions and Identification of Dyslexia Using Handwriting Features with Machine Learning Techniques
2. Materials and Methods
2.1. Participants
2.2. Chinese Word Dictation Task
2.3. Data Classification
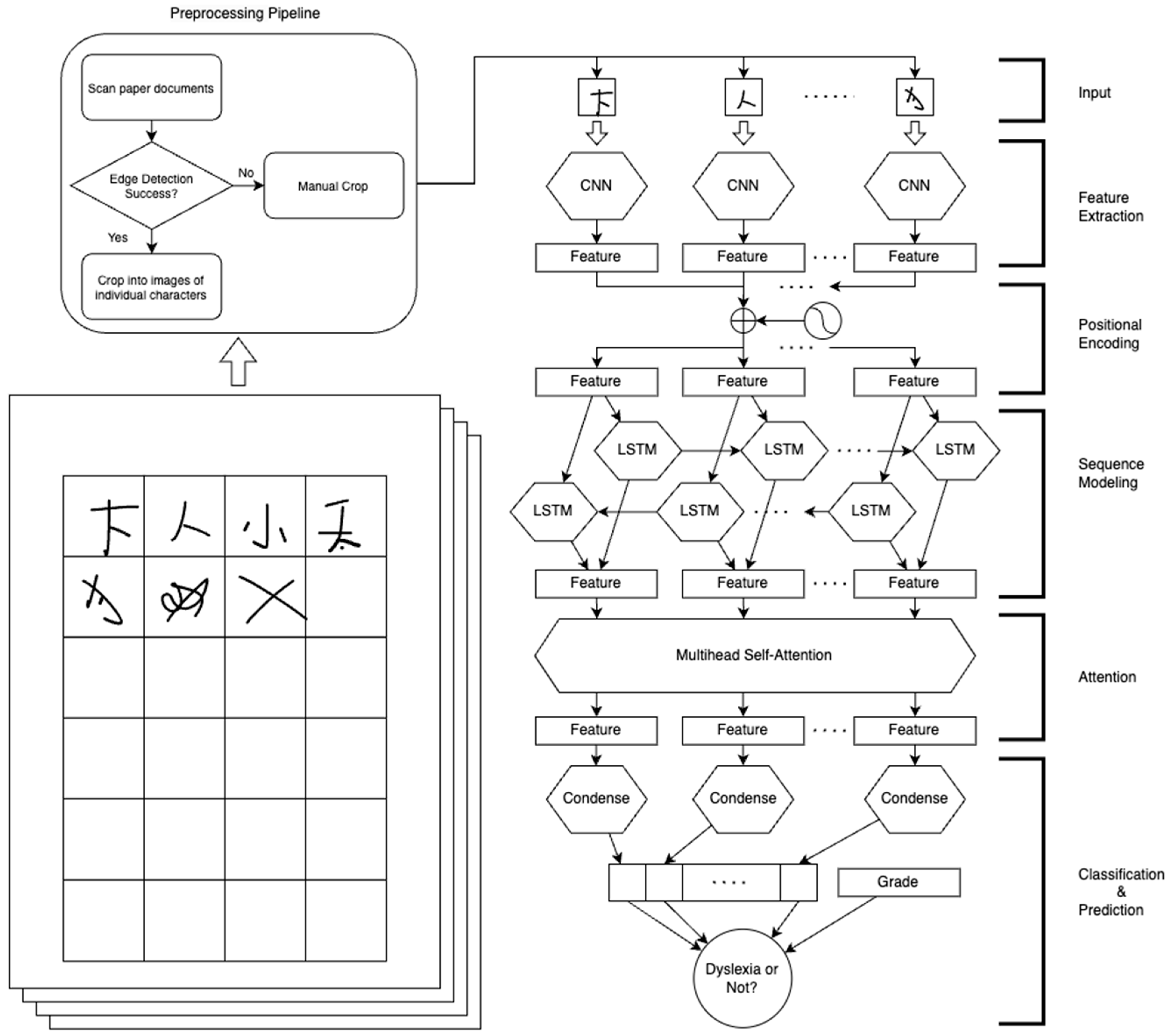
2.4. Data Preprocessing
2.5. Model Architecture
2.5.1. CNN Module with Positional Encoding
2.5.2. Bi-LSTM Module
2.5.3. Multi-Head Self-Attention Module
2.5.4. Classification and Prediction with Grade Information
2.6. Model Training
3. Results
3.1. Pilot Study
3.2. Ablation Study
3.2.1. Positional Encoding with Grade Information
3.2.2. LSTM and Attention Modules
3.3. Attention Map
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Snowling, M.J.; Hulme, C.; Nation, K. Defining and Understanding Dyslexia: Past, Present and Future. Oxf. Rev. Educ. 2020, 46, 501–513. [Google Scholar] [CrossRef] [PubMed]
- McBride, C.; Wang, Y.; Cheang, L.M.-L. Dyslexia in Chinese. Curr. Dev. Disord. Rep. 2018, 5, 217–225. [Google Scholar] [CrossRef]
- Lee, S.M.K.; Tong, X. Spelling in Developmental Dyslexia in Chinese: Evidence of Deficits in Statistical Learning and over-Reliance on Phonology. Cogn. Neuropsychol. 2020, 37, 494–510. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Rao, N.; Tse, S.K. Adapting Western Pedagogies for Chinese Literacy Instruction: Case Studies of Hong Kong, Shenzhen, and Singapore Preschools. Early Educ. Dev. 2012, 23, 603–621. [Google Scholar] [CrossRef]
- McBride-Chang, C.; Chung, K.K.H.; Tong, X. Copying Skills in Relation to Word Reading and Writing in Chinese Children with and without Dyslexia. J. Exp. Child Psychol. 2011, 110, 422–433. [Google Scholar] [CrossRef] [PubMed]
- Lam, S.S.T.; Au, R.K.C.; Leung, H.W.H.; Li-Tsang, C.W.P. Chinese Handwriting Performance of Primary School Children with Dyslexia. Res. Dev. Disabil. 2011, 32, 1745–1756. [Google Scholar] [CrossRef] [PubMed]
- Cheng-Lai, A.; Li-Tsang, C.W.P.; Chan, A.H.L.; Lo, A.G.W. Writing to Dictation and Handwriting Performance among Chinese Children with Dyslexia: Relationships with Orthographic Knowledge and Perceptual-Motor Skills. Res. Dev. Disabil. 2013, 34, 3372–3383. [Google Scholar] [CrossRef]
- Yang, Y.; Zuo, Z.; Tam, F.; Graham, S.J.; Li, J.; Ji, Y.; Meng, Z.; Gu, C.; Bi, H.Y.; Ou, J.; et al. The Brain Basis of Handwriting Deficits in Chinese Children with Developmental Dyslexia. Dev. Sci. 2022, 25, e13161. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Li, J.; Bi, H.Y.; Xu, M.; Yang, Y. Disruption of Functional Brain Networks Underlies the Handwriting Deficit in Children with Developmental Dyslexia. Front. Neurosci. 2022, 16, 919440. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Bengio, Y.; Liu, C.L. Online and Offline Handwritten Chinese Character Recognition: A Comprehensive Study and New Benchmark. Pattern Recognit. 2017, 61, 348–360. [Google Scholar] [CrossRef]
- An, W. Quality Evaluation and Key Defects Correction for Handwritten Chinese Characters. In Proceedings of the 2019 6th International Conference on Systems and Informatics (ICSAI), Shanghai, China, 2–4 November 2019; pp. 752–756. [Google Scholar]
- Hu, Z.H.; Xu, Y.; Huang, L.S.; Leung, H.W.H. A Chinese Handwriting Education System with Automatic Error Detection. J. Softw. 2009, 4, 101–107. [Google Scholar] [CrossRef]
- Wu, J.; Han, Q.; Li, Y. Study on Correctness Judgement of Handwritten Chinese Characters Based on Feature Matrix for Similarity Matching. In Proceedings of the 2019 Twelfth International Conference on Ubi-Media Computing (Ubi-Media), Bali, Indonesia, 5–8 August 2019; pp. 85–90. [Google Scholar]
- Bai, X.; Qiao, X. A Method of Chinese Character Shape Representation and Its Application in the Error Correction for Normative Handwritten Chinese Characters. In Proceedings of the 2017 10th International Conference on Ubi-media Computing and Workshops (Ubi-Media), Pattaya, Thailand, 1–4 August 2017; pp. 1–7. [Google Scholar]
- Li, Y.; Du, J.; Zhang, J.; Wu, C. A Tree-Structure Analysis Network on Handwritten Chinese Character Error Correction. IEEE Trans. Multimed. 2022, 25, 3615–3627. [Google Scholar] [CrossRef]
- Hu, P.; Ma, J.; Zhang, Z.; Du, J.; Zhang, J. Count, Decode and Fetch: A New Approach to Handwritten Chinese Character Error Correction. arXiv 2023, arXiv:2307.16253. [Google Scholar]
- Zhong, S.; Song, S.; Tang, T.; Nie, F.; Zhou, X.; Zhao, Y.; Zhao, Y.; Sin, K.F.; Chan, S.H.G. DYPA: A Machine Learning Dyslexia Prescreening Mobile Application for Chinese Children. In Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies; Association for Computing Machinery: New York, NY, USA, 2023; Volume 7. [Google Scholar]
- Ho, C.S.H.; Chan, D.W.O.; Chung, K.K.H.; Tsang, S.M.; Lee, S.H.; Cheng, W.Y.R. The Hong Kong Test of Specific Learning Difficulties in Reading and Writing for Primary School Students, 2nd ed.; [HKT-P(II)]; Hong Kong Specific Learning Difficulties Research Team: Hong Kong, 2007. [Google Scholar]
- Sanfilippo, J.; Ness, M.; Petscher, Y.; Rappaport, L.; Zuckerman, B.; Gaab, N. Reintroducing Dyslexia: Early Identification and Implications for Pediatric Practice. Pediatrics 2020, 146, e20193046. [Google Scholar] [CrossRef] [PubMed]
- Usman, O.L.; Muniyandi, R.C.; Omar, K.; Mohamad, M. Advance Machine Learning Methods for Dyslexia Biomarker Detection: A Review of Implementation Details and Challenges. IEEE Access 2021, 9, 36879–36897. [Google Scholar] [CrossRef]
- Kaisar, S. Developmental Dyslexia Detection Using Machine Learning Techniques: A Survey. ICT Express 2020, 6, 181–184. [Google Scholar] [CrossRef]
- Alqahtani, N.D.; Alzahrani, B.; Ramzan, M.S. Deep Learning Applications for Dyslexia Prediction. Appl. Sci. 2023, 13, 2804. [Google Scholar] [CrossRef]
- Rosli, M.S.A.B.; Isa, I.S.; Ramlan, S.A.; Sulaiman, S.N.; Maruzuki, M.I.F. Development of CNN Transfer Learning for Dyslexia Handwriting Recognition. In Proceedings of the 11th IEEE International Conference on Control System, Computing and Engineering (ICCSCE), Penang, Malaysia, 27–28 August 2021; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2021; pp. 194–199. [Google Scholar]
- Spoon, K.; Crandall, D.; Siek, K. Towards Detecting Dyslexia in Children’s Handwriting Using Neural Networks. In Proceedings of the International Conference on Machine Learning AI for Social Good Workshop, Long Beach, CA, USA, 15 June 2019; pp. 1–5. [Google Scholar]
- Spoon, K.; Siek, K.; Crandall, D.; Fillmore, M. Can We (and Should We) Use AI to Detect Dyslexia in Children’s Handwriting? In Proceedings of the Artificial Intelligence for Social Good (NeurIPS 2019), Vancouver, BC, Canada, 13 December 2019; pp. 1–6. [Google Scholar]
- Isa, I.S.; Syazwani Rahimi, W.N.; Ramlan, S.A.; Sulaiman, S.N. Automated Detection of Dyslexia Symptom Based on Handwriting Image for Primary School Children. Procedia Comput. Sci. 2019, 163, 440–449. [Google Scholar] [CrossRef]
- Danna, J.; Puyjarinet, F.; Jolly, C. Tools and Methods for Diagnosing Developmental Dysgraphia in the Digital Age: A State of the Art. Children 2023, 10, 1925. [Google Scholar] [CrossRef]
- Wu, Z.; Lin, T.; Li, M. Automated Detection of Children at Risk of Chinese Handwriting Difficulties Using Handwriting Process Information: An Exploratory Study. IEICE Trans. Inf. Syst. 2019, 102, 147–155. [Google Scholar] [CrossRef]
- Lee, S.M.K.; Liu, H.W.; Tong, S.X. Identifying Chinese Children with Dyslexia Using Machine Learning with Character Dictation. Sci. Stud. Read. 2023, 27, 82–100. [Google Scholar] [CrossRef]
- Sultana, F.; Sufian, A.; Dutta, P. Advancements in Image Classification Using Convolutional Neural Network. In Proceedings of the 2018 Fourth International Conference on Research in Computational Intelligence and Communication Networks (ICRCICN), Kolkata, India, 22–23 November 2018; pp. 122–129. [Google Scholar]
- Purwono, P.; Ma’arif, A.; Rahmaniar, W.; Fathurrahman, H.I.K.; Frisky, A.Z.K.; ul Haq, Q.M. Understanding of Convolutional Neural Network (CNN): A Review. Int. J. Robot. Control Syst. 2022, 2, 739–748. [Google Scholar] [CrossRef]
- Jogin, M.; Madhulika, M.S.; Divya, G.D.; Meghana, R.K.; Apoorva, S. Feature Extraction Using Convolution Neural Networks (CNN) and Deep Learning. In Proceedings of the 2018 3rd IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT), Bangalore, India, 18–19 May 2018; pp. 2319–2323. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; ACM: New York, NY, USA, 2017; pp. 1–11. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A Review of Recurrent Neural Networks: LSTM Cells and Network Architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef] [PubMed]
- Weerakody, P.B.; Wong, K.W.; Wang, G. Policy Gradient Empowered LSTM with Dynamic Skips for Irregular Time Series Data. Appl. Soft Comput. 2023, 142, 110314. [Google Scholar] [CrossRef]
- Niu, Z.; Zhong, G.; Yu, H. A Review on the Attention Mechanism of Deep Learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- You, K.; Kou, Z.; Long, M.; Wang, J. Co-Tuning for Transfer Learning. Adv. Neural Inf. Process. Syst. 2020, 33, 17236–17246. [Google Scholar]
- Han, X.; Zhang, Z.; Ding, N.; Gu, Y.; Liu, X.; Huo, Y.; Qiu, J.; Yao, Y.; Zhang, A.; Zhang, L. Pre-Trained Models: Past, Present and Future. AI Open 2021, 2, 225–250. [Google Scholar] [CrossRef]
- Isa, I.S.; Zahir, M.A.; Ramlan, S.A.; Li-chih, W.; Sulaiman, S.N. CNN Comparisons Models on Dyslexia Handwriting Classification. ESTEEM Acad. J. 2021, 17, 12–25. [Google Scholar]
- Jasira, K.T.; Laila, V.; Jemsheer Ahmed, P. DyslexiScan: A Dyslexia Detection Method from Handwriting Using CNN LSTM Model. In Proceedings of the 2023 International Conference on Innovations in Engineering and Technology (ICIET), Muvattupuzha, India, 13–14 July 2023; pp. 1–6. [Google Scholar]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.C.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R.; et al. Searching for MobileNetV3. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Yogarajah, P. Deep Learning Approach to Automated Detection of Dyslexia-Dysgraphia. In Proceedings of the 25th IEEE International Conference on Pattern Recognition, Milan, Italy, 10–15 January 2020; pp. 1–12. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Grade | TD | DD | t | |||||
|---|---|---|---|---|---|---|---|---|
| N | M | SD | N | M | SD | |||
| 2 | 165 | 42.9 | 15.4 | 162 | 20.9 | 12.4 | 14.20 | *** |
| 3 | 111 | 53.1 | 16.7 | 101 | 32.6 | 16.2 | 9.06 | *** |
| 4 | 102 | 68.1 | 13.6 | 54 | 38.3 | 16.5 | 11.40 | *** |
| 5 | 56 | 76.3 | 13.0 | 62 | 48.9 | 18.9 | 9.26 | *** |
| 6 | 31 | 83.0 | 10.3 | 25 | 56.3 | 17.4 | 6.76 | *** |
| DysDiTect+ | Confusion Matrix | Overall (N = 107) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| P | L | A | G | G23 (N = 62) | G456 (N = 45) | Accuracy | Sensitivity | Specificity | AUC | ||
| ✓ | ✓ | ✓ | ✓ | 25 | 10 | 11 | 2 | 0.776 | 0.750 | 0.797 | 0.883 |
| 3 | 24 | 9 | 23 | ||||||||
| ✓ | ✓ | ✓ | 24 | 6 | 14 | 2 | 0.832 | 0.792 | 0.864 | 0.912 | |
| 4 | 28 | 6 | 23 | ||||||||
| ✓ | ✓ | ✓ | 17 | 4 | 8 | 0 | 0.748 | 0.521 | 0.932 | 0.823 | |
| 11 | 30 | 12 | 25 | ||||||||
| ✓ | ✓ | 23 | 7 | 11 | 1 | 0.794 | 0.708 | 0.864 | 0.888 | ||
| 5 | 27 | 9 | 24 | ||||||||
| ✓ | ✓ | ✓ | 26 | 4 | 14 | 4 | 0.850 | 0.833 | 0.864 | 0.898 | |
| 2 | 30 | 6 | 21 | ||||||||
| ✓ | ✓ | 22 | 8 | 7 | 1 | 0.738 | 0.604 | 0.847 | 0.805 | ||
| 6 | 26 | 13 | 24 | ||||||||
| ✓ | ✓ | 15 | 3 | 5 | 0 | 0.710 | 0.417 | 0.949 | 0.820 | ||
| 13 | 31 | 15 | 25 | ||||||||
| ✓ | 21 | 5 | 10 | 6 | 0.738 | 0.646 | 0.814 | 0.769 | |||
| 7 | 29 | 10 | 19 | ||||||||
| ✓ | ✓ | ✓ | 24 | 6 | 14 | 2 | 0.832 | 0.792 | 0.864 | 0.922 | |
| 4 | 28 | 6 | 23 | ||||||||
| ✓ | ✓ | 22 | 4 | 13 | 2 | 0.822 | 0.729 | 0.898 | 0.901 | ||
| 6 | 30 | 7 | 23 | ||||||||
| ✓ | ✓ | 25 | 9 | 9 | 1 | 0.776 | 0.708 | 0.831 | 0.833 | ||
| 3 | 25 | 11 | 24 | ||||||||
| ✓ | 22 | 4 | 9 | 0 | 0.804 | 0.646 | 0.932 | 0.855 | |||
| 6 | 30 | 11 | 25 | ||||||||
| ✓ | ✓ | 25 | 9 | 7 | 3 | 0.738 | 0.667 | 0.797 | 0.832 | ||
| 3 | 25 | 13 | 22 | ||||||||
| ✓ | 25 | 11 | 11 | 2 | 0.766 | 0.750 | 0.780 | 0.823 | |||
| 3 | 23 | 9 | 23 | ||||||||
| ✓ | 24 | 10 | 10 | 3 | 0.748 | 0.708 | 0.780 | 0.809 | |||
| 4 | 24 | 10 | 22 | ||||||||
| 21 | 9 | 10 | 2 | 0.738 | 0.646 | 0.814 | 0.858 | ||||
| 7 | 25 | 10 | 23 | ||||||||
| Group | Response | Entropy | ||
|---|---|---|---|---|
| K | M | SD | ||
| TD | Correct | 3014 | 6.53 | 0.078 |
| Wrong | 1882 | 6.49 | 0.101 | |
| DD | Correct | 1235 | 6.51 | 0.098 |
| Wrong | 2701 | 6.48 | 0.090 |
| Previous Studies | Language | Task | Sample Size | Dataset Size | Acc | Sen | Spe | AUC | ||
|---|---|---|---|---|---|---|---|---|---|---|
| DD | TD | |||||||||
| Spoon et al. [24] | English | Patches from writing | 11 | 77 | 25,650 | 0.557 a | / | / | / | |
| Spoon et al. [25] | 22 | 78 | / | 0.776 a | / | / | / | |||
| Isa et al. [26] | English/ Malaysian | 4× | Letters + 4 × Digit | 30 | / | 24 | 0.708 a | / | / | / |
| Isa et al. [40] | Letters | / | / | 39,897 | 0.870 a,b | / | / | / | ||
| Rosli et al. [23] | / | / | 233,354 × 0.2 | 0.953 a,b | / | / | / | |||
| Yogarajah et al. [43] | Hindi | 14× | Words from writing | 54 | / | 267 | 0.861 a | / | / | / |
| Jasira et al. [41] | English | Letters | / | / | 86,115 × 0.1 | 0.950 a,b | / | / | / | |
| DYPA [17] | Chinese | Character copying + Behavioral tasks | 39 | 168 | / | 0.811 | 0.743 | 0.827 | 0.790 | |
| Lee et al. [29] | Chinese | 47× | Dictation | 454 | 561 | 47,705 | 0.800 | 0.749 | 0.841 | 0.857 |
| DysDiTect_PLA | 96× | 48 | 59 | 10,272 | 0.832 | 0.792 | 0.864 | 0.912 | ||
| DysDiTect_PAG | 0.850 | 0.833 | 0.864 | 0.900 | ||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.W.; Wang, S.; Tong, S.X. DysDiTect: Dyslexia Identification Using CNN-Positional-LSTM-Attention Modeling with Chinese Dictation Task. Brain Sci. 2024, 14, 444. https://doi.org/10.3390/brainsci14050444
Liu HW, Wang S, Tong SX. DysDiTect: Dyslexia Identification Using CNN-Positional-LSTM-Attention Modeling with Chinese Dictation Task. Brain Sciences. 2024; 14(5):444. https://doi.org/10.3390/brainsci14050444
Chicago/Turabian StyleLiu, Hey Wing, Shuo Wang, and Shelley Xiuli Tong. 2024. "DysDiTect: Dyslexia Identification Using CNN-Positional-LSTM-Attention Modeling with Chinese Dictation Task" Brain Sciences 14, no. 5: 444. https://doi.org/10.3390/brainsci14050444
APA StyleLiu, H. W., Wang, S., & Tong, S. X. (2024). DysDiTect: Dyslexia Identification Using CNN-Positional-LSTM-Attention Modeling with Chinese Dictation Task. Brain Sciences, 14(5), 444. https://doi.org/10.3390/brainsci14050444