


Tumor Diagnosis against Other Brain Diseases Using T2 MRI Brain Images and CNN Binary Classifier and DWT
 ,
, 
Abstract
1. Introduction
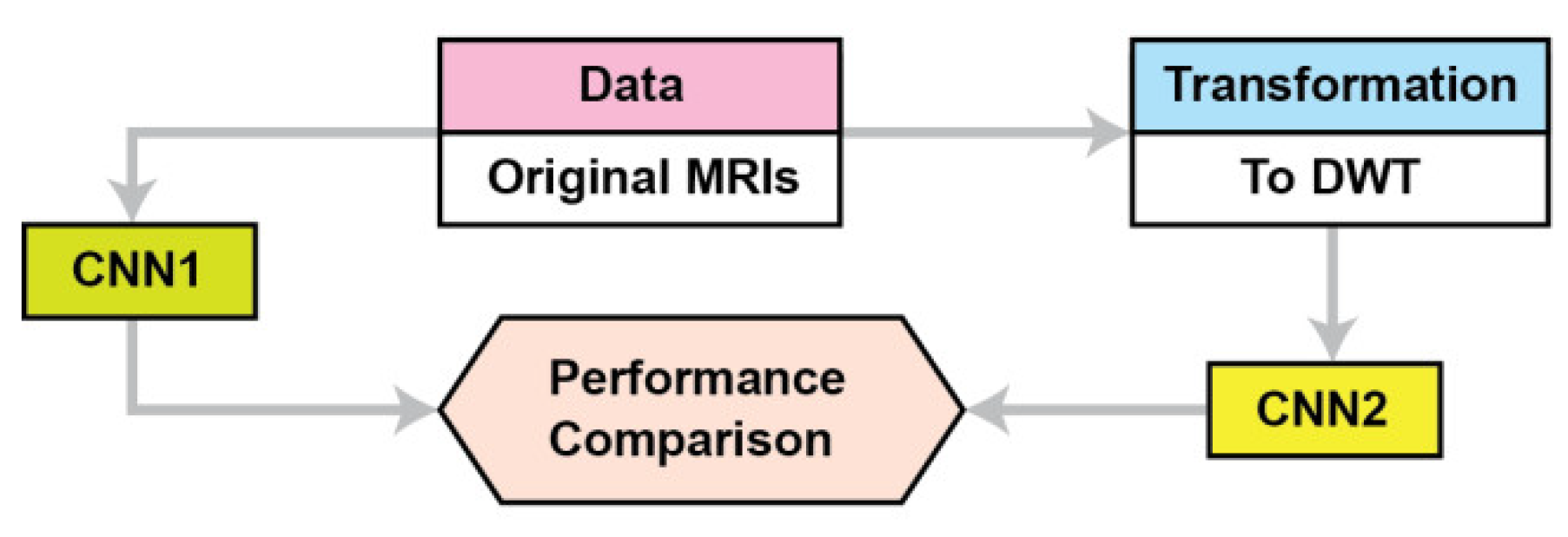
2. Materials and Methods
2.1. Data
Preprocessing
2.2. Data Prevalence
2.3. The CNN Base Model Architecture
CNN1 Model Architecture
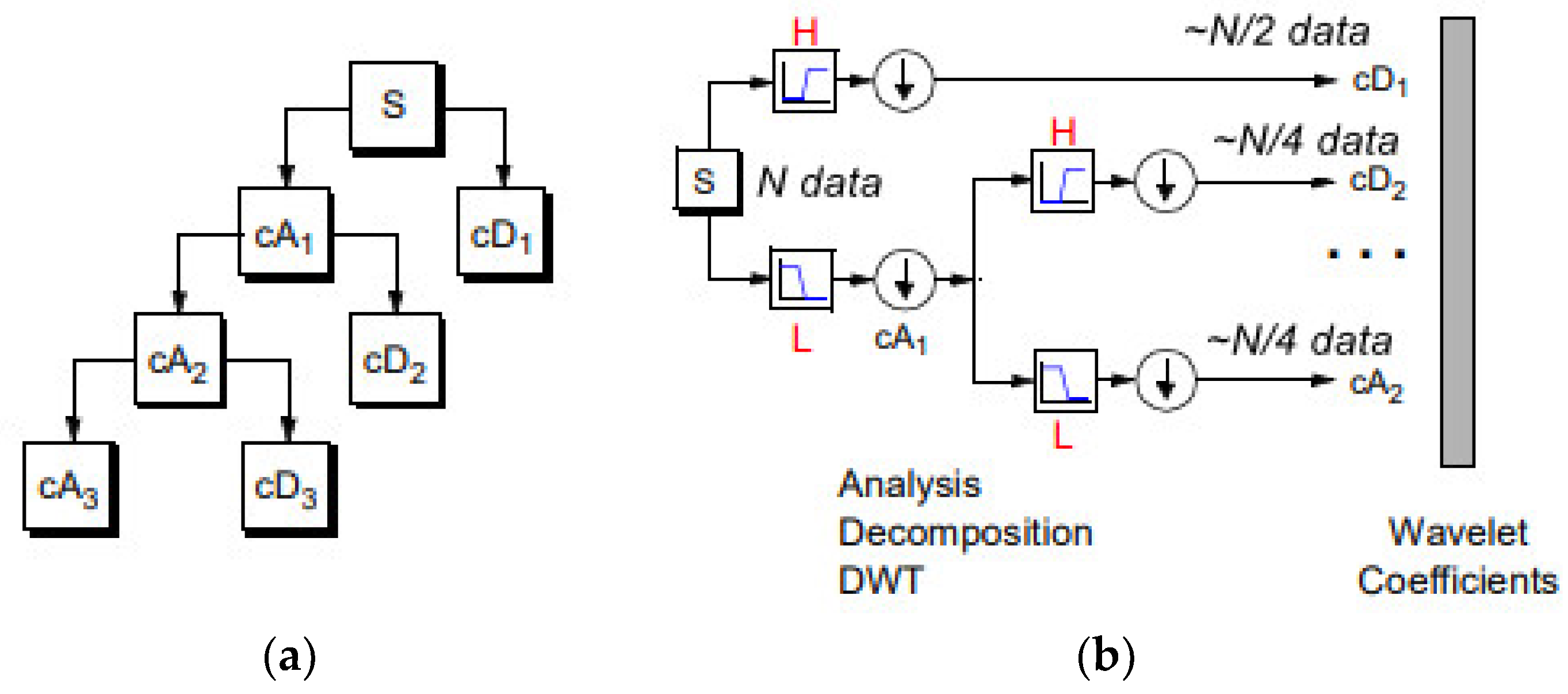
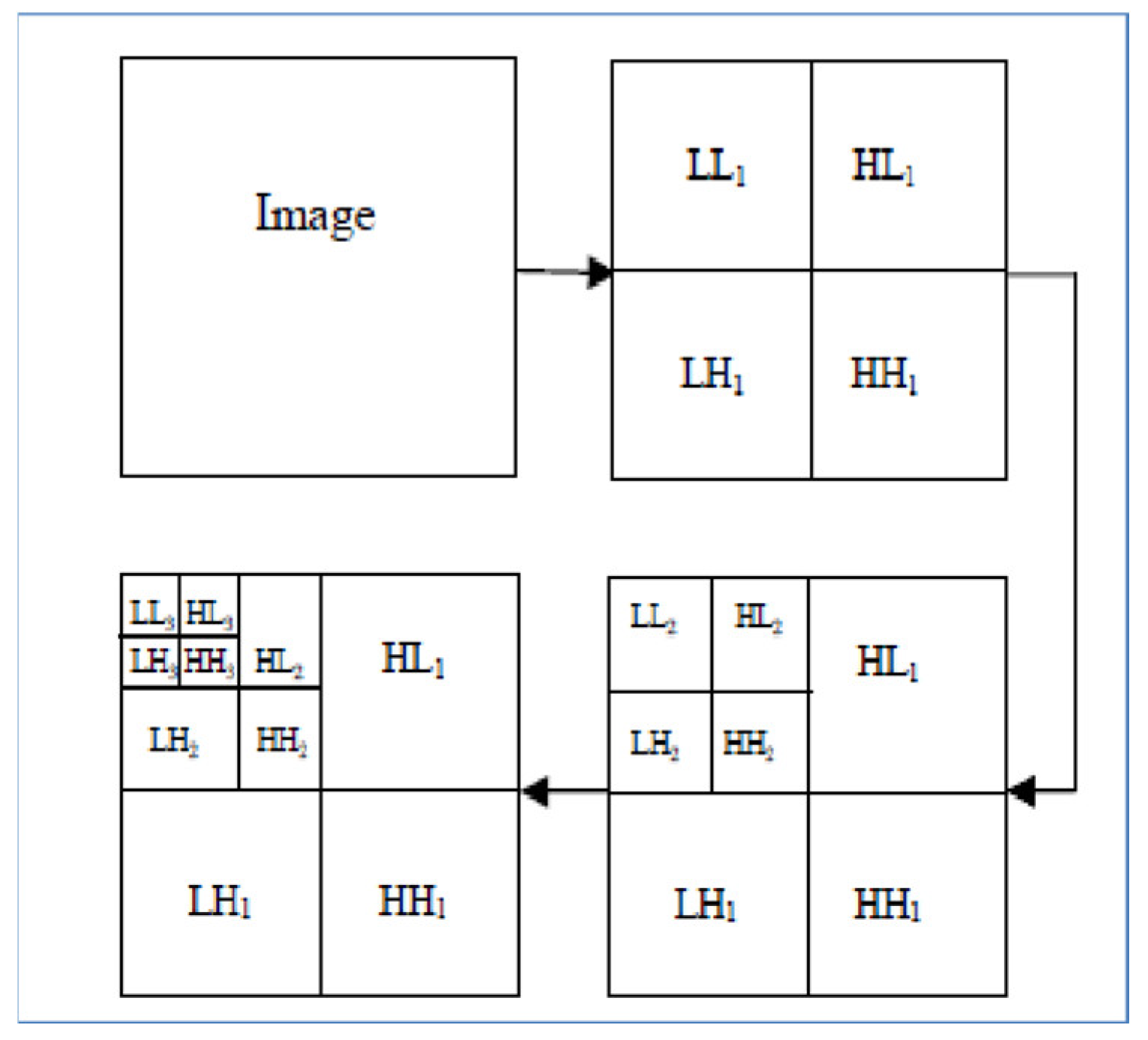
2.4. DWT and CNN MRI Feature Extraction
2.4.1. CNN2 Architecture
2.4.2. SVM Classifier Creation
3. Evaluation Measures
3.1. Performance Metrics of a Single ML Model
3.2. Comparing Performance of Two Binary ML Models
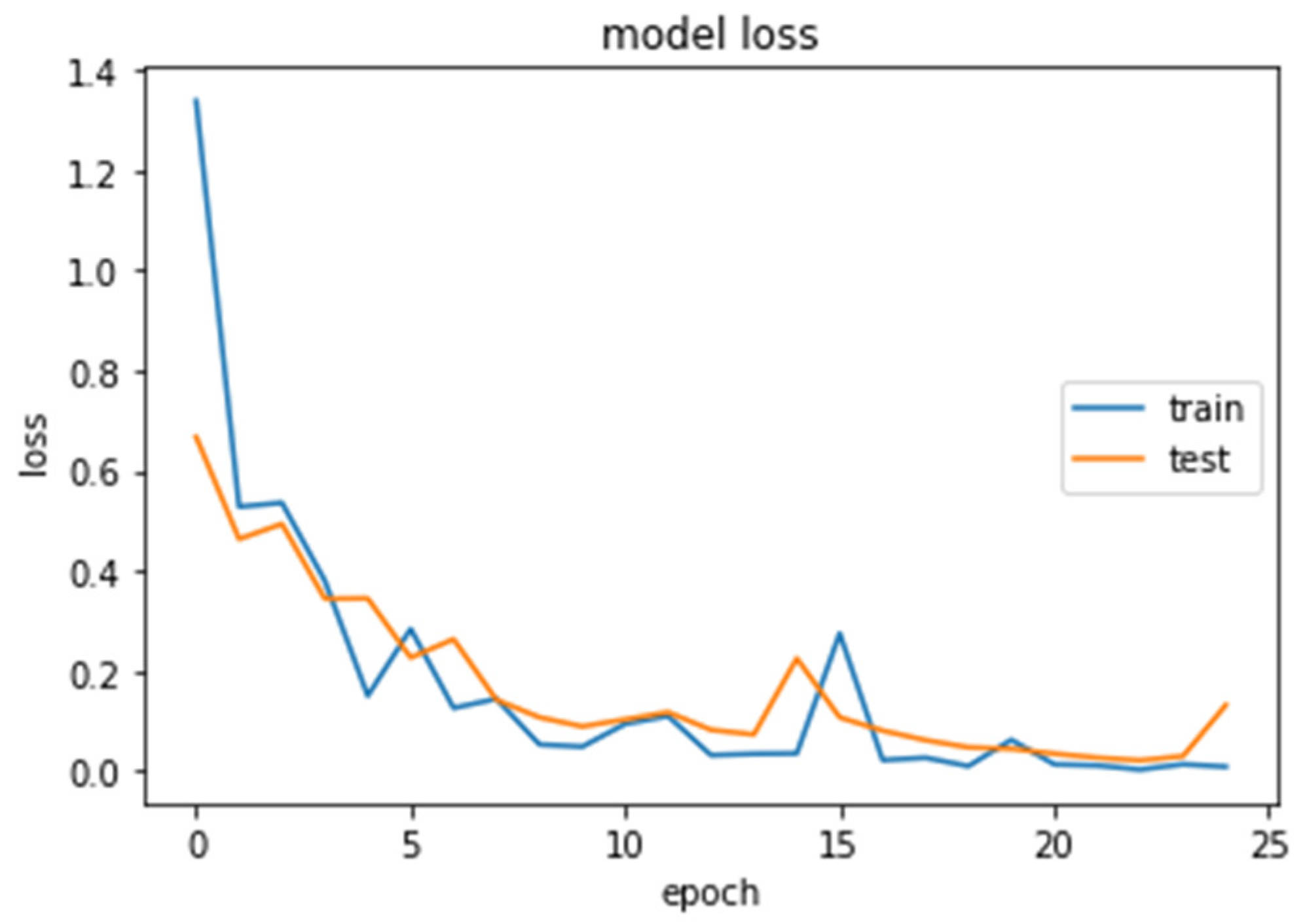
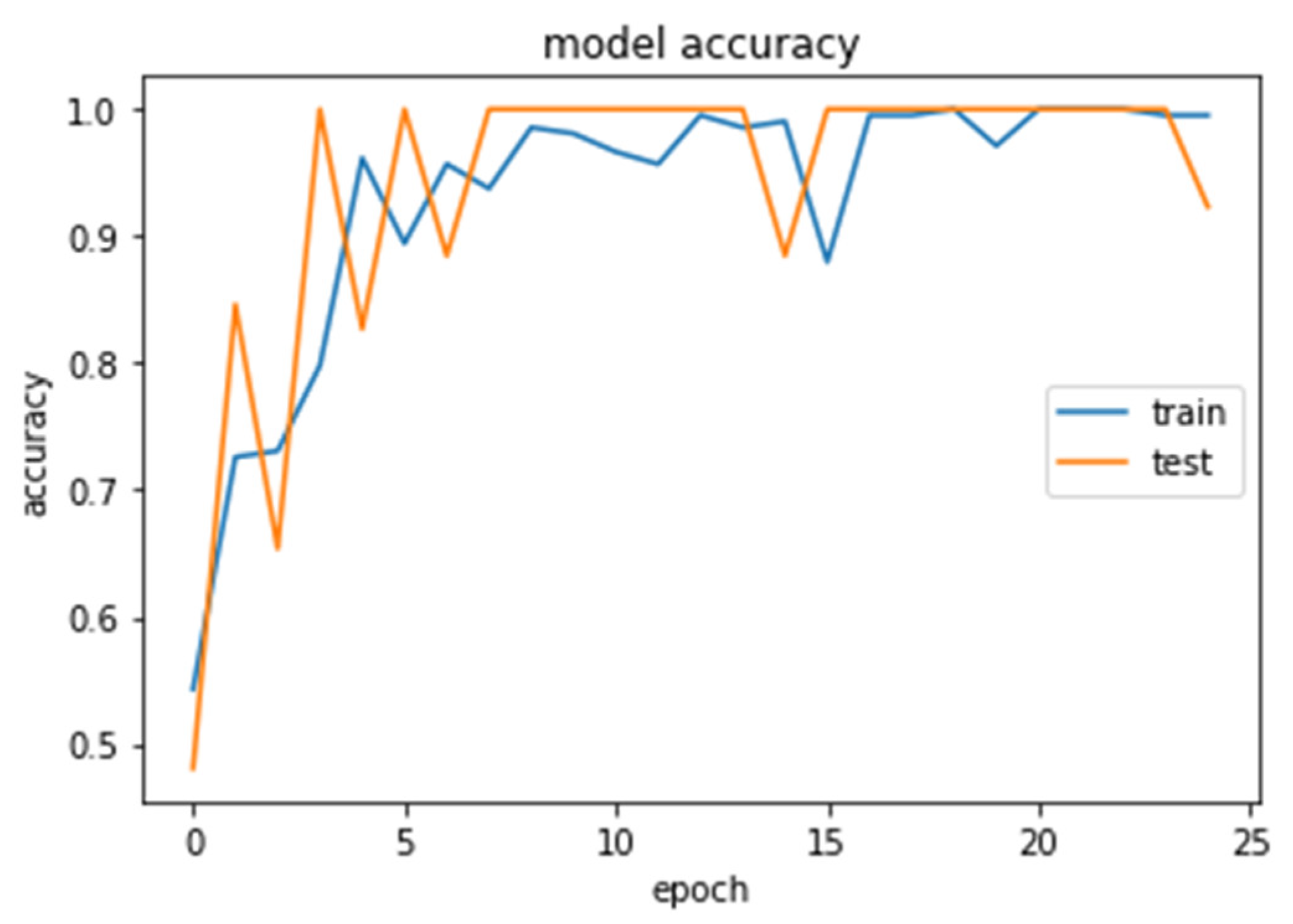
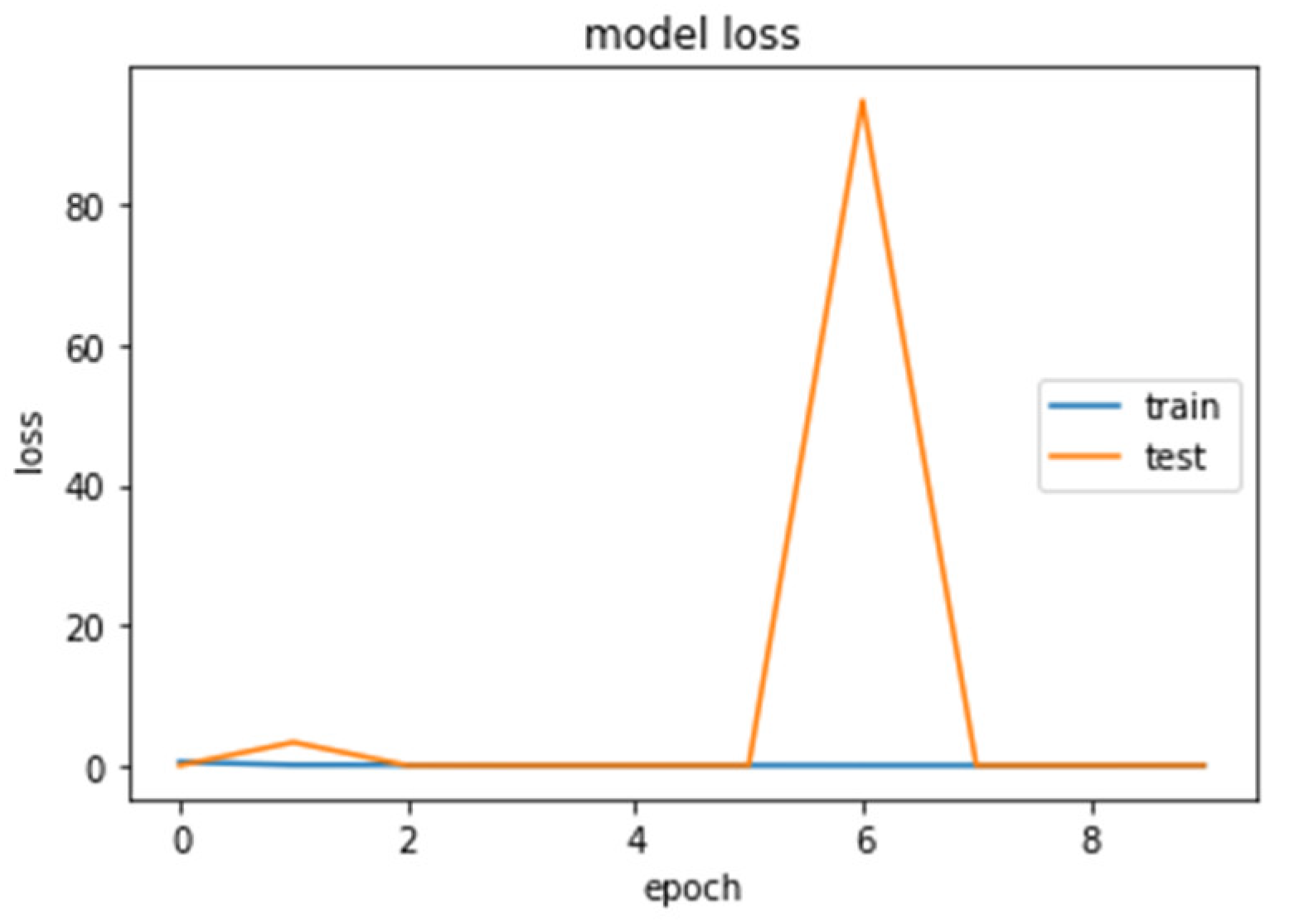
4. Results
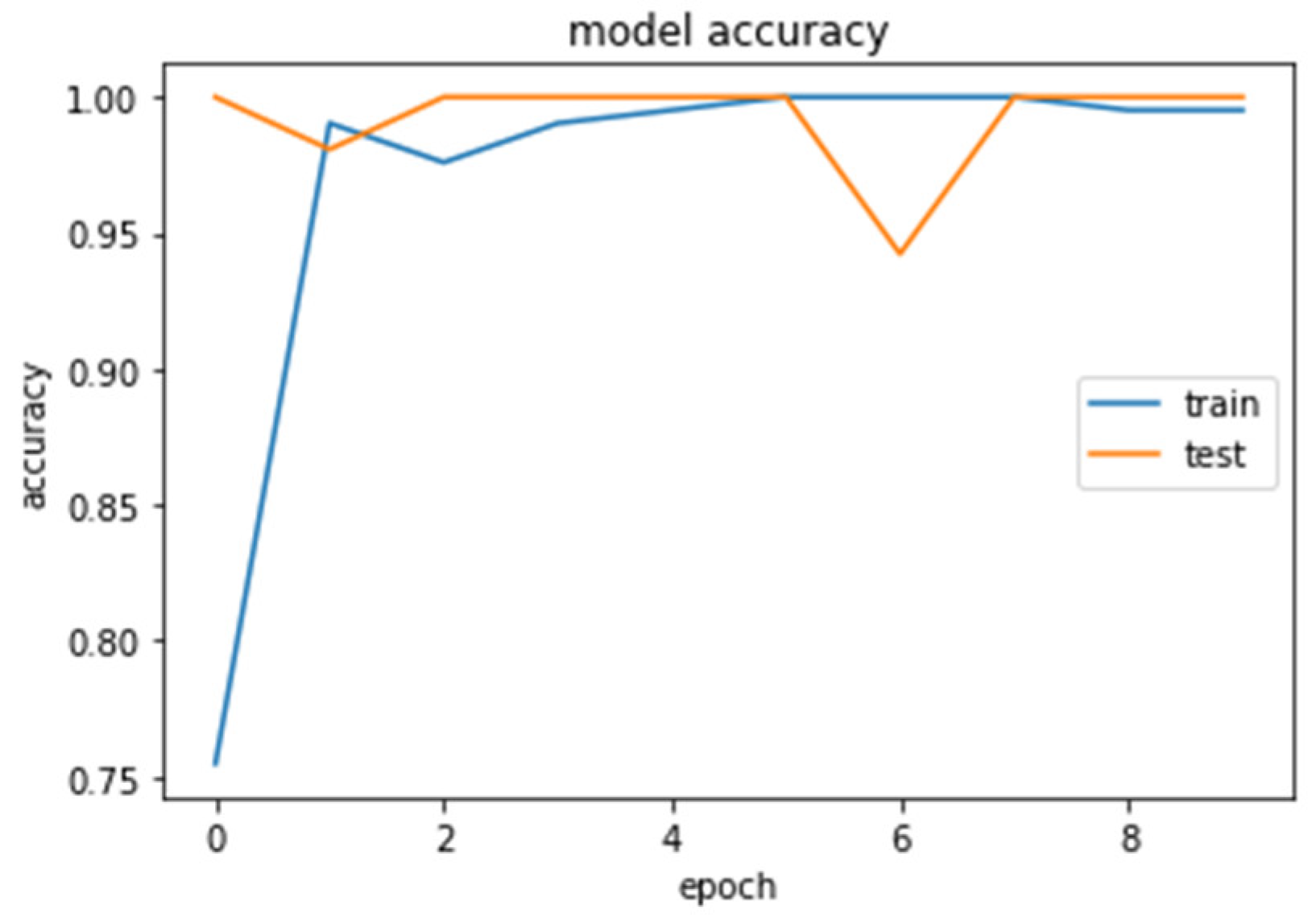
4.1. CNN2 Down-Sampling Utilizing DWT
4.2. CNN1 Down-Sampling Utilizing Average Pooling
4.3. SVM Classifier
4.4. Models Comparison
5. Discussion, Conclusions, and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Buetow, M.P.; Buetow, P.C.; Smirniotopoulos, J.G. Typical, atypical, and misleading features in meningioma. Radiogr. A Rev. Publ. Radiol. Soc. N. Am. 1991, 11, 1087–1106. [Google Scholar] [CrossRef] [PubMed]
- Choi, K.; Kim, D.Y.; Kim, H.J.; Hwang, G.; Kim, M.K.; Kim, H.G.; Paik, S. Imaging features and pathological correlation in mixed microcystic and angiomatous meningioma: A case report. J. Korean Soc. Radiol. 2022, 83, 951–957. [Google Scholar] [CrossRef] [PubMed]
- Watts, J.; Box, G.; Galvin, A.; Brotchie, P.; Trost, N.; Sutherland, T. Magnetic resonance imaging of meningiomas: A pictorial review. Insights Imaging 2014, 5, 113–122. [Google Scholar] [CrossRef] [PubMed]
- Reeves, R.A.; Parekh, M. Pituitary Gland Imaging. In StatPearls; StatPearls Publishing: Treasure Island, FL, USA, 2022. Available online: https://www.ncbi.nlm.nih.gov/books/NBK555989/ (accessed on 20 January 2022).
- Zinn, P.O.; Majadan, B.; Sathyan, P.; Singh, S.K.; Majumder, S.; Jolesz, F.A.; Colen, R.R. Radiogenomic mapping of edema/cellular invasion MRI-phenotypes in glioblastoma multiforme. PLoS ONE 2011, 6, e25451. [Google Scholar] [CrossRef]
- Minh Thong, P.; Minh Duc, N. The role of apparent diffusion coefficient in the differentiation between cerebellar medulloblastoma and brainstem glioma. Neurol Int. 2020, 12, 34–40. [Google Scholar] [CrossRef]
- Villanueva-Meyer, J.E.; Mabray, M.C.; Cha, S. Current clinical brain tumor imaging. Neurosurgery 2017, 81, 397–415. [Google Scholar] [CrossRef]
- Sartor, G. Artificial intelligence and human rights: Between law and ethics. Maastricht J. Eur. Comp. Law 2020, 27, 705–719. [Google Scholar] [CrossRef]
- Bakas, S.; Akbari, H.; Sotiras, A.; Bilello, M.; Rozycki, M.; Kirby, J.S.; Freymann, J.B.; Farahani, K.; Davatzikos, C. Advancing the cancer genome Atlas glioma MRI collections with expert segmentation labels and radiomic features. Nat. Sci. Data 2017, 4, 170117. [Google Scholar] [CrossRef] [PubMed]
- Bakas, S.; Reyes, M.; Jakab, A.; Bauer, S.; Rempfler, M.; Crimi, A.; Shinohara, R.T.; Berger, C.; Ha, S.M.; Rozycki, M.; et al. Identifying the best machine learning algorithms for brain tumor segmentation, progression assessment, and overall survival prediction in the BRATS challenge. arXiv 2018, arXiv:1811.02629. [Google Scholar]
- Bakas, S.; Akbari, H.; Sotiras, A.; Bilello, M.; Rozycki, M.; Kirby, J.; Freymann, J.; Farahani, K.; Davatzikos, C. Segmentation labels and radiomic features for the pre-operative scans of the TCGA-GBM collection. Cancer Imaging Arch. 2017. [Google Scholar]
- Bakas, S.; Akbari, H.; Sotiras, A.; Bilello, M.; Rozycki, M.; Kirby, J.; Freymann, J.; Farahani, K.; Davatzikos, C. Segmentation labels and radiomic features for the pre-operative scans of the TCGA-LGG collection. Cancer Imaging Arch. 2017. [Google Scholar]
- Bakas, S.; Zeng, K.; Sotiras, A.; Rathore, S.; Akbari, H.; Gaonkar, B.; Rozycki, M.; Pati, S.; Davatzikos, C. Segmentation of gliomas in multimodal magnetic resonance imaging volumes based on a hybrid generative-discriminative framework. In Proceedings of the Multimodal Brain Tumor Image Segmentation Challenge Held in Conjunction with MICCAI 2015 (MICCAI-BRATS 2015), Munich, Germany, 5–9 October 2015; pp. 5–12. [Google Scholar]
- Dvorak, P.; Menze, B. Structured prediction with convolutional neural networks for multimodal brain tumor segmentation. In Proceedings of the Multimodal Brain Tumor Image Segmentation Challenge held in Conjunction with MICCAI 2015 (MICCAI-BRATS 2015), Munich, Germany, 5–9 October 2015; pp. 13–24. [Google Scholar]
- Irmak, E. Multi-classification of brain tumor MRI images using deep convolutional neural network with fully optimized framework. Iran J. Sci. Technol. Trans. Electr. Eng. 2021, 45, 1015–1036. [Google Scholar] [CrossRef]
- Tandel, G.S.; Balestrieri, A.; Jujaray, T.; Khanna, N.N.; Saba, L.; Suri, J.S. Multiclass magnetic resonance imaging brain tumor classification using artificial intelligence paradigm. Comput. Biol. Med. 2020, 122, 103804. [Google Scholar] [CrossRef] [PubMed]
- Zhao, M.; Chang, C.H.; Xie, W.; Xie, Z.; Hu, J. Cloud shape classification system based on multi-channel CNN and improved FDM. IEEE Access 2020, 8, 44111–44124. [Google Scholar] [CrossRef]
- Khan, M.; Rahman, A.; Debnath, T.; Karim, M.R.; Nasir, M.K.; Band, S.S.; Mosavi, A.; Dehzangi, I. Accurate brain tumor detection using deep convolutional neural network. Comput. Struct. Biotechnol. J. 2022, 20, 4733–4745. [Google Scholar] [CrossRef] [PubMed]
- Alis, D.; Alis, C.; Yergin, M.; Topel, C.; Asmakutlu, O.; Bagcilar, O.; Senli, Y.D.; Ustundag, A.; Salt, V.; Dogan, S.N.; et al. A joint convolutional-recurrent neural network with an attention mechanism for detecting intracranial hemorrhage on noncontrast head CT. Sci. Rep. 2022, 12, 2084. [Google Scholar] [CrossRef] [PubMed]
- Jeong, J.J.; Tariq, A.; Adejumo, T.; Trivedi, H.; Gichoya, J.W.; Banerjee, I. Systematic review of generative adversarial networks (GANs) for medical image classification and segmentation. J. Digit Imaging 2022, 35, 137–152. [Google Scholar] [CrossRef]
- Kuang, Z. Transfer learning in brain tumor detection: From AlexNet to Hyb-DCNN-ResNet. Highlights Sci. Eng. Technol. 2022, 4, 313–324. [Google Scholar] [CrossRef]
- Cinar, N.; Ozcan, A.; Kaya, M. A hybrid DenseNet121-UNet model for brain tumor segmentation from MR images. Biomed. Signal Process. Control 2022, 76, 103647. [Google Scholar] [CrossRef]
- Liu, J.W.; Zuo, F.L.; Guo, Y.X.; Li, T.Y.; Chen, J.M. Research on improved wavelet convolutional wavelet neural networks. Appl. Intell. 2021, 51, 4106–4126. [Google Scholar] [CrossRef]
- Li, Q.; Shen, L. Wavesnet: Wavelet integrated deep networks for image segmentation. arXiv 2020, arXiv:2005.14461. [Google Scholar]
- Savareh, B.A.; Emami, H.; Hajiabadi, M.; Azimi, S.M.; Ghafoori, M. Wavelet-enhanced convolutional neural network: A new idea in a deep learning paradigm. Biomed. Eng./Biomed. Tech. 2019, 64, 195–205. [Google Scholar] [CrossRef]
- Liu, P.; Zhang, H.; Lian, W.; Zuo, W. Multi-level wavelet convolutional neural networks. IEEE Access 2019, 7, 74973–74985. [Google Scholar] [CrossRef]
- Fayaz, M.; Torokeldiev, N.; Turdumamatov, S.; Qureshi, M.S.; Qureshi, M.B.; Gwak, J. An efficient methodology for brain MRI classification based on DWT and convolutional neural network. Sensors 2021, 21, 7480. [Google Scholar] [CrossRef] [PubMed]
- Kumar, Y.; Mahajan, M. Recent Advancement of Machine Learning and Deep Learning in the Field of Healthcare System. In Computational Intelligence for Machine Learning and Healthcare Informatics; De Gruyter: Berlin, Germany, 2020; pp. 7–98. [Google Scholar]
- Kumar, N.; Kumar, D. Machine learning based heart disease diagnosis using non-invasive methods: A review. J. Phys. Conf. Ser. 2021, 1950, 012081. [Google Scholar] [CrossRef]
- Javeed, A.; Khan, S.U.; Ali, L.; Ali, S.; Imrana, Y.; Rahman, A. Machine learning-based automated diagnostic systems developed for heart failure prediction using different types of data modalities: A systematic review and future directions. Comput. Math. Methods Med. 2022, 2022, 9288452. [Google Scholar] [CrossRef] [PubMed]
- Wang, P.; En Fan, E.; Peng Wang, P. Comparative analysis of image classification algorithms based on traditional machine learning and deep learning. Pattern Recognit. Lett. 2021, 141, 61–67. [Google Scholar] [CrossRef]
- Chaplot, S.; Patnaik, L.; Jagannathan, N.R. Classification of magnetic resonance brain images using wavelets as input to support vector machine and neural network. Biomed. Signal Process. Control 2006, 1, 86–92. [Google Scholar] [CrossRef]
- Ullah, Z.; Lee, S.H.; Fayaz, M. Enhanced feature extraction technique for brain MRI classification based on Haar wavelet and statistical moments. Int. J. Adv. Appl. Sci. 2019, 6, 89–98. [Google Scholar] [CrossRef]
- Amin, J.; Sharif, M.; Gul, N.; Yasmin, M.; Shad, S.A. Brain tumor classification based on DWT fusion of MRI sequences using convolutional neural network. Pattern Recognit. Lett. 2020, 129, 115–122. [Google Scholar] [CrossRef]
- Mohsen, H.; El-Dahshan, E.S.A.; El-Horbaty, E.S.M.; Salem, A.B.M. Classification using deep learning neural networks for brain tumors. Futur. Comput. Inform. J. 2018, 3, 68–71. [Google Scholar] [CrossRef]
- Guo, Z.; Yang, M.; Huang, X. Bearing fault diagnosis based on speed signal and CNN model. Energy Rep. 2022, 8 (Suppl. 13), 904–913. [Google Scholar] [CrossRef]
- Chu, W.L.; Lin, C.J.; Kao, K.C. Fault diagnosis of a rotor and ball-bearing system using DWT integrated with SVM, GRNN, and visual dot patterns. Sensors 2019, 19, 4806. [Google Scholar] [CrossRef]
- Li, T.; Zhao, Z.; Sun, C.; Cheng, L.; Chen, X.; Yan, R.; Gao, R.X. WaveletKernelNet: An interpretable deep neural network for industrial intelligent diagnosis. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 2302–2312. [Google Scholar] [CrossRef]
- Liu, P.; Zhang, H.; Zhang, K.; Lin, L.; Zuo, W. Multi-Level Wavelet-CNN for Image Restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 773–782. [Google Scholar]
- Yiping, D.; Fang, L.; Licheng, J.; Peng, Z.; Lu, Z. SAR image segmentation based on convolutional wavelet neural network and Markov random field. Pattern Recognit. 2017, 64, 255–267. [Google Scholar]
- Lo, S.C.B.; Li, H.; Jyh-Shyan, L.; Hasegawa, A.; Wu, C.Y.; Matthew, T.; Mun, S.K.; Wu, M.T.; Freedman, M.D. Artificial Convolution Neural Network with Wavelet Kernels for Disease Pattern Recognition. In Proceedings of the SPIE, Medical Imaging 1995: Image Processing, San Diego, CA, USA, 17 February 1995; Volume 2434. [Google Scholar]
- Haweel, R.; Shalaby, A.; Mahmoud, A.; Seada, N.; Ghoniemy, S.; Ghazal, M.; Casanova, M.F.; Barnes, G.N.; El-Baz, A. A robust DWT-CNN-based CAD system for early diagnosis of autism using task-based fMRI. Med. Phys. 2021, 48, 2315–2326. [Google Scholar] [CrossRef] [PubMed]
- Kumar, S.; Dabas, C.; Godara, S. Classification of brain MRI tumor images: A hybrid approach. Procedia Comput. Sci. 2017, 122, 510–517. [Google Scholar] [CrossRef]
- Menze, B.H.; Jakab, A.; Bauer, S.; Kalpathy-Cramer, S.; Farahani, J.; Kirby, K.J. The multimodal brain tumor image segmentation benchmark (BRATS). IEEE Trans. Med. Imaging 2015, 34, 1993–2024. [Google Scholar] [CrossRef]
- Hajiabadi, M.; Alizadeh Savareh, B.; Emami, H.; Bashiri, A. Comparison of wavelet transformations to enhance convolutional neural network performance in brain tumor segmentation. BMC Med. Inform. Decis. Mak. 2021, 21, 327. [Google Scholar] [CrossRef]
- Srivastava, V.; Purwar, R.K. A five-level wavelet decomposition and dimensional reduction approach for feature extraction and classification of MR and CT scan images. Free Library 2014, 2017, 9571262. [Google Scholar] [CrossRef]
- Pérez-García, F.; Sparks, R.; Ourselin, S.; Torch, I.O. A Python library for efficient loading, preprocessing, augmentation and patch-based sampling of medical images in deep learning. arXiv 2020, arXiv:2003.04696. [Google Scholar] [CrossRef]
- Image Optimization Academy. 2021. Available online: http://www.mrishark.com/image-resolution.html (accessed on 10 January 2022).
- Shi, X.; De-Silva, V.; Aslan, Y.; Ekmekcioglu, E.; Kondoz, A. Evaluating the learning procedure of CNNs through a sequence of prognostic tests utilising information theoretical measures. Entropy 2021, 24, 67. [Google Scholar] [CrossRef]
- Sipper, M. High per parameter: A large-scale study of hyperparameter tuning for machine learning Algorithms. Algorithms 2022, 15, 315. [Google Scholar] [CrossRef]
- Bischl, B.; Binder, M.; Lang, M.; Pielok, T.; Richter, J.; Coors, S.; Thomas, J.; Ullmann, T.; Becker, M.; Boulesteix, A.L.; et al. Hyperparameter optimization: Foundations, algorithms, best practices and open challenges. arXiv 2021, arXiv:2107.05847. [Google Scholar] [CrossRef]
- Williams, T.; Li, R.Y. Wavelet Pooling for Convolutional Neural Networks. In Proceedings of the 2018 International Conference on Learning Representations (ICLR 2018), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Rosner, M. Transfer Learning & Machine Learning: How It Works, What It’s Used for, and Where It’s Taking Us. Available online: https://www.sparkcognition.com/transfer-learning-machine-learning (accessed on 10 January 2022).
- Mallat, S. A Wavelet Tour of Signal Processing: The Sparse Way, 3rd ed.; Academic Press: Burlington, NJ, USA, 2009. [Google Scholar]
- Lapuyade-Lahorgue, J.; Vera, P.; Ruan, S. A quantitative comparison between Shannon and Tsallis–Havrda–Charvat entropies applied to cancer outcome prediction. Entropy 2022, 24, 436. [Google Scholar] [CrossRef]
- Pembury-Smith, M.Q.R.; Ruxton, G.D. Effective use of the McNemar test. Behav. Ecol. Sociobiol. 2020, 74, 133. [Google Scholar] [CrossRef]
- Canbek, G.; Taskaya Temizel, T.; Sagiroglu, S. BenchMetrics: A systematic benchmarking method for binary classification performance metrics. Neural Comput. Appl. 2021, 33, 14623–14650. [Google Scholar] [CrossRef]
- Bisong, E. Building Machine Learning and Deep Learning Models on Google Cloud Platform; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Cınar, N.; Kaya, B.; Kaya, K. Comparison of Deep Learning Models for Brain Tumor Classification Using MRI Images. In Proceedings of the 2022 International Conference on Decision Aid Sciences and Applications (DASA), Chiangrai, Thailand, 23–25 March 2022; pp. 1382–1385. [Google Scholar] [CrossRef]
- Cinar, N.; Kaya, B.; Kaya, K. A Novel Convolutional Neural Network-Based Approach for Brain Tumor Classification Using Magnetic Resonance Images. Int. J. Imaging Syst. Technol. 2022. [Google Scholar] [CrossRef]
- Raza, A.; Ayub, H.; Khan, J.A.; Ahmad, I.; Salama, S.A.; Daradkeh, Y.I.; Javeed, D.; Ur Rehman, A.; Hamam, H. A hybrid deep learning-based approach for brain tumor classification. Electronics 2022, 11, 1146. [Google Scholar] [CrossRef]
- Ozyurt, F.; Sert, E.; Avci, D. An expert system for brain tumor detection: Fuzzy C-means with super resolution and convolutional neural network with extreme learning machine. Med. Hypotheses 2020, 134, 109433. [Google Scholar] [CrossRef]
- Deepak, S.; Ameer, P.M. Brain tumors classification using in-depth CNN features via transfer learning. Comput. Biol. Med. 2019, 111, 103345. [Google Scholar] [CrossRef]
- Cinar, A.; Yildirim, M. Detection of tumors on brain MRI images using the hybrid convolutional neural network architecture. Med. Hypotheses 2020, 139, 109684. [Google Scholar] [CrossRef]
- Sajjad, M.; Khan, S.; Muhammad, K.; Wu, W.; Ullah, A.; Baik, S.W. Multi-grade brain tumors classification using deep CNN with extensive data augmentation. J. Comput. Sci. 2019, 30, 174–182. [Google Scholar] [CrossRef]
- Ozyurt, F.; Sert, E.; Avci, D.; Dogantekin, E. Brain tumor detection based on convolutional neural network with neutrosophic expert maximum fuzzy sure entropy. Measurement 2019, 147, 106830. [Google Scholar] [CrossRef]
- Kaplan, K.; Kaya, Y.; Kuncan, M.; Ertunç, H.M. Brain tumors classification using modified local binary patterns (LBP) feature extraction methods. Med. Hypotheses 2020, 139, 109696. [Google Scholar] [CrossRef] [PubMed]
- Swati, Z.N.K.; Zhao, Q.; Kabir, M.; Ali, F.; Ali, Z.; Ahmed, S.; Lu, J. Brain tumors classification for MR images using transfer learning and fine-tuning. Comput. Med. Imaging Graph 2019, 75, 34–46. [Google Scholar] [CrossRef] [PubMed]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Set1 (Training Set): Selected 382 T2 MRIs from 382 Patients 3* | |||
| Diagnosis | Patients | Augmented Scans (×2) | |
| Non-pathologica l 1* | 168 | 2 × 168 | |
| Other disease (not tumor) 1*, 2* | 151 | 2 × 151 | |
| Widened perivascular spaces | in 11 cases, | ||
| Foci most probably associated with brain aging | 12 cases, | ||
| Hemorrhagic foci | 9 cases, | ||
| Ischemic changes and necrosis | 32 cases, | ||
| Hypoxic-ischemic changes | 7 cases, | ||
| Lesions associated with neurometabolic diseases | 12 cases, | ||
| Eclampsia | 2 cases, | ||
| Vasculitis | 15 cases, | ||
| Central pontine myelinolysis | 9 cases, | ||
| CNS degenerative diseases | 12 cases, | ||
| Multiple sclerosis | 30 cases | ||
| Tumor Glioma (Grade II, III, IV) 2* | 34 | 2 × 34 | |
| Tumor Meningioma (Grade II, III, IV) 2* | 20 | 2 × 20 | |
| Tumor Pituitary 2* | 9 | 2 × 9 | |
| 2* Set2 (Testing Set): Selected 190 T2 MRIs from 190 Patients | |||
| Diagnosis | Patients | ||
| Non-pathological 1* | 10 | ||
| Other disease than tumor 1*, 2* | 90 | ||
| Tumor Glioma (Grade II, III, IV) 2* | 30 | ||
| Tumor Meningioma (Grade II, III, IV) 2* | 30 | ||
| Tumor Pituitary 2* | 30 | ||
| Hyperparameters | Setting |
|---|---|
| Loss function | ReLU, sigmoid |
| Optimizer function | Root Mean Square Propagation (RMSprop) |
| Metrics | binary_crossentropy |
| Epochs | 30 |
| Learning rate | 0.0001 |
| Dropout Rate | 0.3 |
| Number of Dense Nodes | 2 to 1024 |
| Layer Name | Layer Type | Layer Configuration | Output Shape | Number of Parameters |
|---|---|---|---|---|
| Conv2D_1 | Convolution | Number of Filters = 32—Kernel Size = (3 × 3)—Activation function = ReLU | (240,240,32) | 320 |
| Dropout_1 | Dropout | Possibility = 0.3 | (240,240,32) | 0 |
| Conv2D_2 | Convolution | Number of Filters = 32—Kernel Size = (3 × 3)—Activation function = ReLU | (240,240,32) | 9248 |
| MaxPool2D_1 | MaxPooling | Kernel size = (2 × 2) | (120,120,32) | 0 |
| Dropout_2 | Dropout | Possibility = 0.3 | (120,120,32) | 0 |
| Conv2D_3 | Convolution | Number of Filters = 64—Kernel Size = (3 × 3)—Activation function = ReLU | (120,120,64) | 18,496 |
| Dropout_3 | Dropout | Possibility = 0.3 | (120,120,64) | 0 |
| Conv2D_4 | Convolution | Number of Filters = 64—Kernel Size = (3 × 3)—Activation function = ReLU | (120,120,64) | 36,928 |
| MaxPool2D_2 | MaxPooling | Kernel size = (2 × 2) | (60,60,64) | 0 |
| Dropout_4 | Dropout | Possibility = 0.3 | (60,60,64) | 0 |
| Conv2D_5 | Convolution | Number of Filters = 128—Kernel Size = (3 × 3)—Activation function = ReLU | (60,60,128) | 73,856 |
| Dropout_5 | Dropout | Possibility = 0.3 | (60,60,128) | 0 |
| Conv2D_6 | Convolution | Number of Filters = 128—Kernel Size = (3 × 3)—Activation function = ReLU | (60,60,128) | 147,584 |
| MaxPool2D_3 | MaxPooling | Kernel size = (2 × 2) | (30,30,128) | 0 |
| Dropout_6 | Dropout | Possibility = 0.3 | (30,30,128) | 0 |
| Flatten | Flatten | - | 115,200 | 0 |
| Dropout_7 | Dropout | Possibility = 0.3 | 115,200 | 0 |
| Dense_1 | Dense | Neurons = 1024—Activation function = ReLU | 1024 | 117,965,824 |
| Dropout_8 | Possibility = 0.3 | 1024 | 0 | |
| Dense_2 | Dense | Neurons = 512—Activation function = ReLU | 512 | 524,800 |
| Dropout_9 | Possibility = 0.3 | 512 | 0 | |
| Dense_3 | Dense | Neurons = 512—Activation function = ReLU | 512 | 262,656 |
| Dropout_10 | Possibility = 0.3 | 512 | 0 | |
| Dense_4 | Dense | Neurons = 128—Activation function = ReLU | 128 | 65,664 |
| Dropout_11 | Possibility = 0.3 | 128 | 0 | |
| Dense_5 | Dense | Neurons = 64—Activation function = ReLU | 64 | 8256 |
| Dropout_12 | Possibility = 0.3 | 64 | 0 | |
| Dense_6 | Dense | Neurons = 2—Activation function = sigmoid | 2 | 130 |
| Objects | Description | |
|---|---|---|
| Image in original resolution | s A0 Ak, 1 ≤ k ≤ j Dk, 1 ≤ k ≤ j | Original image Approximation at level 0 Approximation at level k Details at level k |
| Coefficients in scale-related resolution | cAk, 1 ≤ k ≤ j cDk, 1 ≤ k ≤ j [cAj, cDj,..., cD1] | Approximation coefficients at level k Detail coefficients at level k Wavelet decomposition at level j |
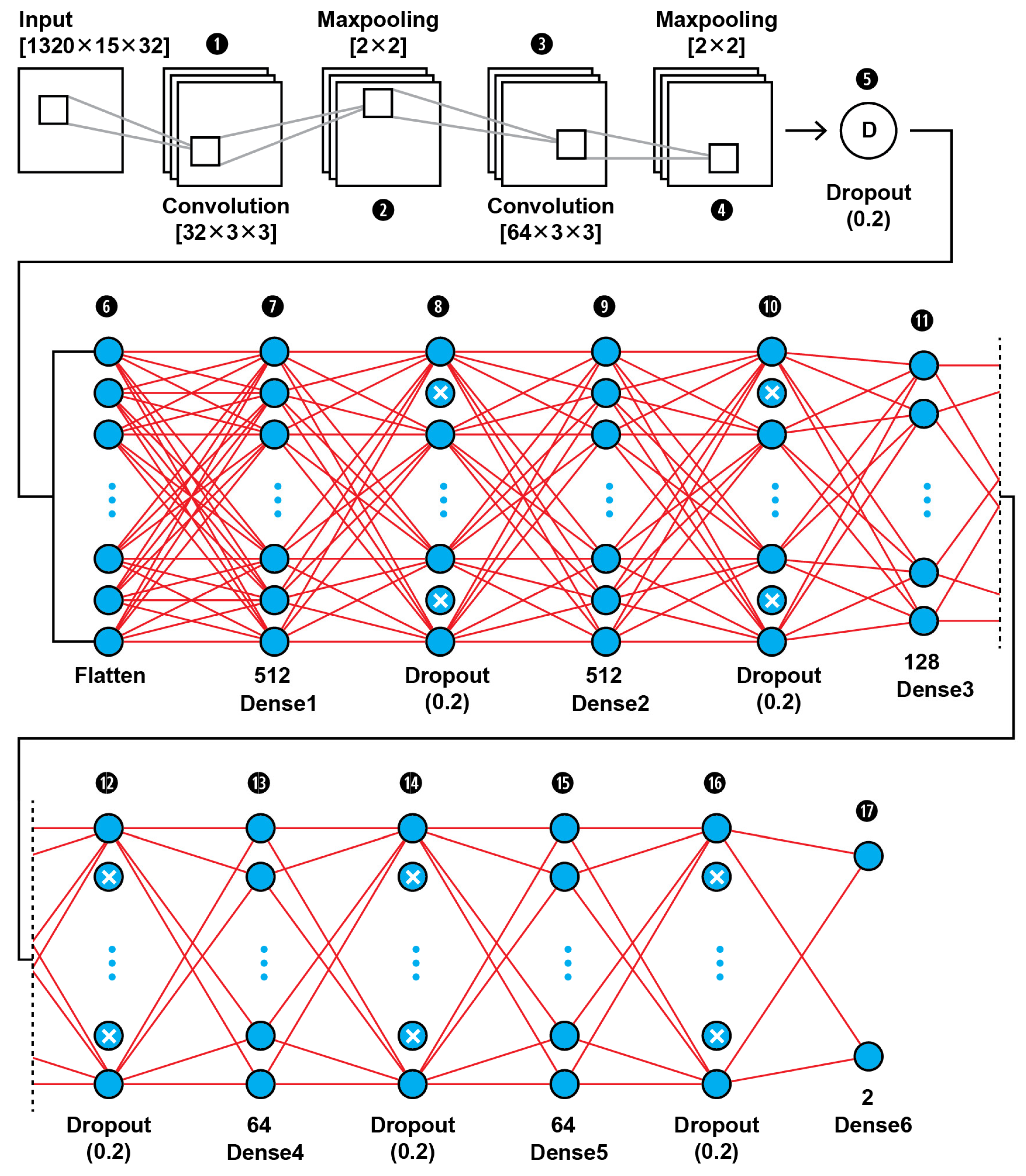
| Layer Name | Layer Type | Layer Configuration | Output Shape | Number of Parameters |
|---|---|---|---|---|
| Conv2D_1 | Convolution | Number of filters = 32—Kernel Size = (3 × 3)—Activation function = ReLU | (1320,15,32) | 320 |
| MaxPool2D_1 | MaxPooling | Kernel size = (2 × 2) | (660,7,32) | 0 |
| Conv2D_2 | Convolution | Number of filters = 64—Kernel Size = (3 × 3)—Activation function = ReLU | (658,5,64) | 18,496 |
| MaxPool2D_2 | MaxPooling | Kernel size = (2 × 2) | (329,2,64) | 0 |
| Dropout_1 | Dropout | Possibility = 0.2 | (329,2,64) | 0 |
| Flatten | Flatten | - | 42112 | 0 |
| Dense_1 | Dense | Neurons = 512—Activation function = ReLU | 512 | 21,561,856 |
| Dropout_2 | Dropout | Possibility = 0.2 | 512 | 0 |
| Dense_2 | Dense | Neurons = 512—Activation function = ReLU | 512 | 262,656 |
| Dropout_3 | Dropout | Possibility = 0.2 | 512 | 0 |
| Dense_3 | Dense | Neurons = 128—Activation function = ReLU | 128 | 65,664 |
| Dropout_4 | Dropout | Possibility = 0.2 | 128 | 0 |
| Dense_4 | Dense | Neurons = 64—Activation function = ReLU | 64 | 8256 |
| Dropout_5 | Dropout | Possibility = 0.2 | 64 | 0 |
| Dense_5 | Dense | Neurons = 64—Activation function = ReLU | 64 | 4160 |
| Dropout_6 | Dropout | Possibility = 0.2 | 64 | 0 |
| Dense_6 | Dense | Neurons = 2—Activation function = sigmoid | 64 | 130 |
| Hyperparameters | Setting |
|---|---|
| Loss function | ReLU, sigmoid |
| Optimizer function | Root-Mean-Square Propagation (RMSprop) |
| Metrics | binary_crossentropy |
| Epochs | 80 |
| Learning rate | 0.0001 |
| Dropout Rate | 0.2 |
| Number of Dense Nodes | 2 to 512 |
| Models Report | ||||||
|---|---|---|---|---|---|---|
| Proposed Classifier | TP | TN | FP | FN | Total Correct | Total Wrong |
| Model 1: CNN-DWT | 100 | 78 | 6 | 6 | 178 | 12 |
| Model 2: CNN | 95 | 84 | 0 | 11 | 179 | 11 |
| Model 3: SVM-DWT | 84 | 61 | 0 | 45 | 145 | 45 |
| Model 4: SVM | 67 | 106 | 17 | 0 | 173 | 17 |
| Model 5: CNN-TL VGG16 | 74 | 92 | 17 | 7 | 166 | 24 |
| Classification Report | ||||||
| Proposed Classifier | Accuracy | Sensitivity | Specificity | FPR | FNR | Precision |
| Model 1: CNN-DWT | 0.97 | 1.00 | 0.93 | 0.06 | 0.00 | 0.95 |
| Model 2: CNN | 0.97 | 0.94 | 1.00 | 0.00 | 0.05 | 1.00 |
| Model 3: SVM-DWT | 0.91 | 1.00 | 0.80 | 0.20 | 0.00 | 0.86 |
| Model 4: SVM | 0.79 | 0.63 | 1.00 | 0.00 | 0.36 | 1.00 |
| Model 5: CNN-TL VGG16 | 0.87 | 0.91 | 0.84 | 0.14 | 0.08 | 0.86 |
| Contingency Table Model 4/Model 3 | Model 3: SVM Correct TP | Model 3: SVM Wrong FN | Row Total |
|---|---|---|---|
| Model 4: SVM-DWT Correct TP | 84 | 0 | 84 |
| Model 4: SVM-DWT Wrong FN | 45 | 67 | 112 |
| Column total | 129 | 67 | 196 |
| X2 (1, N = 196) = 73.5302, p-value < 0.00001 The result is significant at p < 0.05 | |||
| Contingency Table | Model 2: CNN Correct TP | Model 2: CNN Wrong FN | Row Total |
|---|---|---|---|
| Model 1: CNN–DWT Correct TP | 100 | 6 | 106 |
| Model 1: CNN–DWT Wrong FN | 11 | 95 | 106 |
| Column total | 111 | 101 | 212 |
| X2 (1, N = 212) = 149.7861, p-value = 0.00001 The result is significant at p < 0.05 | |||
| Authors | Classification Type | Technique | MRI Type Data | Accuracy (%) |
|---|---|---|---|---|
| Cinar et al., 2022 [60] | CNN | Multi-class | T1-W | 99.64 |
| Raza et al., 2022 [61] | Deep CNN | Multi-class | T1-W | 99.67 |
| Ozyurt et al., 2020 [62] | SR-FCM-CNN | Multi-class | T1-W | 98.33 |
| Deepak et al., 2019 [63] | GoogLeNet | Multi-class | T1-W | 98 |
| Çinar et al., 2020 [64] | Hybrid ResNet50 | Multi-class | T1-W | 97.2 |
| Sajjad et al., 2019 [65] | CNN–TL | Multi-class | T1-W | 96.14 |
| Ozyurt et al., 2019 [66] | NS-EMFSE AlexNet SVM KNN | Multi-class | T1-W | 95.62 |
| Kaplan et al., 2020 [67] | LBP SVM KNN | Multi-Class | T1-W | 95.56 |
| Swati et al., 2019 [68] | Deep CNN VGG-19 | Multi-Class | T1-W | 94.84 |
| Present work | CNN-DWT | Binary (glioma) | T2 | 97 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Papadomanolakis, T.N.; Sergaki, E.S.; Polydorou, A.A.; Krasoudakis, A.G.; Makris-Tsalikis, G.N.; Polydorou, A.A.; Afentakis, N.M.; Athanasiou, S.A.; Vardiambasis, I.O.; Zervakis, M.E. Tumor Diagnosis against Other Brain Diseases Using T2 MRI Brain Images and CNN Binary Classifier and DWT. Brain Sci. 2023, 13, 348. https://doi.org/10.3390/brainsci13020348
Papadomanolakis TN, Sergaki ES, Polydorou AA, Krasoudakis AG, Makris-Tsalikis GN, Polydorou AA, Afentakis NM, Athanasiou SA, Vardiambasis IO, Zervakis ME. Tumor Diagnosis against Other Brain Diseases Using T2 MRI Brain Images and CNN Binary Classifier and DWT. Brain Sciences. 2023; 13(2):348. https://doi.org/10.3390/brainsci13020348
Chicago/Turabian StylePapadomanolakis, Theodoros N., Eleftheria S. Sergaki, Andreas A. Polydorou, Antonios G. Krasoudakis, Georgios N. Makris-Tsalikis, Alexios A. Polydorou, Nikolaos M. Afentakis, Sofia A. Athanasiou, Ioannis O. Vardiambasis, and Michail E. Zervakis. 2023. "Tumor Diagnosis against Other Brain Diseases Using T2 MRI Brain Images and CNN Binary Classifier and DWT" Brain Sciences 13, no. 2: 348. https://doi.org/10.3390/brainsci13020348
APA StylePapadomanolakis, T. N., Sergaki, E. S., Polydorou, A. A., Krasoudakis, A. G., Makris-Tsalikis, G. N., Polydorou, A. A., Afentakis, N. M., Athanasiou, S. A., Vardiambasis, I. O., & Zervakis, M. E. (2023). Tumor Diagnosis against Other Brain Diseases Using T2 MRI Brain Images and CNN Binary Classifier and DWT. Brain Sciences, 13(2), 348. https://doi.org/10.3390/brainsci13020348