RMTF-Net: Residual Mix Transformer Fusion Net for 2D Brain Tumor Segmentation

 ,
,
Abstract
:1. Introduction
- We propose a novel end-to-end framework to segment brain tumors, namely RMFT-net.
- We design a mix transformer module to reduce the interference of irrelevant background information on the segmentation results.
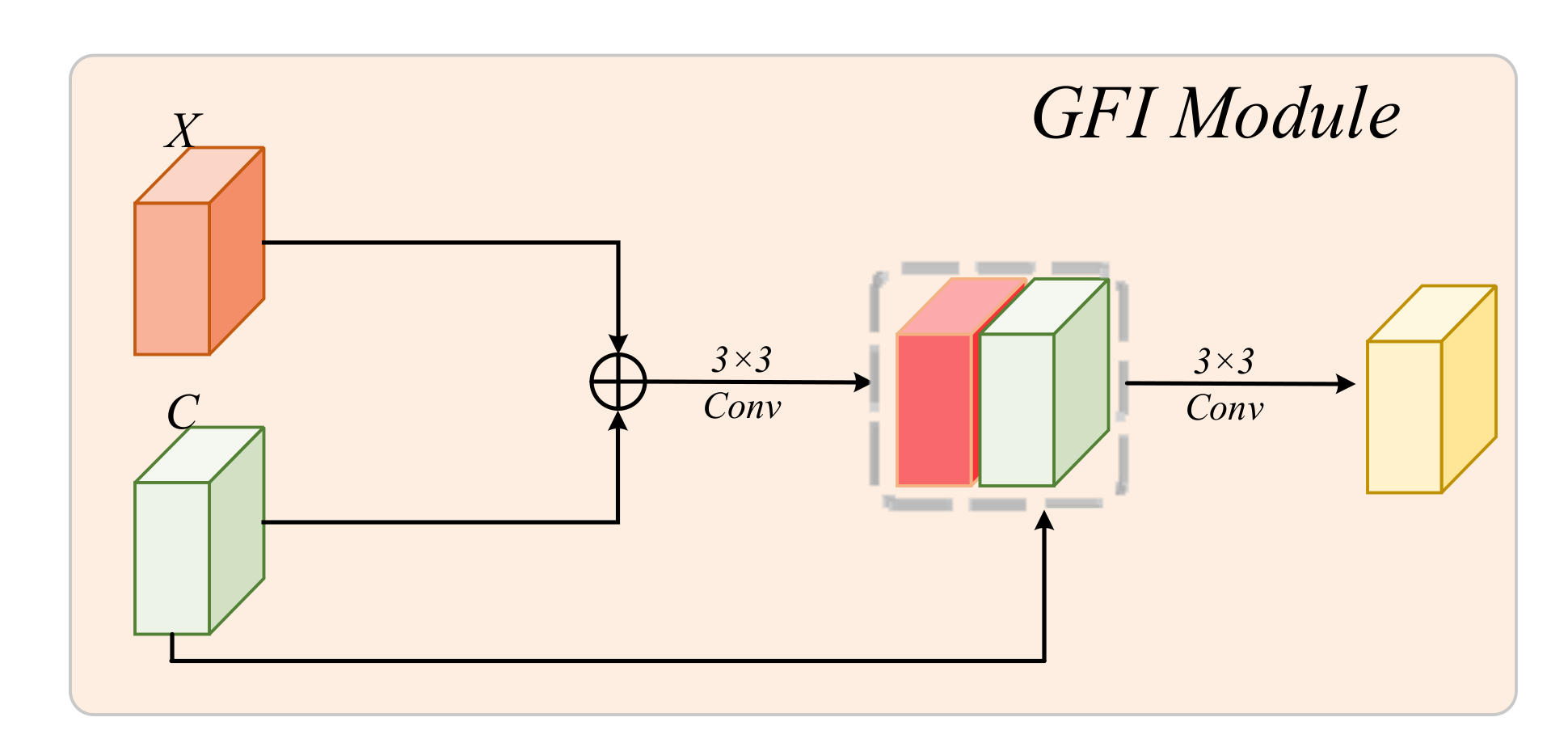
- We devise a global feature integration module to enrich the context and incorporate global attention features.
- The proposed model achieves excellent segmentation results on LGG, BraTS2019, and BraTS2020 datasets.
2. Related Work
2.1. Brain Tumor Segmentation-Based Medical Image Segmentation Method
2.2. U-Shaped Network Structure-Based Medical Image Segmentation Method
2.3. Transformers-Based 3D Medical Image Segmentation Method
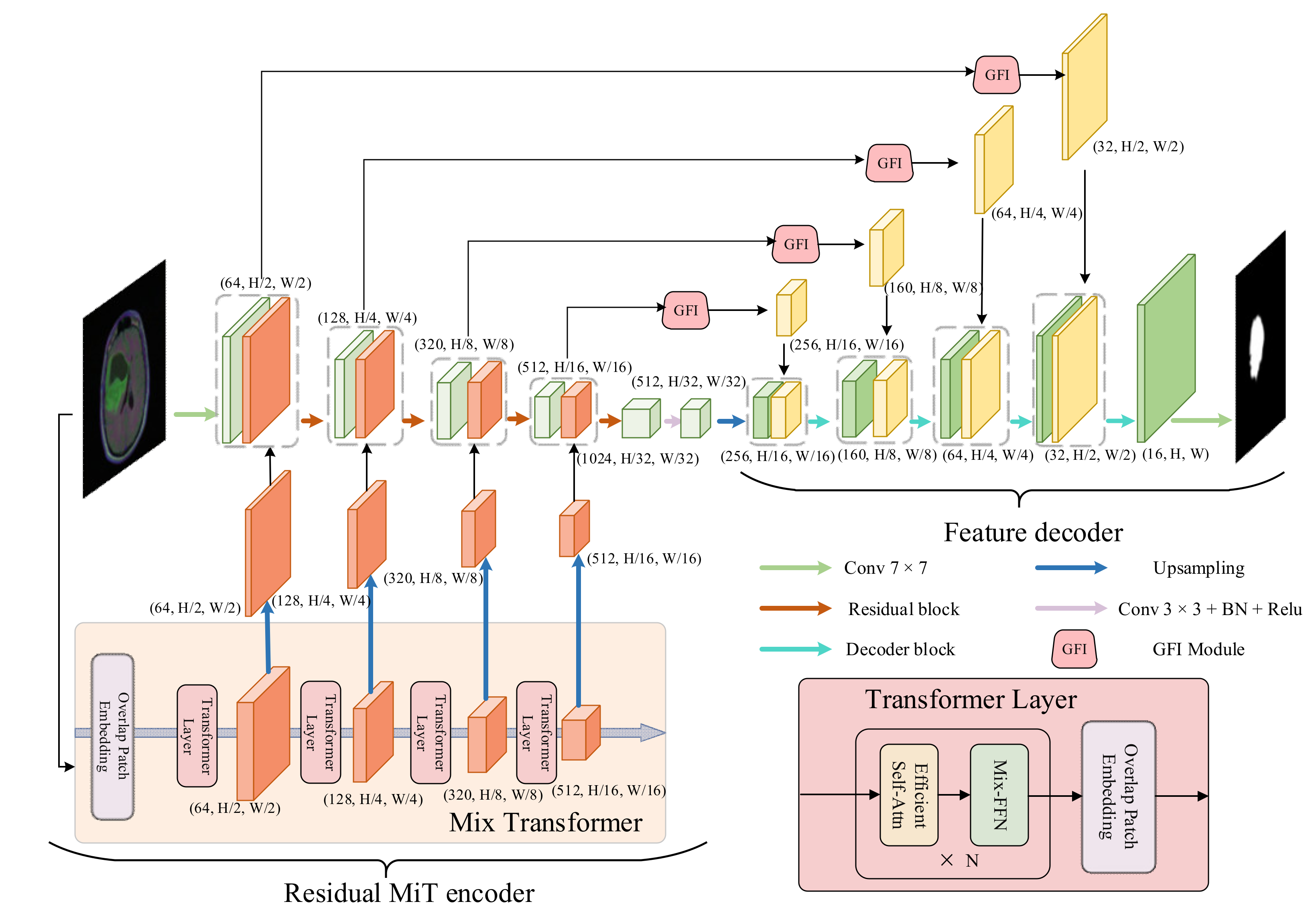
3. Methodology
3.1. Residual MiT Encoder
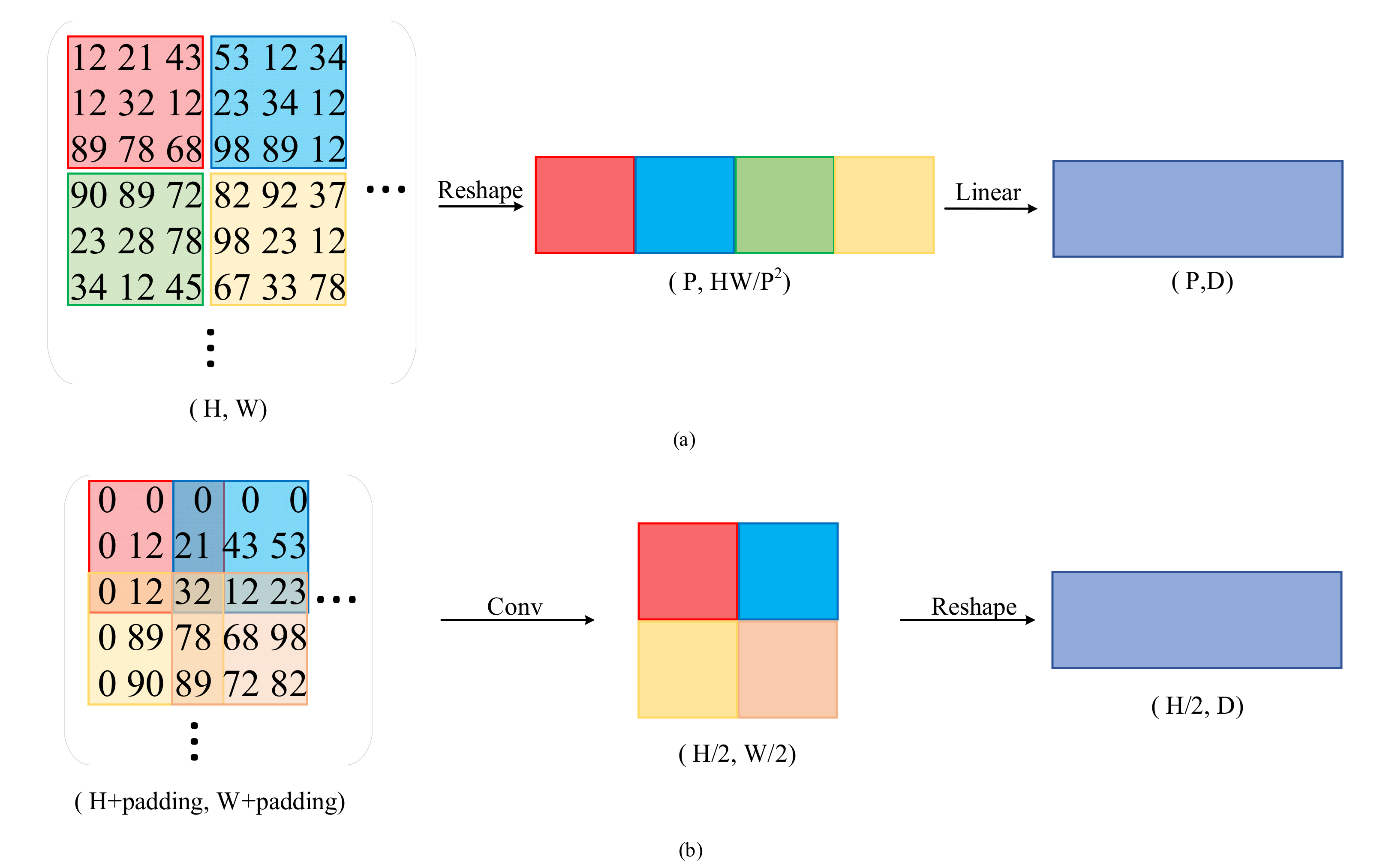
3.1.1. Mix Transformer
3.1.2. Parallel Fusion Strategy
3.2. Feature Decoder
3.3. Hybrid Loss
3.3.1. Dice Loss
3.3.2. Binary Cross Entropy Loss
3.3.3. SSIM Loss
4. Experiment
4.1. Dataset
4.2. Implementation Details
4.3. Evaluation Metrics
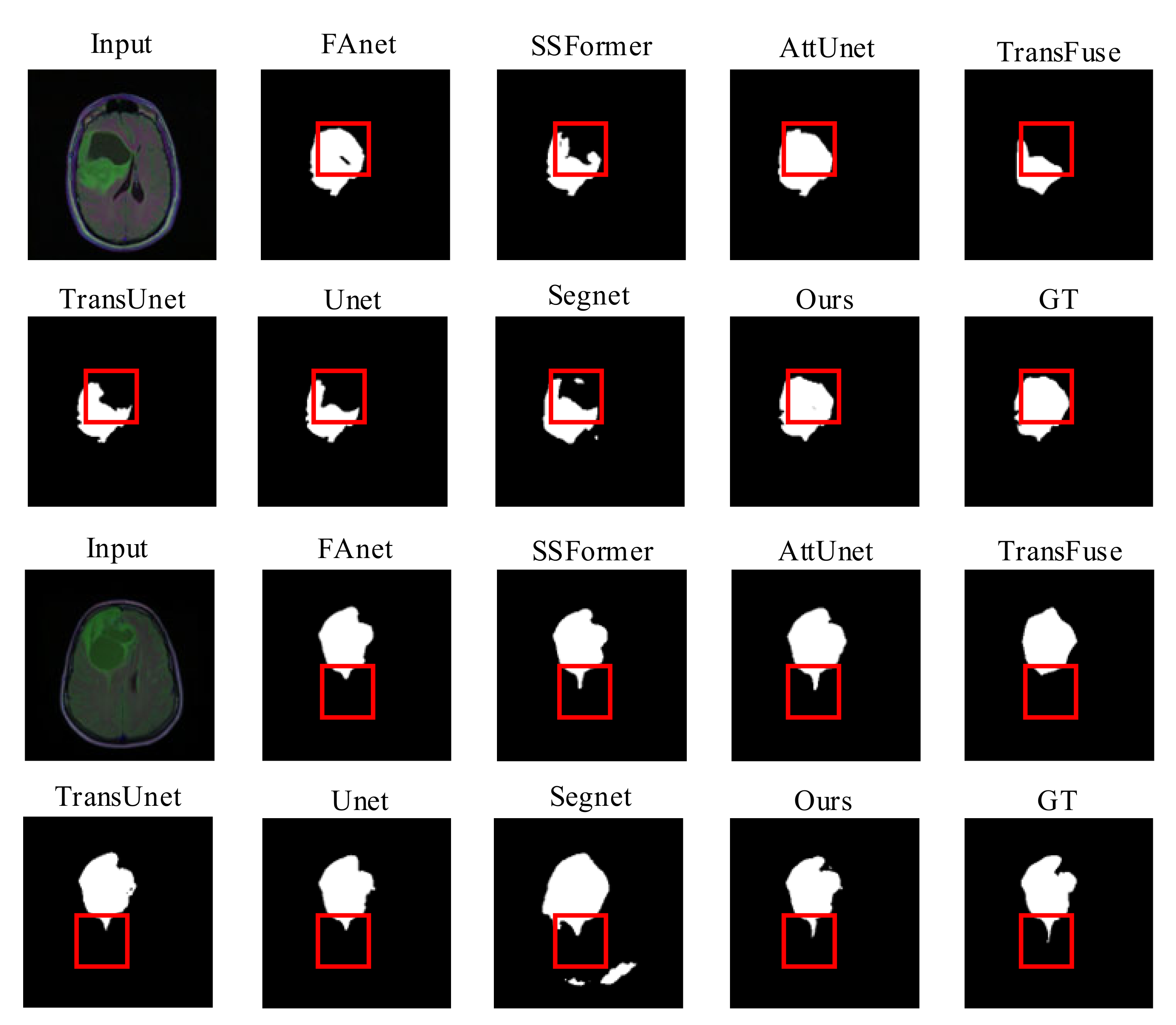
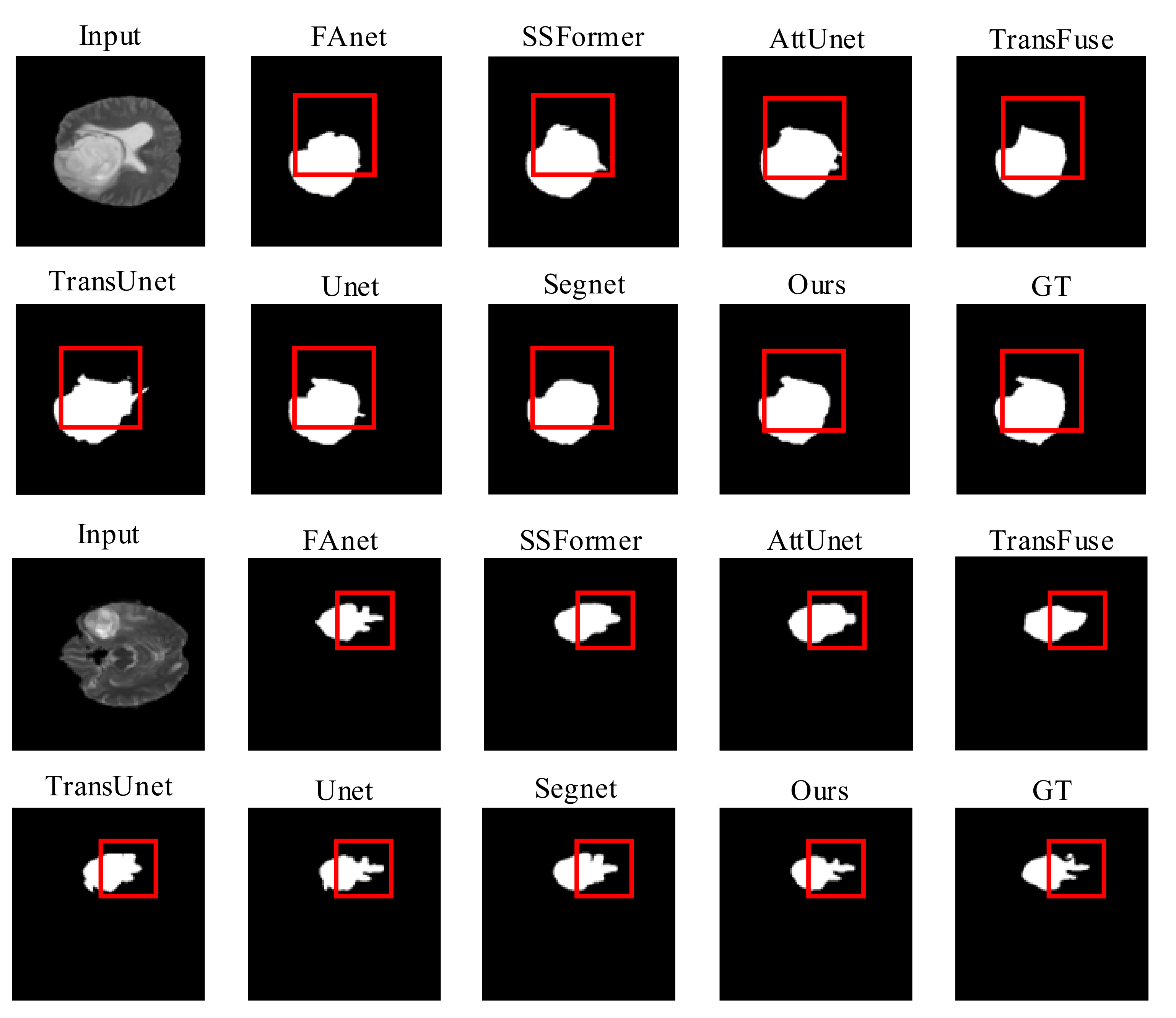
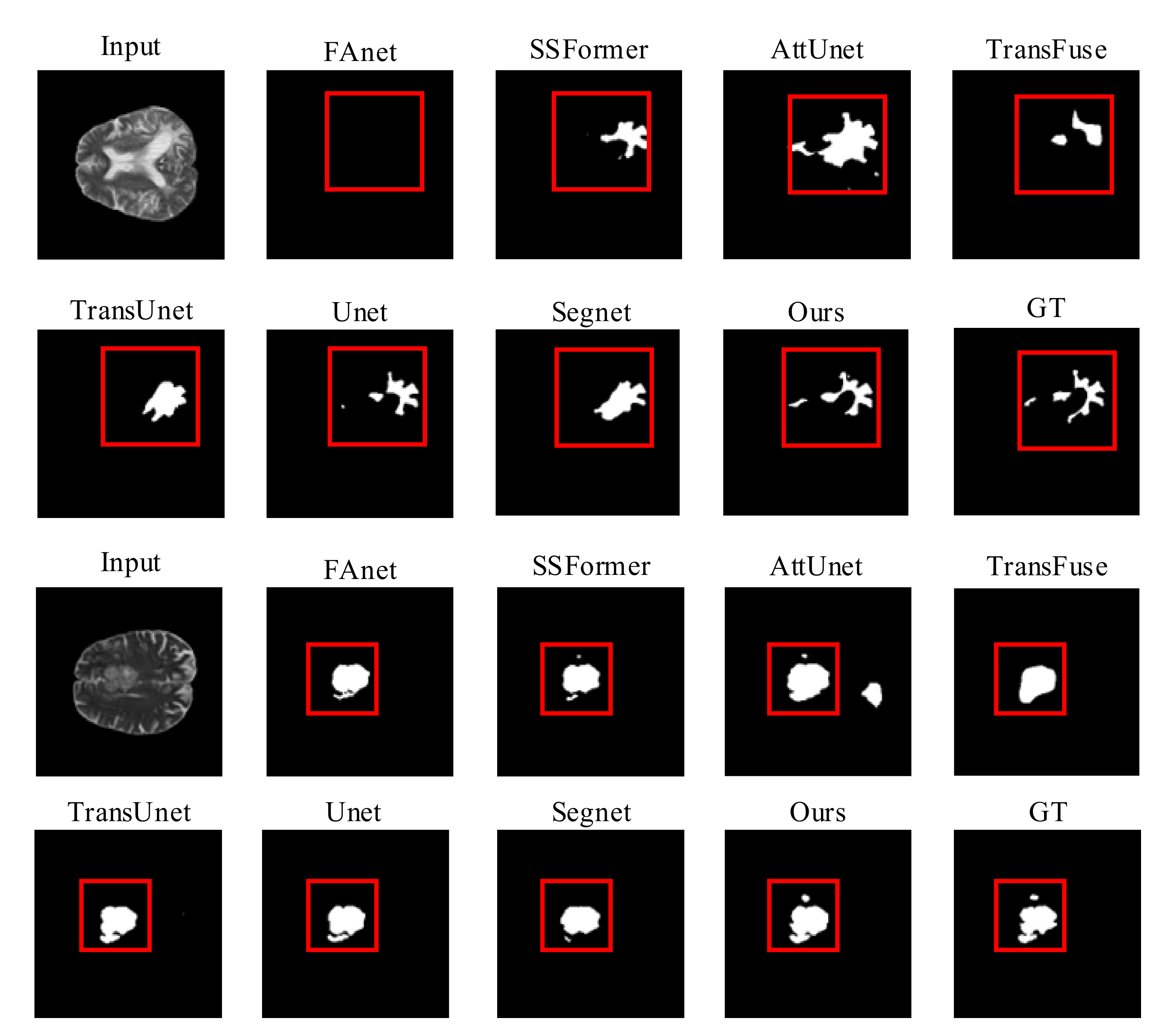
4.4. Comparison Experiments
4.4.1. LGG Dataset
4.4.2. BraTS2019 Dataset
4.4.3. BraTS2020 Dataset
4.5. Ablations Experiments and Analysis
4.5.1. Effectiveness of GFI Module and Hybrid Loss
4.5.2. Size of the MiT
4.5.3. Effect of Different Transformer Structures
4.5.4. Effectiveness of Global–Local Feature Fusion for Segmentation Tasks
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Menze, B.H.; Jakab, A.; Bauer, S.; Kalpathy-Cramer, J.; Farahani, K.; Kirby, J.; Burren, Y.; Porz, N.; Slotboom, J.; Wiest, R.; et al. The Multimodal Brain Tumor Image Segmentation Benchmark (BRATS). IEEE Trans. Med. Imaging 2015, 34, 1993–2024. [Google Scholar] [CrossRef]
- Shah, A.H.; Heiss, J.D. Neurosurgical Clinical Trials for Glioblastoma: Current and Future Directions. Brain Sci. 2022, 12, 787. [Google Scholar] [CrossRef] [PubMed]
- Ali, M.B.; Gu, I.Y.H.; Berger, M.S.; Pallud, J.; Southwell, D.; Widhalm, G.; Roux, A.; Vecchio, T.G.; Jakola, A.S. Domain Mapping and Deep Learning from Multiple MRI Clinical Datasets for Prediction of Molecular Subtypes in Low Grade Gliomas. Brain Sci. 2020, 10, 463. [Google Scholar] [CrossRef] [PubMed]
- Gai, D.; Shen, X.; Chen, H.; Xie, Z.; Su, P. Medical image fusion using the PCNN based on IQPSO in NSST domain. IET Image Process. 2020, 14, 1870–1880. [Google Scholar] [CrossRef]
- Bakas, S.; Akbari, H.; Sotiras, A.; Bilello, M.; Rozycki, M.; Kirby, J.; Freymann, J.B.; Farahani, K.; Davatzikos, C. Advancing the Cancer Genome Atlas glioma MRI collections with expert segmentation labels and radiomic features. Nat. Sci. Data 2017, 4, 170117. [Google Scholar] [CrossRef]
- Isensee, F.; Kickingereder, P.; Wick, W.; Bendszus, M.; Maier-Hein, K.H. Brain tumor segmentation and radiomics survival prediction: Contribution to the brats 2017 challenge. In Proceedings of the International MICCAI Brainlesion Workshop, Quebec, QC, Canada, 14 September 2017; pp. 287–297. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xiaomeng, L.; Hao, C.; Xiaojuan, Q.; Qi, D.; Chi-Wing, F.; Pheng-Ann, H. H-DenseUNet: Hybrid Densely Connected UNet for Liver and Liver Tumor Segmentation from CT Volumes. IEEE Trans. Med. Imaging 2018, 37, 2663–2674. [Google Scholar] [CrossRef]
- Wang, Q.; Min, W.; Han, Q.; Liu, Q.; Zha, C.; Zhao, H.; Wei, Z. Inter-domain adaptation label for data augmentation in vehicle re-identification. IEEE Trans. Multimed. 2022, 24, 1031–1041. [Google Scholar] [CrossRef]
- Xiong, X.; Min, W.; Zheng, W.-S.; Liao, P.; Yang, H.; Wang, S. S3D-CNN: Skeleton-based 3D consecutive-low-pooling neural network for fall detection. Appl. Intell. 2020, 50, 3521–3534. [Google Scholar] [CrossRef]
- Wang, Q.; Min, W.; Han, Q.; Yang, Z.; Xiong, X.; Zhu, M.; Zhao, H. Viewpoint adaptation learning with cross-view distance metric for robust vehicle re-identification. Inf. Sci. 2021, 564, 71–84. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Sengara, S.S.; Meulengrachtb, C.; Meulengrachtb, C.; Boesenb, M.P.; Mikael, P.; Overgaardb, A.F.; Gudbergsenb, H.; Nybingb, J.D.; Dam, E.B. UNet Architectures in Multiplanar Volumetric Segmentation—Validated on Three Knee MRI Cohorts RI Cohorts. arXiv 2022, arXiv:2203.08194. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Graham, B.; El-Nouby, A.; Touvron, H.; Stock, P.; Joulin, A.; Jégou, H.; Douze, M. Levit: A vision transformer in convnet’s clothing for faster inference. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 12259–12269. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 568–578. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic seg-mentation with transformers. In Proceedings of the Neural Information Processing Systems, Virtual Event, 6–14 December 2021; pp. 12077–12090. [Google Scholar]
- Liu, A.; Wang, Z. CV 3315 Is All You Need: Semantic Segmentation Competition. arXiv 2022, arXiv:2206.12571. [Google Scholar]
- Goin, J.E. Classification bias of the k-nearest neighbor algorithm. IEEE Trans. Pattern Anal. Mach. Intell. 1984, 3, 379–381. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. k-means ++: The Advantages of Careful Seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]
- Stormo, G.D.; Schneider, T.D.; Gold, L.; Ehrenfeucht, A. Use of the ‘Perceptron’ algorithm to distinguish translational initiation sites in E. coli. Nucleic Acids Res. 1982, 10, 2997–3011. [Google Scholar] [CrossRef]
- Li, W.; Gu, J.; Dong, Y.; Dong, Y.; Han, J. Indoor scene understanding via RGB-D image segmentation employing depth-based CNN and CRFs. Multimed. Tools Appl. 2020, 79, 35475–35489. [Google Scholar] [CrossRef]
- Zhang, S.; Ma, Z.; Zhang, G.; Lei, T.; Zhang, R.; Cui, Y. Semantic image segmentation with deep convolutional neural networks and quick shift. Symmetry 2020, 12, 427. [Google Scholar] [CrossRef]
- Wang, X.; Lv, R.; Zhao, Y.; Yang, T.; Ruan, Q. Multi-scale context aggregation network with attention-guided for crowd counting. In Proceedings of the 2020 15th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 6–9 December 2020; pp. 240–245. [Google Scholar]
- Jiang, D.; Li, G.; Tan, C.; Huang, L.; Sun, Y.; Kong, J. Semantic segmentation for multiscale target based on object recognition using the improved Faster-RCNN model. Future Gener. Comput. Syst. 2021, 123, 94–104. [Google Scholar] [CrossRef]
- Xu, H.; Xie, H.; Zha, Z.-J.; Liu, S.; Zhang, Y. March on Data Imperfections: Domain Division and Domain Generalization for Semantic Segmentation. In Proceedings of the 28th ACM International Conference on Multimedia, Virtual Event, 12–16 October 2020; pp. 3044–3053. [Google Scholar]
- Takikawa, T.; Acuna, D.; Jampani, V.; Fidler, S. Gated-scnn: Gated shape cnns for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 5229–5238. [Google Scholar]
- Lee, S.; Lee, M.; Lee, J.; Shim, H. Railroad is not a train: Saliency as pseudo-pixel supervision for weakly supervised semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5495–5505. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.; Kainz, B. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Gu, Z.; Cheng, J.; Fu, H.; Zhou, K.; Hao, H.; Zhao, Y.; Zhang, T.; Gao, S.; Liu, J. Ce-net: Context encoder network for 2D medical image segmentation. IEEE Trans. Med. Imaging 2019, 38, 2281–2292. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Min, W.; Xu, J.; Han, Q.; Wang, Q.; Yang, Z.; Zhou, L. SPACE: Finding key-speaker in complex multi-person scenes. IEEE Trans. Emerg. Top. Comput. 2021, 1. [Google Scholar] [CrossRef]
- Wang, Q.; Min, W.; He, D.; Zou, S.; Huang, T.; Zhang, Y.; Liu, R. Discriminative fine-grained network for vehicle re-identification using two-stage re-ranking. Sci. China Inf. Sci. 2020, 63, 212102. [Google Scholar] [CrossRef]
- Gai, D.; Shen, X.; Chen, H.; Su, P. Multi-focus image fusion method based on two stage of convolutional neural network. Signal Process. 2020, 176, 107681. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, C.; Zhou, Z.; Liu, Z. Enhancing transformer with sememe knowledge. In Proceedings of the 5th Workshop on Representation Learning for NLP, Virtual Event, 9 July 2020; pp. 177–184. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jegou, H. Training data-efficient image transformers & distillation through attention. Proc. Mach. Learn. Res. 2021, 139, 10347–10357. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Zhang, Y.; Liu, H.; Hu, Q. Transfuse: Fusing transformers and cnns for medical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Virtual Event, 27 September 2021; pp. 14–24. [Google Scholar]
- Islam, M.A.; Jia, S.; Bruce, N.D.B. How much position information do convolutional neural networks encode? arXiv 2020, arXiv:2001.08248. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Buda, M.; Saha, A.; Mazurowski, M.A. Association of genomic subtypes of lower-grade gliomas with shape features automatically extracted by a deep learning algorithm. Comput. Biol. Med. 2019, 109, 218–225. [Google Scholar] [CrossRef] [Green Version]
- Mazurowski, M.A.; Clark, K.; Czarnek, N.M.; Shamsesfandabadi, P.; Peters, K.B.; Saha, A. Radiogenomics of lower-grade glioma: Algorithmically-assessed tumor shape is associated with tumor genomic subtypes and patient outcomes in a multi-institutional study with The Cancer Genome Atlas data. J. Neuro-Oncol. 2017, 133, 27–35. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Tomar, N.K.; Jha, D.; Riegler, M.A.; Johansen, H.D.; Johansen, D.; Rittscher, J.; Halvorsen, P.; Ali, S. Fanet: A feedback attention network for improved biomedical image segmentation. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–14. [Google Scholar] [CrossRef]
- Wang, J.; Huang, Q.; Tang, F.; Meng, J.; Su, J.; Song, S. Stepwise Feature Fusion: Local Guides Global. arXiv 2022, arXiv:2203.03635. [Google Scholar]
- Yu, W.; Luo, M.; Zhou, P.; Si, C.; Zhou, Y.; Wang, X.; Feng, J.; Yan, S. Metaformer is actually what you need for vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–23 June 2022; pp. 10819–10829. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pvt v2: Improved baselines with pyramid vision transformer. Comput. Vis. Media 2022, 8, 415–424. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Method | MeanDice | MeanIoU | wFm | Sm | Em |
|---|---|---|---|---|---|---|
| LGG | AttUnet [35] | 0.907 | 0.836 | 0.892 | 0.922 | 0.975 |
| SSFormer [50] | 0.925 | 0.866 | 0.926 | 0.939 | 0.984 | |
| TransFuse [43] | 0.891 | 0.811 | 0.892 | 0.915 | 0.977 | |
| FAnet [49] | 0.932 | 0.879 | 0.934 | 0.945 | 0.987 | |
| Unet [14] | 0.922 | 0.861 | 0.925 | 0.937 | 0.983 | |
| Transunet [42] | 0.926 | 0.869 | 0.928 | 0.940 | 0.986 | |
| Segnet [48] | 0.831 | 0.722 | 0.790 | 0.858 | 0.928 | |
| RMTF-Net (Ours) | 0.935 | 0.882 | 0.941 | 0.948 | 0.988 |
| Dataset | Method | MeanDice | MeanIoU | wFm | Sm | Em |
|---|---|---|---|---|---|---|
| BraTS2019 | AttUnet [35] | 0.728 | 0.622 | 0.703 | 0.816 | 0.869 |
| SSFormer [50] | 0.820 | 0.735 | 0.821 | 0.877 | 0.942 | |
| TransFuse [43] | 0.804 | 0.720 | 0.808 | 0.873 | 0.933 | |
| FAnet [49] | 0.780 | 0.699 | 0.786 | 0.858 | 0.899 | |
| Unet [14] | 0.808 | 0.727 | 0.814 | 0.874 | 0.928 | |
| Transunet [42] | 0.755 | 0.659 | 0.753 | 0.838 | 0.912 | |
| Segnet [48] | 0.778 | 0.69 | 0.781 | 0.856 | 0.910 | |
| RMTF-Net (Ours) | 0.821 | 0.743 | 0.831 | 0.883 | 0.933 |
| Dataset | Method | MeanDice | MeanIoU | wFm | Sm | Em |
|---|---|---|---|---|---|---|
| BraTS2020 | AttUnet [35] | 0.730 | 0.613 | 0.692 | 0.808 | 0.869 |
| SSFormer [50] | 0.810 | 0.724 | 0.815 | 0.875 | 0.937 | |
| TransFuse [43] | 0.806 | 0.714 | 0.808 | 0.872 | 0.948 | |
| FAnet [49] | 0.804 | 0.718 | 0.812 | 0.870 | 0.932 | |
| Unet [14] | 0.807 | 0.724 | 0.815 | 0.874 | 0.928 | |
| Transunet [42] | 0.756 | 0.659 | 0.757 | 0.839 | 0.911 | |
| Segnet [48] | 0.784 | 0.693 | 0.791 | 0.858 | 0.924 | |
| RMTF-Net (Ours) | 0.818 | 0.733 | 0.825 | 0.880 | 0.941 |
| Variants | Module | Dataset | ||||||
|---|---|---|---|---|---|---|---|---|
| GFI Module | Hybrid Loss | LGG | BraTS2019 | BraTS2020 | ||||
| Mean Dice | Mean IoU | Mean Dice | Mean IoU | Mean Dice | Mean IoU | |||
| backbone | 0.929 | 0.873 | 0.810 | 0.734 | 0.813 | 0.726 | ||
| w/H-loss | √ | 0.93 | 0.874 | 0.804 | 0.725 | 0.808 | 0.721 | |
| w/GFI | √ | 0.931 | 0.877 | 0.818 | 0.738 | 0.815 | 0.729 | |
| RMTF-Net | √ | √ | 0.935 | 0.882 | 0.821 | 0.743 | 0.818 | 0.733 |
| Variants | Dataset | |||||
|---|---|---|---|---|---|---|
| LGG | BraTS2019 | BraTS2020 | ||||
| Mean Dice | Mean IoU | Mean Dice | Mean IoU | Mean Dice | Mean IoU | |
| RMTF-Net-L | 0.927 | 0.871 | 0.815 | 0.733 | 0.814 | 0.729 |
| RMTF-Net-B | 0.935 | 0.882 | 0.821 | 0.743 | 0.818 | 0.733 |
| Variants | Dataset | |||||
|---|---|---|---|---|---|---|
| LGG | BraTS2019 | BraTS2020 | ||||
| Mean Dice | Mean IoU | Mean Dice | Mean IoU | Mean Dice | Mean IoU | |
| PoolTF-Net | 0.932 | 0.877 | 0.805 | 0.725 | 0.813 | 0.727 |
| PTF-Net | 0.934 | 0.882 | 0.806 | 0.725 | 0.811 | 0.726 |
| PTv2F-Net | 0.929 | 0.873 | 0.813 | 0.729 | 0.802 | 0.714 |
| RMTF-Net | 0.935 | 0.882 | 0.821 | 0.743 | 0.818 | 0.733 |
| Variants | Dataset | |||||
|---|---|---|---|---|---|---|
| LGGS | BraTS2019 | BraTS2020 | ||||
| Mean Dice | Mean IoU | Mean Dice | Mean IoU | Mean Dice | Mean IoU | |
| MiTencoder-Net | 0.929 | 0.874 | 0.812 | 0.728 | 0.801 | 0.715 |
| RCNNencoder-Net | 0.928 | 0.872 | 0.810 | 0.734 | 0.808 | 0.723 |
| RMTF-Net | 0.935 | 0.882 | 0.821 | 0.743 | 0.818 | 0.733 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gai, D.; Zhang, J.; Xiao, Y.; Min, W.; Zhong, Y.; Zhong, Y. RMTF-Net: Residual Mix Transformer Fusion Net for 2D Brain Tumor Segmentation. Brain Sci. 2022, 12, 1145. https://doi.org/10.3390/brainsci12091145
Gai D, Zhang J, Xiao Y, Min W, Zhong Y, Zhong Y. RMTF-Net: Residual Mix Transformer Fusion Net for 2D Brain Tumor Segmentation. Brain Sciences. 2022; 12(9):1145. https://doi.org/10.3390/brainsci12091145
Chicago/Turabian StyleGai, Di, Jiqian Zhang, Yusong Xiao, Weidong Min, Yunfei Zhong, and Yuling Zhong. 2022. "RMTF-Net: Residual Mix Transformer Fusion Net for 2D Brain Tumor Segmentation" Brain Sciences 12, no. 9: 1145. https://doi.org/10.3390/brainsci12091145
APA StyleGai, D., Zhang, J., Xiao, Y., Min, W., Zhong, Y., & Zhong, Y. (2022). RMTF-Net: Residual Mix Transformer Fusion Net for 2D Brain Tumor Segmentation. Brain Sciences, 12(9), 1145. https://doi.org/10.3390/brainsci12091145