
Automated Classification of Cognitive Workload Levels Based on Psychophysiological and Behavioural Variables of Ex-Gaussian Distributional Features


Abstract
:1. Introduction
- To verify whether the cognitive and physiological data collected during cognitive-workload-related experiments fit the ex-Gaussian distribution;
- To determine the possibilities of machine-learning-based classifiers regarding automatic recognition of cognitive workload using ex-Gaussian parameters of eye-tracking and cognitive measures.
2. Materials and Methods
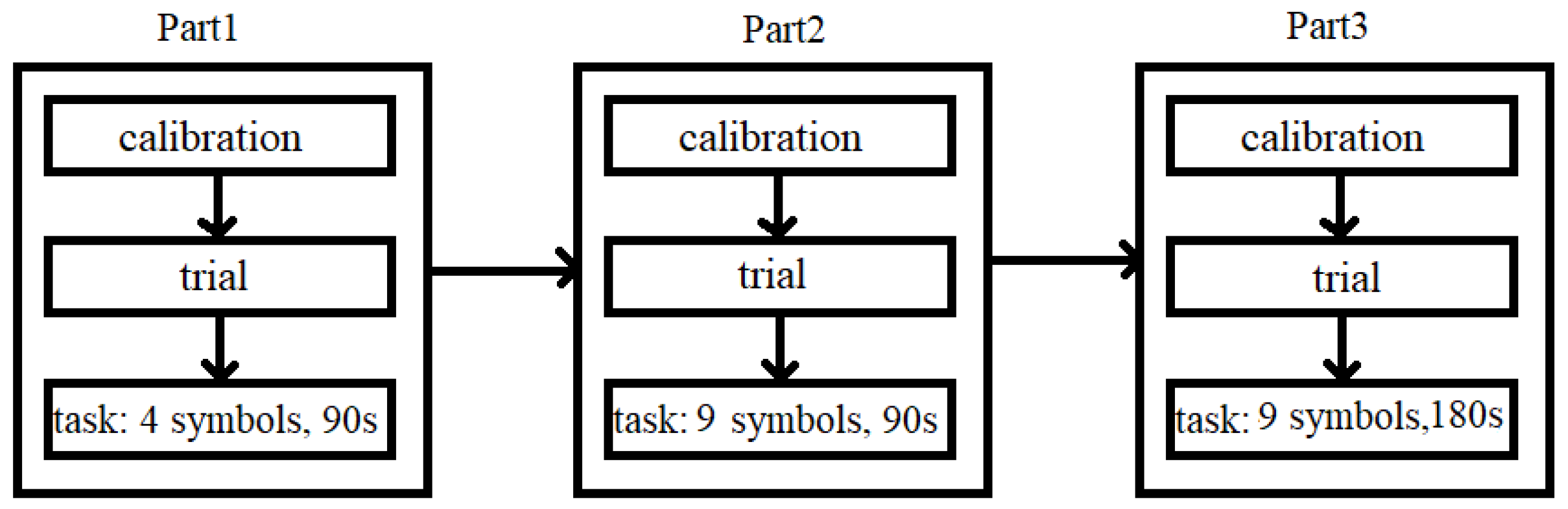
2.1. Research Procedure
2.2. Data Acquisition
2.3. Data Processing
- Response time defined as the time needed to perform a single matching in the application.
- Good response numbers understood as the number of correct answers given in a certain time period.
- Mu (µ)—corresponding to the mean of the normal component;
- Sigma (σ)—representing the symmetric standard deviation of the normal component;
- Tau (τ)—reflecting the exponential part of the distribution.
- Saccade-related features: mu of saccade amplitude, tau of saccade amplitude, mu of saccade duration, tau of saccade duration, mu of saccade number in 10 s, tau of saccade number in 10 s;
- Fixation-related features: mu of fixation duration, tau of fixation duration, mu of fixation number in 10 s, tau of fixation number in 10 s;
- Blink-related features: mu of blink number in 10 s, tau of blink number in 10 s;
- DSST-related measures: mu of correct answers number in 10 s, tau of correct answers number in 10 s, mu of single trial response time, tau of single trial response time.
3. Results
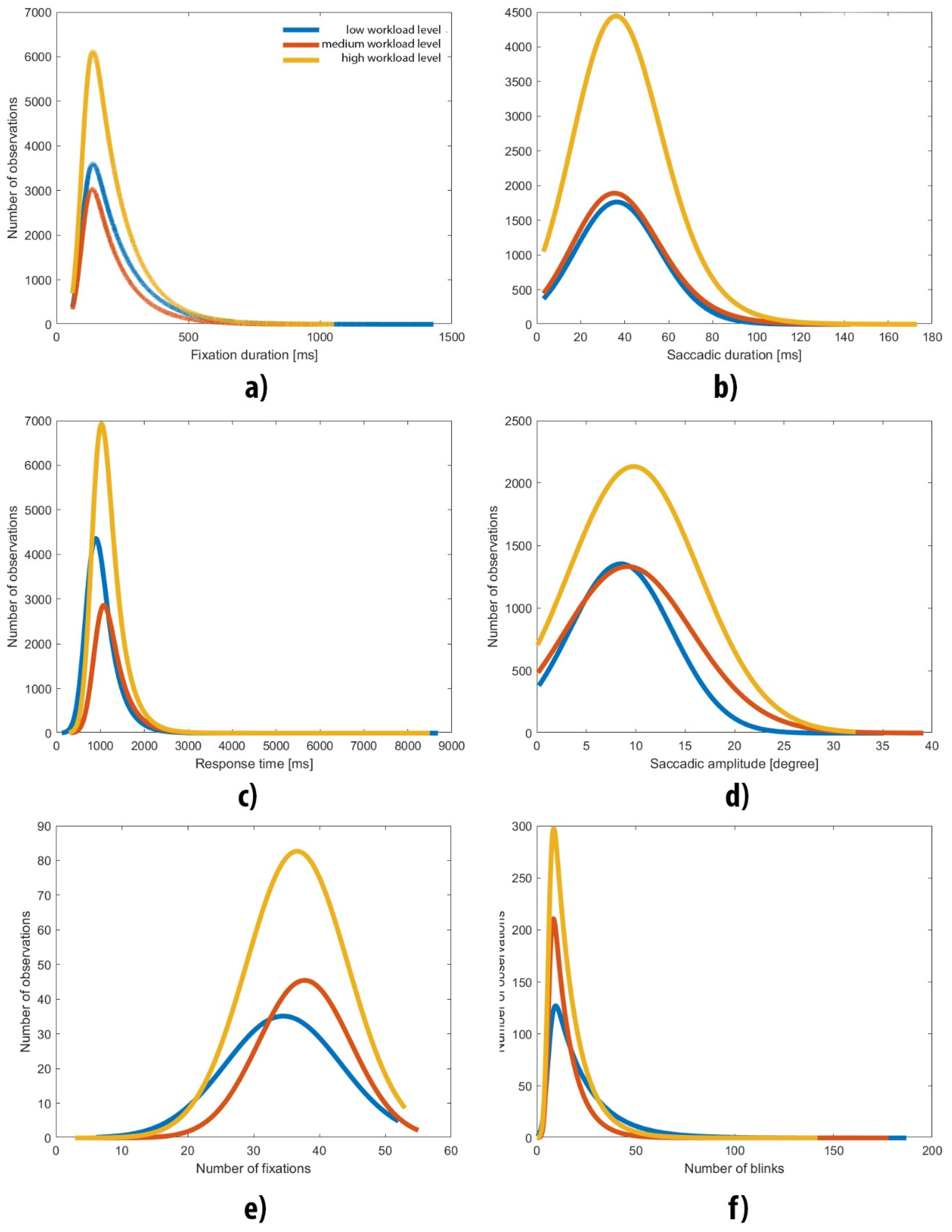
3.1. Distributional Analyses
3.2. Classification Results
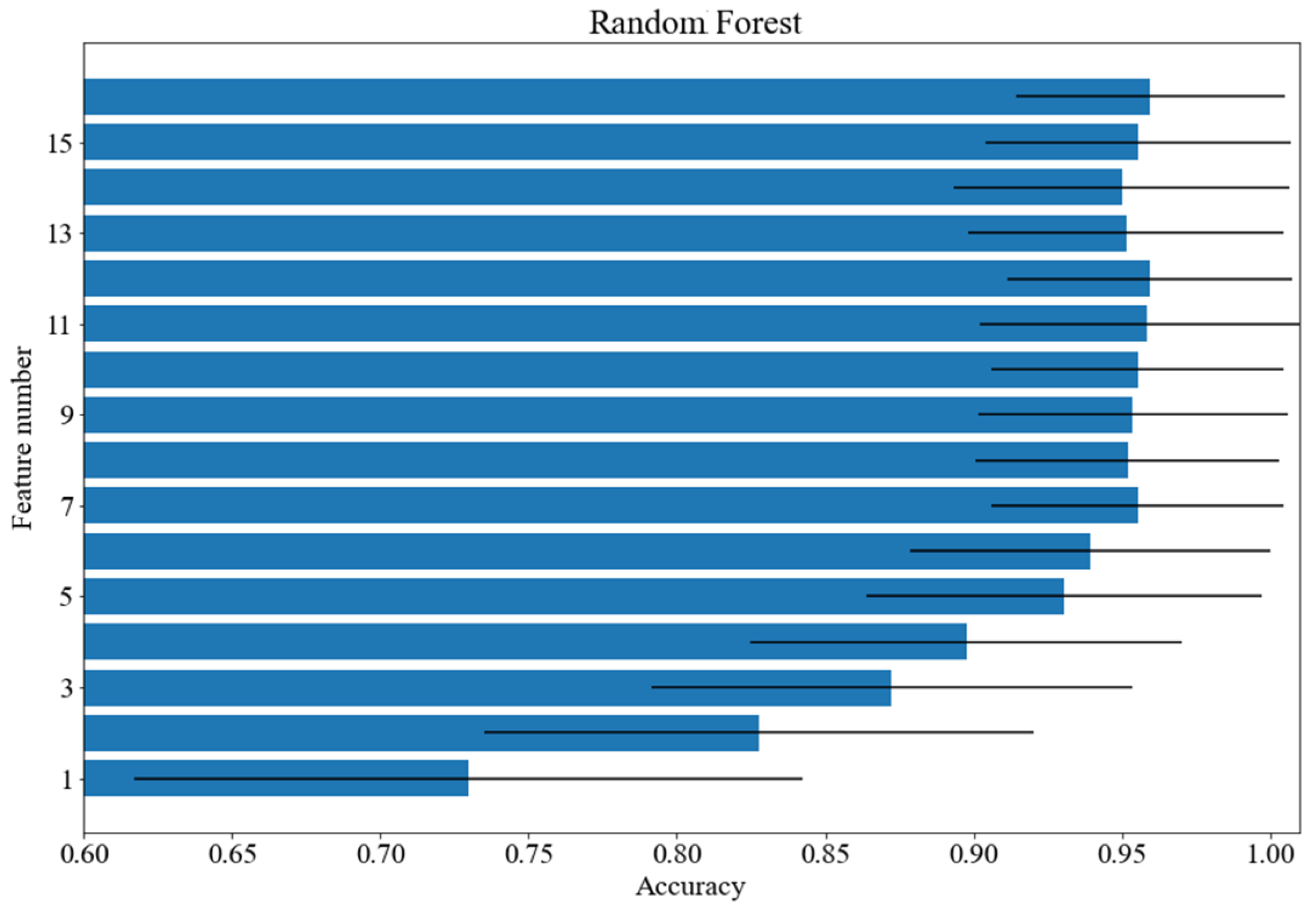
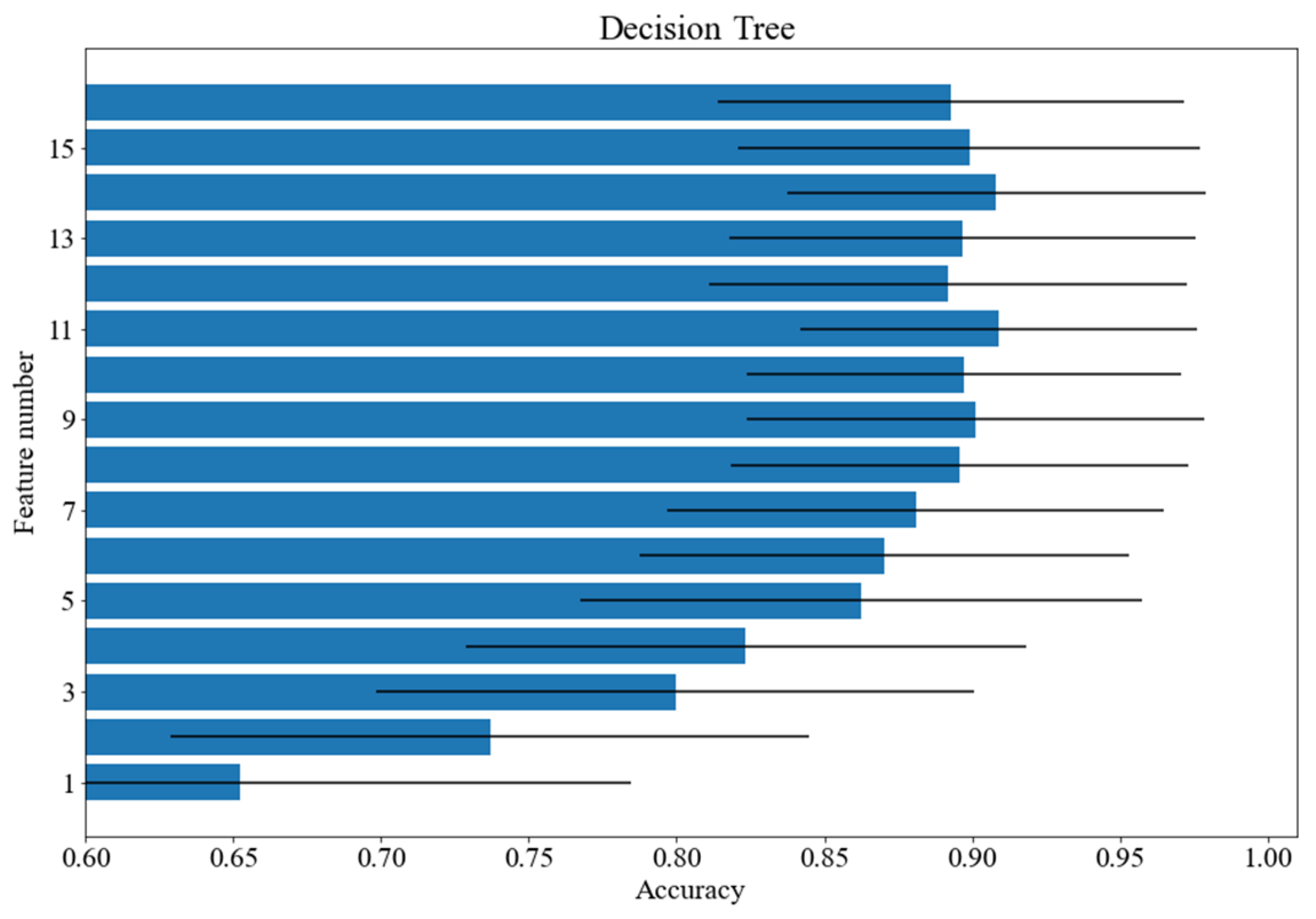
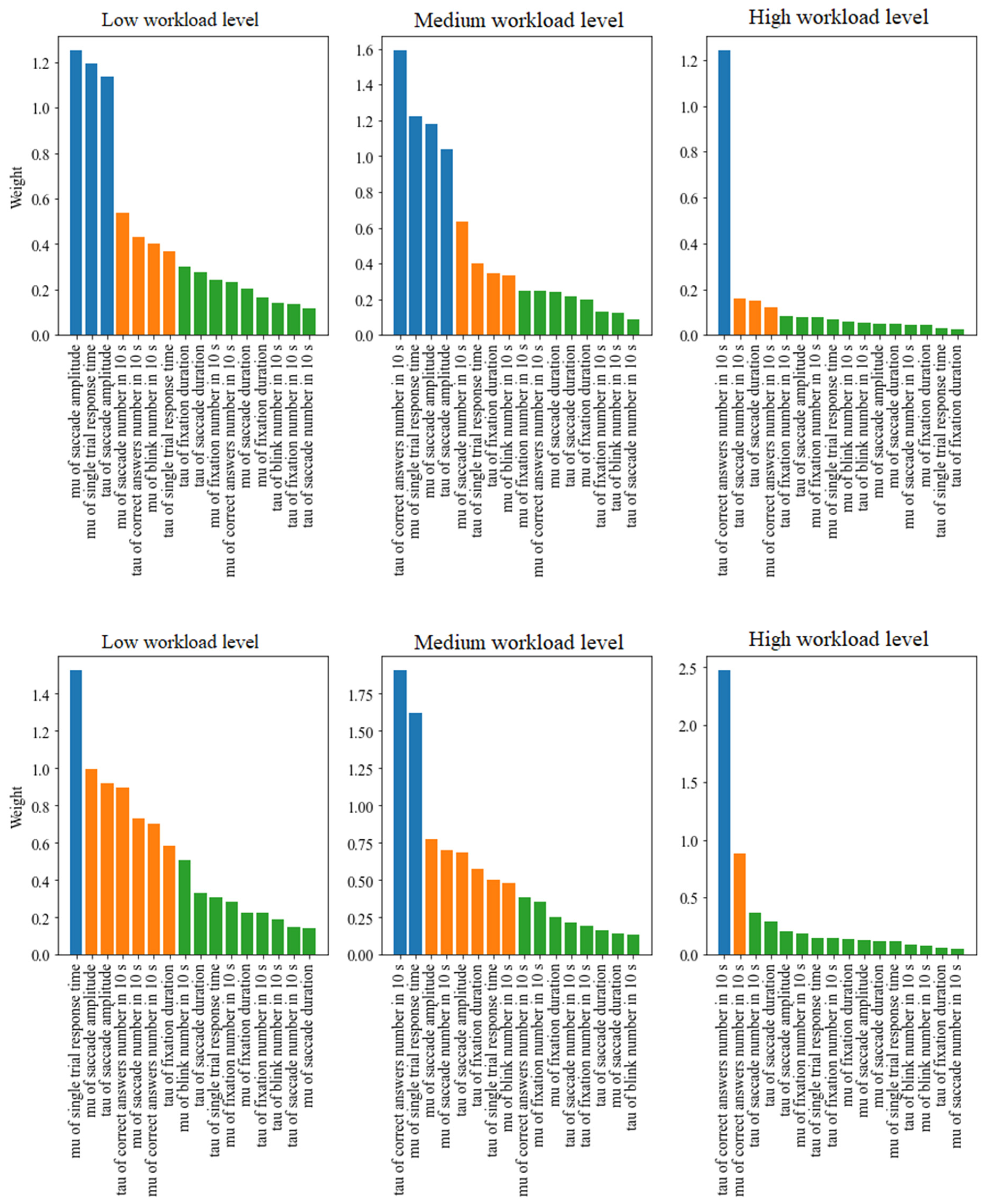
3.3. Feature Ranking
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, J.; Wang, H.; Wang, Q.; Hua, C. Exploring the fatigue affecting electroencephalography based functional brain networks during real driving in young males. Neuropsychologia 2019, 129, 200–211. [Google Scholar] [CrossRef]
- Lobo, J.L.; Ser, J.D.; De Simone, F.; Presta, R.; Collina, S.; Moravek, Z. Cognitive workload classification using eye-tracking and EEG data. In Proceedings of the International Conference on Human-Computer Interaction in Aerospace, Paris, France, 14–16 September 2016; pp. 1–8. [Google Scholar]
- Khushaba, R.N.; Kodagoda, S.; Lal, S.; Dissanayake, G. Driver drowsiness classification using fuzzy wavelet-packet-based feature-extraction algorithm. IEEE Trans. Biomed. Eng. 2010, 58, 121–131. [Google Scholar] [CrossRef] [Green Version]
- Walter, C.; Wolter, P.; Rosenstiel, W.; Bogdan, M.; Spüler, M. Towards cross-subject workload prediction. In Proceedings of the 6th International Brain-Computer Interface Conference, Graz, Austria, 16–21 September 2014. [Google Scholar]
- Thodoroff, P.; Pineau, J.; Lim, A. Learning robust features using deep learning for automatic seizure detection. In Proceedings of the Machine Learning for Healthcare Conference, Los Angeles, CA, USA, 19–20 August 2016; pp. 178–190. [Google Scholar]
- Appel, T.; Scharinger, C.; Gerjets, P.; Kasneci, E. Cross-subject workload classification using pupil-related measures. In Proceedings of the 2018 ACM Symposium on Eye Tracking Research & Applications, Warsaw, Poland, 14–17 June 2018; pp. 1–8. [Google Scholar]
- Hefron, R.; Borghetti, B.; Schubert Kabban, C.; Christensen, J.; Estepp, J. Cross-participant EEG-based assessment of cognitive workload using multi-path convolutional recurrent neural networks. Sensors 2018, 18, 1339. [Google Scholar] [CrossRef] [Green Version]
- Fridman, L.; Reimer, B.; Mehler, B.; Freeman, W.T. Cognitive load estimation in the wild. In Proceedings of the 2018 Chi Conferenceon Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; pp. 1–9. [Google Scholar]
- Hajinoroozi, M.; Mao, Z.; Jung, T.P.; Lin, C.T.; Huang, Y. EEG-based prediction of driver’s cognitive performance by deep convolutional neural network. Signal Proc. Imag. Commun. 2016, 47, 549–555. [Google Scholar] [CrossRef]
- Wang, Z.; Hope, R.M.; Wang, Z.; Ji, Z.; Gray, W.D. Cross-subject workload classification with a hierarchical Bayes model. NeuroImage 2012, 59, 64–69. [Google Scholar] [CrossRef]
- Jimnez-Guarneros, M.; Gomez-Gil, P. Custom Domain Adaptation: A new method for cross-subject, EEG-based cognitive load recognition. IEEE Sign. Proc. Let. 2020, 27, 750–754. [Google Scholar] [CrossRef]
- Nuamah, J.K.; Seong, Y. Support vector machine (SVM) classification of cognitive tasks based on electroencephalography (EEG) engagement index. Br. Comput. Interf. 2017, 5, 1–12. [Google Scholar] [CrossRef]
- Atasoy, H.; Yildirim, E. Classification of Verbal and Quantitative Mental Tasks Using Phase Locking Values between EEG Signals. Int. J. Signal Process. Image Process. Pattern Recognit. 2016, 9, 383–390. [Google Scholar] [CrossRef]
- Yamada, Y.; Kobayashi, M. Detecting mental fatigue from eye-tracking data gathered while watching video: Evaluation in younger and older adults. Artif. Intell. Med. 2018, 91, 39–48. [Google Scholar] [CrossRef]
- Zarjam, P.; Epps, J.; Chen, F.; Lovell, N.H. Estimating cognitive workload using wavelet entropy-based features during an arithmetic task. Comput. Biol. Med. 2013, 43, 2186–2195. [Google Scholar] [CrossRef]
- Işbilir, E.; Çakır, M.P.; Acartürk, C.; Tekerek, A. Şimcek Towards a Multimodal Model of Cognitive Workload Through Synchronous Optical Brain Imaging and Eye Tracking Measures. Front. Hum. Neurosci. 2019, 13, 375. [Google Scholar] [CrossRef] [PubMed]
- Ziegler, M.D.; Kraft, A.; Krein, M.; Lo, L.-C.; Hatfield, B.; Casebeer, W.; Russell, B. Sensing and Assessing Cognitive Workload Across Multiple Tasks. In Proceedings of the International Conference on Augmented Cognition, Toronto, ON, Canada, 17–22 July 2016; Springer Nature: Cham, Switzerland, 2016; pp. 440–450. [Google Scholar]
- Almogbel, M.A.; Dang, A.H.; Kameyama, W. EEG-signals based cognitive workload detection of vehicle driver using deep learning. In Proceedings of the 2018 20th International Conference on Advanced Communication Technology (ICACT), Chuncheon, Korea, 11–14 February 2018; pp. 256–259. [Google Scholar]
- McKendrick, R.; Feest, B.; Harwood, A.; Falcone, B. Theories and Methods for Labeling Cognitive Workload: Classification and Transfer Learning. Front. Hum. Neurosci. 2019, 13, 295. [Google Scholar] [CrossRef]
- Luce, R.D. Response Times: Their Role in Inferring Elementary Mental Organization (No. 8); Oxford University Press on Demand: Oxford, UK, 1986. [Google Scholar]
- Matzke, D.; Wagenmakers, E.J. Psychological interpretation of the ex-Gaussian and shifted Wald parameters: A diffusion model analysis. Psychon. Bull. Rev. 2009, 16, 798–817. [Google Scholar] [CrossRef] [PubMed]
- Lacouture, Y.; Cousineau, D. How to use MATLAB to fit the ex-Gaussian and other probability functions to a distribution of response times. Tutor. Quant. Methods Psychol. 2008, 4, 35–45. [Google Scholar] [CrossRef]
- Gmehlin, D.; Fuermaier, A.B.; Walther, S.; Debelak, R.; Rentrop, M.; Westermann, C.; Sharma, A.; Tucha, L.; Koerts, J.; Tucha, O.; et al. Intraindividual variability in inhibitory function in adults with ADHD—An ex-Gaussian approach. PLoS ONE 2014, 9, e112298. [Google Scholar] [CrossRef]
- Thomson, D.R.; Seli, P.; Besner, D.; Smilek, D. On the link between mind wandering and task performance over time. Conscious. Cogn. 2014, 27, 14–26. [Google Scholar] [CrossRef]
- Krukow, P.; Jonak, K.; Karpiński, R.; Karakuła-Juchnowicz, H. Abnormalities in hubs location and nodes centrality predict cognitive slowing and increased performance variability in first-episode schizophrenia patients. Sci. Rep. 2019, 9, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Pereira, E.J.; Gurguryan, L.; Ristic, J. Trait-Level Variability in Attention Modulates Mind Wandering and Academic Achievement. Front. Psychol. 2020, 11, 909. [Google Scholar] [CrossRef]
- Robison, M.K.; Unsworth, N. Cognitive and contextual correlates of spontaneous and deliberate mind-wandering. J. Exp. Psychol. Learn. Mem. Cogn. 2018, 44, 85. [Google Scholar] [CrossRef]
- Stawarczyk, D.; D’Argembeau, A. Conjoint influence of mind-wandering and sleepiness on task performance. J. Exp. Psychol. Hum. Percept. Perform. 2016, 42, 1587. [Google Scholar] [CrossRef] [Green Version]
- Killingsworth, M.; Gilbert, T. A wandering mind is an unhappy mind. Science 2010, 330, 932. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Moukhtarian, T.R.; Reinhard, I.; Morillas-Romero, A.; Ryckaert, C.; Mowlem, F.; Bozhilova, N.; Moran, P.; Ebner-Priemer, U.; Asherson, P. Wandering minds in attention-deficit/hyperactivity disorder and borderline personality disorder. Eur. Neuropsychopharmacol. 2020, 38, 98–109. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Nomi, J.S.; Uddin, L.Q.; Duan, X.; Chen, H. Intrinsic functional connectivity variance and state-specific under-connectivity in autism. Hum. Brain Mapp. 2017, 38, 5740–5755. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Y.; Zhu, Y.; Nguchu, B.A.; Wang, Y.; Wang, H.; Qiu, B.; Wang, X. Dynamic Functional Connectivity Reveals Abnormal Variability and Hyper-connected Pattern in Autism Spectrum Disorder. Autism Res. 2020, 13, 230–243. [Google Scholar] [CrossRef] [PubMed]
- Koenig, J.; Kemp, A.H.; Feeling, N.R.; Thayer, J.F.; Kaess, M. Resting state vagal tone in borderline personality disorder: A meta-analysis. Prog. Neuropsychopharmacol. Biol. Psychiatry 2016, 64, 18–26. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Spangler, D.P.; Williams, D.P.; Speller, L.F.; Brooks, J.R.; Thayer, J.F. Resting heart rate variability is associated with ex-Gaussian metrics of intra-individual reaction time variability. Int. J. Psychophysiol. 2018, 125, 10–16. [Google Scholar] [CrossRef]
- Karakula-Juchnowicz, H.; Gałęcka, M.; Rog, J.; Bartnicka, A.; Łukaszewicz, Z.; Krukow, P.; Morylowska-Topolska, J.; Skonieczna-Zydecka, K.; Krajka, T.; Jonak, K.; et al. The food-specific serum IgG reactivity in major depressive disorder patients, irritable bowel syndrome patients and healthy controls. Nutrients 2018, 10, 548. [Google Scholar] [CrossRef] [Green Version]
- Otero-Millan, J.; Troncoso, X.G.; Macknik, S.L.; Serrano-Pedraza, I.; Martinez-Conde, S. Saccades and microsaccades during visual fixation, exploration, and search: Foundations for a common saccadic generator. J. Vis. 2008, 8, 21. [Google Scholar] [CrossRef] [Green Version]
- Guy, N.; Lancry-Dayan, O.C.; Pertzov, Y. Not all fixations are created equal: The benefits of using ex-Gaussian modeling of fixation durations. J. Vis. 2020, 20, 9. [Google Scholar] [CrossRef]
- Boake, C. From the Binet-Simon to the Wechsler-Bellevue: Tracing the history of intelligence testing. J. Clin. Exp. Neuropsychol. 2002, 24, 383–405. [Google Scholar] [CrossRef]
- Rayner, K. Eye movements in reading and information processing: 20 years of research. Psychol. Bull. 1998, 124, 372–422. [Google Scholar] [CrossRef] [PubMed]
- Hessels, R.S.; Niehorster, D.C.; Nyström, M.; Andersson, R.; Hooge, I.T. Is the eye-movement field confused about fixations and saccades? A survey among 124 researchers. R. Soc. Open Sci. 2018, 5, 180502. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tobii, A.B. Tobii Studio User’s Manual. Available online: https://www.tobiipro.com/siteassets/tobii-pro/user-manuals/tobii-pro-studio-user-manual.pdf (accessed on 7 October 2020).
- Krukow, P.; Szaniawska, O.; Harciarek, M.; Plechawska-Wójcik, M.; Jonak, K. Cognitive inconsistency in bipolar patients is determined by increased intra-individual variability in initial phase of task performance. J. Affect. Disord. 2017, 210, 222–225. [Google Scholar] [CrossRef] [PubMed]
- Krukow, P.; Harciarek, M.; Morylowska-Topolska, J.; Karakuła-Juchnowicz, H.; Jonak, K. Ineffective initiation contributes to deficient verbal and non-verbal fluency in patients with schizophrenia. Cogn. Neuropsychiatry 2017, 22, 391–406. [Google Scholar] [CrossRef] [PubMed]
- Krukow, P.; Harciarek, M.; Grochowski, C.; Makarewicz, A.; Jonak, K.; Karakuła-Juchnowicz, H. What specifically contributes to disturbed non-verbal fluency in patients with bipolar disorder: Ineffective performance initiation, slowed processing or lack of the execution strategy? Psychiatry Res. 2019, 271, 15–22. [Google Scholar] [CrossRef]
- Du, M.; Liu, N.; Hu, X. Techniques for interpretable machine learning. Commun. ACM 2019, 63, 68–77. [Google Scholar] [CrossRef] [Green Version]
- Khaire, U.M.; Dhanalakshmi, R. Stability of feature selection algorithm: A review. J. King Saud Univ.-Comput. Inf. Sci. 2019, 34, 1060–1073. [Google Scholar] [CrossRef]
- Toth, A.J.; Campbell, M.J. Investigating sex differences, cognitive effort, strategy, and performance on a computerised version of the mental rotations test via eye tracking. Sci. Rep. 2019, 9, 19430. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier | Accuracy | F1 | Number of Features |
|---|---|---|---|
| Decision Tree | 90.91 (6.73) | 90.93 (6.72) | 14 |
| SVM With Linear Kernel | 91.44 (6.62) | 91.36 (6.72) | 14 |
| Logistic Regression | 90.06 (7.58) | 90.03 (7.68) | 13 |
| Random Forest | 95.97 (4.55) | 95.98 (4.52) | 16 |
| Low Cognitive Workload | Medium Cognitive Workload | High Cognitive Workload |
|---|---|---|
| mu of blink number in 10 s mu of saccade amplitude mu of saccade number in 10 s mu of single trial response time tau of correct answers number in 10 s tau of saccade amplitude tau of single trial response time | mu of blink number in 10 s mu of saccade amplitude mu of saccade number in 10 s mu of single trial response time tau of correct answers number in 10 s tau of fixation duration tau of saccade amplitude tau of single trial response times | mu of correct answers number in 10 s tau of correct answers number in 10 s tau of saccade duration tau of saccade number in 10 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kaczorowska, M.; Plechawska-Wójcik, M.; Tokovarov, M.; Krukow, P. Automated Classification of Cognitive Workload Levels Based on Psychophysiological and Behavioural Variables of Ex-Gaussian Distributional Features. Brain Sci. 2022, 12, 542. https://doi.org/10.3390/brainsci12050542
Kaczorowska M, Plechawska-Wójcik M, Tokovarov M, Krukow P. Automated Classification of Cognitive Workload Levels Based on Psychophysiological and Behavioural Variables of Ex-Gaussian Distributional Features. Brain Sciences. 2022; 12(5):542. https://doi.org/10.3390/brainsci12050542
Chicago/Turabian StyleKaczorowska, Monika, Małgorzata Plechawska-Wójcik, Mikhail Tokovarov, and Paweł Krukow. 2022. "Automated Classification of Cognitive Workload Levels Based on Psychophysiological and Behavioural Variables of Ex-Gaussian Distributional Features" Brain Sciences 12, no. 5: 542. https://doi.org/10.3390/brainsci12050542
APA StyleKaczorowska, M., Plechawska-Wójcik, M., Tokovarov, M., & Krukow, P. (2022). Automated Classification of Cognitive Workload Levels Based on Psychophysiological and Behavioural Variables of Ex-Gaussian Distributional Features. Brain Sciences, 12(5), 542. https://doi.org/10.3390/brainsci12050542