1. Introduction
Alzheimer’s disease (AD) is a progressively developing degenerative disease of the brain and nervous system. With the global escalation of the aging process, the incidence of Alzheimer’s disease is increasing every year. Elderly people with Alzheimer’s disease will experience a series of brain damages such as gradual memory loss, inconvenience of movement, decline in language expression and cognitive difficulties as the disease continues to worsen [
1]. A large number of clinical studies have shown that drug intervention and care for early AD patients can delay the development of the disease and stabilize the patient’s condition. Therefore, the early and accurate judgment of patients with suspected AD has important practical significance.
At present, researchers use machine learning and deep learning to replace traditional methods for the auxiliary diagnosis of Alzheimer’s disease [
2,
3,
4]. The methods of traditional machine learning for the classification of Alzheimer’s disease generally extract features from collected medical image data manually or semi-manually, and then send them to traditional classifiers for classification [
5,
6]. The algorithms of classification based on traditional methods mainly include two stages of feature extraction and classification, and sometimes also include feature selection and feature fusion [
7,
8,
9]. In the process of image feature extraction, there are different methods such as Histogram of Oriented Gradient (HOG), Local Binary Pattern (LBP), and Principal Component Analysis (PCA) [
10,
11]. HOG constitutes a feature by calculating and counting the gradient direction histogram of the local area of the image. LBP is an operator used to describe the local texture features of the image; it has the advantages of rotation invariance and grayscale invariance. PCA is an effective algorithm for eliminating redundancy and simplifying datasets; it can remove redundant image features [
12,
13].
The deep learning uses the characteristics of its network to extract image features, discover hidden laws from it, and then achieve classification and recognition. Therefore, deep learning has achieved breakthrough results in target detection, face recognition, image classification and other fields [
14,
15,
16,
17]. In recent years, deep learning methods for Alzheimer’s disease classification have been continuously emerging, such as: the bottom-up unsupervised learning method of Stacked Auto Encoder (SAE), Deep Boltzmann Machine (DBM), and a top-down supervised learning method of deep convolutional neural network [
18,
19,
20]. Suk et al. [
21] used DBM to extract multi-modal features from PET and MRI data in the ADNI database, and used a 3D patch to pair potential hierarchical feature representations to classify AD and NC images; they got good results. Shi et al. [
22] used a deep polynomial network (DPN) to classify AD and NC images of MRI and PET data respectively, and further proposed a multi-modal stacked deep polynomial network (MM-SDPN) to perform binary classification tasks, finally the accuracy of their experiment reached 96.93%. Recently, Tomassini et al. [
23] proposed an end-to-end 3D convolutional long short-term memory network framework (LSTM) for early diagnosis of AD from full-resolution sMRI images.
In the process of Alzheimer’s disease research, the selection of different classifiers, model structures and appropriate attention mechanisms all play a crucial role in image classification, image recognition, and image segmentation [
24]. For example, decision tree is a very common classification method [
25]. It is a tree structure, each internal node represents a judgment on an attribute, each branch represents the output of a judgment result, and finally each leaf node represents a classification result. At the same time, in order to preserve the inherent characteristics of the original image and improve the good characteristics of the image in disease detection and classification, researchers usually use the latest visual sensing equipment, which can clearly observe tens of thousands of pixels in the image [
26]. The vision sensor is the direct source of the machine vision system, it mainly consists of auxiliary equipment such as a graphics sensor and a light projector, which can obtain the original images that the machine vision system needs to process [
27]. In addition, some researchers have studied the activation functions and pooling functions of the convolutional neural network, to compare the impact on the classification performance of Alzheimer’s disease [
28,
29]. Even image preprocessing is also an effective way to improve the classification performance of subsequent experiments, including template registration of images and various image filtering [
30].
We conduct image classification of Alzheimer’s disease in order to better distinguish the difference between patients and normal people, and we are eager to apply it in clinical experiments in the future, but there are various uncertain problems in the research. Therefore, most researchers use neutrosophic statistics to expand and solve the uncertainty of various problems. Neutrosophic statistics refers to the statistical analysis of data samples with uncertainty, which is an extension of classical statistics and is suitable for situations where the data come from complex processes or uncertain environments [
31].
In the field of computer vision, the attention mechanisms can effectively extract the feature of images. The attention mechanisms have various implementations, roughly divided into soft attention and hard attention [
32,
33,
34]. The attention mechanism selects the focal position of the image, yielding more discriminative feature representations and bringing continuous performance improvements to the model. The soft attention mechanism means that when selecting information, it calculates the weighted average of the N input information instead of selecting only one information from the N information, and then inputs it into the neural network [
35]. While the hard attention mechanism refers to selecting the information in a certain position of the input sequence, such as randomly selecting a piece of information or selecting the information with the highest probability. The visual attention mechanism can be used to pay attention to key areas in the image to obtain high-level information of image features.
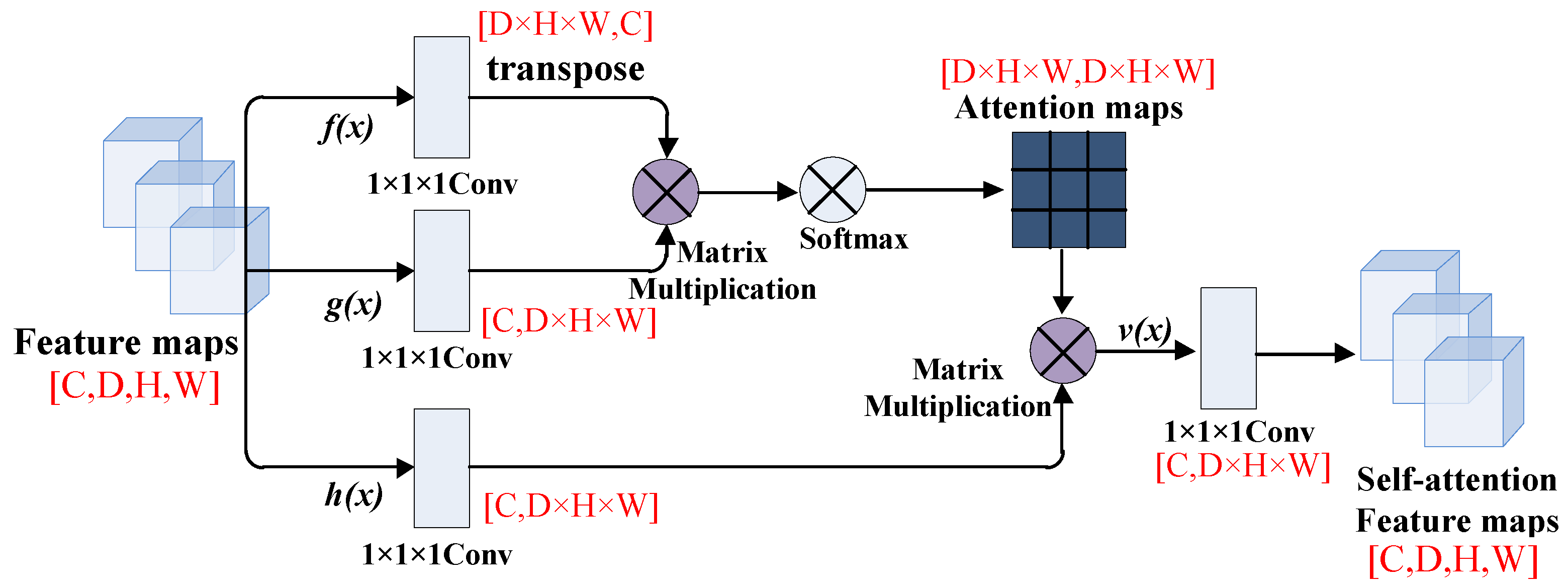
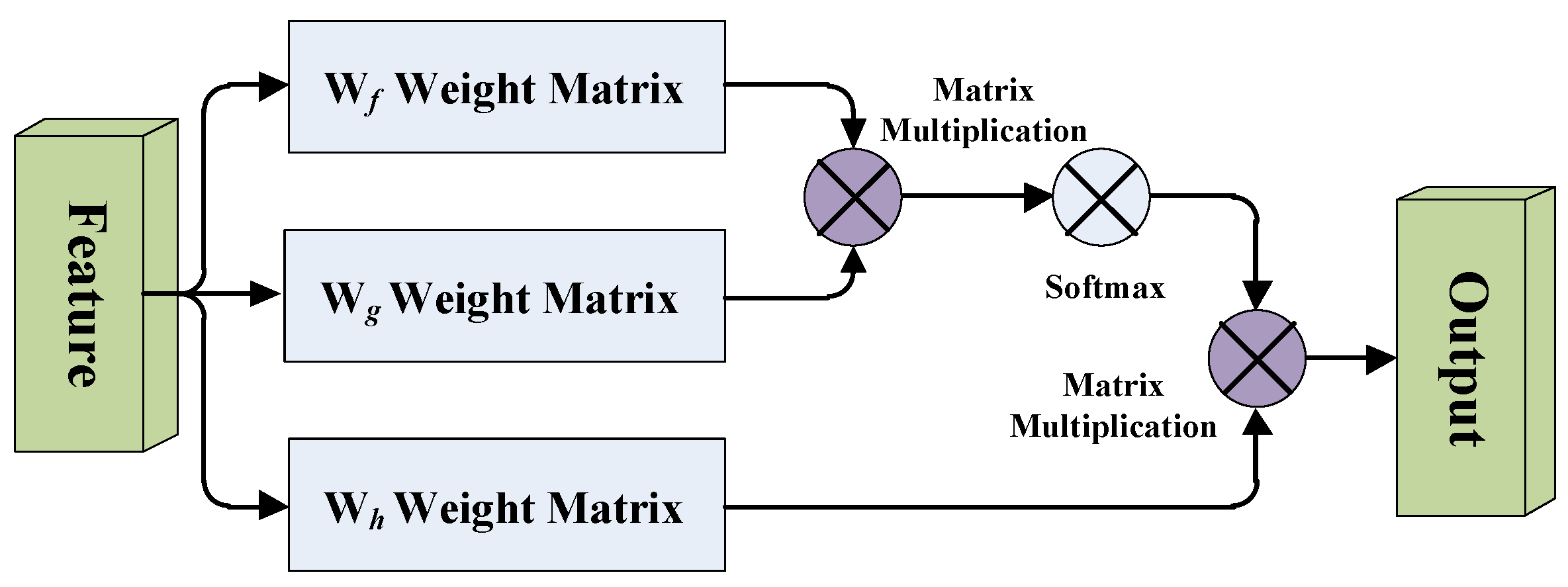
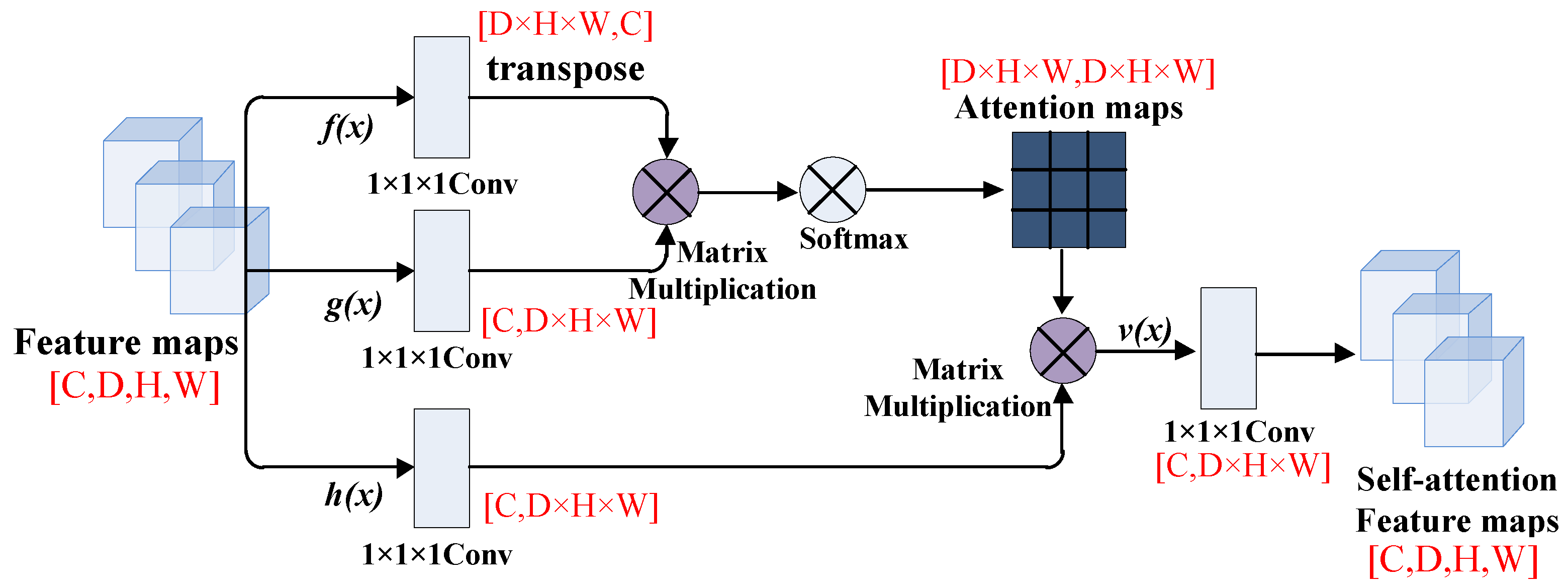
The self-attention mechanism (SA) was proposed by Zhang et al. [
36], and they used the weight matrix of three branches to capture the internal feature correlation of a single sample, thereby reducing the dependence on external information. But the self-attention mechanism has quadratic complexity and ignores the potential correlation between different samples. So, Guo et al. [
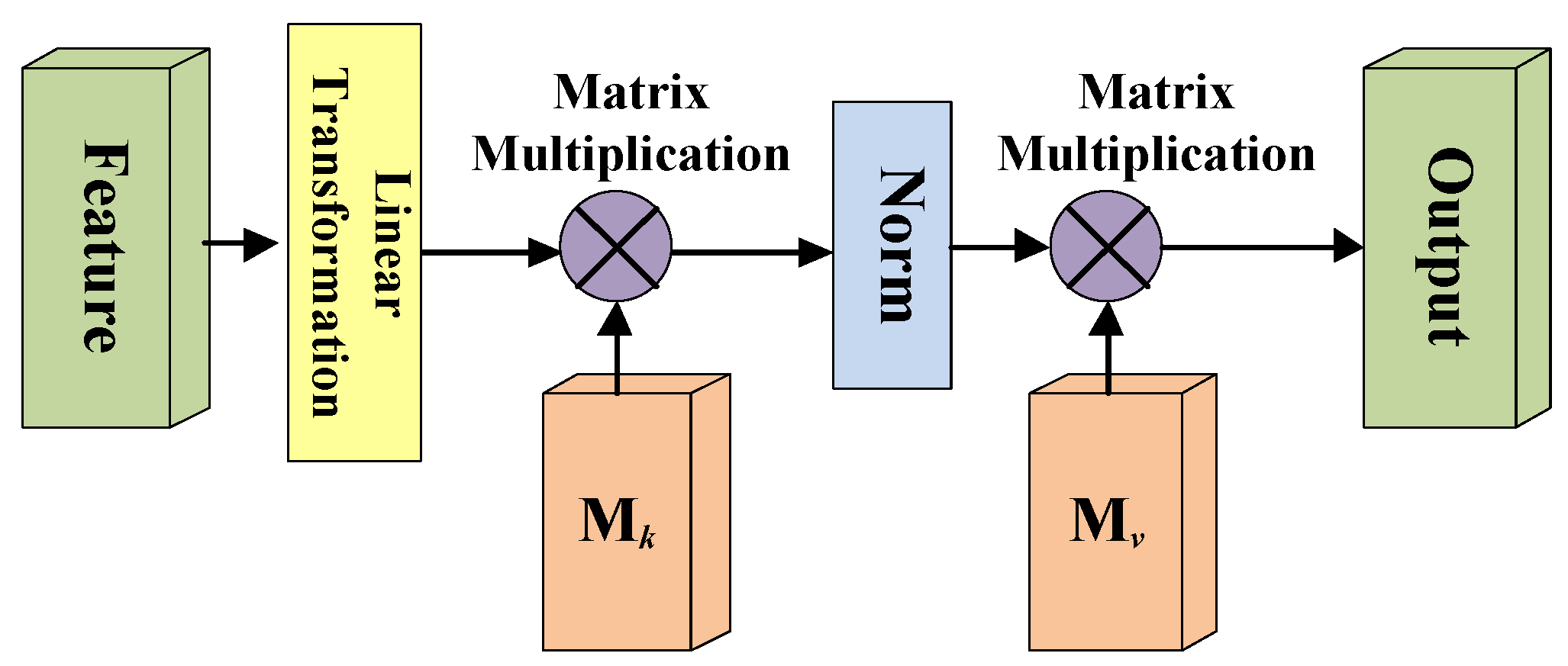
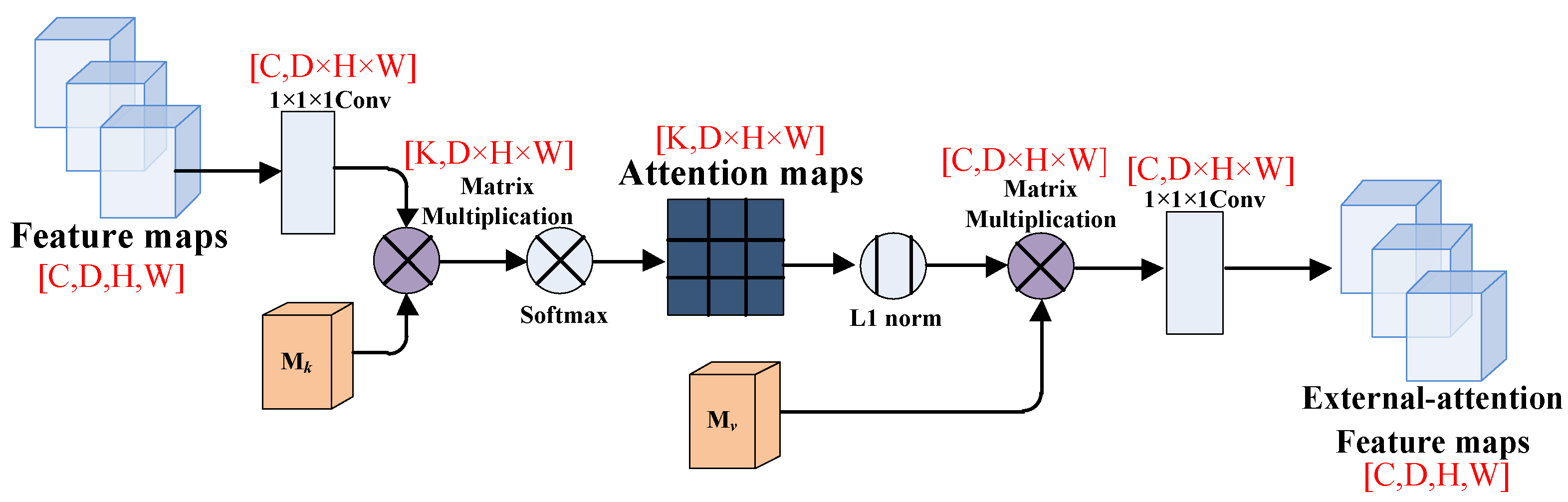
37] proposed an external attention mechanism in 2021 to solve this problem, and they adopted two external matrices, M
k and M
v, to model the potential correlation between samples. Meanwhile, the external attention mechanism has linear complexity and implicitly considers the correlation among all data samples. Recently, Jiao et al. [
38] proposed a feature fusion model for AD classification, which can comprehensively utilize multiple types of data to improve the classification performance.
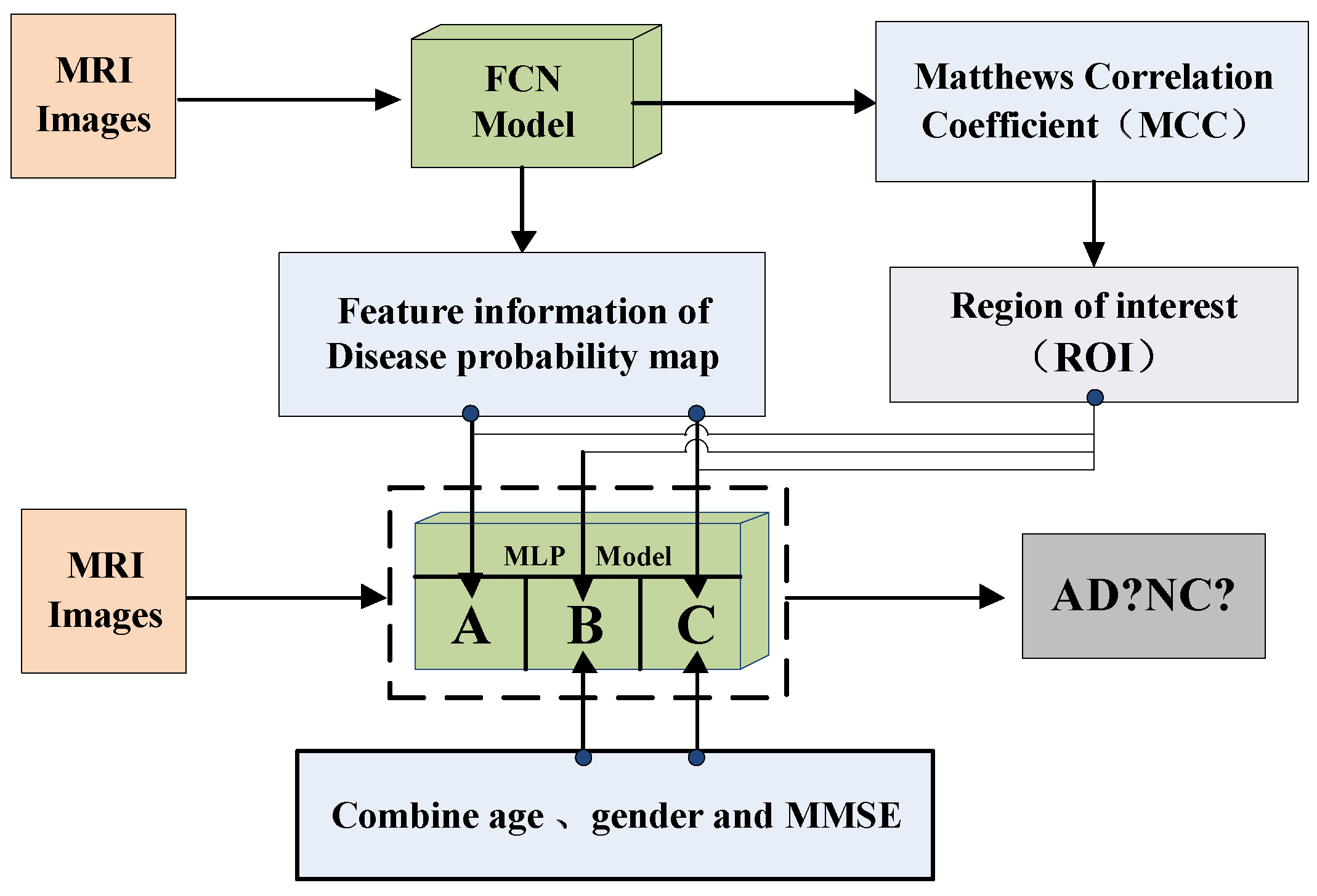
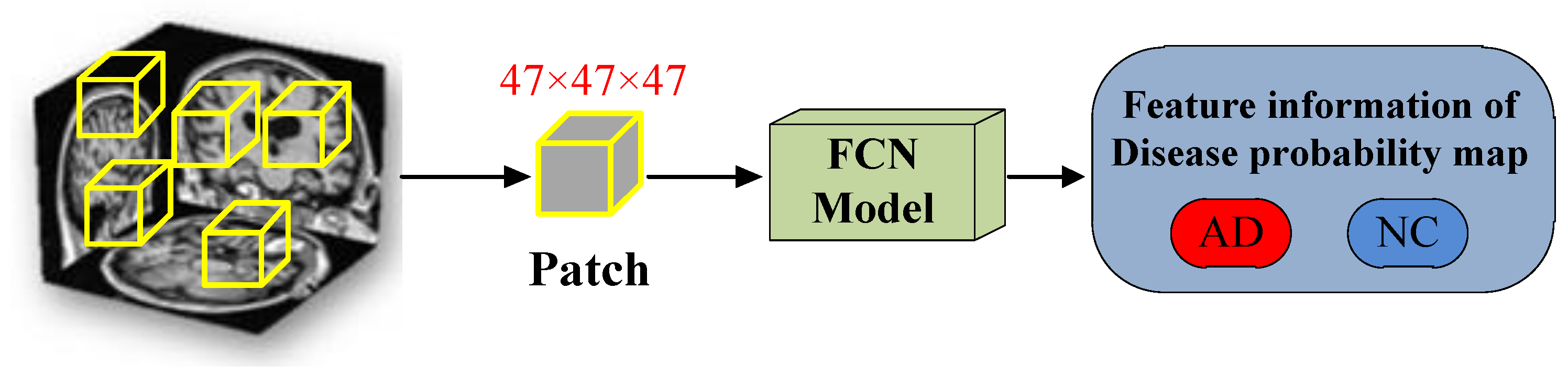
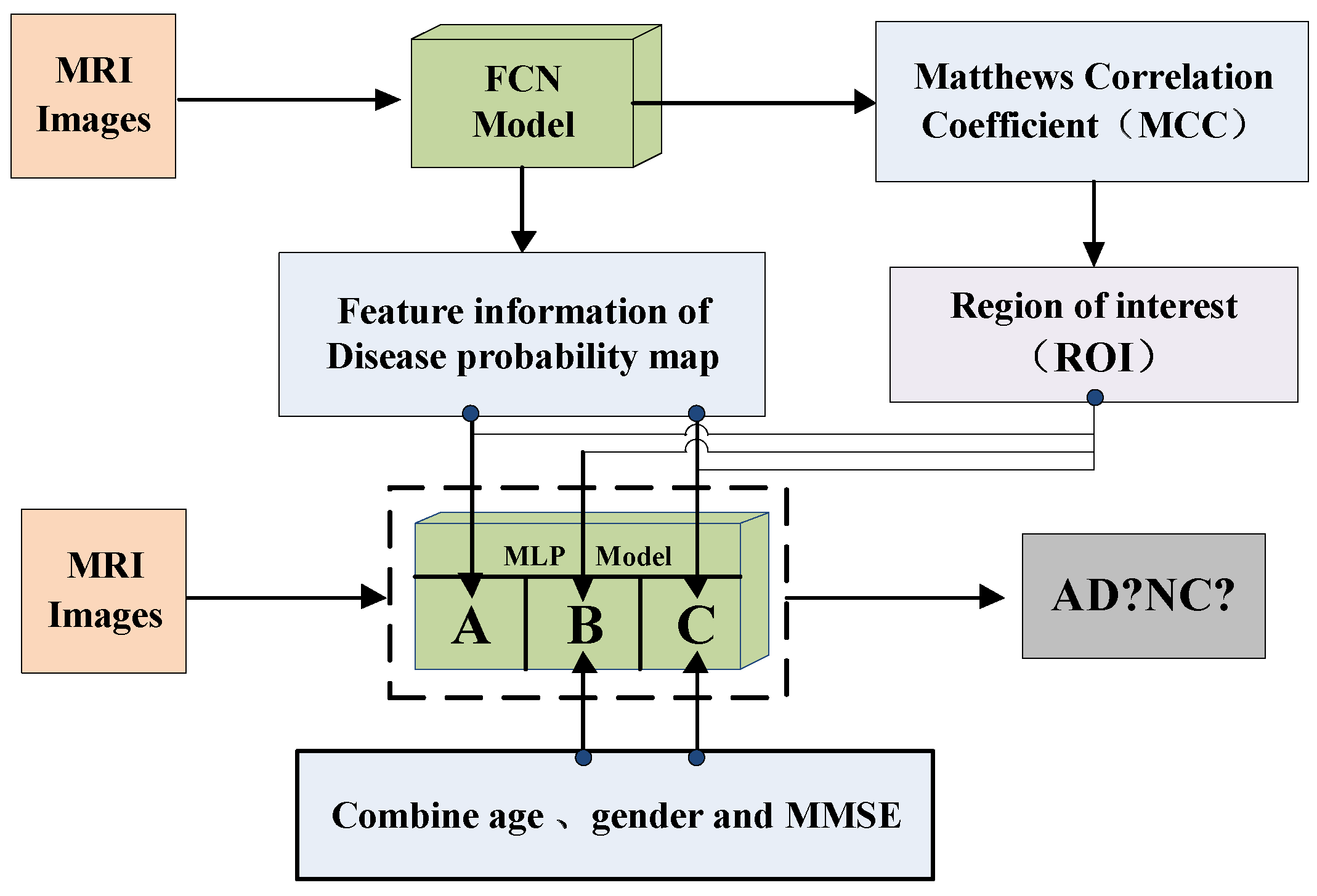
Based on the fully convolutional network, this paper proposes a new method for image classification of Alzheimer’s disease that combines the external-attention mechanism with double normalization [
39]. First, we obtain the feature information of the disease probability map through the FCN model, and then select the region of interest (ROI) according to the MCC heatmap of the FCN model, finally combine with age, gender, MMSE as the input of the MLP model to classify AD and NC images. The contributions of this paper are: (1) We propose a method for image classification of Alzheimer’s disease based on external-attention mechanism and fully convolutional network; (2) and add a self-attention module to the FCN model as a comparative experiment to highlight the effectiveness and efficiency of the external-attention mechanism; (3) In the normalization process of the attention map, the double normalization method of Softmax and L1 norm is used to replace the original Softmax, which can improve the classification performance in a small range.
3. Experiments and Results
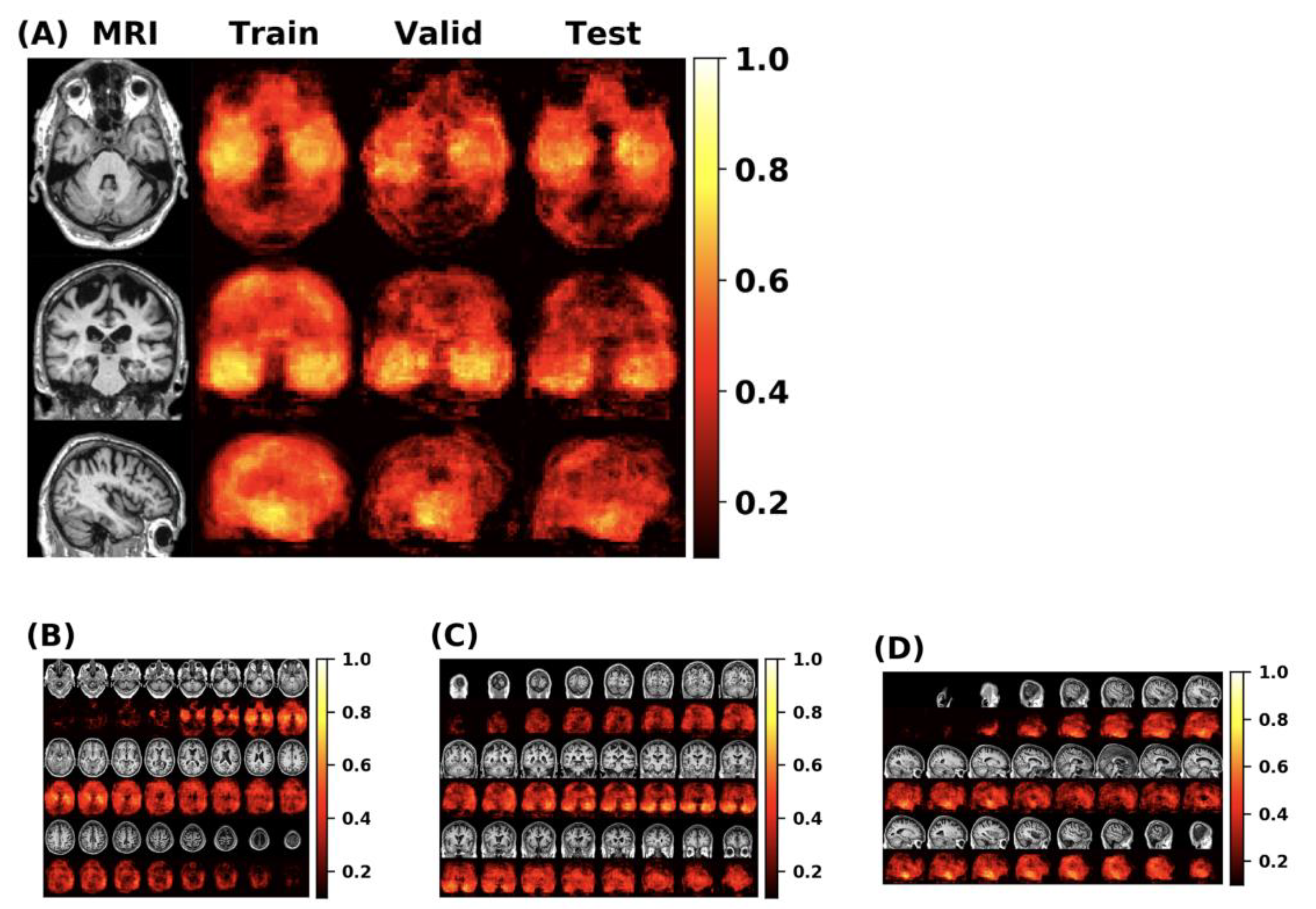
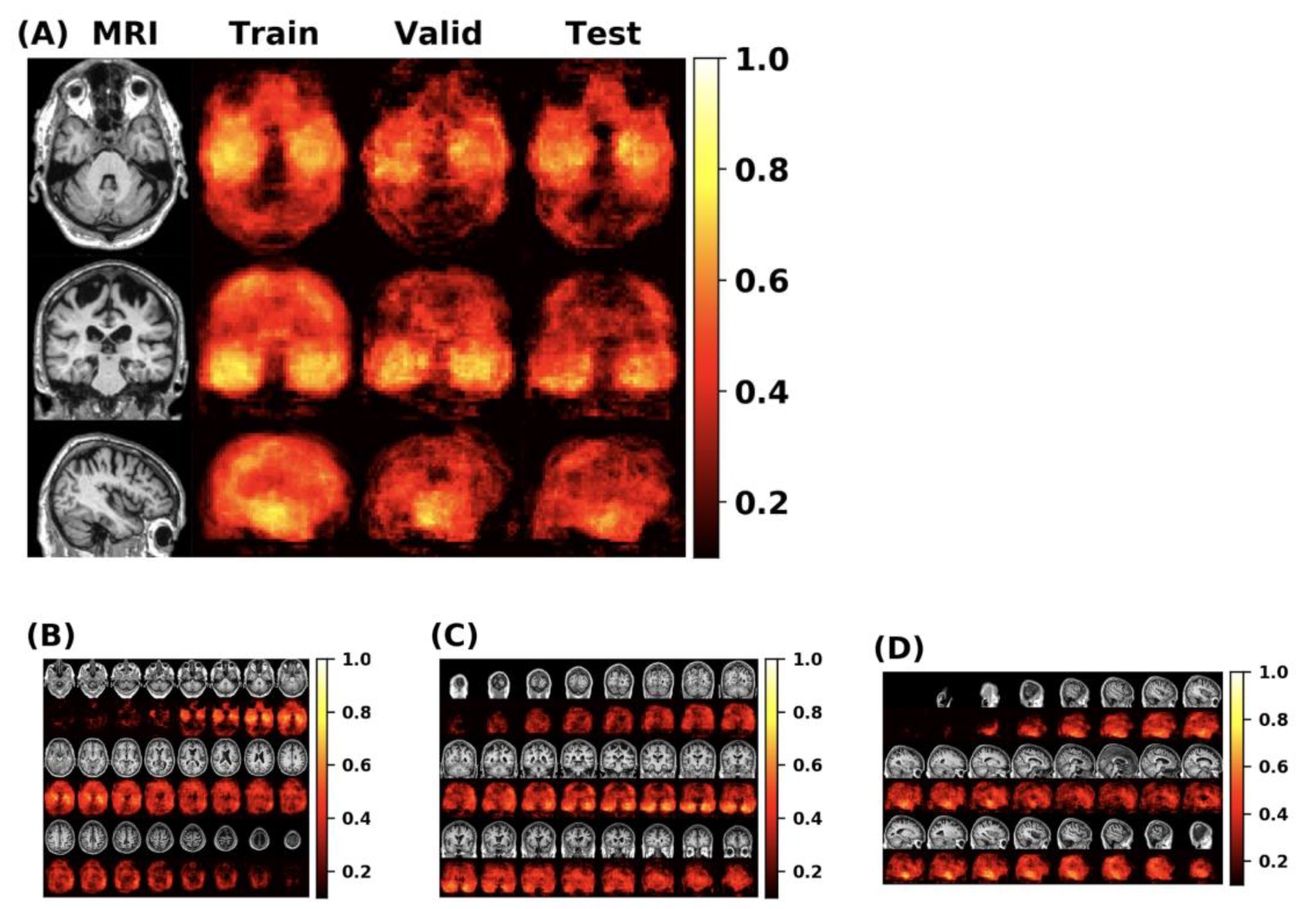
First, this paper conducts experiments on the original FCN model and MLP model, then adds the self-attention module and the external-attention module respectively for multiple experiments. Finally, we use the mean and standard deviation to represent the classification performance of the model. The double normalization of Softmax and L1 norm are used to replace Softmax in the external-attention module. The MCC heatmap of the FCN model is shown in
Figure 10.
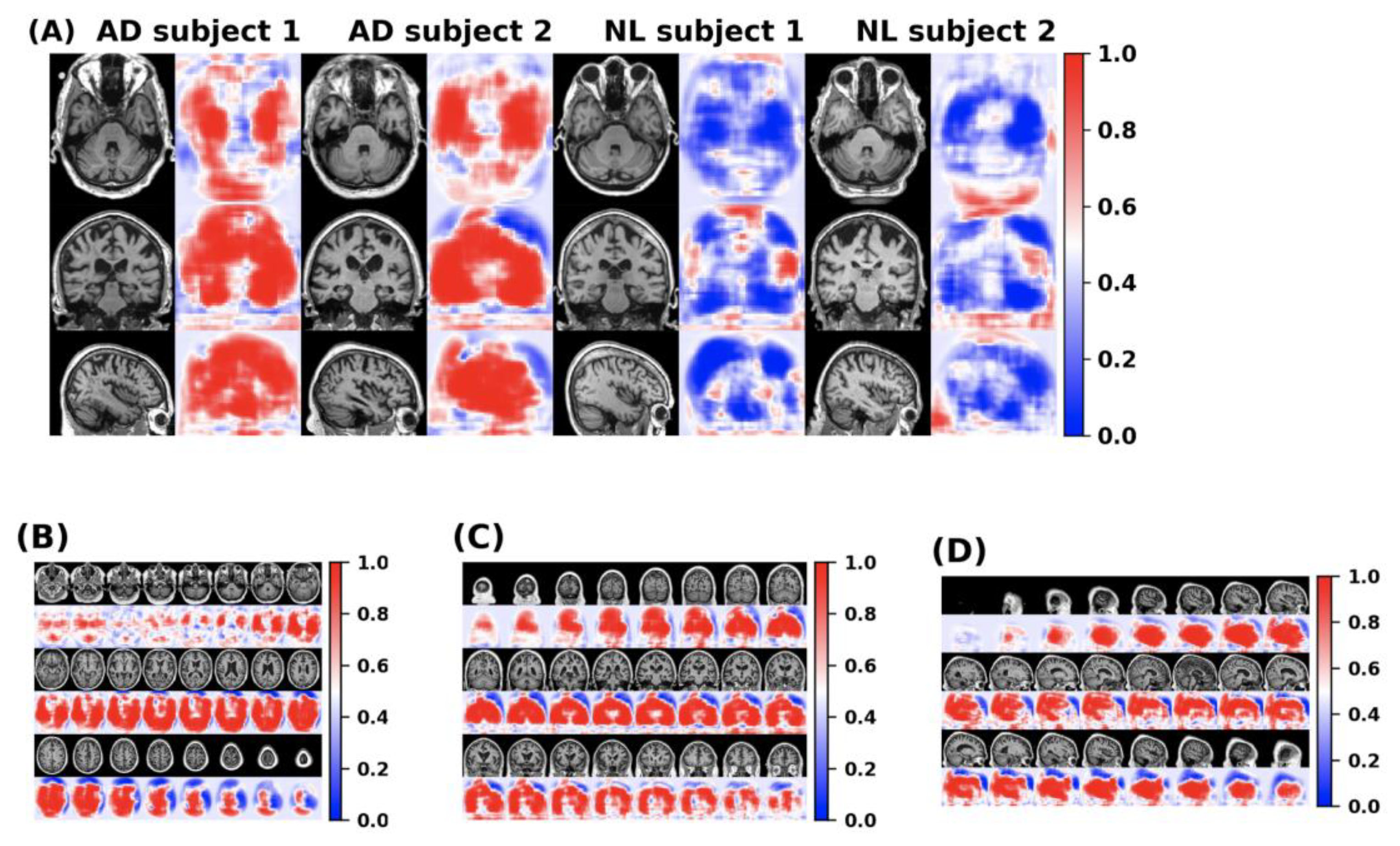
The feature information of the disease probability map generated by the FCN model is shown in the
Figure 11. Red and blue indicate the probability of suffering from Alzheimer’s disease in different parts of the brain. The dividing line between the two is 0.5.
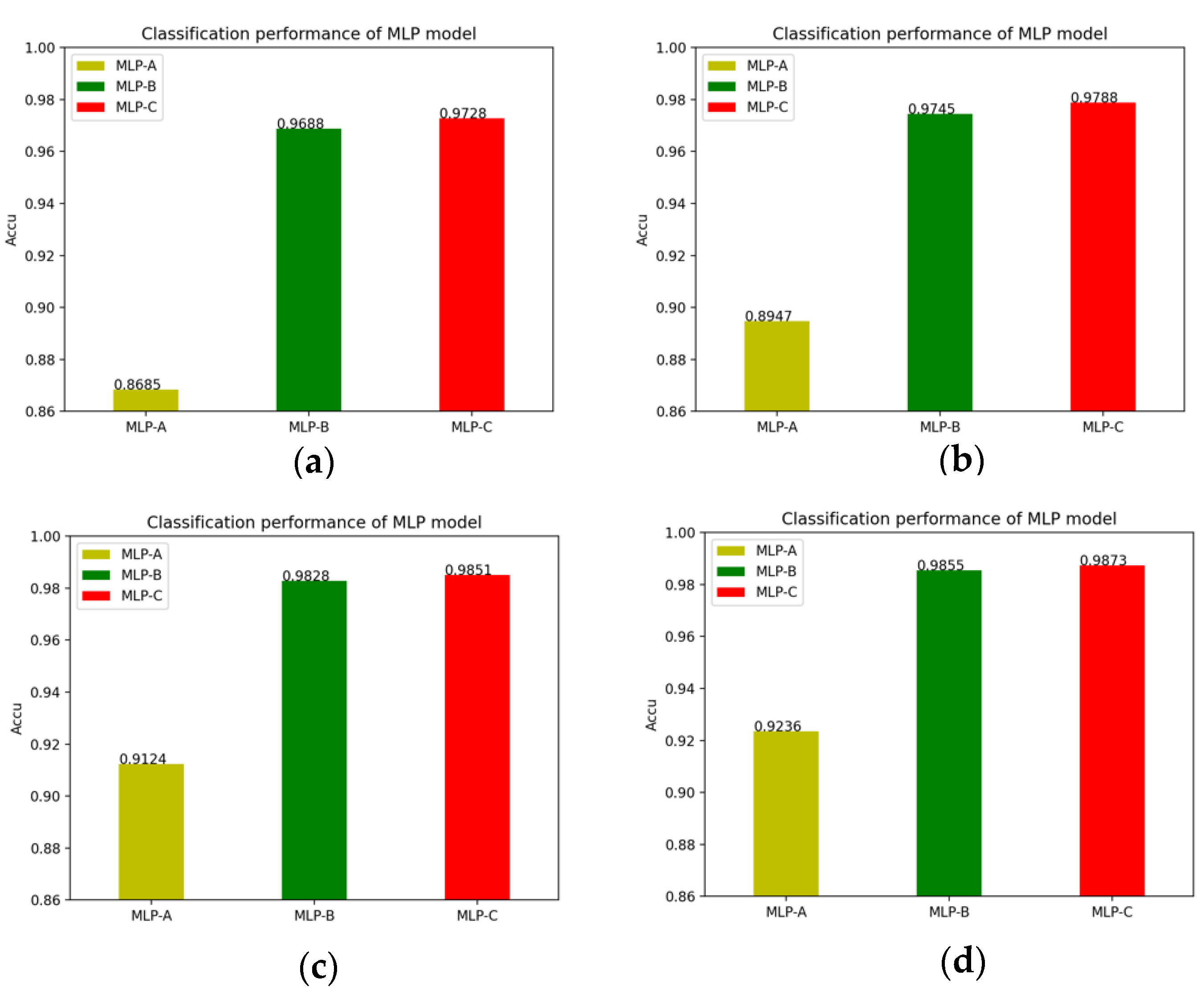
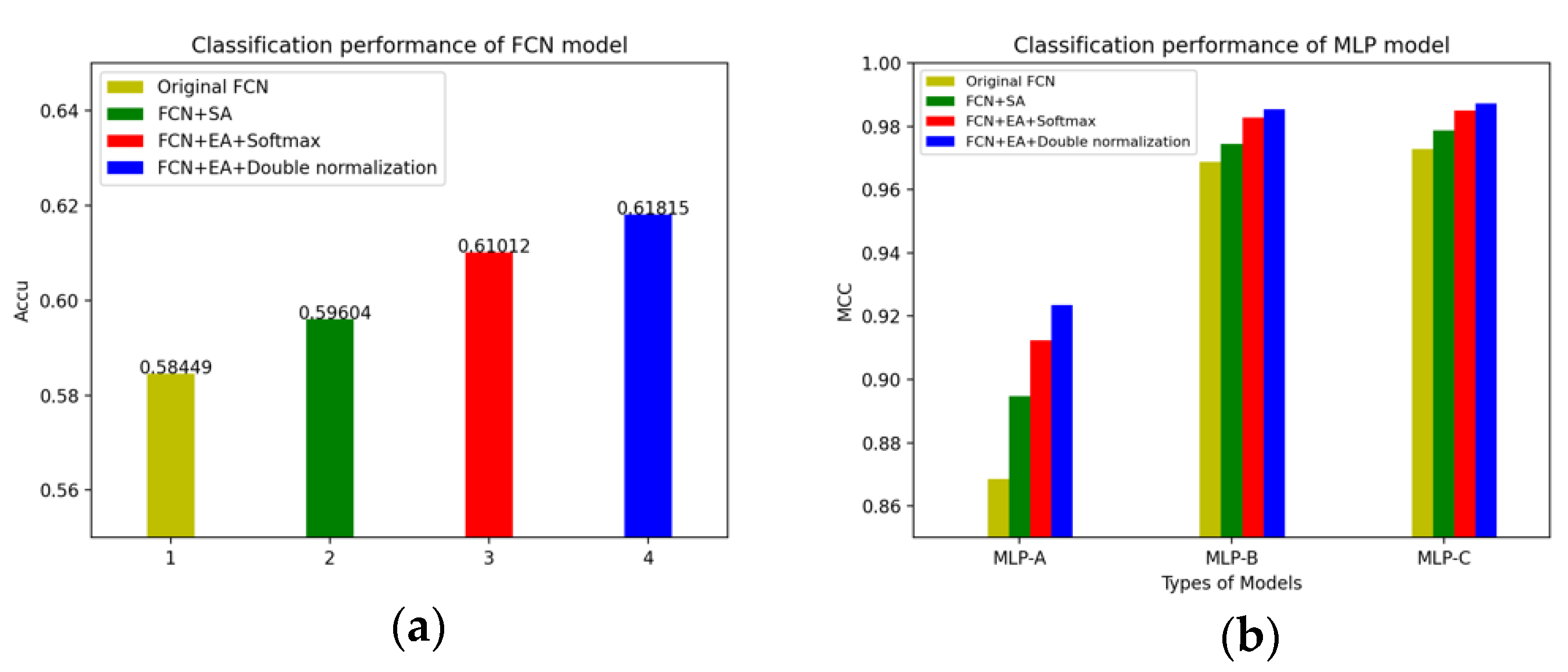
We have summarized the changes in the accuracy of the FCN models and the MLP models in different situations. The changes of the FCN models’ accuracy and the MLP models’ accuracy after adding the self-attention mechanism and the external-attention mechanism are shown in
Figure 12.
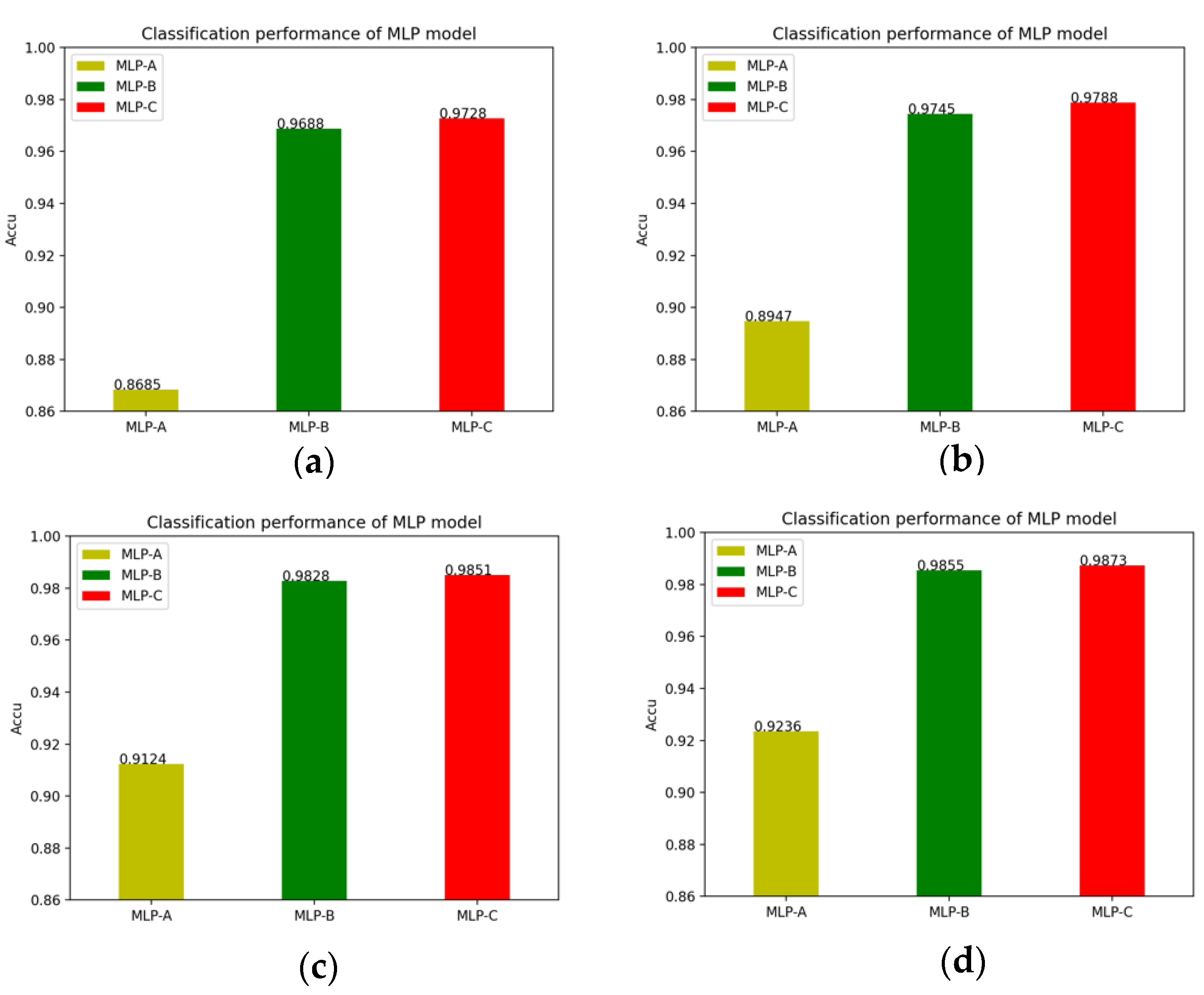
In detail, the changes of the MLP models’ accuracy after adding the self-attention mechanism and the external-attention mechanism, as well as the double normalization are shown in
Figure 13.
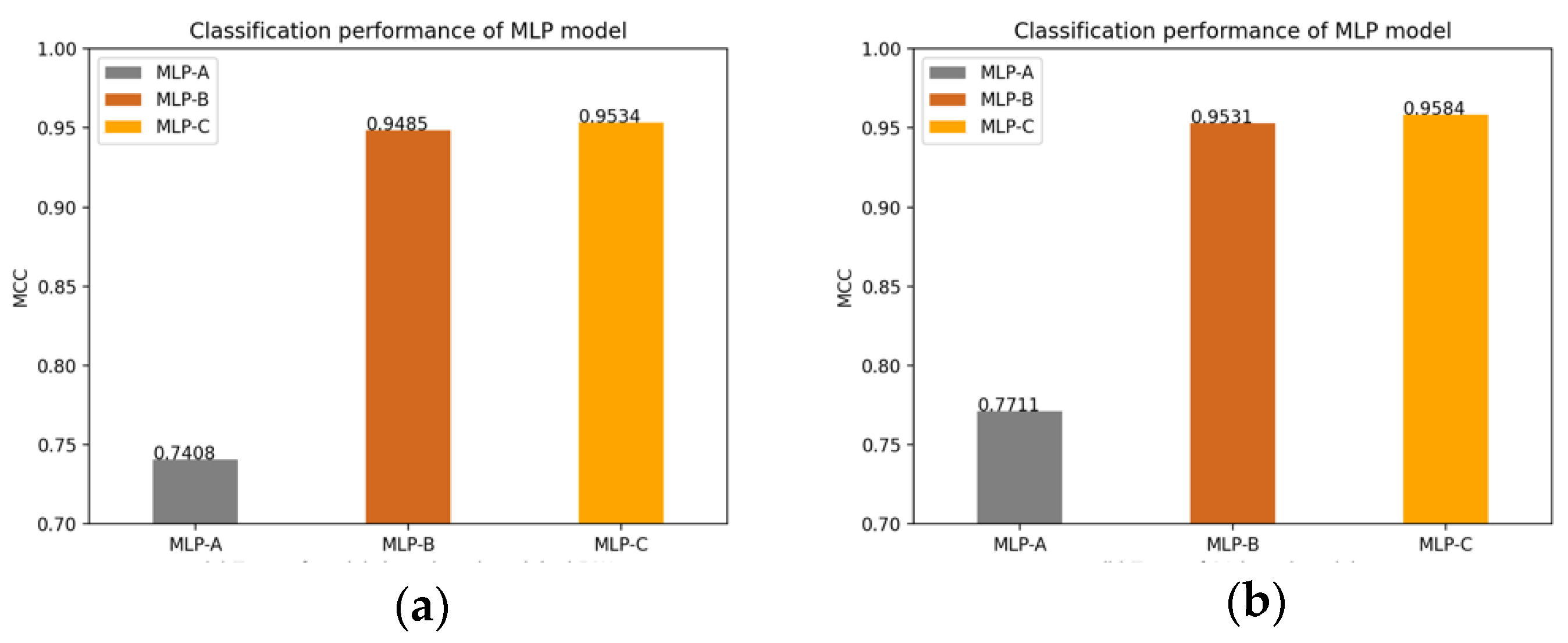
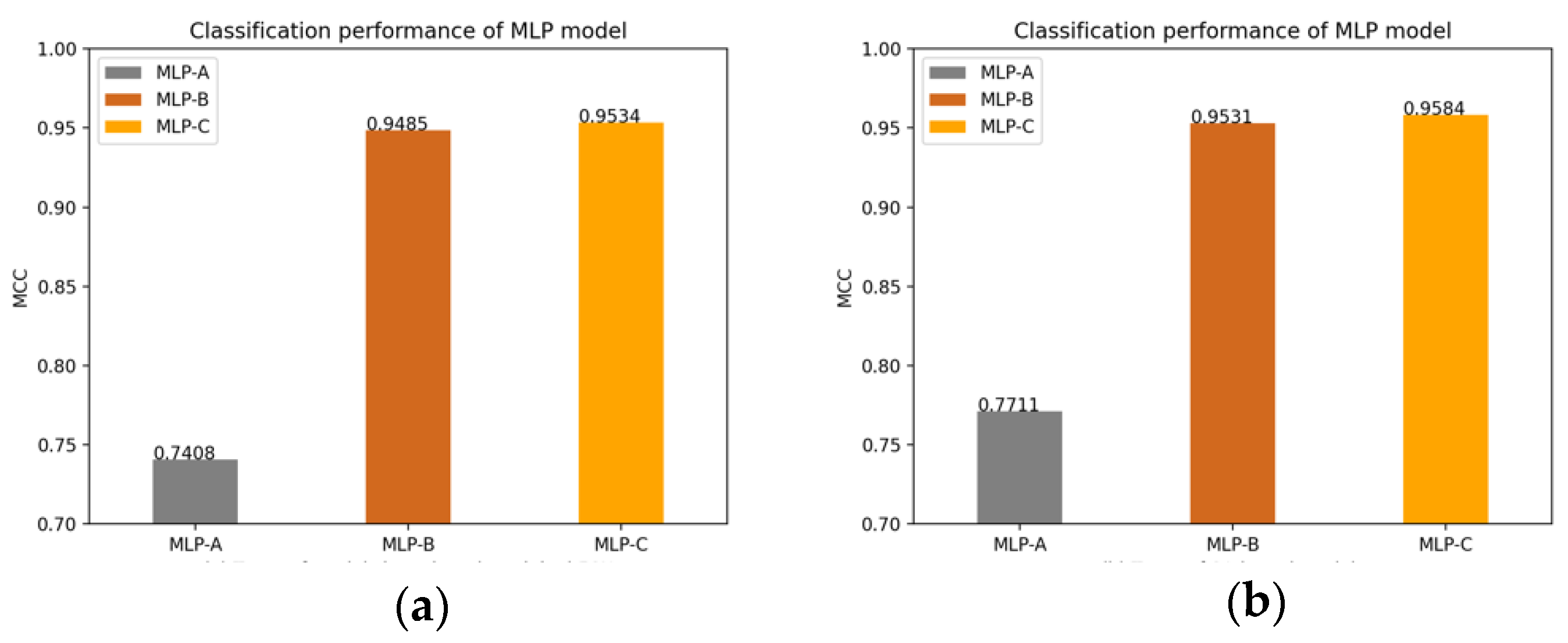
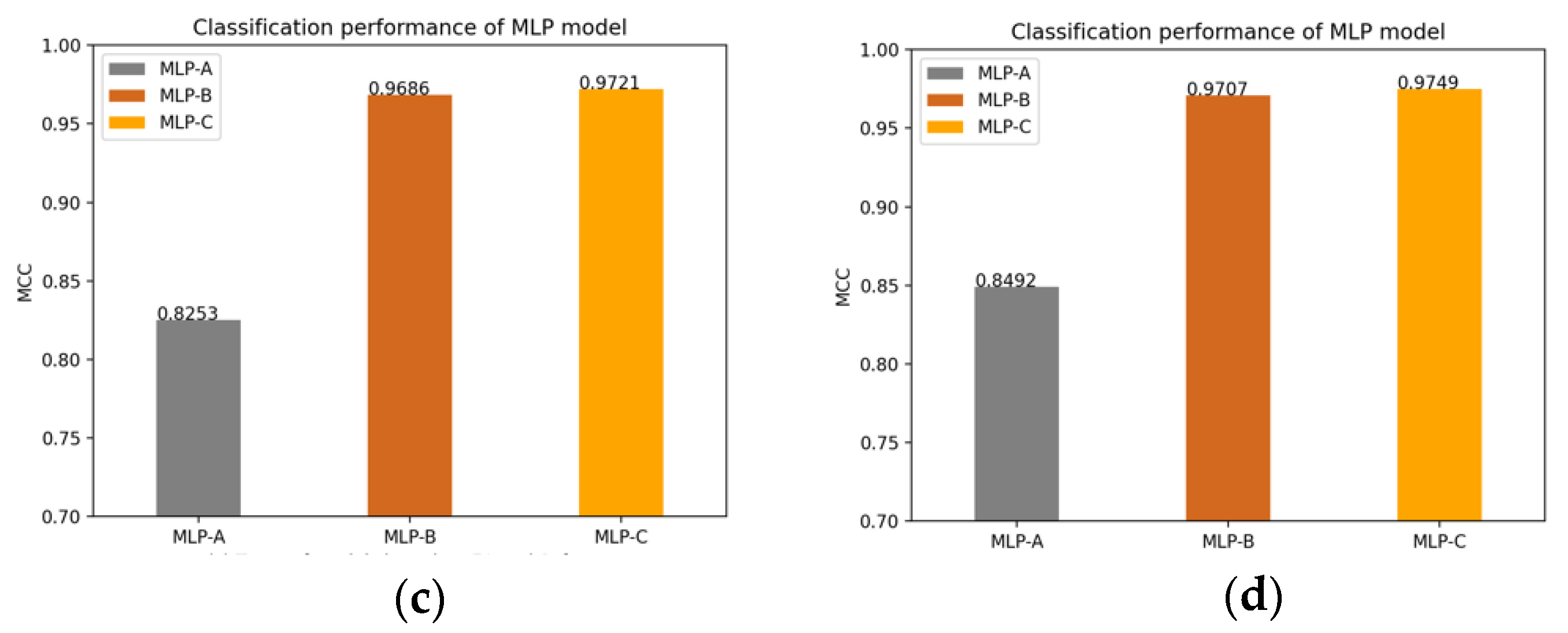
Of course, we also plot the changes of the MLP models’ MCC value after adding the self-attention mechanism, the external attention mechanism and double normalization, as shown in
Figure 14.
Next, we list the various experimental results of the FCN models and the MLP models, which are the final classification performance (mean and standard deviation), including accuracy, sensitivity, specificity, F1 score, MCC. The classification performance of the FCN model without any attention module is shown in
Table 4.
As a comparative experiment, the experimental results of the CNN model and the MLP fusion model are shown in
Table 5. Among them, the fusion model means that MLP model combines the feature information of the CNN model with age, gender, and MMSE to classify MRI images.
Comparing the experimental results of the MLP-C in
Table 4 with the fusion model in
Table 5. It can be found that selecting the region of interest (ROI) of the MLP model through the MCC heatmap of the FCN model, and combining with the feature information of the disease probability map can improve the classification performance better than the MLP fusion model.
We use accuracy and MCC to evaluate the classification performance of the FCN model, as shown in
Table 6.
At here, the MCC is calculated by using each pixel in the 3D-MRI image as a sample. After each pixel in the 3D-MRI image is trained by the FCN model, a predicted probability value of Alzheimer’s disease will be generated. The prediction of each pixel is compared with the input label, and then the corresponding pixel is marked as TP, TN, FP, FN.
The classification performance of the MLP models after adding the self-attention module is shown in
Table 7.
The results in
Table 6 show that after the self-attention module is integrated into the FCN model, the accuracy increases of about 1.155%, and the MCC value increases of about 2.454%. Comparing the experimental results in
Table 4 and
Table 7, it can be found that after adding the self-attention module, for the MLP models, the accuracy increases by about 0.57% to 2.62%, and the MCC value increases by about 0.60% to 3.03%. This shows the effectiveness of the self-attention mechanism and it can improve the classification performance of the model.
On the other hand, the experimental results in
Table 6 show that after adding the external-attention module and double normalization, compared with the original FCN model, the accuracy increases by about 3.366%, and the MCC value increases by about 5.195%. Furthermore, double normalization compares with Softmax, the accuracy increases by about 0.803%, and the MCC value increases by about 0.432%.
After adding the external-attention module, the classification performance of the MLP models by using double normalization or Softmax respectively are shown in
Table 8 and
Table 9.
Table 8 and
Table 9 compare the classification performance difference between using double normalization with only using Softmax in the external-attention mechanism. Experimental results show that double normalization can increase the accuracy of the MLP models by about 0.22% to 1.12%, and the MCC value by about 0.21% to 2.39%. This shows that double normalization can improve the classification performance in a small range, highlighting the effectiveness of double normalization.
The classification index sensitivity of the model represents the proportion of all positive samples that are paired and measures the model’s ability to discriminate against positive samples. From the experimental results, after adding an external-attention mechanism to the FCN model and combining with double normalization, the sensitivity of MLP-A model classification is 92.6%, the sensitivity of MLP-B model classification is 99.02%, and the sensitivity of MLP-C model classification is 99.29%. This also shows that our proposed model has a high discriminative ability for images of Alzheimer’s disease patients.
4. Discussion
The above experimental results show that the external-attention mechanism can generate richer feature information of a disease probability map for the MLP models, thereby improving the classification performance of the model. In addition, the MLP models combine with age, gender, and MMSE, which are more conducive to the accurate judgment of image classification, in the case of selecting the region of interest (ROI) according to the FCN model.
The reason we choose to add the self-attention module to the FCN model as a comparative experiment is because the external-attention mechanism changes the weight matrix on the basis of the self-attention mechanism. The self-attention mechanism calculates the direct interaction between any two locations, allowing the network to focus on areas that are scattered in different locations. However, this self-attention mechanism only considers the correlations within a single sample, it ignores the potential connections between samples. Therefore, the external-attention mechanism uses a learnable external matrix to establish potential correlations between samples. In addition, the Softmax in the self-attention module normalizes the attention map, but the attention map is calculated by matrix multiplication, which is sensitive to the size of the input feature and susceptible to particularly large or small feature values. Therefore, the double normalization in the external-attention module first applies Softmax to the columns, and then applies L1 norm to the rows to solve this problem. The experimental results show that after adding external-attention mechanism to the fully convolutional network and combining with double normalization, the classification performance of the MLP models is better than other comparison methods. However, due to the many unknown factors of the deep learning model, the limitation of our study is that it is difficult to quantify and visually analyze the correspondence between models and results, which makes it difficult to apply in clinical practice. Therefore, we expect further research on the interpretability of the deep learning model in order to improve the confidence of the classification results.
Finally, we compare with the models of other references on Alzheimer’s disease, as shown in
Table 10. Different classification techniques have their own advantages and disadvantages. For example, SVM uses the inner product kernel function to replace the nonlinear mapping to the high-dimensional space, and its goal is to divide the feature space into the optimal classification hyperplane [
40]. However, its disadvantage is that it is difficult to implement large-scale training samples, and it is sensitive to the choice of parameter adjustment and function.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}