
Theta Band (4–8 Hz) Oscillations Reflect Online Processing of Rhythm in Speech Production

Abstract
:1. Introduction
2. Literature Review
2.1. Structural Priming for Prosodic Representations
2.2. Electrophysiological Studies of Rhythmic Processing in Language
2.3. The Relationship between Neural Oscillations and Rhythmic Processing
2.4. The Present Study
3. Materials and Methods
3.1. Participants
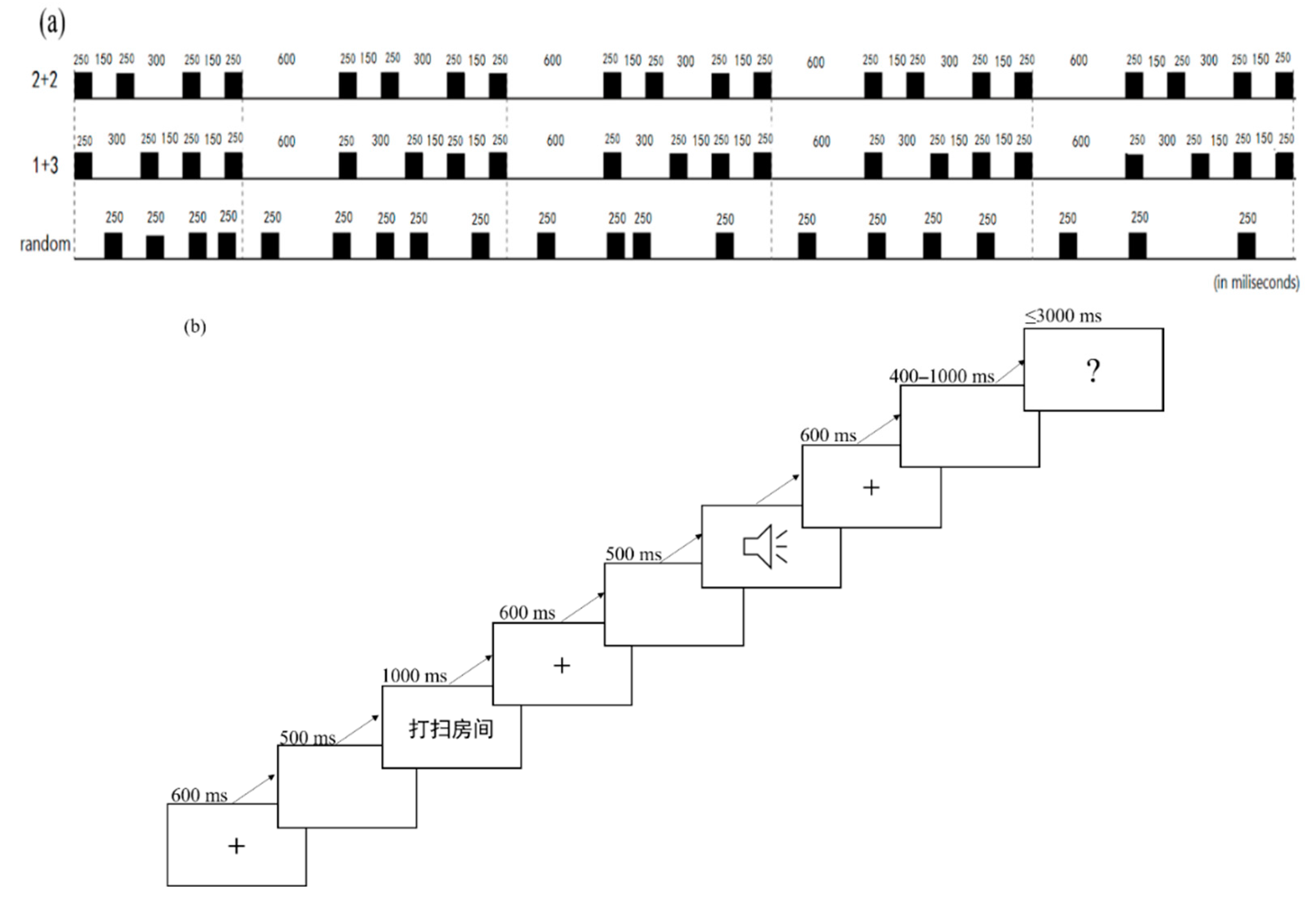
3.2. Materials
3.3. Design
3.4. Apparatus
3.5. Procedure
3.6. EEG Recordings
3.7. EEG Analysis
3.7.1. CACoh Preprocessing and Calculation
3.7.2. TFR (Time–Frequency-Representations) Preprocessing and Calculation
4. Results
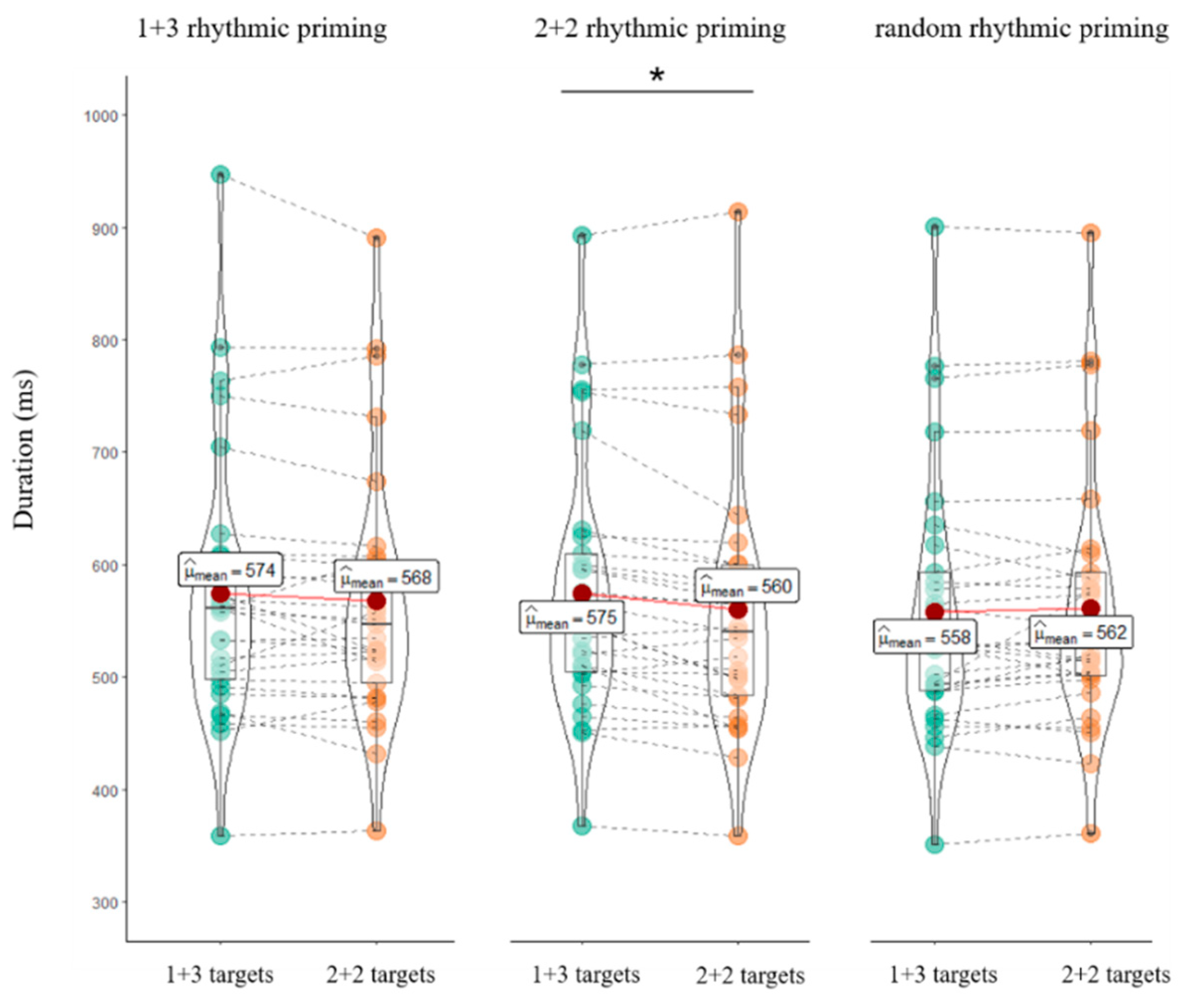
4.1. Behavioral Results
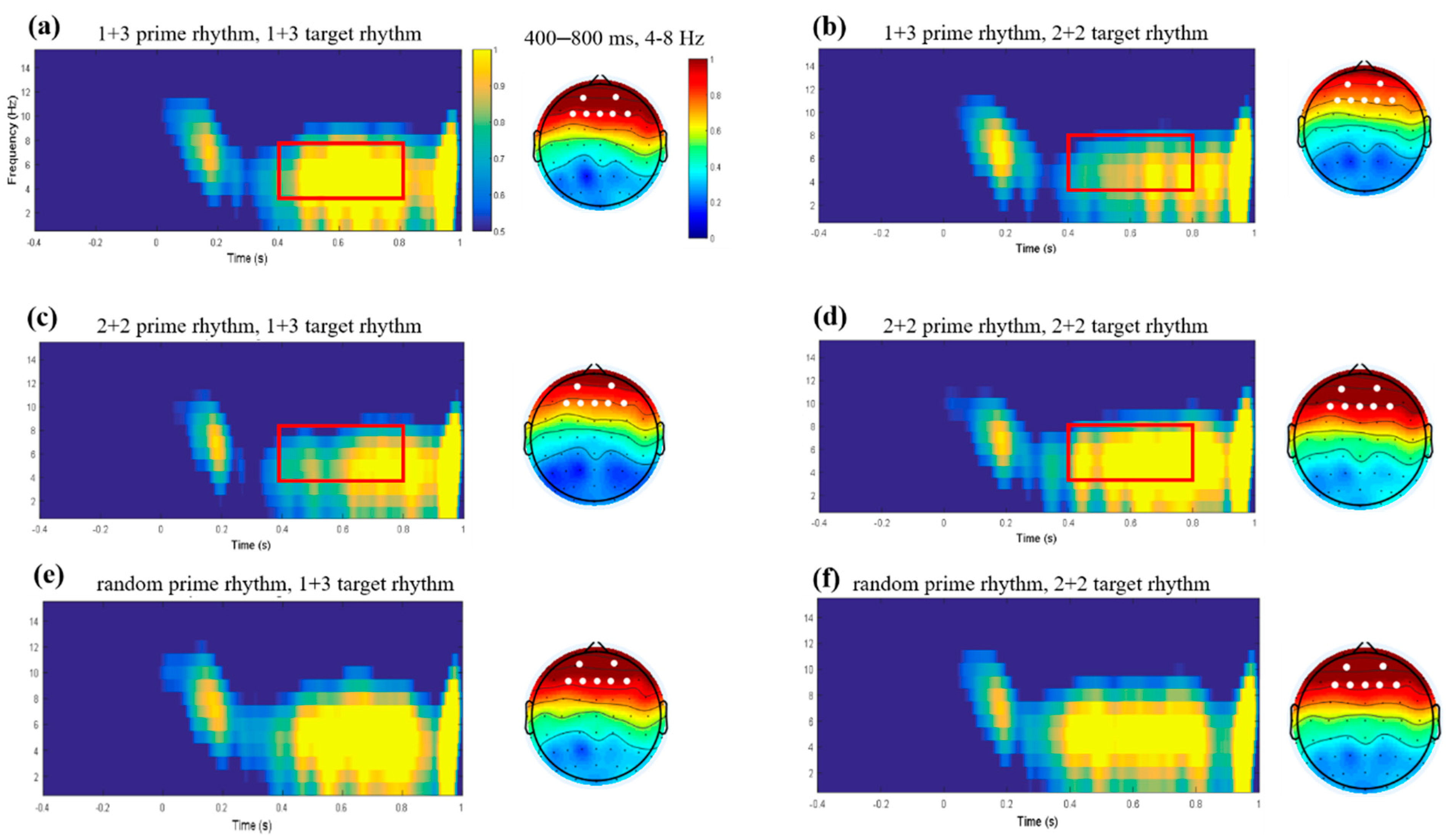
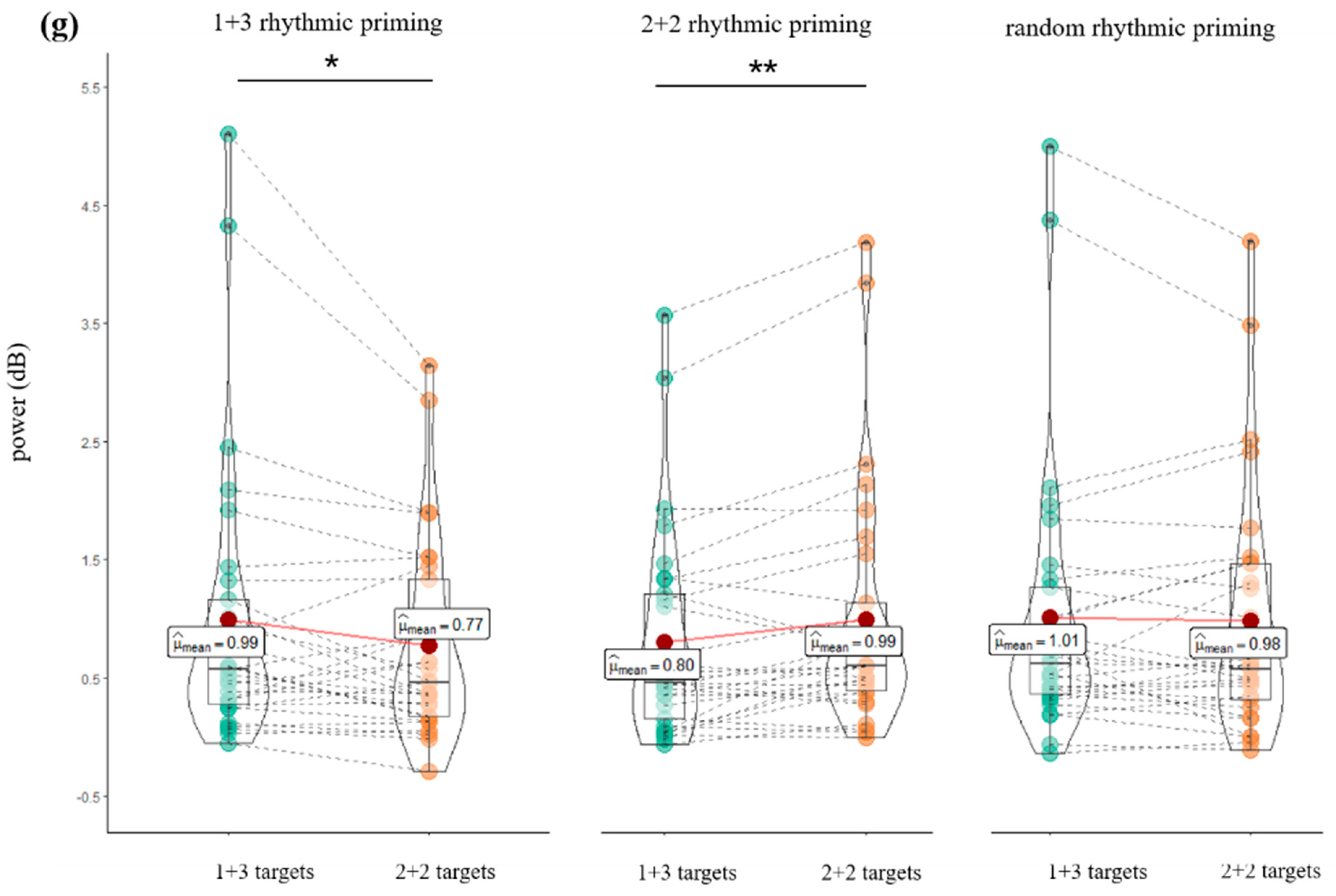
4.2. CACoh and TFR Results
5. Discussion
5.1. Behavioral Evidence for the Rhythmic Priming Effect
5.2. Cortical Tracking, Theta-Band Oscillation, and Rhythmic Priming Effect
6. Limitations and Future Directions
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cason, N.; Schön, D. Rhythmic priming enhances the phonological processing of speech. Neuropsychologia 2012, 50, 2652–2658. [Google Scholar] [CrossRef] [PubMed]
- Cutler, A. The perception of rhythm in language. Cognition 1994, 50, 79–81. [Google Scholar] [CrossRef]
- Dilley, L.C.; McAuley, J.D. Distal prosodic context affects word segmentation and lexical processing. J. Mem. Lang. 2008, 59, 294–311. [Google Scholar] [CrossRef]
- Pitt, M.A.; Samuel, A.G. The use of rhythm in attending to speech. J. Exp. Psychol.-Hum. Percept. Perform. 1990, 16, 564–573. [Google Scholar] [CrossRef] [PubMed]
- Poeppel, D.; Assaneo, M.F. Speech rhythms and their neural foundations. Nat. Rev. Neurosci. 2020, 21, 322–334. [Google Scholar] [CrossRef]
- Hilton, C.B.; Goldwater, M. Linguistic syncopation: Meter-syntax alignment and its effect on sentence comprehension and sensorimotor synchronization. Cognition 2020, 217, 104880. [Google Scholar] [CrossRef]
- Tilsen, S. Metrical regularity facilitates speech planning and production. Lab. Phonol. 2011, 2, 185–218. [Google Scholar] [CrossRef]
- Zhang, N.; Zhang, Q. Rhythmic pattern facilitates speech production: An ERP study. Sci. Rep. 2019, 9, 12974. [Google Scholar] [CrossRef] [Green Version]
- Geiser, E.; Zaehle, T.; Jancke, L.; Meyer, M. The neural correlate of speech rhythm as evidenced by metrical speech processing. J. Cogn. Neurosci. 2008, 20, 541–552. [Google Scholar] [CrossRef]
- Magne, C.; Astesano, C.; Aramaki, M.; Ystad, S.; Kronland-Martinet, R.; Besson, M. Influence of syllabic lengthening on semantic processing in spoken French: Behavioral and electrophysiological evidence. Cereb. Cortex. 2007, 17, 2659–2668. [Google Scholar] [CrossRef]
- Li, X.; Shao, X.; Xia, J.; Xu, X. The cognitive and neural oscillatory mechanisms underlying the facilitating effect of rhythm regularity on speech comprehension. J. Neurolinguist. 2019, 49, 155–167. [Google Scholar] [CrossRef]
- Levelt, W.J.M. Speaking: From Intention to Articulation; MIT Press: Cambridge, MA, USA, 1989. [Google Scholar]
- Tooley, K.M.; Konopka, A.E.; Watson, D.G. Assessing priming for prosodic representations: Speaking rate, intonational phrase boundaries, and pitch accenting. Mem. Cogn. 2018, 46, 625–641. [Google Scholar] [CrossRef] [Green Version]
- Tooley, K.M.; Konopka, A.E.; Watson, D.G. Can intonational phrase structure be primed (like syntactic structure)? J. Exp. Psychol.-Learn. Mem. Cogn. 2014, 40, 348–363. [Google Scholar] [CrossRef] [Green Version]
- Ferreira, F. Prosody-Encyclopedia of Cognitve Science; Macmillan Reference Ltd.: New York, NY, USA, 2000. [Google Scholar]
- Pickering, M.J.; Ferreira, V.S. Structural priming: A critical review. Psychol. Bull. 2008, 134, 427–459. [Google Scholar] [CrossRef] [Green Version]
- Meyer, D.E.; Schvaneveldt, R.W. Facilitation in recognizing pairs of words: Evidence of a dependence between retrieval operations. J. Exp. Psychol. 1971, 90, 227–234. [Google Scholar] [CrossRef] [Green Version]
- Garrod, S.; Pickering, M.J. Why is conversation so easy? Trends. Cogn. Sci. 2004, 8, 8–11. [Google Scholar] [CrossRef]
- Pardo, J.S. On phonetic convergence during conversational interaction. J. Acoust. Soc. Am. 2006, 119, 2382–2393. [Google Scholar] [CrossRef] [Green Version]
- Jungers, M.K.; Hupp, J.M. Speech priming: Evidence for rate persistence in unscripted speech. Lang. Cogn. Process. 2009, 24, 611–624. [Google Scholar] [CrossRef]
- Cason, N.; Hidalgo, C.; Isoard, F.; Roman, S.; Schon, D. Rhythmic priming enhances speech production abilities: Evidence from prelingually deaf children. Neuropsychology 2015, 29, 102–107. [Google Scholar] [CrossRef]
- Gould, L.; McKibben, T.; Ekstrand, C.; Lorentz, E.; Borowsky, R. The beat goes on: The effect of rhythm on reading aloud. Lang. Cogn. Neurosci. 2015, 31, 236–250. [Google Scholar] [CrossRef]
- Luo, Y.; Zhou, X. ERP evidence for the online processing of rhythmic pattern during Chinese sentence reading. NeuroImage. 2010, 49, 2836–2849. [Google Scholar] [CrossRef] [PubMed]
- Chen, Q.; Zhang, J.; Xu, X.; Scheepers, C.; Yang, Y.; Tanenhaus, M.K. Prosodic expectations in silent reading: ERP evidence from rhyme scheme and semantic congruence in classic Chinese poems. Cognition 2016, 154, 11–21. [Google Scholar] [CrossRef] [PubMed]
- Marie, C.; Magne, C.; Besson, M. Musicians and the metric structure of words. J. Cogn. Neurosci. 2011, 23, 294–305. [Google Scholar] [CrossRef] [PubMed]
- Rothermich, K.; Schmidt-Kassow, M.; Schwartze, M.; Kotz, S.A. Event-related potential responses to metric violations: Rules versus meaning. Neuroreport 2010, 21, 580–584. [Google Scholar] [CrossRef] [PubMed]
- Schmidt-Kassow, M.; Kotz, S.A. Event-related brain potentials suggest a late interaction of meter and syntax in the P600. J. Cogn. Neurosci. 2009, 21, 1693–1708. [Google Scholar] [CrossRef]
- Schmidt-Kassow, M.; Kotz, S.A. Attention and perceptual regularity in speech. Neuroreport 2009, 20, 1643–1647. [Google Scholar] [CrossRef]
- Jones, M.R.; Boltz, M. Dynamic attending and responses to time. Psychol. Rev. 1989, 96, 459–491. [Google Scholar] [CrossRef] [Green Version]
- Jones, M.R.; Moynihan, H.; MacKenzie, N.; Puente, J. Temporal aspects of stimulus-driven attending in dynamic arrays. Psychol. Sci. 2002, 13, 313–319. [Google Scholar] [CrossRef]
- Large, E.W.; Jones, M.R. The dynamics of attending: How people track time-varying events. Psychol. Rev. 1999, 106, 119–159. [Google Scholar] [CrossRef]
- Obleser, J.; Kayser, C. Neural Entrainment and Attentional Selection in the Listening Brain. Trends Cogn. Sci. 2019, 23, 913–926. [Google Scholar] [CrossRef]
- Harding, E.E.; Sammler, D.; Henry, M.J.; Large, E.W.; Kotz, S.A. Cortical tracking of rhythm in music and speech. NeuroImage 2019, 185, 96–101. [Google Scholar] [CrossRef]
- Nederlanden, C.M.; Joanisse, M.F.; Grahn, J.A. Music as a scaffold for listening to speech: Better neural phase-locking to song than speech. NeuroImage 2020, 214, 116767. [Google Scholar] [CrossRef]
- Doelling, K.B.; Assaneo, M.F.; Bevilacqua, D.; Pesaran, B.; Poeppel, D. An oscillator model better predicts cortical entrainment to music. Proc. Natl. Acad. Sci. USA 2019, 116, 10113–10121. [Google Scholar] [CrossRef] [Green Version]
- Calderone, D.J.; Lakatos, P.; Butler, P.D.; Castellanos, F.X. Entrainment of neural oscillations as a modifiable substrate of attention. Trends Cogn. Sci. 2014, 18, 300–309. [Google Scholar] [CrossRef] [Green Version]
- Cohen, M.X. Where Does EEG Come From and What Does It Mean? Trends Neurosci. 2017, 40, 208–218. [Google Scholar] [CrossRef]
- Keitel, A.; Gross, J.; Kayser, C. Perceptually relevant speech tracking in auditory and motor cortex reflects distinct linguistic features. PLoS Biol. 2018, 16, e2004473. [Google Scholar] [CrossRef] [Green Version]
- Ghitza, O. Linking speech perception and neurophysiology: Speech decoding guided by cascaded oscillators locked to the input rhythm. Front. Psychol. 2011, 2, 130. [Google Scholar] [CrossRef] [Green Version]
- Giraud, A.L.; Poeppel, D. Cortical oscillations and speech processing: Emerging computational principles and operations. Nat. Neurosci. 2012, 15, 511–517. [Google Scholar] [CrossRef] [Green Version]
- Ward, L.M. Synchronous neural oscillations and cognitive processes. Trends Cogn. Sci. 2003, 7, 553–559. [Google Scholar] [CrossRef]
- Beier, E.J.; Chantavarin, S.; Rehrig, G.; Ferreira, F.; Miller, L.M. Cortical Tracking of Speech: Toward Collaboration between the Fields of Signal and Sentence Processing. J. Cogn. Neurosci. 2021, 33, 574–593. [Google Scholar] [CrossRef]
- Fell, J.; Axmacher, N. The role of phase synchronization in memory processes. Nat. Rev. Neurosci. 2011, 12, 105–118. [Google Scholar] [CrossRef] [PubMed]
- Klimesch, W. Alpha-band oscillations, attention, and controlled access to stored information. Trends Cogn. Sci. 2012, 16, 606–617. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Siegel, M.; Donner, T.H.; Engel, A.K. Spectral fingerprints of large-scale neuronal interactions. Nat. Rev. Neurosci. 2012, 13, 121–134. [Google Scholar] [CrossRef] [PubMed]
- Lewis, A.G.; Wang, L.; Bastiaansen, M. Fast oscillatory dynamics during language comprehension: Unification versus maintenance and prediction? Brain Lang. 2015, 148, 51–63. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gnanateja, G.N.; Devaraju, D.S.; Heyne, M.; Quique, Y.M.; Sitek, K.R.; Tardif, M.C.; Tessmer, R.; Dial, H.R. On the Role of Neural Oscillations Across Timescales in Speech and Music Processing. Front. Comput. Neurosci. 2022, 16, 872093. [Google Scholar] [CrossRef]
- Gross, J.; Hoogenboom, N.; Thut, G.; Schyns, P.; Panzeri, S.; Belin, P.; Garrod, S. Speech rhythms and multiplexed oscillatory sensory coding in the human brain. PLoS Biol. 2013, 11, e1001752. [Google Scholar] [CrossRef]
- Lehongre, K.; Ramus, F.; Villiermet, N.; Schwartz, D.; Giraud, A.L. Altered low-gamma sampling in auditory cortex accounts for the three main facets of dyslexia. Neuron 2011, 72, 1080–1090. [Google Scholar] [CrossRef] [Green Version]
- Peelle, J.E.; Gross, J.; Davis, M.H. Phase-locked responses to speech in human auditory cortex are enhanced during comprehension. Cereb. Cortex. 2013, 23, 1378–1387. [Google Scholar] [CrossRef]
- Zuk, N.J.; Teoh, E.S.; Lalor, E.C. EEG-based classification of natural sounds reveals specialized responses to speech and music. NeuroImage 2020, 210, 116558. [Google Scholar] [CrossRef]
- Bourguignon, M.; De Tiege, X.; Op de Beeck, M.; Ligot, N.; Paquier, P.; Van Bogaert, P.; Goldman, S.; Hari, R.; Jousmäki, V. The pace of prosodic phrasing couples the listener’s cortex to the reader’s voice. Hum. Brain Mapp. 2013, 34, 314–326. [Google Scholar] [CrossRef]
- Peelle, J.E.; Davis, M.H. Neural Oscillations Carry Speech Rhythm through to Comprehension. Front. Psychol. 2012, 3, 320. [Google Scholar] [CrossRef] [Green Version]
- Assaneo, M.F.; Poeppel, D. The coupling between auditory and motor cortices is rate-restricted: Evidence for an intrinsic speech-motor rhythm. Sci. Adv. 2018, 4, eaao3842. [Google Scholar] [CrossRef] [Green Version]
- Yao, B.; Taylor, J.R.; Banks, B.; Kotz, S.A. Theta activity phase-locks to inner speech in silent reading. PsyArXiv 2020. [Google Scholar] [CrossRef]
- Park, H.; Ince, R.A.; Schyns, P.G.; Thut, G.; Gross, J. Frontal top-down signals increase coupling of auditory low-frequency oscillations to continuous speech in human listeners. Curr. Biol. 2015, 25, 1649–1653. [Google Scholar] [CrossRef] [Green Version]
- Power, A.J.; Mead, N.; Barnes, L.; Goswami, U. Neural entrainment to rhythmically presented auditory, visual, and audio-visual speech in children. Front. Psychol. 2012, 3, 216. [Google Scholar] [CrossRef] [Green Version]
- Myers, B.R.; Watson, D.G. Evidence of Absence: Abstract Metrical Structure in Speech Planning. Cogn. Sci. 2021, 45, e13017. [Google Scholar] [CrossRef]
- Luo, Y.; Zhang, Y.; Feng, X.; Zhou, X. Electroencephalogram oscillations differentiate semantic and prosodic processes during sentence reading. Neuroscience 2010, 169, 654–664. [Google Scholar] [CrossRef]
- Feng, S.; Wang, L. Hanyu Yunlv Yufa Jiaocheng, 1st ed.; Peking University Press: Beijing, China, 2018. [Google Scholar]
- Cason, N.; Astesano, C.; Schon, D. Bridging music and speech rhythm: Rhythmic priming and audio-motor training affect speech perception. Acta Psychol. 2015, 155, 43–50. [Google Scholar] [CrossRef] [Green Version]
- Faul, F.; Erdfelder, E.; Lang, A.G.; Buchner, A.G. Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behav. Res. Methods 2007, 39, 175–191. [Google Scholar] [CrossRef]
- Doelling, K.B.; Arnal, L.H.; Ghitza, O.; Poeppel, D. Acoustic landmarks drive delta-theta oscillations to enable speech comprehension by facilitating perceptual parsing. NeuroImage 2014, 85 Pt 2, 761–768. [Google Scholar] [CrossRef]
- Delorme, A.; Makeig, S. EEGLAB: An open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J. Neurosci. Methods 2004, 134, 9–21. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Oostenveld, R.; Fries, P.; Maris, E.; Schoffelen, J.M. FieldTrip: Open source so ware for advanced analysis of MEG, EEG, and invasive electrophysiological data. Comput. Intell. Neurosc. 2011, 2011, 156869. [Google Scholar] [CrossRef] [PubMed]
- Tal, I.; Large, E.W.; Rabinovitch, E.; Wei, Y.; Schroeder, C.E.; Poeppel, D.; Golumbic, E.Z. Neural Entrainment to the Beat: The “Missing-Pulse” Phenomenon. J. Neurosci. 2017, 37, 6331–6341. [Google Scholar] [CrossRef] [PubMed]
- Tierney, A.; Kraus, N. Neural entrainment to the rhythmic structure of music. J. Cogn. Neurosci. 2015, 27, 400–408. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bates, D.; Mächler, M.; Boler, B.; Walker, S. Fitting Linear Mixed-Effects Models Using lme4. J. Stat. Softw. 2015, 67, 1–48. [Google Scholar] [CrossRef]
- Howell, D.C. Statistical Methods for Psychology, 7th ed.; Cengage Wadsworth: Belmont, CA, Australia, 2010; pp. 372–373. [Google Scholar]
- Ghitza, O. The theta-syllable: A unit of speech information defined by cortical function. Front. Psychol. 2013, 4, 138. [Google Scholar] [CrossRef] [Green Version]
- Teng, X.; Tian, X.; Rowland, J.; Poeppel, D. Concurrent temporal channels for auditory processing: Oscillatory neural entrainment reveals segregation of function at different scales. PLoS Biol. 2017, 15, e2000812. [Google Scholar] [CrossRef]
- Hyafil, A.; Giraud, A.L.; Fontolan, L.; Gutkin, B. Neural Cross-Frequency Coupling: Connecting Architectures, Mechanisms, and Functions. Trends Neurosci. 2015, 38, 725–740. [Google Scholar] [CrossRef]
- Lizarazu, M.; Lallier, M.; Molinaro, N. Phase-amplitude coupling between theta and gamma oscillations adapts to speech rate. Ann. N. Y. Acad. Sci. 2019, 1453, 140–152. [Google Scholar] [CrossRef] [Green Version]
- Hovsepyan, S.; Olasagasti, I.; Giraud, A.L. Combining predictive coding and neural oscillations enables online syllable recognition in natural speech. Nat. Commun. 2020, 11, 3117. [Google Scholar] [CrossRef]
- Jiang, Y.; Cai, X.; Zhang, Q. Theta band (4~8 Hz) oscillations reflect syllables processing in Chinese spoken word production. Acta Psychol. Sin. 2020, 52, 1199–1211. [Google Scholar] [CrossRef]
- Zhang, Q. The Syllable’s Role in Language Production. Adv. Psychol. Sci. 2005, 13, 752–759. [Google Scholar]
- Zhang, Q.; Damian, M.F. Syllables constitute proximate units for Mandarin speakers: Electrophysiological evidence from a masked priming task. Psychophysiology 2019, 56, e13317. [Google Scholar] [CrossRef] [Green Version]
- Kotz, S.A. A critical review of ERP and fMRI evidence on L2 syntactic processing. Brain Lang. 2008, 109, 68–74. [Google Scholar] [CrossRef]
- Baddeley, A. Working memory: Looking back and looking forward. Nat. Rev. Neurosci. 2003, 4, 829–839. [Google Scholar] [CrossRef]
- Meyer, A.S. The time course of phonological encoding in language production: Phonological encoding inside a syllable. J. Mem. Lang. 1991, 30, 69–89. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Term | Sum Sq | Mean Sq | dfNum | dfDen |
|---|---|---|---|---|
| Prime | 108,655.70 | 54,327.83 | 2 | 384.25 |
| Target | 32,927.37 | 39,279.37 | 1 | 375.31 |
| Prime × target | 66,479.60 | 33,239.80 | 2 | 384.25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, Q.; Zhang, Q. Theta Band (4–8 Hz) Oscillations Reflect Online Processing of Rhythm in Speech Production. Brain Sci. 2022, 12, 1593. https://doi.org/10.3390/brainsci12121593
Yan Q, Zhang Q. Theta Band (4–8 Hz) Oscillations Reflect Online Processing of Rhythm in Speech Production. Brain Sciences. 2022; 12(12):1593. https://doi.org/10.3390/brainsci12121593
Chicago/Turabian StyleYan, Qin, and Qingfang Zhang. 2022. "Theta Band (4–8 Hz) Oscillations Reflect Online Processing of Rhythm in Speech Production" Brain Sciences 12, no. 12: 1593. https://doi.org/10.3390/brainsci12121593
APA StyleYan, Q., & Zhang, Q. (2022). Theta Band (4–8 Hz) Oscillations Reflect Online Processing of Rhythm in Speech Production. Brain Sciences, 12(12), 1593. https://doi.org/10.3390/brainsci12121593