
A Visual Encoding Model Based on Contrastive Self-Supervised Learning for Human Brain Activity along the Ventral Visual Stream


Abstract
:1. Introduction
2. Materials and Methods
2.1. Experimental Data
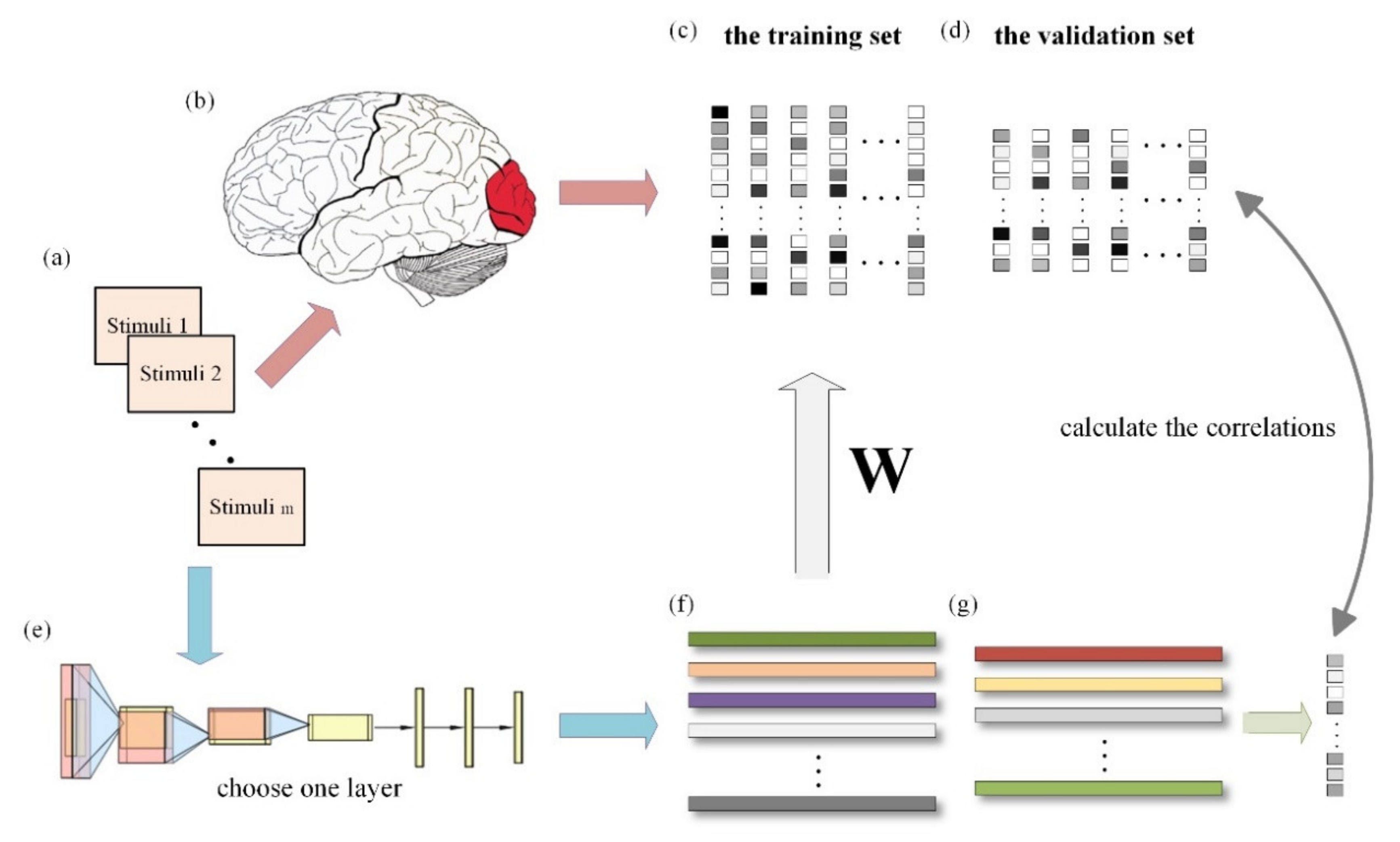
2.2. Overview of the Proposed Method
2.3. Extracting Hierarchical Features from Pre-Trained Models
2.4. Voxel-Wise Linear Regression Mapping
2.5. Quantitative Analysis of Models
2.6. Representational Similarity Analysis
3. Results
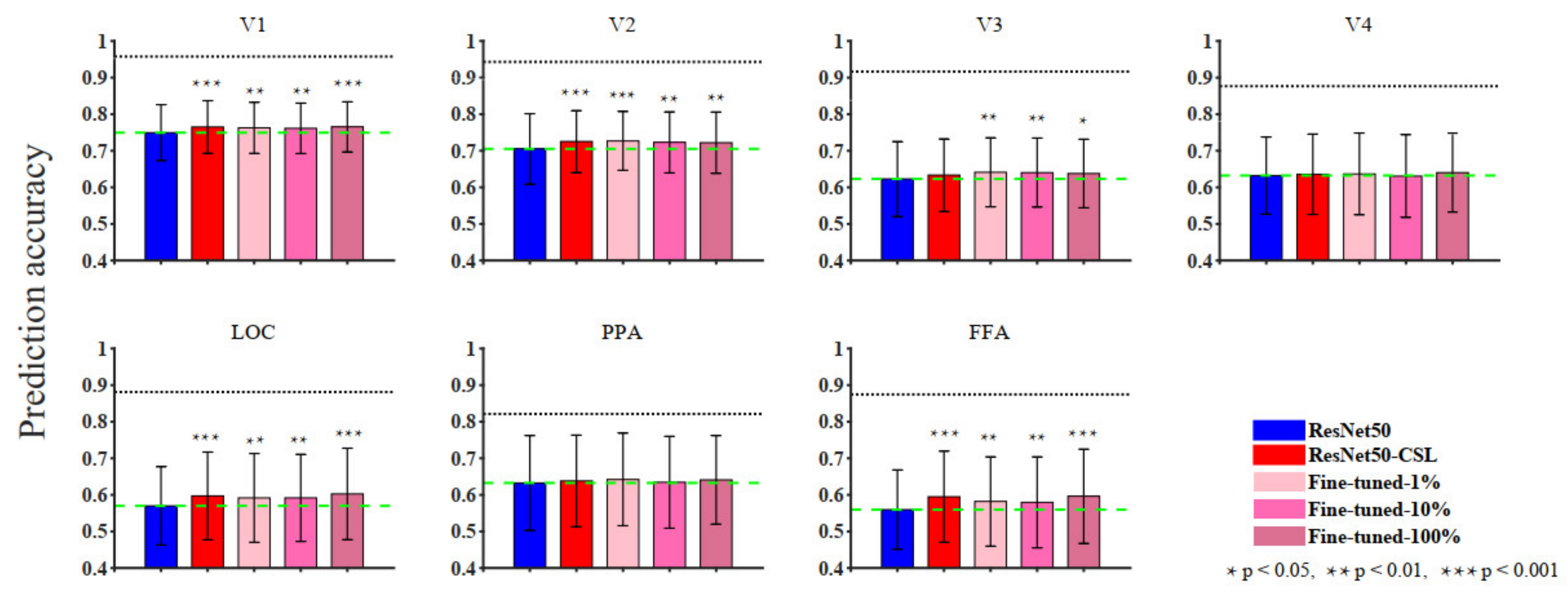
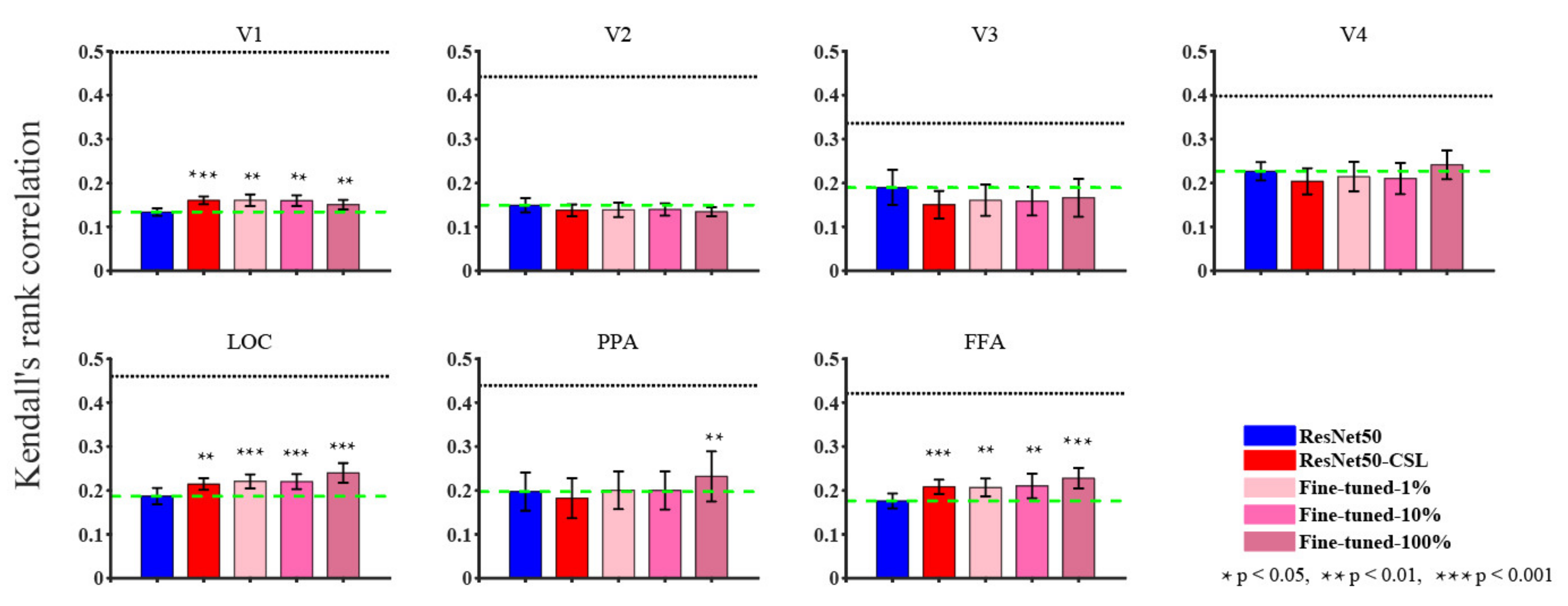
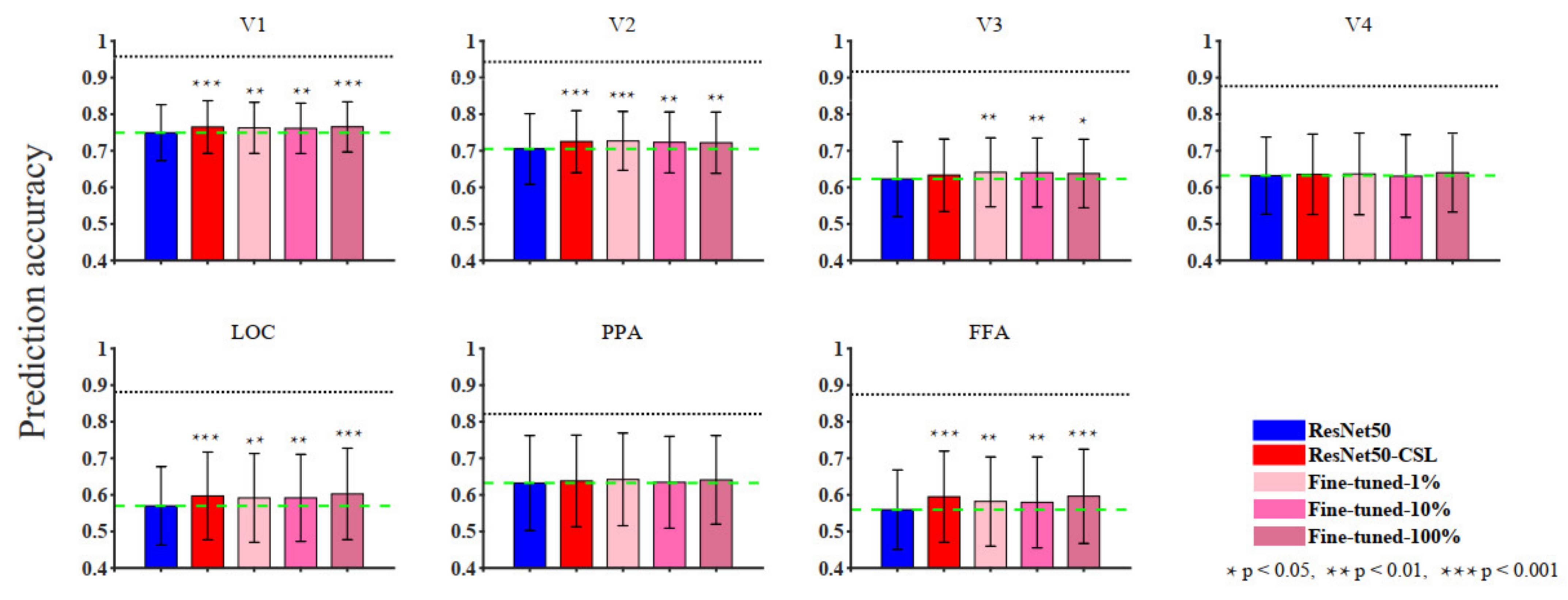
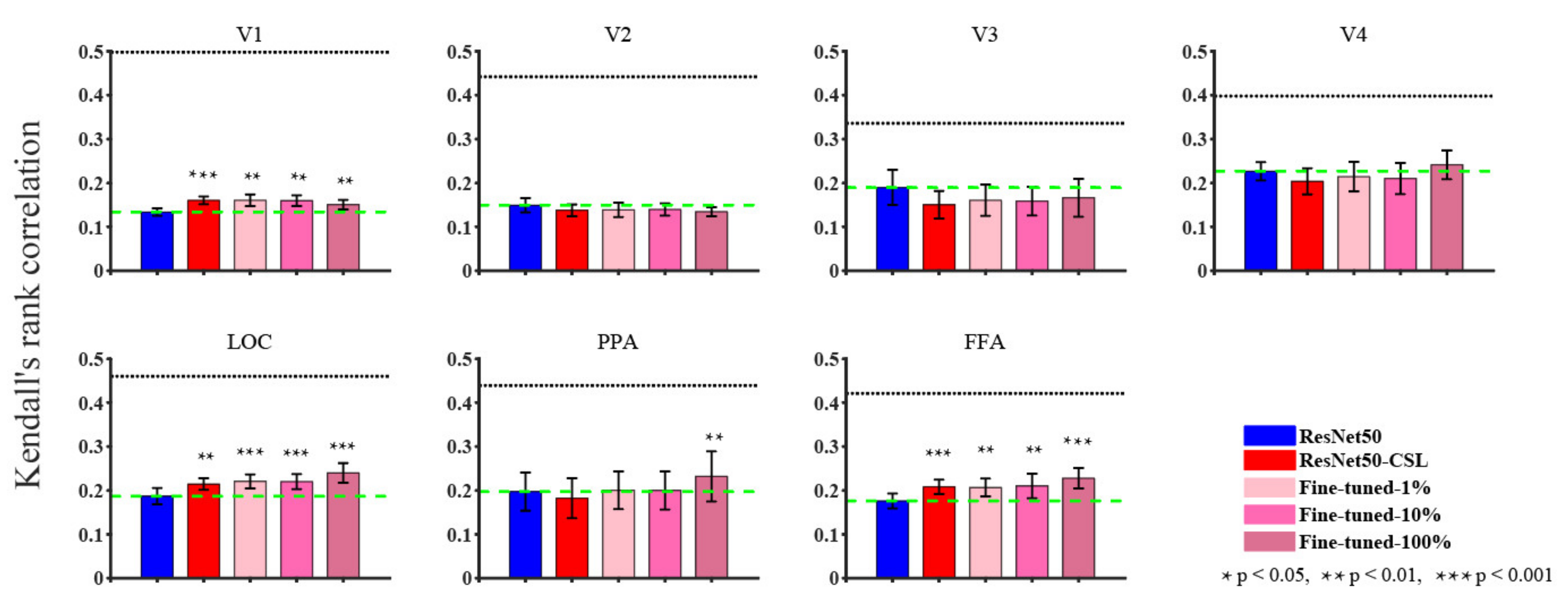
3.1. Overall Comparisons in Encoding and Representational Performance of Different Visual Areas between Models
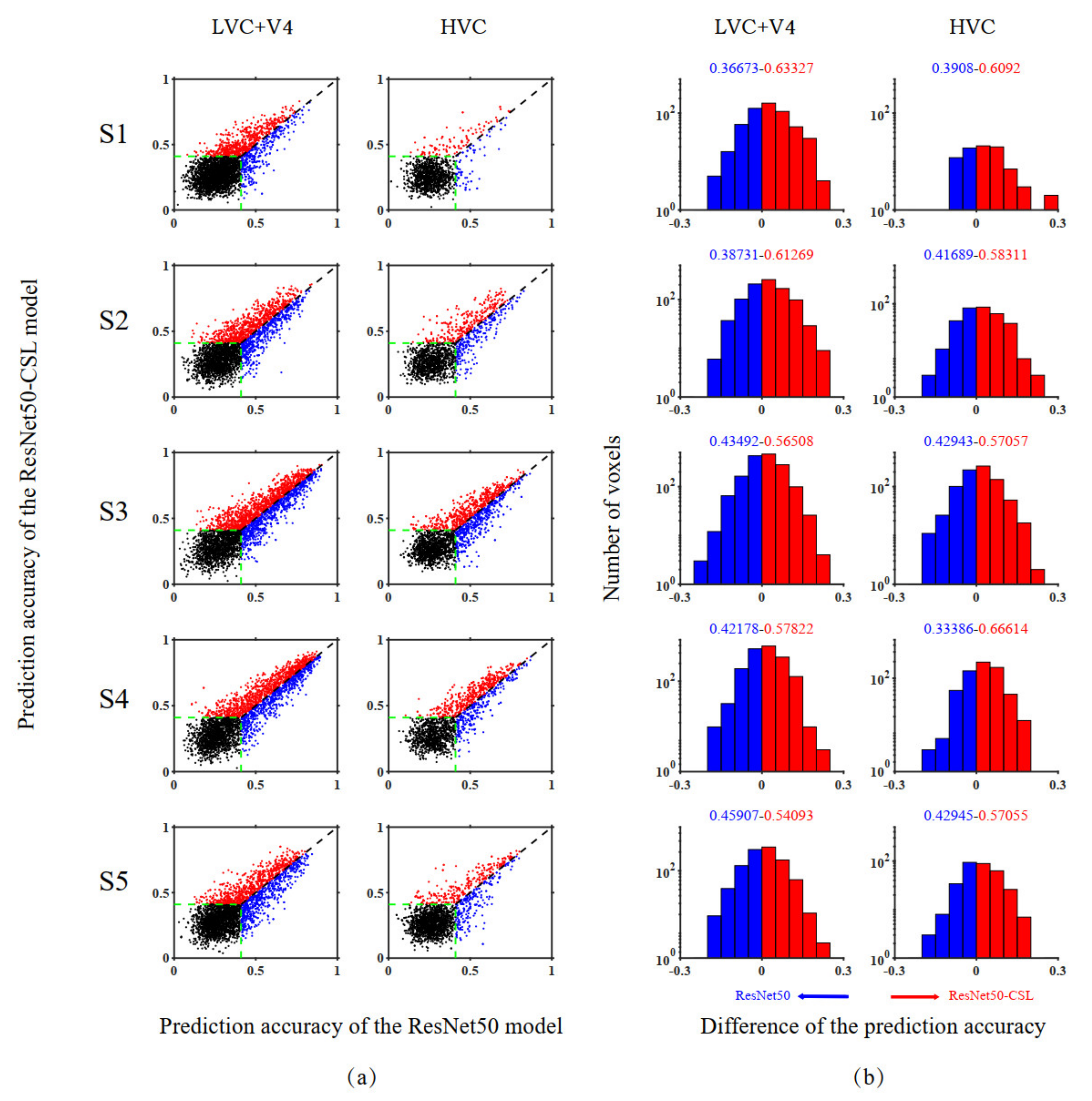
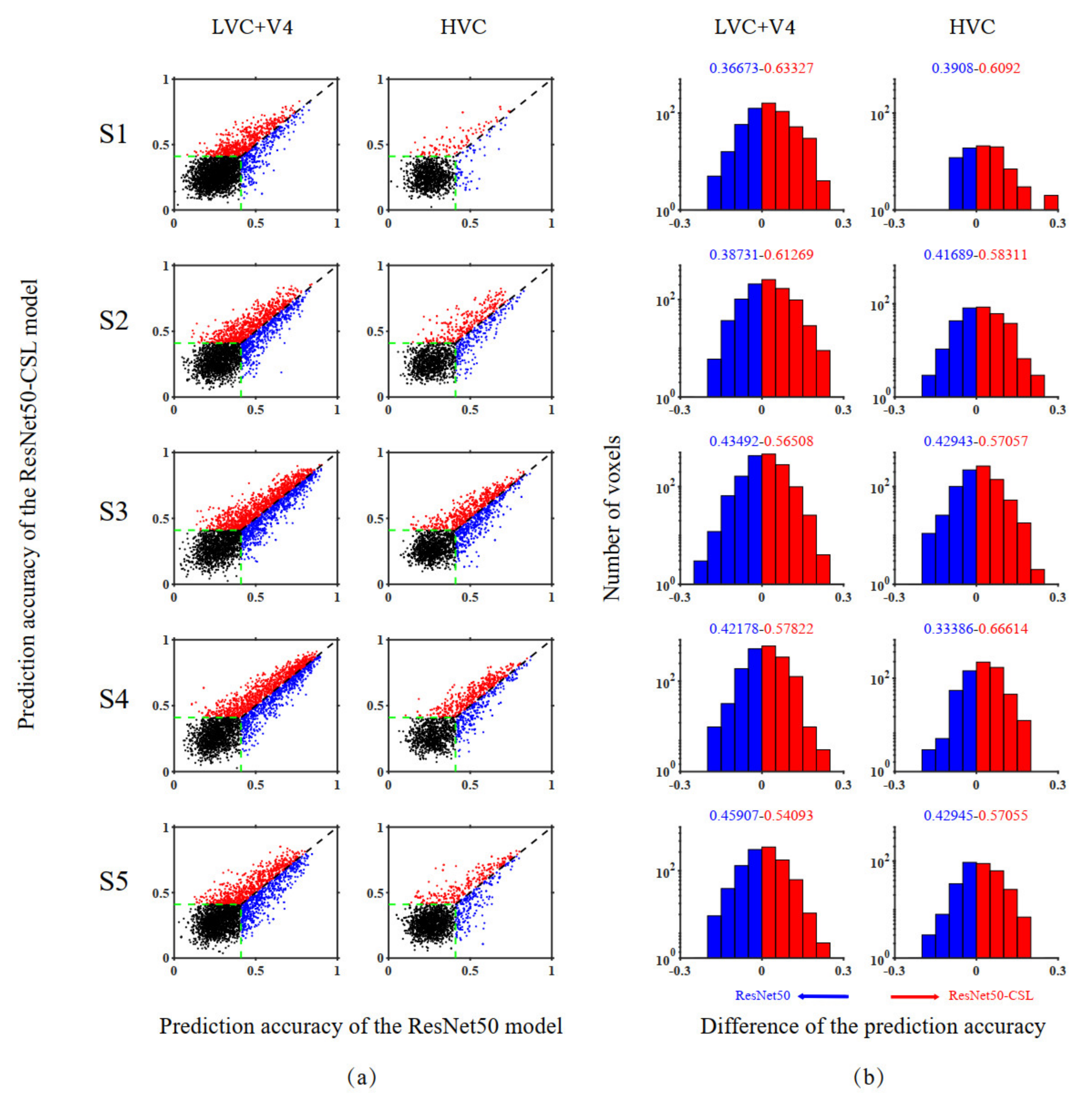
3.2. Voxel-to-Voxel Comparisons of Prediction Accuracy between the ResNet50-CSL and the ResNet50 Encoding Models
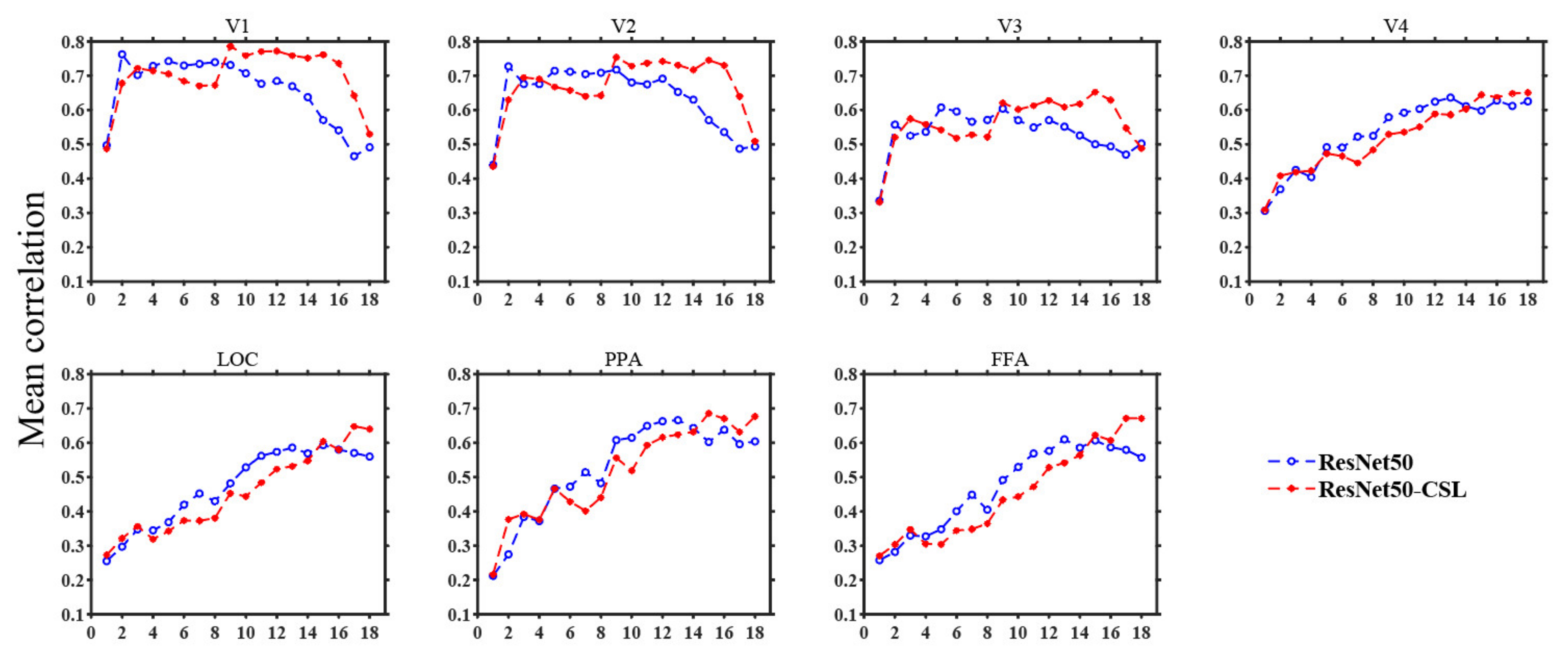
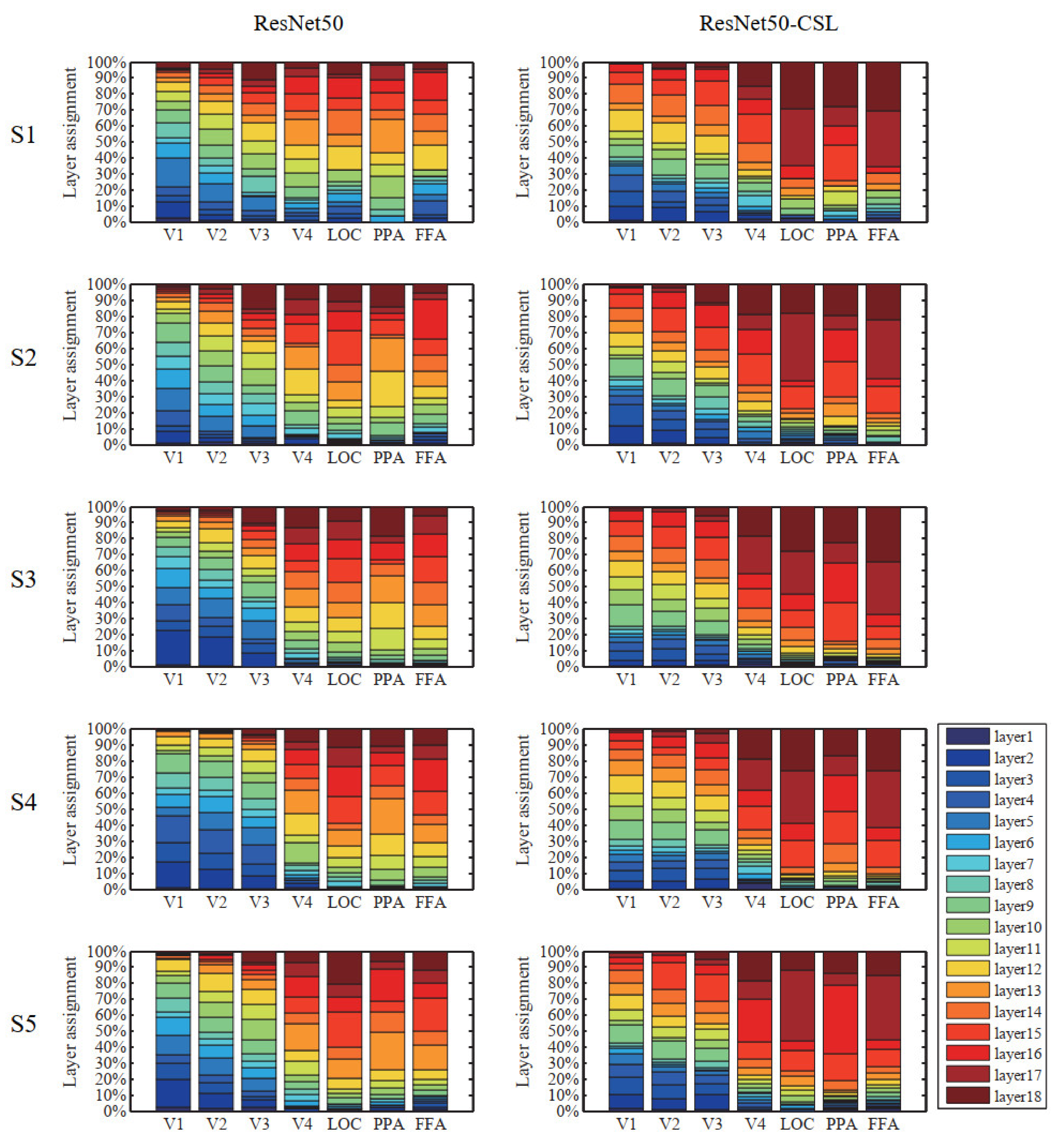
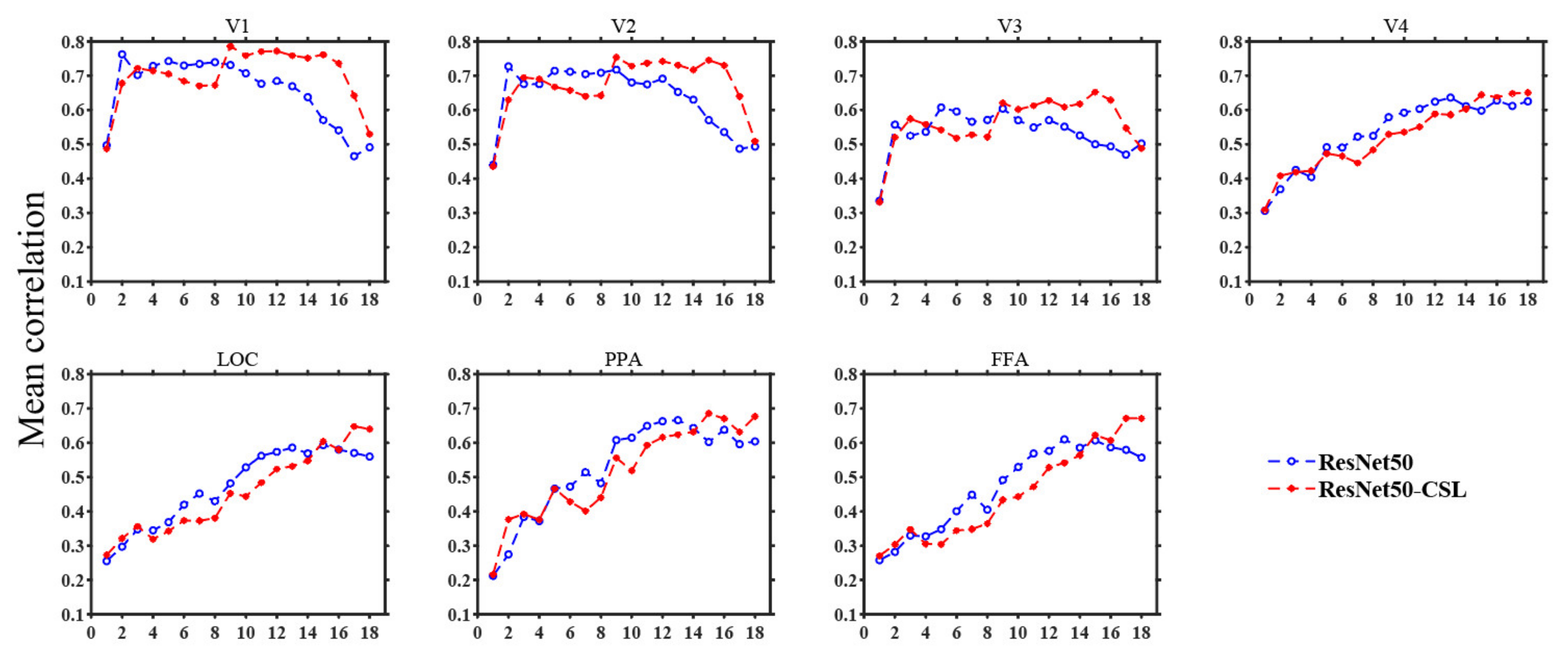
3.3. Contributions of Different Feature Layers to Encoding Performance
4. Discussion
4.1. Contrastive Self-Supervised Model vs. Supervised Classification Model
4.2. Exploring Feature Layers of ResNet50-CSL from Visual Encoding
4.3. Future Development Directions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kay, K.N. Principles for Models of Neural Information Processing. NeuroImage 2018, 180, 101–109. [Google Scholar] [CrossRef]
- Ogawa, S.; Lee, T.M.; Kay, A.R.; Tank, D.W. Brain Magnetic Resonance Imaging with Contrast Dependent on Blood Oxygenation. Proc. Natl. Acad. Sci. USA 1990, 87, 9868–9872. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kriegeskorte, N.; Douglas, P.K. Cognitive Computational Neuroscience. Nat. Neurosci. 2018, 21, 1148–1160. [Google Scholar] [CrossRef]
- Kriegeskorte, N.; Diedrichsen, J. Peeling the Onion of Brain Representations. Annu. Rev. Neurosci. 2019, 42, 407–432. [Google Scholar] [CrossRef] [PubMed]
- Van Gerven, M.A.J. A Primer on Encoding Models in Sensory Neuroscience. J. Math. Psychol. 2017, 76, 172–183. [Google Scholar] [CrossRef]
- Chen, M.; Han, J.; Hu, X.; Jiang, X.; Guo, L.; Liu, T. Survey of Encoding and Decoding of Visual Stimulus via FMRI: An Image Analysis Perspective. Brain Imaging Behav. 2014, 8, 7–23. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vintch, B.; Movshon, J.A.; Simoncelli, E.P. A Convolutional Subunit Model for Neuronal Responses in Macaque V1. J. Neurosci. 2015, 35, 14829–14841. [Google Scholar] [CrossRef] [Green Version]
- Kay, K.N.; Winawer, J.; Rokem, A.; Mezer, A.; Wandell, B.A. A Two-Stage Cascade Model of BOLD Responses in Human Visual Cortex. PLoS Comput. Biol. 2013, 9, e1003079. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Naselaris, T.; Kay, K.N.; Nishimoto, S.; Gallant, J.L. Encoding and Decoding in FMRI. NeuroImage 2011, 56, 400–410. [Google Scholar] [CrossRef] [Green Version]
- Carandini, M. Do We Know What the Early Visual System Does? J. Neurosci. 2005, 25, 10577–10597. [Google Scholar] [CrossRef]
- Kay, K.N.; Naselaris, T.; Prenger, R.J.; Gallant, J.L. Identifying Natural Images from Human Brain Activity. Nature 2008, 452, 352–355. [Google Scholar] [CrossRef] [PubMed]
- Huth, A.G.; Nishimoto, S.; Vu, A.T.; Gallant, J.L. A Continuous Semantic Space Describes the Representation of Thousands of Object and Action Categories across the Human Brain. Neuron 2012, 76, 1210–1224. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Naselaris, T.; Prenger, R.J.; Kay, K.N.; Oliver, M.; Gallant, J.L. Bayesian Reconstruction of Natural Images from Human Brain Activity. Neuron 2009, 63, 902–915. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brunton, B.W.; Beyeler, M. Data-Driven Models in Human Neuroscience and Neuroengineering. Curr. Opin. Neurobiol. 2019, 58, 21–29. [Google Scholar] [CrossRef]
- Cichy, R.M.; Khosla, A.; Pantazis, D.; Torralba, A.; Oliva, A. Comparison of Deep Neural Networks to Spatio-Temporal Cortical Dynamics of Human Visual Object Recognition Reveals Hierarchical Correspondence. Sci. Rep. 2016, 6, 27755. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Eickenberg, M.; Gramfort, A.; Varoquaux, G.; Thirion, B. Seeing It All: Convolutional Network Layers Map the Function of the Human Visual System. NeuroImage 2017, 152, 184–194. [Google Scholar] [CrossRef] [Green Version]
- Kruger, N.; Janssen, P.; Kalkan, S.; Lappe, M.; Leonardis, A.; Piater, J.; Rodriguez-Sanchez, A.J.; Wiskott, L. Deep Hierarchies in the Primate Visual Cortex: What Can We Learn for Computer Vision? IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1847–1871. [Google Scholar] [CrossRef]
- Cadena, S.A.; Denfield, G.H.; Walker, E.Y.; Gatys, L.A.; Tolias, A.S.; Bethge, M.; Ecker, A.S. Deep Convolutional Models Improve Predictions of Macaque V1 Responses to Natural Images. PLOS Comput. Biol. 2019, 15, e1006897. [Google Scholar] [CrossRef] [Green Version]
- Cichy, R.M.; Kaiser, D. Deep Neural Networks as Scientific Models. Trends Cogn. Sci. 2019, 23, 305–317. [Google Scholar] [CrossRef] [Green Version]
- Storrs, K.R.; Kietzmann, T.C.; Walther, A.; Mehrer, J.; Kriegeskorte, N. Diverse Deep Neural Networks All Predict Human IT Well, after Training and Fitting. bioRxiv 2020. [Google Scholar] [CrossRef]
- Güçlü, U.; van Gerven, M.A.J. Increasingly Complex Representations of Natural Movies across the Dorsal Stream Are Shared between Subjects. NeuroImage 2017, 145, 329–336. [Google Scholar] [CrossRef]
- Guclu, U.; van Gerven, M.A.J. Deep Neural Networks Reveal a Gradient in the Complexity of Neural Representations across the Ventral Stream. J. Neurosci. 2015, 35, 10005–10014. [Google Scholar] [CrossRef] [Green Version]
- Cui, Y.; Qiao, K.; Zhang, C.; Wang, L.; Yan, B.; Tong, L. GaborNet Visual Encoding: A Lightweight Region-Based Visual Encoding Model With Good Expressiveness and Biological Interpretability. Front. Neurosci. 2021, 15, 614182. [Google Scholar] [CrossRef]
- Zhang, C.; Qiao, K.; Wang, L.; Tong, L.; Hu, G.; Zhang, R.-Y.; Yan, B. A Visual Encoding Model Based on Deep Neural Networks and Transfer Learning for Brain Activity Measured by Functional Magnetic Resonance Imaging. J. Neurosci. Methods 2019, 325, 108318. [Google Scholar] [CrossRef]
- Wen, H.; Shi, J.; Chen, W.; Liu, Z. Deep Residual Network Predicts Cortical Representation and Organization of Visual Features for Rapid Categorization. Sci. Rep. 2018, 8, 3752. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wen, H.; Shi, J.; Zhang, Y.; Lu, K.-H.; Cao, J.; Liu, Z. Neural Encoding and Decoding with Deep Learning for Dynamic Natural Vision. Cereb. Cortex 2018, 28, 4136–4160. [Google Scholar] [CrossRef]
- Shi, J.; Wen, H.; Zhang, Y.; Han, K.; Liu, Z. Deep Recurrent Neural Network Reveals a Hierarchy of Process Memory during Dynamic Natural Vision. Hum. Brain Mapp. 2018, 39, 2269–2282. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qiao, K.; Zhang, C.; Chen, J.; Wang, L.; Tong, L.; Yan, B. Neural Encoding and Interpretation for High-Level Visual Cortices Based on FMRI Using Image Caption Features. arXiv 2020, arXiv:200311797. [Google Scholar]
- Hinton, G.E.; Sejnowski, T.J. (Eds.) Unsupervised Learning: Foundations of Neural Computation; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Hinton, G.; Dayan, P.; Frey, B.; Neal, R. The “Wake-Sleep” Algorithm for Unsupervised Neural Networks. Science 1995, 268, 1158–1161. [Google Scholar] [CrossRef]
- Yuille, A.; Kersten, D. Vision as Bayesian Inference: Analysis by Synthesis? Trends Cogn. Sci. 2006, 10, 301–308. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Han, K.; Wen, H.; Shi, J.; Lu, K.-H.; Zhang, Y.; Fu, D.; Liu, Z. Variational Autoencoder: An Unsupervised Model for Encoding and Decoding FMRI Activity in Visual Cortex. NeuroImage 2019, 198, 125–136. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2014, arXiv:13126114. [Google Scholar]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive Multiview Coding. arXiv 2020, arXiv:190605849. [Google Scholar]
- Hénaff, O.J.; Srinivas, A.; De Fauw, J.; Razavi, A.; Doersch, C.; Eslami, S.M.A.; van den Oord, A. Data-Efficient Image Recognition with Contrastive Predictive Coding. arXiv 2020, arXiv:190509272. [Google Scholar]
- Hjelm, R.D.; Fedorov, A.; Lavoie-Marchildon, S.; Grewal, K.; Bachman, P.; Trischler, A.; Bengio, Y. Learning Deep Representations by Mutual Information Estimation and Maximization. arXiv 2019, arXiv:180806670. [Google Scholar]
- Bachman, P.; Hjelm, R.D.; Buchwalter, W. Learning Representations by Maximizing Mutual Information Across Views. arXiv 2019, arXiv:190600910. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum Contrast for Unsupervised Visual Representation Learning. arXiv 2020, arXiv:191105722. [Google Scholar]
- Van den Oord, A.; Li, Y.; Vinyals, O. Representation Learning with Contrastive Predictive Coding. arXiv 2019, arXiv:180703748. [Google Scholar]
- Wu, Z.; Xiong, Y.; Yu, S.X.; Lin, D. Unsupervised Feature Learning via Non-Parametric Instance Discrimination. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3733–3742. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. arXiv 2020, arXiv:200205709. [Google Scholar]
- Zhuang, C.; Yan, S.; Nayebi, A.; Schrimpf, M.; Frank, M.C.; DiCarlo, J.J.; Yamins, D.L.K. Unsupervised Neural Network Models of the Ventral Visual Stream. Proc. Natl. Acad. Sci. USA 2021, 118, e2014196118. [Google Scholar] [CrossRef]
- Horikawa, T.; Kamitani, Y. Generic Decoding of Seen and Imagined Objects Using Hierarchical Visual Features. Nat. Commun. 2017, 8, 15037. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Chen, T.; Kornblith, S.; Swersky, K.; Norouzi, M.; Hinton, G. Big Self-Supervised Models Are Strong Semi-Supervised Learners. arXiv 2020, arXiv:200610029. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:14091556. [Google Scholar]
- Needell, D.; Vershynin, R. Signal Recovery from Incomplete and Inaccurate Measurements via Regularized Orthogonal Matching Pursuit. IEEE J. Sel. Top. Signal Process. 2010, 4, 310–316. [Google Scholar] [CrossRef] [Green Version]
- Kay, K.N.; Winawer, J.; Mezer, A.; Wandell, B.A. Compressive Spatial Summation in Human Visual Cortex. J. Neurophysiol. 2013, 110, 481–494. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yamins, D.L.K.; DiCarlo, J.J. Using Goal-Driven Deep Learning Models to Understand Sensory Cortex. Nat. Neurosci. 2016, 19, 356–365. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subject | Visual Cortex | Advantage of ResNet50 | Advantage of ResNet50-CSL | Significance Indicators |
|---|---|---|---|---|
| S1 | LVC + V4 | 36.67% | 63.33% | 53.49% |
| HVC | 39.08% | 60.92% | 58.62% | |
| S2 | LVC + V4 | 38.73% | 61.27% | 52.74% |
| HVC | 41.69% | 58.31% | 54.50% | |
| S3 | LVC + V4 | 43.49% | 56.51% | 52.06% |
| HVC | 42.94% | 57.06% | 52.87% | |
| S4 | LVC + V4 | 42.18% | 57.82% | 52.19% |
| HVC | 33.39% | 66.61% | 53.32% | |
| S5 | LVC + V4 | 45.91% | 54.09% | 52.77% |
| HVC | 42.95% | 57.05% | 54.60% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Zhang, C.; Wang, L.; Ding, P.; Hu, L.; Yan, B.; Tong, L. A Visual Encoding Model Based on Contrastive Self-Supervised Learning for Human Brain Activity along the Ventral Visual Stream. Brain Sci. 2021, 11, 1004. https://doi.org/10.3390/brainsci11081004
Li J, Zhang C, Wang L, Ding P, Hu L, Yan B, Tong L. A Visual Encoding Model Based on Contrastive Self-Supervised Learning for Human Brain Activity along the Ventral Visual Stream. Brain Sciences. 2021; 11(8):1004. https://doi.org/10.3390/brainsci11081004
Chicago/Turabian StyleLi, Jingwei, Chi Zhang, Linyuan Wang, Penghui Ding, Lulu Hu, Bin Yan, and Li Tong. 2021. "A Visual Encoding Model Based on Contrastive Self-Supervised Learning for Human Brain Activity along the Ventral Visual Stream" Brain Sciences 11, no. 8: 1004. https://doi.org/10.3390/brainsci11081004
APA StyleLi, J., Zhang, C., Wang, L., Ding, P., Hu, L., Yan, B., & Tong, L. (2021). A Visual Encoding Model Based on Contrastive Self-Supervised Learning for Human Brain Activity along the Ventral Visual Stream. Brain Sciences, 11(8), 1004. https://doi.org/10.3390/brainsci11081004