Are Linguistic Prediction Deficits Characteristic of Adults with Dyslexia?




Abstract
1. Are Linguistic Prediction Deficits Characteristic of Adults with Dyslexia?
2. Prediction in Language Comprehension
2.1. Relationship between Prediction and Language Abilities
2.2. Multiple Deficit Theories of Dyslexia
2.3. Current Study
3. Method
3.1. Participants
3.2. Rapid Automatised Naming
3.3. Linguistic Prediction Task
3.4. Apparatus
3.5. Design and Procedure
3.6. Data Screening and Analysis
4. Results
4.1. Main Analysis
4.2. Age and Gender
5. Discussion
5.1. Limitations
5.2. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lyon, G.R.; Shaywitz, S.E.; Shaywitz, B.A. A definition of dyslexia. Ann. Dyslexia 2003, 53, 1–14. [Google Scholar] [CrossRef]
- Pennington, B.F. From single to multiple deficit modes of developmental disorders. Cognition 2006, 101, 385–413. [Google Scholar] [CrossRef]
- Sonuga-Barke, E.J.S. Causal models of attention-deficit/hyperactivity disorder: From common simple deficits to multiple developmental pathways. Biol. Psychiatry 2005, 57, 1231–1238. [Google Scholar] [CrossRef] [PubMed]
- Huettig, F.; Brouwer, S. Delayed anticipatory spoken language proce3ssing in adults with Dyslexia—Evidence from eye-tracking. Dyslexia 2015, 21, 97–122. [Google Scholar] [CrossRef]
- Ng, S.; Payne, B.R.; Stine-Morrow, E.A.; Federmeier, K.D. How struggling adult readers use contextual information when comprehending speech: Evidence from event-related potentials. Int. J. Psychophysiol. 2018, 125, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Ben-Dor, I.; Pollatsek, A.; Scarpati, S. Word identification in isolation and in context by college dyslexic students. Brain Lang. 1991, 40, 471–490. [Google Scholar] [CrossRef]
- Bruck, M. Word-recognition skills of adults with childhood diagnosis of dyslexia. Dev. Psychol. 1990, 26, 439–454. [Google Scholar] [CrossRef]
- Ehrlich, S.F.; Rayner, K. Contextual effects on word perception and eye movements during reading. J. Verbal Learn. Verbal Behav. 1981, 20, 641–655. [Google Scholar] [CrossRef]
- Rayner, K.; Well, A.D. Effects of contextual constraint on eye movements in reading: A further examination. Psychon. Bull. Rev. 1996, 3, 504–509. [Google Scholar] [CrossRef]
- Rayner, K. Eye movements in reading and information processing: 20 year of research. Psychol. Bull. 1998, 124, 372–422. [Google Scholar] [CrossRef]
- Altmann, G.T.M. Ambiguity in sentence processing. Trends Cogn. Sci. 1998, 2, 146–152. [Google Scholar] [CrossRef]
- Brothers, T.; Swaab, T.Y.; Traxler, M.J. Goals and strategies influence lexical prediction during sentence comprehension. J. Mem. Lang. 2017, 93, 203–216. [Google Scholar] [CrossRef]
- Clark, A. Are we predictive engines? Perils, prospects, and the puzzle of the porous perceiver. Behav. Brain Sci. 2013, 36, 233–253. [Google Scholar] [CrossRef]
- Henderson, J.M.; Choi, W.; Lowder, M.W.; Ferreira, F. Language structure in the brain: A fixation-related fMRI study of syntactic surprisal in reading. NeuroImage 2016, 132, 293–300. [Google Scholar] [CrossRef] [PubMed]
- Huettig, F. Four central questions about prediction in language processing. Brain Res. 2015, 1626, 118–135. [Google Scholar] [CrossRef]
- Lupyan, G.; Clark, A. Words and the world: Predictive coding and the language-perception-cognition interface. Curr. Dir. Psychol. Sci. 2015, 24, 279–284. [Google Scholar] [CrossRef]
- Rayner, K.; Ashby, J.; Pollatsek, A.; Reichle, E.D. The effects of frequency and predictability on eye fixations in reading: Implications for the E-Z reader model. J. Exp. Psychol. Hum. Percept. Perform. 2004, 30, 720–732. [Google Scholar] [CrossRef]
- Gibson, E. Linguistic complexity: Locality of syntactic dependencies. Cognition 1998, 68, 1–76. [Google Scholar] [CrossRef]
- Van Petten, C.; Luka, B.J. Prediction during language comprehension: Benefits, costs, and ERP components. Int. J. Psychophysiol. 2012, 83, 176–190. [Google Scholar] [CrossRef]
- DeLong, K.A.; Urbach, T.P.; Kutas, M. Probabilistic word pre-activation during language comprehension inferred from electrical brain activity. Nat. Neurosci. 2005, 8, 1117–1121. [Google Scholar] [CrossRef]
- Federmeier, K.D. Thinking ahead: The role and roots of prediction in language comprehension. Psychophysiology 2007, 44, 491–505. [Google Scholar] [CrossRef]
- Federmeier, K.D.; Kutas, M. A Rose by Any Other Name: Long-Term Memory Structure and Sentence Processing. J. Mem. Lang. 1999, 41, 469–495. [Google Scholar] [CrossRef]
- Van Berkum, J.J.; Brown, C.M.; Zwitserlood, P.; Kooijman, V.; Hagoort, P. Anticipating upcoming words in discourse: Evidence from ERPs and reading times. J. Exp. Psychol. Learn. Mem. Cogn. 2005, 31, 443–467. [Google Scholar] [CrossRef] [PubMed]
- Hagoort, P.; Baggio, B.; Willems, R. Semantic Unification. In The Cognitive Neurosciences, 4th ed.; Gazzaniga, M., Ed.; MIT Press: Cambridge, MA, USA, 2009; pp. 819–836. [Google Scholar]
- Jackendoff, R. Foundations of Language: Brain, Meaning, Grammar, Evolution; Oxford University Press: New York, NY, USA, 2002. [Google Scholar]
- Lau, E.F.; Phillips, C.; Poeppel, D. A cortical network for semantics: (de)constructing the N400. Nat. Rev. Neurosci. 2008, 9, 920–933. [Google Scholar] [CrossRef]
- Kuperberg, G.R.; Jaeger, T.F. What do we mean by prediction in language comprehension? Lang. Cogn. Neurosci. 2016, 31, 32–59. [Google Scholar] [CrossRef] [PubMed]
- Ferreira, F.; Chantavarin, S. Integration and prediction in language processing: A synthesis of old and new. Curr. Dir. Psychol. Sci. 2016, 27, 443–448. [Google Scholar] [CrossRef] [PubMed]
- Altmann, G.; Mirković, J. Incrementality and prediction in human sentence processing. Cogn. Sci. 2009, 33, 583–609. [Google Scholar] [CrossRef]
- Van Berkum, J.J.; Hagoort, P.; Brown, C.M. Semantic integration in sentences and discourse: Evidence from the N400. J. Cogn. Neurosci. 1999, 11, 657–671. [Google Scholar] [CrossRef] [PubMed]
- Ferreira, F.; Lowder, M.W. Prediction, information structure, and good-enough language processing. Psychol. Learn. Motiv. 2016, 65, 217–247. [Google Scholar]
- Taylor, W.L. “Cloze procedure”: A new tool for measuring readability. Journal. Bull. 1953, 30, 415–433. [Google Scholar] [CrossRef]
- Loerts, H.; Stowe, L.A.; Schmid, M.S. Predictability speeds up the re-analysis process: An ERP investigation of gender agreement and cloze probability. J. Neurolinguist. 2013, 26, 561–580. [Google Scholar] [CrossRef]
- Kutas, M.; Federmeier, K.D. Thirty years and counting: Finding meaning in the N400 component of the event-related brain potential (ERP). Annu. Rev. Psychol. 2011, 62, 621–647. [Google Scholar] [CrossRef] [PubMed]
- Kutas, M.; Hillyard, S.A. Brain potentials during reading reflect word expectancy and semantic association. Nature 1984, 307, 161–163. [Google Scholar] [CrossRef] [PubMed]
- Noordenbos, M.W.; Segers, E.; Wagensveld, B.; Verhoeven, L. Aberrant N400 responses to phonological overlap during rhyme judgements in children at risk for dyslexia. Brain Res. 2013, 1537, 233–243. [Google Scholar] [CrossRef] [PubMed]
- Jednoróg, K.; Marchewka, A.; Tacikowski, P.; Grabowska, A. Implicit phonological and semantic processing in children with developmental dyslexia: Evidence from event-related potentials. Neuropsychologia 2010, 48, 2447–2457. [Google Scholar] [CrossRef] [PubMed]
- Kutas, M.; Hillyard, S.A. Reading senseless sentences: Brain potentials reflect semantic incongruity. Science 1980, 207, 203–205. [Google Scholar] [CrossRef]
- DeLong, K.A.; Quante, L.; Kutas, M. Predictability, plausiblity, and two late ERP positivities during written sentence comprehension. Neuropsychologia 2014, 61, 150–162. [Google Scholar] [CrossRef]
- Deacon, D.; Dynowska, A.; Ritter, W.; Grose-Fifer, J. Repetition and semantic priming of nonwords: Implications for theories of N400 and word recognition. Psychophysiology 2004, 41, 60–74. [Google Scholar] [CrossRef]
- Staub, A. The effect of lexical predictability on eye movements in reading: Critical review and theoretical interpretation. Lang. Linguist. Compass 2015, 9, 311–327. [Google Scholar] [CrossRef]
- Staub, A.; Grant, M.; Astheimer, L.; Cohen, A. The influence of cloze probability and item constraint on cloze task response time. J. Mem. Lang. 2015, 82, 1–17. [Google Scholar] [CrossRef]
- Otto, T.U.; Mamassian, P. Noise and correlations in parallel perceptual decision making. Curr. Biol. 2012, 22, 1391–1396. [Google Scholar] [CrossRef] [PubMed]
- Huettig, F.; Mishra, R.K. How literacy acquisition affects the illiterate mind: A critical examination of theories and evidence. Lang. Linguist. Compass 2014, 8, 401–427. [Google Scholar] [CrossRef]
- Mani, N.; Huettig, F. Prediction during language processing is a piece of cake—But only for skilled producers. J. Exp. Psychol. Hum. Percept. Perform. 2012, 38, 843–847. [Google Scholar] [CrossRef]
- Mishra, R.K.; Singh, N.; Pandey, A.; Huettig, F. Spoken language-mediated anticipatory eye movements are modulated by reading ability: Evidence from Indian low and high literates. J. Eye Mov. Res. 2012, 5, 1–10. [Google Scholar]
- Huettig, F.; Pickering, M.J. Literacy advantages beyond reading: Prediction of spoken language. Trends Cogn. Sci. 2019, 23, 464–475. [Google Scholar] [CrossRef]
- Connolly, J.F.; Phillips, N.A. Event-related potential components reflect phonological and semantic processing of the terminal word of spoken sentences. J. Cogn. Neurosci. 1994, 6, 256–266. [Google Scholar] [CrossRef]
- Stanovich, K.E. The Future of a Mistake: Will Discrepancy Measurement Continue to Make the Learning Disabilities Field a Pseudoscience? Learn. Disabil. Q. 2005, 28, 103. [Google Scholar] [CrossRef]
- Stanovich, K.E.; Siegel, L.S. Phenotypic performance profile of children with reading disabilities: A regression-based test of the phonological-core variable-difference model. J. Educ. Psychol. 1994, 86, 24–53. [Google Scholar] [CrossRef]
- Wolf, M.; Bowers, P.G. The double-deficit hypothesis for the developmental dyslexias. J. Educ. Psychol. 1999, 91, 415–438. [Google Scholar] [CrossRef]
- Peterson, R.L.; Pennington, B.F. Developmental dyslexia. Lancet 2012, 379, 1997–2007. [Google Scholar] [CrossRef]
- Shankweiler, D.; Crain, S. Language mechanisms and reading disorder: A modular approach. Cognition 1986, 24, 139–168. [Google Scholar] [CrossRef]
- Stein, J. The current status of the magnocellular theory of developmental dyslexia. Neuropsychologia 2019, 130, 66–77. [Google Scholar] [CrossRef] [PubMed]
- Rosen, S. Auditory processing in dyslexia and specific language impairment: Is there a deficit? What is its nature? Does it explain anything? J. Phon. 2003, 31, 509–527. [Google Scholar] [CrossRef]
- Laprevotte, J.; Papaxanthis, C.; Saltarelli, S.; Quericia, P.; Gaveau, J. Is my Arm moving? Proprioceptive impairment in developmental dyslexia. medRxiv 2020. [Google Scholar] [CrossRef]
- Nicolson, R.I.; Fawcett, A.J. Development of dyslexia: The delayed neural commitment framework. Front. Behav. Neurosci. 2019, 13, 112. [Google Scholar] [CrossRef]
- Cicchini, G.M.; Marino, C.; Mascheretti, S.; Perani, D.; Morrone, M.C. Strong motion deficits in dyslexia associated with DCDC2 gene alternation. J. Neurosci. 2015, 35, 8059–8064. [Google Scholar] [CrossRef]
- Hagoort, P. Interplay between syntax and semantics during sentence comprehension: ERP effects of combining syntactic and semantic violations. J. Cogn. Neurosci. 2003, 15, 883–899. [Google Scholar] [CrossRef]
- Arcuri, S.M.; Rabe-Hesketh, S.; Morris, R.G.; McGuire, P.K. Regional variation of cloze probabilities for sentence contexts. Behav. Res. Methods Instrum. Comput. 2001, 33, 80–90. [Google Scholar] [CrossRef]
- Bonifacci, P.; Snowling, M.J. Speed of processing and reading disability: A cross-linguistic investigation of dyslexia and borderline intellectual functioning. Cognition 2008, 107, 999–1017. [Google Scholar] [CrossRef]
- Moll, K.; Gobel, S.M.; Gooch, D.; Landerl, K.; Snowling, M.J. Cognitive risk factors for specific learning disorder: Processing speed, temporal processing, and working memory. J. Learn. Disabil. 2016, 49, 272–281. [Google Scholar] [CrossRef]
- Stoodley, C.J.; Stein, J.F. A processing speed deficit in dyslexic adults? Evidence from a peg-moving task. Neurosci. Lett. 2006, 399, 264–267. [Google Scholar] [CrossRef] [PubMed]
- Stella, M.; Engelhardt, P.E. Syntactic ambiguity resolution in dyslexia: An examintation of cogntive facators udnerlying eye movement differences and comprehension failures. Dyslexia 2019, 25, 115–141. [Google Scholar] [CrossRef] [PubMed]
- Denckla, M.B.; Rudel, R.G. Rapid automized naming (RAN): Dyslexia differentiated from other learning disabilities. Neuropsychologia 1976, 14, 471–479. [Google Scholar] [CrossRef]
- Wolf, M.; Bowers, P.G.; Biddle, K. Naming-Speed Processes, Timing, and Reading. J. Learn. Disabil. 2000, 33, 387–407. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing; R Core Team: Vienna, Austria, 2018; Available online: https://www.R-project.org/ (accessed on 12 December 2019).
- Bates, D.M.; Maechler, M.; Bolker, B.; Walker, S. Lme4: Linear Mixed-Effects Models Using S4 Classes; R package version 1.1-18-1. 2018. Available online: https://cran.r-project.org/web/packages/lme4/index.html (accessed on 15 December 2019).
- Barr, D.J.; Levy, R.; Scheepers, C.; Tily, H.J. Random effects structure for confirmatory hypothesis testing: Keep it maximal. J. Mem. Lang. 2013, 68, 255–278. [Google Scholar] [CrossRef]
- Kail, R.; Salthouse, T.A. Processing speed as a mental capacity. Acta Psychol. 1994, 86, 199–225. [Google Scholar] [CrossRef]
- Salthouse, T.A. The processing speed theory of adult age differences in cognition. Psychol. Rev. 1996, 103, 403–428. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| High | Low | Anomalous | |
|---|---|---|---|
| Low Constraint | |||
| The ruby was so big it looked like a ______. | Cherry (0.14) | Tomato (0.07) | Jacket |
| I don’t know why he didn’t take his ______. | Medicine (0.14) | Umbrella (0.09) | Pavement |
| They went to the rear of the long ________. | Queue (0.15) | Train (0.06) | Nails |
| Hank reached into his pocket to get the ___. | Money (0.30) | Change (0.09) | Shade |
| The hunter shot and killed a large _______. | Deer (0.36) | Lion (0.06) | Wind |
| High Constraint | |||
| The sail got loose so they tightened the __. | Rope (0.54) | Mast (0.06) | Idea |
| Yesterday, they canoed down the _______. | River (0.81) | Amazon (0.01) | Woods |
| The ship disappeared into the thick _____. | Fog (0.89) | Mist (0.10) | Cat |
| At night, the old woman locked the _____. | Doors (0.94) | House (0.03) | Feast |
| Her job was easy most of the __________. | Time (0.99) | Way (0.01) | Hair |
| High | Low | Anomalous | ||
|---|---|---|---|---|
| Length (# Characters) | 4.81 (1.15) | 5.40 (1.59) | 4.79 (1.23) | F(2,216) = 11.47, p < 0.001 |
| Length (# Syllables) | 1.32 (0.59) | 1.52 (0.70) | 1.35 (0.61) | F(2,216) = 3.33, p < 0.05 |
| BNC Frequency | 113.1 (189.8) | 105.3 (155.5) | 90.7 (146.7) | F(2,216) = 0.55, p = 0.58 |
| KF Written Frequency | 123.9 (205.2) | 119.1 (186.3) | 106.1 (180.3) | F(2,216) = 0.26, p = 0.77 |
| Thorndike-Lorge WF | 855.6 (1266.9) | 765.4 (1138.6) | 761.5 (1281.6) | F(2,216) = 0.19, p = 0.83 |
| Brown Verbal Frequency | 21.2 (49.2) | 27.2 (78.9) | 14.0 (36.7) | F(2,216) = 1.53, p = 0.22 |
| Concreteness | 395.7 (242.3) | 379.6 (241.6) | 444.2 (234.0) | F(2,216) = 2.67, p = 0.07 |
| Imagability | 411.7 (245.1) | 406.2 (243.5) | 455.6 (230.4) | F(2,216) = 1.80, p = 0.17 |
| Neighborhood Size | 19.1(14.0) | 14.0(13.7) | 18.0(13.9) | F(2,214) = 4.72, p = 0.01 |
| Neighborhood Frequency | 183.7(510.8) | 104.8(300.7) | 114.5(204.0) | F(2,212) = 1.93, p = 0.24 |
| Fixed Effects | Estimate | Std. Error | DF | t-Value | p-Value |
|---|---|---|---|---|---|
| Intercept | 1388.75 | 55.59 | 121 | 24.98 | <0.001 |
| Continuation | −30.71 | 29.00 | 303 | −1.06 | 0.29 |
| Constraint | 23.01 | 35.70 | 264 | 0.64 | 0.52 |
| Group | −215.27 | 72.82 | 96 | −2.96 | 0.004 |
| Continuation × Constraint | −144.38 | 35.56 | 5166 | −4.06 | <0.001 |
| Continuation × Group | −110.38 | 39.01 | 282 | −2.83 | 0.005 |
| Constraint × Group | −37.42 | 34.74 | 5077 | −1.08 | 0.28 |
| Continuation × Constraint × Group | 110.56 | 48.00 | 5070 | 2.30 | 0.02 |
| Linear Hypotheses | Estimate | Std. Error | z-Value | p-Value | Cohen’s D |
|---|---|---|---|---|---|
| Low-Constraint Items | |||||
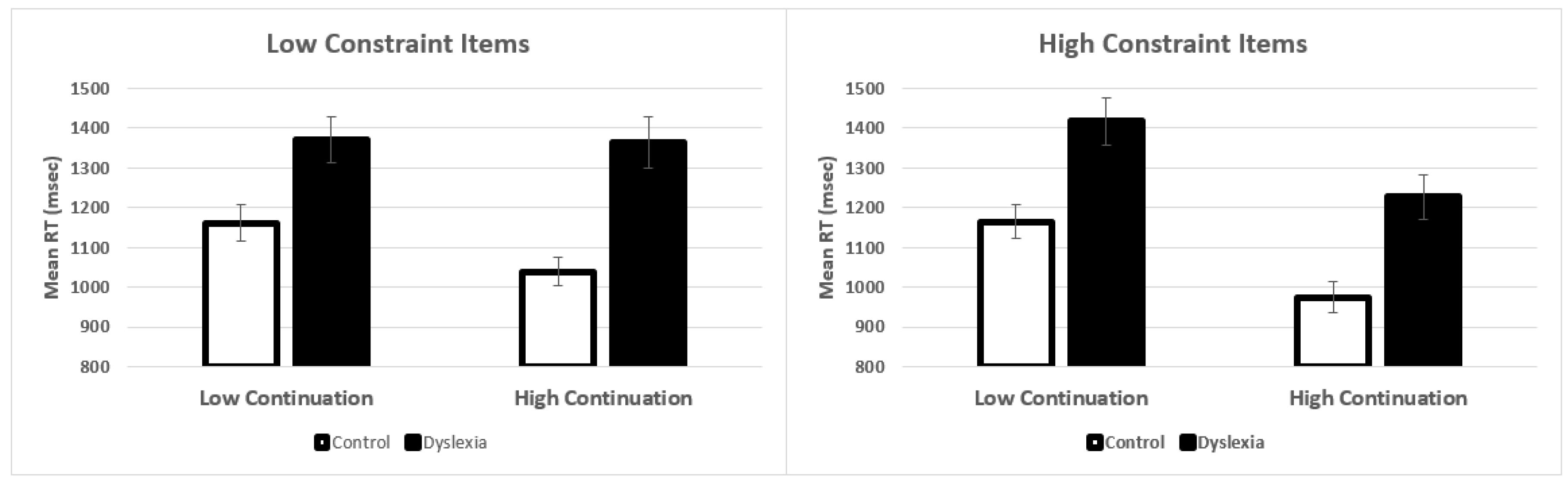
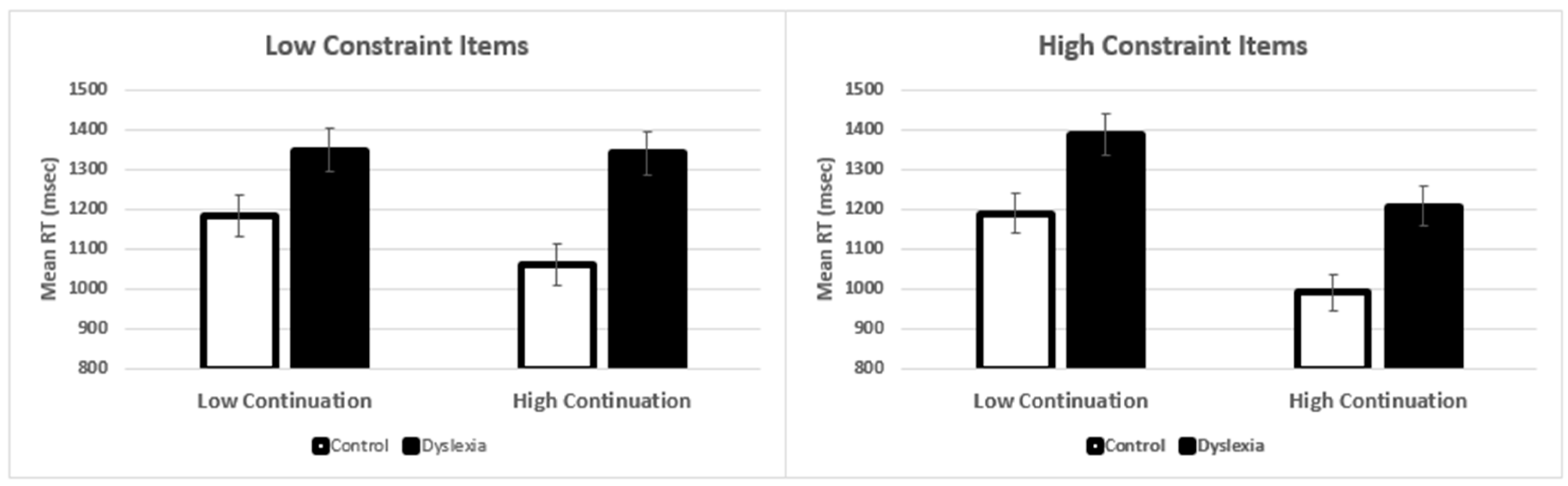
| 1. Control-Low Cont. vs. Control-High Cont. | −140.20 | 28.20 | −4.92 | <0.001 | 0.584 |
| 2. Control-Low Cont. vs. Dyslexia-Low Cont. | −216.25 | 73.79 | −2.93 | 0.046 | 0.615 |
| 3. Control-High Cont. vs. Dyslexia-High Cont. | −326.68 | 73.75 | −4.43 | <0.001 | 0.968 |
| 4. Dyslexia-Low Cont. vs. Dyslexia-High Cont. | −29.76 | 29.45 | −1.01 | 0.955 | 0.035 |
| High-Constraint Items | |||||
| 5. Control-Low Cont. vs. Control-High Cont. | −175.31 | 25.65 | −6.84 | <0.001 | 1.15 |
| 6. Control-Low Cont. vs. Dyslexia-Low Cont. | −252.81 | 72.24 | −3.50 | 0.007 | 0.753 |
| 7. Control-High Cont. vs. Dyslexia-High Cont. | −253.89 | 66.29 | −3.83 | 0.002 | 0.825 |
| 8. Dyslexia-Low Cont. vs. Dyslexia-High Cont. | −174.23 | 26.46 | −6.59 | <0.001 | 1.06 |
| Additional Contrasts | |||||
| Controls | |||||
| 9. Low-Cont./Low-Const. vs. Low-Cont./High-Const. | −13.93 | 34.40 | −0.41 | 0.999 | 0.02 |
| 10. High-Cont./Low Const. vs. High-Cont./High-Const. | 126.27 | 35.77 | 3.53 | 0.007 | 0.543 |
| Dyslexia | |||||
| 11. Low-Cont./Low-Const. vs. Low-Cont./High-Const. | 22.64 | 38.04 | 0.60 | 0.998 | 0.028 |
| 12. High-Cont./Low-Const. vs. High-Cont./High-Const. | −121.83 | 37.46 | −3.25 | 0.017 | 0.747 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Engelhardt, P.E.; Yuen, M.K.Y.; Kenning, E.A.; Filipovic, L. Are Linguistic Prediction Deficits Characteristic of Adults with Dyslexia? Brain Sci. 2021, 11, 59. https://doi.org/10.3390/brainsci11010059
Engelhardt PE, Yuen MKY, Kenning EA, Filipovic L. Are Linguistic Prediction Deficits Characteristic of Adults with Dyslexia? Brain Sciences. 2021; 11(1):59. https://doi.org/10.3390/brainsci11010059
Chicago/Turabian StyleEngelhardt, Paul E., Michelle K. Y. Yuen, Elise A. Kenning, and Luna Filipovic. 2021. "Are Linguistic Prediction Deficits Characteristic of Adults with Dyslexia?" Brain Sciences 11, no. 1: 59. https://doi.org/10.3390/brainsci11010059
APA StyleEngelhardt, P. E., Yuen, M. K. Y., Kenning, E. A., & Filipovic, L. (2021). Are Linguistic Prediction Deficits Characteristic of Adults with Dyslexia? Brain Sciences, 11(1), 59. https://doi.org/10.3390/brainsci11010059