State-of-the-Art CNN Optimizer for Brain Tumor Segmentation in Magnetic Resonance Images

 , ,
, ,  ,
,
Abstract
1. Introduction
2. Literature Review
3. Optimization Algorithms
3.1. Adaptive Momentum (Adam)
- : Initial learning rate
- : Gradient at time t along
- : Exponential average of gradient along
- : Exponential average of squares of gradient along
- : Hyperparameters
3.2. Stochastic Gradient Descent (SGD)
3.3. Momentum
3.4. Adaptive Gradient (Adagrad)
3.5. Adaptive Delta (AdaDelta)
- the incessant rot of learning rates for the training time and
- the requirement for automatically chosen comprehensive learning rates.
3.6. Adaptive Max Pooling (Adamax)
3.7. Nesterov Adaptive Momentum (Nadam)
3.8. Root Mean Square Propagation (RMSProp)
3.9. Cyclic Learning Rate (CLR)
- CLR provides a technique for setting the global learning rates for training neural systems that take out the the need to perform tons of investigations to locate the best values with no extra computations.
- CLR provides an excellent learning rate range (LR range) for an experiment by introducing the concept of LR range test.
3.10. Nesterov Accelerated Gradient (NAG)
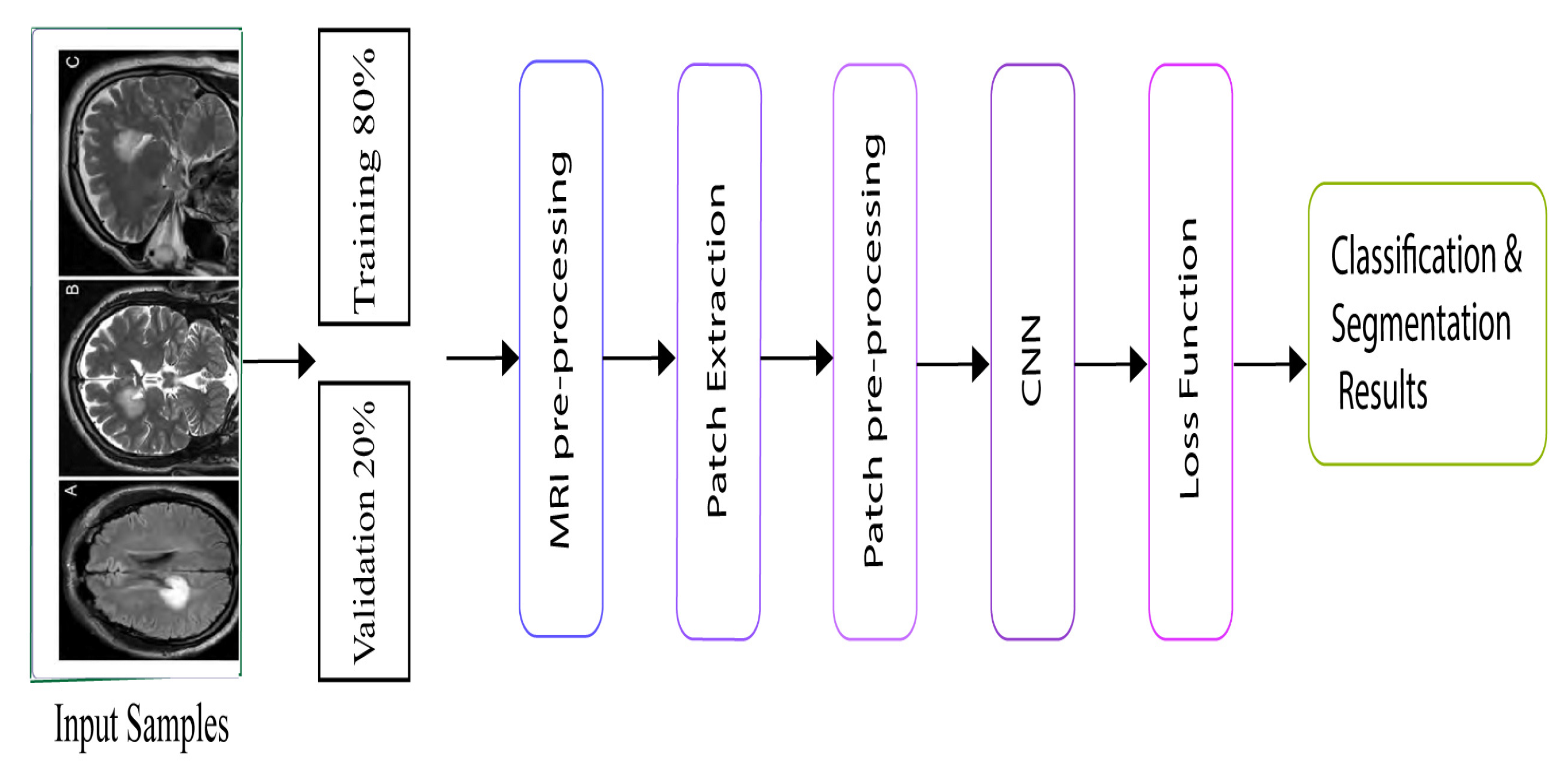
4. Data Set and Methodology
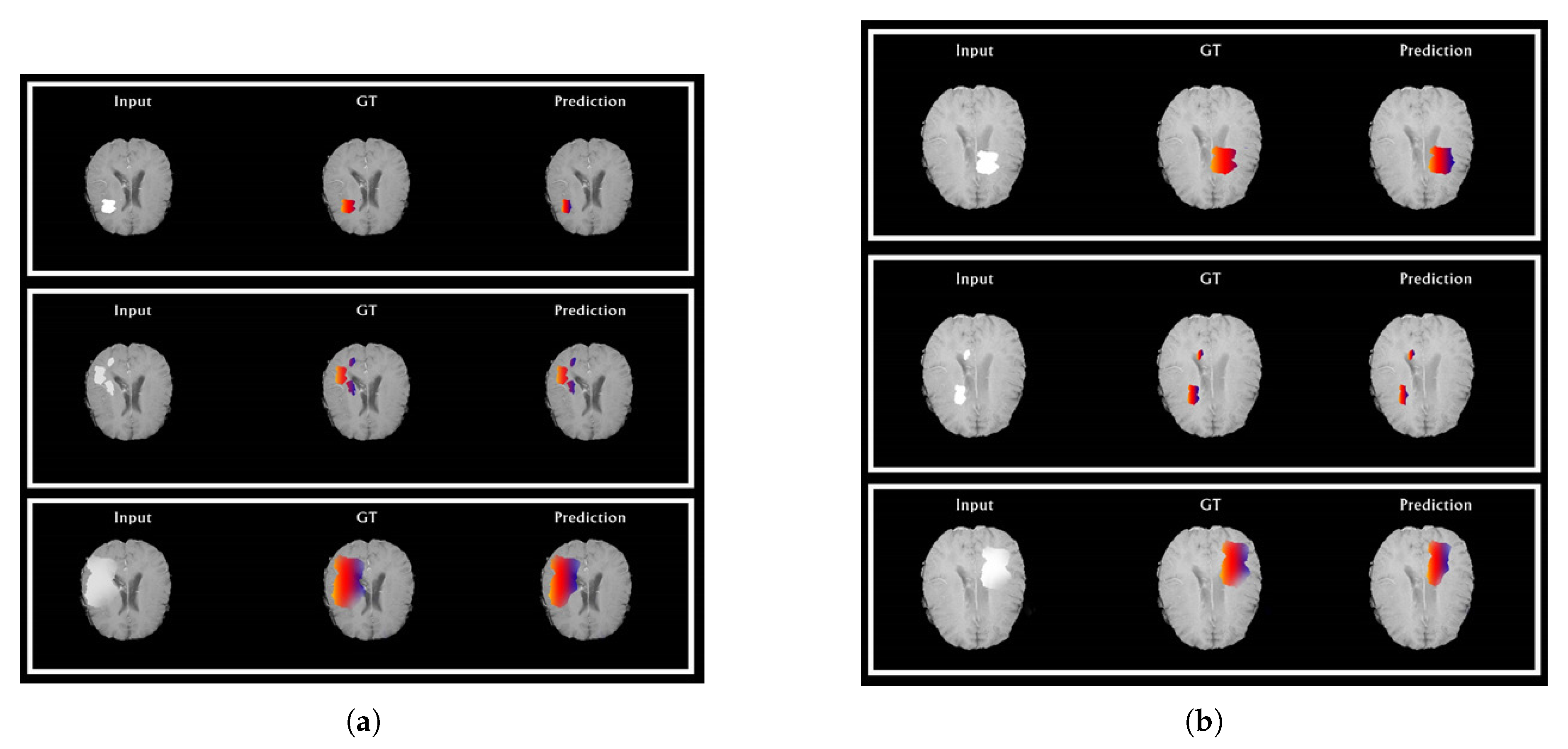
5. Experimental Results and Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| DLA | Deep learning algorithms |
| CNN | Convolutional Neural Network |
| MRI | Magnetic Resonance Images |
| Adagrad | Adaptive Gradient |
| AdaDelta | Adaptive Delta |
| SGD | Stochastic Gradient14Descent |
| Adam | Adaptive Momentum |
| CLR | Cyclic Learning Rate |
| Adamax | Adaptive Max Pooling15 |
| RMS Prop | Root Mean Square Propagation |
| NADAM | Nesterov Adaptive Momentum |
| NAG | Nesterov accelerated gradient |
| HGG | High-Grade Gliomas |
| LGG | Low-Grade Gliomas |
| CNS | Central nervous system |
| ANN | Artificial Neural Network |
| GT | Ground Truth |
| CV | Computer Vision |
| PSO | Particle Swarm Optimization |
| FLAIR | Fluid Attenuation Inversion Recovery |
| SIFT | Scale-Invariant Feature Transform |
| DCNN | Deep Convolutional Neural Network |
References
- Walker, E.V.; Davis, F.G. Malignant primary brain and other central nervous system tumors diagnosed in Canada from 2009 to 2013. Neuro Oncol. 2019, 21, 360–369. [Google Scholar] [CrossRef] [PubMed]
- Mzoughi, H.; Njeh, I.; Wali, A.; Slima, M.B.; BenHamida, A.; Mhiri, C.; Mahfoudhe, K.B. Deep Multi-Scale 3D Convolutional Neural Network (CNN) for MRI Gliomas Brain Tumor Classification. J. Digit. Imaging 2020. [Google Scholar] [CrossRef] [PubMed]
- Havaei, M.; Davy, A.; Warde-Farley, D.; Biard, A.; Courville, A.; Bengio, Y.; Pal, C.; Jodoin, P.M.; Larochelle, H. Brain tumor segmentation with deep neural networks. Med Image Anal. 2017, 35, 18–31. [Google Scholar] [CrossRef] [PubMed]
- Fukushima, K. Neocognitron. Scholarpedia 2007, 2, 1717. [Google Scholar] [CrossRef]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. Int. Conf. Mach. Learn. 2013, 1139–1147. [Google Scholar]
- Fletcher, E.; Knaack, A. Applications of deep learning to brain segmentation and labeling of mri brain structures. Handb. Pattern Recognit. Comput. Vis. 2020, 251. [Google Scholar]
- Ahmad, A.; Hassan, M.; Abdullah, M.; Rahman, H.; Hussin, F.; Abdullah, H.; Saidur, R. A review on applications of ANN and SVM for building electrical energy consumption forecasting. Renew. Sustain. Energy Rev. 2014, 33, 102–109. [Google Scholar] [CrossRef]
- Fukushima, K. Neocognitron: A hierarchical neural network capable of visual pattern recognition. Neural Netw. 1988, 1, 119–130. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Lee, S.G.; Sung, Y.; Kim, Y.G.; Cha, E.Y. Variations of AlexNet and GoogLeNet to Improve Korean Character Recognition Performance. J. Inf. Process. Syst. 2018, 14. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Imaging 2018, 9, 611–629. [Google Scholar] [CrossRef] [PubMed]
- Yang, T.; Wu, Y.; Zhao, J.; Guan, L. Semantic segmentation via highly fused convolutional network with multiple soft cost functions. Cogn. Syst. Res. 2019, 53, 20–30. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef]
- Graham, B. Spatially-sparse convolutional neural networks. arXiv 2014, arXiv:1409.6070. [Google Scholar]
- Kayalibay, B.; Jensen, G.; van der Smagt, P. CNN-based segmentation of medical imaging data. arXiv 2017, arXiv:1701.03056. [Google Scholar]
- Hosseini, H.; Xiao, B.; Jaiswal, M.; Poovendran, R. On the limitation of convolutional neural networks in recognizing negative images. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 352–358. [Google Scholar]
- Bao, P.; Zhang, L.; Wu, X. Canny edge detection enhancement by scale multiplication. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1485–1490. [Google Scholar] [CrossRef] [PubMed]
- Bouvrie, J. Notes on Convolutional Neural Networks. 2006; Unpublished. [Google Scholar]
- Mehmood, A.; Maqsood, M.; Bashir, M.; Shuyuan, Y. A Deep Siamese Convolution Neural Network for Multi-Class Classification of Alzheimer Disease. Brain Sci. 2020, 10, 84. [Google Scholar] [CrossRef]
- Ghoreishi, S.F.; Imani, M. Bayesian optimization for efficient design of uncertain coupled multidisciplinary systems. In Proceedings of the 2020 American Control Conference (ACC 2020), Denver, CO, USA, 1–3 July 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Sultan, H.H.; Salem, N.M.; Al-Atabany, W. Multi-classification of Brain Tumor Images using Deep Neural Network. IEEE Access 2019, 7, 69215–69225. [Google Scholar] [CrossRef]
- Swati, Z.N.K.; Zhao, Q.; Kabir, M.; Ali, F.; Ali, Z.; Ahmed, S.; Lu, J. Content-Based Brain Tumor Retrieval for MR Images Using Transfer Learning. IEEE Access 2019, 7, 17809–17822. [Google Scholar] [CrossRef]
- Becherer, N.; Pecarina, J.; Nykl, S.; Hopkinson, K. Improving optimization of convolutional neural networks through parameter fine-tuning. Neural Comput. Appl. 2019, 31, 3469–3479. [Google Scholar] [CrossRef]
- Barkana, B.D.; Saricicek, I.; Yildirim, B. Performance analysis of descriptive statistical features in retinal vessel segmentation via fuzzy logic, ANN, SVM, and classifier fusion. Knowl. Based Syst. 2017, 118, 165–176. [Google Scholar] [CrossRef]
- Emery, N.J.; Seed, A.M.; Von Bayern, A.M.; Clayton, N.S. Cognitive adaptations of social bonding in birds. Philos. Trans. R. Soc. Biol. Sci. 2007, 362, 489–505. [Google Scholar] [CrossRef] [PubMed]
- He, S.; Wu, Q.; Saunders, J. A group search optimizer for neural network training. In International Conference on Computational Science and Its Applications; Springer: Berlin, Germany, 2006; pp. 934–943. [Google Scholar]
- Yousoff, S.N.M.; Baharin, A.; Abdullah, A. A review on optimization algorithm for deep learning method in bioinformatics field. In Proceedings of the 2016 IEEE EMBS Conference on Biomedical Engineering and Sciences (IECBES), Kuala Lumpur, Malaysia, 4–8 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 707–711. [Google Scholar]
- De, S.; Mukherjee, A.; Ullah, E. Convergence guarantees for RMSProp and ADAM in non-convex optimization and an empirical comparison to Nesterov acceleration. arXiv 2018, arXiv:1807.06766. [Google Scholar]
- Prilianti, K.; Brotosudarmo, T.; Anam, S.; Suryanto, A. Performance comparison of the convolutional neural network optimizer for photosynthetic pigments prediction on plant digital image. AIP Conf. Proc. 2019, 2084, 020020. [Google Scholar]
- Zhao, H.; Liu, F.; Zhang, H.; Liang, Z. Research on a learning rate with energy index in deep learning. Neural Netw. 2019, 110, 225–231. [Google Scholar] [CrossRef]
- Moulines, E.; Bach, F.R. Non-asymptotic analysis of stochastic approximation algorithms for machine learning. In Proceedings of the Advances in Neural Information Processing Systems, Granada, Spain, 12–14 December 2011; pp. 451–459. [Google Scholar]
- Chandra, B.; Sharma, R.K. Deep learning with adaptive learning rate using laplacian score. Expert Syst. Appl. 2016, 63, 1–7. [Google Scholar] [CrossRef]
- Shen, D.; Wu, G.; Suk, H.I. Deep learning in medical image analysis. Annu. Rev. Biomed. Eng. 2017, 19, 221–248. [Google Scholar] [CrossRef]
- Sajjad, M.; Khan, S.; Muhammad, K.; Wu, W.; Ullah, A.; Baik, S.W. Multi-grade brain tumor classification using deep CNN with extensive data augmentation. J. Comput. Sci. 2019, 30, 174–182. [Google Scholar] [CrossRef]
- Afshar, P.; Mohammadi, A.; Plataniotis, K.N. Brain tumor type classification via capsule networks. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 3129–3133. [Google Scholar]
- Qayyum, A.; Anwar, S.M.; Majid, M.; Awais, M.; Alnowami, M. Medical image analysis using convolutional neural networks: A review. arXiv 2017, arXiv:1709.02250. [Google Scholar]
- Iftikhar, S.; Fatima, K.; Rehman, A.; Almazyad, A.S.; Saba, T. An evolution based hybrid approach for heart diseases classification and associated risk factors identification. Biomed. Res. 2017, 28, 3451–3455. [Google Scholar]
- Isensee, F.; Kickingereder, P.; Wick, W.; Bendszus, M.; Maier-Hein, K.H. Brain tumor segmentation and radiomics survival prediction: Contribution to the BRATS 2017 challenge. In International MICCAI Brainlesion Workshop; Springer: Berlin, Germany, 2017; pp. 287–297. [Google Scholar]
- Wu, H.; Yang, S.; Huang, Z.; He, J.; Wang, X. Type 2 diabetes mellitus prediction model based on data mining. Inform. Med. Unlocked 2018, 10, 100–107. [Google Scholar] [CrossRef]
- Doike, T.; Hayashi, K.; Arata, S.; Mohammad, K.N.; Kobayashi, A.; Niitsu, K. A Blood Glucose Level Prediction System Using Machine Learning Based on Recurrent Neural Network for Hypoglycemia Prevention. In Proceedings of the 2018 16th IEEE International New Circuits and Systems Conference (NEWCAS), Montreal, QC, Canada, 24–27 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 291–295. [Google Scholar]
- Pereira, D.A.; Ourique de Morais, W.; Pignaton de Freitas, E. NoSQL real-time database performance comparison. Int. J. Parallel Emergent Distrib. Syst. 2018, 33, 144–156. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Alfian, G.; Syafrudin, M.; Ijaz, M.; Syaekhoni, M.; Fitriyani, N.; Rhee, J. A Personalized Healthcare Monitoring System for Diabetic Patients by Utilizing BLE-Based Sensors and Real-Time Data Processing. Sensors 2018, 18, 2183. [Google Scholar] [CrossRef]
- Huh, J.H. Big Data Analysis for Personalized Health Activities: Machine Learning Processing for Automatic Keyword Extraction Approach. Symmetry 2018, 10, 93. [Google Scholar] [CrossRef]
- Kögel, M.; Findeisen, R. A fast gradient method for embedded linear predictive control. IFAC Proc. Vol. 2011, 44, 1362–1367. [Google Scholar] [CrossRef]
- Menze, B.H.; Jakab, A.; Bauer, S.; Kalpathy-Cramer, J.; Farahani, K.; Kirby, J.; Burren, Y.; Porz, N.; Slotboom, J.; Wiest, R.; et al. The Multimodal Brain Tumor Image Segmentation Benchmark (BRATS). IEEE Trans. Med. Imaging 2014, 34, 1993–2024. [Google Scholar] [CrossRef]
- Bai, C.; Huang, L.; Pan, X.; Zheng, J.; Chen, S. Optimization of deep convolutional neural network for large scale image retrieval. Neurocomputing 2018, 303, 60–67. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sr. No. | Methodology | Results | Future Directions |
|---|---|---|---|
| 1 | Three layered feed forward ANNs and two real world problems are set as a benchmark to access the performance of Group Search Optimizer (GSO) [27]. | GSOANN has a far better performance as compared to regular ANN. | —– |
| 2 | A hybrid model of DSA and DL to help improve the relationship of computer science and bioinformatics [28]. | Differential Search Algorithm (DSA) and DL can help produce more xylitol for sugar free gums. | Computational biologists and computer scientist can together produce a hybrid model using deep learning OA. |
| 3 | In auto-encoders like VVG-9 and CIFAR-10, they design some experiments to study the properties of RMSProp and Adam against Nesterov’s Accelerated Gradient method [29]. | On very high values of 1 = 0.99 Adam outperforms lower training and test losses, whereas with 1 = 0.9, NAG performs better. | Advance theory in getting more better results by getting 1 close to 1. |
| 4 | Different optimization algorithms are studied by side CNN architecture [30]. | Among 7 optimizers, on the LeNet architecture, Adam provides the smallest MSE whereas SGD and Adagrad failed. | Can build analytical protable image devices |
| 5 | Constructed a few illustrative binary classification problems and examined empirical generalization capability of adptive methods agaisnt GD. | Solutions found by adaptive methods generalize worse than GSD. | Adaptive methods should be reconsidered. |
| 6 | Energy Index based Optimization Method (EIOM) that automatically adjusts the learning rate in backpropagation [31]. | EIOM proves to be the best when compared with state-of-the-art optimzation methods. | —– |
| 7 | A non-asymptotic analysis of the convergence of two algorithms: SGD and simple averaging [32]. | The analysis suggests that the learning rate is proportional to the inverse of the number of iterations. | Differential and non-differential stochastic |
| 8 | Adaptive learning rate and laplacian approach have been proposed for Deep Learning in MLP [33]. | Improved classification accuracy | —– |
| 9 | Proposed a fundamental approach for anatomical, celluler stuctures, and tissue segmentation using CNN through image patches measuring 13 × 13 voxels [34]. | On different data sets, comparing the six commonly used tools (i.e., ROBEX, HWA, BET, BEaST, BSE, and 3dSkullStrip), they achived the highest average specifity. | Can be performed on most advanced tools and used a real time data set to get better result. |
| 10 | Used a pretrained CNN model on augmented and orginal data for brain tumor classification [35] | They achieved 90.67 accuracy before and after data augmentation on the proposed methed and compared with most advanced methods | Used light weight CNN to entend their work for fine-grained classification differential stochastic. |
| 11 | A CapsNet for brain tumor classification and investigation of the overfitting problem based on CapNet [36]. | On 10 epochs, they achieved 86.56% accuracy, with the comparative analysis with CNN learning rate proportional to the inverse of the number of iterations. | In the future, investigations on the effects of more layers on the classification accuracy will be performed. |
| 12 | A review on deep learning techniques in the field of medical images classification [37] | They discussed in detail the deep learning approaches and their suitability for medical images. The learning rate is proportional to the inverse of the number of iterations. | Further research is required to apply the techniques to the modalities, where these are not applied. |
| 13 | GA-SVM and PSO-SVM method used to classify heart disease [38]. | GA and particle swarm optimization (PSO) algorithms combined with SVM achieved a high accuracy. | —– |
| 14 | Applied U-NET approach using BraTS2017 data set and prediction of patient survival [39] | 89.6% Accuracy achieved with less computational time | —– |
| 15 | Two-way path architecture based on CNN for brain tumor segmentation on the BraTS 2013 and 2015 data sets [3] | Input cascaded CNN got a high accuracy with 88.2% on the comparitive analysis with other architechtures. | Further improved the results with increasing architechture layers and data set. |
| Tumor Type | No. Patients | No. Patches Extracted | |
|---|---|---|---|
| Training | Testing | ||
| HGG | 220 | 360,000 | 90,000 |
| LGG | 54 | 268,000 | 67,000 |
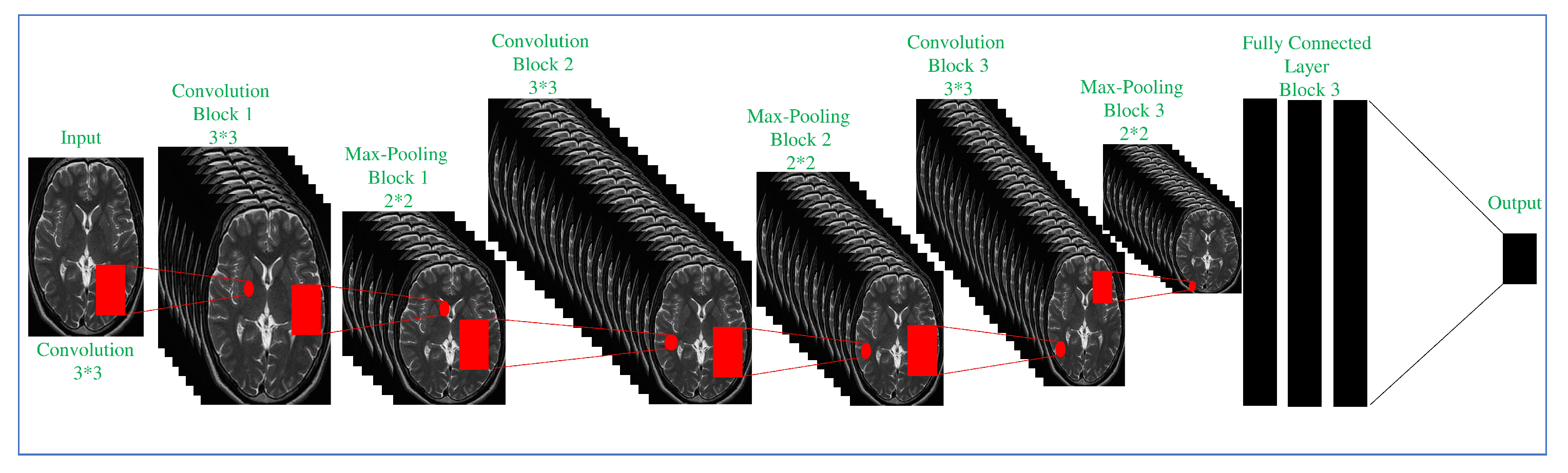
| Block | No.of Filter | Name (Size) | Stride | Kernel Size |
|---|---|---|---|---|
| Input | Input Image | - | ||
| Convolution block 1 | 64 | Con-1ayer 1 (4 × 33 × 33) | 1 × 1 | 3 × 3 |
| - | Relu-1ayer | - | ||
| 64 | Con-1ayer 2 (33 × 33 × 64) | 3 × 3 | ||
| - | Relu-1ayer | - | ||
| 64 | Con-1ayer 3 (33 × 33 × 64) | 3 × 3 | ||
| - | Relu-1ayer | - | ||
| Pooling block 1 | - | Max-Pooling layer 4 (33 × 33 × 64) | 2 × 2 | 3 × 3 |
| Convolution block 2 | 128 | Con-1ayer 5 (4 × 33 × 33) | 1 × 1 | 3 × 3 |
| - | Relu-1ayer | - | ||
| 128 | Con-1ayer 6 (33 × 33 × 64) | 3 × 3 | ||
| - | Relu-1ayer | - | ||
| 128 | Con-1ayer 7 (33 × 33 × 128) | 3 × 3 | ||
| Relu-1ayer | - | |||
| Pooling block 2 | - | MAX-Pooling layer8 (33 × 33 × 128) | 2 × 2 | 3 × 3 |
| Convolution block 3 | 128 | Con-1ayer 9 (33 × 33 × 128) | 1 × 1 | 3 × 3 |
| - | Relu-1ayer | - | ||
| 128 | Con-1ayer 10 (33 × 33 × 128) | 3 × 3 | ||
| - | Relu-1ayer | - | ||
| Pooling block 3 | - | MAX-Pooling layer 11 (33 × 33 × 128) | 2 × 2 | 3 × 3 |
| Fully Connected block | - | FC-1ayer 12 32768 | - | - |
| - | FC-1ayer 13 256 | - | ||
| - | FC-1ayer 14 256 | - | ||
| - | Softmax-1ayer | - |
| Stage | Hyperparameter | Value |
|---|---|---|
| Bias | 0.1 | |
| Weights | Xavier | |
| ReLU | 0.333 | |
| Dropout | HGG | 0.1 |
| LGG | 0.5 | |
| Training | Epochs-HGG | 50–300 |
| Epochs-LGG | 50–300 | |
| Intial | 0.03 | |
| Final | 0.0003 | |
| Batch Size | 128 | |
| Post processing | Tvol-HGG | 10,000 |
| Tvol-HGG | 3000 |
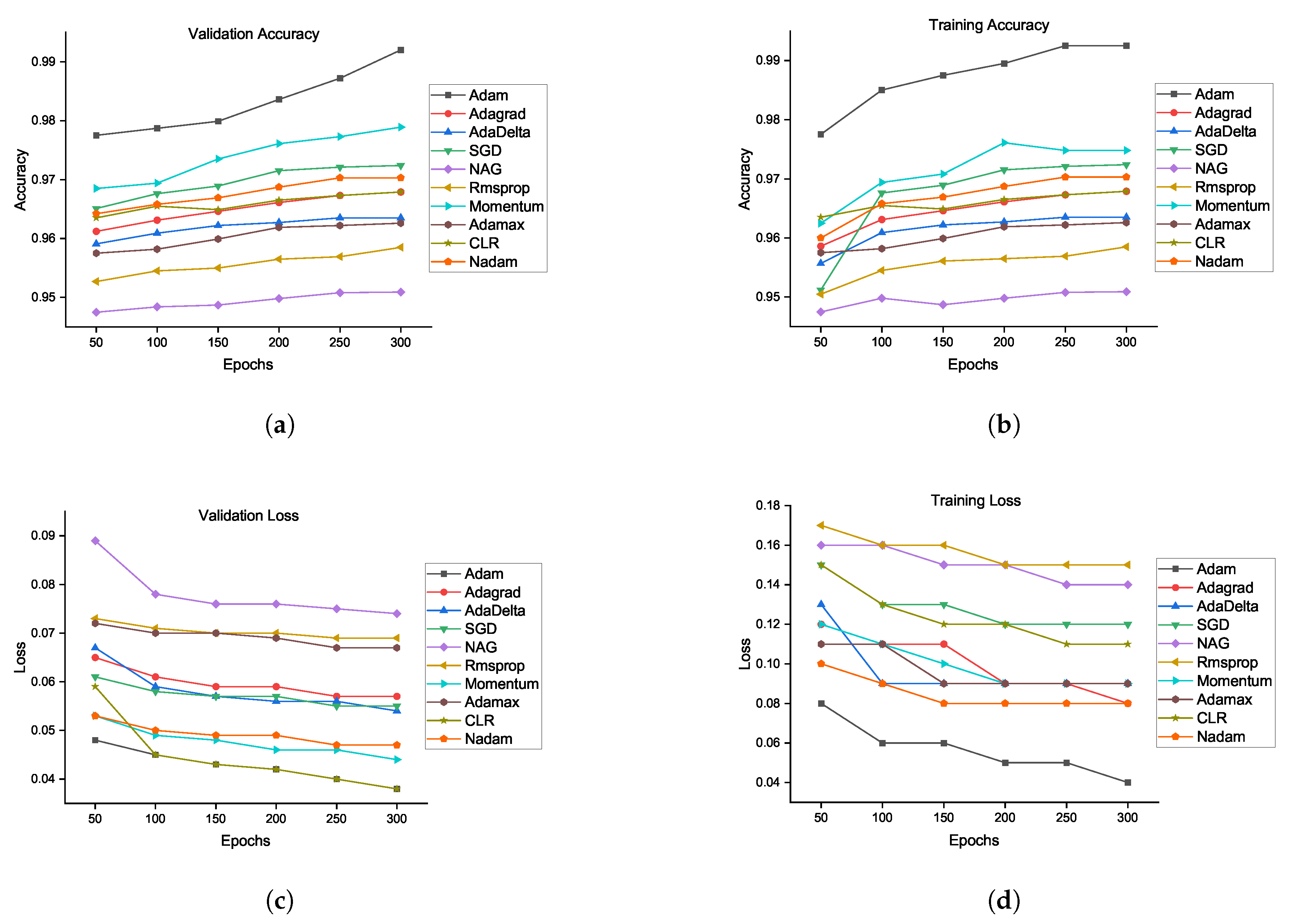
| Epoch → | 50 | 100 | 150 | 200 | 250 | 300 |
|---|---|---|---|---|---|---|
| Optimizers ↓ | ||||||
| Adam | 0.97 | 0.98 | 0.98 | 0.98 | 0.99 | 0.99 |
| Adagrad | 0.95 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 |
| AdaDelta | 0.95 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 |
| SGD | 0.95 | 0.967 | 0.968 | 0.97 | 0.97 | 0.97 |
| NAG | 0.94 | 0.94 | 0.94 | 0.94 | 0.95 | 0.95 |
| Rmsprop | 0.95 | 0.95 | 0.95 | 0.95 | 0.95 | 0.95 |
| Momentum | 0.96 | 0.96 | 0.97 | 0.97 | 0.974 | 0.97 |
| Adamax | 0.95 | 0.95 | 0.95 | 0.96 | 0.96 | 0.96 |
| CLR | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 |
| Nadam | 0.96 | 0.96 | 0.96 | 0.96 | 0.97 | 0.97 |
| Epoch → | 50 | 100 | 150 | 200 | 250 | 300 |
|---|---|---|---|---|---|---|
| Optimizers ↓ | ||||||
| Adam | 0.97 | 0.97 | 0.97 | 0.98 | 0.98 | 0.99 |
| Adagrad | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 |
| AdaDelta | 0.95 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 |
| SGD | 0.96 | 0.96 | 0.96 | 0.97 | 0.97 | 0.97 |
| NAG | 0.94 | 0.94 | 0.94 | 0.94 | 0.95 | 0.95 |
| Rmsprop | 0.95 | 0.95 | 0.95 | 0.95 | 0.95 | 0.95 |
| Momentum | 0.96 | 0.96 | 0.97 | 0.97 | 0.97 | 0.97 |
| Adamax | 0.95 | 0.95 | 0.95 | 0.96 | 0.96 | 0.96 |
| CLR | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 |
| Nadam | 0.96 | 0.96 | 0.96 | 0.96 | 0.97 | 0.97 |
| Epoch → | 50 | 100 | 150 | 300 | 250 | 300 |
|---|---|---|---|---|---|---|
| Optimizers ↓ | ||||||
| Adam | 0.05 | 0.05 | 0.04 | 0.04 | 0.04 | 0.04 |
| Adagrad | 0.07 | 0.06 | 0.06 | 0.06 | 0.06 | 0.06 |
| AdaDelta | 0.07 | 0.06 | 0.06 | 0.06 | 0.06 | 0.05 |
| SGD | 0.06 | 0.06 | 0.06 | 0.06 | 0.06 | 0.06 |
| NAG | 0.09 | 0.08 | 0.08 | 0.08 | 0.08 | 0.07 |
| Rmsprop | 0.07 | 0.07 | 0.07 | 0.07 | 0.07 | 0.07 |
| Momentum | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 | 0.04 |
| Adamax | 0.07 | 0.07 | 0.07 | 0.07 | 0.07 | 0.07 |
| CLR | 0.06 | 0.05 | 0.04 | 0.04 | 0.04 | 0.04 |
| Nadam | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 |
| Epoch → | 50 | 100 | 150 | 300 | 250 | 300 |
|---|---|---|---|---|---|---|
| Optimizers ↓ | ||||||
| Adam | 0.08 | 0.06 | 0.06 | 0.05 | 0.05 | 0.04 |
| Adagrad | 0.12 | 0.11 | 0.11 | 0.09 | 0.09 | 0.08 |
| AdaDelta | 0.13 | 0.09 | 0.09 | 0.09 | 0.09 | 0.09 |
| SGD | 0.15 | 0.13 | 0.13 | 0.12 | 0.12 | 0.12 |
| NAG | 0.16 | 0.16 | 0.15 | 0.15 | 0.14 | 0.14 |
| Rmsprop | 0.17 | 0.16 | 0.16 | 0.15 | 0.15 | 0.15 |
| Momentum | 0.12 | 0.11 | 0.10 | 0.09 | 0.09 | 0.09 |
| Adamax | 0.11 | 0.11 | 0.09 | 0.09 | 0.09 | 0.09 |
| CLR | 0.15 | 0.13 | 0.12 | 0.12 | 0.11 | 0.11 |
| Nadam | 0.10 | 0.09 | 0.08 | 0.08 | 0.08 | 0.08 |
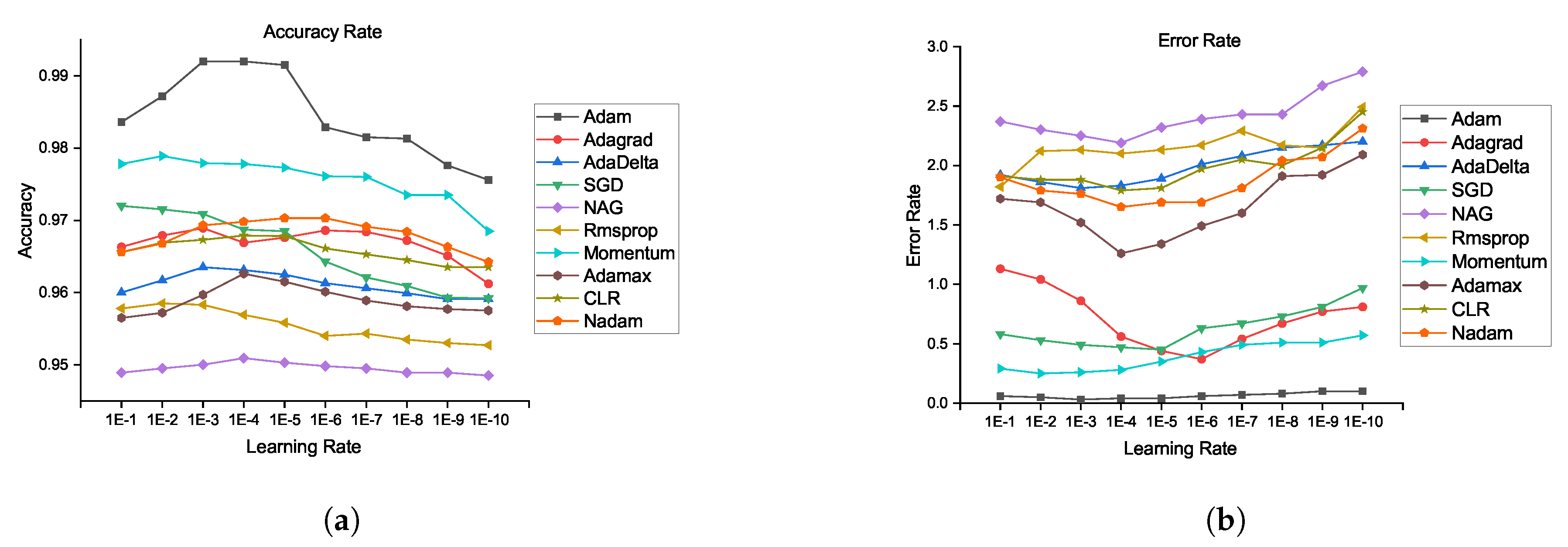
| Learning Rate → | 1e | 1e | 1e | 1e | 1e | 1e | 1e | 1e | 1e | 1e |
|---|---|---|---|---|---|---|---|---|---|---|
| Optimizers ↓ | ||||||||||
| Adam | 0.99 | 0.99 | 0.99 | 0.98 | 0.98 | 0.98 | 0.98 | 0.98 | 0.98 | 0.98 |
| Adagrad | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 | 0.96 | 0.97 | 0.97 | 0.96 |
| AdaDelta | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 |
| SGD | 0.97 | 0.97 | 0.97 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 |
| NAG | 0.95 | 0.95 | 0.95 | 0.95 | 0.95 | 0.95 | 0.95 | 0.95 | 0.95 | 0.95 |
| Rmsprop | 0.96 | 0.96 | 0.96 | 0.95 | 0.95 | 0.95 | 0.95 | 0.95 | 0.95 | 0.95 |
| Momentum | 0.98 | 0.98 | 0.98 | 0.98 | 0.98 | 0.97 | 0.97 | 0.98 | 0.97 | 0.97 |
| Adamax | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 |
| CLR | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 | 0.96 | 0.96 | 0.97 | 0.96 | 0.96 |
| Nadam | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 | 0.96 | 0.969 | 0.97 | 0.96 |
| Learning Rate → | 1e | 1e | 1e | 1e | 1e | 1e | 1e | 1e | 1e | 1e |
|---|---|---|---|---|---|---|---|---|---|---|
| Optimizers ↓ | ||||||||||
| Adam | 0.05 | 0.03 | 0.04 | 0.06 | 0.07 | 0.1 | 0.1 | 0.07 | 0.1 | 0.1 |
| Adagrad | 1.04 | 0.86 | 0.56 | 0.37 | 0.54 | 0.77 | 0.81 | 0.54 | 0.77 | 0.81 |
| AdaDelta | 1.86 | 1.81 | 1.83 | 2.01 | 2.08 | 2.17 | 2.2 | 2.08 | 2.17 | 2.2 |
| SGD | 0.53 | 0.49 | 0.47 | 0.63 | 0.67 | 0.81 | 0.97 | 0.67 | 0.81 | 0.97 |
| NAG | 2.3 | 2.25 | 2.19 | 2.39 | 2.43 | 2.67 | 2.79 | 2.43 | 2.67 | 2.79 |
| Rmsprop | 2.12 | 2.13 | 2.1 | 2.17 | 2.29 | 2.15 | 2.49 | 2.29 | 2.15 | 2.49 |
| Momentum | 0.25 | 0.26 | 0.28 | 0.43 | 0.49 | 0.51 | 0.57 | 0.49 | 0.51 | 0.57 |
| Adamax | 1.69 | 1.52 | 1.26 | 1.49 | 1.6 | 1.92 | 2.09 | 1.6 | 1.92 | 2.09 |
| CLR | 1.88 | 1.88 | 1.79 | 1.97 | 2.05 | 2.15 | 2.45 | 2.05 | 2.15 | 2.45 |
| Nadam | 1.79 | 1.76 | 1.65 | 1.69 | 1.81 | 2.07 | 2.31 | 1.81 | 2.07 | 2.31 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yaqub, M.; Feng, J.; Zia, M.S.; Arshid, K.; Jia, K.; Rehman, Z.U.; Mehmood, A. State-of-the-Art CNN Optimizer for Brain Tumor Segmentation in Magnetic Resonance Images. Brain Sci. 2020, 10, 427. https://doi.org/10.3390/brainsci10070427
Yaqub M, Feng J, Zia MS, Arshid K, Jia K, Rehman ZU, Mehmood A. State-of-the-Art CNN Optimizer for Brain Tumor Segmentation in Magnetic Resonance Images. Brain Sciences. 2020; 10(7):427. https://doi.org/10.3390/brainsci10070427
Chicago/Turabian StyleYaqub, Muhammad, Jinchao Feng, M. Sultan Zia, Kaleem Arshid, Kebin Jia, Zaka Ur Rehman, and Atif Mehmood. 2020. "State-of-the-Art CNN Optimizer for Brain Tumor Segmentation in Magnetic Resonance Images" Brain Sciences 10, no. 7: 427. https://doi.org/10.3390/brainsci10070427
APA StyleYaqub, M., Feng, J., Zia, M. S., Arshid, K., Jia, K., Rehman, Z. U., & Mehmood, A. (2020). State-of-the-Art CNN Optimizer for Brain Tumor Segmentation in Magnetic Resonance Images. Brain Sciences, 10(7), 427. https://doi.org/10.3390/brainsci10070427