Two-Level Attentions and Grouping Attention Convolutional Network for Fine-Grained Image Classification

Abstract
:1. Introduction
2. Related Work
2.1. Two-Level Attention Model
2.2. Grouping Attention Model
2.3. Multi-Level Feature Fusion
3. Approach
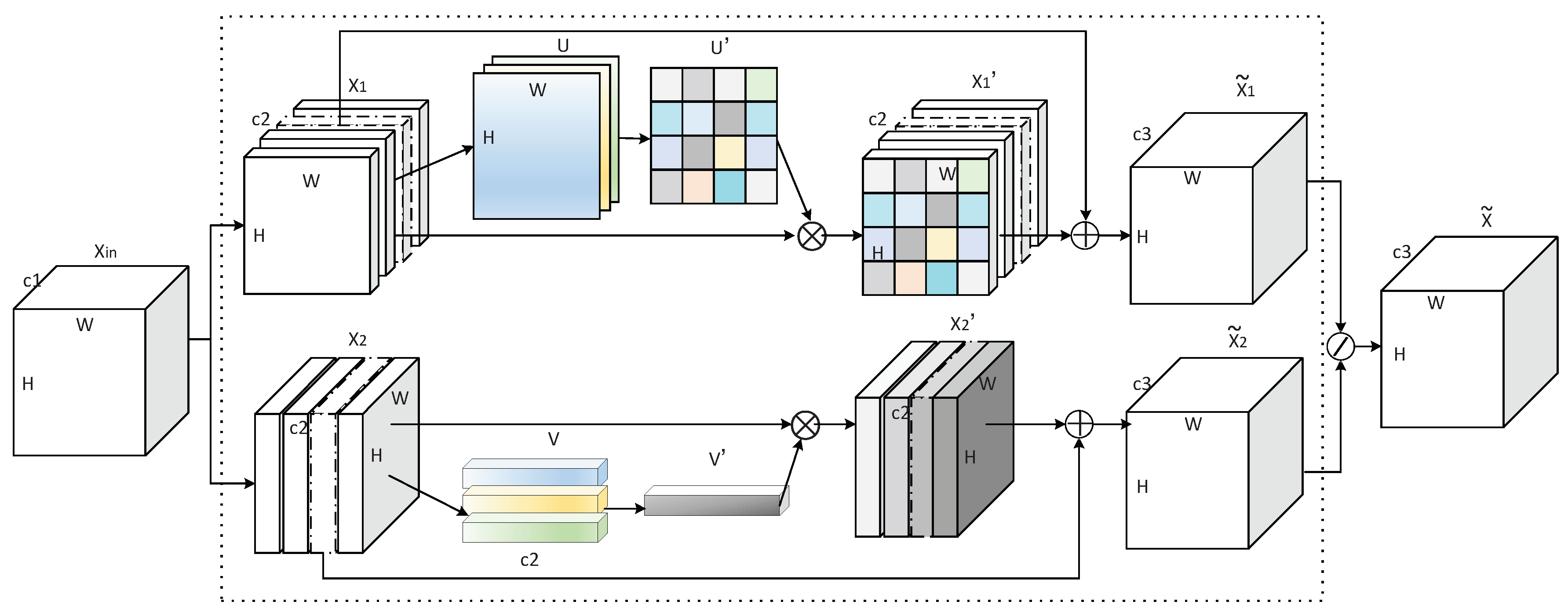
3.1. Two-Level Attention Model
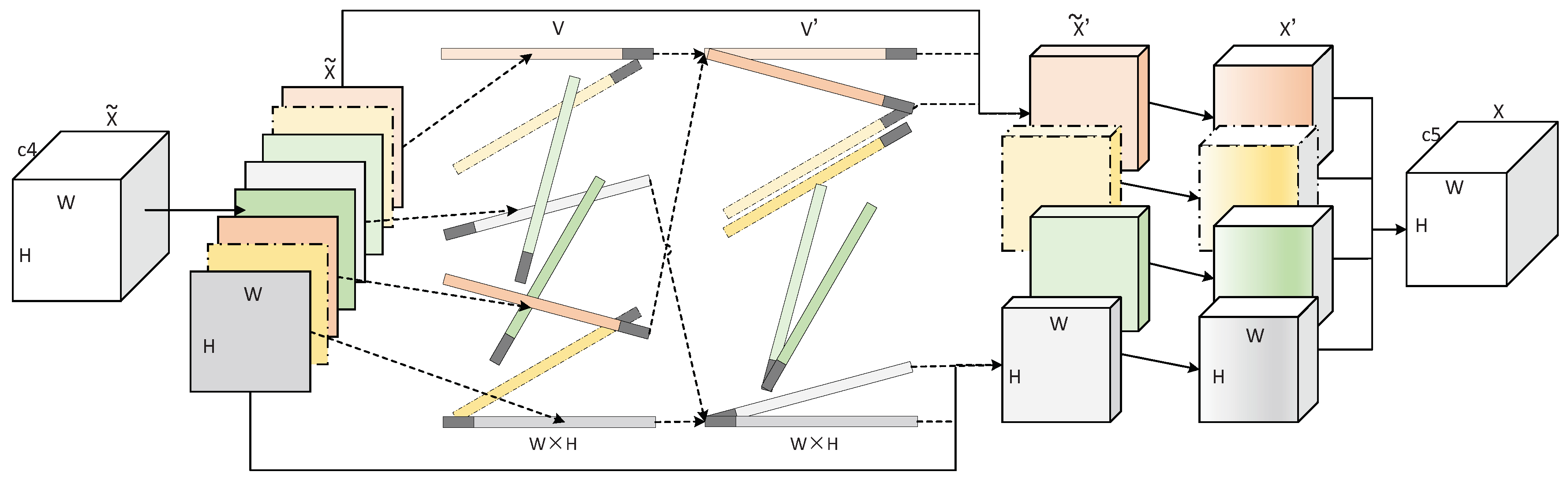
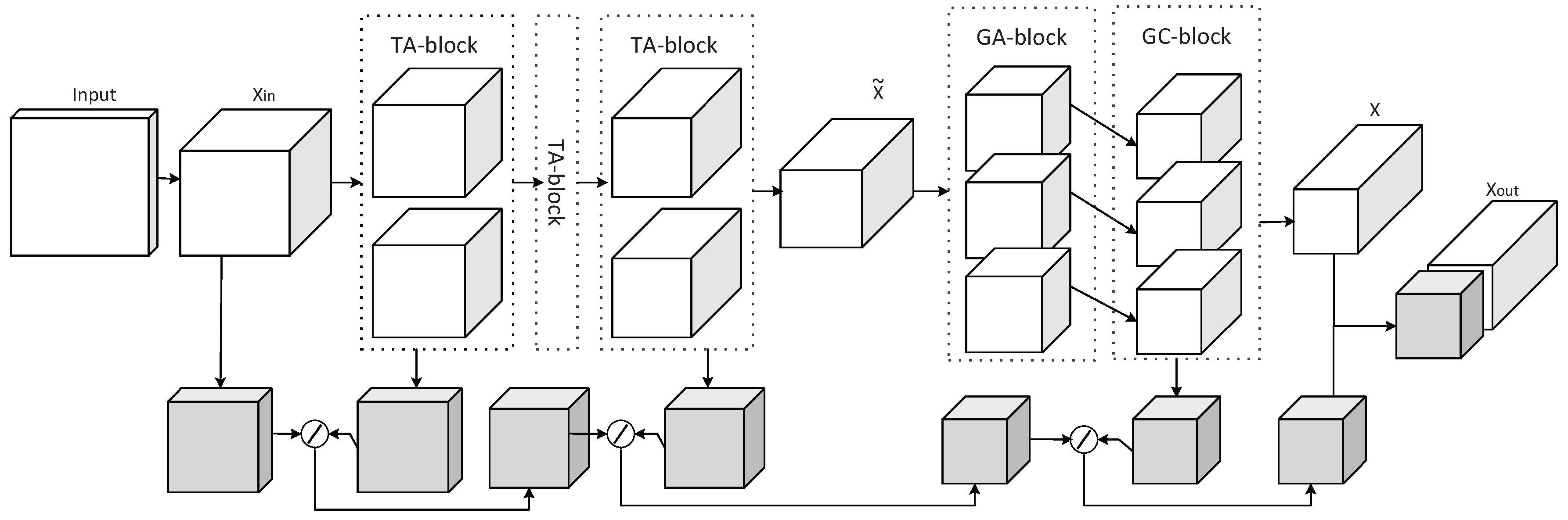
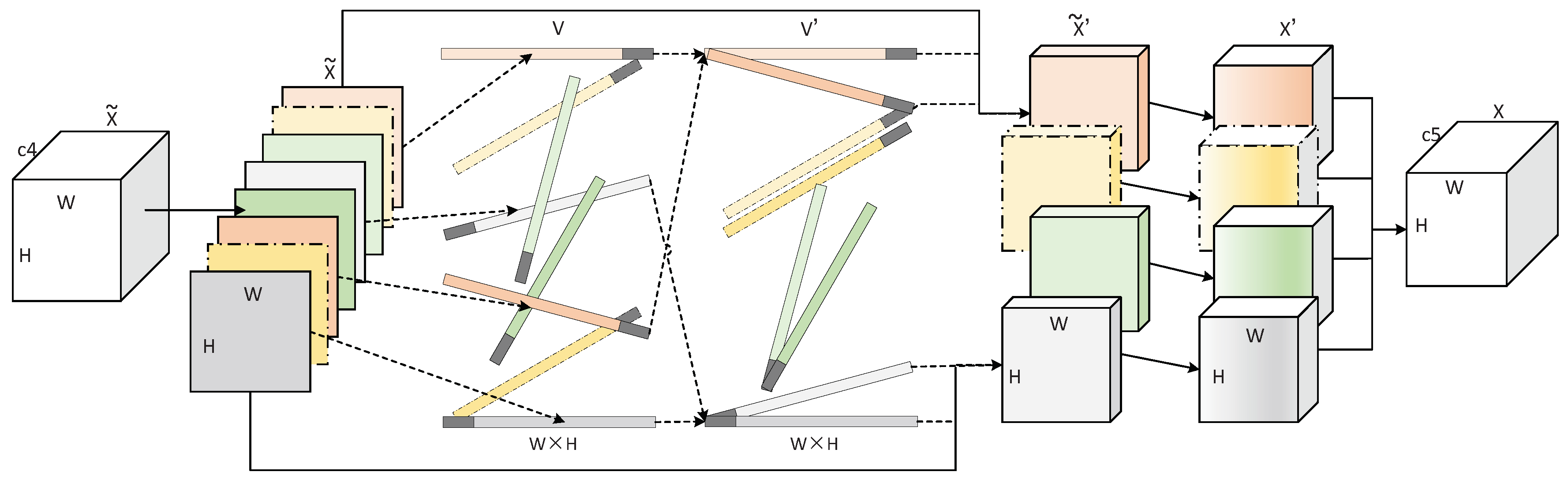
3.2. Grouping Attention Model
3.3. Multi-Level Feature Fusion
4. Experiments
4.1. Datasets and Experimental Details
4.2. Two-Level Attention Model
4.3. Grouping Attention Model
4.4. Multi-Level Feature Fusion
4.5. Comparisons With Prior Methods
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A
| Algorithm A1: Grouping attention method (GA-block) |
| define GA_block( x ): |
| x = permute_d( x, [0, 3, 1, 2] ) |
| x_flat = flatten( x[:, 0, :, :] ) |
| x_sub = x |
| for i in range( Num ): |
| if i != 1: |
| x_flat = x_last |
| x_sub = Sub( x_sub, x_topk ) |
| for j in range( x.shape[1] ): |
| x_arr = flatten( x_sub[:, j, :, :] ) |
| x_dot = dot( x_flat, x_arr ) |
| dict = push( x_dot ) |
| x_sort = sort( x_sub, dict ) |
| x_topk = top_k( x_sort, N ) |
| x_last = top_k( x_sort, -1 ) |
| x_conv = push( x_topk ) |
References
- Li, Y.; Zeng, J.B.; Shan, S.G.; Chen, X.L. Learning Latent Representations of 3D Human Pose with Deep Neural Networks. IEEE Trans. Image Process. 2018, 28, 2439–2450. [Google Scholar] [CrossRef]
- Lu, K.L.; Chu, T.H. An Image-Based Fall Detection System for the Elderly. Appl. Sci. 2018, 8, 1995. [Google Scholar] [CrossRef]
- Liu, J.; Lin, L.; Cai, Z.H.; Wang, J.; Kim, H.J. Deep web data extraction based on visual information processing. J. Ambient. Intell. Humaniz. Comput. 2017, 10, 1–11. [Google Scholar] [CrossRef]
- Katircioglu, I.; Tekin, B.; Salzmann, M.; Lepetit, V.; Fua, P. Occlusion Aware Facial Expression Recognition Using CNN With Attention Mechanism. Int. J. Comput. Vis. 2018, 126, 1326–1341. [Google Scholar] [CrossRef]
- Liu, J.; Gu, C.K.; Wang, J.; Kim, H.J. Multi-scale multi-class conditional generative adversarial network for handwritten character generation. J. Supercomput. 2017, 12, 1–19. [Google Scholar] [CrossRef]
- Berg, T.; Belhumeur, P.N. POOF: Part-Based One-vs.-One Features for Fine-Grained Categorization, Face Verification, and Attribute Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 955–962. [Google Scholar]
- Huang, S.L.; Xu, Z.; Tao, D.C.; Zhang, Y. Part-Stacked CNN for Fine-Grained Visual Categorization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1173–1182. [Google Scholar]
- Lin, D.; Shen, X.Y.; Lu, C.W.; Jia, J.Y. Deep LAC: Deep localization, alignment and classification for fine-grained recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 1666–1674. [Google Scholar]
- Zhang, N.; Donahue, J.; Girshick, R.; Darrell, T. Part-based R-CNNs for Fine-grained Category Detection. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 834–849. [Google Scholar]
- Zhao, B.; Wu, X.; Feng, J.S.; Peng, Q.; Yan, S.C. Diversified Visual Attention Networks for Fine-Grained Object Classification. IEEE Trans. Multimed. 2017, 19, 1245–1256. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuogu, K. Spatial transformer networks. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 7–12 December 2015; pp. 2017–2025. [Google Scholar]
- Wang, Y.M.; Morariu, V.I.; Davis, L.S. Learning a Discriminative Filter Bank within a CNN for Fine-grained Recognition. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 5209–5217. [Google Scholar]
- Wang, D.Q.; Shen, Z.Q.; Shao, J.; Zhang, W.; Xue, X.Y.; Zhang, Z. Multiple Granularity Descriptors for Fine-Grained Categorization. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 2399–2406. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. Imagenet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556v6. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Itti, L.; Koch, C. Computational modelling of visual attention. Nat. Rev. Neurosci. 2001, 2, 194–203. [Google Scholar] [CrossRef] [PubMed]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef]
- Meur, O.E.; Callet, P.L.; Barba, D.; Thoreau, D. A coherent computational approach to model bottom-up visual attention. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 802–817. [Google Scholar] [CrossRef] [PubMed]
- Baluch, F.; Itti, L. Mechanisms of top-down attention. Cell 2011, 34, 210–224. [Google Scholar] [CrossRef] [PubMed]
- Corbetta, M.; Shulman, G.L. Control of goal-directed and stimulus-driven attention in the brain. Nat. Rev. Neurosci. 2002, 3, 201–215. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.M.; Bargal, S.A.; Lin, Z.; Brandt, J.; Shen, X.H.; Sclaroff, S. Top-Down Neural Attention by Excitation Backprop. Int. J. Comput. Vis. 2018, 126, 1084–1102. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 7132–7141. [Google Scholar]
- Yang, Y.D.; Wang, X.F.; Zhang, H.Z. Local Importance Representation Convolutional Neural Network for Fine-Grained Image Classification. Symmetry 2018, 10, 479. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 3–19. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent Models of Visual Attention. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 8–11 December 2014; pp. 1–9. [Google Scholar]
- Bahdanau, D.; Cho, K.H.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473v2. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.Q.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 1–9. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. PRethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- Lin, T.Y.; RoyChowdhury, A.; Maji, S. Bilinear CNN Models for Fine-grained Visual Recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1449–1457. [Google Scholar]
- Gao, Y.; Beijbom, O.; Zhang, N.; Darrell, T. Compact Bilinear Pooling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 317–326. [Google Scholar]
- Kong, S.; Fowlkes, C. Low-Rank Bilinear Pooling for Fine-Grained Classification. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 365–374. [Google Scholar]
- Wang, Y.; Xie, L.X.; Liu, C.X.; Qiao, S.Y.; Zhang, Y.; Zhang, W.J.; Tian, Q.; Yuille, A. SORT: Second-Order Response Transform for Visual Recognition. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1359–1368. [Google Scholar]
- Zhang, T.; Qi, G.J.; Xiao, B.; Wang, J.D. Interleaved Group Convolutions for Deep Neural Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4373–4382. [Google Scholar]
- Chollet, F. Xception: Deep Learning With Depthwise Separable Convolutions. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Zhang, X.Y.; Zhou, X.Y.; Lin, M.X.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 6848–6856. [Google Scholar]
- Xiao, T.J.; Xu, Y.C.; Yang, K.Y.; Zhang, J.X.; Peng, Y.X.; Zhang, Z. The Application of Two-Level Attention Models in Deep Convolutional Neural Network for Fine-Grained Image Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 842–850. [Google Scholar]
- Zhang, X.P.; Xiong, H.K.; Zhou, W.G.; Lin, W.Y.; Tian, Q. Picking Deep Filter Responses for Fine-Grained Image Recognition. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1134–1142. [Google Scholar]
- Zheng, H.L.; Fu, J.L.; Mei, T.; Luo, J.B. Learning Multi-Attention Convolutional Neural Network for Fine-Grained Image Recognition. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5209–5217. [Google Scholar]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic Routing Between Capsules. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 3–9 December 2017; p. 370. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps. arXiv 2014, arXiv:1312.6034v2. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Mahendran, A.; Vedaldi, A. Understanding Deep Image Representations by Inverting Them. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 5188–5196. [Google Scholar]
- Hariharan, B.; Arbelaez, P.; Girshick, R.; Malik, J. Hypercolumns for Object Segmentation and Fine-Grained Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 447–456. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Zhang, P.P.; Wang, D.; Lu, H.C.; Wang, H.Y.; Ruan, X. Amulet: Aggregating Multi-Level Convolutional Features for Salient Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 202–211. [Google Scholar]
- Jin, X.J.; Chen, Y.P.; Jie, Z.Q.; Feng, J.S.; Yan, S.C. Multi-Path Feedback Recurrent Neural Networks for Scene Parsing. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4096–4102. [Google Scholar]
- Krause, J.; Stark, M.; Jia, D.; Li, F.F. 3D Object Representations for Fine-Grained Categorization. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 3–6 December 2013; pp. 554–561. [Google Scholar]
- Maji, S.; Rahtu, E.; Kannala, J.; Blaschko, M.; Vedaldi, A. Fine-grained visual classification of aircraft. arXiv 2013, arXiv:1306.5151. [Google Scholar]
- Gosselin, P.H.; Murray, N.; Jégou, H.; Perronnin, F. Revisiting the Fisher vector for fine-grained classification. Pattern Recognit. Lett. 2014, 49, 92–98. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Conv1 | Conv2 | Conv3 | Conv4 | Conv5 | Conv6 | Dence |
|---|---|---|---|---|---|---|---|
| Res-CNN | (16,7,3) (16,5,3) (16,3,3) | GAP (5,5) Dence (196/100) | |||||
| TA-CNN | TA-block | TA-block | TA-block | TA-block | TA-block | TA-block | |
| GA-CNN | GA-block | GC-block | |||||
| TGA-CNN | TA-block | TA-block | TA-block | TA-block | TA-block | GA-model | |
| MFF | [16,2,2] | [128,1,1] |
| Model | Accuracy(%) | Parameters | FPS | |
|---|---|---|---|---|
| Cars | Aircrafts | |||
| B-CNN | 83.90 | 78.40 | – | 8 |
| Res-CNN | 84.29 | 82.15 | 14.09M | 40 |
| OARes-CNN | 84.87 | 82.65 | 15.78M | 38 |
| PARes-CNN | 84.80 | 82.62 | 14.10M | 38 |
| TA-CNN_ADD | 85.10 | 82.94 | 15.78M | 36 |
| TA-CNN_SORT | 85.22 | 83.01 | 15.78M | 36 |
| Model | Accuracy(%) | Parameters | FPS | |
|---|---|---|---|---|
| Cars | Aircrafts | |||
| Res-CNN | 84.29 | 82.15 | 14.09M | 40 |
| Res-CNN_G4 | 88.30 | 86.11 | 13.40M | 30 |
| Res-CNN_G8 | 89.51 | 87.06 | 12.89M | 24 |
| Res-CNN_G12 | 88.15 | 86.22 | 12.71M | 21 |
| Res-CNN_GX | 85.94 | 83.64 | 12.53M | 38 |
| Model | Accuracy(%) | Parameters | FPS | |
|---|---|---|---|---|
| Cars | Aircrafts | |||
| TA-CNN | 85.22 | 83.01 | 15.78M | 36 |
| TA-CNN_G4 | 89.13 | 86.55 | 15.07M | 27 |
| TA-CNN_G8 | 90.32 | 87.47 | 14.55M | 23 |
| TA-CNN_G12 | 89.04 | 86.82 | 14.38M | 20 |
| TA-CNN_GX | 86.81 | 84.69 | 14.20M | 36 |
| Model | Accuracy(%) | Parameters | FPS | |
|---|---|---|---|---|
| Cars | Aircrafts | |||
| Res-CNN | 84.29 | 82.15 | 14.09M | 40 |
| Res-CNN_MFF | 84.95 | 82.63 | 14.77M | 36 |
| TA-CNN | 85.22 | 83.01 | 15.78M | 36 |
| TA-CNN_MFF | 85.64 | 83.26 | 16.44M | 34 |
| GA-CNN | 89.51 | 87.06 | 12.89M | 24 |
| GA-CNN_MFF | 90.41 | 87.49 | 13.01M | 24 |
| TGA-CNN | 90.32 | 87.47 | 14.55M | 23 |
| TGA-CNN_MFF | 91.05 | 87.93 | 14.67M | 23 |
| Model | Accuracy (%) | |
|---|---|---|
| Cars | Aircrafts | |
| FV-CNN | 87.79 | 81.46 |
| DVAN | 87.10 | – |
| Random Maclaurin | 89.54 | 87.10 |
| Tensor Sketch | 90.19 | 87.18 |
| LRBP | 90.92 | 87.31 |
| MA-CNN | 92.80 | 89.90 |
| TGA-CNN(Ours) | 91.05 | 87.93 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Wang, X.; Zhao, Q.; Sui, T. Two-Level Attentions and Grouping Attention Convolutional Network for Fine-Grained Image Classification. Appl. Sci. 2019, 9, 1939. https://doi.org/10.3390/app9091939
Yang Y, Wang X, Zhao Q, Sui T. Two-Level Attentions and Grouping Attention Convolutional Network for Fine-Grained Image Classification. Applied Sciences. 2019; 9(9):1939. https://doi.org/10.3390/app9091939
Chicago/Turabian StyleYang, Yadong, Xiaofeng Wang, Quan Zhao, and Tingting Sui. 2019. "Two-Level Attentions and Grouping Attention Convolutional Network for Fine-Grained Image Classification" Applied Sciences 9, no. 9: 1939. https://doi.org/10.3390/app9091939