Parallel Image Captioning Using 2D Masked Convolution


Abstract
:Featured Application
Abstract
1. Introduction
2. Related Work
2.1. Image Captioning
2.2. Sequence-to-Sequence Model
3. Materials and Methods
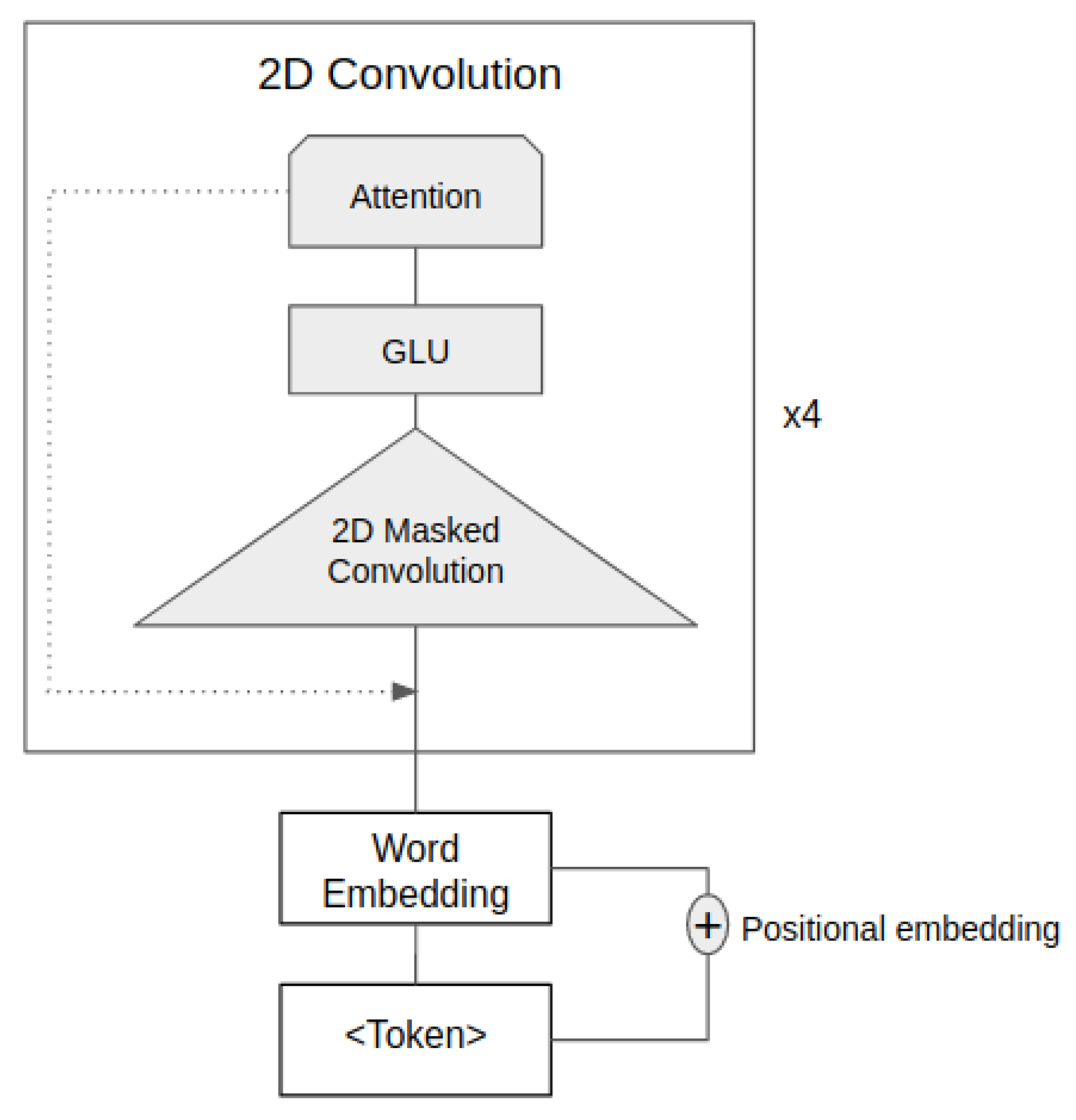
3.1. Image Encoder
3.2. Decoder
3.2.1. Word Embedding
3.2.2. Positional Encoding
3.2.3. 2D Masked Convolutional Layer
3.2.4. Multi-Step Attention
3.2.5. Prediction Layer
4. Experiment
4.1. Dataset
4.2. Training and Evaluation
4.3. Inference
5. Result and Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hossain, M.; Sohel, F.; Shiratuddin, M.F.; Laga, H. A comprehensive survey of deep learning for image captioning. ACM Comput. Surv. (CSUR) 2019, 51, 118. [Google Scholar] [CrossRef]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training recurrent neural networks. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1310–1318. [Google Scholar]
- Lu, Y.; Salem, F.M. Simplified gating in long short-term memory (lstm) recurrent neural networks. In Proceedings of the 2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS), Boston, MA, USA, 6–9 August 2017; pp. 1601–1604. [Google Scholar]
- Elbayad, M.; Besacier, L.; Verbeek, J. Pervasive Attention:{2D} Convolutional Neural Networks for Sequence-to-Sequence Prediction. In Proceedings of the 22nd Conference on Computational Natural Language Learning, Brussels, Belgium, 31 October–1 November 2018; pp. 97–107. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional sequence to sequence learning. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, Sydney, Australia, 6–11 August 2017; pp. 1243–1252. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6077–6086. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Rennie, S.J.; Marcheret, E.; Mroueh, Y.; Ross, J.; Goel, V. Self-critical sequence training for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7008–7024. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Aneja, J.; Deshpande, A.; Schwing, A.G. Convolutional image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5561–5570. [Google Scholar]
- Zhu, X.; Li, L.; Liu, J.; Peng, H.; Niu, X. Captioning transformer with stacked attention modules. Appl. Sci. 2018, 8, 739. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- van den Oord, A.; Kalchbrenner, N.; Kavukcuoglu, K. Pixel recurrent neural networks. arXiv 2016, arXiv:1601.06759. [Google Scholar]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language modeling with gated convolutional networks. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, Sydney, Australia, 6–11 August 2017; pp. 933–941. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Karpathy, A.; Fei-Fei, L. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3128–3137. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: Lessons learned from the 2015 mscoco image captioning challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 652–663. [Google Scholar] [CrossRef] [PubMed]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; pp. 65–72. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]
- Williams, R.J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef] [Green Version]
- Shi, S.; Wang, Q.; Xu, P.; Chu, X. Benchmarking state-of-the-art deep learning software tools. In Proceedings of the 2016 7th International Conference on Cloud Computing and Big Data (CCBD), Macau, China, 16–18 November 2016; pp. 99–104. [Google Scholar]
- Kim, H.; Nam, H.; Jung, W.; Lee, J. Performance analysis of CNN frameworks for GPUs. In Proceedings of the 2017 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Santa Rosa, CA, USA, 24–25 April 2017; pp. 55–64. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | CIDEr |
|---|---|---|---|---|---|---|
| NIC [12] | 66.6 | 46.1 | 32.9 | 24.6 | 23.7 | 85.5 |
| Attention (Soft) [13] | 70.7 | 49.2 | 34.4 | 24.3 | 23.90 | - |
| Attention (Hard) [13] | 71.8 | 50.4 | 35.7 | 25.0 | 23.04 | - |
| SCST [14] | - | - | - | 33.3 | 26.3 | 111.4 |
| Up-Down Attention [8] | 79.8 | - | - | 36.3 | 27.7 | 120.1 |
| ConvCap [16] | 71.1 | 53.8 | 39.4 | 28.7 | 24.4 | 91.2 |
| Caption Transformer [17] | 73.0 | 56.9 | 43.6 | 33.3 | - | 108.1 |
| Baseline | 70.6 | 53.2 | 38.9 | 28.3 | 24.3 | 90.9 |
| Baseline + Positional Embedding | 71.3 | 54.1 | 40.3 | 30.1 | 24.8 | 94.3 |
| Baseline + PE + Residual Connection | 73.0 | 54.6 | 42.2 | 31.6 | 25.2 | 94.4 |
| Baseline + PE + RC + Attention | 73.1 | 55.1 | 42.4 | 32.5 | 25.7 | 96.2 |
| Baseline + PE + RC + A + BeamSearch (size = 3) | 73.6 | 56.6 | 44.1 | 33.2 | 25.9 | 99.4 |
| Model | #param | Single-GPU | Multi-GPU |
|---|---|---|---|
| NIC [12] | 14.6 M | 25 ± 5 min | - |
| Attention [13] | 20.2 M | 50 ± 3 min | - |
| Up-Down [8] | 21.5 M | 46 ± 4 min | 37 ± 4 min |
| Ours | 19 M | 40 ± 5 min | 28 ± 6 min |
| #param | BLEU-1 | METEOR | CIDEr |
|---|---|---|---|
| GPU × 1 | 73.3 | 26.2 | 100.8 |
| GPU × 2 | 73.6 | 25.9 | 99.4 |
| GPU × 3 | 71.7 | 23.9 | 95.5 |
| GPU × 4 | 72.1 | 24.0 | 97.4 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Poleak, C.; Kwon, J. Parallel Image Captioning Using 2D Masked Convolution. Appl. Sci. 2019, 9, 1871. https://doi.org/10.3390/app9091871
Poleak C, Kwon J. Parallel Image Captioning Using 2D Masked Convolution. Applied Sciences. 2019; 9(9):1871. https://doi.org/10.3390/app9091871
Chicago/Turabian StylePoleak, Chanrith, and Jangwoo Kwon. 2019. "Parallel Image Captioning Using 2D Masked Convolution" Applied Sciences 9, no. 9: 1871. https://doi.org/10.3390/app9091871
APA StylePoleak, C., & Kwon, J. (2019). Parallel Image Captioning Using 2D Masked Convolution. Applied Sciences, 9(9), 1871. https://doi.org/10.3390/app9091871