1. Introduction
Solar PV, hydraulic and wind energy sources are supporting continuity of energy supply, which is a key strategic issue for many countries to guarantee their industry growth. They contribute to the use of inexhaustible energy sources, to the implementation of energy multi-sourcing strategies, to a more environmental friendly production of energy, and/or to the preservation of power generation, and distribution means integrity, ensuring dependability of the entire system [
1,
2,
3]. However, the integration of these renewable energy plants into the conventional electrical grid has many challenges. Some of these challenges are related to reliability of the generation systems being used, but others have to do with the fact that these sources of energy are intermittent in nature, and they depend on the climatic conditions, affecting the stability of the network. Matching the supply and the load becomes troublesome and is a clear disturbance of the network. The stability of the network is based on maintaining grid frequency. A load greater than supply makes the frequency fall and a load lesser than supply makes the frequency increase. In this context, relevant research activities are taking place to develop more accurate models for renewable energy supply prediction [
4].
In spite of the existence of well-developed underlying physical models for each component of all kinds of renewal energy generation systems, complexity arising from the combination of these elements makes impractical the direct characterization of the system through closed mathematical expressions, so stochastic models are selected in practice to characterize the behavior of this sort of system.
To gain prediction accuracy, intelligence and flexibility need to be incorporated into prediction models, and that is why the application of Artificial Intelligence (AI)—Machine Learning (ML) techniques is increasing in this field. AI-ML techniques consist of fitting the parameters of a model from observed data (experience) and are best suitable to discover behavioral patterns from data series in the presence of randomness. This property of machine learning algorithms is invaluable in anomaly detection problems [
5].
Within AI-ML techniques, Artificial Neural Network (ANN) models have delivered good results for real-time estimations, and especially when learning from dynamic changes in environmental conditions becomes a key factor to improve prediction accuracy [
6].
This paper reviews the different uses of ANN models for better renewable energy prediction. The idea is, at the same time, to identify those contributions with special emphasis on understanding assets’ reliability issues. The rationale for this is that ANN tools may also become an excellent tool for asset performance monitoring, also a complex problem in these environments where:
The assets can perform in very diverse operating conditions (due to diverse environmental conditions);
Asset conditions are many times not feasible to be monitored, or simply doing it becomes a complex technical problem with a very troublesome and economically non-viable solution (difficulty is many times related to specific functional locations);
Altogether, this could result in a serious lack of asset performance control and subsequent loss of expected performance efficiency.
Therefore, the paper explores the efforts made for ANN models to become a practical asset performance monitoring tool, for any potential asset location, environment (the reader may also notice that this review also remarks on contributions incorporating meteorological forecasting) and operating conditions, offering the possibility to control asset performance and reliability, ensuring life cycle expectations according to existing business plans.
In the review accomplished in this paper, it has also been recorded those occasions in which research was conducted for technique comparison purposes (considering other prediction techniques) or with the intention to identify possibilities of different prediction techniques complementarity. Finally, special attention is also paid to those parameters that were considered for prediction in the different ANN models reviewed. This can also provide relevant information to many researchers and practitioners in the field.
The paper is organized as follows:
Section 2 provides a background of the ANN models, where we do not extend their mathematical formulation but we concentrate on their fundamental capabilities.
Section 3 reviews the literature containing ANN prediction models for renewal energy. In this section, we first classify the models by their specific use and then we concentrate on their features by energy source studied.
Section 4 organizes and compares results obtained for the different energy source prediction models, while in
Section 5 we concentrate on results for one of the main concerns of this paper, the models that we name ARAM (Asset reliability assessments models). Finally, we present conclusions and the list of references in the last two sections.
2. Artificial Neural Network Models Background, and Fundamental Capabilities
Seminal works in this ANN area were developed by Warren MacCulloch and Walter Pitss (1943) [
7]; since then, the interest in ANN properties increased intensively, and after the publication of the John Hopfield’s book (1985) [
8] and the development of backpropagation ANN models by David Rumelhart and G. Hinton in 1986 [
9], the interest was more focused on particular applications in industry (see
Table 1).
Following those initial works related to ANN models, different contributions were published for different purposes. The following references can be considered a good sample of works that can be found in the literature up to 1990, cataloged in
Table 1, according to the reason for their utilization: association, classification, conceptualization, prediction, optimization, and filtering.
Association: Technique to reduce data dimensionality.
Classification: Technique for grouping data into classes.
Conceptualization: Technique for conceptualizing ideas based on concrete data.
Prediction: Technique to find values that are going to happen.
Optimization: Technique to seek convergence to a minimum.
Filtering: Technique for sifting data according to restrictions.
ANN models allow us to obtain updated assets’ condition analysis, and according to the status of the environment variables, they are able to predict production, adding capabilities to foresee existing and potential problems (fault, failure, production losses, etc.) based on collected information from sensors in each particular asset (with an approach very similar to current studies on the Internet of Things—IoT) [
30,
31,
32]. ANN models are mathematical tools emulating human reasoning, learning from past experiences and coping with rather complex non-linear behaviors [
33]. These models are especially well suited to replicate certain behavioral patterns where relationship among input and output variables cannot be explained by other mathematical techniques [
34,
35].
Therefore, we can conclude that ANN models have as their main advantages the capacity to find complex relations among variables, with a high tolerance to data uncertainty (thanks to redundancy in data storage), and providing predicted variable patterns in-real time [
35,
36,
37]. Also, we can say that ANN models have as their main disadvantages the need for abundant information, with enough data quality, which is not always accessible or available at a reasonable cost [
38].
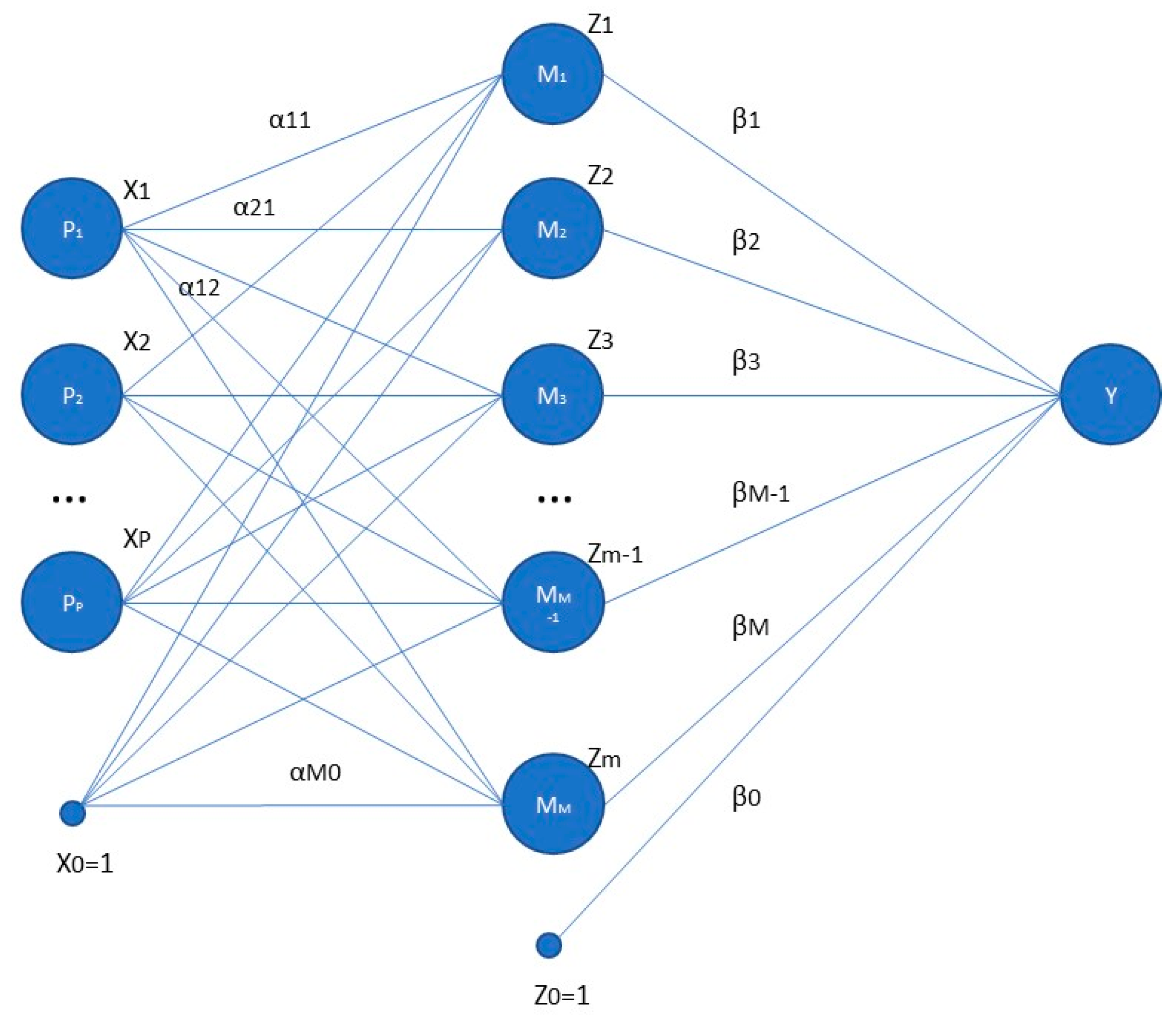
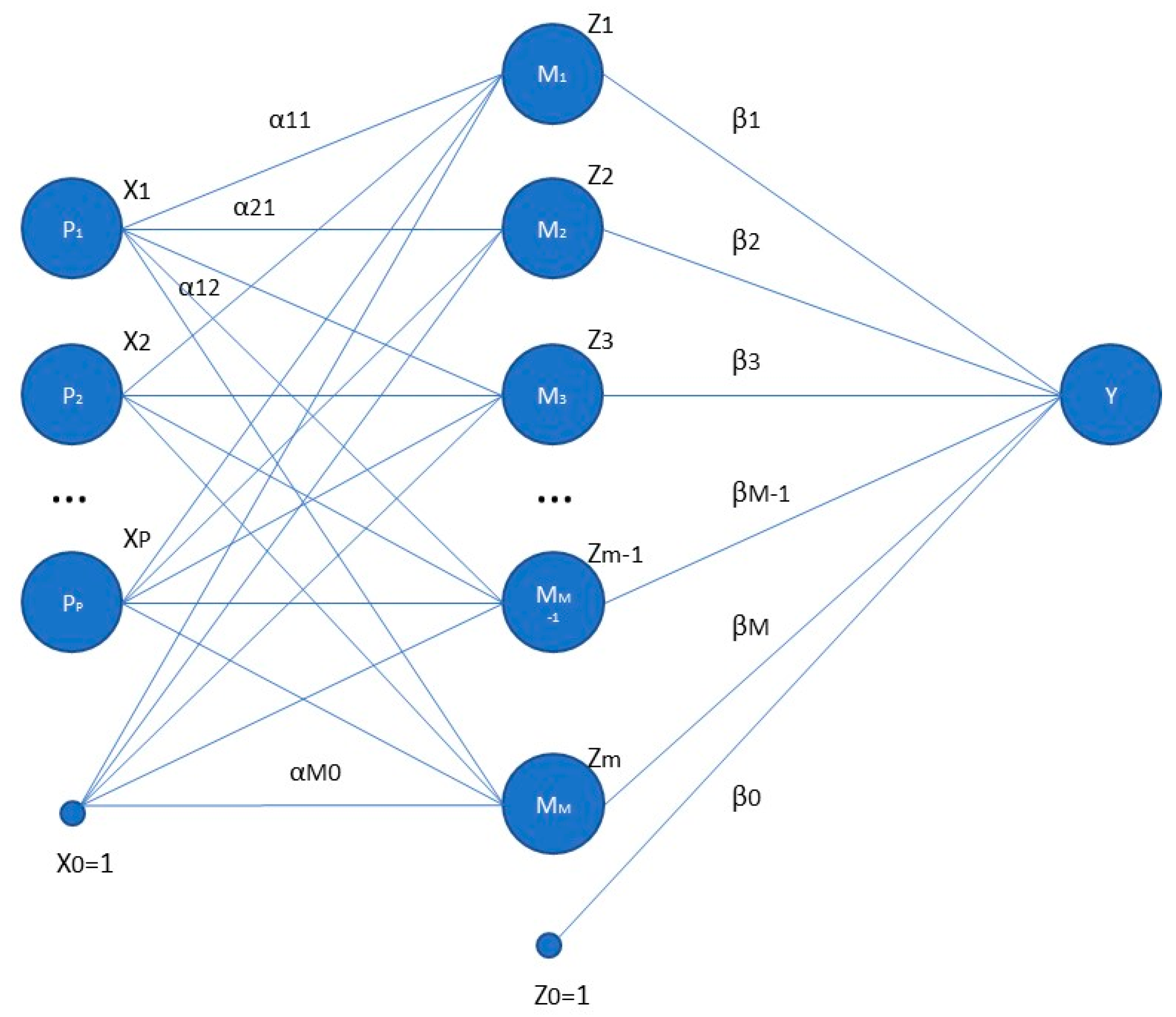
ANNs are built with the mission of processing the information of inputs and transferring that information through different connections where it is activated by a transference function, which is tuned up using a training process that can be developed when reasonable real data are provided [
39]. In this process, ANNs are usually trained with 75% of available data (training set) and with the remaining data, 25%, the network is validated (test set) [
39,
40]. There are different proposed architectures in the literature for ANNs (feed-forward, sequential, convolutional, …), but in its simplest form, a feed-forward neural network, also known as a perceptron, consists of several interconnected layers of processing units called neurons [
34,
41] as shown in
Figure 1. The first layer, called the input layer, is composed of P neurons, arranged as a P-dimensional vector; the intermediate layer, called the hidden layer, is composed of M neurons, arranged as a M-dimensional vector; and the output layer has one neuron, Y.
The output of a neuron (
i) of the input layer is equal to
, whereas the components of the output of the hidden layer,
(Equation (1)) are equal to a function called the activation function, resembling the mechanism of a physiological neuron, of the linear combination of the input neurons
, adjusted by a threshold
. Most usual activation functions are the sigmoid and the hyperbolic tangent.
The output of the neural network, Y in Equation (2), is a function (usually the identity in most common regression problems) of the linear combination of the output of the hidden layer neurons, adjusted by another threshold
, and considering
.
All the aforementioned parameters of the model (weights of linear combinations and thresholds) are calculated through the application of a learning algorithm using observed data (experience). The objective of the learning process is to find the parameter set that minimizes the so-called loss function over the training data set, whereas the validation set is used to find the hyperparameters of the learning algorithm by minimizing the loss function over the validation data set. On the other hand, the test data set is employed to evaluate the accuracy of the model. Furthermore, it is common to apply a k-fold cross-validation process to iteratively apply the algorithm to k different partition sets.
Back-propagation with gradient descent is the most usual algorithm used to train the neural network when the activation functions are differentiable. Lapedes and Farber (1987) [
42] have demonstrated that a type of ANN model, the Backpropagation Neural Network, exceeds in an order of magnitude the results of conventional linear and polynomial methods. The Backpropagation Network is a very popular learning mechanism for prediction problems solving in multiple-layer perceptron networks [
9,
43]. The selected loss function is usually the sum of squared errors, R, over the elements of the training set,
.
The backpropagation algorithm consists of a loop with a maximum of S steps where forward and backwards actions are taken, and in each iteration, forward actions process the output from the training data set, and backwards actions update the weights and . Forward and backward steps are run, starting near a linear learning process with mean 0 and variance 1 in input variables and randomly selected values close to 0 in weight until the sum of squared errors (selected loss function) is optimized with two consecutive iterations differing by less than a predefined threshold or the maximum number of iterations is reached.
Because of non-linearity of expression in Equation (2), a heuristic that guarantees a global minimum is required (for example, R software employees a quasi-Newton approach and Matlab implements the Levenberg-Marquardt method). Nevertheless, obtaining a global minimum can lead to overfitting and lack of generalization, so a regularized loss function (see Equation (3)) is used in practice.
It is important to highlight that in the cross-validation process followed to determine the optimal network architecture, the following assumptions are recommended:
Hidden network neuron number. hyperparameter in (Equation (3)) controls the strength of the weights, so that it is possible to train the neural network with a high number of neurons and discard those with less significant weights.
Initial weights are randomly selected and the algorithm is executed several times for each data set.
Activation function selection. Sigmoid functions are preferably selected for the hidden layer neurons, and identity for the output layer.
3. Review of ANN Models for Prediction in the Renewal Energy Sector
3.1. Scope of the Review and Prediction Model Classification according to Model Use
According to the above-mentioned advantages of using ANNs for prediction, several authors have implemented them in the different types of renewal energy sources. A significant number of contributions have been made for three renewal energy sources: photovoltaic, wind and hydraulic energies, even though there are some references on other sources of energy, in a minor volume [
44,
45,
46,
47].
When we explored all these renewable energy prediction models based on ANN, our intention was to focus on those incorporating intelligence to anticipate reliability problems, those adding new capabilities to improve asset maintenance policies.
The rationale for this is the importance that maintenance and reliability have in this sector, to increase the efficiency of the energy generation process. Failures are many times hidden and they end up having a high impact on business plans due to derived energy production losses. In this sector the risk of failures could even reach ten times the purchase equipment cost [
48].
Difficulties in the detection of failures can be overcome with ANN models, which are more suitable to deal with changing environmental conditions for each specific asset geographical location, by using permanently updated intelligent algorithms [
49]. Our idea is to identify how different authors have approached this problem (one layer, multilayer, convolutional, sequential, deep learning, etc.) to serve as an important guide for all companies with renewable energy facilities that want to use these techniques to predict failures and to improve energy supply continuity (implementation techniques, main input variables, indicative results, etc.).
In this research we have concentrated our literature review on specific databases (Sciencedirect, Elsevier, Scopus, IEEE Xplore) and several keywords (renewable energy, photovoltaics energy, hydraulic energy, wind energy, wind power, neural network, prediction model, energy forecasting, failure detection, intelligence artificially, machine learning, deep learning), and as a result we have found different utilizations of ANN models for prediction, that we will classify as follows:
Concretely, ARAMs have to follow international standards so any future change, modification, improvement, management of the solution will be very much facilitated and understood. For a wide comprehension of the ARAM, potential is needed to analyze its implementation cases for three components [
55]: monitoring, diagnosis and prognosis. Guillen et al. [
56] describe these components in terms of failure mode control:
Detection/monitoring is associated with the system states (for example, the transition from function state to fault state) and, in general, with normal behavior-anomalies distinction (in reference to defined baseline data);
Diagnosis is associated with the location of the failure mode and its causes;
Prognosis is associated with the evolution of the failure mode or its future behavior (risk of failure and remaining useful life at the current time).
Detection is focused more on the functional failure (the way in which a system is unable to fulfil a function at the performance standard that is acceptable for the user) and, diagnosis and prognosis are focused on failure mode (the effect by which a functional failure is observed [ISO 13372:2012, Condition monitoring and diagnostics of machines—Vocabulary]).
Therefore, ARAMs have to link detection, diagnosis and prognosis, with the failure mode determination, identifying parameters required to predict it (consequences of the monitoring outputs can be registered, listed and catalogued to be used). The main effort consists of identifying the monitoring variables required to predict failure modes (when that is feasible). Failure detective/predictive intelligence in ARAM processing could be implemented in a formal way combining not only failure mode degradation solutions but also energy generation predictions depending on the different operating and environmental conditions.
As the reader may guess, efforts in ARAMs come normally together with investments in a suitable combination of condition monitoring, inspection, and/or testing and analysis technologies, besides new tools to release the subsequent maintenance actions, improving prediction processes efficiency [
57].
In this scenario, international standards become a key aspect to ensure the data combination, in a structured and sustainable way, of the three main sources of information: maintenance management systems, reliability analysis systems and condition monitoring systems.
Hereafter, the reviewed contributions for each type of renewable energy source will be presented; we describe their main scope and classify them within one of the above three referred categories (IMEP, MFM, and ARAMs).
3.2. ANN Models in Photovoltaic (PV) Energy
In the area of solar energy, the application of ANN models is in continuous development [
58,
59], and more particularly within the field of PV systems, Photovoltaic Solar Energy. In this case IMEP and MFM are the most common models in literature, although there is a recent growing use of ARAM models.
Table 2 shows a compilation of authors that have developed ANN models in PV energy, describing the type of model according to previous classification (A = IMEP; B = MFM; C = ARAM) in one column, the employed methodology in a second column (D = Neural Network; E = Comparisons Models; F = Others), and another column with the parameters considered for prediction (T = Temperature; D = Date; H = Humidity; WH = Work Hour; SR = Solar Radiation; O = Others). Notice that some prediction works not including ANN are also considered to appreciate the modelling techniques that were used for similar problems (see the comments included in the table). Also, we have noticed that many authors have developed comparative studies of different predictive techniques, all of them indicating how ANN models are an interesting alternative approach requiring admissible computational effort.
In the table we can also appreciate how ANN models are used to predict either n industrial photovoltaic systems or domestic installations. Both types of predictions have been oriented to gain knowledge to link solar radiation patterns with energy production ones.
The results obtained have been very positive from the point of view of the correlation coefficients, higher than 90% and with a mean square error less than 5%. The most common input variables in predictive models are temperature and radiation. These studies have been carried out in different parts of the world and at different times.
Finally, the most recent references, based on the acceptance of ANN to obtain the predictive models, have taken a step further. In the ARAM case, powerful detective energy productions models based on ANNs, comparing expected with real energy production, are focused on to detect asset functional failures. These models improve energy efficiency besides reliability.
Concerning failure diagnosis and prognosis, an extra effort is required to properly measure the different failure mode consequences in order to identify the cause and expected behavior pattern of the failure modes [
33,
71].
3.3. ANN in Wind Energy
Wind energy is the kinetic energy generated from wind and is transformed into another type of energy, as electric energy for its consumption in industry and homes. The application of ANN models to replicate production behavior patterns of wind energy is extensive, using as input environmental variables wind speed or humidity. These models look for relevant links among such variables and the detection of anomalies in energy production.
In the same line as before, the reader can find in
Table 3 a comparison of ANN application on wind farms. As in the table for PV, there is a column about the study objective (A = IMEP; B = MFM; C = ARAM), a second column with the employed methodology (D = Neural Network; E = Comparisons Models; F = Others), and another with the used parameters for prediction (WS = Wind Speed; H = Humidity; T = Temperature; SR = Solar Radiation; WH = Work Hour; O = Others). Here again, authors compare techniques in order to describe the advantages of ANNs and new techniques of data mining with respect to the physical and classic models. Previous reviews in this field remark on the increasing use of ANNs to predict, due to good and fast adaptation when faced with a peculiar quality of unknown environmental situations.
ANNs have been used by authors to predict the energy production of wind farms in different parts of the world, obtaining good results with very low mean square errors. The developed models have been effective in order to plan production of energy and especially for their importance to business models. For the entire system, short- and medium-term wind speed prediction statistics and data mining algorithms have been more frequently utilized. The common input variable for all referenced authors has been wind speed.
References [
80,
82] have been oriented towards failure diagnosis/prediction through ARAM testing the effectiveness against other AI-ML (Artificial Intelligence-Machine Learning) models, such as LR (Logistic Regression), Support Vector Machines (SVM) or Random Forest (RF) algorithms in order to identify faults and reasoning about root causes. Recent research on wind turbine condition monitoring focused more on individual components than on the entire system. It is crucial to determine properly the criticality of each component avoiding numerous alarms than can outgrow the more important alarm. In both references, appropriate parameters are determined and they can provide technical reference values for online monitoring, early warning, and condition-based maintenance of wind turbines.
3.4. ANN in Hydraulic Energy
Hydraulic energy is that source of renewable energy obtained through potential and kinetic energy and is produced by water flows, rivers, rains, thawing, snow, etc.
As with the other renewable energy fields, there are numerous studies on the application of ANNs in hydraulic energy.
In
Table 4 we can see how the possibility to simulate non-linear behaviors of the hydrographic basins with ANN models is lately configuring an alternative to the use of conventional time series models. This is the longest implemented renewal technology and with the most static industrial installations on very specific orography determining their locations. Accordingly, the most ancient ANN references are focused on this type of energy.
Two main characteristics define the references, the preference in the utilization of backpropagation network, and the orientation towards predictive models, in concrete, using it to predict the water flow as a fundamental variable to know electrical energy production.
Table 4 has been configured as previous ones, with a column for the model classification (A = IMEP; B = MFM; C = ARAM), a second column with the employed methodology (D = Neural Network; E = Comparisons Models; F = Others), and another one with the parameters used for prediction (RF = Rainfall; HD = Hydrometric Data; T = Temperature; WP = Water Pressure; O = Others).
The main advantage of ANN application in the hydraulic field is the development of simulation models and real-time dynamic prediction, predominantly in a short-term due to the normal variation of the climatological conditions. The most used input variable in these predictive models has been hydrometric data.
In this field, the main disadvantage of ANN application is that a large amount of historical data are required to obtain good models and results, while in previous energies (photovoltaic and wind) the assets are distributed in farms in a replicated way and so offer enough data that reproduce the same operation context. That is to say, in the two previous energy sources, a wide range of information is available to be processed to obtain a reliable prediction while here it can be scarcer. ARAMs are less implemented than the other types and are centered on the single failure mode water leakage; a clear example is reference [
94] for failure detection and localization of it, searching regularities and patterns using not only AI-ML ANN but also Logistic Regression and Support Vector Machine.
3.5. ANN in Other Energy Sources
In other renewable energy resources, such as biomass, biogas, geothermal, hydrogen, etc., we have found less contributions including ANN models, according to the number of plants dealing with these energy sources in the sector. However, ANN models have also here a high potential for prediction of energy and reliability, as the reader can see in sample contributions in
Table 5. ANNs have offered valuable results in several case studies based on their adaptation on real-time in short specific time frames, and the case studies show as key difficulties the necessity of huge amounts of information and an adequate predictive parameter selection.
Table 6 shows some other references about recent research tendencies, mainly focused on other artificial intelligent models and on how to manage the problem of the lack of data. The solution adopted is sometimes to use historical data or data from other areas (see comments in the table).
Due to these novelty sources of energy, the research majority is orientated to develop advanced IMEP and MFM models searching short- and medium-term estimations, more than to develop degradation models of specific components of the system. ARAMs could be an important tool for detection and diagnosis, because as in the hydraulic case, there are difficulties to obtain enough and replicated data from different plants, and even worse, by assets purchased from different suppliers. Failure mode diagnosis and prognosis are the challenges in this section, and they should be initiated based on research of the same equipment but in other industrial scenarios; simplifying the parameter selection method could effectively simplify the structure of the model, using a comparative study of consistency with the observed values.
4. Discussion of Results Regarding ANN Prediction Models
The historical tendency of the application of ANN models in energy generation prediction grows according to the promotion of the different renewable energy sources.
Table 7 summarizes the tendency and evolution of the application of ANN in prediction problems in Photovoltaic, Wind and Hydraulic energies. These contributions are presented according to:
The source of energy: Photovoltaic, Wind, Hydraulic, other sources and new related research.
The type of model: IMEP; MFM and ARAM.
In
Table 7, the reader can also find the number of contributions, per source of energy and model type, per year. It can be appreciated how for each type of energy source, ANN model applications show a similar pattern, consisting of an initial sort of induction phase, when the models are introduced, developed and deployed, and after that, more pressure is placed on the efficiency of the models in what we could call an efficiency improvement phase.
Table 6 shows that references about hydraulic energy applications are the first to appear, in line with the maturity of the technology, while there have not been more publications recently. For this source of energy, all existing ANN publications have focused on energy prediction modelling. In the other two sources of energy, we can find more recent ANN model applications, initially solely energy prediction models, but lately a few of them oriented to specific failure mode detection. In
Table 6, this tendency is distinguished through time intervals; in the top of the reference list, a specific orientation to failure detection can be acknowledged.
Conventional (time series & regressions) prediction techniques were common in many initial contributions, while in the last publications, ANNs become a more popular tool as long as the scope of the studies also changes to improving efficiency in energy production by anticipating failures, avoiding economic losses as a consequence of low reliability.
Concerning model categories, many early works included meteorological forecasting models, along with the physical models as input. Subsequent models included meteorological variables besides physical variables in order to produce an ideal model of energy production, as close as possible to reality. Later publications are very much related to energy production efficiency, but also deal with a specific single type of failure mode of the asset. This tendency towards energy efficiency modelling is in line with the price reduction of sensors and increase in processing capacity of SCADA systems, located in plants and/or embedded in particular assets, to collect information from asset degradation, environmental and operating conditions.
We have found that 86% of the contributions use ANN models for prediction. It is mentioned in the literature [
88] how more than 40% of prediction studies are related to ANN models. In addition, the most used ANN model is the ANN Backpropagation model (81%), mainly with the Levenberg-Marquardt algorithm (which requires high computation capacity) for minimizing MSE. Another less used algorithm in ANN Backpropagation is the Quasi-Newton algorithm. In all the studies the correlation coefficient is higher than 80%, and results are improving in recent references with convolutional and recurrent ANN models. The most employed parameters for prediction and energy source are the following (see
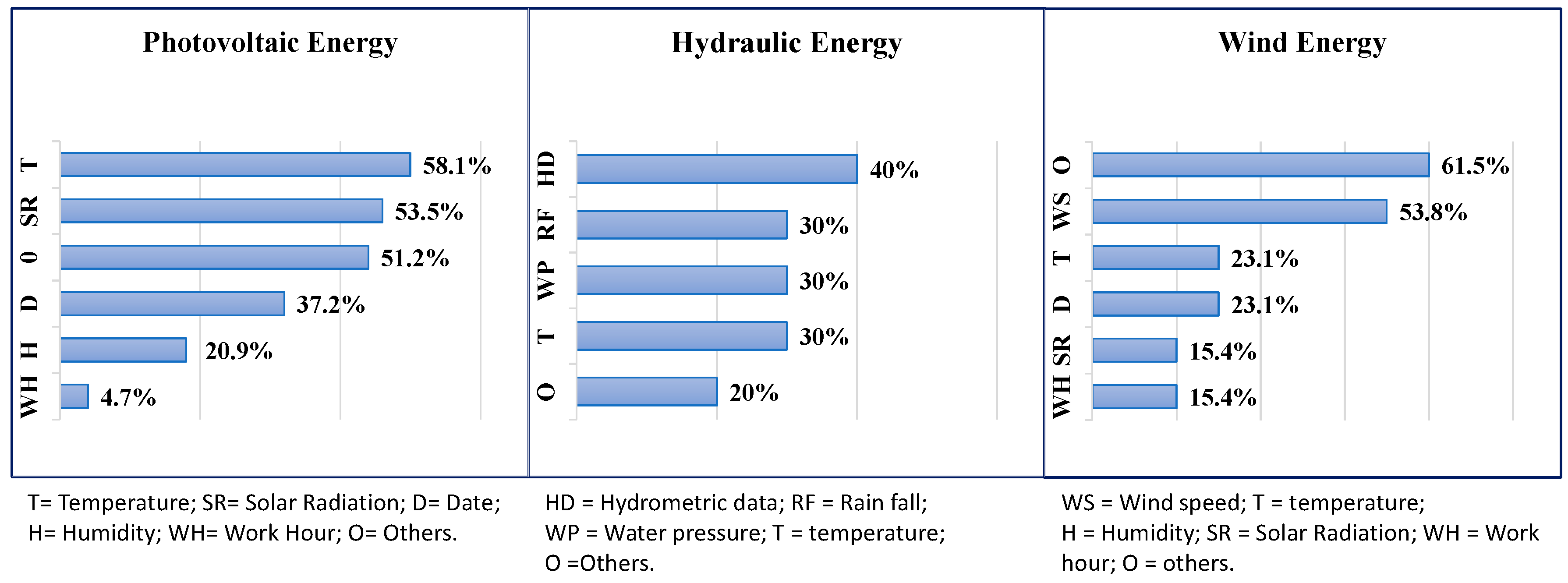
Figure 2):
Photovoltaic Energy: Temperature and Solar radiation.
Wind Energy: Wind Speed.
Hydraulic Energy: Hydrometric data, temperature, rainfall and water pressure.
The main advantages of the use of ANN models, compared to the use of more conventional techniques (time series & regressions), are the following:
Prediction models with good correlation coefficients.
Quick fitting and flexibility to behavior patterns (pattern-recognition and fault tolerance capability including data absence and noise).
Better adaptation to complex and non-linear problems.
Adjustment to dynamic changes in real time.
Quick processing and easy integration in systems.
Availability increment of energy production due to proactivity in fault prediction.
On the other hand, the main drawbacks of ANN models in the renewable energy sector are:
Lack of asset condition monitoring variables. Many companies focus on operation monitoring variables instead.
Presence of poor-quality data, without discerning the different state conditions and without correlation with preventive and corrective activities and their execution results.
Difficulty to reach a local minimum, and to optimize the model coefficients. Need to select proper biases and initial weights.
Lack of out-of-the-box integration in SCADA systems, due to commercial solutions avoiding integration with external intelligent modules.
Lack of qualified professionals with knowledge in these recent types of energy sources, in condition-based and predictive maintenance, and in parallel with experience in big data and machine-learning techniques.
New developments in prediction tools based on AI could be employed or combined with ANN models as the quantity and quality of data variables increase. As an example, the following machine learning techniques are the most recommended to be employed [
103,
104,
105,
106,
107,
108,
109]: Bi-directional Long Short-Term Memory (BLSTM), Deep Learning and Neural Network, Extreme Machine Learning, SVM, T-Basts, Random Forest and Boosting.
5. Discussion of Results Regarding ARAM ANN Models
The necessary knowledge to develop ARAM case studies using ANN models will be very much facilitated and understood if the frameworks for their implementation are based on standards. Standards can help in the process of capturing new monitoring variables and to improve decision making, adopting a more risk-oriented perspective. Most of the ARAM case studies have been successfully implemented for failure detection and correction in the short and medium-term. However, few examples were found for ARAM as diagnosis and prognosis tools (only specific failure mode cases where there was advanced knowledge about degradation and progressive failure consequences).
In grid connected energy plants, the results had the advantage of more replicated accessible data offering better accuracy. Clearly, benefits of ARAMs derived in a quick implementation, and in important reliability improvements. Finally, some of the literature references show how ANN models also allow easy implementation of a parallel agent set that could work with different production models, and then be combined in a certain voting system.
6. Conclusions
ANN models try to replicate complex system behavior patterns and are able to learn through experience, providing many possibilities for their general use. On the other hand, ANN models experienced a great controversy in their utilization because of their mathematical complexity and the huge amount of data needed.
Numerous contributions reviewed endorsed the ANN model utilization under the following premises:
For new knowledge generation, to find knowledge that it is difficult to reach, mainly with non-linear relationships among variables.
Using a wide range of variables to improve prediction accuracy.
Counting on good procedures and information systems as necessary tools to document activities, and data from variables, in order to reproduce results with a high quality.
Not stressing to pursue exact or very accurate results, but flexibility and dynamic adaptation in the model implementations.
The type and scope of the different studies were presented, the prediction variables were analyzed and also different features concerning training methods, algorithms used and data requirements were shown.
Through the reference revisions, this paper discusses the necessity of support ARAM predictions within a structured framework, clarifying the steps and concepts based on international standards, in order to address a sustainable knowledge.
As the main contribution of this paper, we identified the opportunity to develop a new research line focused on the application of AI techniques, and more specifically ANN models, to characterized the reliability of renewable energy plants. Most of the reviewed references were focused on modelling energy production.
Current results provide an important starting point to continue working with this type of AI tool to improve efficiency of this type of facility. In this capital-intensive sector, any minimal efficiency improvement in energy production could represent important economic savings in future business plans and crucial upgrades in service quality delivery. To that end, new developments in prediction tools based on AI could be employed or combined with ANN models as the quantity and quality of data variables increase, for instance: deep learning, SVM, T-Basts, Random Forest and Boosting.

 ,
, 

{kind=link}
{kind=link}