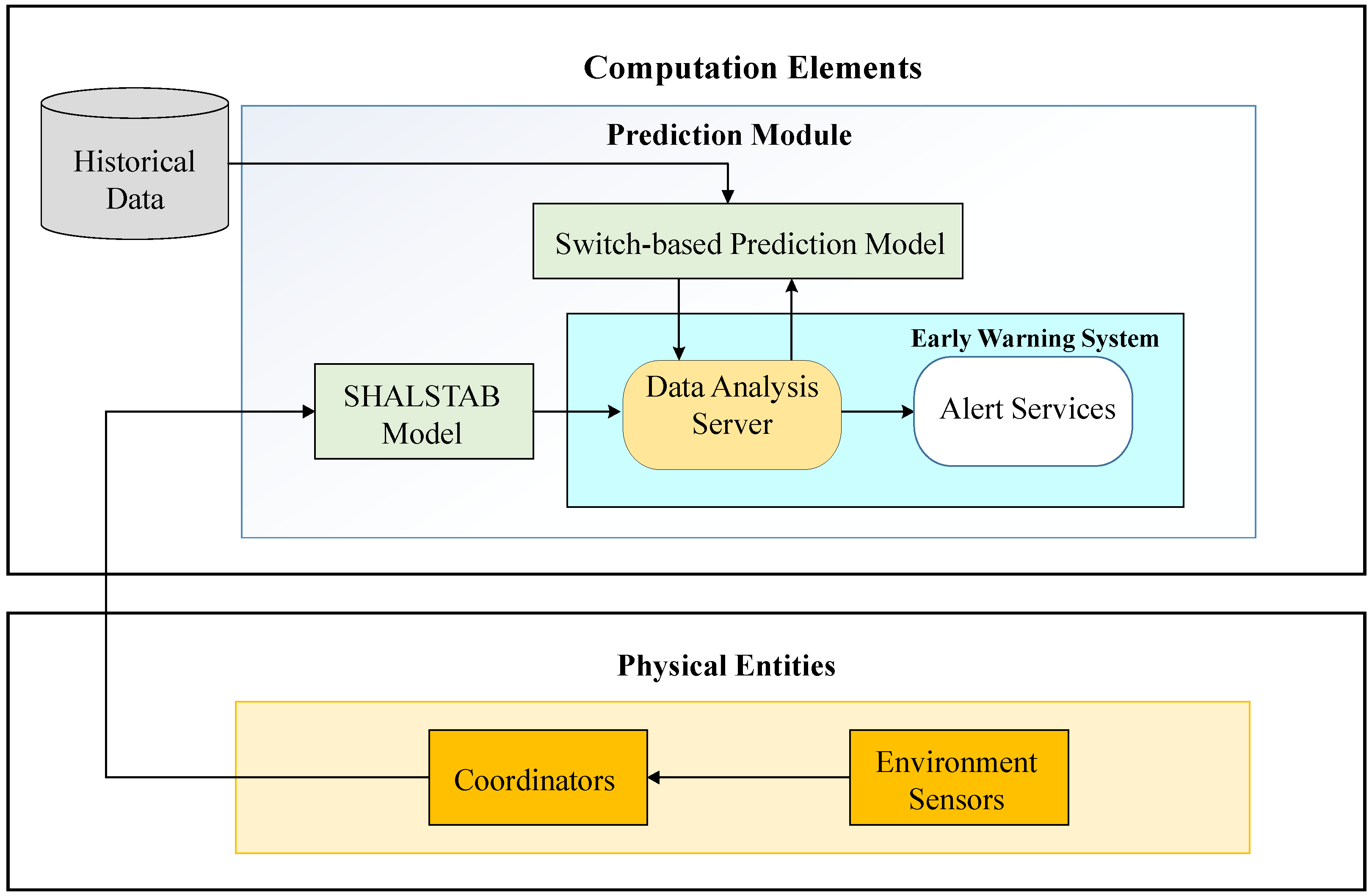
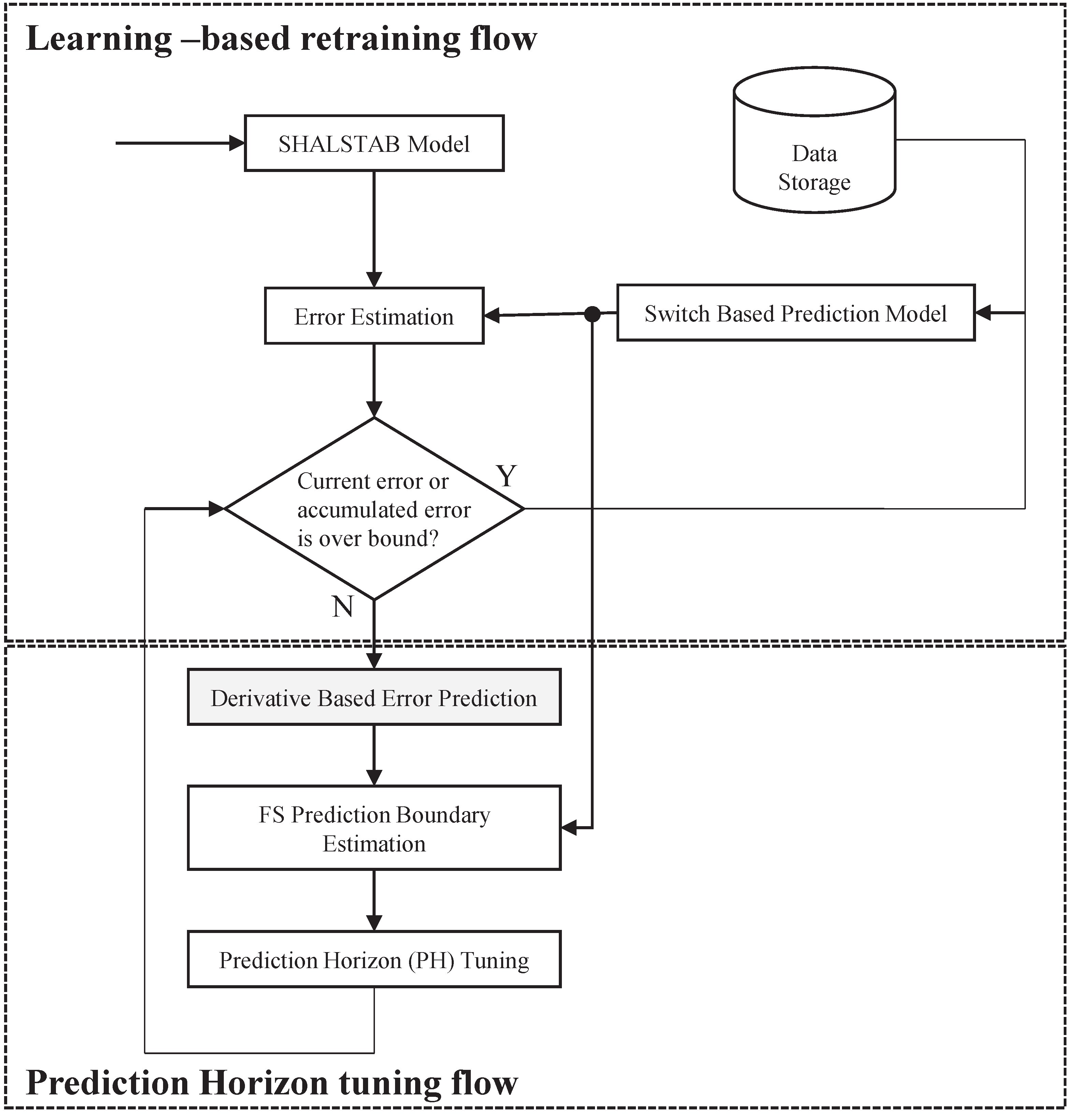
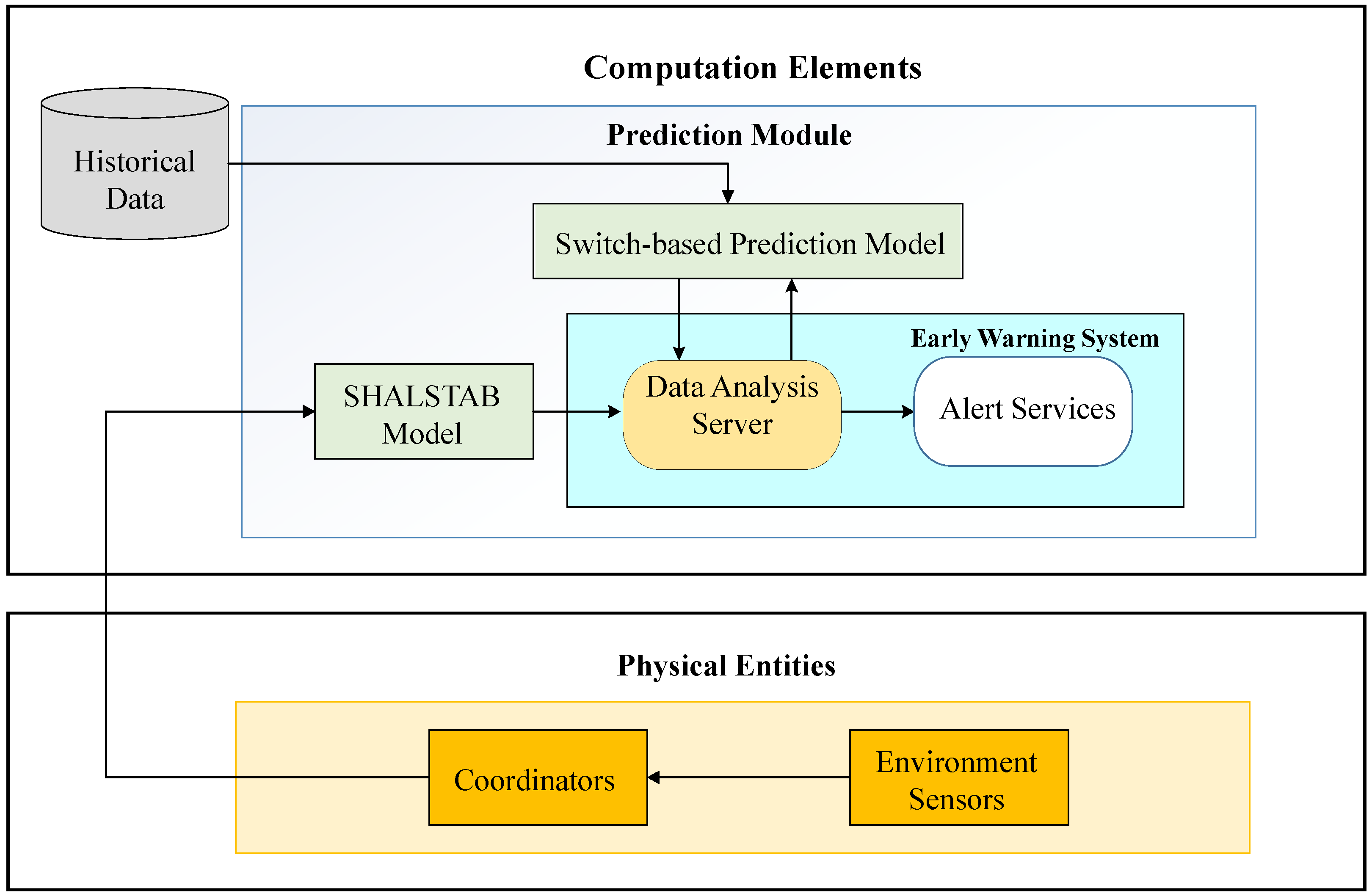
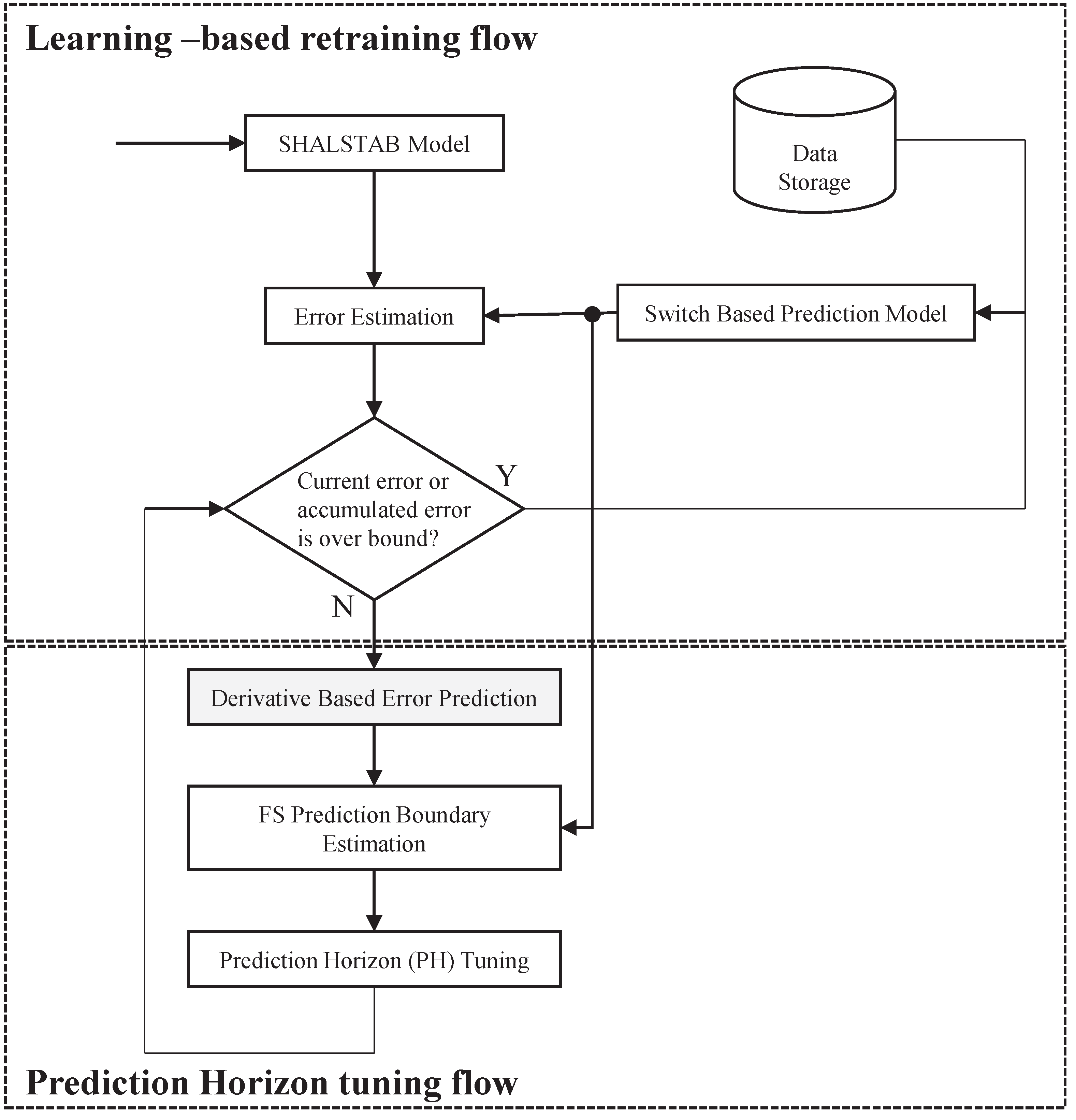
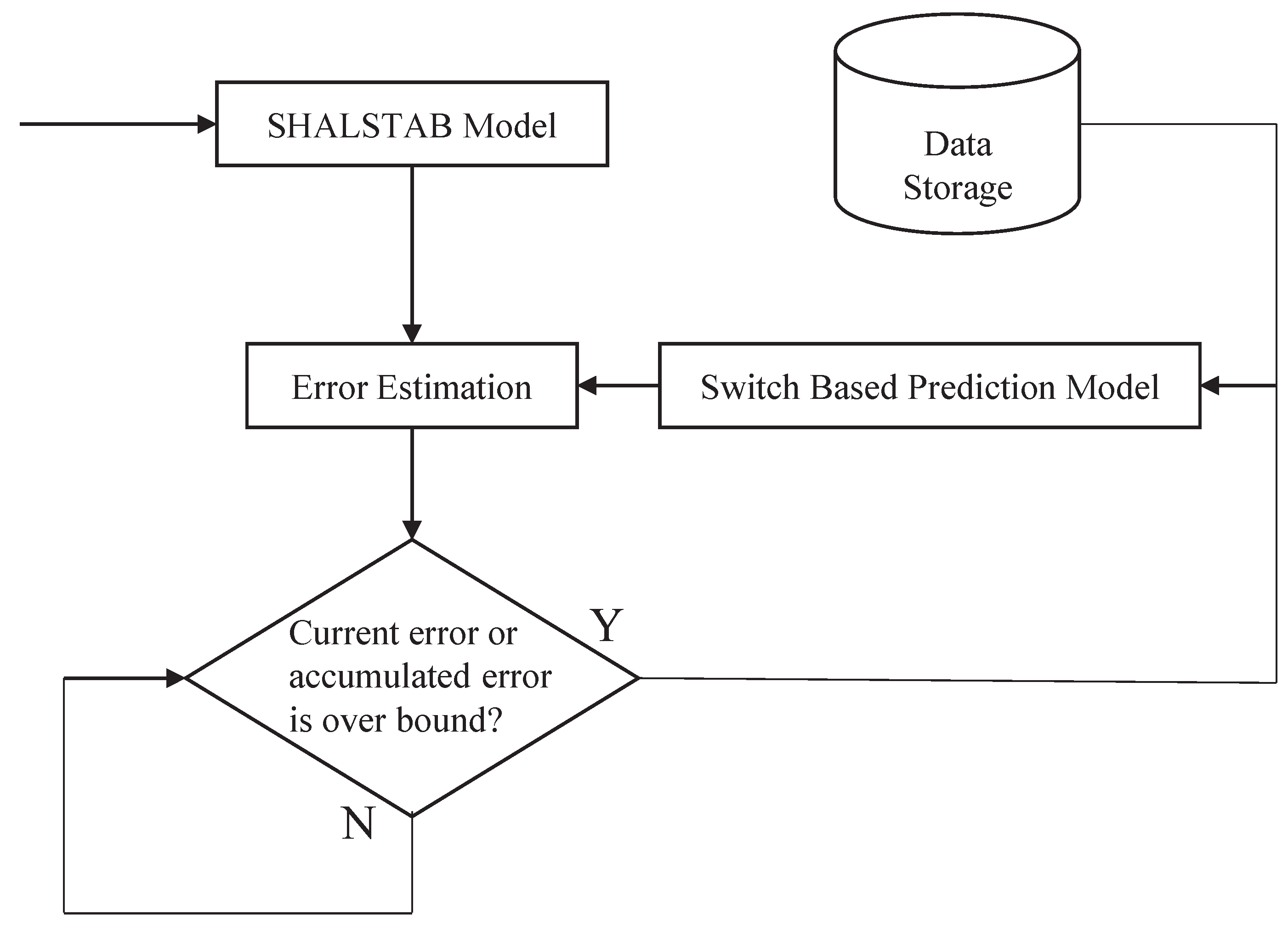
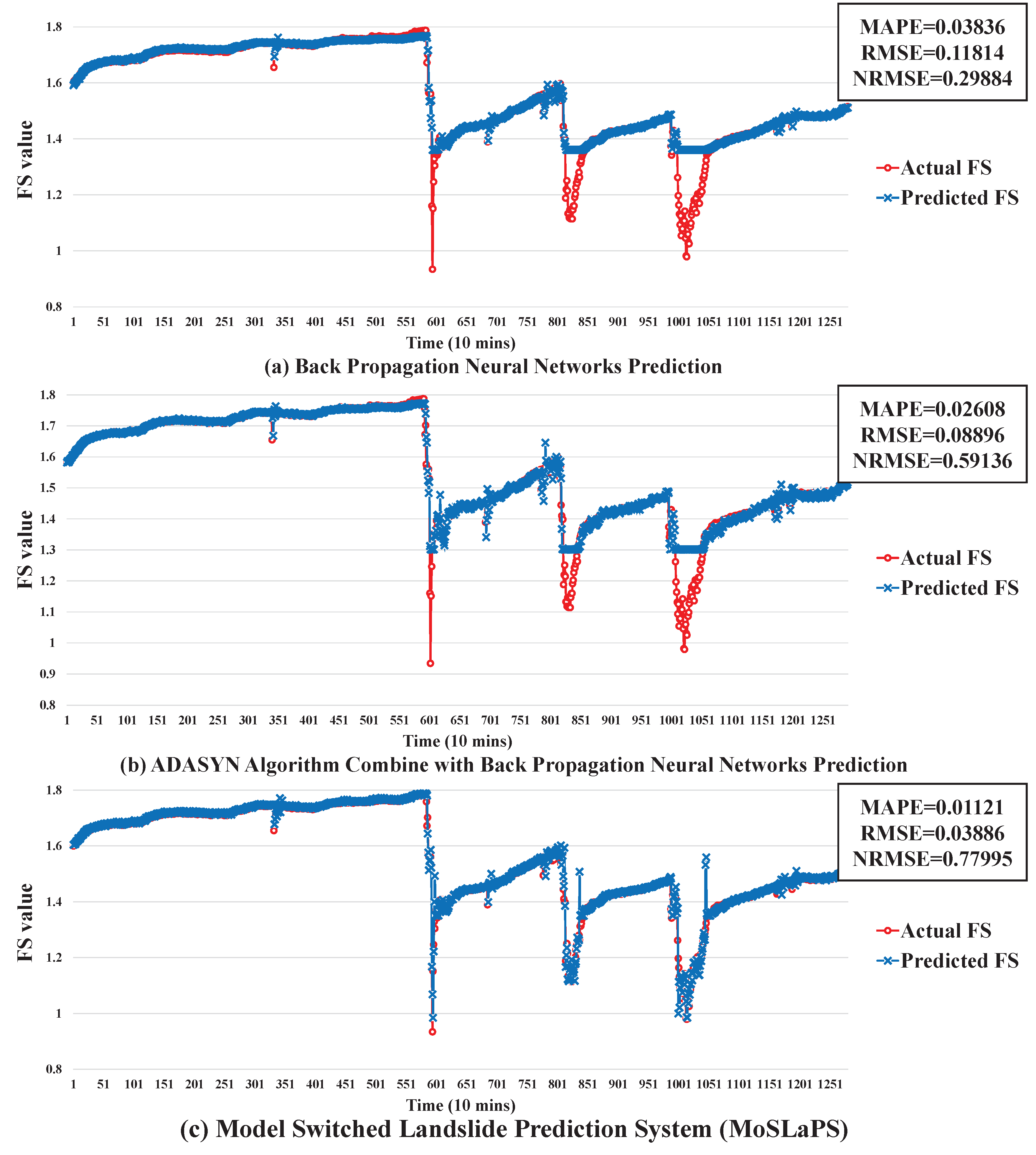
A total solution for landslide prediction with early warnings is proposed in this work. The design of the proposed Model Switched Landslide Prediction System (MoSLaPS) is shown in
Figure 1. It consists of two parts; namely, Physical Entities and Computation Elements. In the Physical Entities, environmental data, such as rainfall, soil moisture, and slope, are collected by sensor nodes. Coordinator nodes integrate the sensed data and transmit them to the Computation Elements through Zigbee transmitters. The Computation Elements consists of a SHALSTAB Model, a Switch-based Prediction Model, and an Accurate Early Warning System, as described in the following.
The details of the prediction models, model switching, and early warning system will be introduced in the rest of this section.
3.3. Switch-Based Prediction Model Design
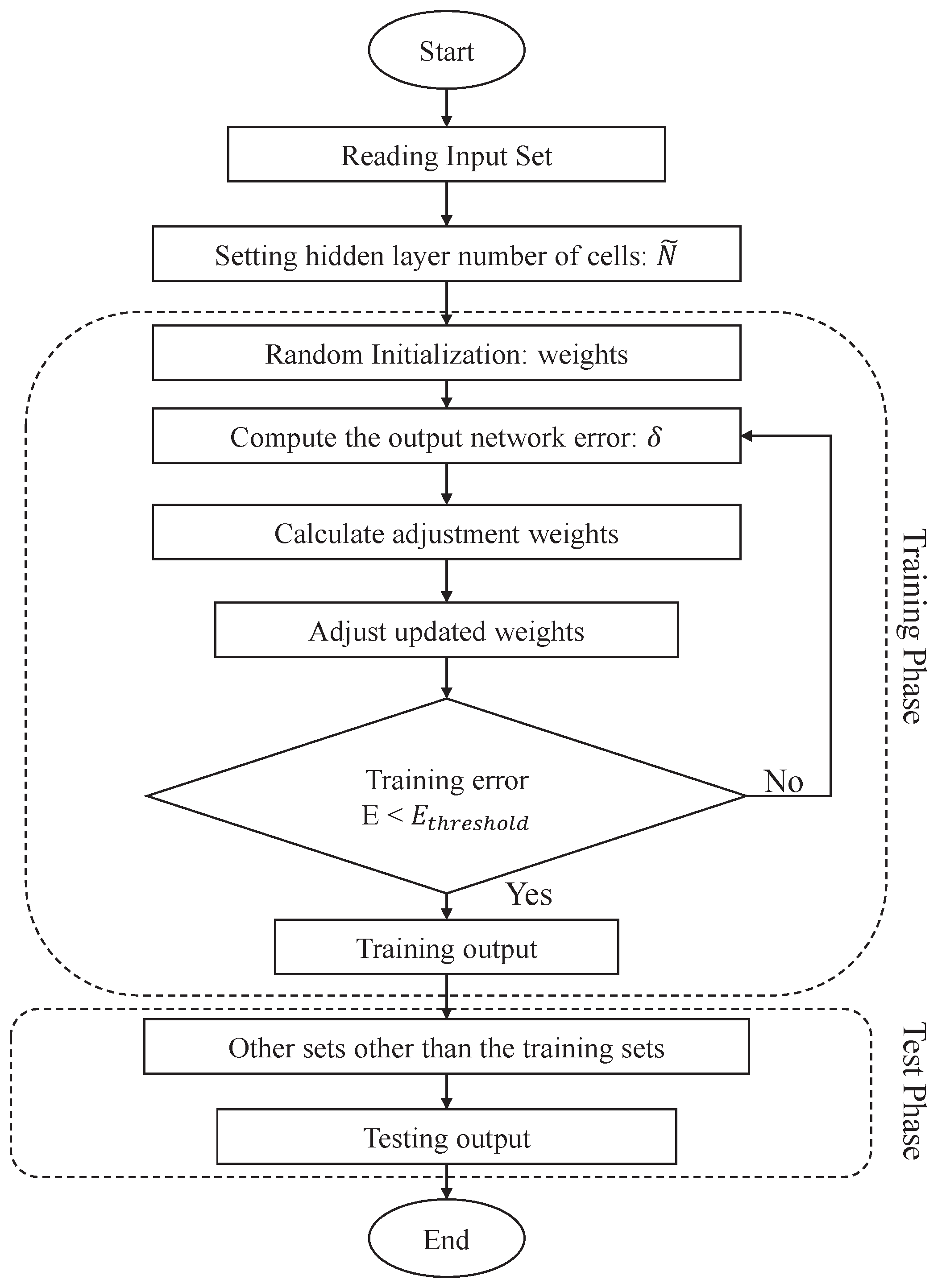
To address the issue of imbalanced data between the unstable and stable classes, a switch-based neural network prediction algorithm is proposed, as detailed in Algorithm 2.
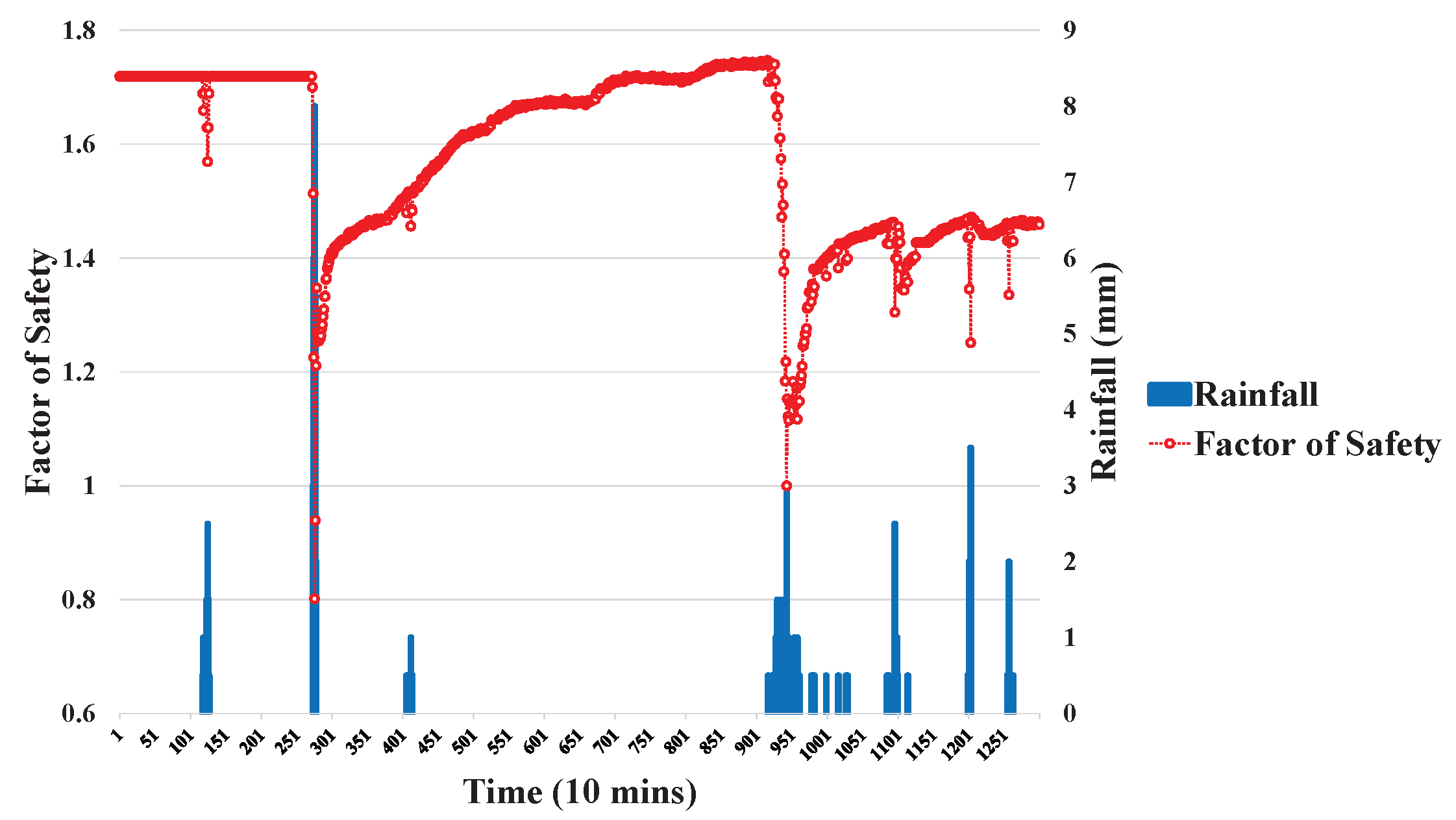
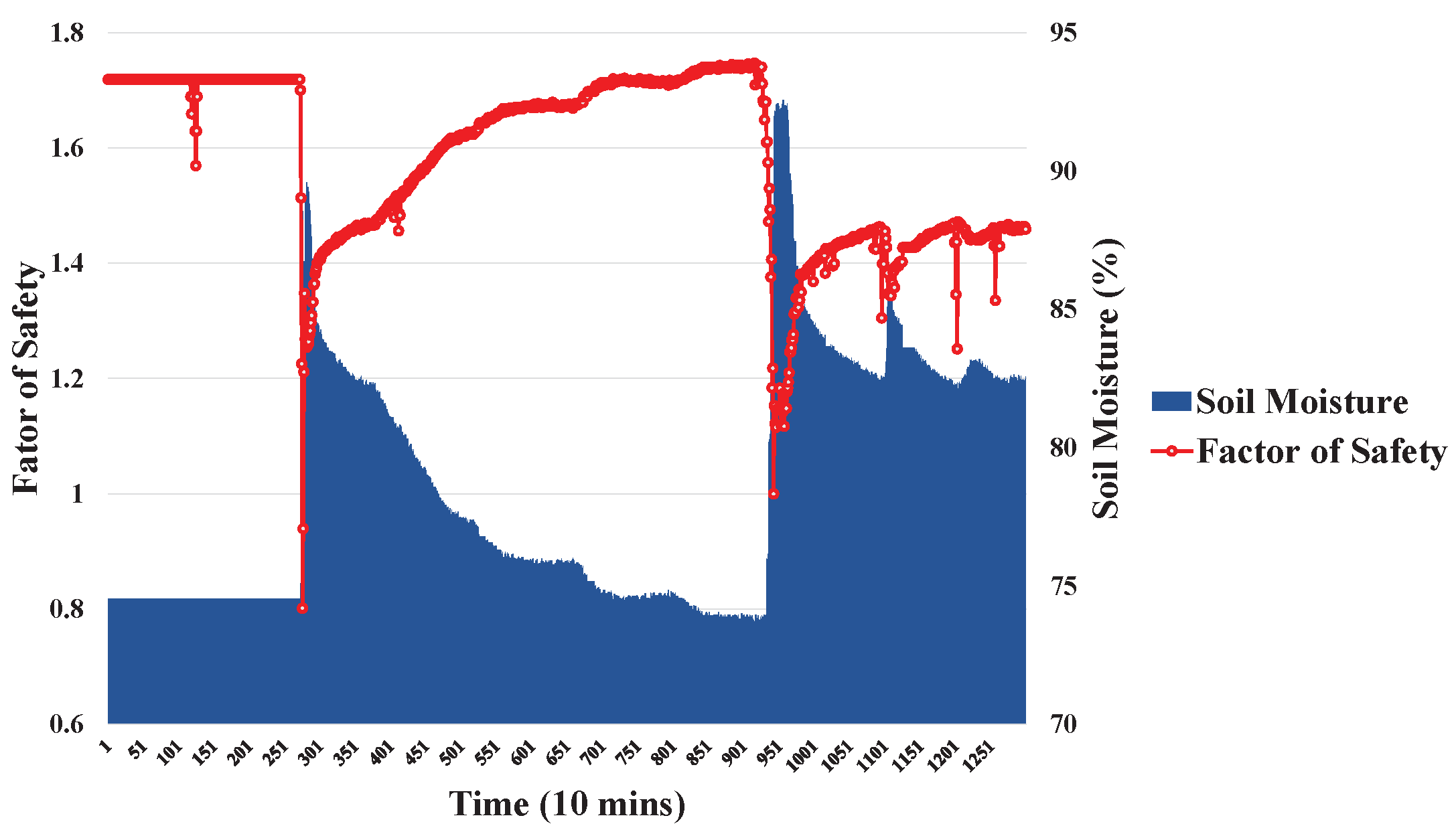
The environmental factors, including rainfall, soil moisture, and slope gradient, are used to calculate the FS values,
, using the SHALSTAB model. Given the environmental samples
, where
,
is the rainfall,
is the soil moisture, and
is the slope gradient, the FS values,
, are calculated given the set of all training samples,
, where
. Then, the corresponding class labels
,
, can be constructed and classified by Equations (
7) and (
8). To construct the BPNN models for different data patterns, the calculated FS need to be classified in two subsets, as follows:
where
is the set of FS values for
, in
, and
is the set of FS values for
, in
; so that
and
.
| Algorithm 2: Switch-based Neural Networks Prediction Algorithm. |
![Applsci 09 01839 i002]() |
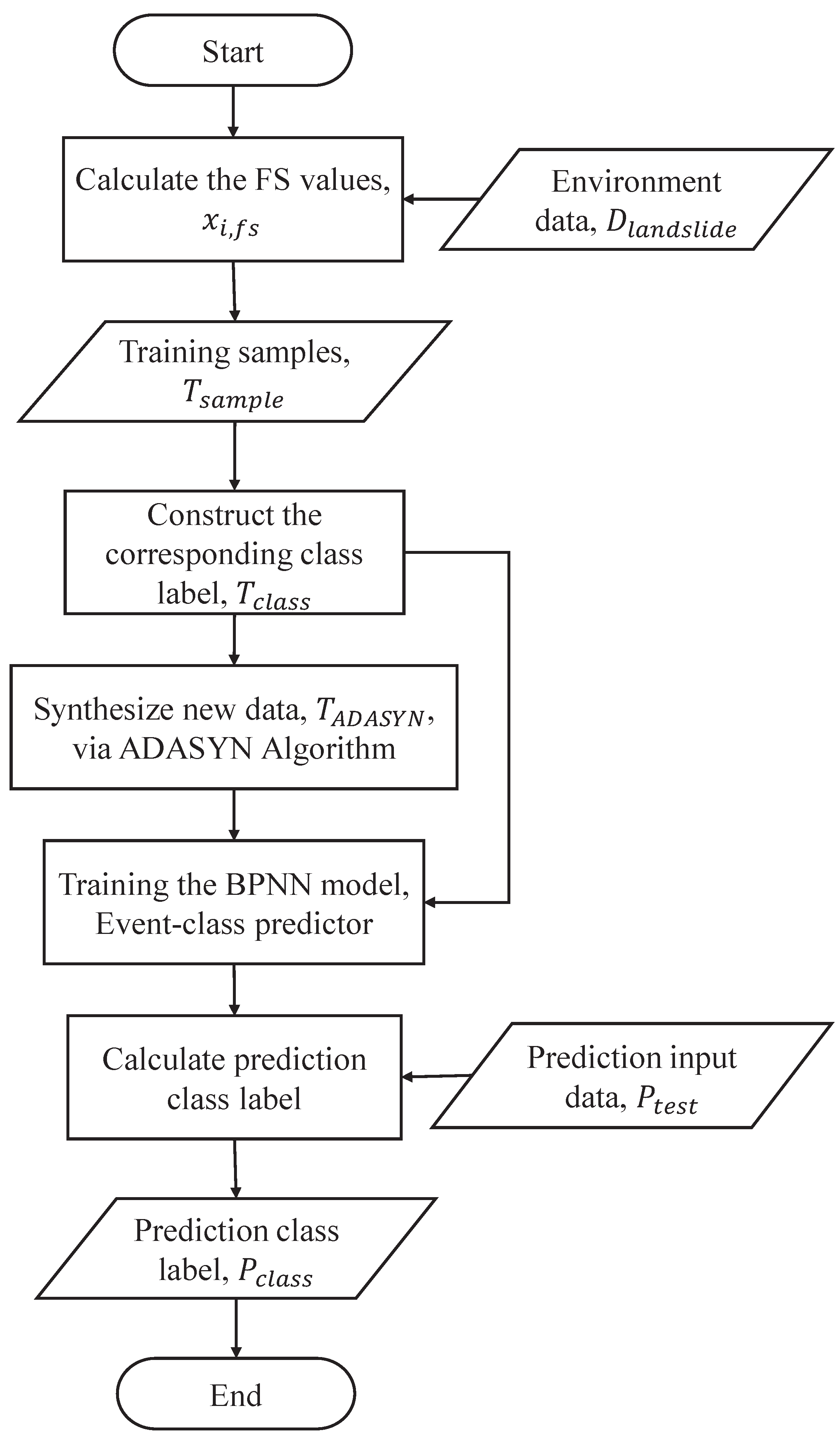
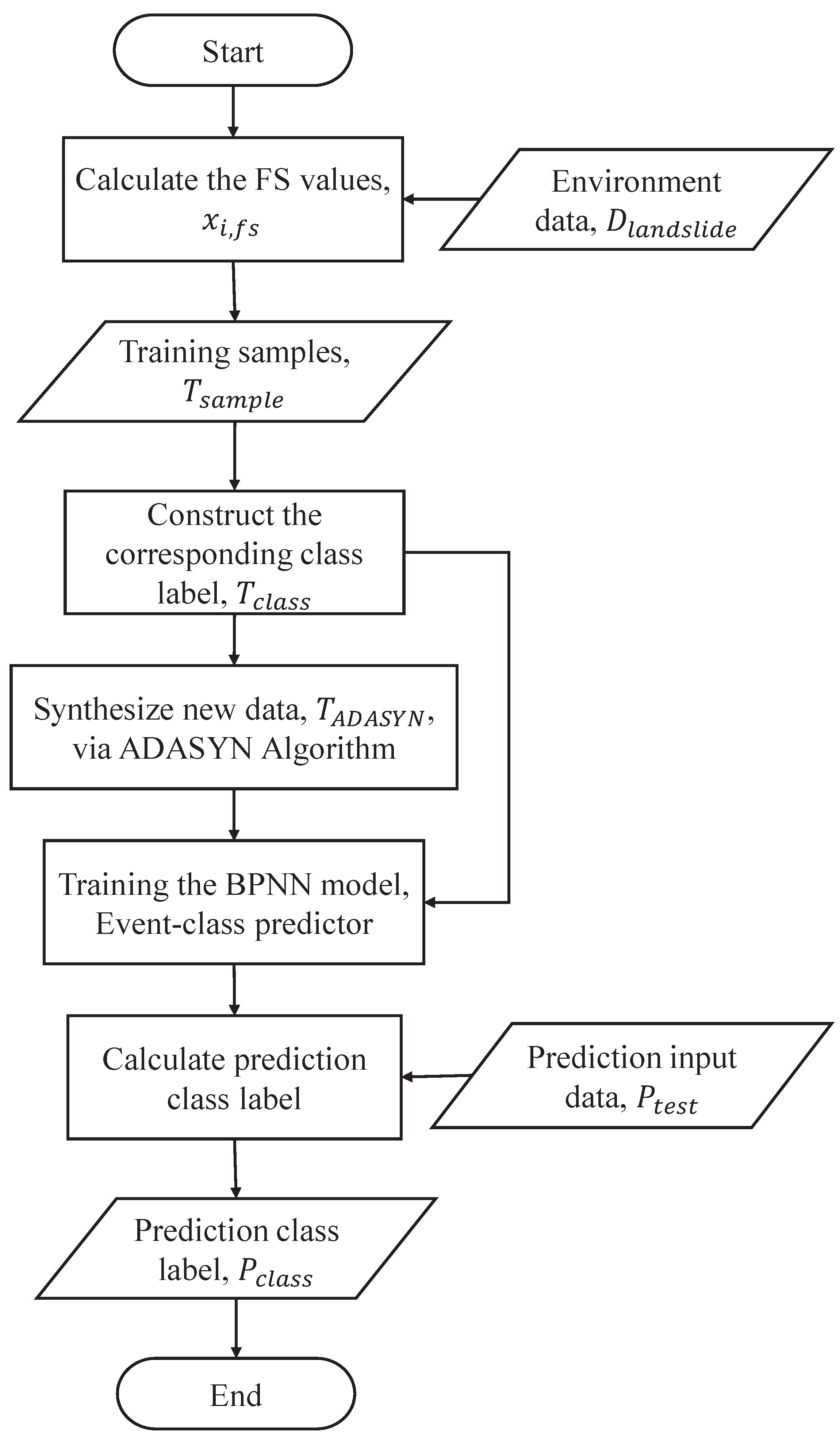
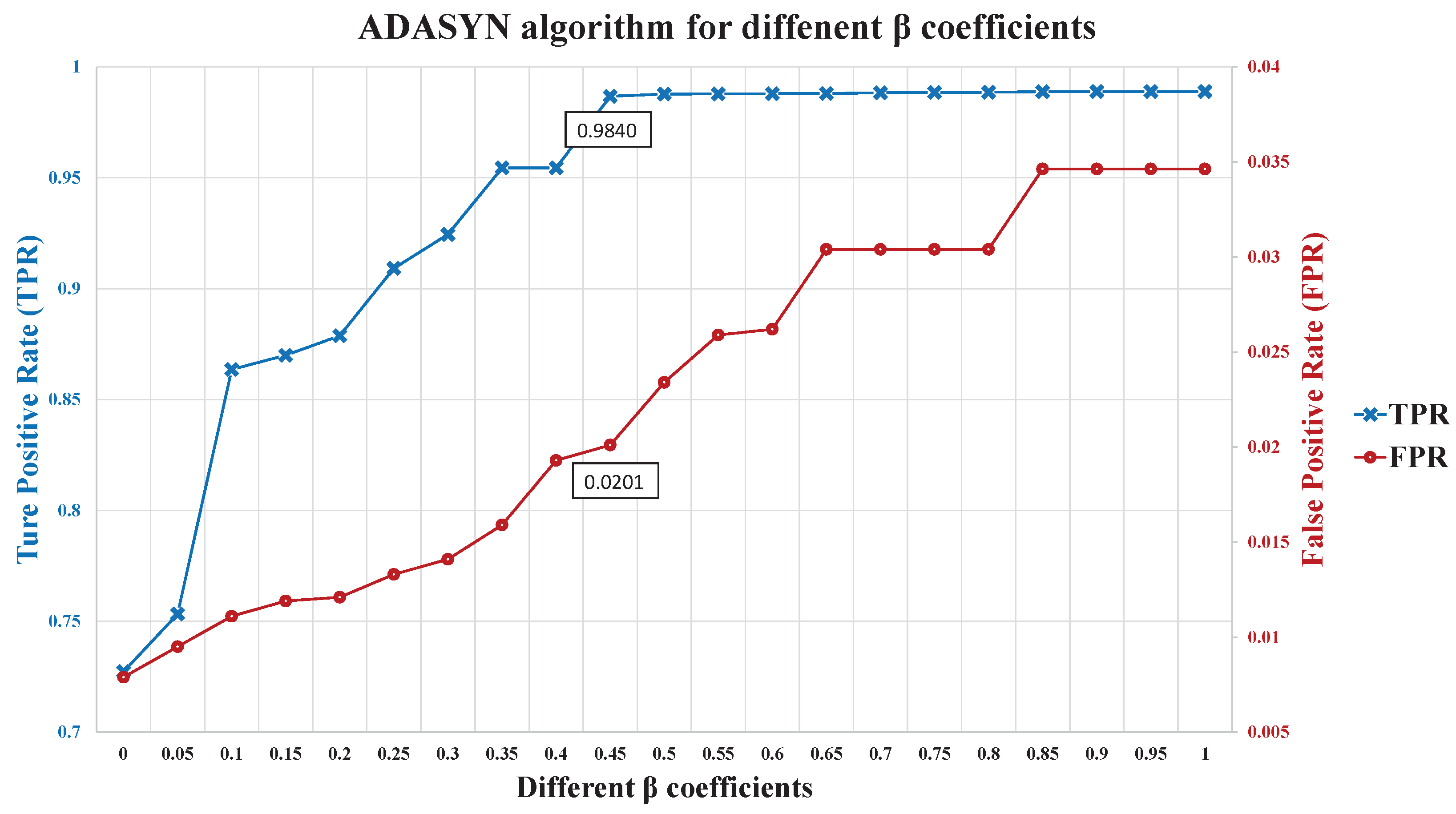
Here, the ADASYN algorithm is used to produce new synthetic samples for the unstable class, in order to balance the sizes of the two classes. The processed dataset,
, is used to predict the future class using a BPNN model. The event-class predictor can switch between the different models, according to the predicted class. As shown in
Figure 4, the steps of the event-class predictor are as follows.
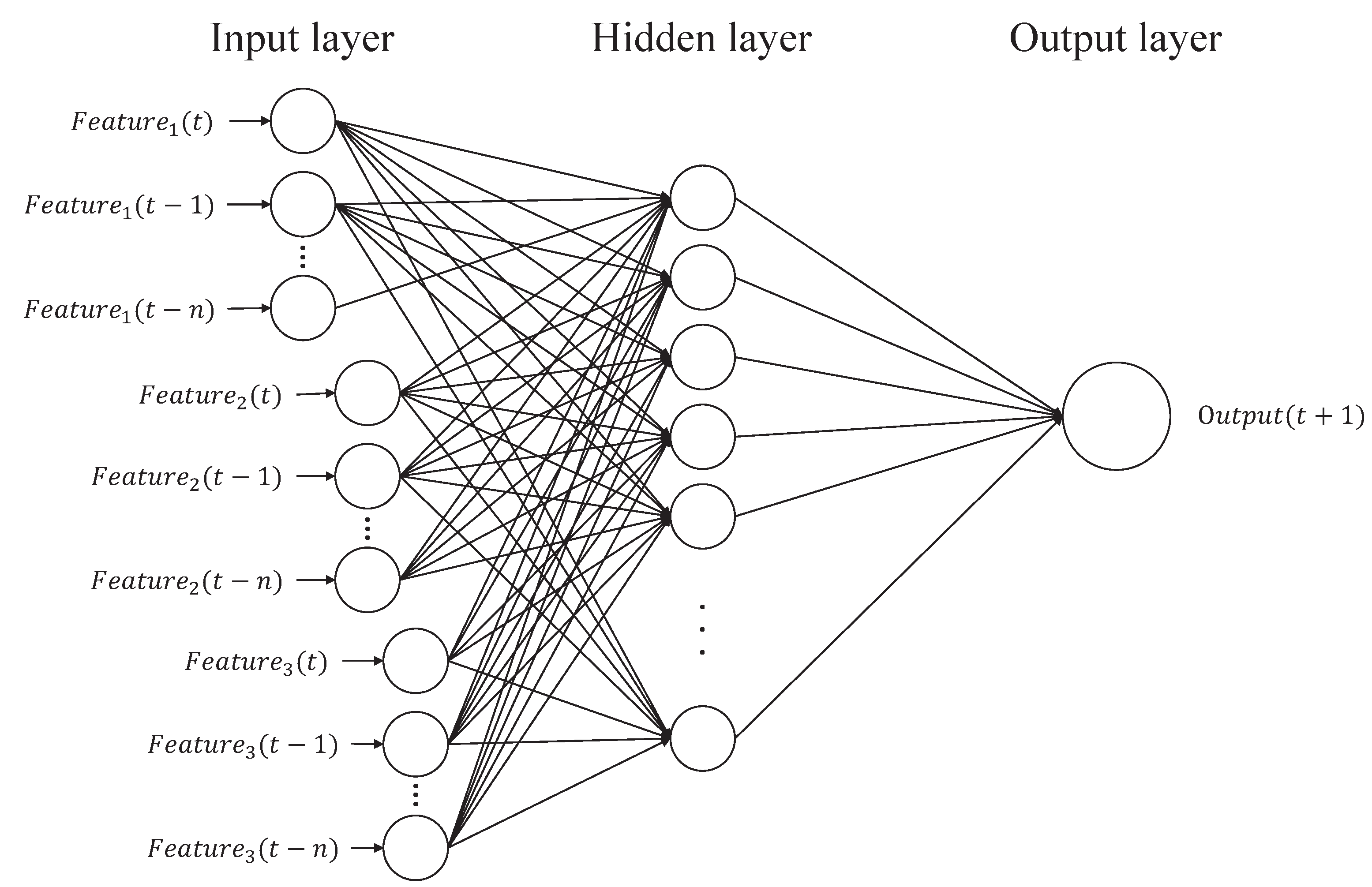
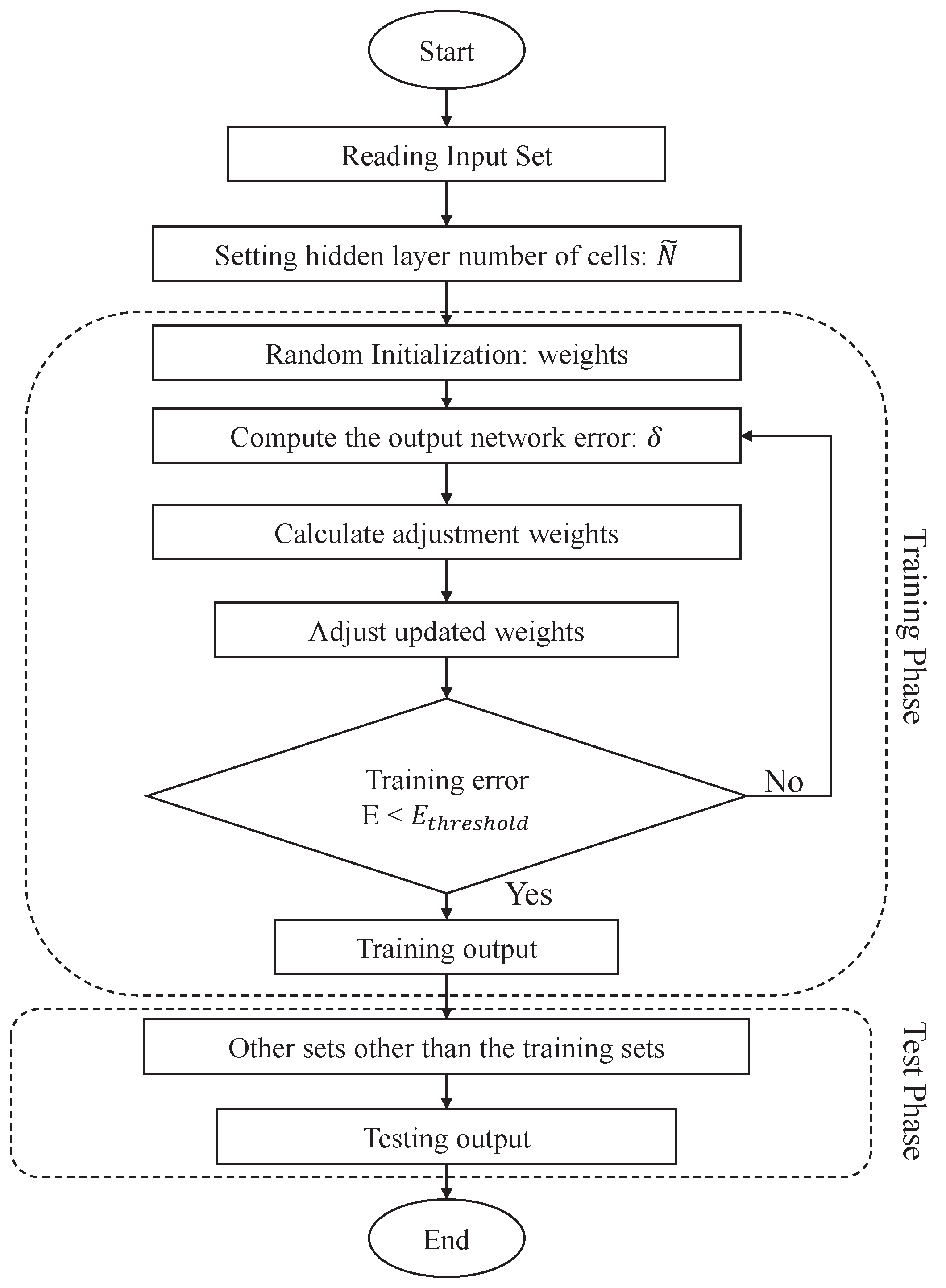
First, is selected to construct the synthetic dataset for balancing class distribution by the ADASYN algorithm, where are the new synthetic samples, , and represents that the synthetic class label is unstable class. The synthetic include , the new synthetic FS value; , the new synthetic rainfall; , the new synthetic soil moisture; and , the new synthetic slope gradient. Both of the classes and are integrated into the training set of the event-class predictor. Second, the event-class predictor is constructed using the BPNN model. Finally, the event-class predictor is used to predict the future class label, , for the testing phase, where represents that the prediction class label is stable and represents that the prediction class label is unstable.
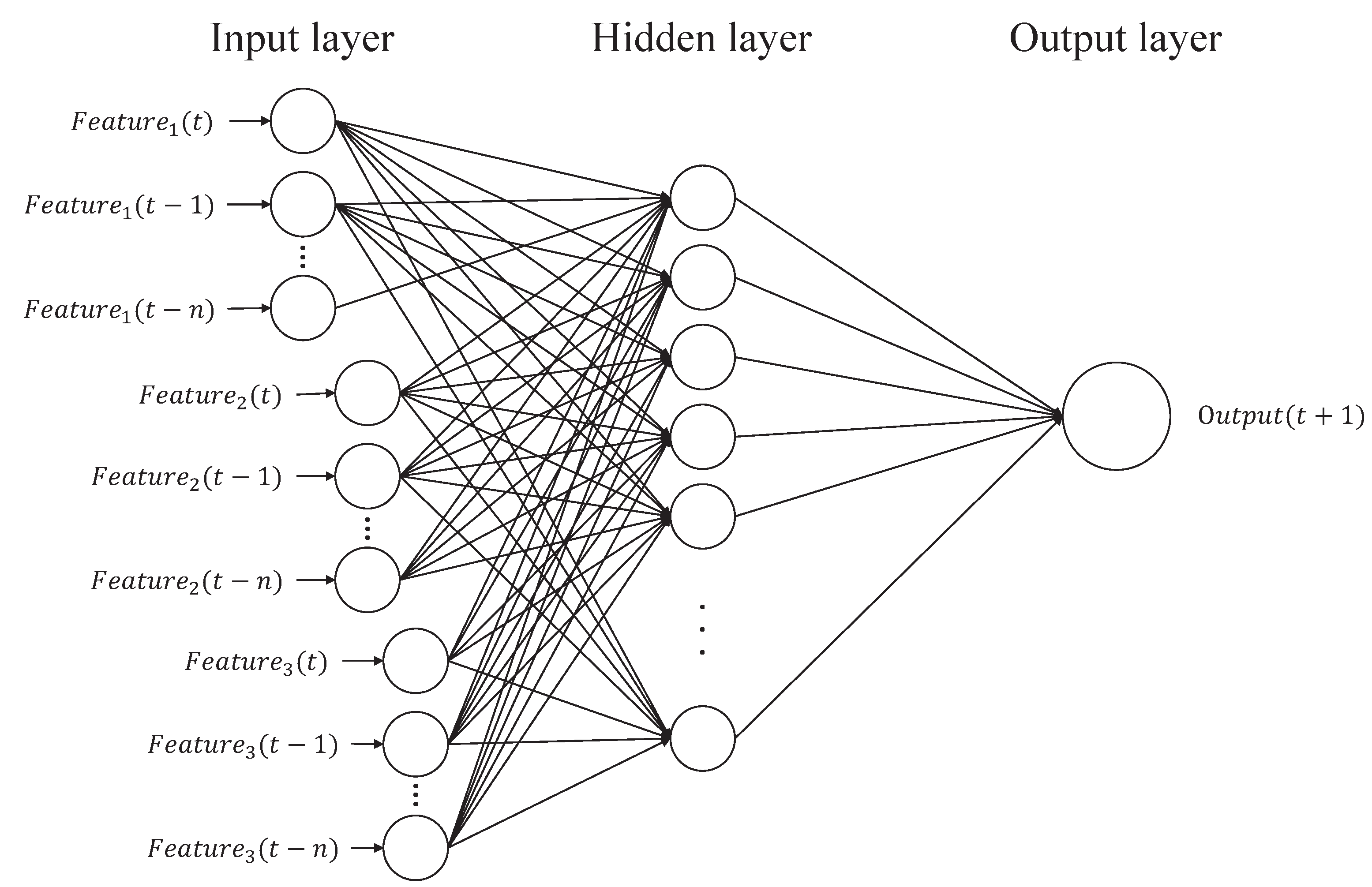
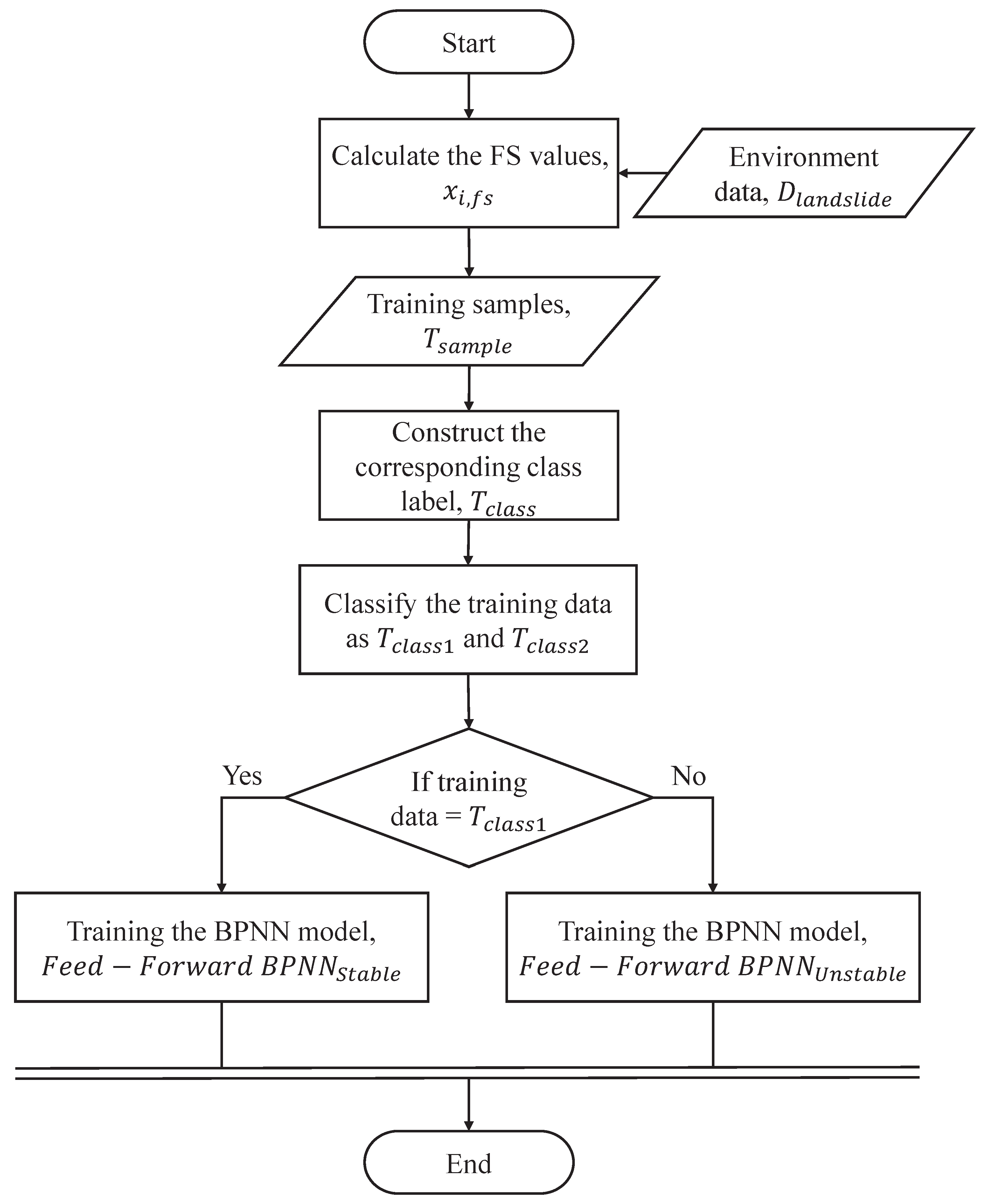
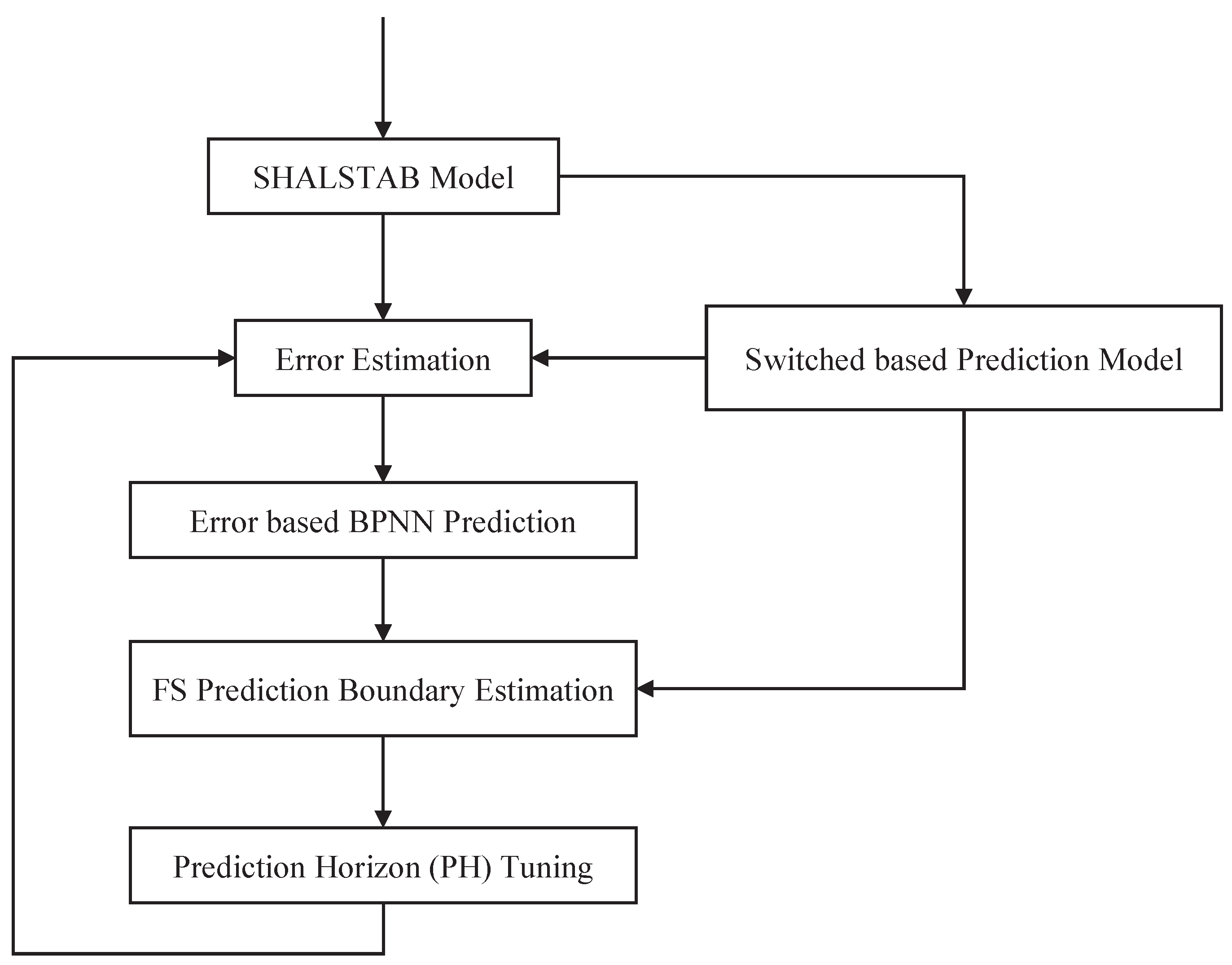
The aim of our proposed method is to construct different pattern predictors, as shown in
Figure 5. The steps of different pattern predictors are as follows. First,
is used as training data to train a BPNN model. After training, the BPNN model is the stable pattern of
(i.e.,
). On the other side,
is applied as training data to train another BPNN model. After training, the BPNN model is the unstable pattern of
(i.e.,
). Thus, two BPNNs are built to deal with different patterns. As shown in
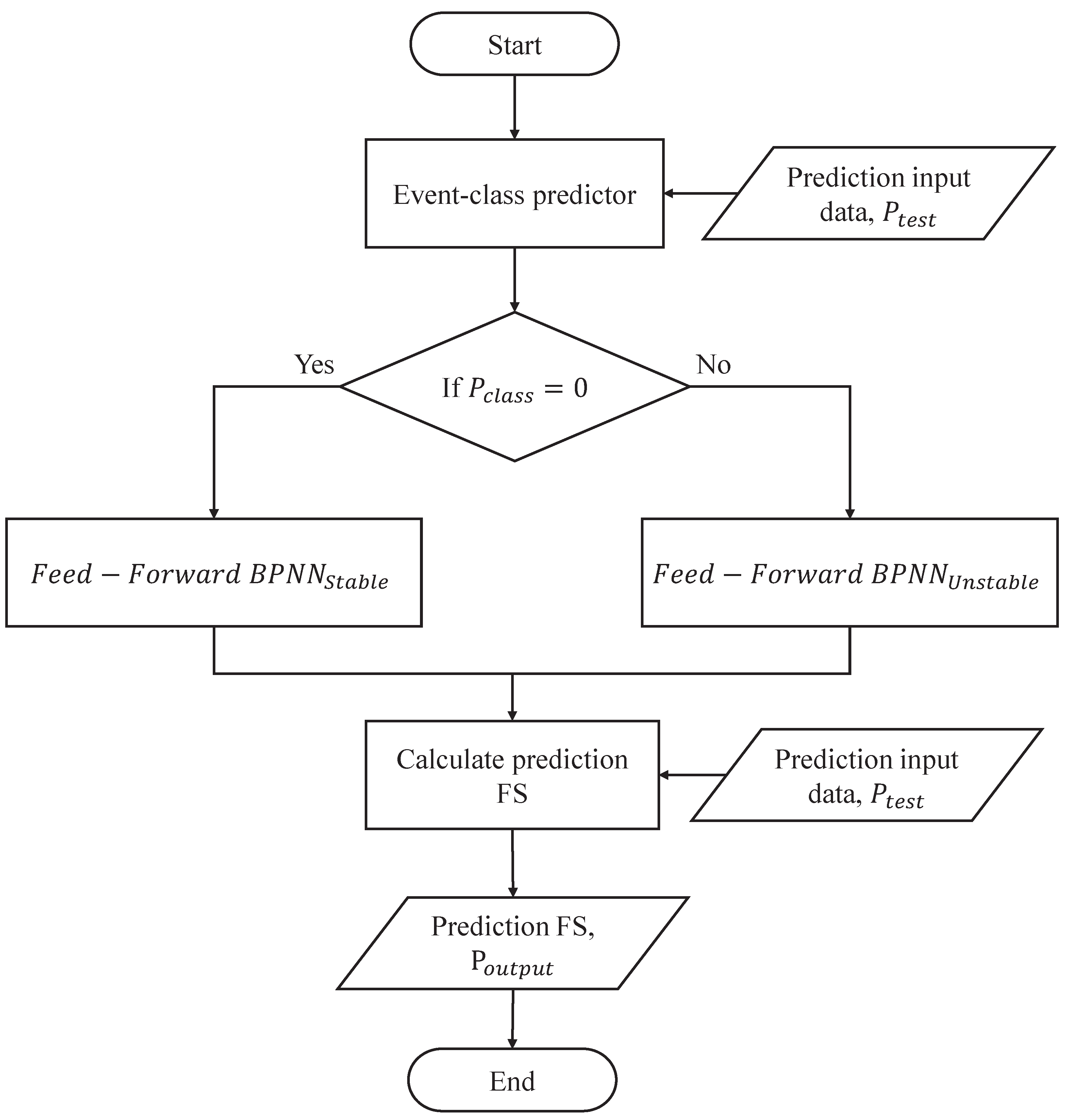
Figure 6, this procedure can switch different pattern predictors, according to the predicted class,
, that is obtained by the event-class predictor. When
, the testing data,
, is applied to predict the future FS using
, where
,
is the testing data of the FS value,
is the testing data of the rainfall,
is the testing data of the soil moisture,
is the testing data of the slope gradient, and
is the testing data of the corresponding class label. On the other side, when
,
is employed to predict the future FS using
. Finally, the predicted FS,
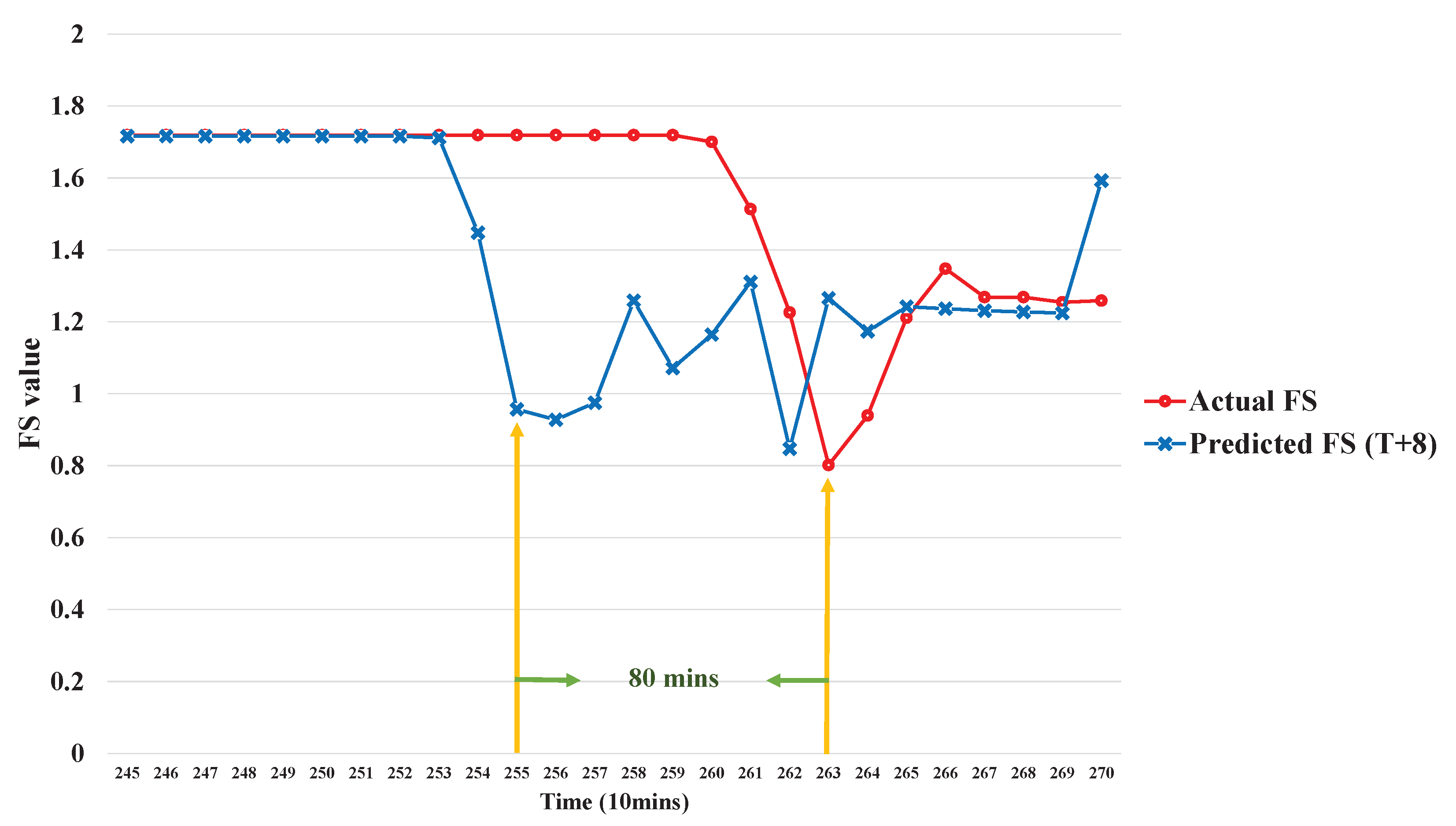
, can be obtained by using the proposed Switch-based Prediction Model.
The main contribution of this work is that the proposed method can make highly accurate predictions, even in the case of highly imbalanced data. Two techniques were employed, ADASYN and an event-class predictor.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}