1. Introduction
With the growing popularity of automatic speaker verification (ASV) systems, the attacks on them have posed significant security threats, which requires that the ASV systems have the ability to detect spoofing attacks. Generally, spoofing attacks can be categorized into four types: impersonation, synthesis, conversion, and replay [
1]. In order to promote research on anti-spoofing, the automatic speaker verification spoofing and countermeasures (ASVspoof) challenge [
2] was first launched in 2015, which focused on discriminating between synthesized or converted voices and those uttered by a human. The second challenge, i.e., the ASVspoof 2017 challenge [
3], focused on detecting replay spoofing to discriminate whether a given speech was the voice of an in-person human or the replay of a recorded speech.
Replay attack refers to when an attacker uses a high-fidelity recording device to record the voice of a legitimate authentication system user and then uses the recorded playback through the device on the ASV system, thereby achieving an attack behavior [
4]. With the development of electronic technology, the performance of high-fidelity recording and playback equipment has been considerably improved. A replay attack is not difficult to implement and does not require any specialized knowledge, which poses a significant threat to ASV systems [
5]. Therefore, the research on replay attack detection has become increasingly important. Villalba et al. [
6] used far-field replay speech recordings to investigate the vulnerability of an ASV system and showed that the equal error rate (EER) of the ASV system increased from 1% to nearly 70% when the human voice was recorded directly and replayed to the device. Algre et al. [
5] further evaluated the risk of replay attack by using the 2005 and 2006 National Institute of Standards and Technology Speaker Recognition Evaluation dataset (NIST’ 05 and NIST’ 06) corpus and six kinds of ASV systems. Their results showed that the low-effort replay attack posed a significant risk to all the ASV systems tested. However, the work presented above only reported the results in conditions without background noise, thus it is still not clear how background noise affects the performance of spoofing detection. Therefore, in order to enhance the security of ASV systems, spoofing detection in noisy environment is investigated in this paper.
2. Related Work
Over the years, different methods have been tested to explore spoofing detection. A replay-detection algorithm, based on peakmap audio features, was proposed in [
4], which calculated the similarity of the peakmap features between the recorded test utterance and the original enrollment one. If the similarity was above a certain threshold, the utterance was determined to be a replay attack. The replay-detection performance was further improved by adopting a relative similarity score in [
7].
Zhang et al. used Mel frequency cepstral coefficients (MFCCs) to detect replay [
8]. They believed that the silent segments of a speech would better detect the channel source than the spoken segments. Therefore, voice activation detection (VAD) was utilized to extract the silent segments of a speech and a universal background model (UBM) was created to model the difference between the speaker’s testing utterance and their enrollment utterance. However, the use of acoustic signal processing to detect replay attacks is considered to be challenging due to the unpredictable changes in voice recording environments, recording equipment, etc. [
3]. For example, artifacts introduced by the acoustic surroundings, such as reverberation, might be confused with the artifacts introduced by playback in some cases. Li et al. [
9] tried to use machine learning to detect replay attacks, but only obtained poor performance due to overfitting.
In the ASVspoof 2017 challenge, an official corpus for detecting replay attack and a baseline system, based on the Gaussian mixture model (GMM) with constant Q cepstral coefficient (CQCC) features [
10], were provided. The challenge required participants to propose a method that distinguished between genuine speech and a replay recording, where a total of 49 submissions were received from the participants. The average EER of all the submissions was 26.01% [
3], where only 20 out of 49 submissions obtained lower EERs than the GMM and CQCC baseline. Among all of the submissions, the best detection performance was reached when using deep convolutional neural networks on spectrograms [
11]. This method used an ensemble of three techniques: convolutional neural network (CNN) with recurrent neural network (RNN), light CNN (LCNN), and support vector machine (SVM) i-vector. In addition, Patil et al. [
12] proposed variable length Teager energy operator-energy separation algorithm-instantaneous frequency cosine coefficients (VESA-IFCC), and Li et al. [
9] utilized a deep neural network (DNN) model with L-Fbanks cepstral coefficient (LFCC) features to identify the genuine and the spoofing speech. All these algorithms achieved better results when compared to the other submissions on the dataset.
The work in this paper is based on the official corpus of the ASVspoof 2017 challenge, i.e., ASVspoof2017 dataset Version 2.0. However, the genuine utterances of the dataset were collected in clean environments (i.e., without any background noises), while the spoof utterances were recorded in environments with various background noises. The genuine utterance setting conflicts with real-world scenarios with complex, noisy environments where the ASV system typically works. In fact, genuine utterances may have background noises, while spoof utterances will contain both the genuine utterances’ noises and the noises of the recording environment. Therefore, noisy environments will definitely create challenges in distinguishing between genuine and spoof utterances. Therefore, it is worth exploring the effectiveness of a noise-robust algorithm on spoofing detection, which is the motivation of this paper.
3. Motivation
The previous related work has confirmed that replay attack is still quite a threat to ASV systems, although a couple of replay detection methods have been proposed with success. Towards noise-robust detection, countermeasures and detection algorithms still have room for improvement, especially in complex, noisy environments.
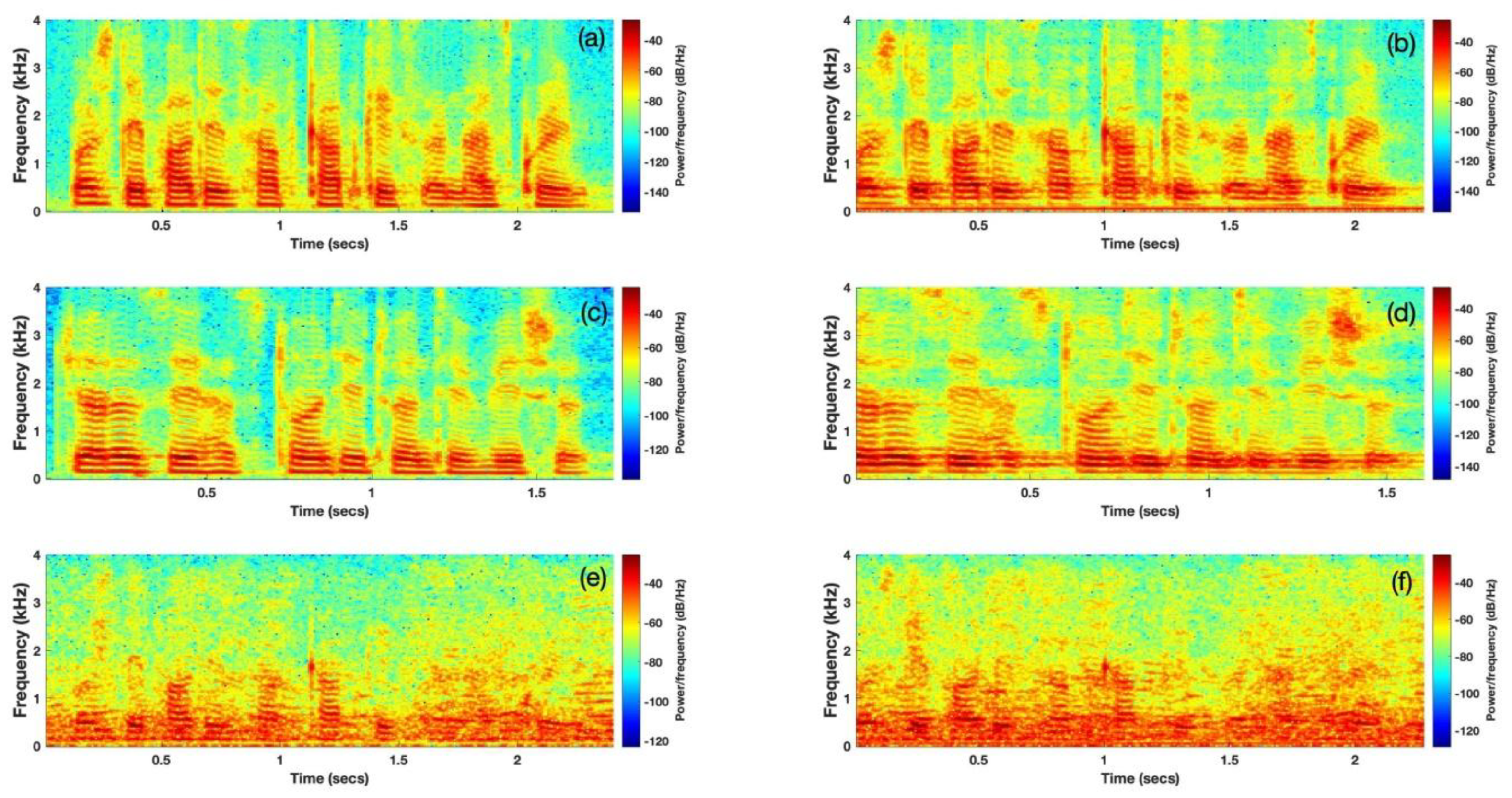
Figure 1 shows two pairs of genuine human voices and their corresponding replay speech from the ASVspoof 2017 dataset Version 2.0. The figure tells us the following:
(1) The durations of the utterances are different. Hence, the chosen algorithm should be able to process signals with variable lengths.
(2) The first pair of the genuine (a) and spoof (b) utterances differ greatly in their low frequency regions, while the differences in the second utterance pair, (c) and (d), lie mainly in the high frequency regions. Therefore, distinguishing features can occur over all frequency bands and it is, thus, not appropriate to focus on only high or low frequency bands.
(3) (e) and (f) are the noise-contaminated utterances of (a) and (b), respectively. The spectrograms show that the utterances in noisy environments are more complicated than those of the clean environments. For example, when comparing (a) and (e), it is obvious that some of the distinguishing features of (a) have been dispersed when noise occurs. This phenomenon highlights the difficulties in spoofing detection for noisy utterances, as will be numerically explained in
Section 5.3.
In this paper, we aim to improve the spoofing detection algorithm by overcoming the problems presented at the beginning of this section, and propose a robust algorithm for replay attack detection in noisy environments. Our research motivations are summarized as follows:
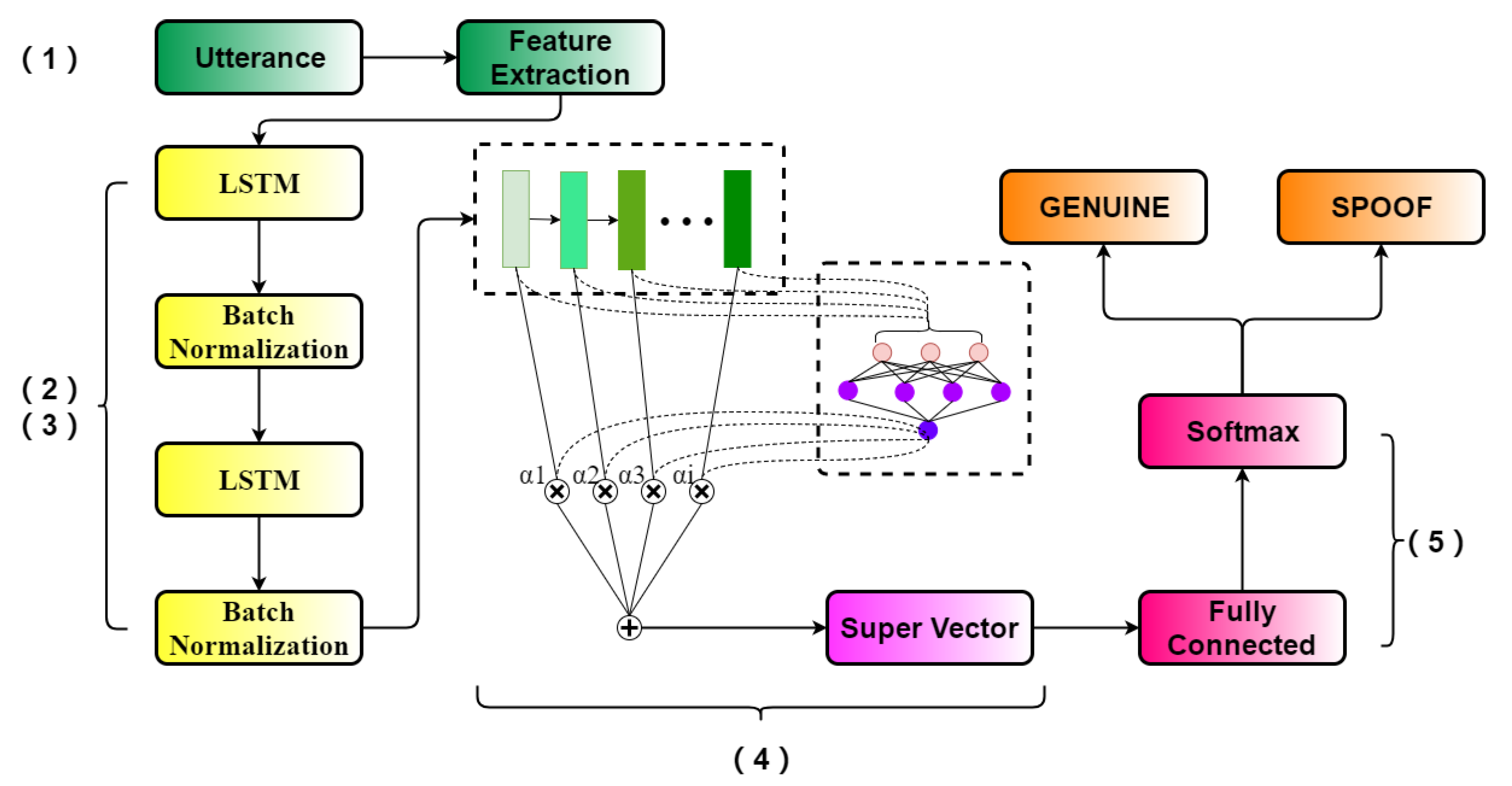
(1) The sequential nature of speech motivated us to choose long short-term memory (LSTM) to obtain a representation of an utterance. By using LSTM, contextual information can be easily transformed into a vector as input for any back-end classifier.
(2) Considering that different audio frames may contribute differently to the task of replay detection, especially under noisy environments where the frames are contaminated to different degrees by noise, an attention mechanism [
13] was used to perform automatic weighting of the frames.
(3) When programming RNNs, for example with TensorFlow, utterance inputs should be the same length, which is normally done by zero-padding the short inputs in the batch to make their length meet a prefixed constant. The lengths of the utterances vary significantly in the ASVspoof 2017 dataset, where the longest utterance has 1423 frames while the shortest one has only 86 frames. There would be too many zeros in the short utterances if simply zero-padding the short ones, which would make the data distribution severely biased toward the padded utterances. In fact, given our research on RNNs, LSTMs, and gated recurrent units (GRUs), the sequence length of the model performs as a hyper-parameter which impacts the model’s performance. Therefore, it is also worth investigating the impact of the sequence length on the accuracy of replay detection in the ASV spoofing scenario. Hence, the split/padding method was used to obtain a group of speech segments with uniform length, and is presented in
Section 5.2.3. For an input sequence whose length was longer than the prefixed one, splitting was utilized to cut the sequence into smaller sections that met the prefixed length. For an input sequence whose length was shorter than the prefixed one, padding was utilized by repeating the sequence until the prefixed length was reached. In this way, fewer zeros are padded onto the sequences, their segments will have a uniform length, and they are ready to be RNN inputs. The split/padding method is detailed in
Section 5.2.3.
(4) Given the split/padding approach described above, a sequence may be divided into several segments, each of which was analyzed to decide on whether it is a genuine or spoofing utterance. Therefore, for the original whole input sequence, it was easy to use the bagging method in ensemble learning to combine the decisions derived on its individual segments.
Section 5.2.4 explains the bagging method in detail.
The rest of this paper is organized as follows:
Section 4 describes the attention-based LSTM algorithm (AB-LSTM) and the network architecture for replay attack detection, experimental settings and results are presented in
Section 5, and the final section,
Section 6, concludes the paper.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}