A Novel Interactive Fusion Method with Images and Point Clouds for 3D Object Detection


Abstract
:1. Introduction
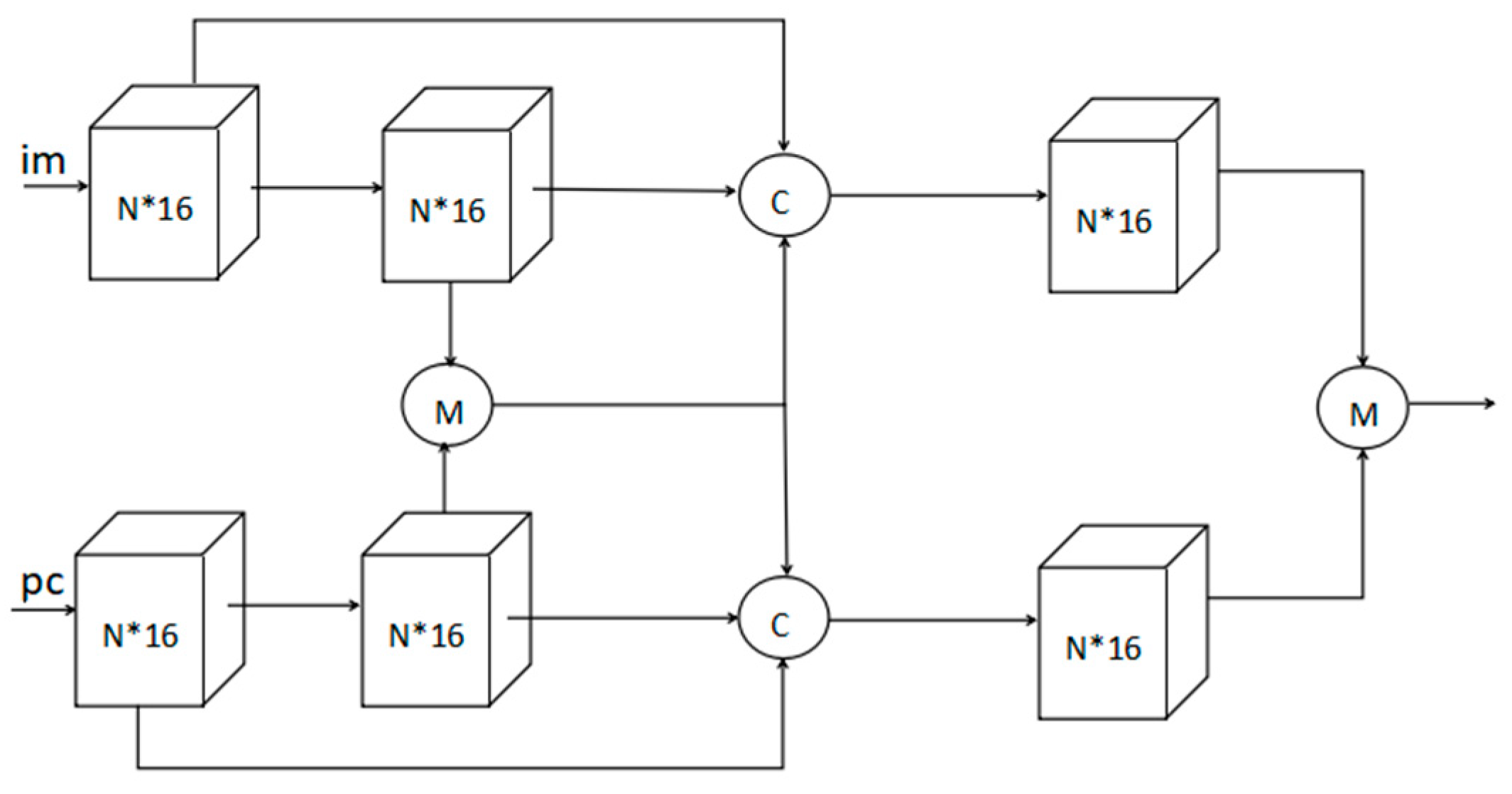
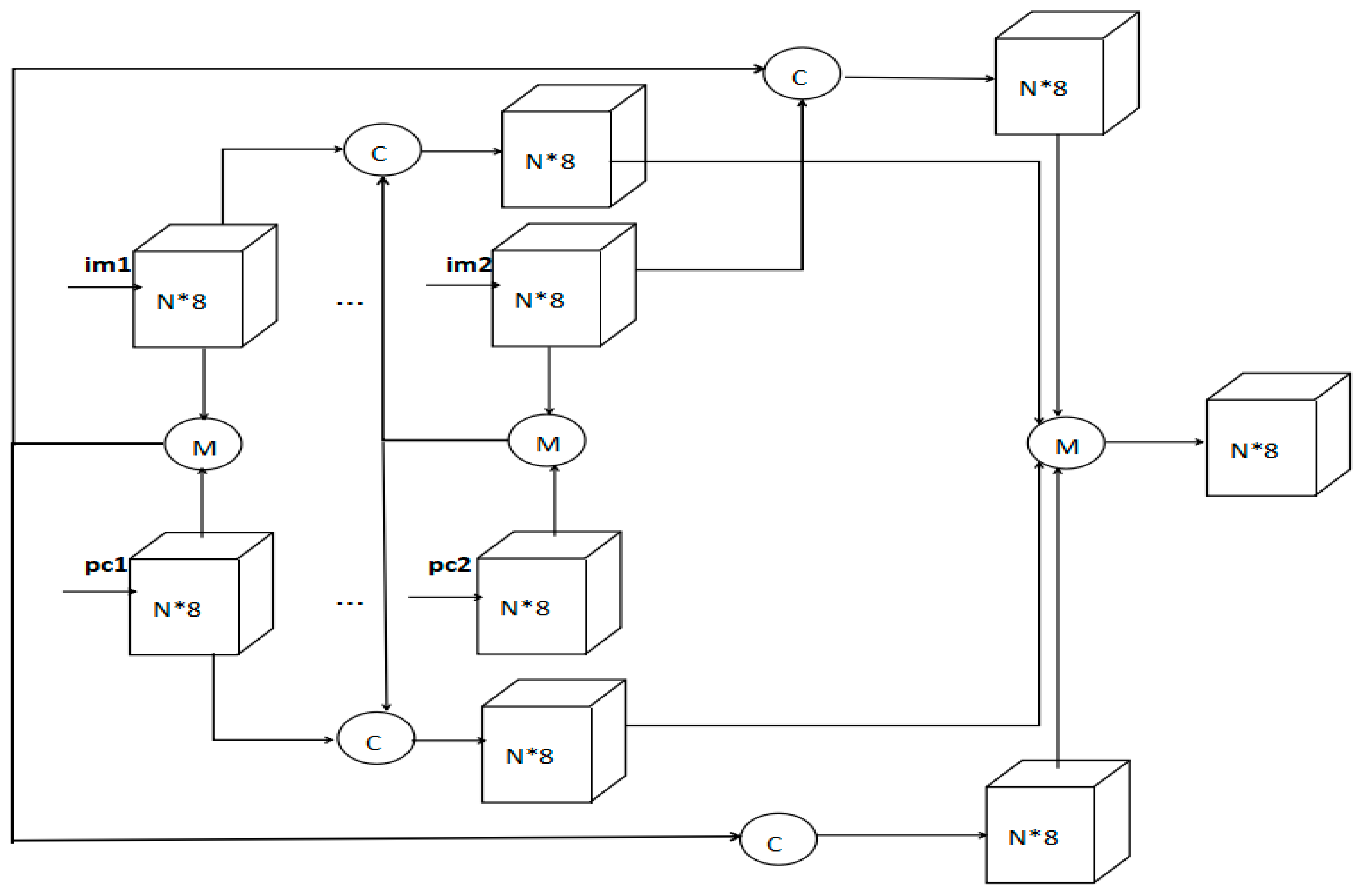
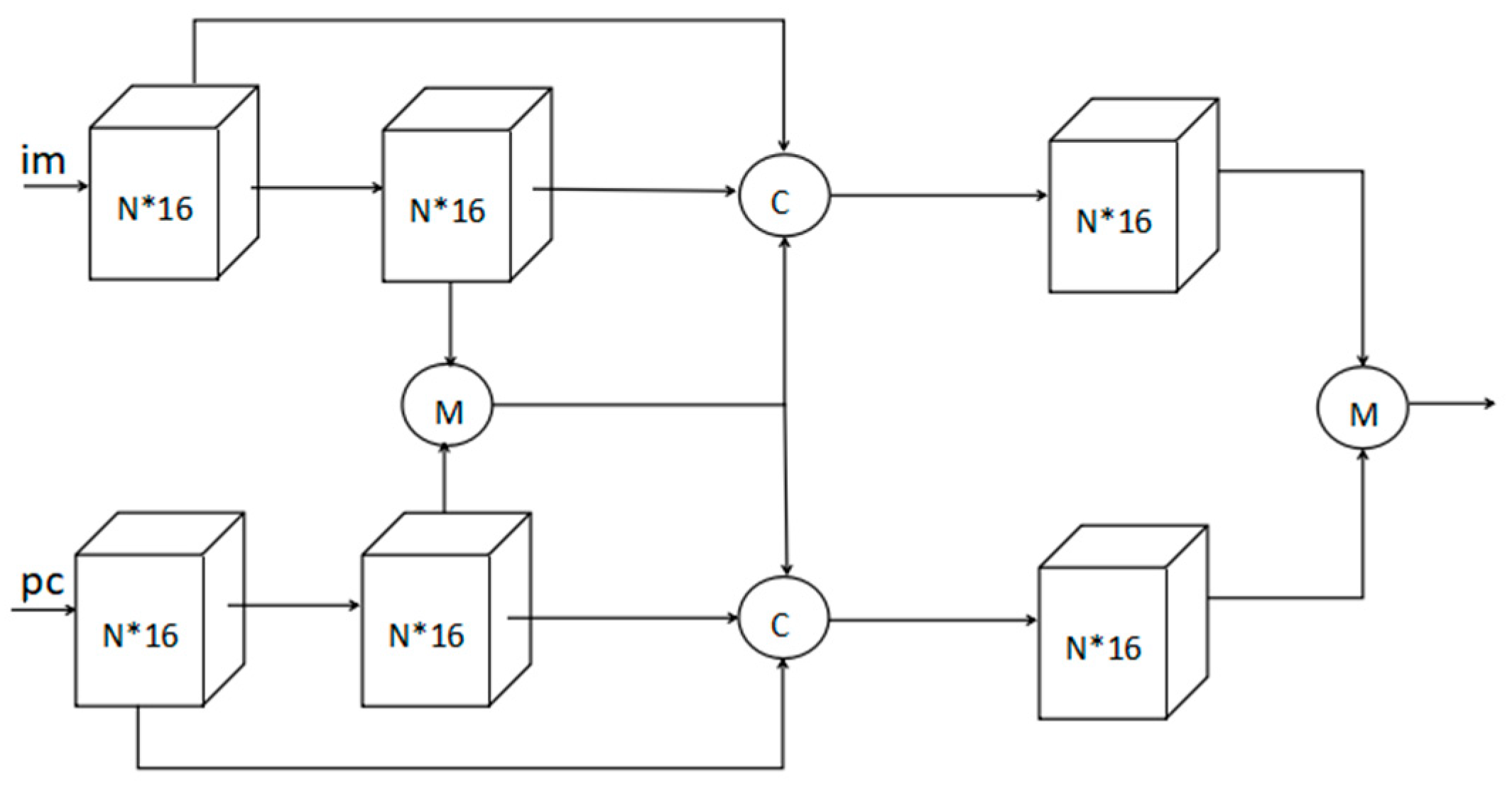
2. Related Work and Proposed Method
3. Experiments
3.1. Kernel Design
3.2. No BatchNorm
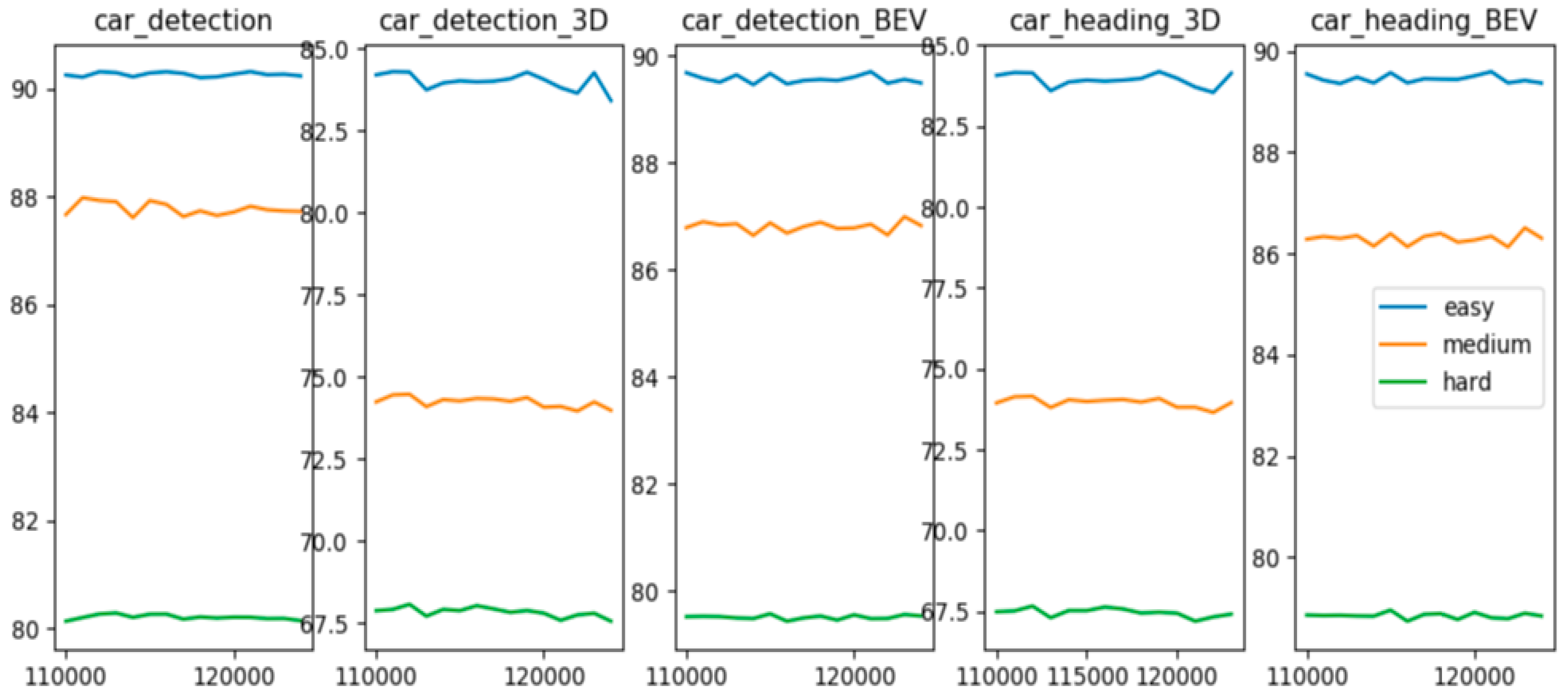
3.3. Trainning Details and Computational Cost
3.4. Architecture Design Analysis
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Macher, H.; Landes, T.; Grussenmeyer, P. From Point Clouds to Building Information Models: 3D Semi-Automatic Reconstruction of Indoors of Existing Buildings. Appl. Sci. 2017, 7, 1030. [Google Scholar] [CrossRef]
- Yang, J.; Li, S.; Gao, Z.; Wang, Z.; Liu, W. Real-Time Recognition Method for 0.8 cm Darning Needles and KR22 Bearings Based on Convolution Neural Networks and Data Increase. Appl. Sci. 2018, 8, 1857. [Google Scholar] [CrossRef]
- Cai, Z.; Fan, Q.; Feris, R.; Vasconcelos, N. A unified multi-scale deep convolutional neural network for fast object detection. In Proceedings of the ECCV, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Kim, T.; Ghosh, J. Robust detection of non-motorized road users using deep learning on optical and lidar data. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 271–276. [Google Scholar]
- Lange, S.; Ulbrich, F.; Goehring, D. Online vehicle detection using deep neural networks and lidar based preselected image patches. In Proceedings of the 2016 IEEE Intelligent Vehicles Symposium (IV), Gothenburg, Sweden, 19–22 June 2016; pp. 954–959. [Google Scholar]
- Cadena, C.; Kosecká, J. Semantic segmentation with heterogeneous sensor coverages. In Proceedings of the ICRA, Hong Kong, China, 31 May–7 June 2014. [Google Scholar]
- Enzweiler, M.; Gavrila, D.M. A multilevel mixture-of-experts framework for pedestrian classification. IEEE Trans. Image Process. 2011, 20, 2967–2979. [Google Scholar] [CrossRef] [PubMed]
- Hoffman, J.; Gupta, S.; Darrell, T. Learning with side information through modality hallucination. In Proceedings of the CVPR, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Song, S.; Xiao, J. Deep sliding shapes for amodal 3D object detection in RGB-D images. In Proceedings of the CVPR, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Zhang, R.; Candra, S.A.; Vetter, K. Sensor Fusion for Semantic Segmentation of Urban Scenes. In Proceedings of the IEEE International Conference on Robotics & Automation, Seattle, WA, USA, 26–30 May 2015. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3D object detection network for autonomous driving. In Proceedings of the IEEE CVPR, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Larsson, G.; Maire, M.; Shakhnarovich, G. Fractalnet: Ultra-deep neural networks without residuals. arXiv, 2016; arXiv:1605.07648. [Google Scholar]
- Wang, J.; Wei, Z.; Zhang, T.; Zeng, W. Deeply-fused nets. arXiv, 2016; arXiv:1605.07716. [Google Scholar]
- Tang, C.; Ling, Y.; Yang, X.; Jin, W.; Zhang, C. Multi-View Object Detection Based on Deep Learning. Appl. Sci. 2018, 8, 1423. [Google Scholar] [CrossRef]
- Kitti 3D Object Detection Benchmark Leader Board. Available online: http://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d (accessed on 14 November 2017).
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S. Joint 3D Proposal Generation and Object Detection from View Aggregation. arXiv, 2017; arXiv:1712.02294v3. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the AISTATS, Fort Lauderdale, FL, USA, 11–13 April 2011. [Google Scholar]
- Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. arXiv, 2014; arXiv:1409.4842v1. [Google Scholar]



{kind=link}
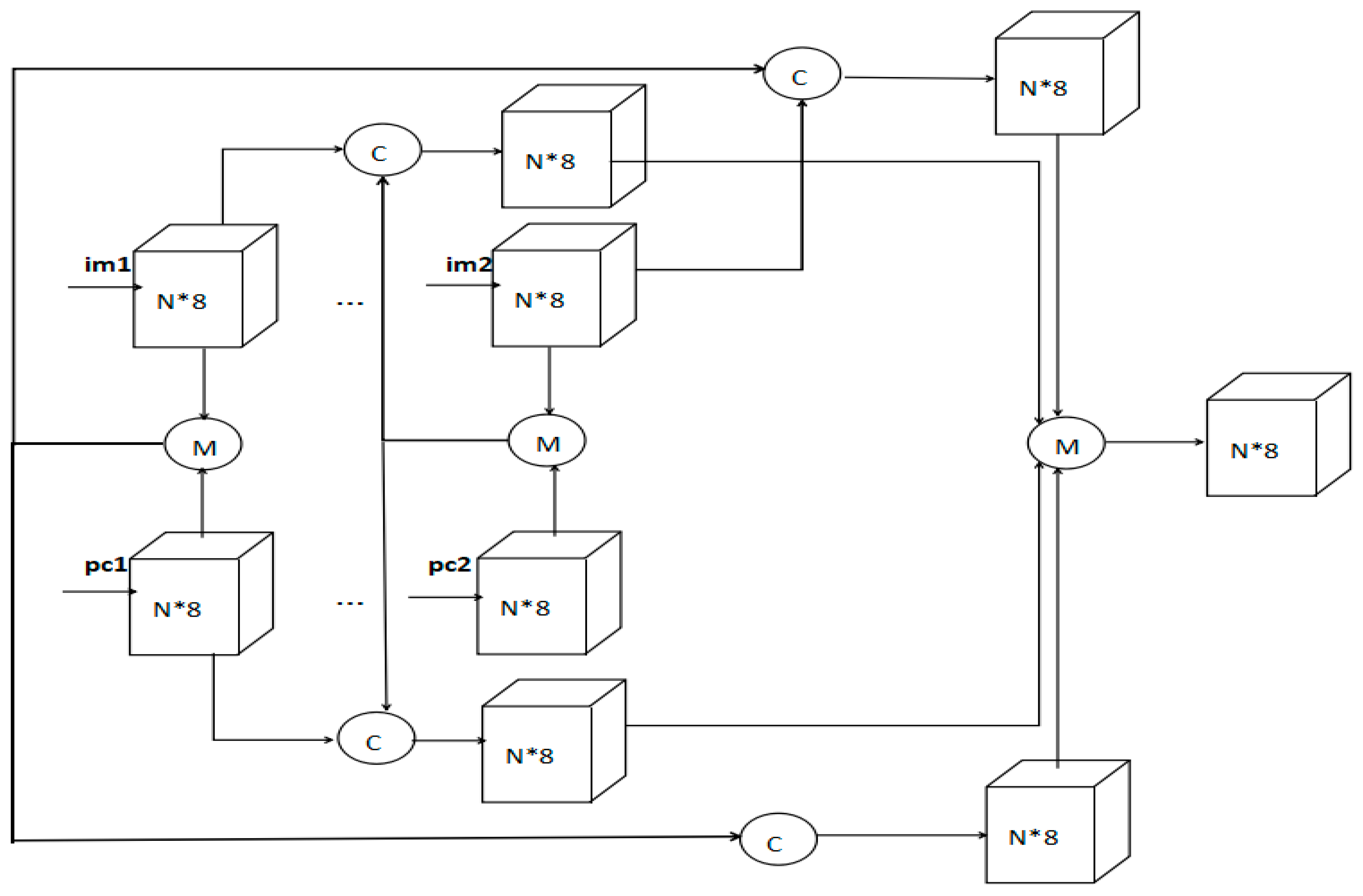{kind=link}
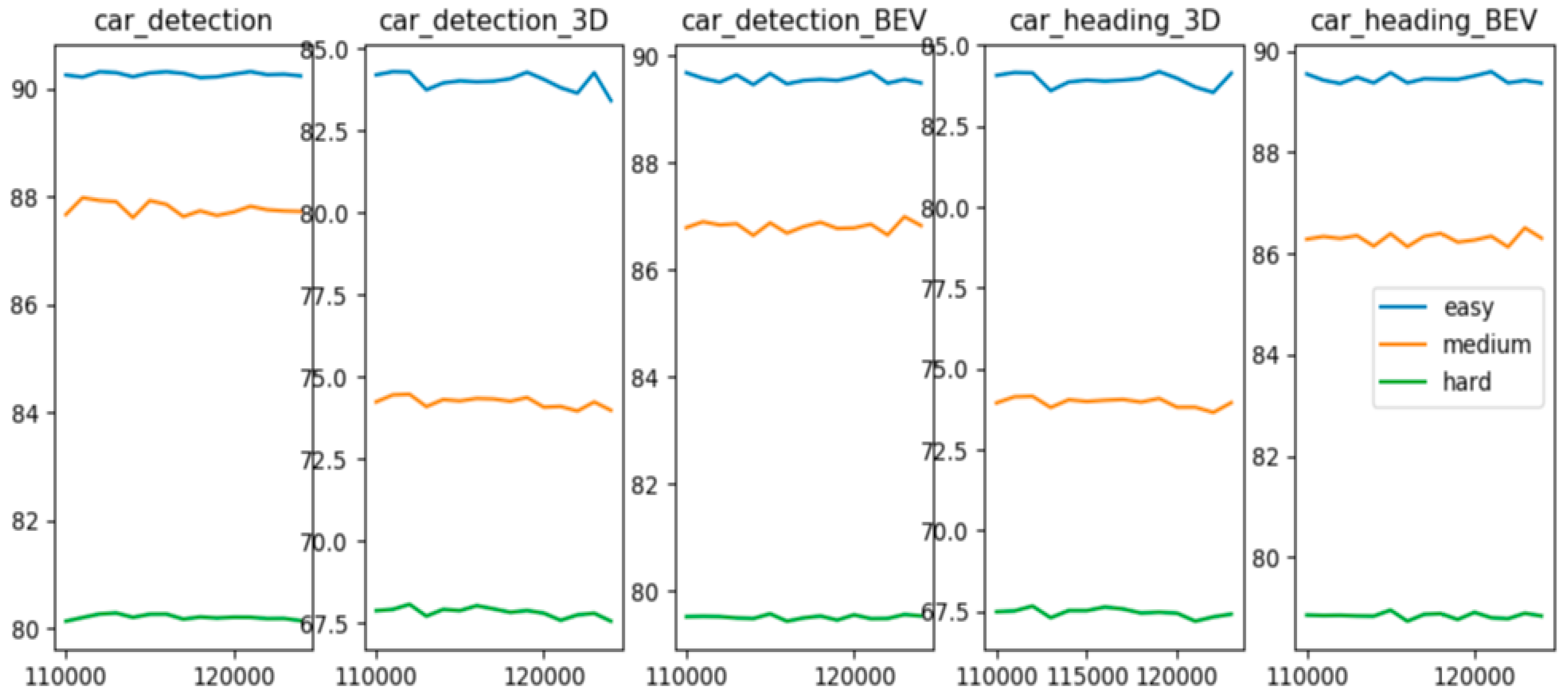{kind=link}
{kind=link}
{kind=link}
| Easy | Moderate | Hard | ||||
|---|---|---|---|---|---|---|
| AP | AHS | AP | AHS | AP | AHS | |
| MV3D [11] | 83.87 | 52.74 | 72.35 | 43.75 | 64.56 | 39.86 |
| AVOD [16] | 83.08 | 82.96 | 73.62 | 73.37 | 67.55 | 67.24 |
| ours | 84.16 | 84.05 | 74.45 | 74.13 | 67.80 | 67.40 |
| Easy | Moderate | Hard | ||||
|---|---|---|---|---|---|---|
| AP | AHS | AP | AHS | AP | AHS | |
| MV3D [11] | 83.87 | 52.74 | 72.35 | 43.75 | 64.56 | 39.86 |
| AVOD [16] | 83.08 | 82.96 | 73.62 | 73.37 | 67.55 | 67.24 |
| ours | 84.62 | 84.41 | 74.88 | 74.45 | 68.30 | 67.79 |
| Easy | Moderate | Hard | ||||
|---|---|---|---|---|---|---|
| AP | AHS | AP | AHS | AP | AHS | |
| baseline1 | 83.02 | 82.84 | 73.71 | 73.13 | 67.79 | 67.15 |
| baseline2 | 84.02 | 83.84 | 74.42 | 74.03 | 68.16 | 67.74 |
| ours | 84.62 | 84.41 | 74.88 | 74.45 | 68.30 | 67.79 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, K.; Yang, Z.; Xu, Y.; Feng, L. A Novel Interactive Fusion Method with Images and Point Clouds for 3D Object Detection. Appl. Sci. 2019, 9, 1065. https://doi.org/10.3390/app9061065
Xu K, Yang Z, Xu Y, Feng L. A Novel Interactive Fusion Method with Images and Point Clouds for 3D Object Detection. Applied Sciences. 2019; 9(6):1065. https://doi.org/10.3390/app9061065
Chicago/Turabian StyleXu, Kai, Zhile Yang, Yangjie Xu, and Liangbing Feng. 2019. "A Novel Interactive Fusion Method with Images and Point Clouds for 3D Object Detection" Applied Sciences 9, no. 6: 1065. https://doi.org/10.3390/app9061065
APA StyleXu, K., Yang, Z., Xu, Y., & Feng, L. (2019). A Novel Interactive Fusion Method with Images and Point Clouds for 3D Object Detection. Applied Sciences, 9(6), 1065. https://doi.org/10.3390/app9061065