Deep Reinforcement Learning for Query-Conditioned Video Summarization

Abstract
:1. Introduction
2. Related Work
2.1. Video Summarization Using Reinforcement Learning
2.2. Query-Conditioned Video Summarization
3. Our Approach
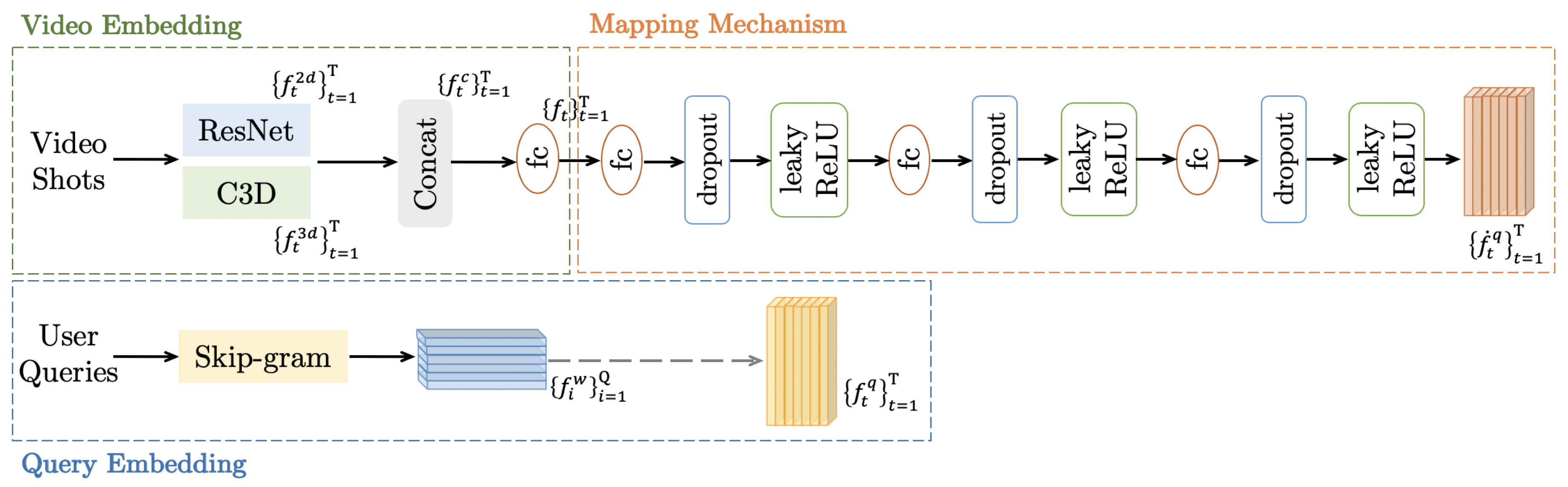
3.1. Mapping Network
3.1.1. Video Embedding
3.1.2. Query Embedding
3.1.3. Mapping Mechanism
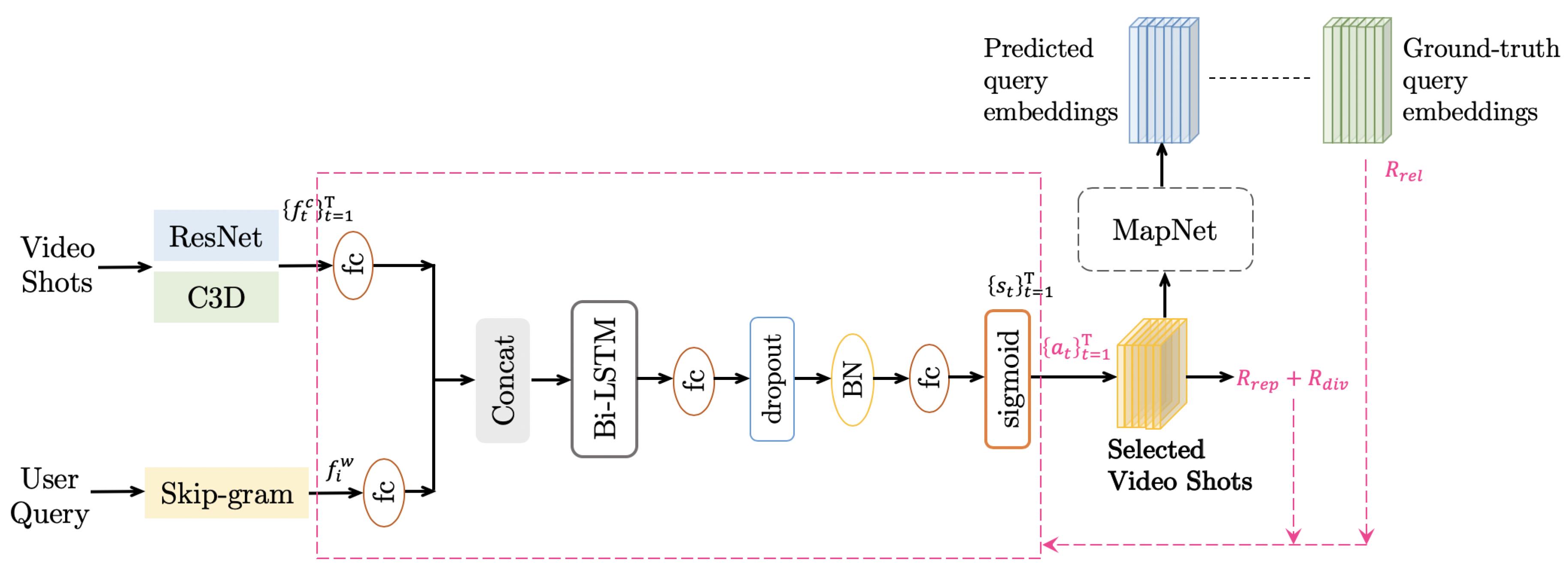
3.2. Summarization Network
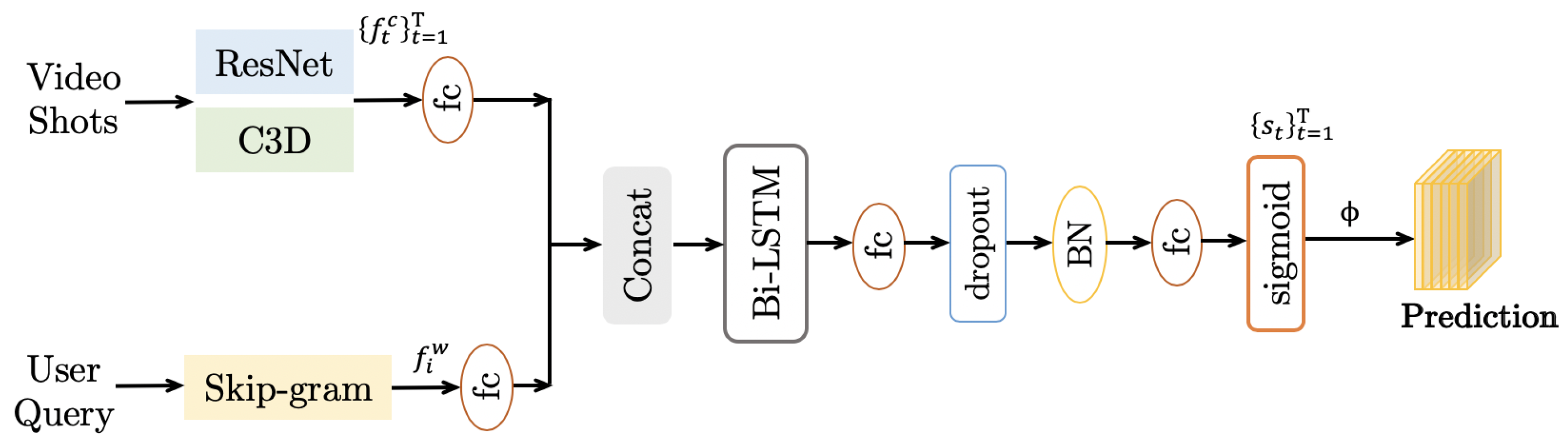
3.2.1. Importance Scores Prediction
3.2.2. Video Summary Prediction
3.2.3. Relatedness Reward Using MapNet
3.2.4. Diversity and Representativeness Rewards
3.3. Policy Gradient Descend
3.4. Video Summarization Inference
4. Experiments
4.1. Experimental Settings
4.1.1. Videos
4.1.2. Evaluation Metrics
4.1.3. Implementation Details
4.2. Comparisons to the State-of-the-Art Methods
4.3. Ablation Analysis
4.3.1. The Effect of the Proposed Mapping Mechanism
4.3.2. The Effect of Ground-Truth Regularization
4.3.3. The Effect of Rewards
4.3.4. The Effect of Representativeness+Diversity Rewards
4.4. Qualitative Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cisco, V. Cisco Visual Networking Index: Forecast and Methodology 2016–2021. 2017. Available online: https://www.cisco.com/ (accessed on 15 February 2019).
- Kanehira, A.; Gool, L.V.; Ushiku, Y.; Harada, T. Viewpoint-aware video summarization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7435–7444. [Google Scholar]
- Zhang, K.; Grauman, K.; Sha, F. Retrospective encoders for video summarization. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 383–399. [Google Scholar]
- Sharghi, A.; Borji, A.; Li, C.; Yang, T.; Gong, B. Improving sequential determinantal point processes for supervised video summarization. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 517–533. [Google Scholar]
- Panda, R.; Roy-Chowdhury, A.K. Collaborative summarization of topic-related videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7083–7092. [Google Scholar]
- Mahasseni, B.; Lam, M.; Todorovic, S. Unsupervised video summarization with adversarial lstm networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 202–211. [Google Scholar]
- Amato, F.; Castiglione, A.; Moscato, V.; Picariello, A.; Sperlì, G. Multimedia summarization using social media content. Multimed. Tools Appl. 2018, 77, 17803–17827. [Google Scholar] [CrossRef]
- Zhu, L.; Xu, Z.; Yang, Y.; Hauptmann, A.G. Uncovering the temporal context for video question answering. Int. J. Comput. Vis. 2017, 124, 409–421. [Google Scholar] [CrossRef]
- Kalashnikov, D.; Irpan, A.; Pastor, P.; Ibarz, J.; Herzog, A.; Jang, E.; Quillen, D.; Holly, E.; Kalakrishnan, M.; Vanhoucke, V.; et al. Qt-opt: Scalable deep reinforcement learning for vision-based robotic manipulation. arXiv, 2018; arXiv:1806.10293. [Google Scholar]
- Feng, W.; Ji, D.; Wang, Y.; Chang, S.; Ren, H.; Gan, W. Challenges on large scale surveillance video analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshop on the AI City Challenge, Salt Lake City, UT, USA, 18–22 June 2018; pp. 69–76. [Google Scholar]
- Wang, M.; Hong, R.; Li, G.; Zha, Z.J.; Yan, S.; Chua, T.S. Event driven web video summarization by tag localization and key-shot identification. IEEE Trans. Multimed. 2012, 14, 975–985. [Google Scholar] [CrossRef]
- Sharghi, A.; Gong, B.; Shah, M. Query-focused extractive video summarization. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 3–19. [Google Scholar]
- Sharghi, A.; Laurel, J.S.; Gong, B. Query-focused video summarization: dataset, evaluation, and a memory network based approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4788–4797. [Google Scholar]
- Vasudevan, A.B.; Gygli, M.; Volokitin, A.; Van Gool, L. Query-adaptive video summarization via quality-aware relevance estimation. In Proceedings of the ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 582–590. [Google Scholar]
- Ji, Z.; Ma, Y.; Pang, Y.; Li, X. Query-aware sparse coding for multi-video summarization. arXiv, 2017; arXiv:1707.04021. [Google Scholar] [CrossRef]
- Xiong, B.; Kim, G.; Sigal, L. Storyline representation of egocentric videos with an applications to story-based search. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015; pp. 4525–4533. [Google Scholar]
- Varini, P.; Serra, G.; Cucchiara, R. Personalized egocentric video summarization for cultural experience. In Proceedings of the 5th ACM on International Conference on Multimedia Retrieval, Shanghai, China, 23–26 June 2015; pp. 539–542. [Google Scholar]
- Varini, P.; Serra, G.; Cucchiara, R. Personalized egocentric video summarization of cultural tour on user preferences input. IEEE Trans. Multimed. 2017, 19, 2832–2845. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1928–1937. [Google Scholar]
- Salimans, T.; Ho, J.; Chen, X.; Sidor, S.; Sutskever, I. Evolution strategies as a scalable alternative to reinforcement learning. arXiv, 2017; arXiv:1703.03864. [Google Scholar]
- Song, G.; Myeong, H.; Mu Lee, K. SeedNet: Automatic seed generation with deep reinforcement learning for robust interactive segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1760–1768. [Google Scholar]
- Wang, X.; Chen, W.; Wu, J.; Wang, Y.F.; Yang Wang, W. Video captioning via hierarchical reinforcement learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4213–4222. [Google Scholar]
- Tang, Y.; Tian, Y.; Lu, J.; Li, P.; Zhou, J. Deep progressive reinforcement learning for skeleton-based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5323–5332. [Google Scholar]
- Zhou, K.; Qiao, Y. Deep reinforcement learning for unsupervised video summarization with diversity-representativeness reward. arXiv, 2017; arXiv:1801.00054. [Google Scholar]
- Lei, J.; Luan, Q.; Song, X.; Liu, X.; Tao, D.; Song, M. Action parsing driven video summarization based on reinforcement learning. IEEE Trans. Circ. Syst. Video Technol. 2018. [Google Scholar] [CrossRef]
- Zhou, K.; Xiang, T.; Cavallaro, A. Video summarisation by classification with deep reinforcement learning. arXiv, 2018; arXiv:1807.03089. [Google Scholar]
- Li, Y.; Wang, L.; Yang, T.; Gong, B. How local is the local diversity? Reinforcing sequential determinantal point processes with dynamic ground sets for supervised video summarization. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 151–167. [Google Scholar]
- Masumitsu, K.; Echigo, T. Video summarization using reinforcement learning in eigenspace. In Proceedings of the IEEE International Conference on Image Processing, Vancouver, BC, Canada, 10–13 September 2000; Volume 2, pp. 267–270. [Google Scholar]
- Gong, B.; Chao, W.L.; Grauman, K.; Sha, F. Diverse Sequential subset selection for supervised video summarization. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2069–2077. [Google Scholar]
- Lan, S.; Panda, R.; Zhu, Q.; Roy-Chowdhury, A.K. FFNet: Video fast-forwarding via reinforcement learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6771–6780. [Google Scholar]
- Oosterhuis, H.; Ravi, S.; Bendersky, M. Semantic video trailers. arXiv, 2016; arXiv:1609.01819. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Kulesza, A.; Taskar, B. Determinantal point processes for machine learning. Found. Trends® Mach. Learn. 2012, 5, 123–286. [Google Scholar] [CrossRef]
- Zhang, Y.; Kampffmeyer, M.; Liang, X.; Tan, M.; Xing, E.P. Query-conditioned three-player adversarial network for video summarization. arXiv, 2018; arXiv:1807.06677. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein gan. arXiv, 2017; arXiv:1701.07875. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas Valley, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput.Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4489–4497. [Google Scholar]
- Graves, A.; Mohamed, A.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Gygli, M.; Grabner, H.; Van Gool, L. Video summarization by learning submodular mixtures of objectives. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3090–3098. [Google Scholar]
- Lee, Y.J.; Ghosh, J.; Grauman, K. Discovering important people and objects for egocentric video summarization. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Providence, Rhode Island, 16–21 June 2012; pp. 1346–1353. [Google Scholar]
- Yeung, S.; Fathi, A.; Li, F.-F. Videoset: Video summary evaluation through text. arXiv, 2014; arXiv:1406.5824. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in pytorch. In Proceedings of the Advances in Neural Information Processing Systems Workshop, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SeqDPP [30] | SH-DPP [12] | QC-DPP [13] | QueryGAN [36] | Ours | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pre | Rec | F | Pre | Rec | F | Pre | Rec | F | Pre | Rec | F | Pre | Rec | F | |
| Video1 | 53.43 | 29.81 | 36.59 | 50.56 | 29.64 | 35.67 | 49.86 | 53.38 | 48.68 | 49.66 | 50.91 | 48.74 | 50.81 | 51.57 | 48.77 |
| Video2 | 44.05 | 46.65 | 43.67 | 42.13 | 46.81 | 42.72 | 33.71 | 62.09 | 41.66 | 43.02 | 48.73 | 45.30 | 39.99 | 58.51 | 46.65 |
| Video3 | 49.25 | 17.44 | 25.26 | 51.92 | 29.24 | 36.51 | 55.16 | 62.40 | 56.47 | 58.73 | 56.49 | 56.51 | 63.48 | 54.91 | 57.01 |
| Video4 | 11.14 | 63.49 | 18.15 | 11.51 | 62.88 | 18.62 | 21.39 | 63.12 | 29.96 | 36.70 | 35.96 | 33.64 | 39.03 | 38.37 | 36.37 |
| Avg. | 39.47 | 39.35 | 30.92 | 39.03 | 42.14 | 33.38 | 40.03 | 60.25 | 44.19 | 47.03 | 48.02 | 46.05 | 48.33 | 50.84 | 47.20 |
| W/O MapNet | W/O | Ours | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Pre | Rec | F | Pre | Rec | F | Pre | Rec | F | |
| Video1 | 49.88 | 44.26 | 43.37 | 30.45 | 64.36 | 40.20 | 50.81 | 51.57 | 48.77 |
| Video2 | 44.17 | 45.49 | 43.54 | 42.01 | 37.78 | 39.50 | 39.99 | 58.51 | 46.65 |
| Video3 | 61.89 | 52.95 | 55.45 | 39.72 | 74.92 | 51.63 | 63.48 | 54.91 | 57.01 |
| Video4 | 28.19 | 48.13 | 33.28 | 36.28 | 29.40 | 32.12 | 39.03 | 38.37 | 36.37 |
| Avg. | 46.03 | 47.71 | 43.91 | 37.12 | 51.62 | 40.86 | 48.33 | 50.84 | 47.20 |
| W/O Rewards | W/O Rep+Div Rewards | Ours | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Pre | Rec | F | Pre | Rec | F | Pre | Rec | F | |
| Video1 | 58.49 | 35.23 | 42.07 | 39.89 | 60.67 | 46.18 | 50.81 | 51.57 | 48.77 |
| Video2 | 33.88 | 59.23 | 42.38 | 37.17 | 57.83 | 44.61 | 39.99 | 58.51 | 46.65 |
| Video3 | 43.51 | 63.06 | 50.83 | 46.86 | 71.73 | 56.03 | 63.48 | 54.91 | 57.01 |
| Video4 | 24.90 | 49.82 | 32.73 | 39.91 | 31.27 | 31.71 | 39.03 | 38.37 | 36.37 |
| Avg. | 40.20 | 51.84 | 42.00 | 40.96 | 55.38 | 44.63 | 48.33 | 50.84 | 47.20 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Kampffmeyer, M.; Zhao, X.; Tan, M. Deep Reinforcement Learning for Query-Conditioned Video Summarization. Appl. Sci. 2019, 9, 750. https://doi.org/10.3390/app9040750
Zhang Y, Kampffmeyer M, Zhao X, Tan M. Deep Reinforcement Learning for Query-Conditioned Video Summarization. Applied Sciences. 2019; 9(4):750. https://doi.org/10.3390/app9040750
Chicago/Turabian StyleZhang, Yujia, Michael Kampffmeyer, Xiaoguang Zhao, and Min Tan. 2019. "Deep Reinforcement Learning for Query-Conditioned Video Summarization" Applied Sciences 9, no. 4: 750. https://doi.org/10.3390/app9040750
APA StyleZhang, Y., Kampffmeyer, M., Zhao, X., & Tan, M. (2019). Deep Reinforcement Learning for Query-Conditioned Video Summarization. Applied Sciences, 9(4), 750. https://doi.org/10.3390/app9040750