1. Introduction
With the rapid development of information technology, all walks of life have been generating a large amount of data. Therefore, it is of great significance to promote the development and progress of various industries by mining useful knowledge and information from text data and applying them to information retrieval and data analysis. Text classification is a technology that can effectively organize and manage texts, and facilitate users to quickly obtain useful information, thus becomes an important research direction in the field of information processing.
Text classification refers to a text divided into one or multiple predefined categories according to the content of text data, including single-label text classification and multi-label text classification. In single-label text classification, a text is associated with one predefined topic and only divided into one category [
1,
2,
3]. However, in multi-label text classification, a text is associated with multiple predefined topics and divided into multiple categories [
4,
5,
6]. For example, a news report about a movie may be associated with the topics of “movie”, “music”, and others. Also, an article about computers may be associated with the topics of “computers”, “software engineering”, and others. In the real world, it is very common for a text to be associated with multiple topics, so it is more practical to study multi-label text classification.
Feature selection is an important part of multi-label text classification. Text data is unstructured data, consisting of words. The vector space model is often used to represent text data for facilitating computer processing. In this method, all the terms in all the texts are used as features to construct the feature space which is called the original feature space. Since a text may consist of thousands of different terms, the original feature space is high-dimensional and sparse. If the original feature space is directly used for text classification, it will be time-consuming and over-fitting. Therefore, reducing the dimension of the original feature space is of significant importance. Feature selection is a commonly used dimensionality reduction technology. It removes useless and redundant features, and only keeps the features with strong category discrimination ability to construct the feature subset, realizing the reduction of feature space dimension and the improvement of classification performance [
7,
8]. We study the feature selection method for multi-label text in this paper.
Currently, there are some researches on feature selection for multi-label data, which can be divided into three categories: wrapped methods, embedded methods, and filter methods. In wrapped methods, several different feature subsets are constructed in advance, the pros and cons of the feature subsets are then evaluated by the predictive precision of the classification algorithm, and the final feature subset is determined based on the evaluation [
9,
10,
11,
12,
13]. In embedded methods, the feature selection process is integrated into the classification model training process, that is, features with high contribution to model training are selected to construct the feature subset in the process of classification model construction [
14,
15,
16]. In filter methods, the classification contribution of each feature is calculated as its feature importance, and features with higher importance are selected to construct the feature subset [
17,
18,
19,
20]. Based on this selected feature subset, the training of the classification model is performed. Therefore, this type of feature selection methods has low computational complexity and high operational efficiency, and is very suitable for text data [
21].
In filter methods, the core is how to calculate the feature importance. At present, the commonly used feature importance calculation method is to count the frequency of features in the whole training set. However, the selected features using this method do not necessarily have strong category discrimination ability. For example, the feature “people” appears frequently in the whole training set, so the importance of “people” is very high, calculated by the method of counting its frequency in the whole training set. However, such a feature may appear similar times in each category of the training set, and doesn’t have category discrimination ability indeed. The category discrimination ability of features is an ability to distinguish one category from others. Therefore, the importance of features should be calculated from the perspective of the category discrimination ability. Features with strong category discrimination ability have high correlation with one category and low correlation with others. To the best of our knowledge, there are some researches on the calculation of feature importance based on the two aspects [
22,
23]. They consider one aspect or two aspects abovementioned, design the feature importance calculation formula, and apply it to single-label text classification. In this paper, on the basis of these researches, the contributions of features to category discrimination are redefined from the above two aspects, and the importance of the features is obtained with the combination of them.
A filter feature selection method for multi-label text is proposed in the paper. Firstly, multi-label texts are transformed into single-label texts using the label assignment method. Secondly, the importance of each feature is calculated using the proposed method of Category Contribution (CC). Finally, features with higher importance are selected to construct the feature space. Thus, the contributions of this paper can be summarized as follows.
- (1)
The importance of features for classification is analyzed from two aspects of inter-category and intra-category, and then the formulas for calculating inter-category contribution and intra- category contribution are proposed.
- (2)
A formula for calculating feature importance based on CC is proposed.
- (3)
The proposed feature selection method is combined with Binary Relevance k-Nearest Neighbor (BRKNN) [
24] and Multi-label k-Nearest Neighbor (MLKNN) [
25] algorithms, achieving a good classification performance.
The rest of this paper is organized as follows.
Section 2 describes some related works.
Section 3 introduces the details of the proposed method. Experimental results are shown in
Section 4. Finally,
Section 5 concludes the findings shown in this paper.
2. Related Works
The purpose of feature selection is to reduce the dimension of the feature space and improve the efficiency and performance of the classification through removing irrelevant and redundant features. The filter feature selection methods are viewed as a pure pre-processing tool and have low computational complexity. As a result, there are many scholars focusing on the research of this type of methods. For multi-label data, there are two main research ideas in filter feature selection methods.
One method is the feature selection method based on the idea of algorithm adaptation. In this type of methods, the feature importance calculation methods commonly used in single-label feature selection are adapted to be suitable for multi-label data, then the feature selection for multi-label data is performed on them [
18,
19,
20,
26,
27]. Lee et al. [
18] proposed a filter multi-label feature selection method by adapting mutual information. This method was evaluated on multi-label data sets of various fields, including text. Lin et al. [
20] proposed a method named max-dependency and min-redundancy, which considers two factors of multi-label feature, feature dependency, and feature redundancy. Three text data sets, Artificial, Health, and Recreation were used to evaluate the method. Lastra et al. [
26] extended the technique fast correlation-based filter [
28] to deal with multi-label data directly. Text data sets were also used in his experiments. In this type of methods, multi-label data is directly processed for feature selection, so the computational complexity is very high when there are many categories in the data set.
The other is the feature selection method based on the idea of problem transformation. In this type of methods, multi-label data is transformed into single-label data, then the feature selection is performed on single-label data [
17,
29,
30,
31,
32,
33,
34]. Since a piece of multi-label data belongs to multiple categories, the single-label feature importance calculation methods can’t directly deal with it. A simple transformation technique is used to convert a piece of multi-label data into a single-label one, selecting just one label for each sample from its multi-label subset. This label can be the most frequent label in the data set (select-max), the least frequent label (select-min), or a random label (select-random). Xu et al. [
17] designed a transformation method based on the definition of ranking loss for multi-label feature selection and tested it on four text data sets. Chen et al. [
29] proposed a transformation method based on entropy and made the application of traditional feature selection techniques to the multi-label text classification problem. Spolaôr et al. [
31] proposed four multi-label feature selection methods by combining two transformation methods and two feature importance calculation methods, and verified them on data sets of various fields, including the field of text. Lin et al. [
34] focused on the feature importance calculation method based on mutual information and presented a multi-label feature selection method. Five text data sets were used to evaluate the proposed method. In this type of methods, feature selection is performed on single-label data, which reduces the complexity of feature importance calculation and is very suitable for text feature space. The transformation technique and feature importance calculation method are the two key technologies in this type of multi-label feature selection methods. As a result, the label assignment methods, which are a type of commonly used transformation techniques, and some feature importance calculation methods are briefly introduced in the following.
2.1. Label Assignment Methods
Label assignment methods are used to transform multi-label data into single-label data. The commonly used label assignment methods include All Label Assignment (ALA), No Label Assignment (NLA), Largest Label Assignment (LLA), and Smallest Label Assignment (SLA) [
29]. In order to describe these methods conveniently, we define the following variables:
d denotes a piece of data in the multi-label data set and {
C1,
C2,...,
Cn} denotes the set of categories to which
d belongs.
2.1.1. All Label Assignment (ALA)
In the ALA method, a piece of multi-label data is assigned to multiple categories to which it belongs, that is, a copy of the multi-label data exists in multiple categories to which it belongs. ALA aims to keep as much as category information as possible on each category by generating multiple copy data. Meanwhile it may introduce multi-label noise, which could affect the classification performance. The results of
d transformed into
n pieces of single-label data using ALA are as follows.
where
d1 is a copy of
d existing in category
C1.
2.1.2. No Label Assignment (NLA)
In the NLA method, all multi-label data is regarded as noised data, and only single-label data in the original data set is kept. NLA can get rid of the noise by only introducing single-label data, but it may lose some useful information because the multi-label data is discarded. Thus, it is suitable for the data sets with more single-label data and less multi-label data. The transformation processing of
d using NLA can be described as follows.
where
n is the number of categories to which
d belongs.
2.1.3. Largest Label Assignment (LLA)
In the LLA method, the multi-label data belongs to the category with the largest size. Assuming that |
Ck| is the number of samples in category
Ck, then |
Ck| is called the size of the category
Ck. LLA is based on the assumption that the data with larger categories has higher anti-noise ability than those with smaller categories. Let
Cmax denote the category with the largest size, which can be described as follows.
The result of
d transformed into single-label data using LLA is as follows.
2.1.4. Smallest Label Assignment (SLA)
In the SLA method, the multi-label data belongs to the category with the smallest size. SLA assumes that the categories with smaller sizes need more training data in order to make the data as balance as possible. Let
Cmin denote the category with the smallest size, which can be described as follows.
The result of
d transformed into single-label data using SLA is as follows.
2.2. Feature Importance Calculation Methods
Feature importance, also named feature category discrimination ability, refers to the contribution of features to classification. Adapting an appropriate feature importance method to accurately calculate the contribution of each feature to the classification and selecting features with higher importance to construct the feature space are very important to classification performance. The commonly used methods for calculating the importance of features are document frequency (DF) [
35], mutual information (MI) [
36], and information gain (IG) [
35].
In order to describe these methods conveniently, we define the following variables: Fj denotes a feature, N denotes the total number of samples in the training set, A denotes the number of samples with Fj in category k, B denotes the number of samples with Fj in categories except category k, C denotes the number of samples without Fj in category k, D denotes the number of samples without Fj in categories except category k and q is the number of categories.
2.2.1. Importance Calculation Method Based on DF
DF refers to the number of samples in which the feature appears in the training set. In this method, features with higher DF will be selected to construct the feature space. The DF of
Fj is calculated as follows.
The method based on DF is the simplest feature importance calculation method. It is very suitable for the feature selection of large-scale text data sets because it has a good time performance. However, the correlation between features and categories is not considered in this method, as a result, features with low-frequency but high classification discrimination can’t be selected.
2.2.2. Importance Calculation Method Based on MI
MI is an extended concept of information entropy, which measures the correlation between two random events. It measures the importance of the feature to a category according to whether the feature appears or not. The MI of
Fj for the category
k is as follows.
The MI of
Fj for the whole training set is as follows.
The method based on MI considers the correlation between features and categories, but its formula focuses on giving the features with low-frequency higher importance, which is too biased to low-frequency features.
2.2.3. Importance Calculation Method Based on IG
IG is a feature importance calculation method based on information entropy. It measures the number of bits of information obtained for category prediction by knowing the presence or absence of a feature in a document. The IG of
Fj is calculated as follows.
The method based on IG considers the case where a feature does not occur. When the distribution of the categories and features in the data set is not uniform, the classification effect may be affected.
In this paper, we design a feature importance calculation method from two aspects of inter-category and intra-category, which can effectively select features with strong category discrimination ability and is beneficial to improve the performance of multi-label text classification.
3. Proposed Method
In this paper, a feature importance calculation method based on CC is proposed, and based on this method, a feature selection method for multi-label text is proposed. The process of the feature selection method proposed in this paper is shown in
Figure 1.
The purpose of feature selection is to select features with strong category discrimination ability. Calculating the importance of each feature accurately and selecting features with higher importance to construct the feature space are very important for the classification performance. In this paper, the contribution of features to the classification is considered from two aspects of inter-category and intra-category, and a method of feature importance based on CC is proposed. The main steps of the feature importance method are as follows.
- (1)
The inter-category contribution and intra-category contribution of each feature to each category are calculated respectively.
- (2)
For each feature, the inter-category contribution variance and intra-category contribution variance are calculated respectively based on the inter-category contribution and intra-category contribution to each category calculated in (1).
- (3)
The importance of each feature is calculated by fusing the intra-category contribution variance and the inter-category contribution variance.
3.1. Category Contribution
Category contribution refers to the role that the features play in distinguishing one category from others, including inter-category contribution and intra-category contribution.
3.1.1. Inter-Category Contribution
If a feature appears many times in category a, while rarely appears in other categories, thus, the feature may be closely associated with category a and contributes a lot to distinguish category a. Therefore, we calculate the contribution of a feature to the classification based on the number of samples with the feature in one category and the average number of samples with the feature in other categories. In this method, the contribution is calculated by the occurrence of the feature among different categories, so we call it inter-category contribution.
The information entropy measures the uncertainty between random variables in a quantified form [
37]. In text processing, information entropy can be used to describe the distribution of features in different categories. The distribution of the feature in different categories reflects the contribution of the feature to the classification. Therefore, we introduce the information entropy of the feature into the calculation of inter-category contribution in this paper. The information entropy of the feature
Fj is as follows.
where
TF (
Fj) is the number of samples with
Fj in the training set,
Tf (
Fj,Lk) is the number of samples with
Fj in category
k, and
q is the number of categories.
The more uniformly the feature is distributed in different categories, the greater the information entropy of the feature is, and vice versa. Therefore, the formula for calculating the inter-category contribution of the feature
Fj based on information entropy is as follows.
where
ejk is the inter-category contribution of
Fj to category
k,
Tf (
Fj,Lk) is the number of samples with
Fj in category
k,
H(
Fj) is the information entropy of
Fj and
q is the number of categories.
3.1.2. Intra-Category Contribution
If a feature appears in one sample in category
a, but appears in all samples in category
b, thus, the feature may be a word occasionally appearing in category
a, but a very relevant word to category
b. Therefore, we calculate the contribution of the feature to the classification by the proportion of the number of samples with the feature in the category to the total number of samples in the category. The proportion reflects the degree of correlation between the feature and the category. In this method, the contribution is calculated by the occurrence of the feature in one category, so we call it intra-category contribution.
where
rjk is the intra-category contribution of
Fj to category
k,
Tf (
Fj,Lk) is the number of samples with
Fj in category
k, and
Nk is the total number of samples in category
k.
The intra-category contribution of the feature is a value between 0 and 1, including 0 and 1. The closer the value is to 1, the greater the contribution of the feature to the classification of the category is.
3.2. Feature Importance Calculation Method Based on Category Contribution
Calculating the importance of each feature accurately and selecting features with higher importance to construct the feature space directly determine the performance of classification. In this paper, the contribution of the feature to classification is considered from two aspects of inter-category and intra-category, and a method of feature importance based on CC is proposed.
Let
Ej={
e1j,
e2j,…,
eqj} denote the inter-category contribution set of the feature
Fj in
q categories, and
Rj={
r1j,
r2j,…,
rqj} denote the intra-category contribution set of the feature
Fj in
q categories. When the difference between the data in
Ej is great, the category discrimination ability of
Fj is strong and when the difference between the data in
Rj is great, the category discrimination ability of
Fj is strong too. In this paper, the variance is used to represent the difference between the data in the set. The variance of the data in
Ej and
Rj are called the inter-category contribution variance and intra-category contribution variance respectively. The formulas are as follows.
where
VE(
Fj) is the inter-category contribution variance of
Fj,
VR(
Fj) is the intra-category contribution variance of
Fj,
ejk is the inter-category contribution of
Fj to category
k,
rjk is the intra-category contribution of
Fj to category
k,
is the mean inter-category contribution of
Fj,
is the mean intra-category contribution of
Fj and
q is the number of categories.
The greater the inter-category contribution variance and intra-category contribution variance are, the stronger the category discrimination ability of the feature is. Therefore, it is necessary to consider from the perspective of making the inter-category contribution variance and intra-category contribution variance both greater when defining the formula of feature importance calculation. In the field of information retrieval, F-measure is the harmonic mean of precision and recall, which ensures that both precision and recall get a greater value [
38]. Based on this idea, the formula for feature importance calculation is defined as follows.
where
f (
Fj) is the feature importance of
Fj.
After the importance of each feature is calculated, the features with higher importance are selected based on the predefined dimension, to construct the feature space.
4. Experiment and Results
4.1. Data Sets
In order to demonstrate the effectiveness of the proposed method, we collected six public multi-label text data sets, including the fields of medical, business, computers, entertainment, health, and social [
39,
40], from the Mulan website (
http://mulan.sourceforge.net/datasets.html) for experiments.
For the data set
S, we describe it from five aspects: the number of samples |
S|, the number of features
dim(
S), the number of categories
L(
S), label cardinality
LCard(
S), and label density
LDen(
S). The data set
S is defined as follows.
where
xi is a sample,
Yi is the set of categories of
xi and
p is the number of samples in
S.
Label cardinality, which measures the average number of categories per sample.
Label density, which is the label cardinality normalized by the number of categories.
Details of the experimental data sets are described in
Table 1.
4.2. Evaluation Metrics
The results of the multi-label classification experiments were evaluated by the following five evaluation metrics, which are described in FormulaS (20)–(24) [
41].
In order to describe these formulas conveniently, we define the following variables: denotes a multi-label test set, denotes the category set, denotes the multi-label classifier, denotes the prediction function and denotes the ranking function. Where xi is a sample, Yi is the set of categories of xi, and , and p is the number of samples in S. Also, if , then .
Average precision (
AP), which evaluates the average fraction of categories ranked above a particular category
Ls. The higher the value is, the better the performance is.
Hamming loss (
HL), which evaluates how many times a sample-label pair is misclassified. The smaller the value is, the better the performance is.
where
denotes the symmetric difference between two sets.
One error (
OE), which evaluates how many times the top-ranked category is not in the set of proper categories of the sample. The smaller the value is, the better the performance is.
where for any predicate π, [π] equals 1 if π holds and 0 otherwise.
Coverage (
CV), which evaluates how many steps are needed, on average, to move down the category list in order to cover all the proper categories of the sample. The smaller the value is, the better the performance is.
Ranking loss (
RL), which evaluates the average fraction of category pairs that are not correctly ordered. The smaller the value is, the better the performance is.
where
denotes the complementary set of
in
.
4.3. Experimental Settings
In order to demonstrate the effectiveness of the proposed method, we designed two parts of experiments.
(1) Proposed algorithm validation experiment. This part includes two groups of experiments. In the first group, in different feature space dimensions, the proposed feature selection method is compared with the baseline method which keeps all features to demonstrate the effectiveness of the proposed method. ALA is used to transform multi-label texts into single-label texts, and BRKNN and MLKNN are used as the classifiers. For MLKNN, the number of nearest neighbors and the value of smooth are set as 10 and 1 respectively [
42]. For BRKNN, the number of hidden neurons is set as 20% of the number of features in the feature space, the learning rate is set as 0.05, and the number of iterations for training is set as 100 [
42]. Let
t denote the proportion of the dimension of the feature space to the dimension of the original feature space, this is,
t denotes the proportion of the number of selected features to the number of all features. We run experiments of this group with the value of
t ranging from 10% to 90%, and 10% as an interval. In the second group, the method based on CC proposed in the paper is performed on different label assignment methods to further demonstrate the effectiveness of the proposed method. BRKNN is used as the classifier and the value of
t ranges from 10% to 50%, with 10% as an interval.
(2) Performance comparison experiment. In this part, we compare the performance of the proposed feature selection method with that of the commonly used feature selection methods to demonstrate the effectiveness of the proposed method. The feature selection method based on DF and the feature selection method based on MI are selected as the comparison methods. ALA is used to transform multi-label texts into single-label texts, and BRKNN is used as the classifier. The value of t ranges from 10% to 50%, with 10% as an interval.
All the code in this paper is implemented in MyEclipse version 2014 in a Windows 10 using 3.30 GHz Intel (R) CPU with 8 GB of RAM. The Term Frequency-Inverse Document Frequency (TF-IDF) method [
43] is used to calculate the weight of the feature in each text. BRKNN and MLKNN multi-label classification algorithms are implemented based on MULAN software package [
44]. The cross validation is used in the experiments. And all the experimental results shown in this paper are the average of ten-fold cross validation.
4.4. Experimental Results and Analysis
4.4.1. Proposed Algorithm Validation Experiment
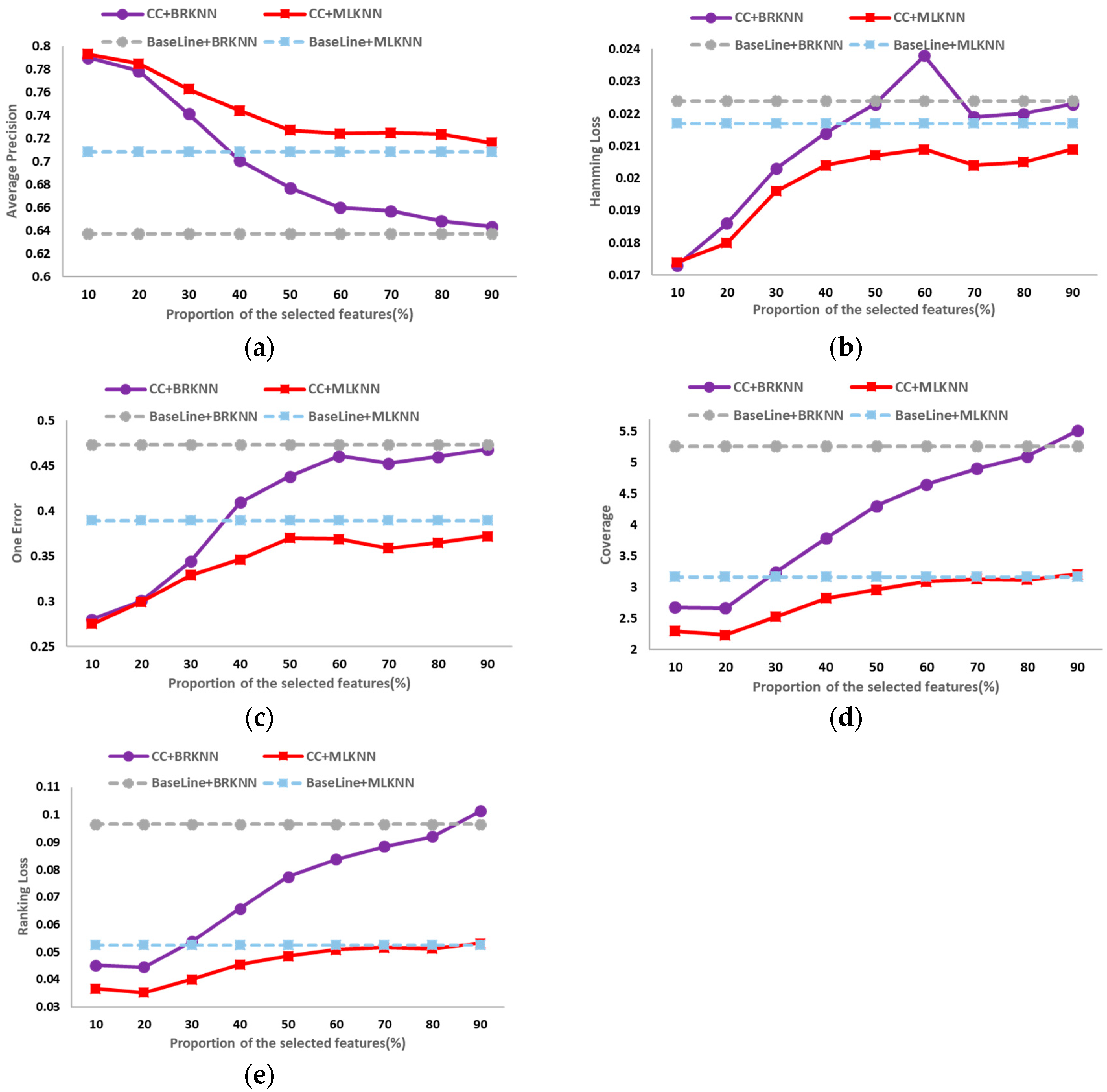
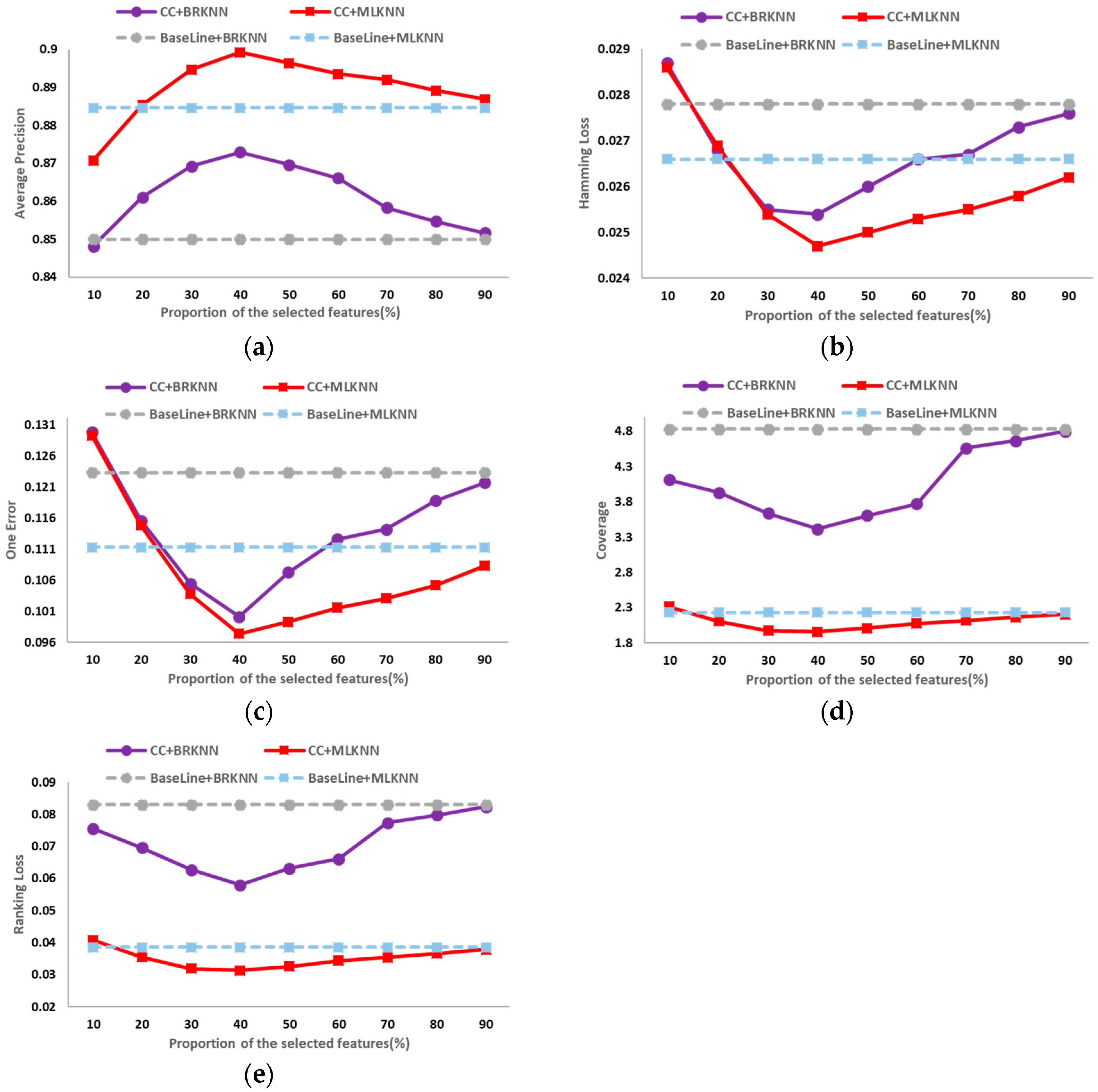
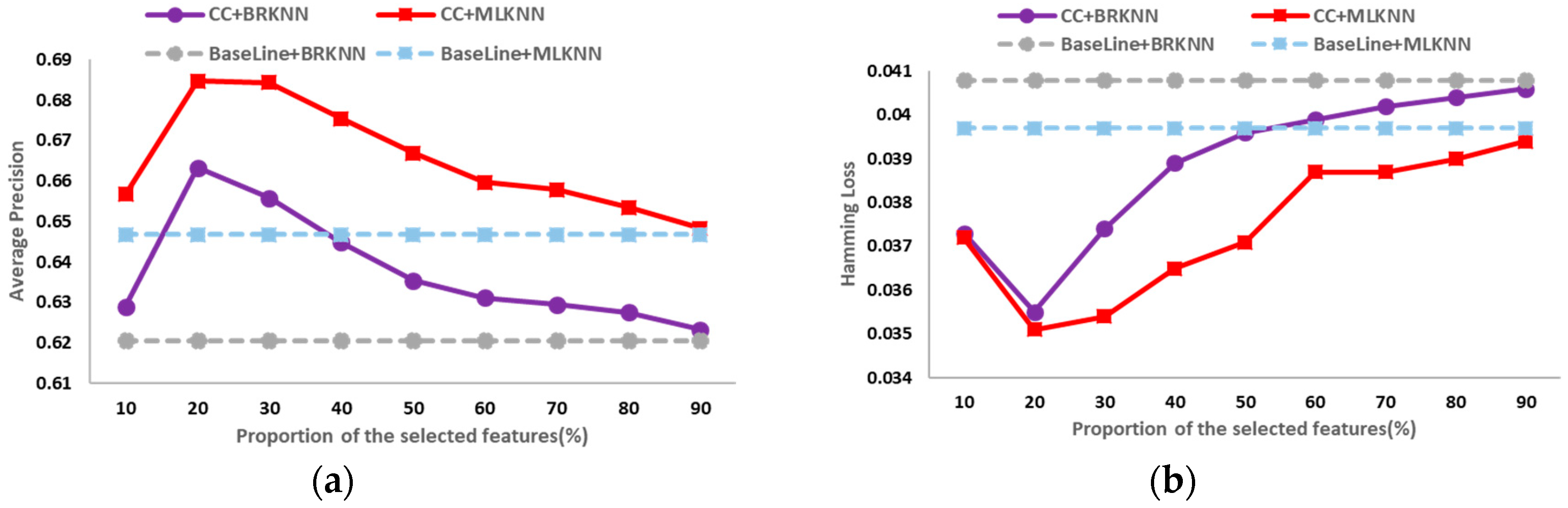
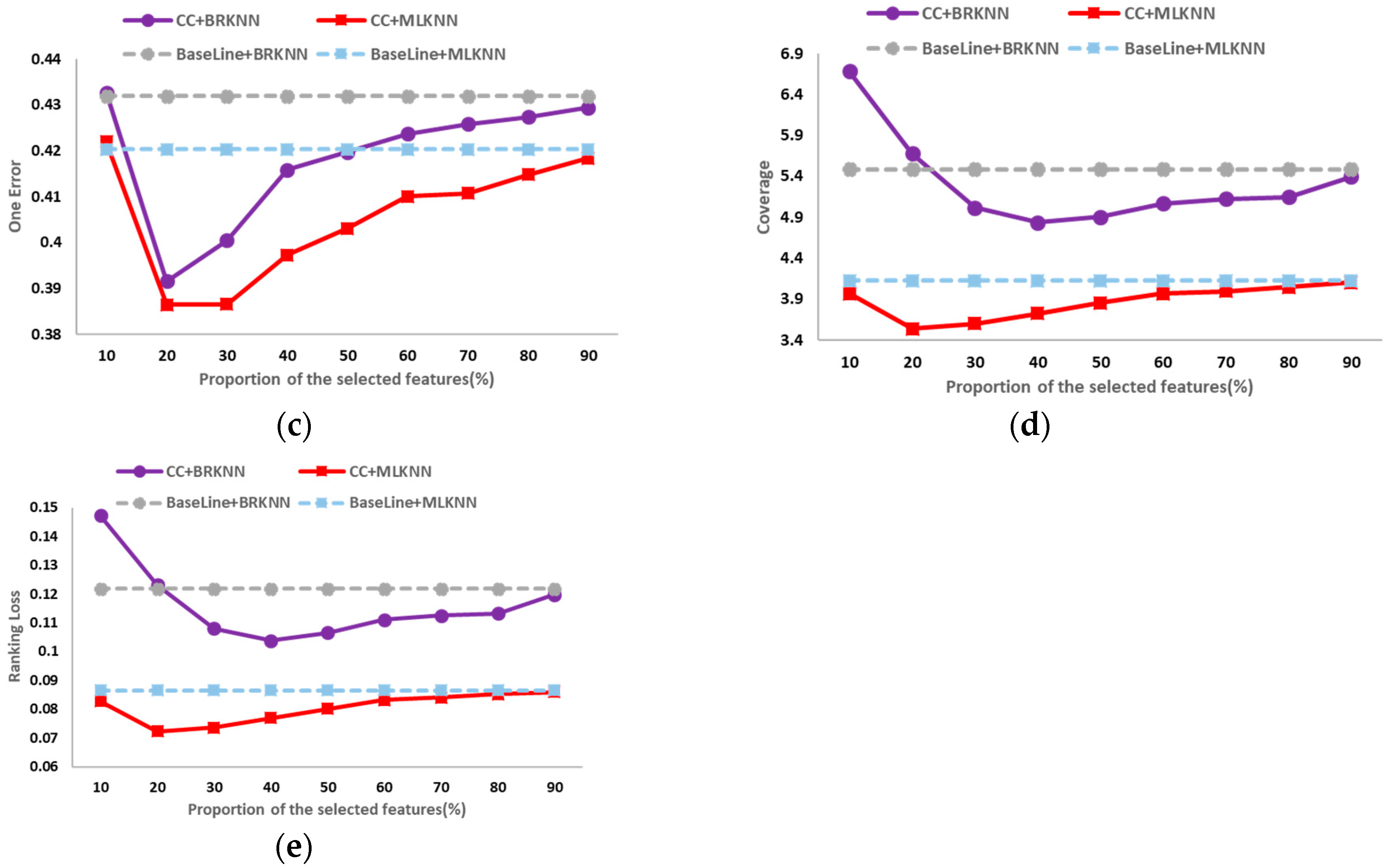
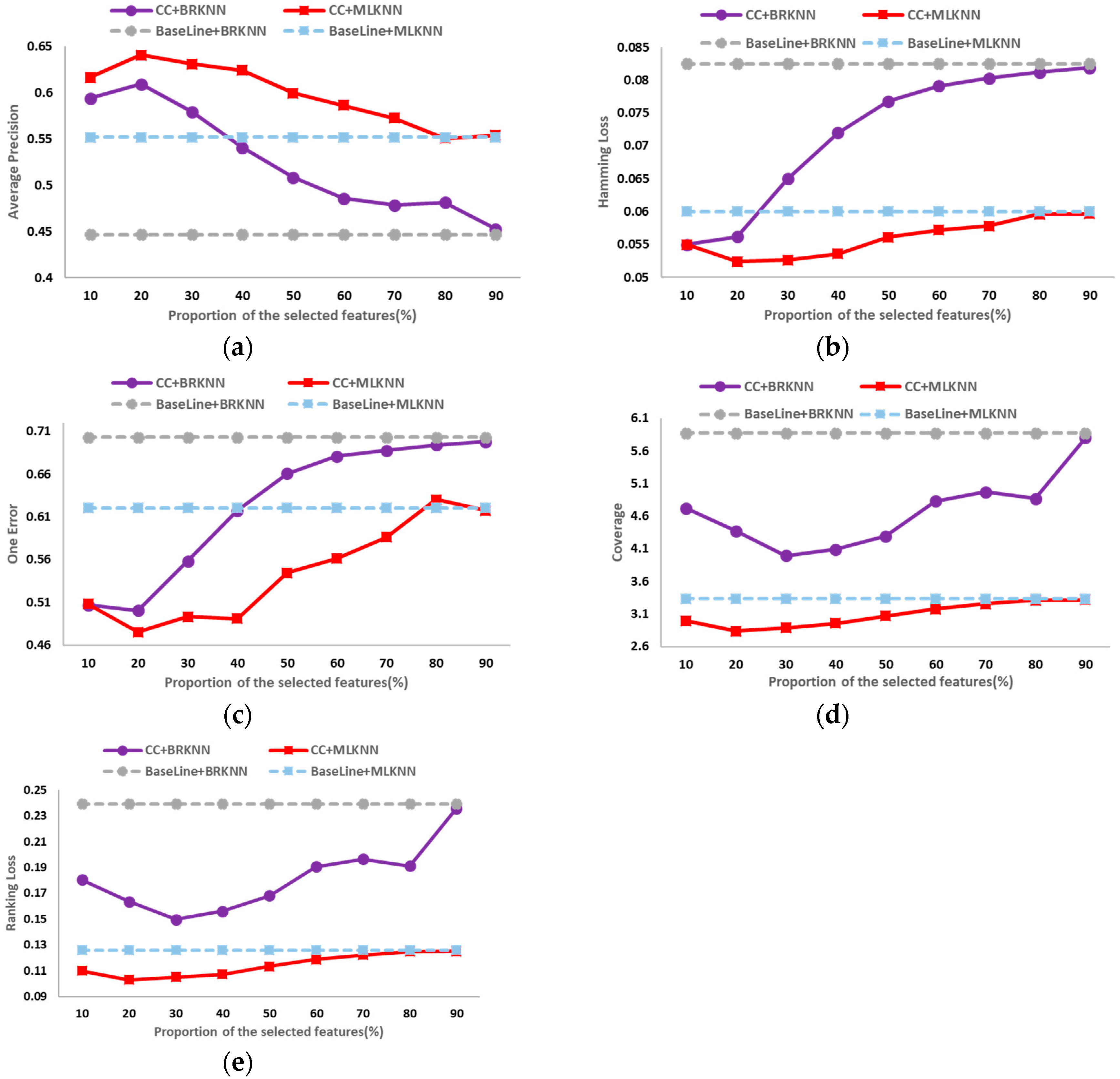
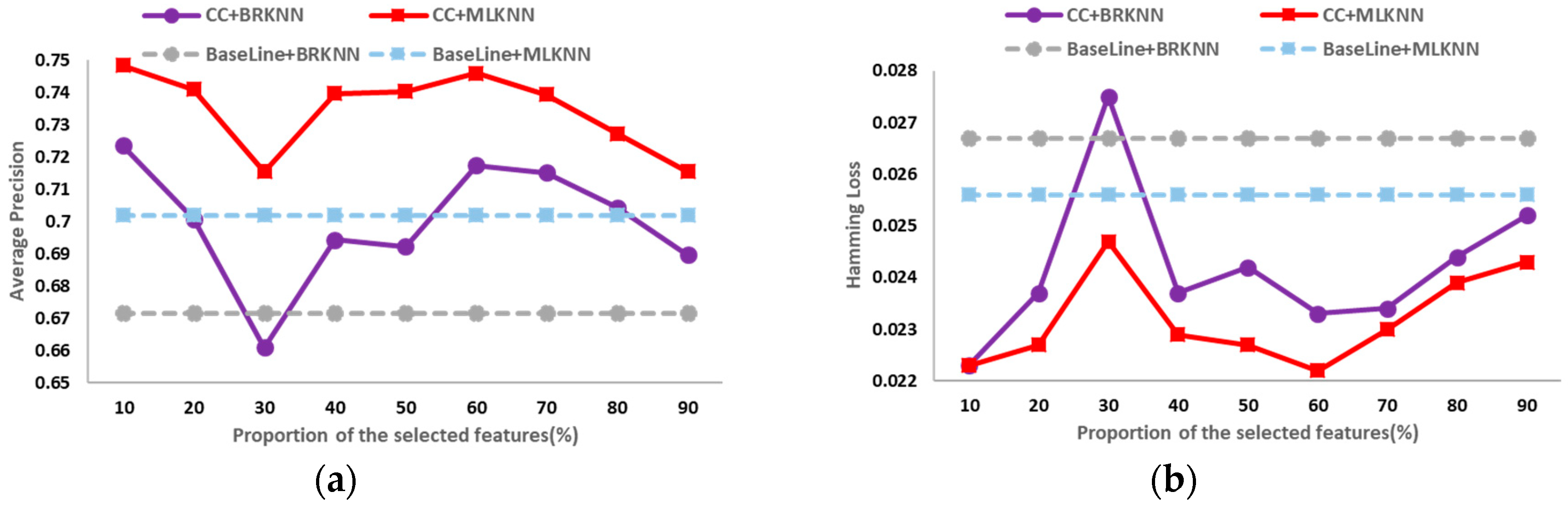
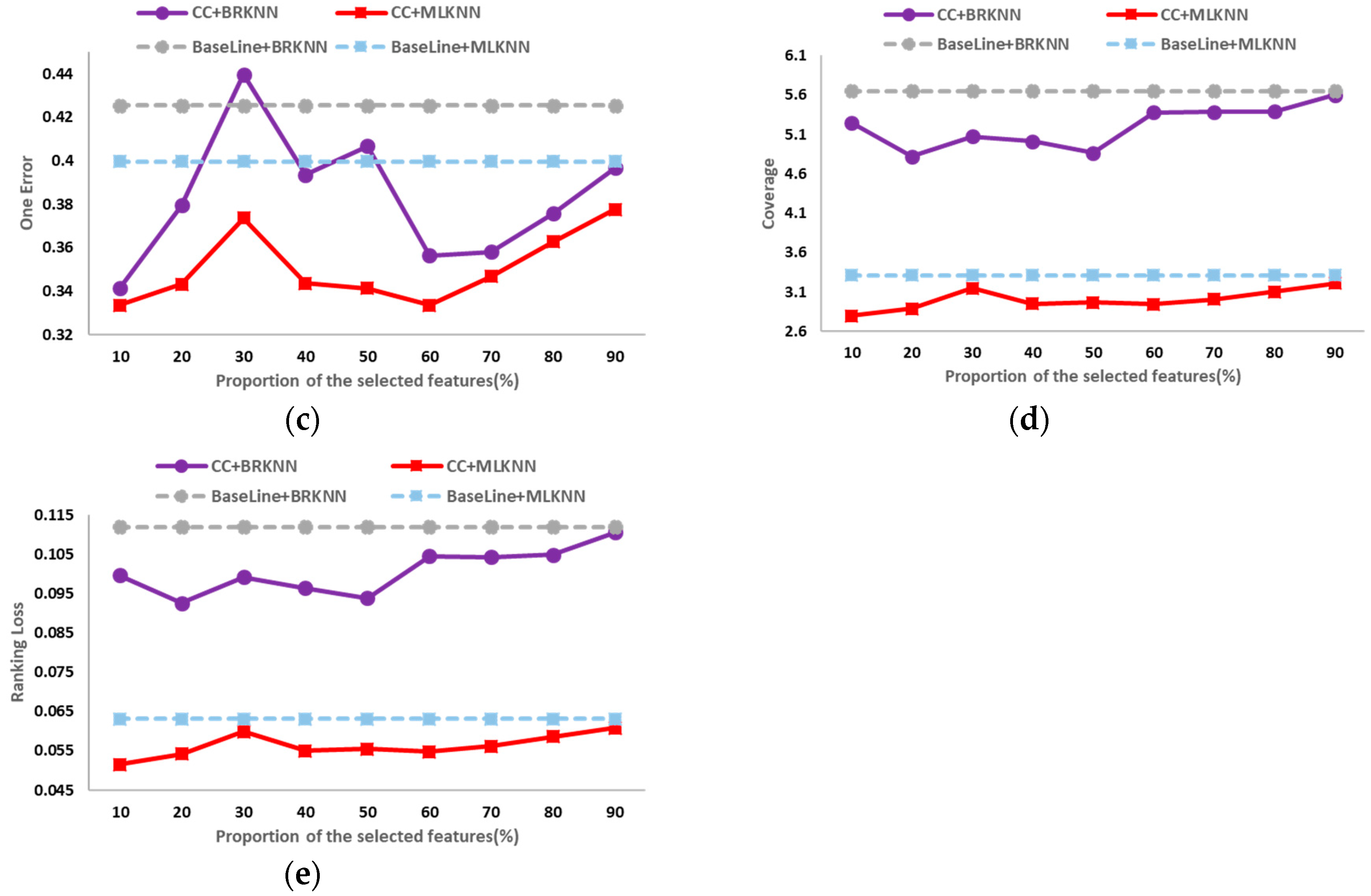
The classification results on the six public data sets in different dimensions of average precision, hamming loss, one error, coverage and ranking loss are shown in
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6 and
Figure 7. In these figures, the horizontal axis denotes the proportion of the selected features, that is, the horizontal axis denotes the value of
t, and the vertical axis denotes the value of the evaluation metric; CC+BRKNN denotes that the multi-label classification is performed on the feature space constructed by the proposed method, and BRKNN is used as the classifier; CC+MLKNN denotes that the multi-label classification is performed on the feature space constructed by the proposed method, and MLKNN is used as the classifier; BaseLine+BRKNN denotes that the multi-label classification is performed on the original feature space, and BRKNN is used as the classifier; and BaseLine+MLKNN denotes that the multi-label classification is performed on the original feature space, and MLKNN is used as the classifier.
It can be seen from
Figure 2 to
Figure 7 that, on the six data sets, the classifications performed on the feature spaces constructed by the proposed feature selection method universally have better performance than that of the baseline method in each dimension. In classification experiments, the average precision is the most intuitive and concerned evaluation metric. Therefore, we regard the best value of the average precision as the best performance of the classification, so as to analyze the experimental results. Compared with the classification results in the original feature space, the increase (decrease) percentage of each evaluation metric is shown in
Table 2.
From
Table 2, it can be seen that on the six data sets, most of the classification evaluation metrics obtained in the feature space constructed by the proposed method are universally better than those obtained in the original feature space. Only on the Computers data set, when the value of
t is 20% and BRKNN is used as the classifier, the coverage and ranking loss obtained in the feature space constructed by the proposed method are worse than those obtained in the original feature space. Excitingly, on the Health data set, when the value of
t is 20% and BRKNN is used as the classifier, the average precision is increased by 67.79%, which is the greatest increase among all.
In order to further demonstrate the effectiveness of the proposed feature importance method based on CC, we experimented it on ALA, NLA, LLA, and SLA.
The experimental results of the six public data sets are shown in
Table 3,
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8. In these tables, BaseLine denotes the multi-label classifications performed on the original feature space; 10%, 20%, 30%, 40%, and 50% denote the multi-label classifications performed on the feature spaces in different dimensions, respectively; and Average denotes the average of the classification results in five different dimensions.
From
Table 3 to
Table 8, it can be seen that the feature importance method based on CC performed on ALA, NLA, LLA, and SLA all can effectively select the features with strong category discrimination ability. The performance of the classifications based on the feature space constructed by the proposed method is all superior to that on the original feature space, demonstrating that the proposed feature importance method is effective and universal.
4.4.2. Performance Comparison Experiment
In this section, we demonstrate the effectiveness of the proposed method by comparing its performance with that of the feature selection method based on DF and the feature selection method based on MI. The classification results on the six data sets in different dimensions using different feature selection methods are shown in
Table 9,
Table 10,
Table 11,
Table 12,
Table 13 and
Table 14.
In these tables, CC denotes the proposed feature selection method, DF denotes the feature selection method based on DF, MI denotes the feature selection method based on MI, CC+BRKNN denotes the multi-label classification performed on the feature space constructed by the proposed method, and BRKNN is used as the classifier. The naming rules for other symbols are the same. Also, we use bold font to denote the best performance in one dimension and underline to denote the best performance in all dimensions.
From
Table 9 to
Table 14, it can be seen that there are 150 comparison results using three feature selection algorithms on six data sets with five evaluation metrics. Among them, the feature selection method based on CC wins 126 times, and the winning percentage is up to 84.0%.
Aside from dimensions, the five evaluation metrics have 30 best values on six data sets, 29 of which are obtained in the feature selection method based on CC proposed in this paper. In addition, in the proposed feature selection method, most of the best values of the evaluation metrics are obtained when the dimensions are 10% and 20%, only a few are obtained when the dimension are 30% and 40%, but none when the dimension is 50%.
From the perspective of the average precision, compared with the method base on DF, the evaluation metric has the largest increase on the Entertainment data set, which is 8.22%, and compared with the method based on MI, the evaluation metric has the largest increase on the Medical data set, which is 91.65%.
Therefore, the performance of the multi-label text feature selection method based on CC is better than that of the common feature selection methods based on DF and MI. Also, the best values of the evaluation metrics are all obtained in smaller dimensions, which greatly reduces the feature space dimension and improves the classification performance.
In summary, it can be seen from the experimental results and analysis on the six data sets that
- (1)
Compared with the baseline method, the classification performance of the feature selection method proposed in this paper are generally superior in all dimensions, which demonstrates the effectiveness of the proposed method.
- (2)
Good classification performance has been achieved when the proposed method of feature importance is performed on different label assignment methods, demonstrating that the feature importance method based on CC is effective and universal.
- (3)
Compared with the commonly used feature selection methods, the percentage of the best values of the evaluation metrics obtained on the proposed feature selection method is 84.0%, demonstrating that the proposed method has a good performance.
- (4)
The best values of the evaluation metrics are obtained in the proposed multi-label feature selection method all in smaller dimensions, which has an obvious dimension reduction effect, and is suitable for high-dimensional text data.
5. Conclusions
Aiming at the high dimensionality and sparsity of text feature space, a multi-label text feature selection method was proposed in this paper. Firstly, the label assignment method was used to transformed multi-label texts into single-label texts. Then, on this basis, an importance method based on CC was proposed to calculate the importance of each feature. Finally, features with higher importance were selected to construct the feature space. In the proposed method, the multi-label feature selection problem has been transformed into a single-label one. Thus, the feature selection process is simple and fast, and the dimension reduction effect is obvious. The proposed method is very suitable for high-dimensional text data. Compared with the baseline method and the commonly used feature selection methods, the proposed feature selection methods all achieved better performance on the six public data sets, which demonstrates the effectiveness of the method.
In this paper, a method of feature importance based on CC is proposed from the perspective of category. The contribution of features to classification of different categories was calculated from two aspects of inter-category and intra-category, clarifying the importance of features to different categories, and selecting features with strong category classification ability. The proposed method has a good performance.
However, the proposed algorithm does not consider the correlation between categories, which should be studied in the future.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}