Multiscale Object Detection in Infrared Streetscape Images Based on Deep Learning and Instance Level Data Augmentation


Abstract
:1. Introduction
- (1)
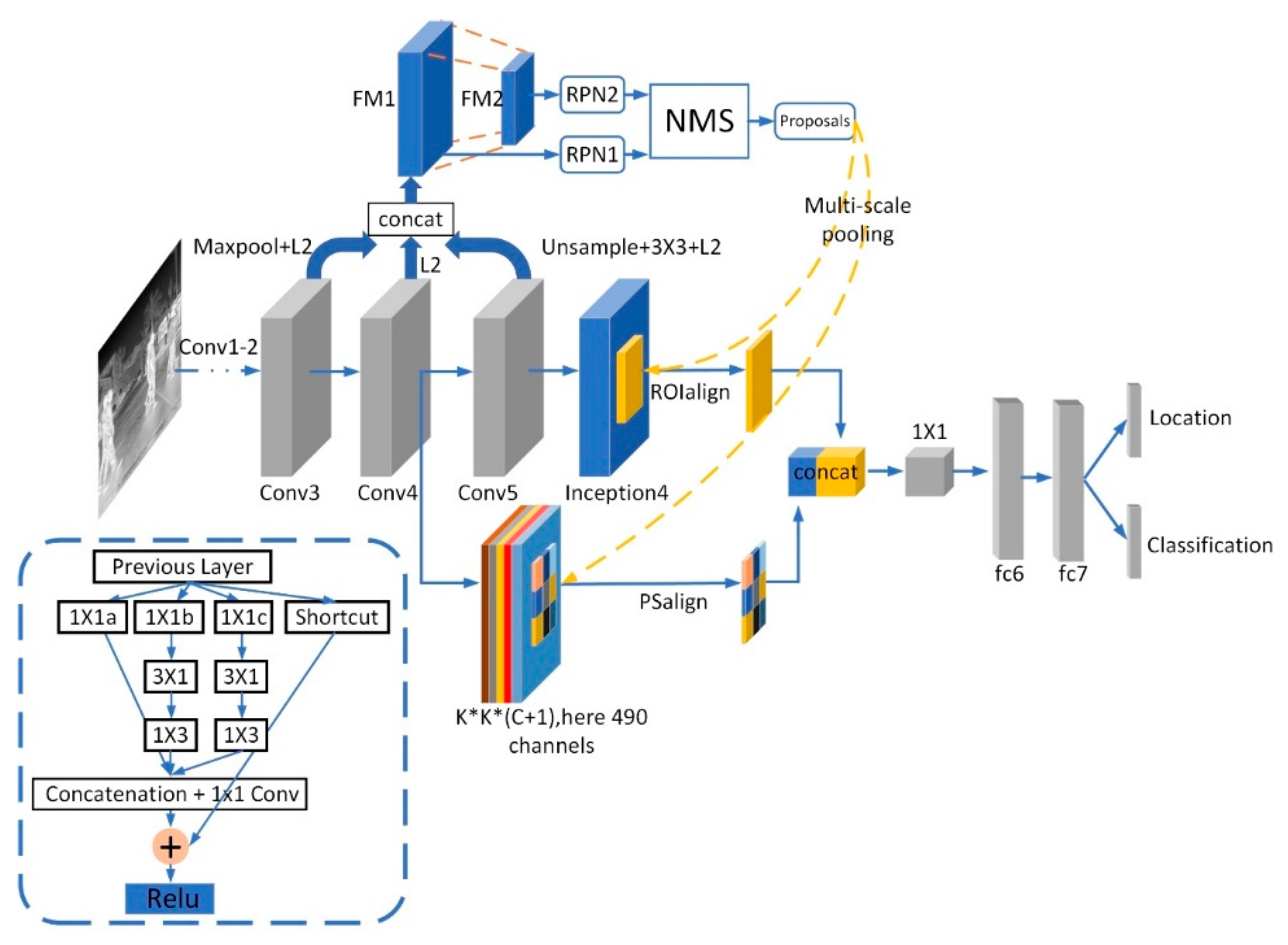
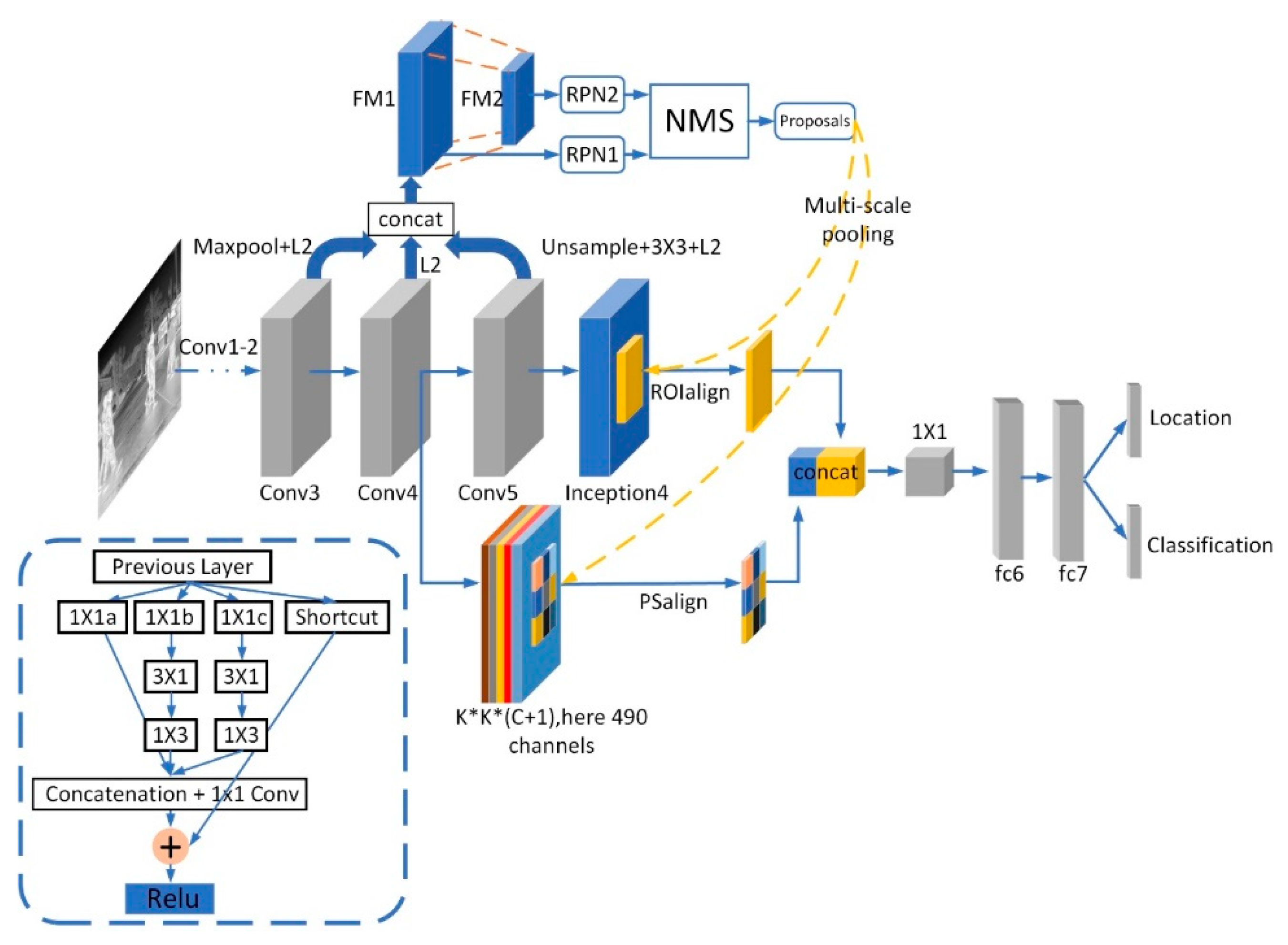
- We designed a double-layer RPN pyramid, in which the receptive field of the top feature map is more suitable for the prediction of large objects, while the receptive field of the bottom is denser and the resolution is higher for the prediction of small objects.
- (2)
- We introduce a multi-scale pooling method plus the inception4 module to project proposals on outputs of different scales simultaneously. A 1 × 1 convolution is then utilized to synthesize coarse and fine features. In this way, the network can capture more abundant multi-scale information.
- (3)
- By adding the inception4 module after the backbone, the receptive fields of feature maps generated by different size convolution kernels are various. This makes the extractor more sensitive to objects with different sizes. At the same time, the shortcut makes network training smoother.
- (4)
- Because of the background noise and the scarcity of foreground details, we used PSalign pooling to extract the local features of objects. It can fully explore the foreground information of objects.
- (5)
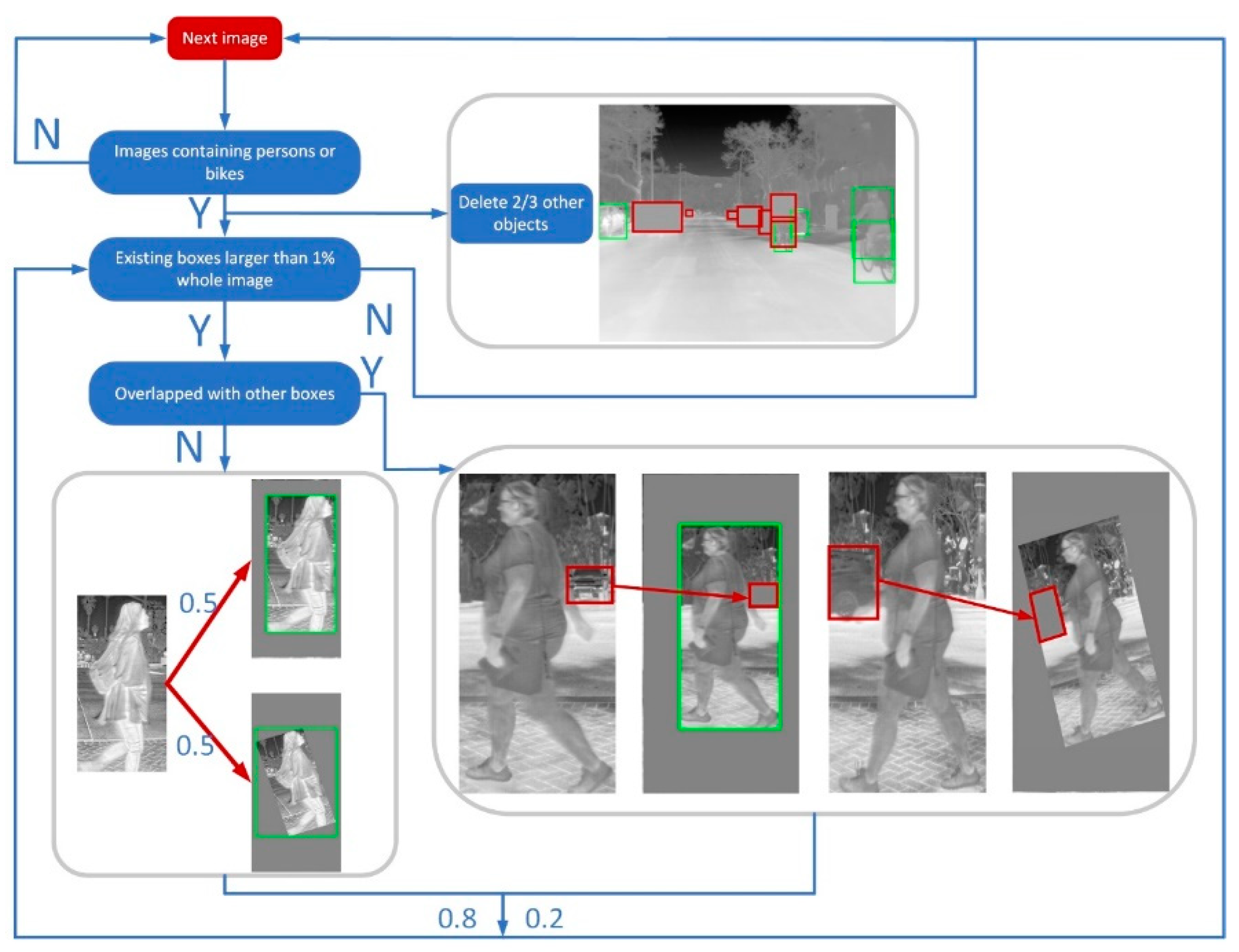
- Since the existing data augmentation methods cannot deal well with the imbalance of categories, we elaborately designed an instance-level data augmentation method. Taking account of the proportion of different categories and the spatial relationships between objects, the algorithm ensures that the original data is not damaged while expanding the dataset.
2. Double-Layer RPN Pyramid
3. Multi-Scale Pooling with Inception4 Module and PSalign
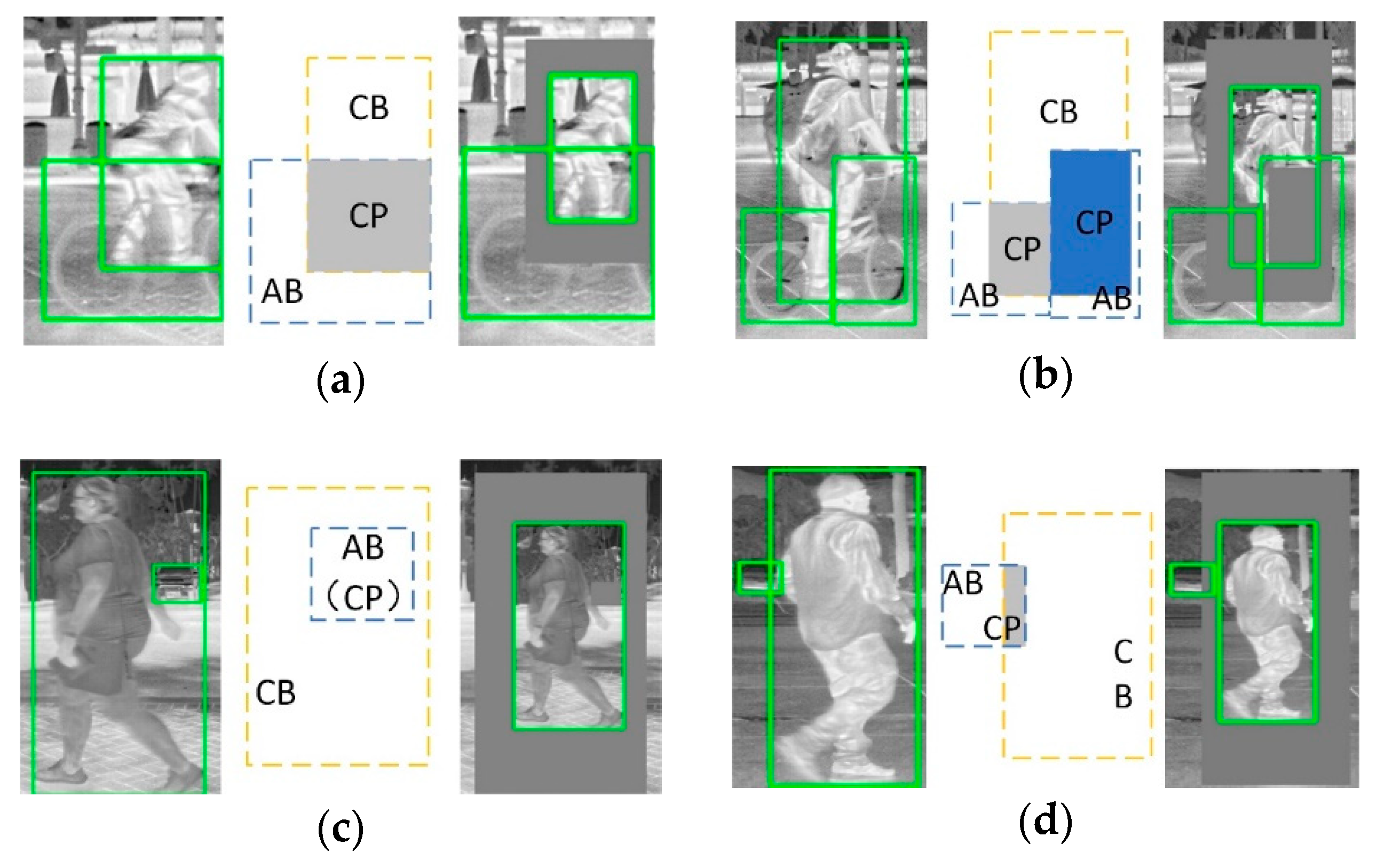
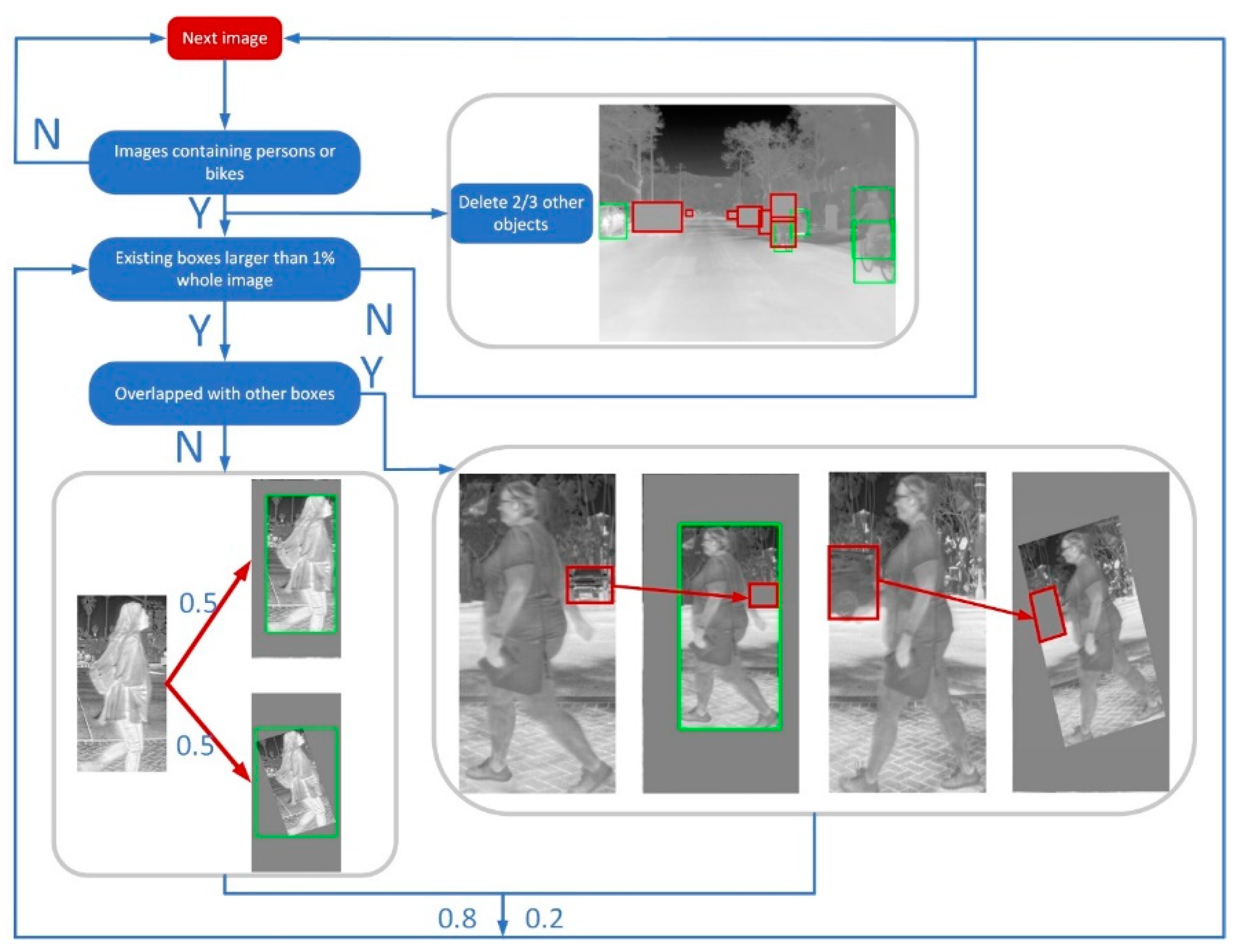
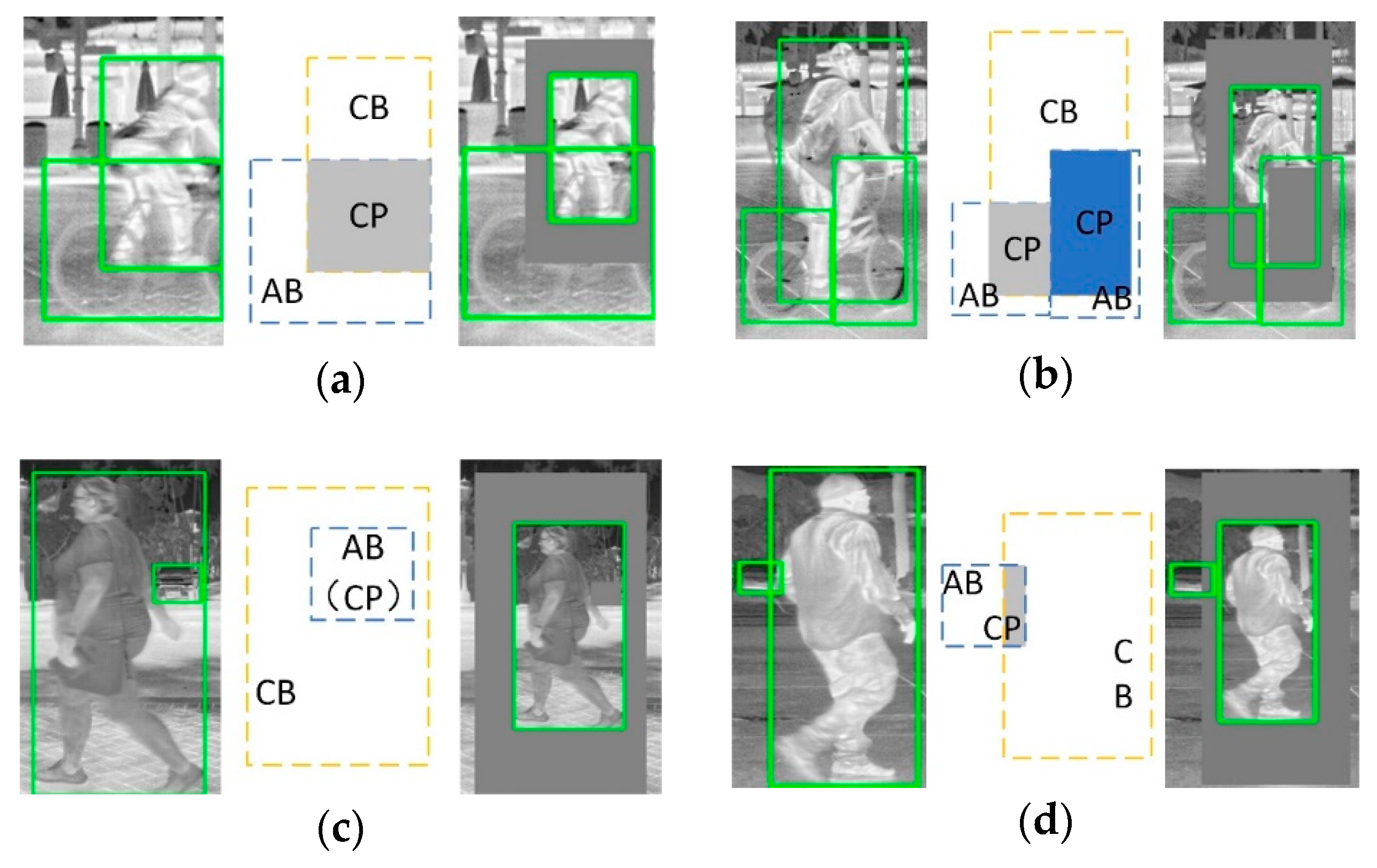
4. Instance Level Data Augmentation
5. Experiments and Results
5.1. Implementation Steps
5.2. Implement Details of Instance Level Data Augmentation
5.3. Online Hard Example Mining
5.4. Comparative Experiment
5.5. False Alarms and Misjudgment
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- O’Malley, R.; Jones, E.; Glavin, M. Detection of pedestrians in far-infrared automotive night vision using region-growing and clothing distortion compensation. Infrared Phys. Technol. 2010, 53, 439–449. [Google Scholar] [CrossRef]
- Qi, B.; John, V.; Liu, Z.; Mita, S. Use of Sparse Representation for Pedestrian Detection in Thermal Images. In Proceedings of the Workshop on Perception Beyond the Visible Spectrum, Columbus, OH, USA, 23–28 June 2014; pp. 274–280. [Google Scholar]
- Bertozzi, M.; Broggi, A.; Carletti, M.; Fascioli, A.; Graf, T.; Grisleri, P.; Meinecke, M. IR Pedestrian Detection for Advanced Driver Assistance Systems. In Proceedings of the Pattern Recognition, Dagm Symposium, Magdeburg, Germany, 10–12 September 2003; pp. 582–590. [Google Scholar]
- Dai, C.; Zheng, Y.; Xin, L. Pedestrian detection and tracking in infrared imagery using shape and appearance. Comput. Vis. Image Underst. 2007, 106, 288–299. [Google Scholar] [CrossRef]
- Piotr, D.; Ron, A.; Serge, B.; Pietro, P. Fast Feature Pyramids for Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1532–1545. [Google Scholar]
- Biswas, S.K.; Milanfar, P. Linear Support Tensor Machine: Pedestrian Detection in Thermal Infrared Images. IEEE Trans. Image Process. 2016. [Google Scholar] [CrossRef] [PubMed]
- Shi, Y.B.; Zhang, Y. Algorithm for Infrared Pedestrian Detection Based on Aggregated Channel Features. Infrared 2018, 39, 44–50. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. arXiv, 2015; arXiv:1504.08083. [Google Scholar]
- Hou, Y.L.; Song, Y.; Hao, X.; Shen, Y.; Qian, M. Multispectral pedestrian detection based on deep convolutional neural networks. In Proceedings of the IEEE International Conference on Signal Processing, Communications and Computing, Xiamen, China, 22–25 October 2017; pp. 1–4. [Google Scholar]
- Liu, J.; Zhang, S.; Wang, S.; Metaxas, D.N. Multispectral deep neural networks for pedestrian detection. arXiv, 2016; arXiv:1611.02644. [Google Scholar]
- Galarza-Bravo, M.A.; Flores-Calero, M.J. Pedestrian Detection at Night Based on Faster R-CNN and Far Infrared Images. In Proceedings of the International Conference on Intelligent Robotics and Applications, Newcastle, NSW, Australia, 9–11 August 2018; pp. 335–345. [Google Scholar]
- Kong, T.; Yao, A.; Chen, Y.; Sun, F. HyperNet: Towards Accurate Region Proposal Generation and Joint Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 845–853. [Google Scholar]
- Ren, Y.; Zhu, C.; Xiao, S. Small Object Detection in Optical Remote Sensing Images via Modified Faster R-CNN. Appl. Sci. 2018, 8, 813. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. arXiv, 2015; arXiv:1512.02325. [Google Scholar]
- Jeong, J.; Park, H.; Kwak, N. Enhancement of SSD by concatenating feature maps for object detection. arXiv, 2017; arXiv:1705.09587. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional Single Shot Detector. arXiv, 2017; arXiv:1701.06659. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S.J. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; p. 4. [Google Scholar]
- Kong, T.; Sun, F.; Yao, A.; Liu, H.; Lu, M.; Chen, Y. Ron: Reverse connection with objectness prior networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; p. 2. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Zhong, Z.; Jin, L.; Zhang, S.; Feng, Z. Deeptext: A unified framework for text proposal generation and text detection in natural images. arXiv, 2016; arXiv:1605.07314. [Google Scholar]
- Xu, D.; Ouyang, W.; Ricci, E.; Wang, X.; Sebe, N. Learning Cross-Modal Deep Representations for Robust Pedestrian Detection. arXiv, 2017; arXiv:1704.02431. [Google Scholar]
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic ship detection in remote sensing images from google earth of complex scenes based on multiscale rotation dense feature pyramid networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. DetNet: A Backbone network for Object Detection. arXiv, 2018; arXiv:1804.06215. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Receptive Field Block Net for Accurate and Fast Object Detection. arXiv, 2018; arXiv:1711.07767. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random Erasing Data Augmentation. arXiv, 2017; arXiv:1708.0489. [Google Scholar]
- Liu, X.-Y.; Wu, J.; Zhou, Z.-H. Exploratory undersampling for class-imbalance learning. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2009, 39, 539–550. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv, 2016; arXiv:1602.07261. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. arXiv, 2016; arXiv:1605.06409. [Google Scholar]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. Light-Head R-CNN: In Defense of Two-Stage Object Detector. arXiv, 2017; arXiv:1711.07264. [Google Scholar]
- Shen, L.; Lin, Z.; Huang, Q. Relay Backpropagation for Effective Learning of Deep Convolutional Neural Networks. Comput. Sci. 2015, 7214, 467–482. [Google Scholar]
- Zhu, C.; Zheng, Y.; Luu, K.; Savvides, M. CMS-RCNN: Contextual Multi-Scale Region-Based CNN for Unconstrained Face Detection. arXiv, 2016; arXiv:1606.05413. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Detention Method | AP (%) | mAP (%) | Test Time (s) | ||
|---|---|---|---|---|---|
| Car | Person | Bicycle | |||
| Faster R-CNN (vgg16) | 74.05 | 62.02 | 43.98 | 60.02 | 0.068 |
| Faster R-CNN(Res101) | 77.80 | 65.73 | 46.06 | 63.20 | 0.157 |
| HyperNet | 78.10 | 72.42 | 47.61 | 66.04 | 0.113 |
| CMS-R-CNN [32] | 77.39 | 60.59 | 42.50 | 60.16 | 0.085 |
| R-FCN | 76.80 | 63.62 | 43.87 | 61.43 | 0.065 |
| Light head R-FCN [30] | 77.77 | 64.49 | 48.78 | 63.68 | 0.119 |
| Our method | 78.96 | 74.12 | 52.49 | 68.52 | 0.108 |
| Detection Method | DR | MSP | ILDA | OHEM | AP (%) | mAP (%) | ||
|---|---|---|---|---|---|---|---|---|
| Car | Person | Bicycle | ||||||
| baseline | ⅹ | ⅹ | ⅹ | ⅹ | 78.59 | 67.29 | 52.73 | 66.20 |
| Ours1 | √ | ⅹ | ⅹ | ⅹ | 78.66 | 71.71 | 52.40 | 67.59 |
| Ours2 | √ | √ | ⅹ | ⅹ | 78.96 | 74.12 | 52.49 | 68.52 |
| Ours3 | √ | √ | √ | ⅹ | 79.10 | 73.96 | 55.60 | 69.55 |
| Ours4 | √ | √ | √ | √ | 79.58 | 74.95 | 55.48 | 70.00 |
| Ours5 | √ | ⅹ | √ | √ | 78.87 | 72.20 | 55.49 | 68.85 |
| Ours6 | √ | √ | ⅹ | √ | 79.29 | 74.72 | 53.68 | 69.23 |
| Ours7 | ⅹ | √ | √ | √ | 79.46 | 73.46 | 52.02 | 68.31 |
| Detention Method | INCEP | PS | AP (%) | mAP (%) | ||
|---|---|---|---|---|---|---|
| Car | Person | Bicycle | ||||
| Ours4a | ⅹ | ⅹ | 79.32 | 75.07 | 53.78 | 69.39 |
| Ours4b | √ | ⅹ | 79.17 | 72.29 | 55.72 | 69.06 |
| Ours4c | ⅹ | √ | 79.53 | 75.18 | 53.27 | 69.33 |
| Ours4 | √ | √ | 79.58 | 74.95 | 55.48 | 70.00 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qu, H.; Zhang, L.; Wu, X.; He, X.; Hu, X.; Wen, X. Multiscale Object Detection in Infrared Streetscape Images Based on Deep Learning and Instance Level Data Augmentation. Appl. Sci. 2019, 9, 565. https://doi.org/10.3390/app9030565
Qu H, Zhang L, Wu X, He X, Hu X, Wen X. Multiscale Object Detection in Infrared Streetscape Images Based on Deep Learning and Instance Level Data Augmentation. Applied Sciences. 2019; 9(3):565. https://doi.org/10.3390/app9030565
Chicago/Turabian StyleQu, Hao, Lilian Zhang, Xuesong Wu, Xiaofeng He, Xiaoping Hu, and Xudong Wen. 2019. "Multiscale Object Detection in Infrared Streetscape Images Based on Deep Learning and Instance Level Data Augmentation" Applied Sciences 9, no. 3: 565. https://doi.org/10.3390/app9030565
APA StyleQu, H., Zhang, L., Wu, X., He, X., Hu, X., & Wen, X. (2019). Multiscale Object Detection in Infrared Streetscape Images Based on Deep Learning and Instance Level Data Augmentation. Applied Sciences, 9(3), 565. https://doi.org/10.3390/app9030565