Practical implementation of effective data encoding involves minimising the average number of bits per single data generated by the S source (in the case of audio compression the input data are samples, in this work, we adopted the standard 16-bit per samples, which the source S is a stream of sample from CD). Depending on what sources we deal with, we can divide them into sources without memory DMS (Discrete Memoryless Source) and sources with memory CSM (Conditional Source Model). Considering this division from the point of view of Markov model, in the first case, for the lower limit of the bit average we can introduce unconditional entropy (H(SDMS) - zero order entropy), and in the second case, we deal with the conditional entropy of the k-th order defined as H(S|C(k)), where in the case of audio signal, the context of C(k) is defined in example as k samples backwards. By introducing the total entropy as H(S), we obtain the relation H(S) ≤ H(S|C(k)) ≤ H(SDMS).
Trying to use a static version of Huffman code, for example, in the case of 16-bit data, requires giving the decoder a probability distribution of the encoded file, which is an impractical idea, because, with 16-bit samples and possibly low precision of writing, the individual probabilities
pi, for example, using 2 bytes per one
pi value, the size of the file header itself will be 2
17 B. In addition, the zero order entropy, which is the lower limit of the bit average of the static encoder, indicates that this approach gives unsatisfactory results (see the second column in
Table 3).
For this reason adaptive versions of codecs are used in practice. Moreover, since the audio data do not constitute a sequence of independent values it is difficult to determine and apply the
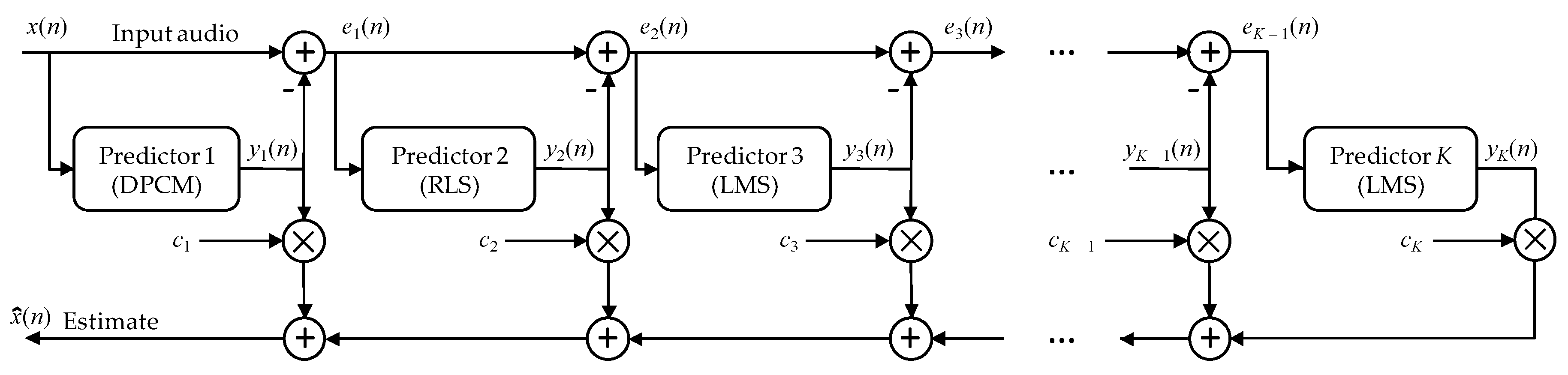
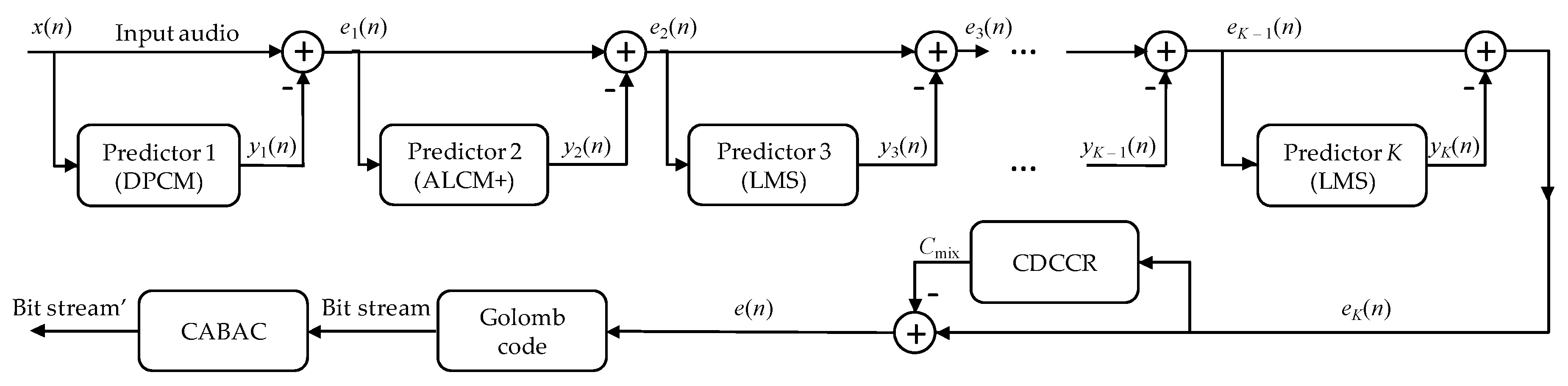
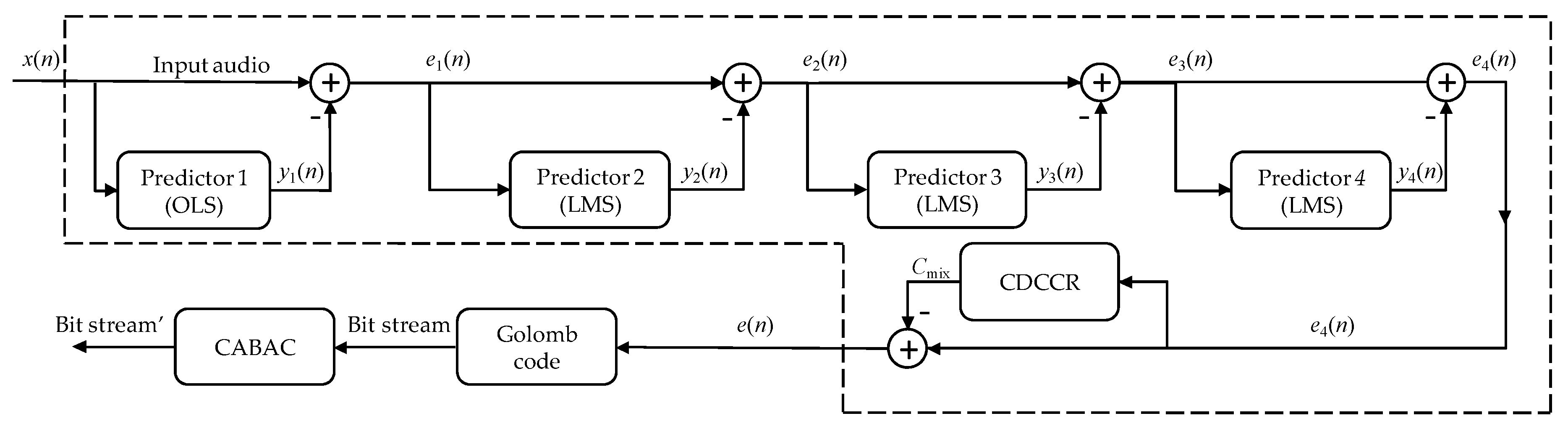
k-th order of Markov model. In practice, it is assumed that the removal of interdependencies is possible by use of predictive techniques writing only predictive errors into the file. The prediction model can be a linear model of the
k-th order or a more complex nonlinear solution, but we reduce it to the one value predicted
(creating not explicitly defined first-order Markov model), which we subtract from the current sample
x(
n), see Formula (1). As a result a sequence of prediction errors can be interpreted as a source for which the first-order entropy value is noticeably smaller than the zero order entropy (see the third column in
Table 3). It should be noted here that it is extremely difficult to determine the total entropy
H(
S) because it is difficult to determine the order of the Markov model, which will take into account all the interdependencies between the individual data (an example is the use of linear prediction of the order of
r = 1000 in the first degree of NLMS proposed here the cascading prediction technique).
Usually, instead of a static Huffman code, the adaptive Rice coder [
36] and the multivalued arithmetic coder with quantisation are used for efficient coding of prediction errors [
15]. This allows reducing the size of the alphabet as a result of which a part of less-significant bits representing the value of prediction errors is saved without further coding [
37]. The method proposed here has a similar implementation complexity compared to the one described in the work [
37], where simple mapping function is used. That indicates currently the best Rice code parameter, which corresponds statistically to the most suitable fit (in the medium-term sense) to the distribution used by the coder.
7.1. Short-Term Feature of the Probability Distribution
Analysing the closest neighbourhood composed of samples x(n − i) and the prediction error signal e(n − i), the fact that there are short-term dependencies between the coded data in sequence can be used. On the basis of these features, the correct type of distribution of the currently coded modified prediction error value can be determined quite accurately, where = 2e(n) − 1 for e(n) > 0, and = −2e(n) in otherwise.
Starting from this assumption, a contextual arithmetic coder is usually designed so that has
t distributions of probabilities associated with individual context numbers from 0 to
t − 1. Theoretically, it is expected the increase in compression efficiency with the increasing number of contexts. However, there is the problem of too slow adaptation of their distribution to the approximate actual state. The adaptive nature of calculation of probability distributions requires a quick defined of the approximate target shape of each of
t distributions. Therefore, a certain compromise should be made between the number of contexts and the speed of adaptation of their distributions. In coding of images
t is 8 [
33], 16 and even 20 [
38].
The proposed solution uses nine classes that define coarse signal characteristics from a short-term point of view, using principles similar to those used in the works [
39,
40]. The
ω parameter is calculated as a weighted average of
z = 17 previous prediction error modules |
e(
n −
i)|:
The ω value is quantised using t − 1 thresholds th(j), to obtain the short-term arithmetic context number. For t = 9, thresholds were set as th = {4, 10, 30, 50, 80, 180, 500, 1100}, receiving bmedium number belonging to the range .
It is possible to include ultra-short-term features based on only the closest four errors, by calculating the max{e(n − 1), e(n − 2), e(n − 3), 0.6⋅e(n − 4)} value. If the value is greater than 1500, the bultra bit assumes value 1, otherwise 0.
7.2. Medium-Term Features of the Probability Distribution
The values of
bmedium and
bultra presented in
Section 7.1 provide information on short-term features of the currently estimated probability distribution. Additionally, in the case of the prediction error stream, the assumption is made about the medium-term stationarity of its distribution, which is usually similar to the geometrical distribution. Data on such features can be coded in a highly efficient manner using the Golomb code family [
18].
For each coded value, an individual m group number is calculated. For this purpose, the adaptive average cost of coding with the Golomb code use one of the appropriately selected 40 probability distributions. Probability distributions are defined based on the formula G(i) = (1 − p) ⋅ pi, with individual values p(j) associated with the j-th distribution depending on the m(j) parameter of the Golomb code, which is the j-th number from the experimentally selected set m = {1, 2, 3, 4, 6, 8, 12, 16, 20, 24, 32, 40, 48, 64, 80, 96, 128, 160, 192, 256, 320, 384, 448, 512, 576, 640, 768, 896, 1024, 1152, 1280, 1536, 1792, 2048, 2560, 3072, 4096, 5120, 6144, 8192}. This increased flexibility gives the Golomb codes an advantage over the Rice code, for which m values can be only a number 2 raised to an integer value (e.g., 21 = 2, 22 = 4, 23 = 8, 24 = 16, …).
To calculate a current predicted value of
m, in [
17], the estimate using backward adaptation was proposed, applying a local assumption of stationarity
S(
n), being the average value of modified prediction errors. Assuming that the expected value of modified prediction errors is inversely proportional to 1 −
p, we obtain
p = (
S(
n) − 1)/
S(
n), where the expected value of
S(
n) equals
where
NG specifies the number of previously coded modified prediction errors. The group number
m can be calculated using formula presented in [
41,
42] (at
δ = 0):
An experimental correction value
δ = 0.41 [
17] was introduced to Formula (29) which resulted in a slight decrease in the bit average (for the whole test base). At
δ = 0, there is a linear relationship between
m and
S(
n) values of
m = (ln 2) ⋅
S(
n) [
43], and after taking into account
δ = 0.41, an approximated form of the formula was determined:
After simplifying the Formula (28) to the iterative form and using the auxiliary sum
Sγ, which is adapted using the formula
=
we obtain the value of
=
The value of
γq is the experimentally determined forgetting factor, in work [
17] it was set at a compromise level of 0.952. A noticeable improvement was obtained by using two forgetting factors (
γ1 = 0.935 and
γ2 = 0.992) and using them to calculate two sums of
S(1)(
n) and
S(2)(
n). In addition, we use the weighting effect of these sums, calculating the current average costs
Lcost(q) of encoding the input data stream (for
q = {1, 2}) using Golomb codes separately for parameters
m1 and
m2:
which allows calculating weights
necessary to calculate the final value of
m:
which is additionally scaled to best approximate one of the 40 values found in the
m vector. The method of scaling is as follows; for
m < 1, we assign
m = 1 and values between 1 and 6 remain unchanged, whereas for
m > 6, we calculate
. The last step is the approximation of the calculated
m value to the nearest of those in
m vector. In this way, the index of the quantised value of
m (hereinafter referred to as
bGolomb) is obtained. The
bGolomb value is a fragment of the context number and is invariable when encoding all bits of the next Golomb code word representing the number
.
This allows for a highly flexible adaptation to the local features of the probability distribution of currently coded prediction errors as well as the rate of change of features of this distribution. Then, the quantisation of the m parameter to only 40 values is a compromise approach with regard to the uninterrupted adaptation of each of the 40 probability distributions that are used in the binary arithmetic coder, by which the bit stream coming from Golomb coder is coded.
The Golomb code word coding
value consists of two elements. The first one is the
number specifying the group number that is written in the unary form (sequence
uG zeros ending with one). The second element is the
number, called the number of element in a group (remainder of division by
m). It is coded using a phased-in binary code (which is the variant of the Huffman code for sources with
m equally probable symbols [
42]). Specifying the
parameter means that, in each group, the first
elements
vG are coded using
k − 1 bits, and the remaining
m −
l elements are coded as number
vG + l using
k bits [
13].



{kind=link}
{kind=link}
{kind=link}