1. Introduction
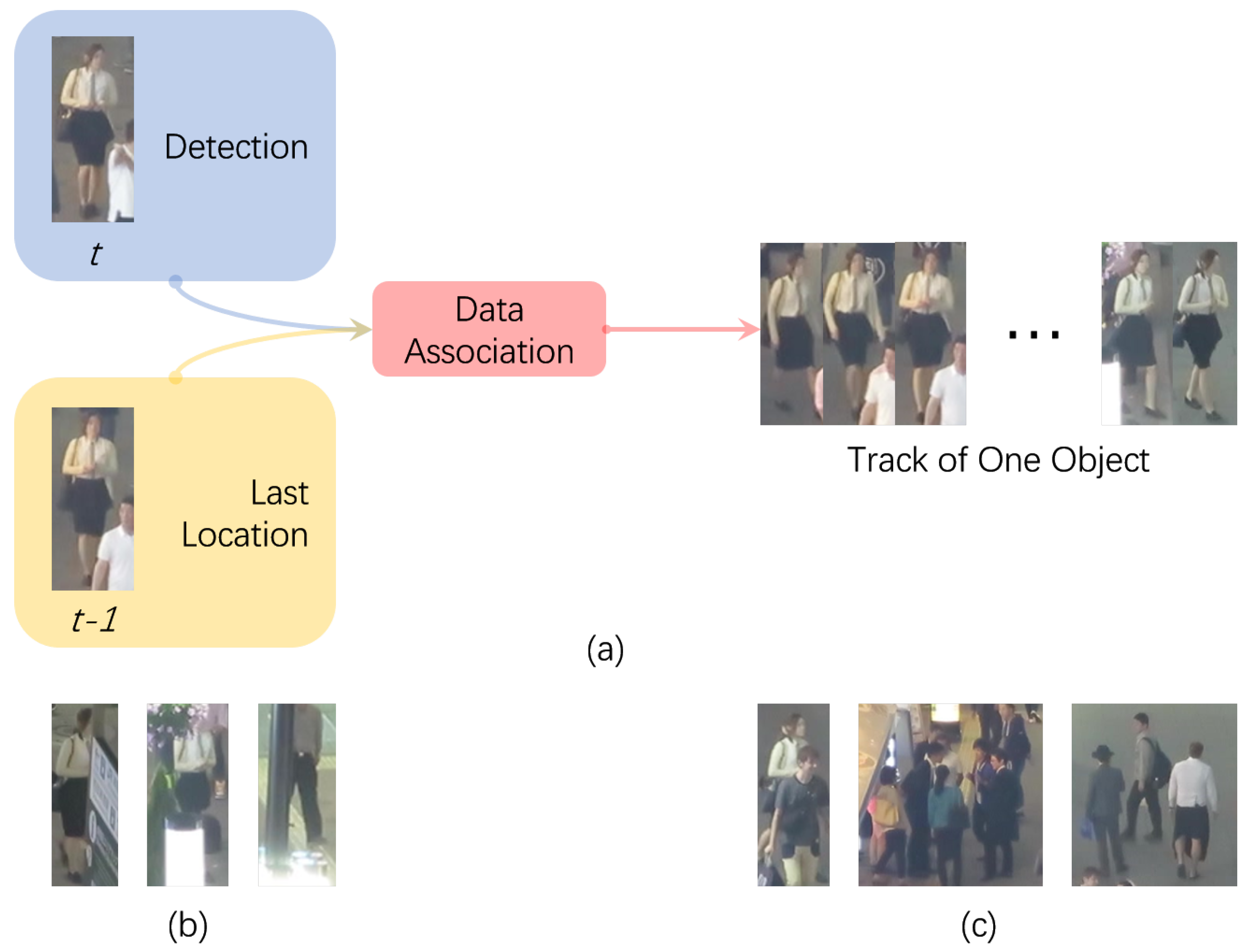
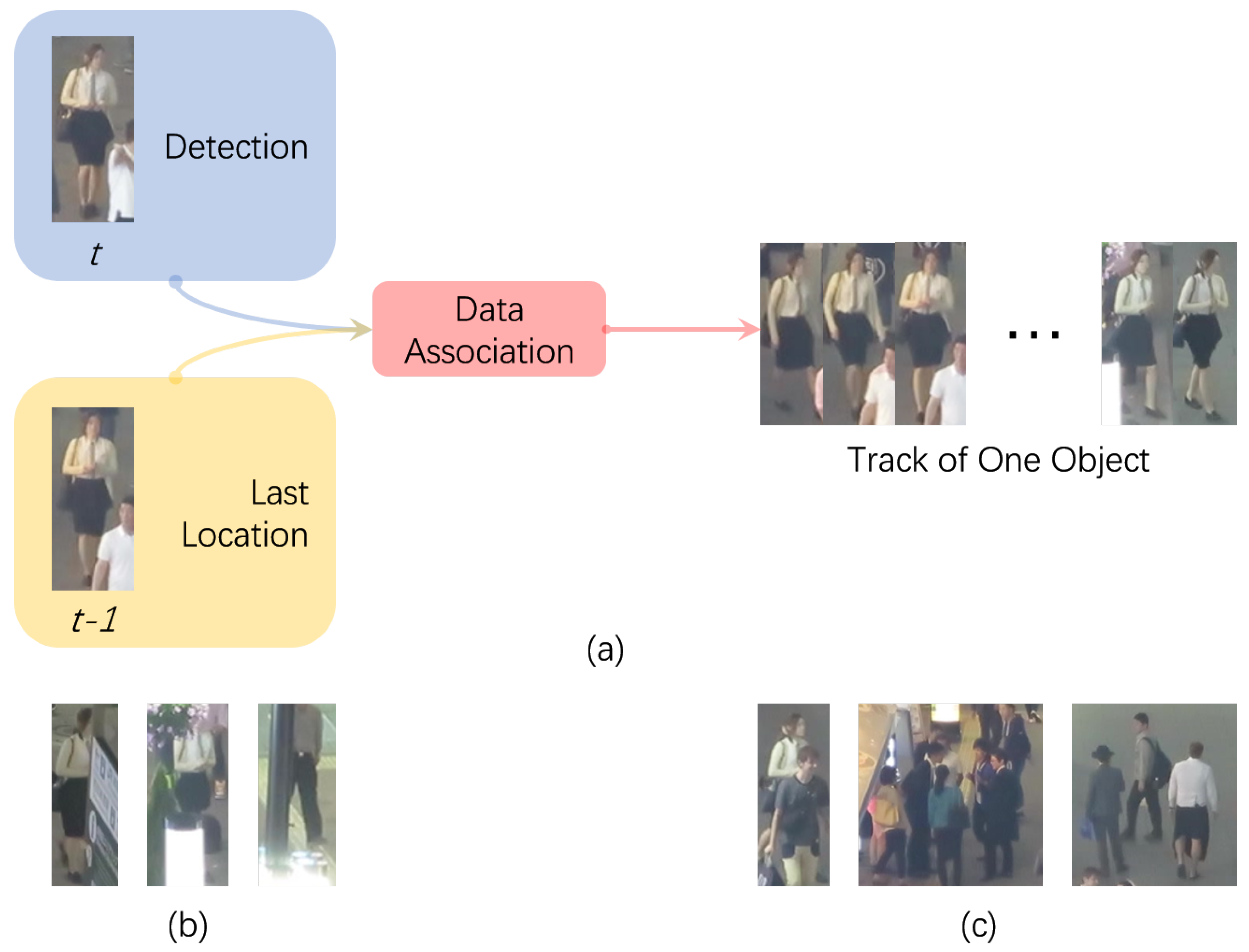
Multiple object tracking (MOT) in video (a critical problem for many applications including robotics, video surveillance, and autonomous driving) remains one of the big challenges of computer vision. The goal is to locate all the objects we are interested in, in a series of frames, and form a reasonable trajectory for each one of them. Since recent progress has been made on object detecting, tracking-by-detection (shown in
Figure 1) has emerged as one of the most popular paradigms to solve the MOT problem, as it breaks MOT into two parts: (i) detection, to separate interesting objects from the background in each frame, and (ii) data association, to align corresponding detections through time series to form reasonable trajectories. However, missing and spurious detections, as well as complex scenes under a MOT scenario like occlusions and object interactions in crowded environments (some of the examples are shown in
Figure 1), may set a barrier for the performance of MOT methods due to the high dependency of detection. Also, the separation of detection from tracking itself may keep object detection inaccessible to the temporal information of a certain object.
A common concern in MOT approaches is identity (ID) consistency—maintaining the objects’ identities as long as possible. This is difficult under occlusion and in crowded scenes, especially when the appearances of the individual objects are not distinctive enough. Some of the offline methods rely on tracklet (short trajectory segments) merging, rather than single detections, to keep track of the objects. Online methods, on the other hand, use a re-identification method to retrieve certain objects which are lost from tracking during occlusion or interaction. However, their performance is still not as promising as desired. A single object tracker is capable of distinguishing objects from the background, where the goal is to maintain tracking a single object as long as possible. Hence, it is intuitive to implement a single object tracking (SOT) method in a MOT scenario to keep the ID consistency.
The MOT problem can be easily rephrased as multiple single object tracking problem, where all of the objects’ states are estimated by a tracker formed of multiple single object trackers. However, scenes under a MOT scenario are quite different from those in a SOT one, usually they are more complex. Thus, directly pushing SOT methods into a MOT scenario still faces various challenges.
The aim of single object tracking (SOT) is to locate an object in continuous video frames given an initial annotation in the first frame. In contrast with MOT, there is only one object of interest and it is always in the considered image scene. A single object tracker is constantly generalized to capture appearance changes of the object, and it is designed to efficiently distinguish the object from the background by training a strong discriminative appearance model to find the location of the object within a searching area in the next frame. However, in the MOT context, multiple objects with similar appearances and geometries in the searching area may confuse the single object tracker. Furthermore, the update strategy of the single object tracker may lead to an ambiguity problem. These kinds of noisy samples may contaminate the online training samples for the tracker, can lead to gradual drift, and eventually will fail to track the object. Moreover, since the steady tracking of the single object tracker heavily relies on the quality of initialized bounding-box in the first frame in order to correctly separate the object from the background and possibly retrieve it after occlusion, the object candidates provided by a real detector under the current MOT framework are usually imperfect. With considerable noise in location and scale, this may become another major challenge.
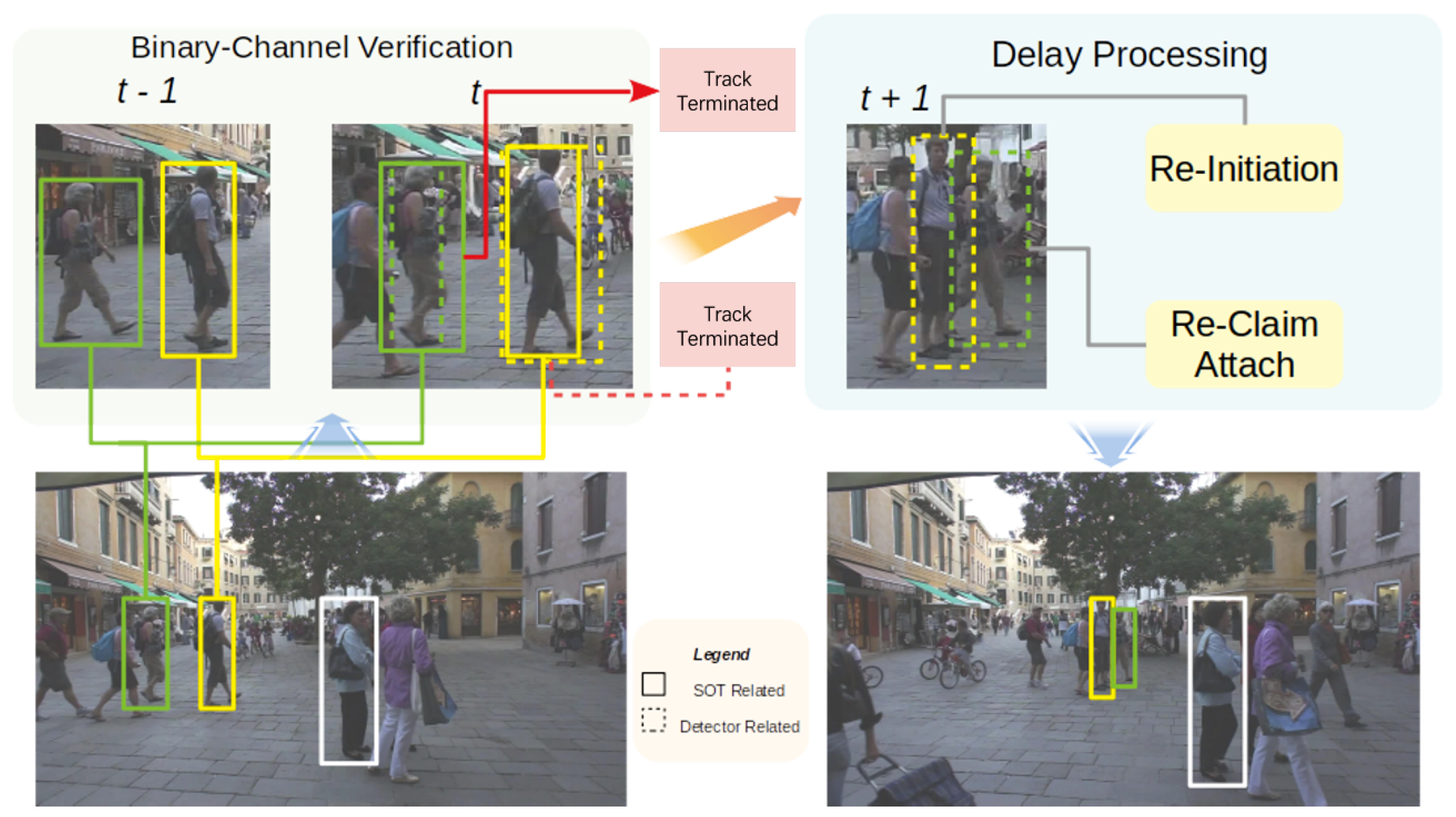
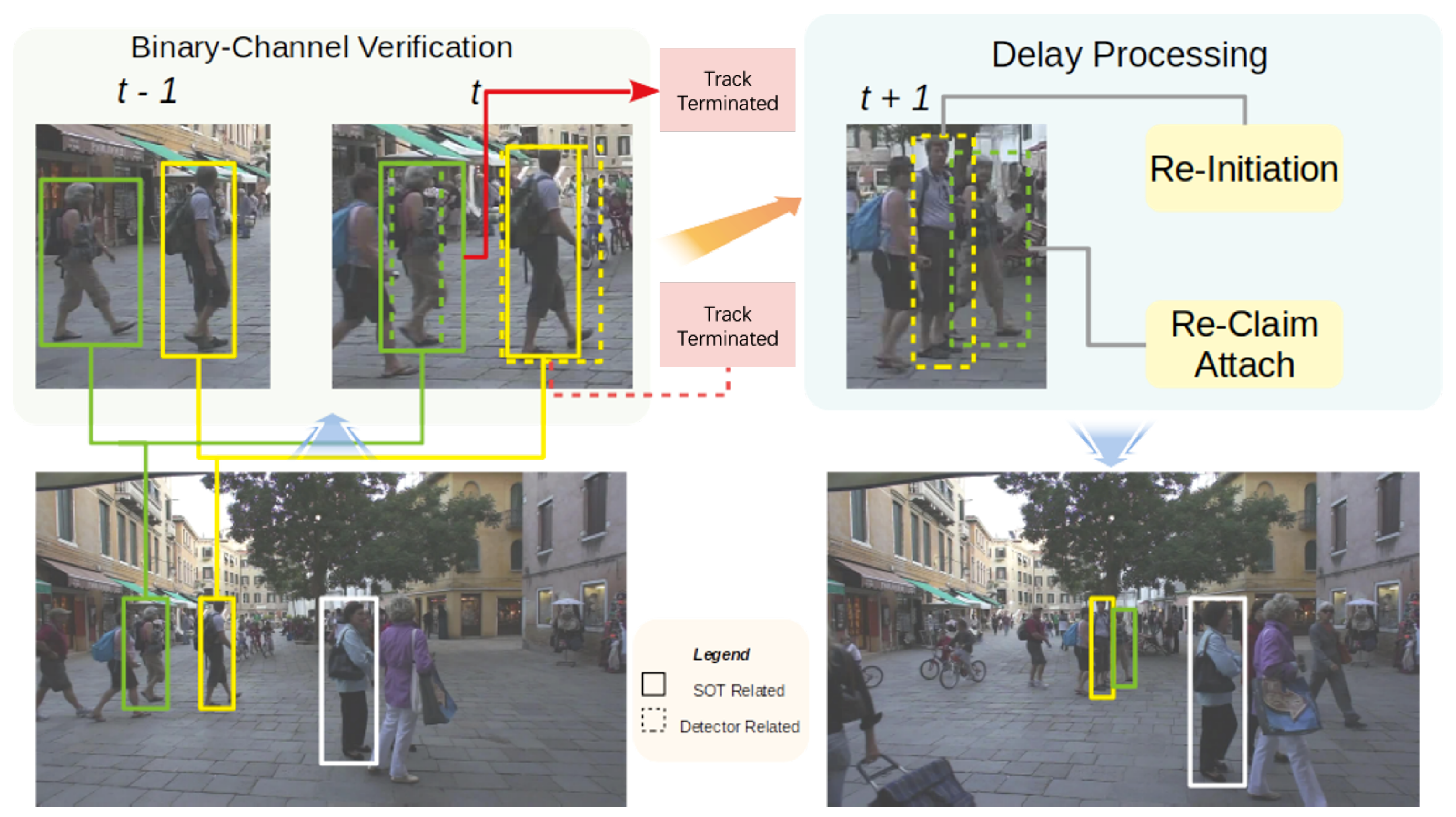
In this paper, we propose an integrated model with a binary-channel verification and delay processing model to tackle the aforementioned problems; see
Figure 2 for an outline. When a new frame comes in, SOT trackers produce two scores on both the predicting location given by the motion model (the same as processing under the SOT scenario) and the region of interest provided by the detection. Combined with the previous tracking score and the trajectory, the association model produces a refined bounding box. When occlusion happens, the association model proceeds as usual, then marks the frame ID where the occlusion happens and keeps the results for later processing. A delay processing model composed with three processing parts is proposed. First, for those tracks encountering the deformation problem (as in those with a low tracker score and low detection score), re-initiation discards the non-deformed features trained before and re-initiates with new features after determination by spatial information as the same object. Second, attaching for newly initialized tracklets during the occlusion period, re-correlates them with tracks lost in the same period and re-attaches them if the correlation score is above a certain threshold. Third, re-claiming, for unattached newly initialized tracklets after the attach phase, assigns them to existing tracks in shadow tracking mode, which means the object is tracked without any verification of detection through recent frames, if the re-correlation score and overlap rate (as in the Intersection over Union (IOU) score between the newly initialized tracklets and existing tracks for several frames) between them are above specified thresholds.
This paper thus presents three main contributions:
We propose a binary-channel verification model to deeply excavate the potential of applying SOT under a MOT scenario, specifically in refining the representation while maintaining the identities of the objects during the tracking process.
We introduce a delay processing model to improve the tracker capability of solving the drift problem under occlusion and object interaction.
We explore the proposed method on the MOT17 benchmark and perform an ablation study of each block, showing the comparable performance on result-refinement and ID consistency, and proving each block of our proposed method is indispensable.
This paper is organised as follows.
Section 2 briefly reviews the state-of-the-art for computer vision-based object tracking. The details of our proposed method are described in
Section 3. The experimental study and benchmark evaluation are then reported in
Section 4. Finally,
Section 5 concludes this paper and describes opportunities for future research.
3. Methodology
3.1. Overview
An overview of our proposed approach is shown in
Figure 2. Following the tracking-by-detection paradigm, the online MOT can be formulated as an optimization problem. Trajectories in the set
are forked by the bounding boxes
of every object in the past frames. At frame
t, the set of the objects’ locations
of the previous frame
t-1 are associate with the
detection candidates to maximize a final score:
Here,
denotes the final association results between the
k-th object in
B and the
j-th detection in
D at frame
t.
indicates that the association of track
k and detection
j is valid, while
otherwise. Furthermore,
means that frame
t is in a complex environment and the association result needs to be post-process by the delay processing model.
is a set of parameters to model each object’s state, including previous information, deformation, and interaction status, which is learned using the appearance and location information through previous frames. The function
calculates the overall results of the tracking procedure for all the existing objects at frame
t, defined as follows:
Therefore, solving the online MOT problem is done by solving Equation (1) from frame to frame.
3.2. Binary-Channel Verification Model
A binary-channel verification model is proposed to improve the quality of the state estimation as function of each object. For each object in frame t, a function is learned to separate the object itself from the background information by assigning a high score to it, while returning low scores for the background. The parameter is set to choose the best correlated spatial location from on object k exclusively to one object only referring to scores from all objects. Regarding different states of incoming tracks, ongoing tracks and occluded tracks, this model can operate on those two tracking states in a similar way with some slight changes.
The function
, as in the state estimation, is the first step to process the incoming frame. An ordinary single object tracker is initialized by the object groundtruth bounding box in the first frame where a certain object existed, and is slowly and constantly updated. However, in MOT, the tracker is initially learned from detections provided by an external detector which contains considerable noise with respect to the location. Moreover, if the object moves closer or away from the viewing point, the scale of the object will also change rapidly. Hence, implementing a single object tracker under a MOT scenario without any supervision will easily lead to identity switches or catastrophic mis-track problems. Benefiting from the tracking-by-detection paradigm, detection can play the role of the supervisor for the tracker. During the state estimation process, we rewrite the function as:
For subsequent tracks,
estimates the score
on the previous location containing the object
k (we assume the object has moved only slightly between frames, which is verified by high frame rates), while
calculates the score
on the location of the detection
j within the search area using the same trained single object tracker.
shows the confidence of the estimated bounding box provided by the tracker as well as the probability of the object
k’s existence in the current frame, while
gives the similarity between the detection
j and the object
k. The output bounding box can be assigned as follows:
Here,
is based on previous tracking information,
represents the bounding box of the same object in the previous frame and
for the bounding box of the
j-th detection in the current frame. Also, results with an untrack mark will be sent to the memory waiting for future re-claim, in order to save computational resources. For occluded tracks,
, since it did not exist, the estimation of the object should take place at a search area provided by the motion model instead of the previous location, for which we follow the constant velocity assumption (CVA) [
21,
22] with a camera motion compensation by calculating the motion information of highly trusted objects’ motion trends.
We take advantage of the idea of the non zero-sum game [
27], where scores calculated on the estimation of the tracker and associated detection push each other from frame to frame with the concept that the result can be optimized as long as one of them shows a promising result, in order to better refine the output bounding box and increase the quality of online training samples added to the tracker at each frame. In this way, the single object tracker and the detection can be complementary to each other and improve the performances of each other along the tracking process.
3.3. Delay Processing Model
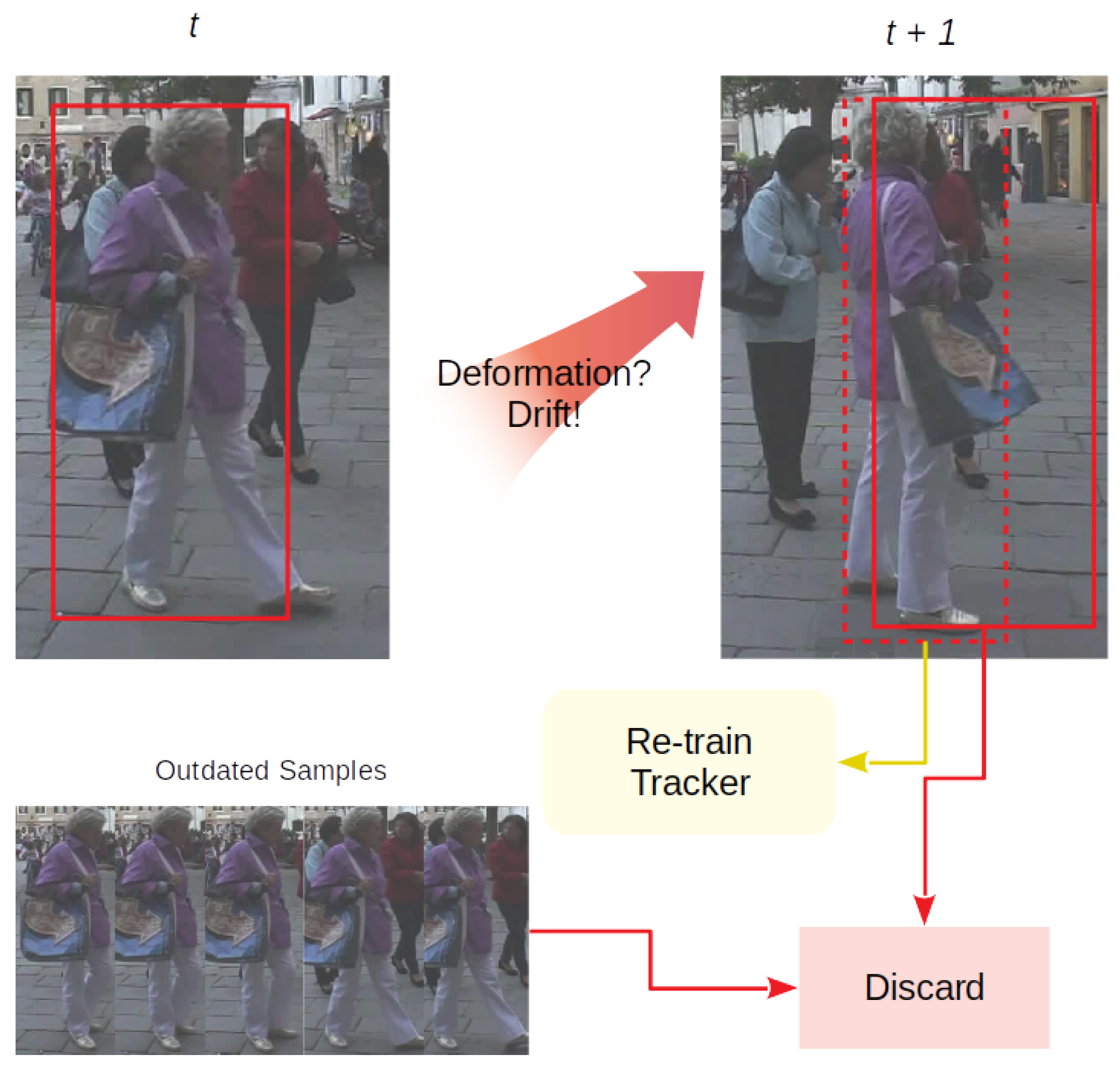
SOT methods are designed to distinguish the object from the background and allow a certain degree of deformation to handle appearance variation of the object. This mechanism will easily lead to insensitivity of the tracker when distractions are similar to the object within the search area under the MOT scenario. Hence, directly pushing a SOT method to MOT may easily lead to drifting problems. To tackle the drifting situation caused by occlusion or instance interaction, we propose a delay processing model. The consequences of occlusion can be seen as three main circumstances:
Object deformation. This appears when and are at the same level but below the association threshold . This kind of circumstance is usually determined as lost by the single object tracker, which leads to the ID switch problem.
Object misalignment. Here the object track is assigned to a false detection with similar appearance and motion features, usually expressed as an abrupt change of location, receiving a reasonable estimation score and similarity score .
Doppelganger initialization. This occurs if the object experiences partial occlusion or slight variation of appearance, where the tracker finds a new location at the current frame without verification of any detection and keeps tracking for upcoming frames. Hence, a doppelganger track will be initialized using the detection supposed to be assigned to the object, causing an overlap problem.
The three circumstances set
is thus formed as follows:
Here, is set to 0.2. To solve the aforementioned problems, we propose a delay processing model consisting of three parts which specifically target those circumstances. Such model is not only able to avoid the noisy appearance features that might contaminate the training space of the single object tracker, but to change the update strategy of the tracker to ensure the tracking performance.
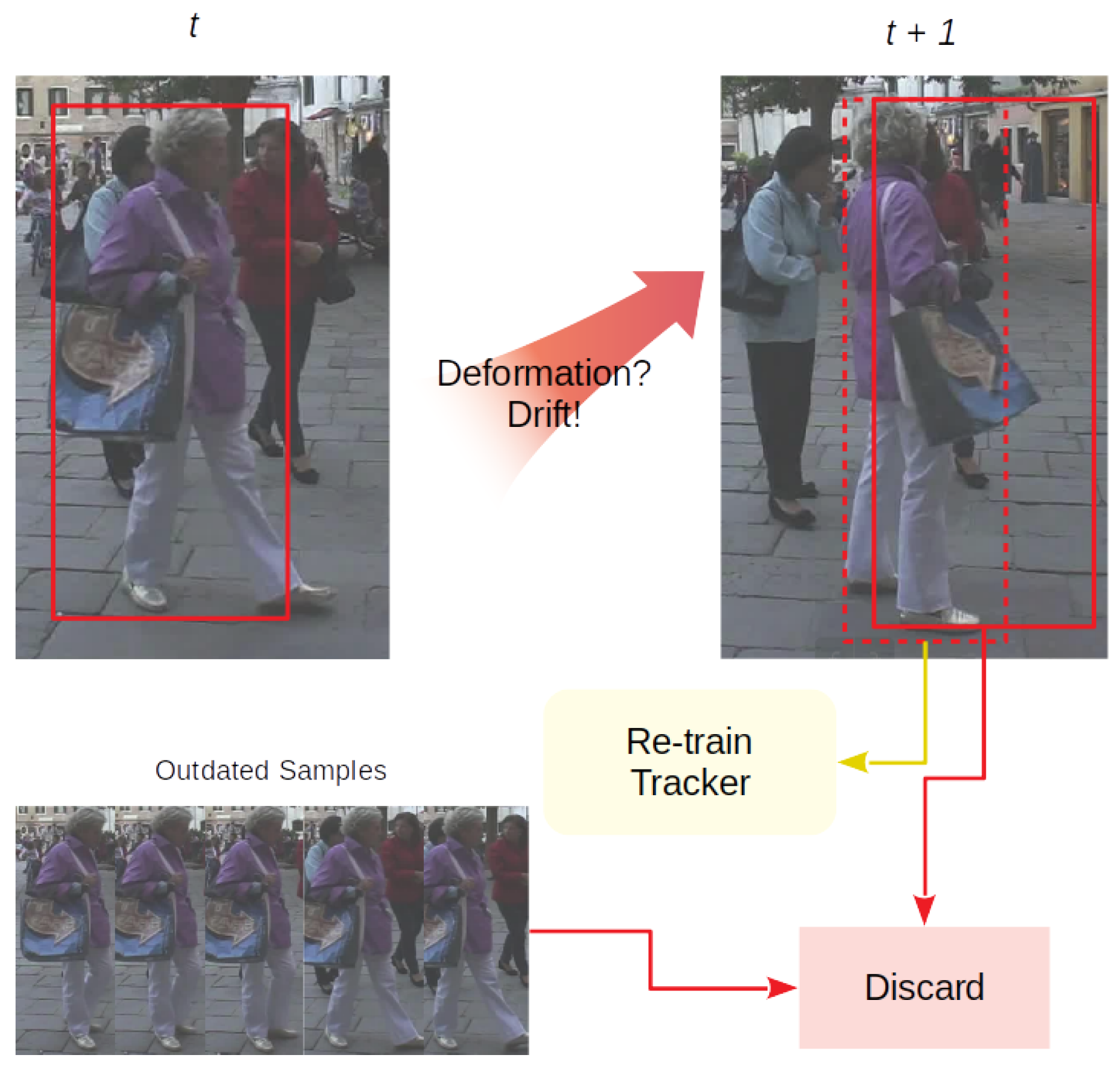
3.3.1. Re-Initiation
The first part is called Re-Initiation, as shown in
Figure 3. When the object encounters the deformation problem,
e.g. a pedestrian turning around, appearance models tend to fail – including the single object tracker. It is non-trivial to rely on motion estimation model to determine the location with highest probability after occlusion for certain objects. We follow the constant velocity assumption and assume that the object’s velocity can not change abruptly through neighboring frames. If the object is retrieved by the motion model and validated by the single object tracker using an independent retrieving score
after several occlusion frames, the tracker discards the outdated non-deformate appearance features and re-initiates with new samples.
3.3.2. Attaching
The second part is named attaching (see
Figure 4). When an object is misaligned with a false detection, the appearance model of the single object tracker is still powerless, since distraction with a similar appearance and geometry can easily give the single object tracker an illusion which may lead to drift results. However, with the high frame rate of the sequence, we assume that the object has moved only slightly between frames. Following this assumption, misaligned distraction can be notified if the offset of the object between adjacent frames is beyond a noticeable score based on the recent motion trend. If this happens, the wrong association is discarded and the object is marked as occluded for now, waiting for later processing. When the occlusion stops, several new tracks may be initialized due to the above situation, the tracker will perform a second-time correlation between the new tracks and the occluded tracks labeled within the occlusion period, and assign new tracks if the re-correlation score
is higher than
.
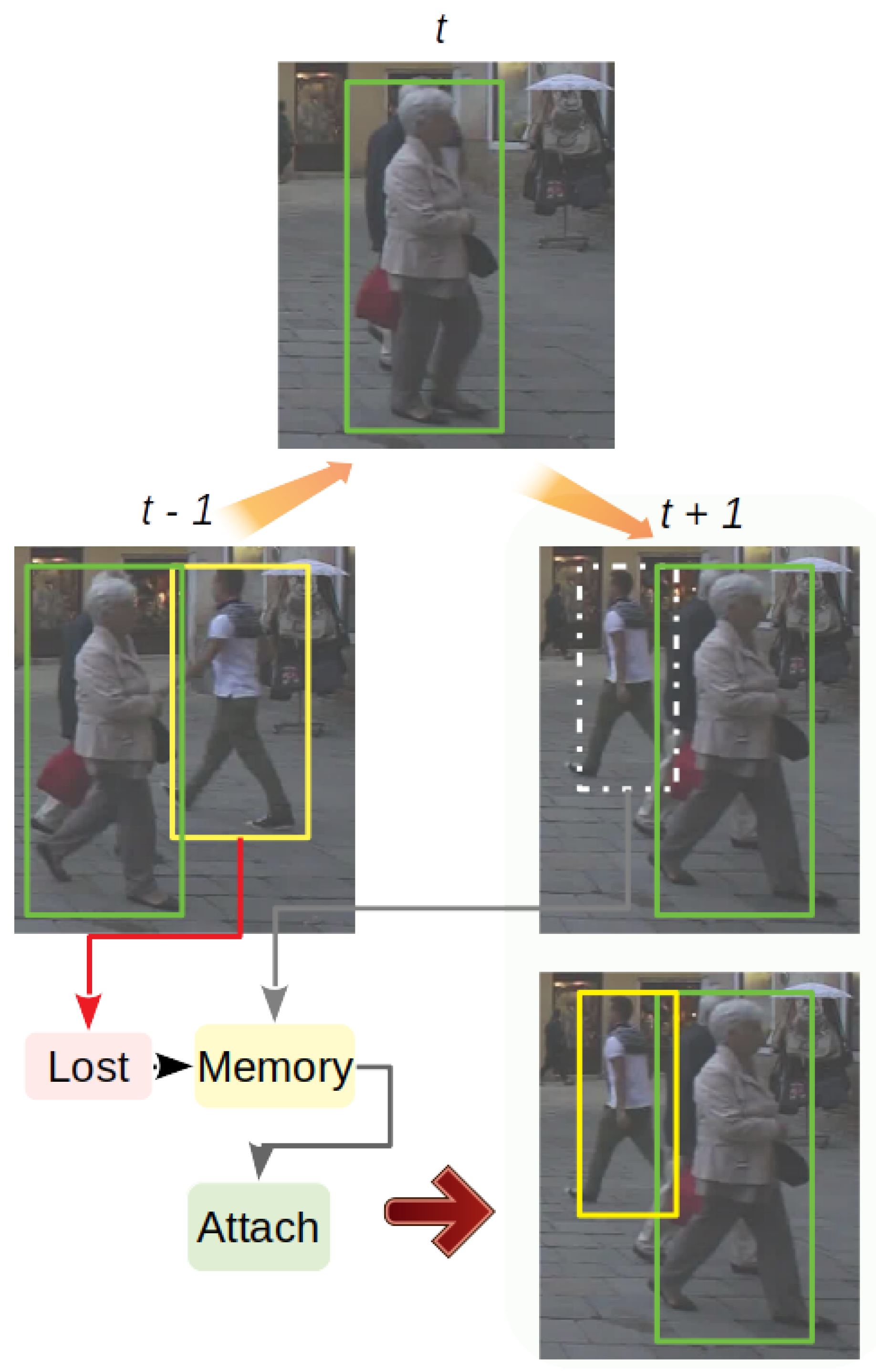
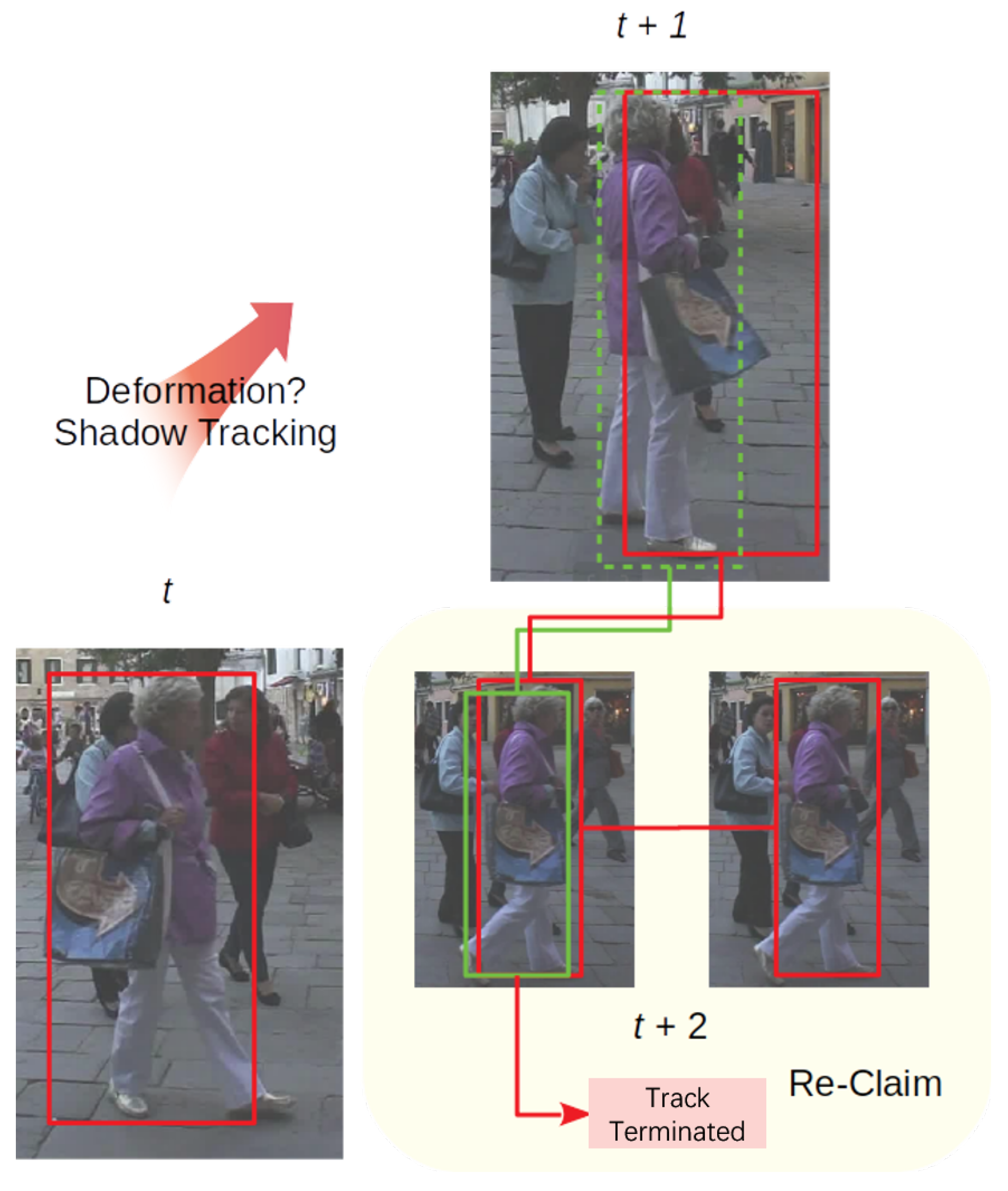
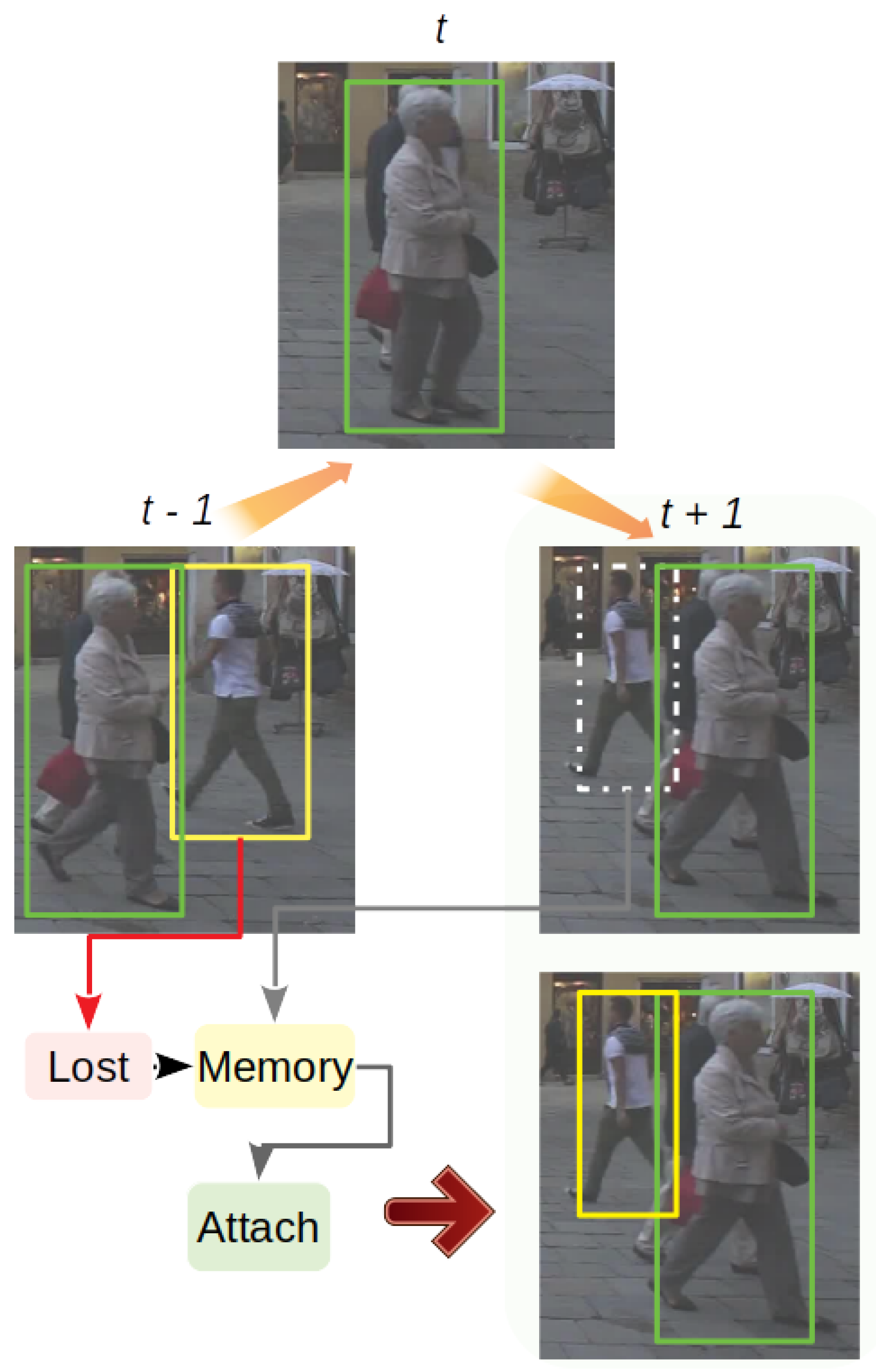
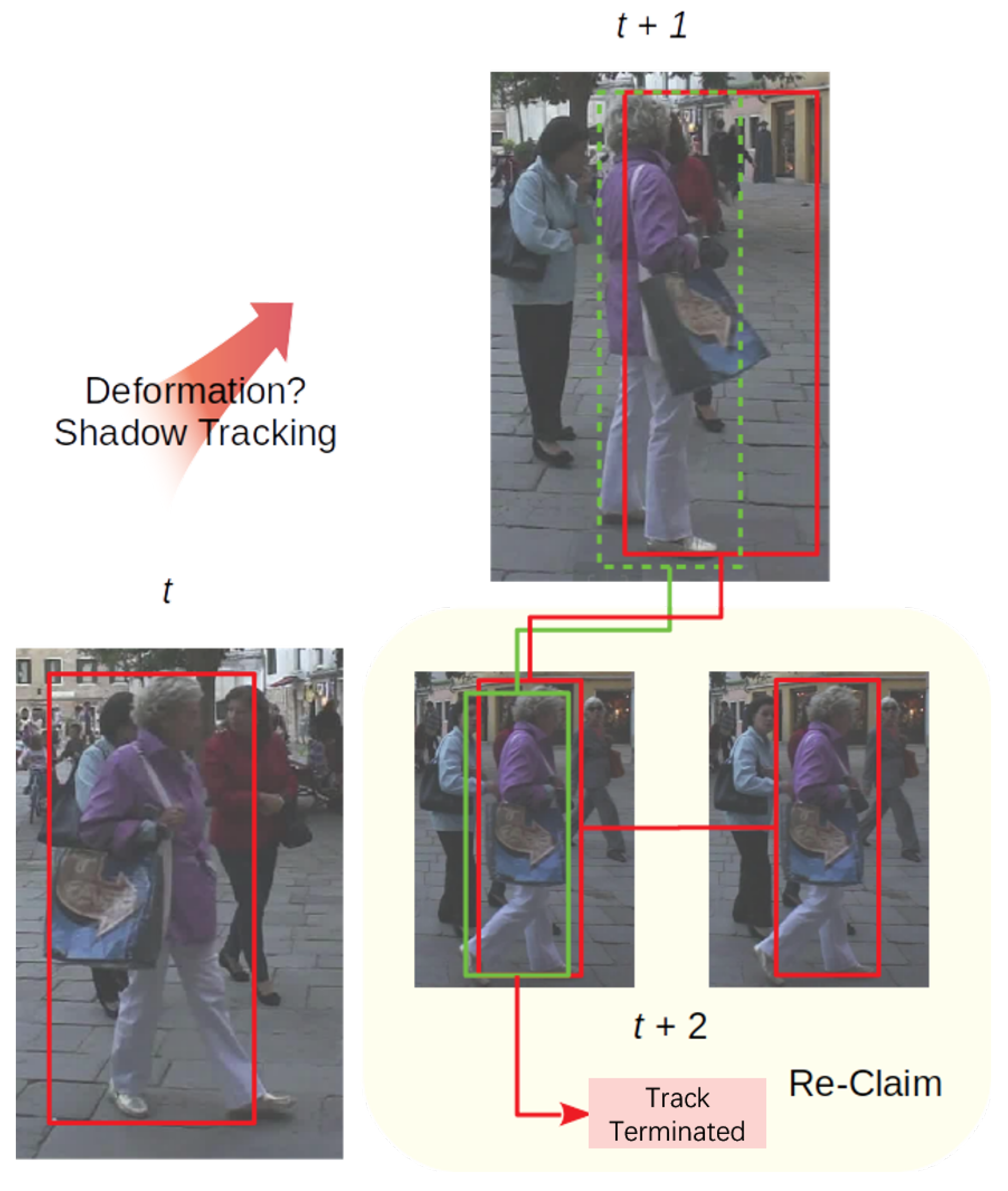
3.3.3. Re-Claiming
The third part, re-claiming, is a core procedure to retrieve occluded objects after messy frames as in
Figure 5. For all the objects in the shadow tracking mode, as lost verification of detection for recent frames, the re-claiming part also performs a second-time correlation between newly initialized tracks and shadow objects. Moreover, the model calculates the overlap rate between those new tracks and the shadow object. If the re-correlation score
and the overlap rate show that the new track is the doppelganger of the shadow object with a high probability, then the re-claiming phase chooses a more accurate bounding box from both tracks based on their tracking scores before, following a rule that each object can only appear a single time at a certain frame. One thing worth mentioning is that these kind of doppelgangers may be created by deformation or partial occlusion. This procedure can be viewed as a precaution in case of failures by the re-initiation part.
3.4. Initialization and Termination
The single object tracker heavily relies on the quality of the initialization bounding box in the first frame, which is usually hand picked in a SOT scenario. However, object candidates provided by an external detector under the current MOT framework are the only inputs to count on, though a high percentage of detections are imperfect in location and scale. We follow the argument in [
6], that trackability of an object is not only dependent on its visibility, but also its size. After analyzing visibility and size of each external detector, we set the confidence score threshold for initialization as
corresponding to Deformable part model (DPM), Faster Region-Convolutional Nueral Network (FRCNN) and Scale-Dependent pooling (SDP). The single object tracker is initialized using the detection results in set
left after pre-processing by the detection purification and filtering by
. As for track termination, since occluded objects will be saved in memory at every frame and trying to be re-established by the above procedures, the ones that can not be relinked for
frames are considered lost and removed from the memory to save computational resources.
3.5. Detection Purification
Detection plays an critical role in the tracking-by-detection paradigm. It is even more important when extending SOT methods to MOT as SOT relies much more on the quality of the detection results. Following the analysis of the detection in
Section 3.4, we perform a purification strategy on the detection set
. Firstly, we adopt non-maximum suppression (NMS) on the incoming frame. Then, we perform a strategy based on the assumption that detections in set
(which is the set of detections within the neighborhood of the
j-th detection) with a similar size, should be provided a similar score by the same detector as in the following:
Here, is set to 0.2. With the two-step aforementioned cleaning strategies, detection results with low confidence and incomplete bounding boxes will be ruled out by the tracker.
4. Experiments
We perform an experimental study of the aforementioned models and further show that our models can tackle drift results when extending SOT to MOT, while maintaining tracking performance. We then demonstrate the tracking performance of our proposed method on the MOT Challenge dataset focusing on pedestrian tracking.
4.1. Implementation Details
We adopt the efficient convolution operator (ECO) tracker [
3] as our single object tracker. ECO addresses computational complexity and over-fitting problems in state-of-the-art discriminative correlation filters (DCF) trackers by presenting a factorized convolution operator and a compact generative model of the training sample distribution. Due to the significantly increasing computational complexity when applying a single object tracker to a MOT scenario, we choose the faster version of ECO using hand craft features (histogram of oriented gradients (HOG) [
31] and colour names (CN) [
32]).
The proposed method is implemented in Python running on a desktop with Intel
® Core™ i7-3930K @ 3.20GHz CPU. With the implementation of the binary-channel verification model and the delay processing model, the average speed of the proposed method on the MOT17 dataset is about 1.72 fps, which is acceptable compared with other state-of-the-art methods including LSST17 (offline) [
33] at 1.5 fps, and DMAN (online) [
34] at 0.3 fps. The average densities on each frame of the MOT17 training set and test set are 21.1 and 31.8 persons per frame, respectively.
The widely accepted clear MOT metrics [
35] are adopted to evaluate the performance of our method, including multiple object tracking accuracy (
MOTA) and multiple object tracking precision (MOTP), computed from false positives (
FP), false negatives (
FN) and the identity switch (
IDs) as Equation (7). The calculation of aforementioned metrics are as follows:
Here
is the bounding box overlapping hypothesis
i with its assigned ground truth object, and
denotes the number of matches in frame
t. The
MOTA score takes into account the number of times a tracker makes an incorrect decision. However, under some circumstances the ability to track the identities of objects is also worth measuring. In [
35] it is introduced the mostly tracked (
MT), mostly lost (
ML), and ID F1 (
IDF1) scores to measure the performance of a tracker for those abilities. The computation of the
IDF1 score is formed as follows:
Here, IDTP is the number of true positive ID matches. This can be seen as the percentage of detections correctly assigned in the whole sequence. IDFN is the number of false negative ID matches, and IDFP denotes the sum of false positive IDs.
4.2. Dataset
We adopt the multi-object tracking benchmarks MOT17 to evaluate our tracking performance. It consists of several challenging pedestrian tracking sequences, with a significant number of occlusions and crowded scenes, varations in angle of view, sizes of objects, camera motion, and frame rates. MOT17 has the same video sequences as the lastest MOT16 [
23] challenge benchmark, but provides more accurate ground truth in the evaluation. In addition to DPM [
24], Faster-RCNN [
25] and scale dependent pooling (SDP) [
26] detections are also provided for evaluating the tracking performance. The number of trajectories in the training data is 546 and the number of total frames is 5316. The complexity of the tracking problem requires several metrics including multiple object tracking accuracy (
MOTA), most tracked (
MT), ID F1 score (
IDF1) and so on. Specifically, the
MOTA and
IDF1 scores quantify two of the main aspects: object coverage and identity. Also, we perform all the experiments using the public detections provided by the MOT Challenge for fair comparison. The single object tracker of our method is only initialized and online trained from public detection bounding boxes.
4.3. Tracking Performance
Evaluation Results on the MOT17 Datasets
Evaluation of our method is performed on the test set of the respective benchmark, without any training or optimization on the training set. The overall results accumulated over all sequences are shown in
Table 1, including three sets with different public detectors in MOT17. Although our method does not show the state-of-the-art
MOTA, high performance in both
IDF1 and
MT metrics proves that our method can manage object ID consistently. This is what we aimed for. Specifically, most tracked (MT) and identity preserving (
IDF1) (which compares groundtruth trajectory and computes trajectory by a bipartite graph, and reflects how long of a object has been correctly tracked) prove the effectiveness of our method on ID preserving, which outperform the other online trackers on MOT17. Different from online methods, offline methods do have both future and past information to further optimize the status of each object, which is usually expressed by a better overall performance. Despite this, our method still shows competitive ability on ID preserving, which is reflected by the
IDF1 and
MT results. The overall results prove the ability of our methods to preserve the identity of objects. By adding another location estimation, provided by the single object tracker, as a second verification, the quality of the objects’ representation is increased. Also the delay processing model helps in tackling the occlusion problem, which leads to better maintaining of the objects’ identity after occlusion or deformation.
To further illustrate the effectiveness of our method on results refinement and object ID preserving, we carefully select other online methods with a similar number of
FP and
FN (which leads to a similar
MOTA score) with ours, since ID consistency metrics are critically affected by FP and FN. According to
Table 2, our method shows the best
IDF1 and
MT results with the same level of
FP and
FN, which proves our method’s ability of maintaining the objects’ identities in a similar environment. As for ID switches metrics, our method only achieve the second best results in
Table 2, which is because most of the switches occur when using the SDP detector, which has additional small detections. For smaller detections, feature representation of the single object tracker is coarse. Thus, correlation filters do not perform well when handling occlusion and deformation. Since our method performs online tracking, using future information to refine trajectories is not an option either.
Figure 6 shows some of the visualization tracking results of our method under different circumstances. Specifically MOT17-03 and MOT17-08 represents static camera and crowded surveillance, while MOT17-07 and MOT17-14 show a moving camera. Each frame is chosen for their complexity that can show the performance of our method well.
4.4. Ablation Study
For better understanding the effectiveness of each building block of our method, we ablate each part from the whole method and compare with a baseline which directly introduces the single object tracker within the MOT scenario, marked as the baseline in each table below. The analysis of performance is carried out on the MOT17 benchmark train set, and each study is conducted separately on the different external detectors (DPM, FRCNN, and SDP) provided by the dataset.
4.4.1. Binary-Channel Verification for Bounding Box Refinement
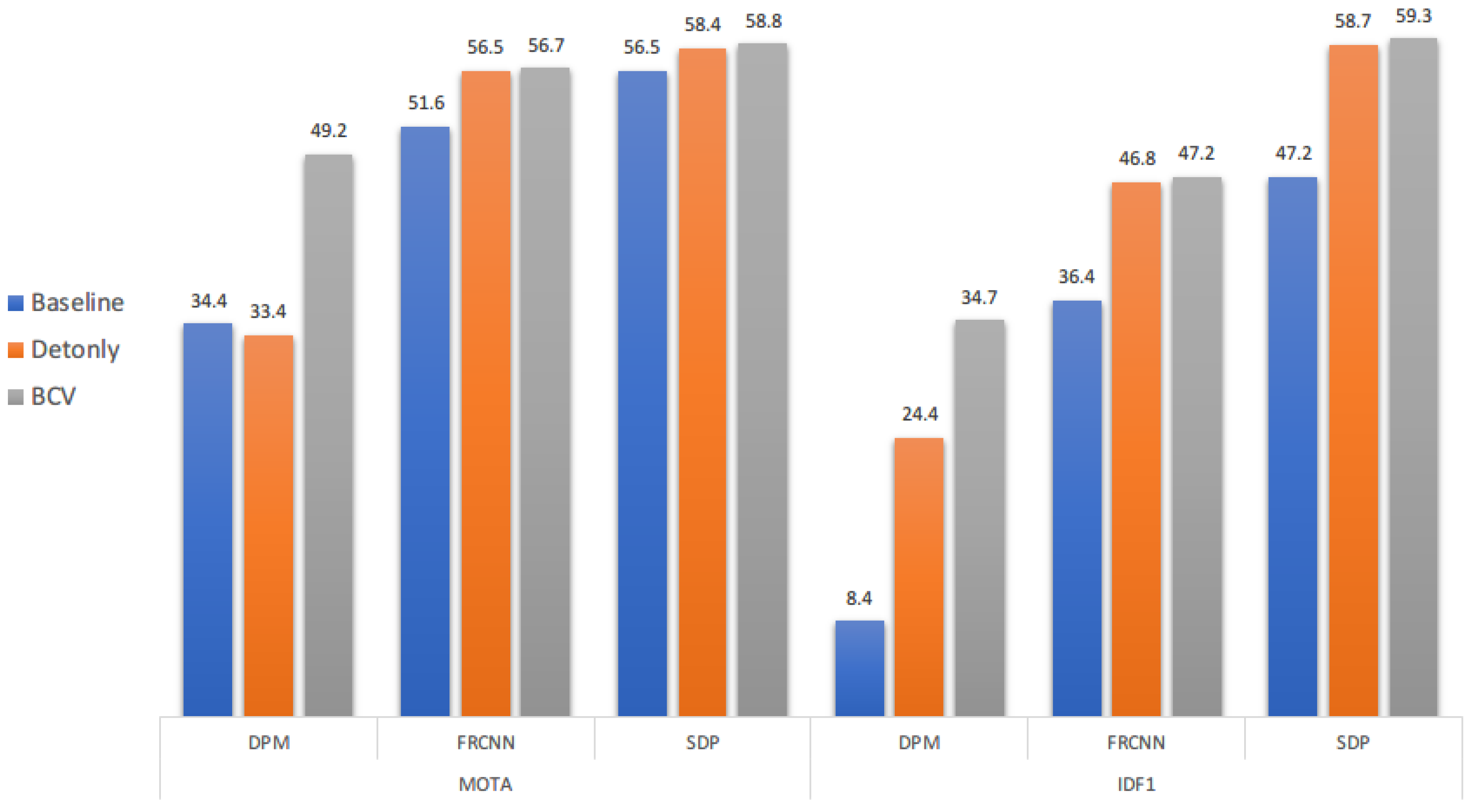
We show the effectiveness of our binary-channel verification (BCV) model within our proposed method based on the aforementioned baseline in
Figure 7, denoted by BCV. We select the
MOTA and
IDF1 metrics to evaluate the overall performance and the ID preserving ability. For both metrics, BCV shows significant improvements of performances on the DPM detector, while there is a relatively small cap between using the detection only and our BCV model on the FRCNN and SDP detectors. The reason for this is most likely the different quality of detection results provided by each detector. The DPM detector tends to have much more noise and usually produces partial detection under complex scenes, such as crowded and occluded environments for objects. On the other hand, BCV is able to increase both metrics for our baseline method, which is the single object tracker using only, where detection is only used to retrieve the object when occlusion happens. By introducing BCV, a clear increase of
IDF1 and
MOTA shows that detection can help the tracker not only to better recognize each object during tracking, but also to optimize the training samples for the single object tracker that may lead to maintaining the identity of each object as long as possible. In this way, detection and the single object tracker may easily complement each other to achieve a better performance than using only one of them.
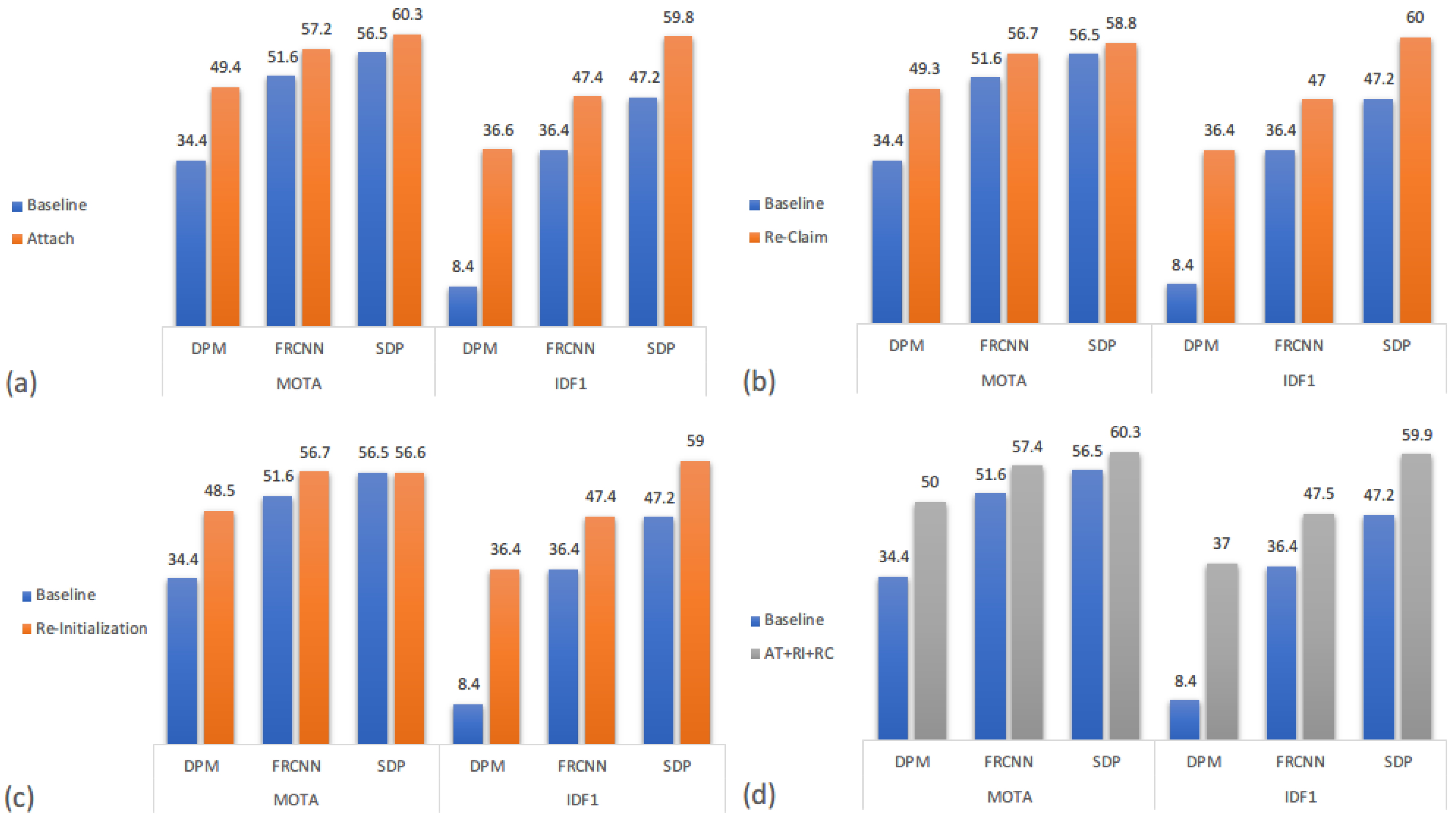
4.4.2. Delay Processing Model
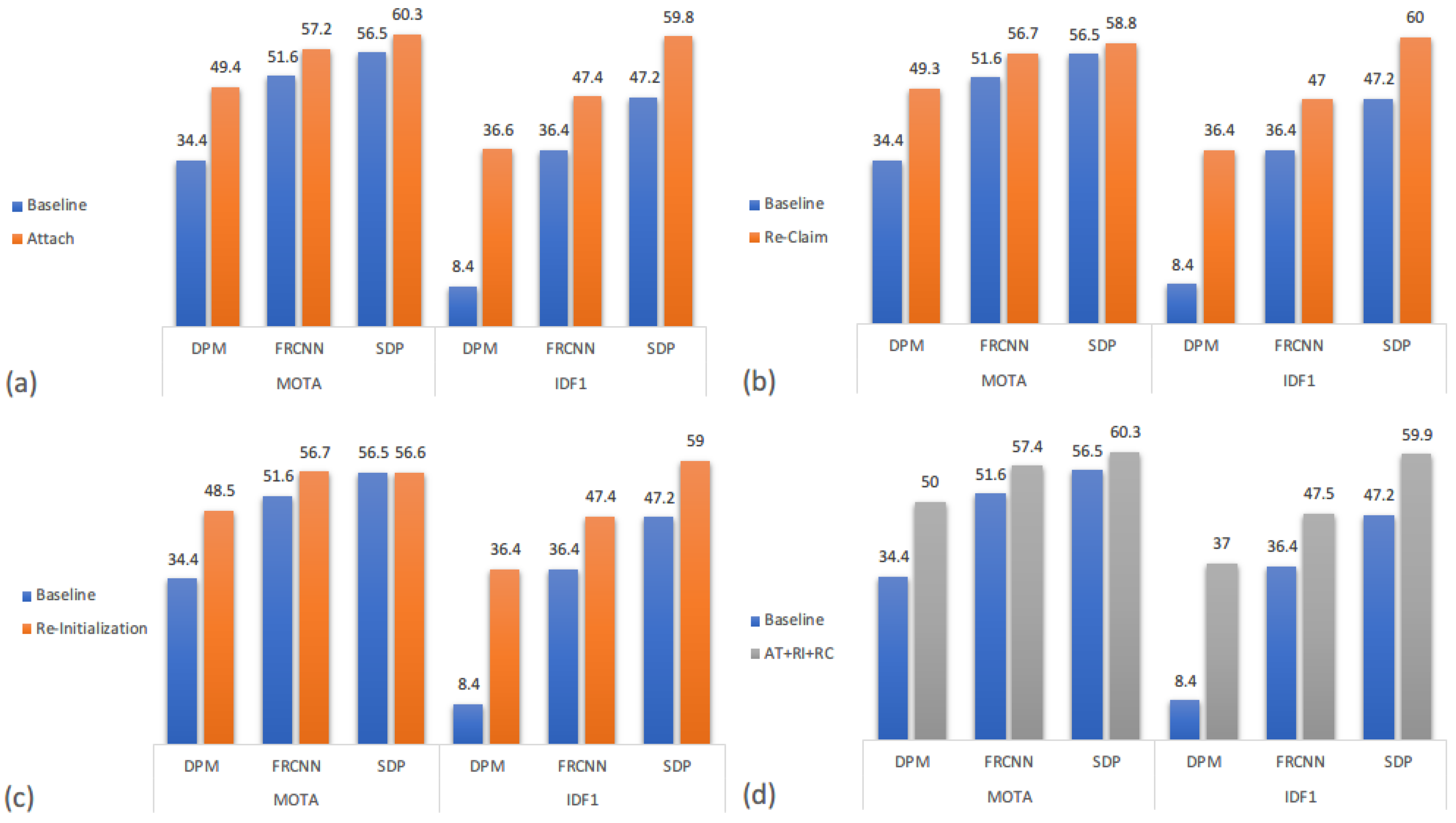
We separate the three parts of the delay processing (DP) model, and using the same metrics mentioned before to analyze how much each part contributes to the overall performance. Quantitative results of each part only along with integrated model are shown in
Figure 8, where baseline indicates simply applying SOT in MOT, the same as in
Figure 7. From
Figure 8a–c, we can see that different parts of the DP model shows approximately the same effect on the baseline method, the quantitative increment of each part is more of the same. Base on that, one can easily presume that merging those three parts together should improve the performance enormously. However, as shown in
Figure 8d, the overall performance of our DP model just slightly increases the quantitative results. That is because although these three parts are for three different circumstances, these circumstances can happen to the same object and emerge as different situation for the following frames. For instance, facing occlusion, one may continue tracking in shadow mode and cause a doppelganger problem, or completely stop, or even deform. Thus, either one part of the DP model could have solved the situation after several frames when we separate three parts, still tracking the same object as a result. Though the overall performance does not show a promising result as we expected, each part is non-trivial for the whole DP model, like icing on the cake. One can fill in the blank space while others ignore.
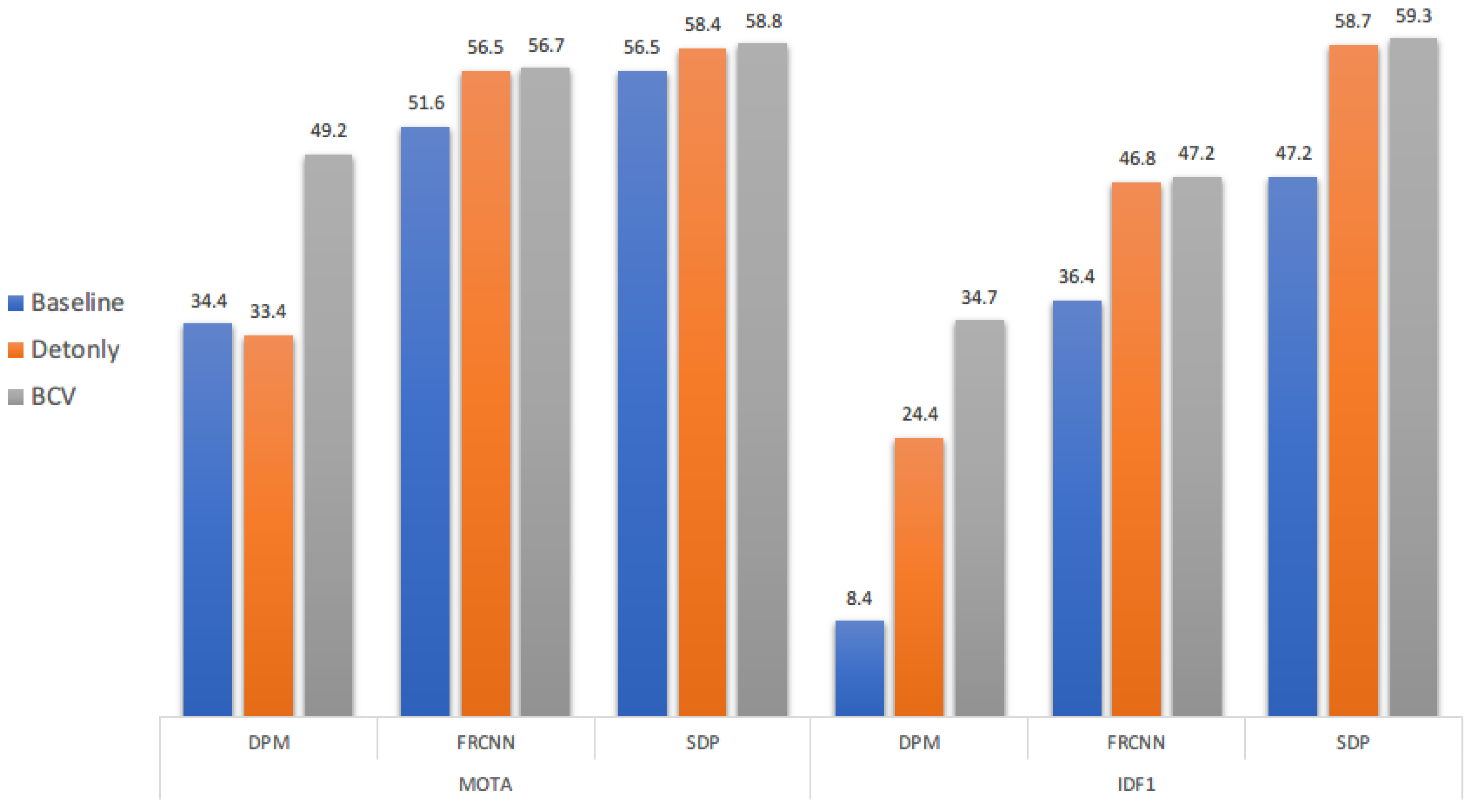
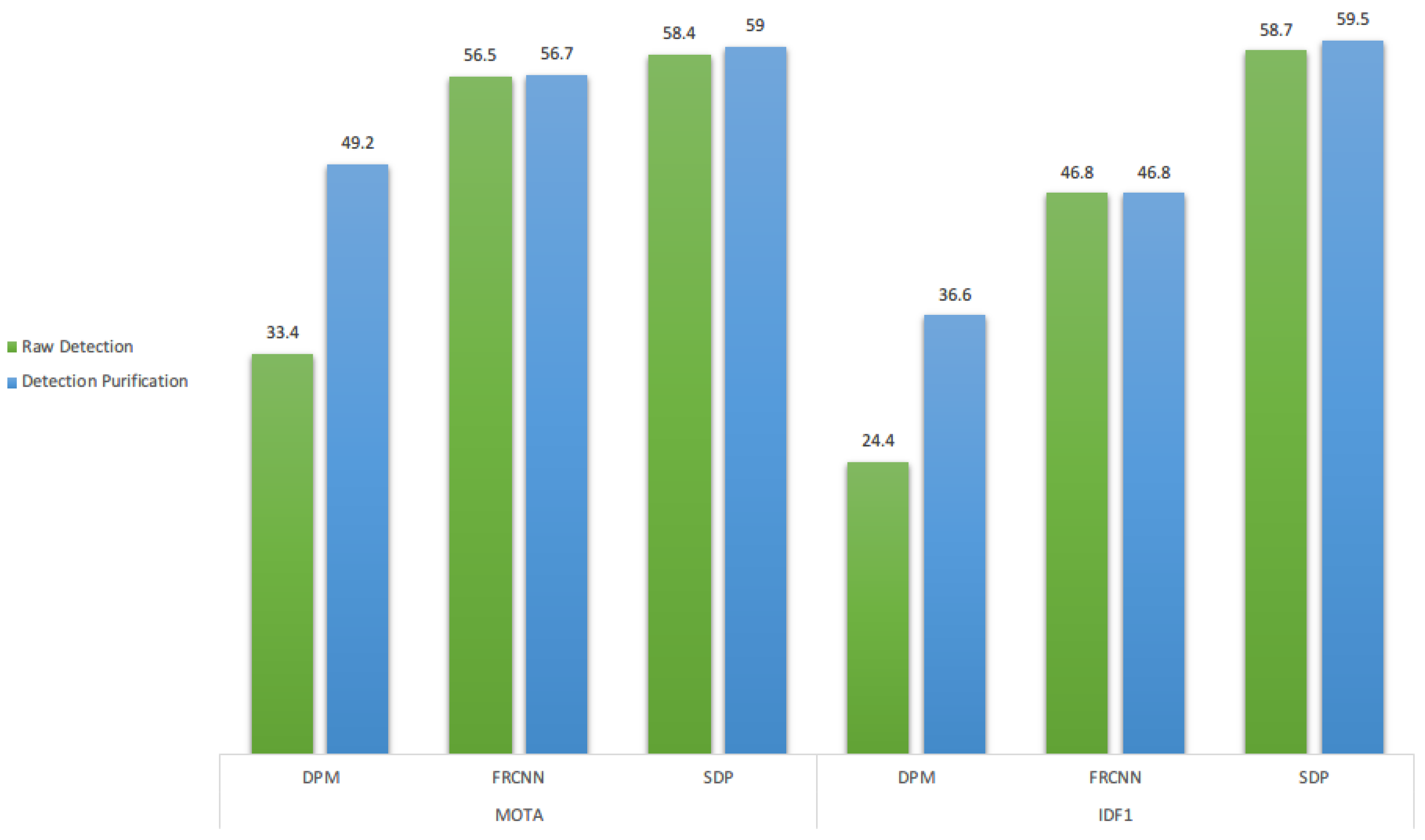
4.4.3. Detection Purification
Detection quality yields an important factor which influences the performance of the single object tracker, since it is critical during initiation and online training throughout the whole tracking procedure. By separating our detection purification strategy with the proposed method, we can tell the effectiveness of the detection quality in tracking.
Figure 9 shows the results of our purification strategy for detection. Following the argument in [
6], that the SDP detector has additional small detections and thus has less
FN samples, which boosts the single object tracker since the tracker itself can impossible initialize from a location that the external detector is incapable of providing. We can see this purification strategy affects most the DPM detector which shows the necessity of our detection purification.
5. Conclusions and Future Work
In this paper, we proposed a SOT-based MOT method in order to increase the accuracy of tracking results focusing on ID preservation. We introduce a binary-channel verification model using a separate single object tracker and detection provided by an external detector equally. Moreover, a delay processing model is proposed to handle the drift problem that easily emerges when applying a single object tracker under a MOT scenario. Our method outperforms other state-of-the-art methods on the MOT17 benchmark according to the IDF1 and MT metrics, which proves our method is capable of preserving identity consistency when dealing with occlusion. Finally, we have shown some qualitative results under different hard-to-solve circumstances.
Though a re-initialization part is implemented in the delay processing model to handle geometry changes of certain objects, tracking objects with significant deformation after occlusion still remains unsolved since appearance features are mostly dissimilar for a tracker to reclaim the object. In our future work, we plan to train a generative model for the tracker to better recognize deformations of the same object without misalignment with other distraction information including similar objects.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}