Enhanced Multistream Fast TCP: Rapid Bandwidth Utilization after Fast-Recovery Phase


Abstract
:1. Introduction
2. Background
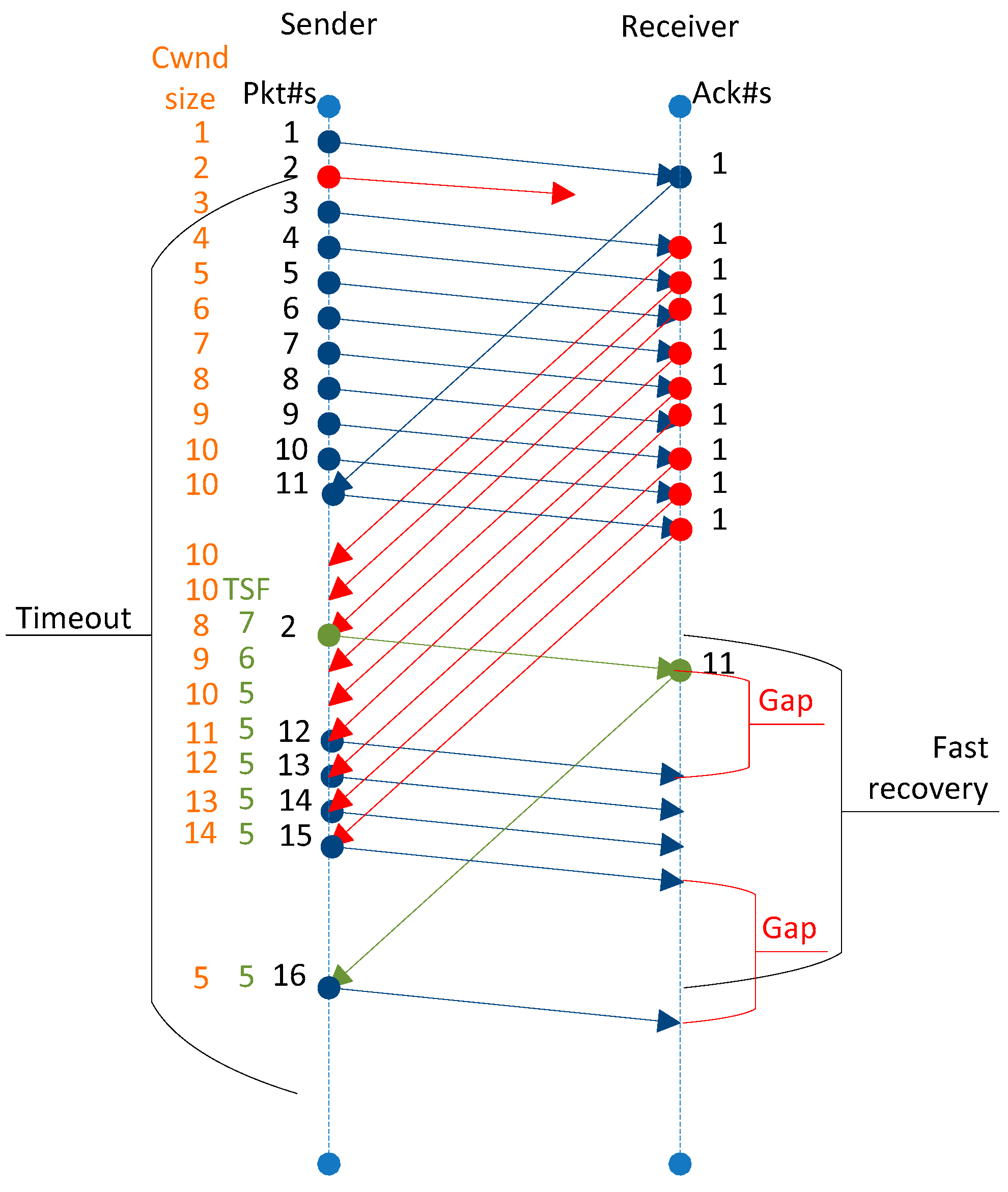
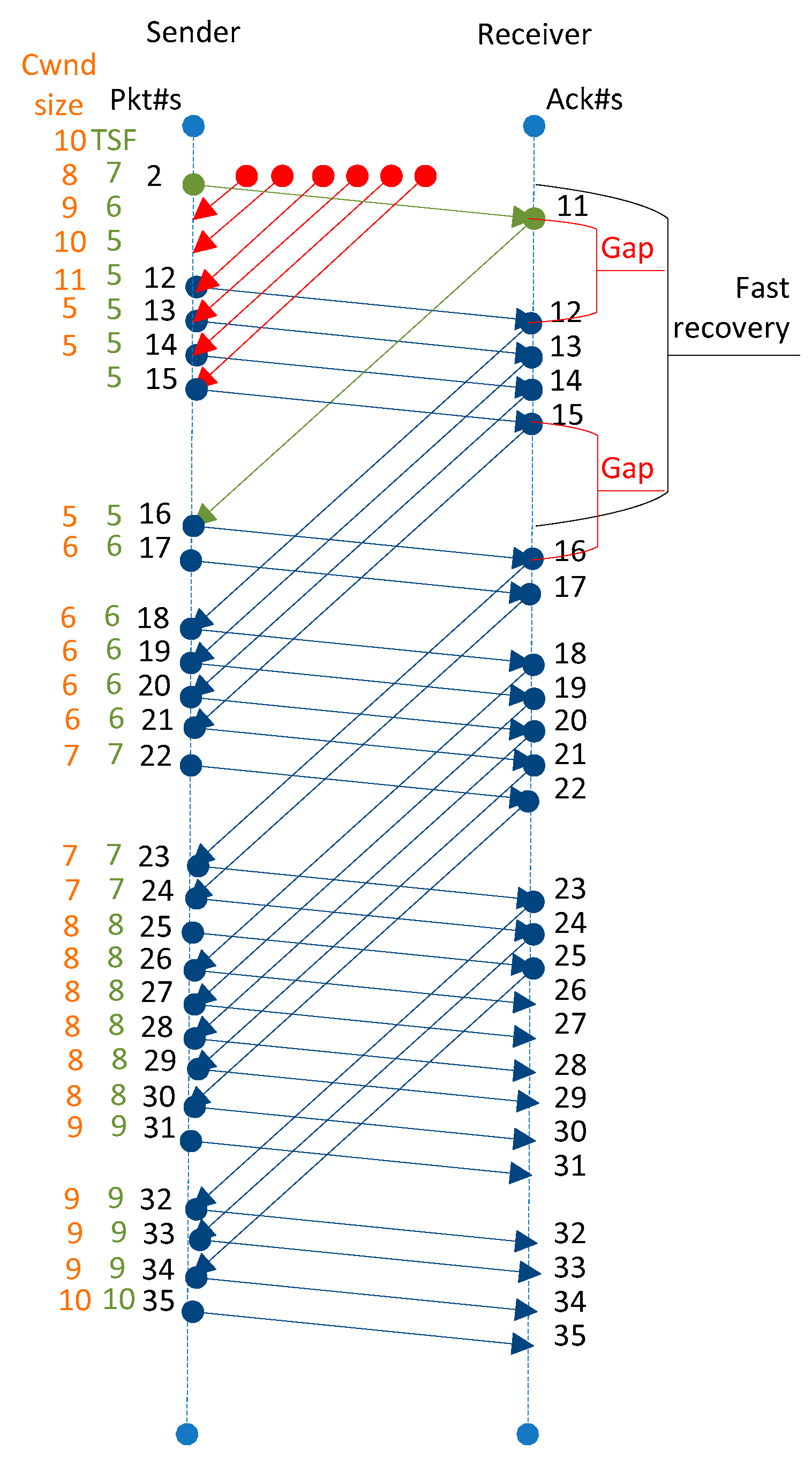
3. Enhanced Multistream Fast TCP (EMFast TCP)
Congestion Control after Fast-Recovery Algorithm (CCaFR)
| Algorithm 1. Growth of congestion window on receipt of each ACK in CCaFR. | |
| Input: (AckPacket, rtt) | |
| Output: cwnd_ | |
| 1 | IF isAFRmode = true THEN |
| 2 | IF avgIPD = IPD and avgRTT = rtt THEN |
| 3 | isAFRmode ← false |
| 4 | gapflag ← false END IF |
| 5 | IF gapflag = true THEN fast_cc_afr(rtt, old_pif) ∇ change cwnd as per its default delay-based scheme |
| 6 | ELSE cwnd_ = cwnd_ + 1/cwnd_ END IF |
| 7 | IF avgIPD = IPD THEN gapflag ← true; |
| 8 | END IF ELSE |
| 9 | fast_cc(rtt, old_pif) ∇ change cwnd as per its default delay-based scheme after each RTT END IF return cwnd_ |
- Did the protocol just exit from the fast-recovery mode? If so, then introduce new segments in the network to increase the congestion window.
- If the average inter-packet delay is equal to the inter-packet delay of the received segment and the average round-trip-time is equal to the round-trip-time of the received segment, it means the protocol has consumed all the available bandwidth of the network link. Therefore, it is appropriate to quit isAFRmode and let the protocol operate in normal mode.
- Set the value of isAFRmode to false so that on receipt of the next segment, the protocol does not execute the CCaFR algorithm.
- Gapflag is the pointer to detect the gap between the series of segments, being received on the sender’s end.
- If the first series of the segment has already been received and the protocol is now receiving the second series of segments, then use the protocol’s default formula to compute the cwnd based on the information of received segment’s RTT and old packets inflight. The function fast_cc_afr is used to compute the congestion window on receipt of each acknowledgment.
- If the first series of the segments are being received by the sender, then increase its congestion window using additive-increase formula. This technique is used here to provide sufficient time to the network to clear its congestion.
- If the average inter-packet delay is equal to the inter-packet delay of the received segment, then the gapflag value is set to true so that the protocol could increase its congestion window by using its delay-based formula.
- Body of if condition given at line 1 ends here.
- Now, the protocol is in normal congestion avoidance phase. Therefore, it is calling fast_cc function that is a part of Fast TCP implementation. This function calculates congestion window after every round-trip-time (RTT). This is the normal behavior of the protocol.
4. Simulation Setup
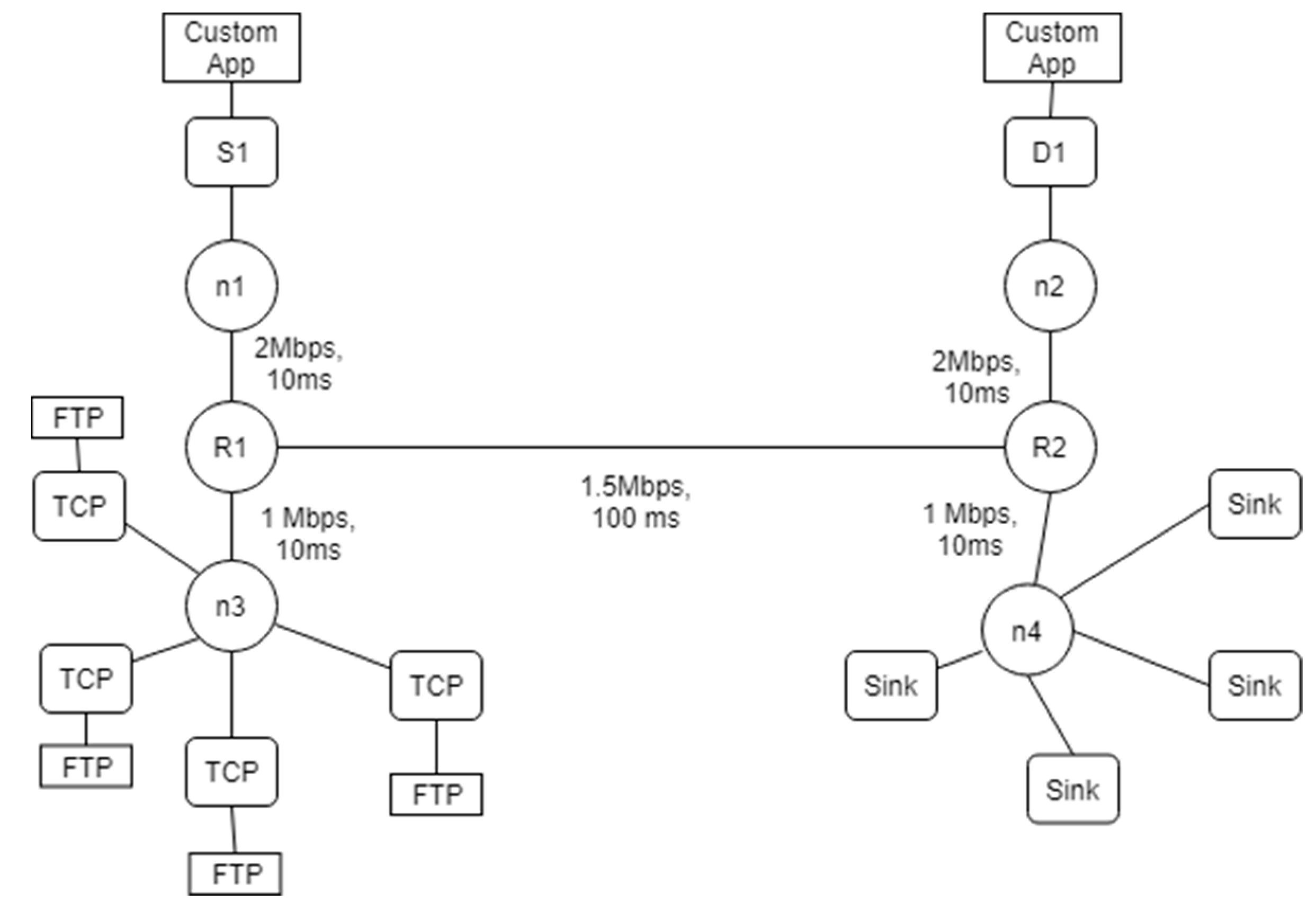
4.1. Experimental Setup and Network Topology
4.1.1. Network Topology
4.1.2. Evaluation Method
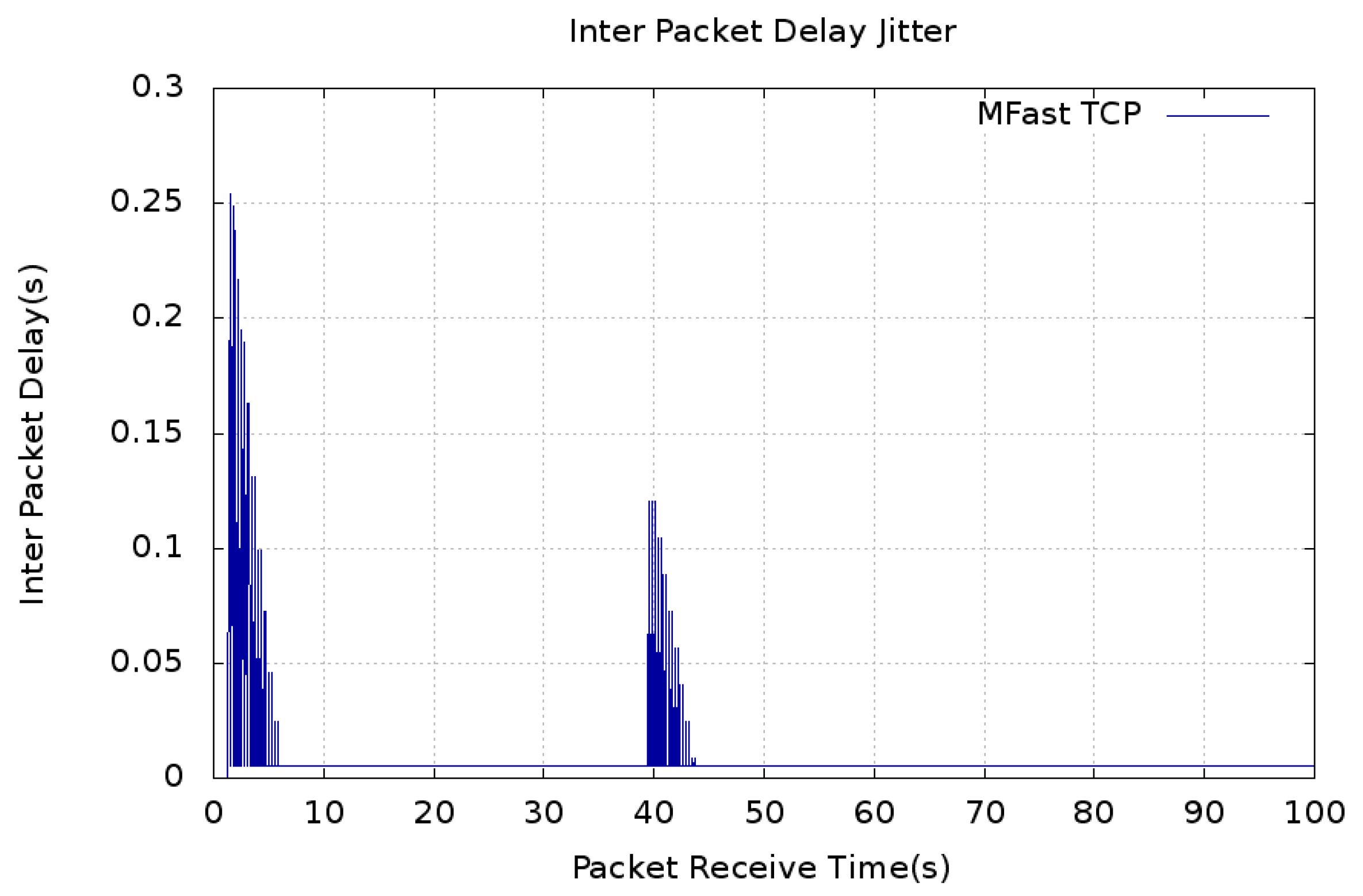
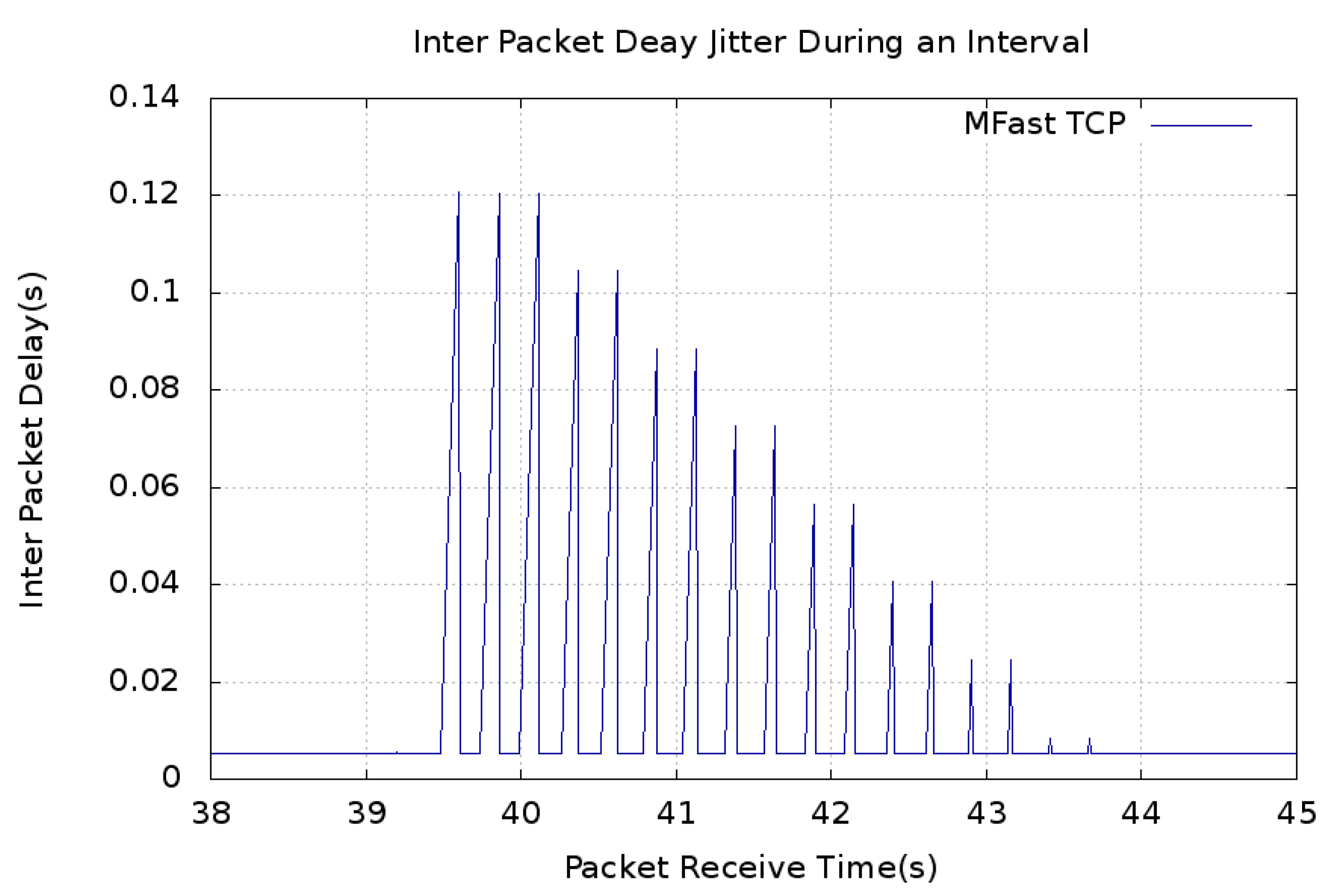
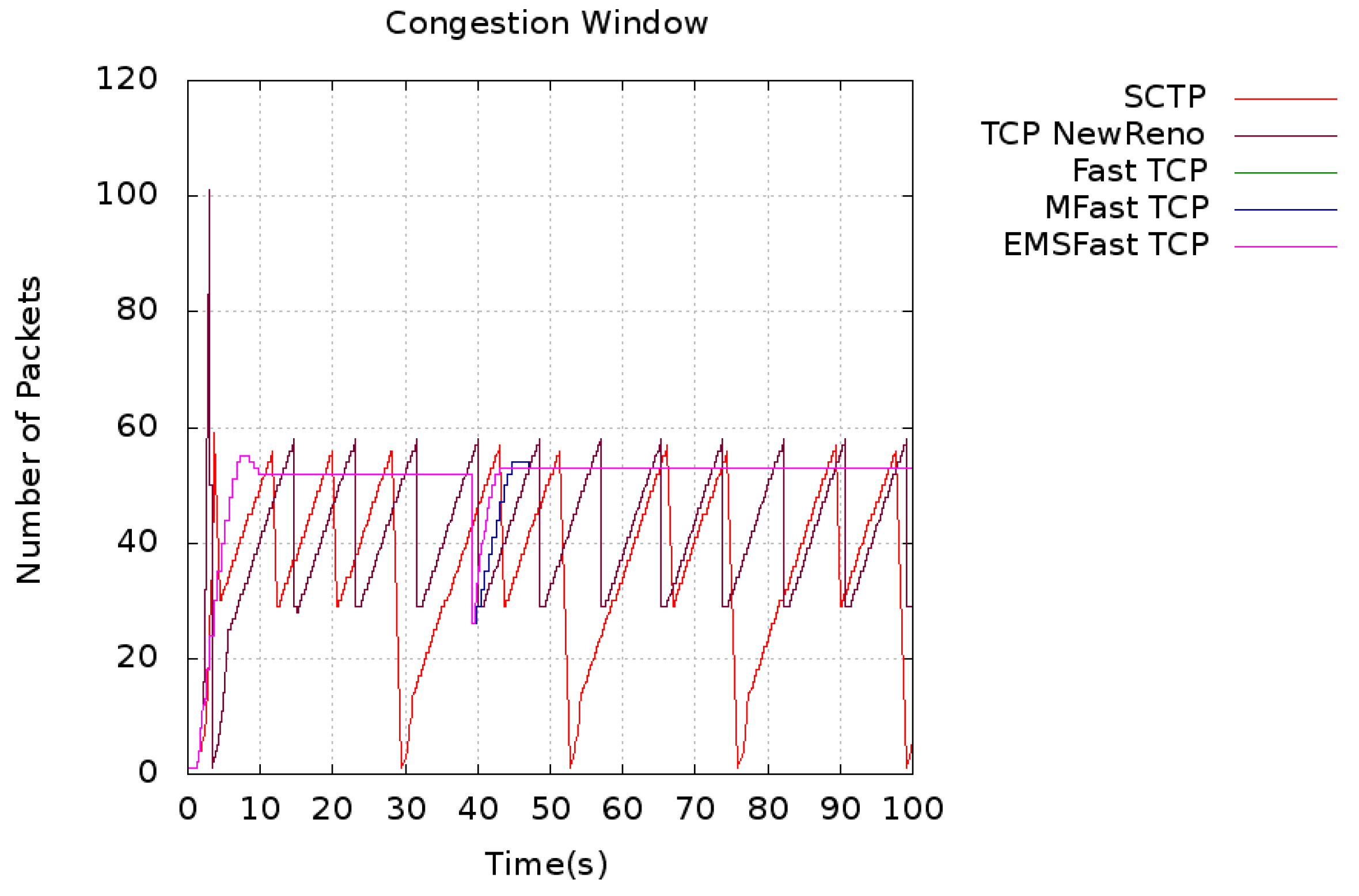
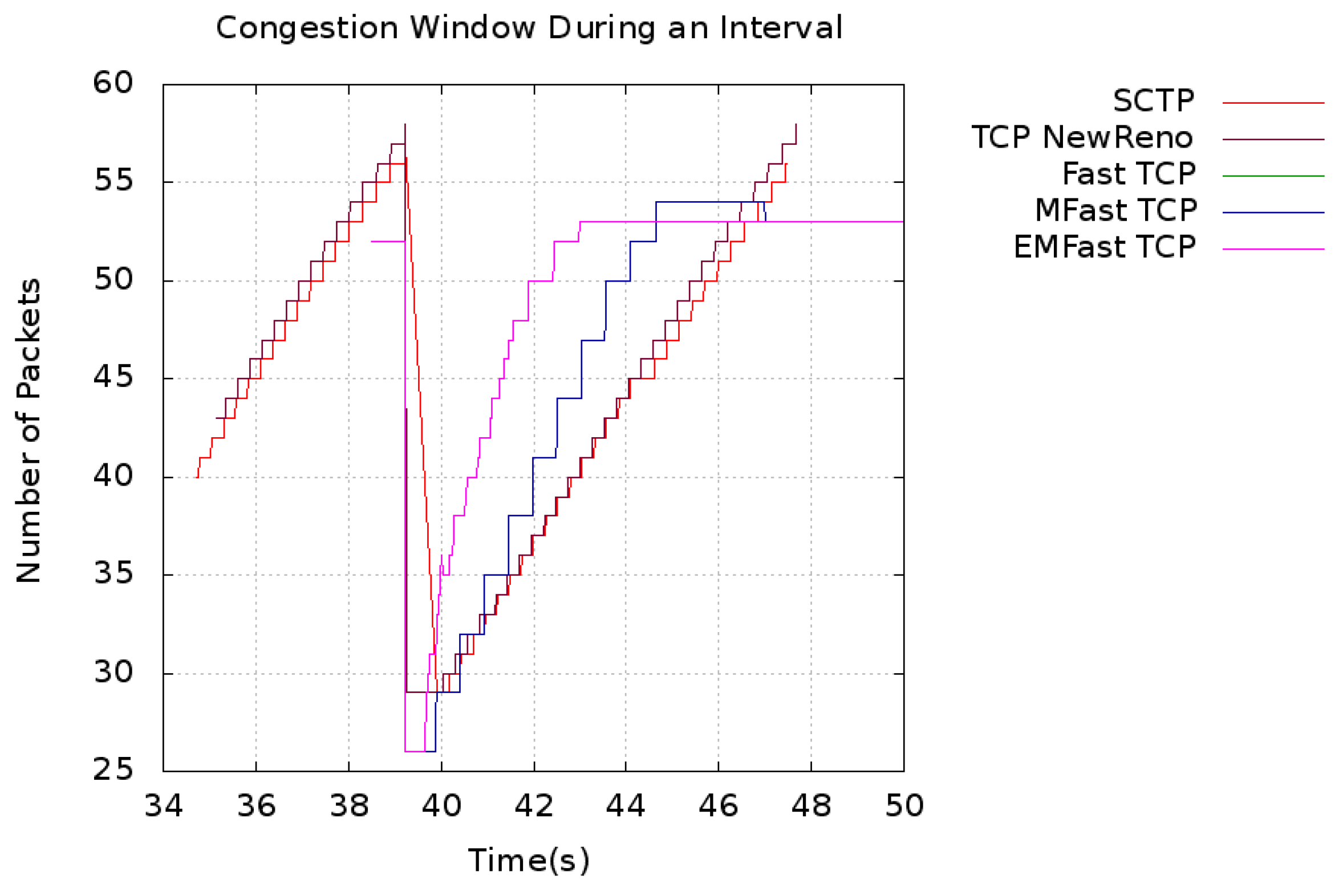
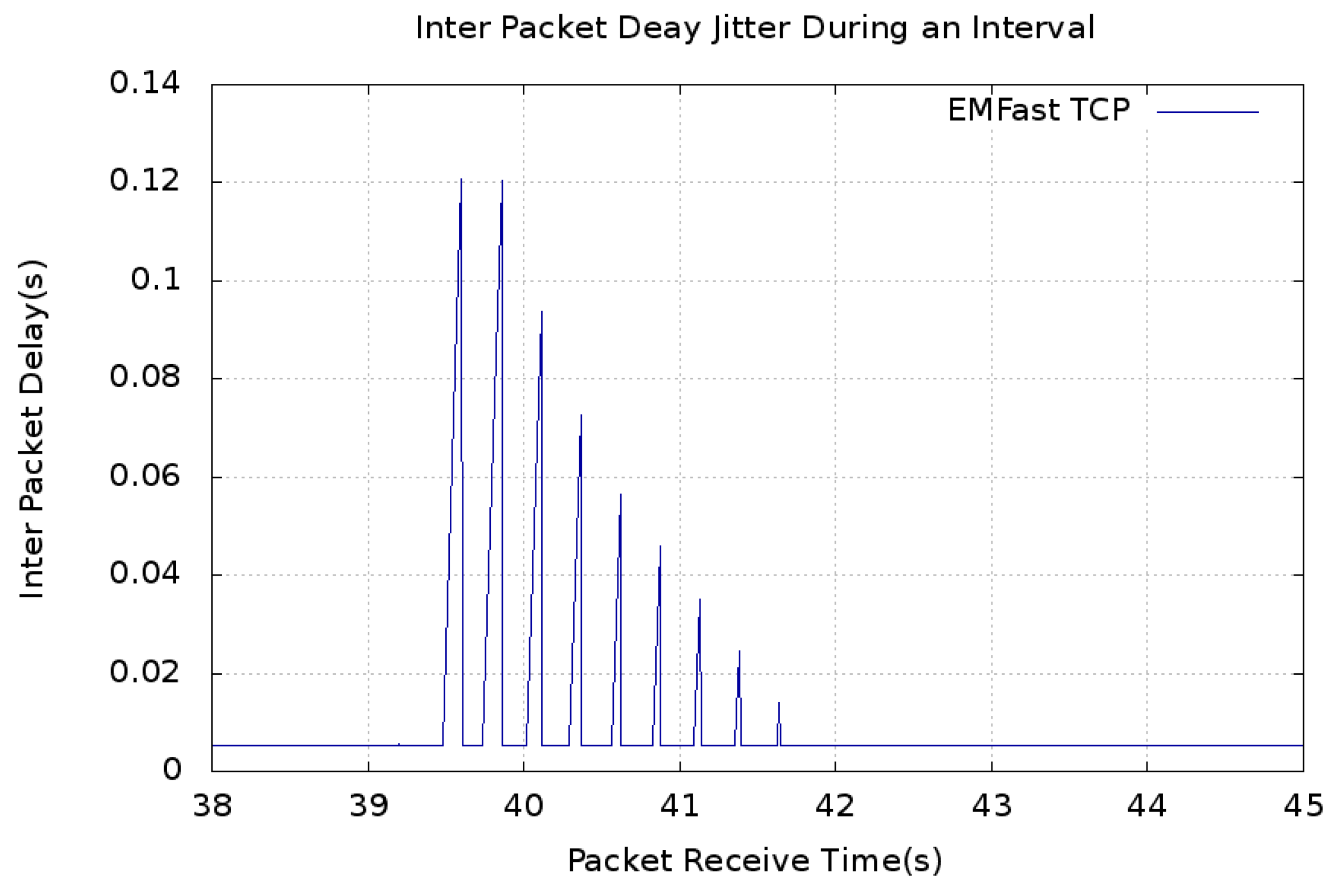
5. Results and Discussion
5.1. Convergence Time
5.2. Throughput
5.3. Goodput
5.4. Fairness Index
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Postel, J. Transmission Control Protocol; RFC-793; Internet Engineering Task Force (IETF): Fremont, CA, USA, 1981. [Google Scholar]
- Shivaranjani, M.; Shanju, R.; Jude, M.J.; Diniesh, V.C. Analysis of TCP’s micro level behaviour in wireless multi-hop environment. In Proceedings of the IEEE International Conference on Computer Communication and Informatics (ICCCI), Coilmbatore, India, 7 January 2016. [Google Scholar]
- Jacobson, V. Congestion avoidance and control. ACM SIGCOMM Comput. Commun. Rev. 1988, 18, 314–329. [Google Scholar] [CrossRef]
- Jacobson, V.; Braden, R.; Borman, D.; Satyanarayanan, M.; Kistler, J.J.; Mummert, L.B.; Ebling, M.R. TCP Extensions for High Performance; RFC 1323; Internet Engineering Task Force (IETF): Fremont, CA, USA, 1992. [Google Scholar]
- Mathis, M.; Mahdavi, J.; Floyd, S.; Romanow, A. TCP Selective Acknowledgment Options; RFC 2018; Internet Engineering Task Force (IETF): Fremont, CA, USA, 1996. [Google Scholar]
- Hoe, J.C. Improving the start-up behavior of a congestion control scheme for TCP. In Proceedings of the Applications, Technologies, Architectures, and Protocols for Computer Communications (SIGCOMM ‘96), Palo Alto, CA, USA, 28–30 August 1996. [Google Scholar]
- Allman, M.; Paxson, V.; Stevens, W. TCP Congestion Control; RFC 2581; Internet Engineering Task Force (IETF): Fremont, CA, USA, 1999. [Google Scholar]
- Henderson, T.; Floyd, S.; Gurtov, A.; Nishida, Y. The NewReno Modification to TCP’s Fast Recovery; RFC 6582; Internet Engineering Task Force (IETF): Fremont, CA, USA, 2012. [Google Scholar]
- Stevens, W. TCP Slow Start. Congestion Avoidance, Fast Retransmit, and Fast Recovery Algorithms; RFC 2001; Internet Engineering Task Force (IETF): Fremont, CA, USA, 1997. [Google Scholar]
- Jin, C.; Wei, D.; Low, S.H.; Bunn, J.; Choe, H.D.; Doylle, J.C.; Newman, H.; Ravot, S.; Singh, S.; Paganini, F.; et al. FAST TCP: From theory to experiments. IEEE Netw. 2005, 19, 4–11. [Google Scholar]
- Brakmo, L.S.; Peterson, L.L. TCP Vegas: End to end congestion avoidance on a global Internet. IEEE J. Sel. Areas Commun. 1995, 13, 1465–1480. [Google Scholar] [CrossRef]
- Wei, D.X.; Jin, C.; Low, S.H.; Hegde, S. FAST TCP: Motivation, architecture, algorithms, performance. IEEE/ACM Trans. Netw. (ToN) 2006, 14, 1246–1259. [Google Scholar] [CrossRef]
- Varvello, M.; Schomp, K.; Naylor, D.; Blackburn, J.; Finamore, A.; Papagiannaki, K. Is the web http/2 yet? In Proceedings of the Springer International Conference on Passive and Active Network Measurement, Heraklion, Greece, 31 March 2016. [Google Scholar]
- Awan, S.A.; Arshad, M.J. Enhancing Fast TCP’s Performance Using Single TCP Connection for Parallel Traffic Flows to Prevent Head-of-Line Blocking. IEEE Access 2019, 7, 148152–148162. [Google Scholar]
- Singh, A.K. A survey on congestion control mechanisms in packet switch networks. In Proceedings of the IEEE International Conference on Advances in Computer Engineering and Applications, Ghaziabad, India, 19 March 2015. [Google Scholar]
- Ahmad, M.; Hussain, M.; Abbas, B.; Aldabbas, O.; Jamil, U.; Ashraf, R.; Asadi, S. End-to-End Loss Based TCP Congestion Control Mechanism as a Secured Communication Technology for Smart Healthcare Enterprises. IEEE Access 2018, 6, 11641–11656. [Google Scholar] [CrossRef]
- Ho, C.Y.; Chen, Y.C.; Chan, Y.C.; Ho, C.Y. Fast retransmit and fast recovery schemes of transport protocols: A survey and taxonomy. Comput. Netw. 2008, 52, 1308–1327. [Google Scholar] [CrossRef]
- Fall, K.; Sally, F. Simulation-based comparisons of Tahoe, Reno and SACK TCP. ACM SIGCOMM Comput. Commun. Rev. 1996, 26, 5–21. [Google Scholar] [CrossRef]
- Awan, S.A.; Arshad, M.J.; Muhammad, S.S. Analysis of FAST TCP for Multiple-Streams Implementation. Univ. Eng. Technol. Taxila Tech. J. 2017, 22, 136. [Google Scholar]
- Koo, K.; Choi, J.Y.; Lee, J.S. Parameter conditions for global stability of FAST TCP. IEEE Commun. Lett. 2008, 12, 155–157. [Google Scholar]
- Wang, J.; Wei, D.X.; Choi, J.Y.; Low, S.H. Modelling and stability of FAST TCP. In Wireless Communications; Springer: New York, NY, USA, 2007. [Google Scholar]
- Stewart, R.; Xie, Q.; Morneault, K.; Sharp, C.; Schwarzbauer, H.; Taylor, T.; Rytina, I.; Kalla, M.; Zhang, L.; Paxson, V. Stream Control Transmission Protocol; RFC 2960; Internet Engineering Task Force (IETF): Fremont, CA, USA, 2000. [Google Scholar]
- Jin, C.; Wei, D.X.; Low, S.H. The case for delay-based congestion control. In Proceedings of the 14th International Conference on Ion Implantation Technology, Dana Point, CA, USA, 20–21 October 2003. [Google Scholar]
- Andrew, L. FAST TCP Simulator Module for ns2. Available online: www.cubinlab.ee.mu.oz.au/ns2fasttcp/ (accessed on 5 March 2006).
- Jain, R.K.; Dah-Ming, W.C.; William, R.H. A Quantitative Measure of Fairness and Discrimination for Resource Allocation in Shared Computer System; Eastern Research Laboratory, Digital Equipment Corporation: Hudson, MA, USA, 1984. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Protocol | Convergence Time (s) | |
|---|---|---|
| Without Any Competing Flow | With Four Competing Flows | |
| SCTP | 8.22 | 8.50 |
| TCP New Reno | 8.46 | 8.92 |
| Fast TCP | 5.43 | 5.18 |
| MFast TCP | 5.43 | 5.18 |
| EMFast TCP | 3.87 | 2.31 |
| Protocol | Throughput (Kbps) | |
|---|---|---|
| Without Any Competing Flow | With Four Competing Flows | |
| SCTP | 1096 | 407 |
| TCP New Reno | 1236 | 397 |
| Fast TCP | 1446 | 430 |
| MFast TCP | 1446 | 430 |
| EMFast TCP | 1454 | 433 |
| Protocol | Goodput (Kbps) | |
|---|---|---|
| Without Any Competing Flow | With Four Competing Flows | |
| SCTP | 1043 | 387 |
| TCP New Reno | 1183 | 379 |
| MFast TCP | 1389 | 413 |
| EMFast TCP | 1396 | 415 |
| Throughput (Kbps) | ||||
|---|---|---|---|---|
| SCTP | Fast TCP | New Reno | EMFast TCP | |
| Flow-1 | 407.00 | 430.46 | 397.00 | 433.00 |
| Flow-2 | 214.50 | 241.21 | 211.64 | 240.13 |
| Flow-3 | 226.02 | 248.93 | 226.42 | 243.17 |
| Flow-4 | 226.99 | 245.25 | 220.36 | 252.06 |
| Flow-5 | 213.82 | 239.19 | 226.42 | 241.25 |
| Total throughput of all flows | 1288.33 | 1405.04 | 1281.84 | 1409.61 |
| Fairness Index | 0.9221 | 0.9338 | 0.9296 | 0.9328 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmad, S.; Arshad, M.J. Enhanced Multistream Fast TCP: Rapid Bandwidth Utilization after Fast-Recovery Phase. Appl. Sci. 2019, 9, 4698. https://doi.org/10.3390/app9214698
Ahmad S, Arshad MJ. Enhanced Multistream Fast TCP: Rapid Bandwidth Utilization after Fast-Recovery Phase. Applied Sciences. 2019; 9(21):4698. https://doi.org/10.3390/app9214698
Chicago/Turabian StyleAhmad, Sarfraz, and Muhammad Junaid Arshad. 2019. "Enhanced Multistream Fast TCP: Rapid Bandwidth Utilization after Fast-Recovery Phase" Applied Sciences 9, no. 21: 4698. https://doi.org/10.3390/app9214698
APA StyleAhmad, S., & Arshad, M. J. (2019). Enhanced Multistream Fast TCP: Rapid Bandwidth Utilization after Fast-Recovery Phase. Applied Sciences, 9(21), 4698. https://doi.org/10.3390/app9214698