1. Introduction
Microservice architecture is a new trend rising fast for application development, as it enhances flexibility to incorporate different technologies, it reduces complexity by using lightweight and modular services, and it improves overall scalability and resilience of the system. In the definition (Microservices:
https://martinfowler.com/tags/microservices.html), the microservice architectural style is an approach to develop a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms (e.g., HTTP resource API). The application then is composed of a number of services (service-based application) that work cohesively to provide complex functionalities. Due to the advantages of microservices architecture, many developers intend to transform traditional monolithic applications into service-based applications. For instance, an online shopping application could be basically divided into product service, cart service, and order service, which can greatly improve the productivity, agility, and resilience of the application. However, it also brings challenges. When deploying a service-based application in clouds, the scheduler has to carefully schedule each service, which may have diverse resource demands, on distributed compute clusters. Furthermore, the network communication between different services needs to be handled well, as the communication conditions significantly influence the quality of service (e.g., the response time of a service). Ensuring the desired performance of service-based applications, especially the network performance between the involved services, becomes increasingly important.
In general, service-based applications involve numerous distributed and complex services which usually require more computing resources beyond single machine capability. Therefore, a cluster of networked machines or cloud computing platforms (e.g., Amazon EC2 (Amazon EC2:
https://aws.amazon.com), Microsoft Azure (Microsoft Azure:
https://azure.microsoft.com), or Google Cloud Platform (Google Cloud Platform:
https://cloud.google.com)) are generally leveraged to run service-based applications. More importantly, containers are emerging as the disruptive technology for effectively encapsulating runtime contexts of software components and services, which significantly improves portability and efficiency of deploying applications in clouds. When deploying a service-based application in clouds, several essential aspects have to be taken into account. First, services involved in the application often have diverse resource demands, such as CPU, memory and disk. The underlying machine has to ensure sufficient resources to run each service and at the same time provide cohesive functionalities. Efficient resource allocation to each service is difficult, while it becomes more challenging when the cluster consists of heterogeneous machines. Second, services involved in the application often have traffic demands among them due to data communication, which require meticulous treatment. Poor handling of the traffic demands can result in severe performance degradation, as the response time of a service is directly affected by its traffic situation. Considering the traffic demands, an intuitive solution is to place the services that have large traffic demands among them on the same machine, which can achieve intra-machine communication and reduce inter-machine traffic. However, such services cannot all be co-located on one machine due to limited resource capacities. Hence, placement of service-based applications is quite complicated in clouds. In order to achieve a desired performance of a service-based application, cluster schedulers have to carefully place each service of the application with respect to the resource demands and traffic demands.
Recent cluster scheduling methods mainly focus on the cluster resource efficiency or job completion time of batch workloads [
1,
2,
3]. For instance, Tetris [
4], a multi-resource cluster scheduler, adapts heuristics for the multi-dimensional bin packing problem to efficiently pack tasks on multi-resource cluster. Firmament [
5], a centralized cluster scheduler, can make high-quality placement decisions on large-scale clusters via a min-cost max-flow optimization. Unfortunately, these solutions would face difficulties for handling service-based applications, as they ignore the traffic demands when making placement decisions. Some other research works [
6,
7] concentrate on composite Software as a service (SaaS) placement problem, which try to minimize the total execution time for composite SaaS. However, they only focus on a set of predefined service components for the application placement. For traffic-aware scheduling, relevant research solutions [
8,
9] are proposed to handle virtual machine (VM) placement problem, which aims to optimize network resource usage over the cluster. However, these solutions rely on a certain network topology, while most of existing cluster schedulers are agnostic to network topology. In particular, it is hard to get the network topology information when deploying a service-based application on a virtual infrastructure.
In this paper, we propose a new approach to optimizing the placement of service-based applications in clouds. The objective is to minimize the inter-machine traffic while satisfying multi-resource demands for service-based applications. Our approach involves two key steps: (1) The requested application is partitioned into several parts while keeping overall traffic between different parts to a minimum. (2) The parts in the partition are packed into machines with multi-resource constraints. Typically, the partition can be abstracted as a minimum k-cut problem; the packing can be abstracted as a multi-dimensional bin packing problem. However, both are NP-hard problems [
10,
11]. To address these problems, we first propose two partition algorithms:
Binary Partition and
K Partition, which are based on a well designed randomized contraction algorithm [
12], for finding a high quality application partition. Then, we propose a packing algorithm, which adopts an effective packing heuristic with traffic awareness, for efficiently packing each part of an application partition into machines. Finally, we combine the partition and packing algorithm with a resource demand threshold to find an appropriate placement solution. We implement a prototype scheduler based on our proposed algorithms and evaluate it on testbed clusters. The results show that our scheduler outperforms existing container cluster schedulers and representative heuristics, leading to much less overall inter-machine traffic.
2. Problem Formulation
In this section, we formulate the placement problem of service-based application, and introduce the objective of this work. The notation used in the work is presented in
Table 1.
2.1. Model Description
We consider a cloud computer cluster is composed of a set of heterogeneous machines , where is the number of machines. We consider R types of resources (e.g., CPU, memory, disk, etc.) in each machine. For machine , let be the vector of its available resources, where the element denotes the amount of resource available on machine .
In infrastructure as a service (IaaS) model or container as a service (e.g., Amazon ECS) model, users would specify the resource demands of VMs or containers (e.g., a combination of CPU, memory, and storage) when submitting deployment requests. Thus, the resource demands are known upon the arrival of service requests. We consider a service-based application is composed of a set of services that are to be deployed on the cluster, and is the number of services. For service , let be the vector of its resource demands, where the element denotes the amount of resource that the service demands. Let matrix denote the traffic between services, where denotes the traffic rate from service to service .
We model a placement solution as a 0–1 matrix . if service is to be deployed on machine , it is . Otherwise, it is .
2.2. Objective
To achieve a desired performance of service-based applications, a scheduler should not only consider the multi-resource demands of services but also the traffic situation between services. As services, especially data-intensive services, often need to transfer data frequently, the network performance would directly influence the overall performance. Considering the network dynamics, the placement of different services of an application is crucial for maintaining the overall performance, particularly when unexpected network latency or congestion occurs in the cluster. Given the traffic situation, the most intuitive solution is to place the services that have high traffic rate among them on the same machine so that the co-located services can leverage the loopback interface to get a high network performance without consuming actual network resources of the cluster. However, such services cannot all be co-located on one machine due to limited resource capacities. Thus, with the resource constraints, we try to find a placement solution to minimize the overall traffic between services that are placed on different machines (inter-machine traffic) while satisfying multi-resource demands of services, so that the objective of this work can be formulated as:
Equation (2) guarantees that each service is placed on a machine. Equation (3) guarantees that resource demands on a machine do not exceed its resource capacities. Equation (
1) expresses the goal of this work.
3. Minimum K-Cut Problem
As a service-based application typically cannot be placed on one machine, an effective partition of the set of services involved in the application is necessary during the deployment. After partition, each subset of the services should be able to be packed into a machine, which means the machine has sufficient resources to run all the services in the subset. Considering the traffic rate between different services, the quality of the partition is crucial for the application performance. To tackle this problem, we first discuss the minimum k-cut problem to understand the problem’s complexity.
Let
be an undirected graph, where
V is the node set, and
E is the edge set. In the graph, each edge
has a non-negative weight
. A k-cut in graph
G is a set of edges, which when removed, partition the graph into
k disjoint nonempty components
. The minimum k-cut problem is to find a k-cut of minimum total weight of edges whose two ends are in different components, which can be computed as:
A minimum cut is a simply minimum k-cut when
.
Figure 1 shows an example of a minimum cut of a graph. There are 2 cuts shown in the figure, and the dash line is a minimum cut of the graph, as the total weight of edges cut by the dash line is the minimum of all cuts. Given a service-based application, we can represent it as a graph, where the nodes represent services and the weights of edges represent the traffic rate. Specifically, the traffic rate from service
to service
and the rate from service
to service
are represented as two edges respectively in the graph. Hence, finding a minimum k-cut of the graph is equivalent to partitioning the application into
k parts while keeping overall traffic between different parts to a minimum. However, for arbitrary
k, the minimum k-cut problem is NP-hard [
10].
Different from developing a deterministic algorithm, Karger’s algorithm [
12] provides an efficient randomized approach to find a minimum cut of a graph. The basic idea of the Karger’s algorithm is to randomly choose an edge
from the graph with probability proportional to the weight of edge
and merge the node
u and node
v into one (called edge contraction). In order to find a minimum cut, the algorithm iteratively contracts the edge which are randomly chosen until two nodes remain. The edges that remain at last are then output by the algorithm. The pseudocode is shown in Algorithm 1.
| Algorithm 1: Contraction Algorithm () |
 |
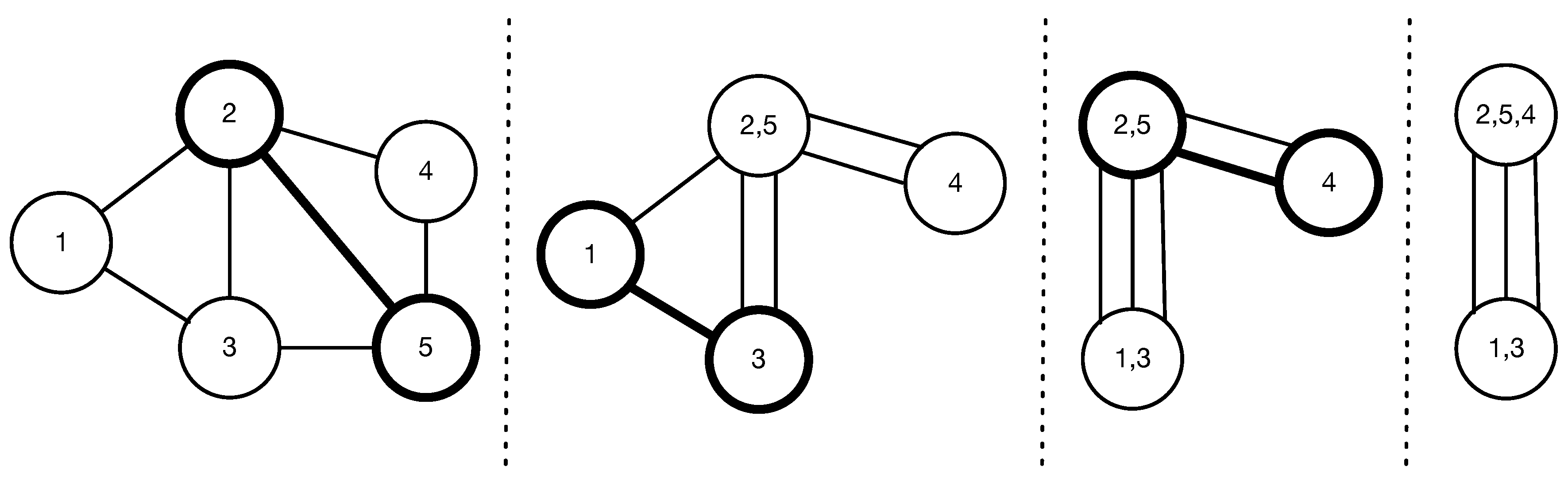
Figure 2 shows an example process of the contraction algorithm (
). The algorithm iteratively merges two nodes of the chosen edge, and all other edges are reconnected to the merged node. For a graph
with
nodes and
edges, Karger [
12] argues that the contraction algorithm returns a minimum cut of the graph with probability
. Therefore, if we perform the contraction algorithm independently
times, we can find a minimum cut with high probability; if we do not get a minimum cut, the probability is less than
. For minimum k-cut, the contraction algorithm is basically the same, except that it terminates when k nodes remain (change
to
in Algorithm 1) and returns all the edges left in the graph
G. Similarly, the contraction algorithm returns a minimum k-cut of the graph with probability
. If we perform the algorithm independently
times, we can obtain a minimum k-cut with high probability. Regarding the time complexity, the contraction algorithm can be implemented to run in strongly polynomial
time [
12].
4. Placement Algorithm
In this section, we describe the algorithms we proposed in this work. The goal of our algorithms is to find a placement solution to minimize inter-machine traffic while satisfying multi-resource demands. The key design of our approach includes: (1) application partition based on contraction algorithms, (2) heuristic packing with traffic awareness, and (3) placement finding with threshold adjustment.
4.1. Application Partition
In order to make the values of different resources comparable to each other and easy to handle, we first normalize the amount of available resources on machines and the resources that services demands to be the fraction of the maximum ones. We define the term
to be the maximum amount of available resources
on a machine.
Then the vector
of available resources on machine
and the vector
of resource demands of service
are normalized as:
After normalization, we start partitioning the service-based application. The key question we ask first is how many parts the application is partitioned into. Considering multi-resource demands of different services, we introduce a threshold
to determine the number of parts when performing partition algorithms. The threshold
denotes the upper bound of the resource demands of partitioned parts, which means we perform partition algorithms continuously until the total resource demands from each part do not exceed
or no part contains more than one service. With a threshold
(as the resource demands have been normalized), it assures that each part after partition can be packed into a machine.
Figure 3 shows an example of an application partition with threshold
. In the figure, the total CPU demands and memory demands from each part do not exceed
. Given a threshold
, we propose two partition algorithms:
binary partition and
k partition, which are based on the contraction algorithm.
4.1.1. Binary Partition
The idea of the binary partition algorithm is to continuously perform binary partition on the application until the resource demands from each part do not exceed
or no part contains more than one service. The pseudocode is shown in Algorithm 2. The basic process can be described as follows. The algorithm continuously checks the resource demands of each part in current application partition
P. The initial partition is
where the entire application is treated as one part. If the total resource demands of a part
in
P exceeds the threshold
and part
contains more than one service, the part is selected to be partitioned into 2 parts (binary partition). It first constructs a graph
based on
, where the nodes represent services and the weights of edges represent the traffic rate. As mentioned in
Section 3, if we repeatedly perform the contraction algorithm many times, we can obtain a minimum cut with high probability. Considering both the partition quality and the partition speed, we choose to perform the contraction algorithm
n times in our algorithm (in offline manner, it can be set to run
times to get a minimum cut with high probability). Then, according to the minimum cut
, we get from the contraction algorithm, it partitions the
into two parts
. This process would be repeatedly performed until the resource demands from each part do not exceed threshold
or no part contains more than one service.
4.1.2. K Partition
The idea of the k partition algorithm is to directly partition the application into
k parts. By iteratively increasing
k, it terminates when the resource demands from each part do not exceed
or no part contains more than one service. The pseudocode is shown in Algorithm 3. The basic process can be described as follows. The algorithm first constructs a graph
based on the application
and then continuously checks the resource demands of each part in current application partition
P where
initially. If the total resource demands of a part
in
P exceeds the threshold
and part
contains more than one service, it increases
k, which is the number of partitioned parts. As mentioned in
Section 3, in order to obtain a minimum k-cut with high probability, we have to perform the contraction algorithm independently
times. However, the time complexity increases exponentially with
k, which is prohibitively high. Thus, we make the time complexity consistent with the binary partition algorithm by sacrificing some probability of finding a minimum k-cut. It also performs the contraction algorithm
n times. Then, according to the minimum k-cut
we get from the contraction algorithm, it partitions the application into
k parts
. Similarly, this process would be repeatedly performed until the resource demands from each part do not exceed threshold
or no part contains more than one service.
| Algorithm 2: Binary Partition |
 |
| Algorithm 3: K Partition |
 |
4.2. Heuristic Packing
Given a partition of the application, the algorithm here is to pack each part into the heterogeneous machines. Without considering the traffic rate, the problem can be formulated as a classical multi-dimensional bin packing problem, which is known to be NP-hard [
11]. When there are a large amount of services involved in the application, it is infeasible to find the optimal solution in polynomial time. Considering the time complexity and packing quality, we adopt two greedy heuristics in our packing algorithm:
Traffic Awareness and
Most-Loaded Heuristic. The algorithm is shown in Algorithm 4.
| Algorithm 4: Heuristic Packing |
 |
In order to find a best possible machine for part , the algorithm calculates two matching factors: and . For machine , the factor is the sum of the traffic rate between the services in part , and the services have been determined to be packed into machine before. The factor is a scalar value of the load situation between the vector of resource demands from part and the vector of available resources on machine . Assuming is the resource demand vector of part and is the amount of resource part demands, it is . The higher is, the more loaded the machine. The idea of this heuristic is to improve the resource efficiency by packing the part to the most loaded machine. As our main goal is to minimize the inter-machine traffic, the algorithm is designed to first prioritize the machines based on the factors of . If the factors of are the same, it then prioritizes the machines based on the factors of . Consequently, if all parts in the partition can be packed into machines, the algorithm returns the placement solution. Otherwise, it returns .
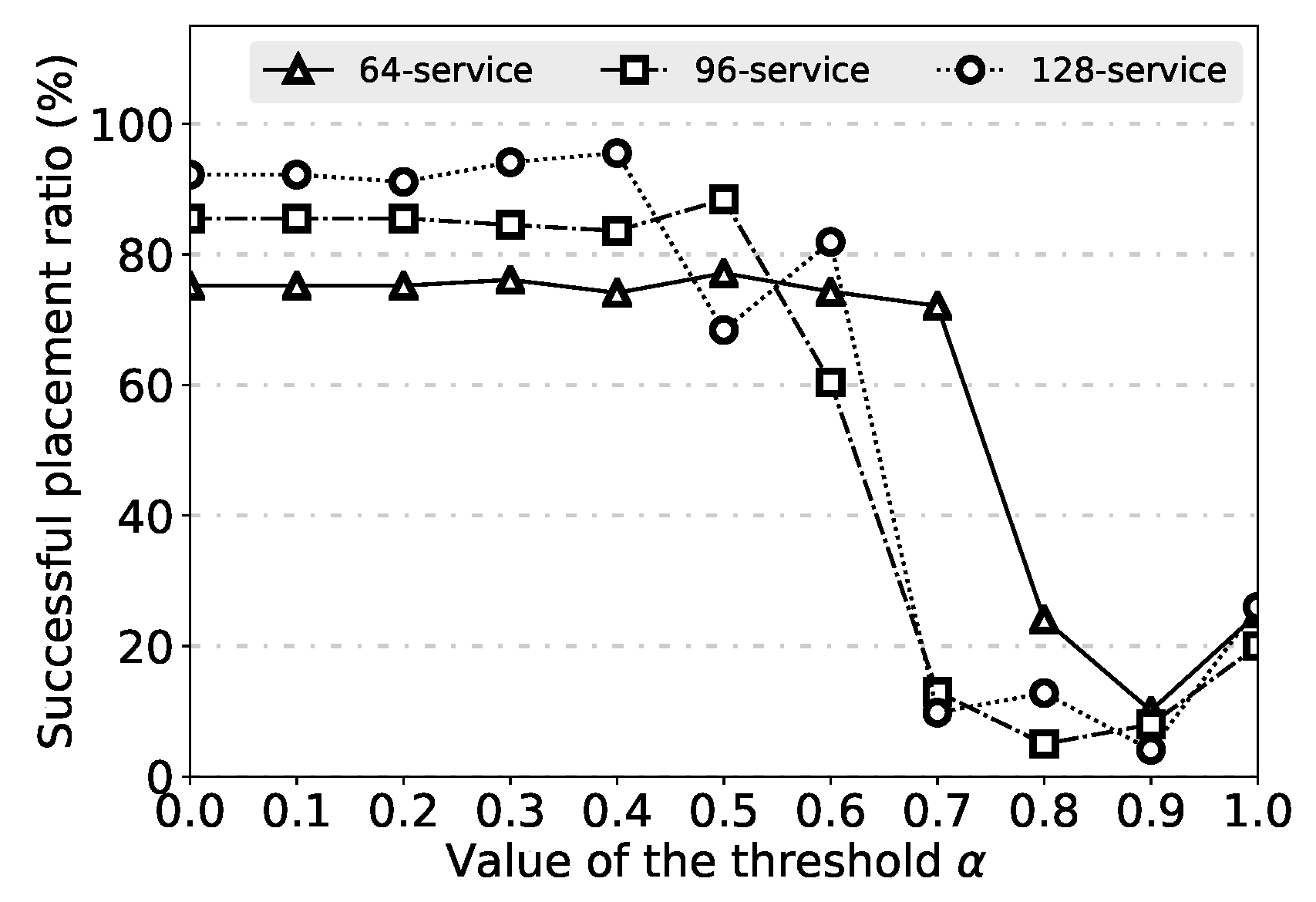
4.3. Placement Finding
As we discussed before, in order to partition the application, the threshold is required by the algorithm. However, giving an appropriate deterministic threshold is difficult, as it cannot guarantee that the algorithm can find a placement solution through the randomized partition and the heuristic packing under a certain threshold . Intuitively, the higher threshold results in less parts in the partition, which leads to less traffic rate between different parts. Thus, we introduce a simple algorithm to find a better threshold by enumerating from large to small. The algorithm is shown in Algorithm 5. At the beginning, the value of is 1.0. To adjust the thresholds, we set a step value , and the default value is 0.1, which can be customized by users. In each iteration, with the threshold , the algorithm first partitions the given application based on the binary partition algorithm or k partition algorithm. Note that the algorithm records the latest partition results to avoid multiple repeated partition. It then tries to pack all parts in the partition into machines based on the heuristic packing algorithm to find a placement solution for the application.
| Algorithm 5: Placement Finding |
 |
Next, we discuss the time complexity of the algorithm we proposed. We assume the number of services is n; the number of edges in the service graph is m (i.e., the number of the traffic rates ); the number of machines is M. For a service-based application, it can be partitioned up to n parts. For each partition, we perform the contraction algorithm n times, and the time complexity of the contraction algorithm is . As we record the latest partition results to avoid multiple repeated partition, the time complexity of the overall partition is . To the heuristic packing, the time complexity is as the overall time complexity of calculating the factor is . Let denote the number of iterations. The overall time complexity of the proposed algorithm is .
6. Related Work
As the microservice architecture is emerging as a primary architectural style choice in the service oriented software industry [
21], many research efforts have been devoted to the analysis and modeling of microservice architecture [
22,
23,
24]. Leitner et al. [
25] proposed a graph-based cost model for deploying microservice-based applications on a public cloud. Balalaie et al. [
26] presented their experience and lessons on migrating a monolithic software architecture to microservices. Amaral et al. [
27] evaluated the performance of microservices architectures using containers. However, the performance of service placement schemes received little attention in these works.
Software as a Service (SaaS) is one of the most important services offered by cloud providers, and many works have been proposed for optimizing composite SaaS placement in cloud environments [
15]. Yusoh et al. [
6] propose a genetic algorithm for the composite SaaS placement problem, which considers both the placement of the software components of a SaaS and the placement of data of the SaaS. It tries to minimize the total execution time of a composite SaaS. Hajji et al. [
7] adopt a new variation of PSO called Particle Swarm Optimization with Composite Particle (PSO-CP) to solve the composite SaaS placement problem. It considers not only the total execution time of the composite SaaS but also the performance of the underlying machines. Unfortunately, they target at the placement for a certain set of predefined service components, which has limitations to handle a large number of different services. In addition, plenty of research has been proposed to optimize service placement in edge and fog computing [
28,
29]. Mennan et al. [
30] proposed a service placement heuristic to maximize the bandwidth allocation when deploying community networks micro-clouds. It uses the information of network bandwidth and node availability to optimize service placement. Different from it, we consider the constraints of multiple resources rather than just network bandwidth to minimize the inter-machine traffic while satisfying multi-resource demands of service-based applications. Carlos et al. [
31] presented a decentralized algorithm for the placement problem to optimize the distance between the clients and the most requested services in fog computing. They assume there are unlimited resources in cloud computing and try to minimize the hop count by placing the most popular services as closer to the users as possible. In contrast, our work focuses on the overall network usage of the cloud underlying cluster, which is modeled as a set of heterogeneous machines.
In recent years, a number of research works have been proposed in the area of VM placement with traffic awareness for cloud data centers [
16,
17]. Meng et al. [
8] analyze the impact of data center network architectures and traffic patterns and propose a heuristic approach to reduce the aggregate traffic when placing VM into the data center. Wang et al. [
9] formulate the VM placement problem with dynamic bandwidth demands as a stochastic bin packing problem and propose an online packing algorithm to minimize the number of machines required. However, they only focus on optimizing the network traffic in the data center, without considering the highly diverse resources requirements of the virtual machines. Biran et al. [
32] proposed a placement scheme to satisfy the traffic demands of the VMs while meeting the CPU and memory requirements. Dong et al. [
33] introduced a placement solution to improve network resource utilization in addition to meeting multiple resource constraints. They both rely on a certain network topology to make placement decisions. Besides, many research efforts have been devoted to the scheduling and partitioning on heterogeneous systems [
34,
35]. Different from them, our work is agnostic to the underlying network topology, which aims to minimize the overall inter-machine traffic on the cluster.
7. Conclusions
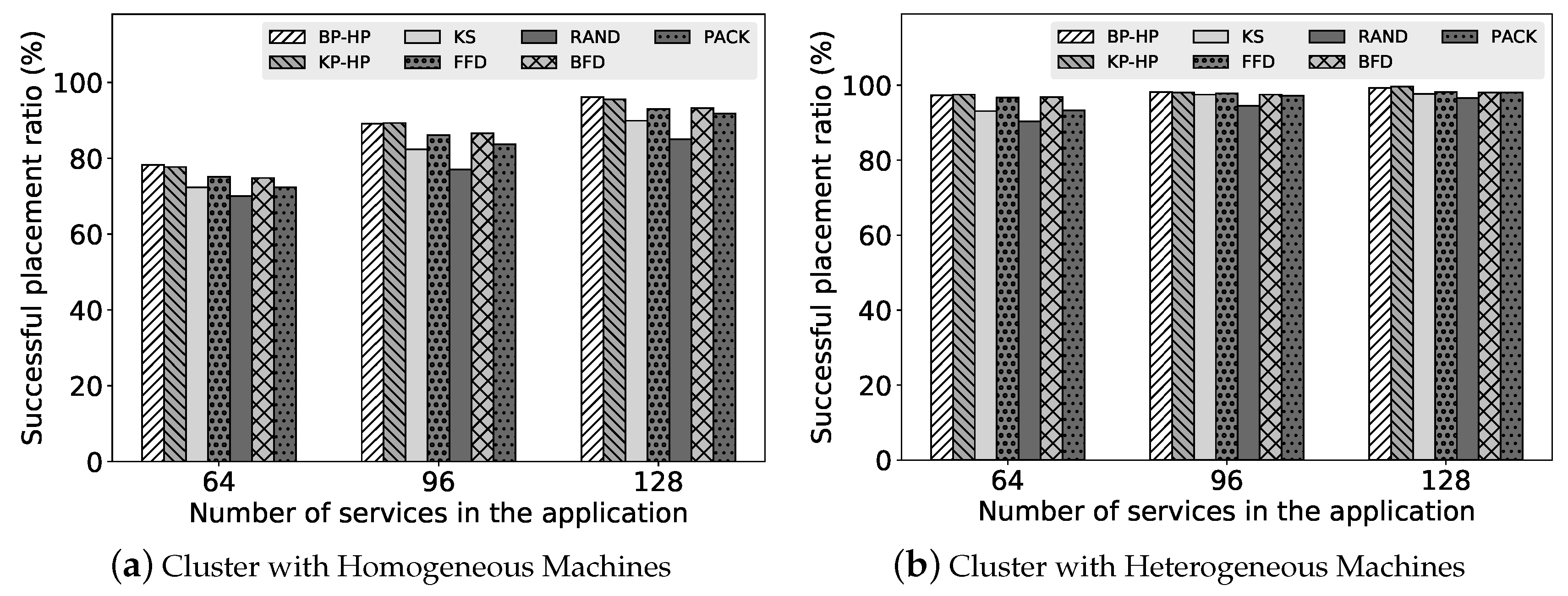
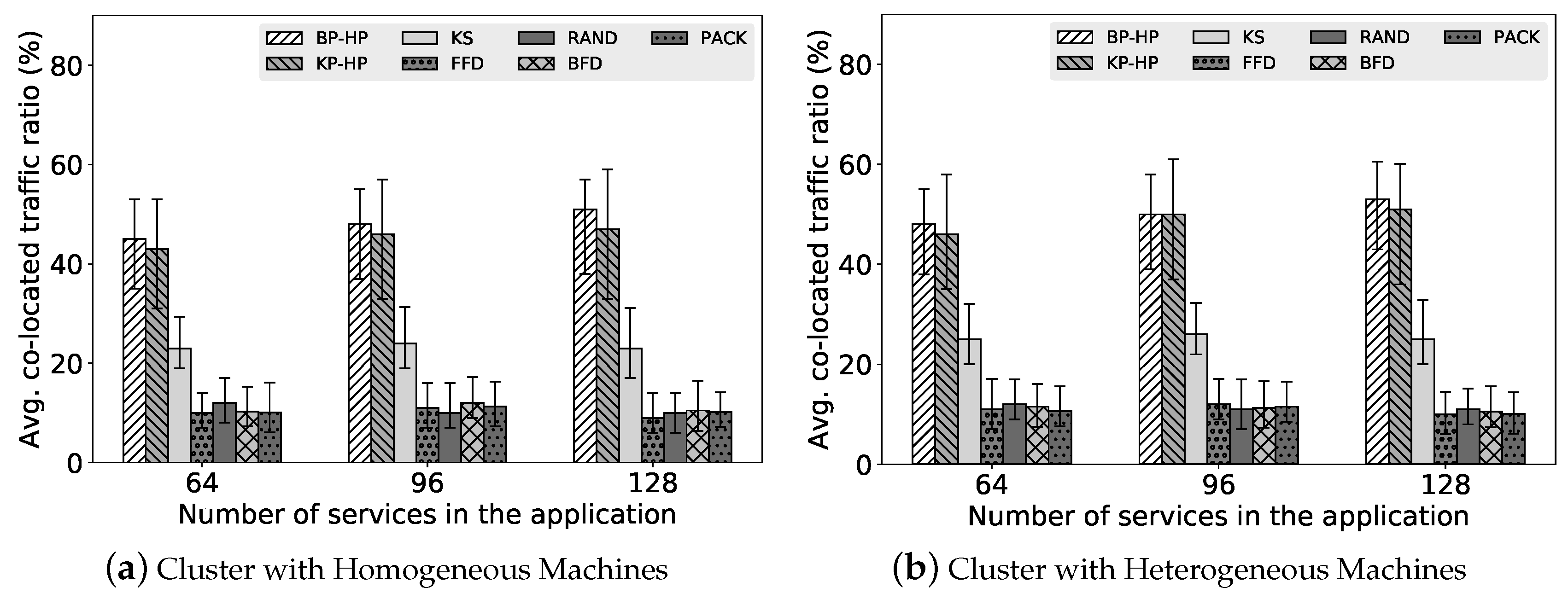
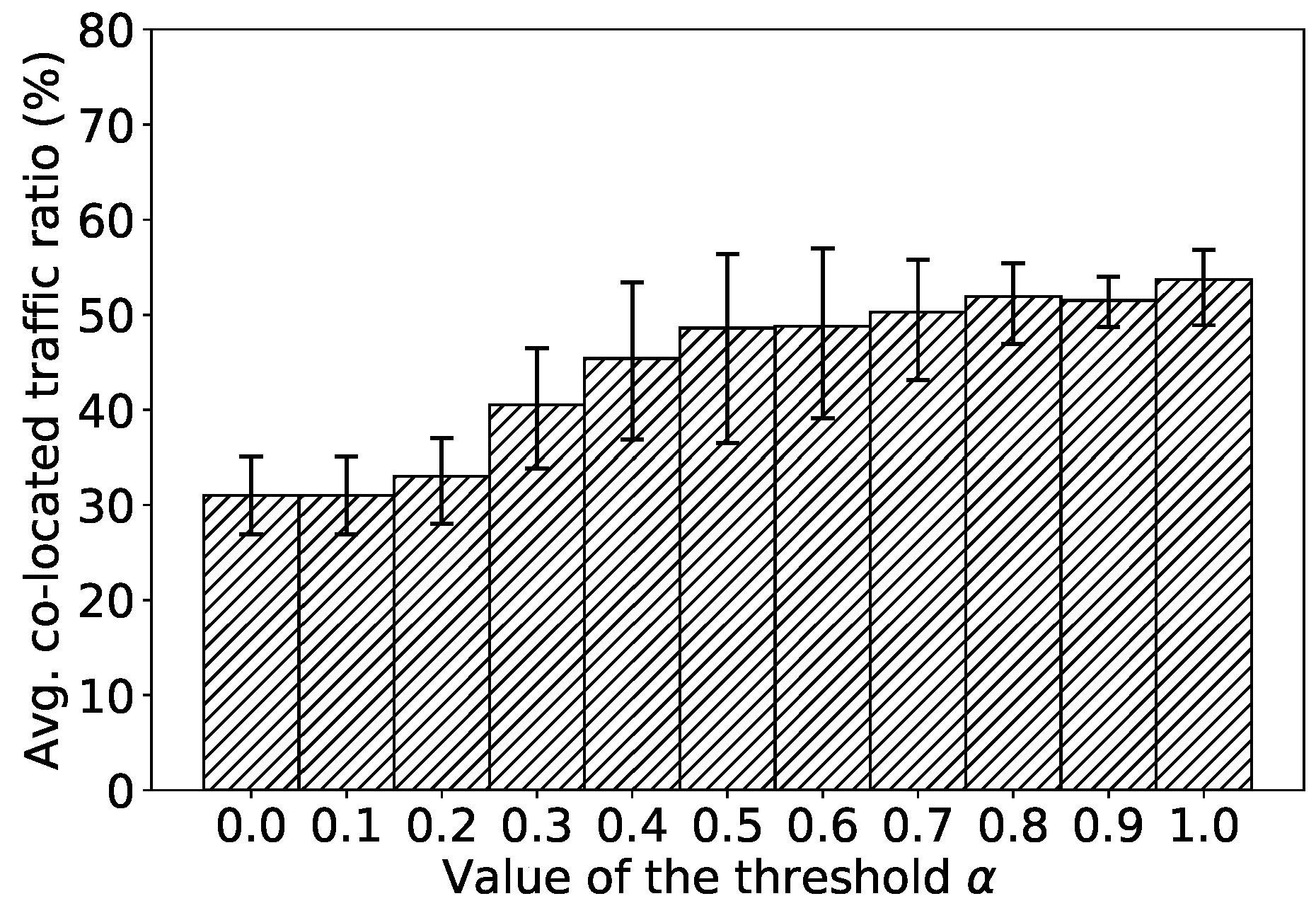
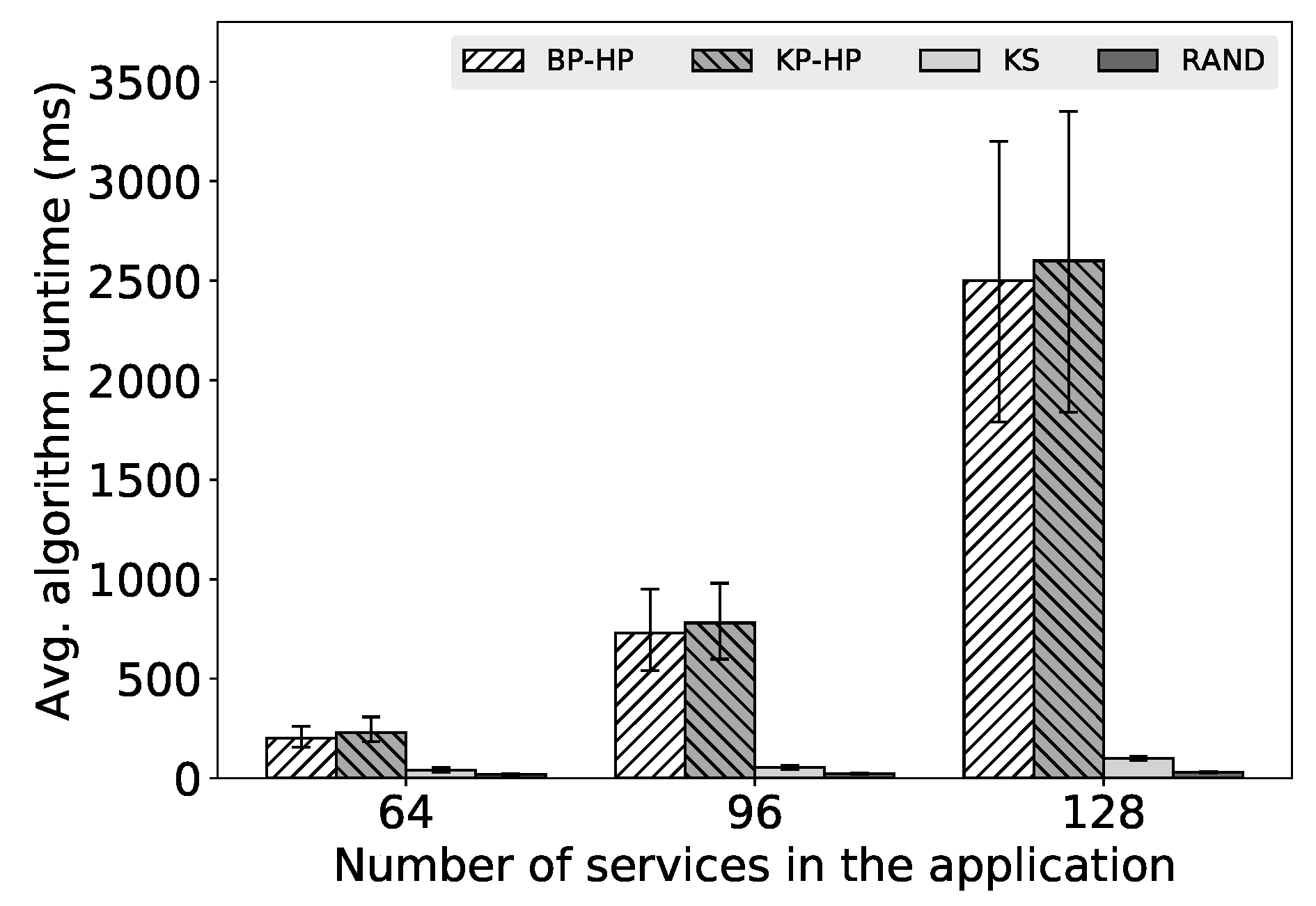
In this paper, we investigated service placement problem for microservice architecture in clouds. In order to find a high quality partition of service-based applications, we propose two partition algorithms: Binary Partition and K Partition, which are based on a well designed randomized contraction algorithm. For efficiently packing the application, we adopt most-loaded heuristic and traffic awareness in the packing algorithm. By adjusting the threshold which denotes the upper bound of the resource demands, we can find a better placement solution for service-based applications. We implement a prototype scheduler based on our proposed algorithms and evaluate it on testbed clusters. In the evaluation, we show that our algorithms can improve the ratio of successfully placing applications on the cluster while significantly increasing the ratio of co-located traffic (i.e., reducing the inter-machine traffic). In the overhead evaluation, the results show that our algorithms incur some overhead but in an acceptable time. We believe that the proposed algorithms are practical for realistic use cases. In the future, we will investigate problem-specific optimizations to improve our implementation and consider resource dynamics in the placement to adapt more sophisticated situations.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}