Expert Finding Systems: A Systematic Review


 ,
,
Abstract
1. Introduction
- Individual Benefits—these systems, along with finding people, also link people who would otherwise not have the opportunity to meet in person. They could also increase the individual’s awareness regarding the activities in the organisation and allow people to tailor their responses based on people they may meet in future.
- Benefits for an organisation (use of conversation for retrieving tacit knowledge)—Expert finding systems help organizations in two ways: (1) They map tacit knowledge and help individuals to develop a better awareness about which individual knows what; however, information of the knowledge location alone is insufficient. The organisation benefits if this knowledge can be applied to actual problems. (2) Any expert finding system must help in building social capital by improving the connections between people who are acquainted with one another and increasing conversations between people who are not acquainted, thus extending their social network (i.e., development of weak or strong ties).
- Expertise evidence (sources of data) selection—Expertise evidence selection extracts the expertise-related data and information from which experts can be discovered. Data related to the person should be obtained to discover whether or not the individual is an expert in a particular field.
- Expert representation—a key objective of expert finding systems is to provide users with information that effectively enables not only locating expertise but also deciding and selecting among relevant experts. It is necessary to identify which information can be useful in determining among experts whose expertise seeker is not personally familiar with them. Generally, an expert can be determined based on his documented evidence and relationships and human interaction factors (which are called contextual factors).
- Model building—Model building consists of pre-processing, indexing, and modelling.
- Pre-processing and indexing—constructing indexes is a regular task for document retrieval systems, and numerous open source software tools exist to facilitate this task; for expertise retrieval, however, there is a further challenge. The identifiers of a candidate expert (e.g., names, emails, etc.) need to be recognized in documents, and heterogeneous data sources need to be integrated to identify experts. Numerous text pre-processing techniques for traditional IR applications are implemented in expert search. For instance, several expert search systems eliminate stopwords from raw text document data, to achieve a higher level of precision [1]. An expert’s data is commonly collected from many documents in heterogeneous data sources. This is a significant difference with document retrieval that produces technical challenges to both data integration and indexing. As an example, different names may refer to the same person or the same names in different sources might refer to different persons. Named entity recognition (NER) and disambiguation play a fundamental role in most operational expert search systems [1]. A simple way of carrying out NER is to use the candidate’s identifiers as the query and associate the retrieved documents with that person [29]. Reference [30] proposed rule-based matching techniques to identify candidates by their names (using three matching forms—exact match, initial and last name, and last name only) and by their emails.
- Modelling and retrieval—Modelling and retrieval are about building models to associate candidate experts with a user query and to provide a ranking based on the strength of these associations [1]. In the literature, there are several different methods for building models to find experts, such as probabilistic, network-based (or sometimes called graph-based), voting, and other models [1,4].
- Models evaluation—the expert finding system is an IR system where interactions start with a user sending a query to the system, and then the system retrieves a list of experts that hopefully are relevant to the user’s query. Normally, expert finding system efficiency is evaluated using a test collection (datasets).
- Interaction design—the presentation of expert search results to users is a primary issue in practice. However, a simple list of names does not every time aid the user to judge the relevance of a candidate to the query. Contrary to document search, there is often no particular document snippet that can be speedily examined to determine relevance. For that reason, expert search result pages often show not only a ranked list of people but also a list of documents, conferences, and journals. Also, the presence of contact details for each ranked expert is important to facilitate communication [1]. There is a significant number of studies on locating personal homepages where several of the suggested methods utilize supervised learning techniques [31,32,33]. Also, photos of experts are essential because users may need to determine the likely seniority or familiarity of an expert in advance of contacting him or her. For instance, the user may be looking for somebody of a similar age or level or type of experience to themselves. Moreover, related information such as affiliations and documents, containing publications, and projects, appear to help the user determine that the expert is likely to have relevant expertise [1].
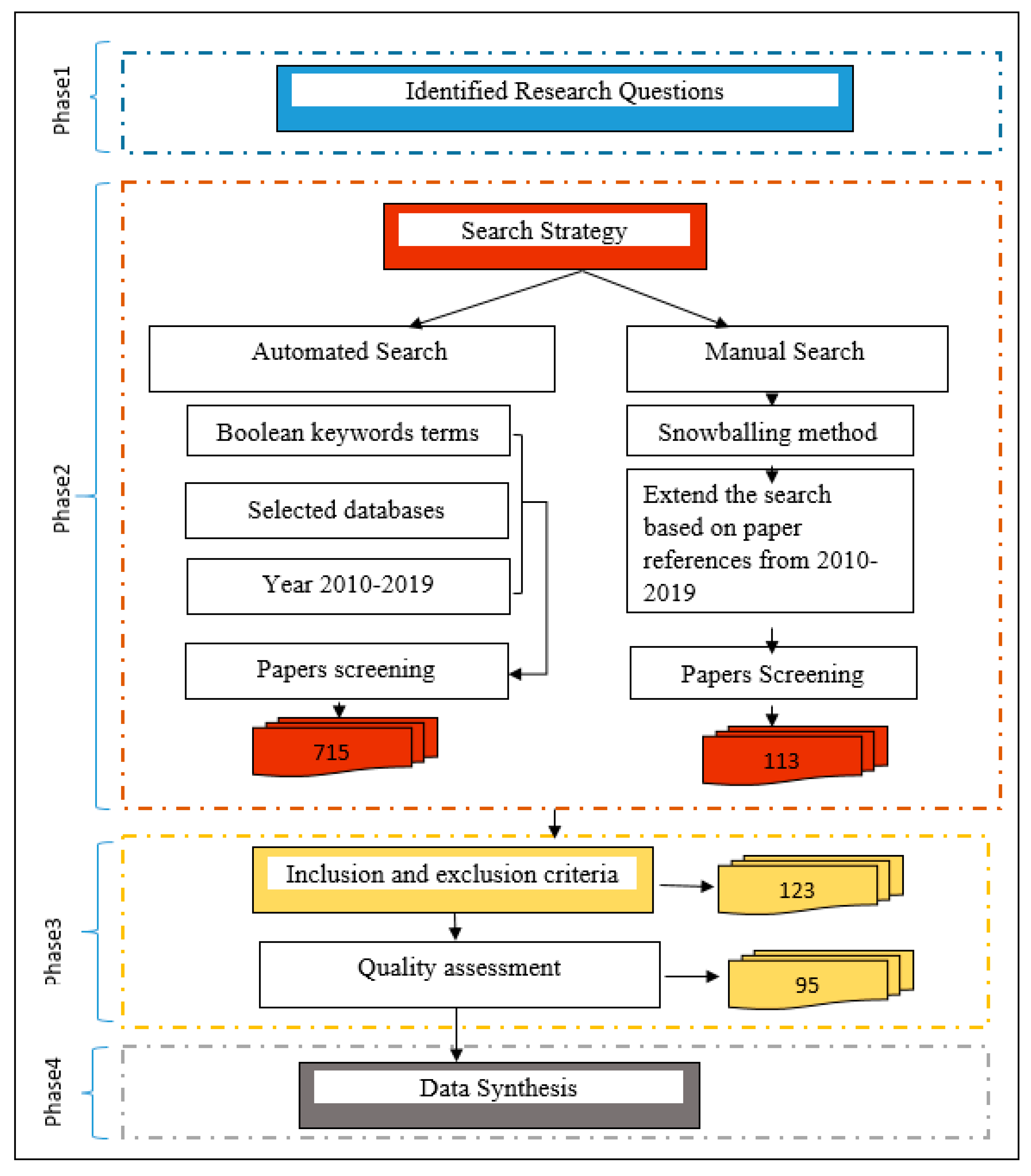
2. Research Method
2.1. Research Questions
2.2. Search Strategies
2.3. Study Selection Process
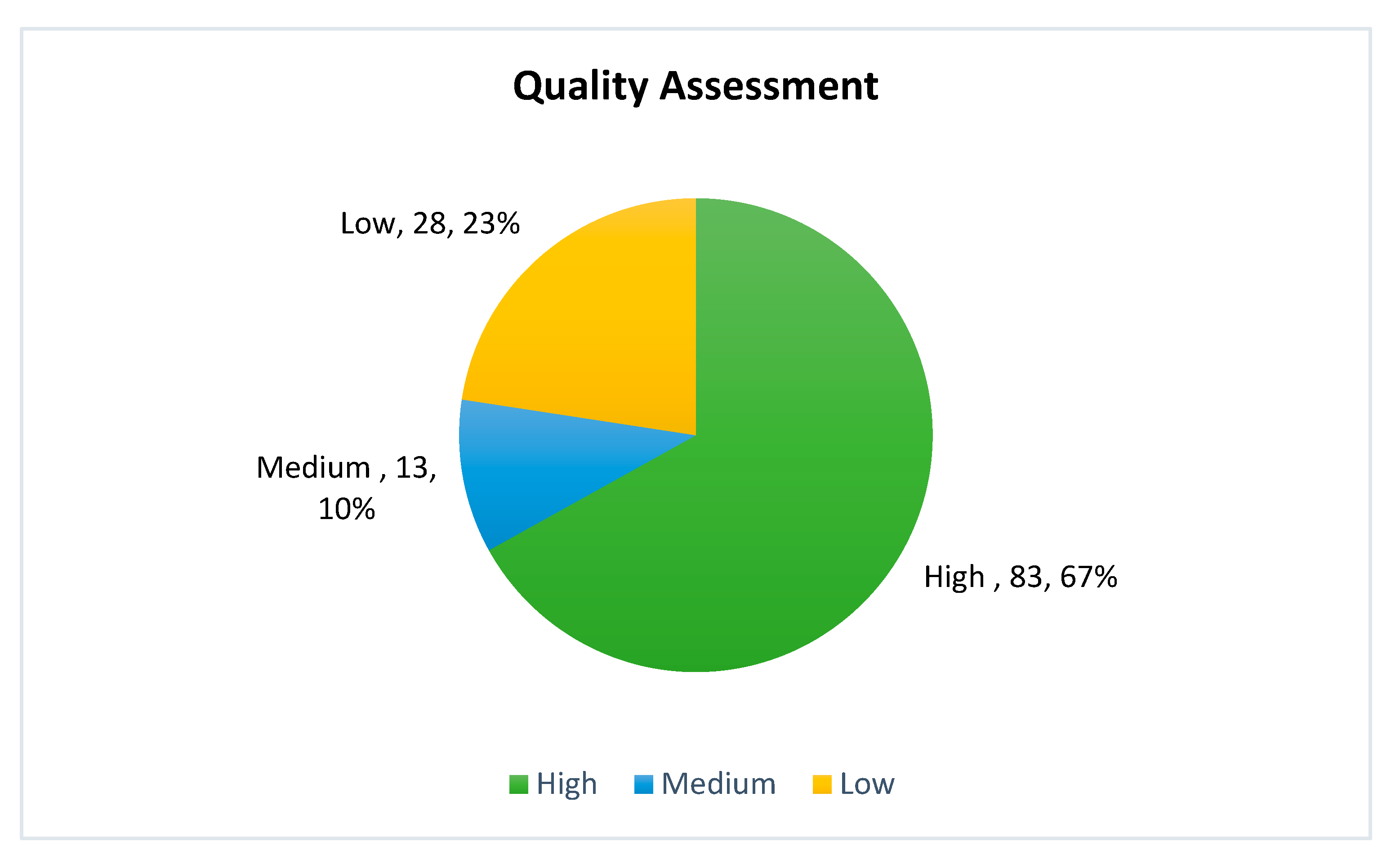
2.4. Quality Assessment (QA)
- QA1: Are all the topics addressed in the research paper related to the review?
- QA2: Does the research paper explain the context clearly?
- QA3: Is the research methodology explained in the paper?
- QA4: Does the paper describe the data collection method?
- QA5: Does the paper present the result analysis?
2.5. Data Extraction and Synthesis
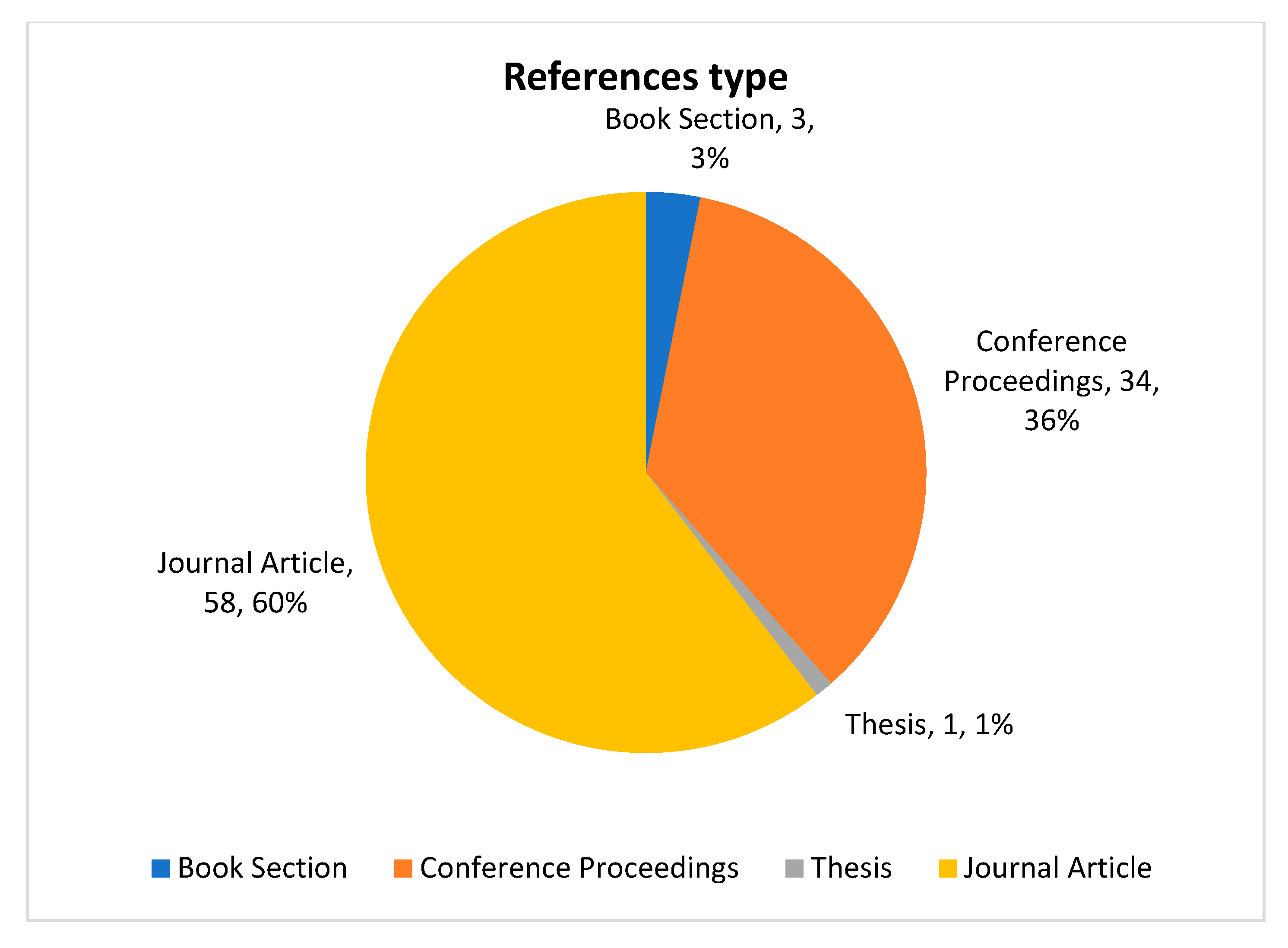
2.5.1. Publications Source Overview
2.5.2. Research Methodologies
3. Results for the Research Questions
3.1. RQ1: Which Domains Used the Expert Finding Systems?
3.2. RQ2: What Are the Expertise Sources Used for Experts Finding Systems?
- Textual sources—Textual sources can be considered as the main evidence of expertness. They include documents, user profiles (meta databases or homepages), and communications (e-mails and textual chats) [45]. Documents are secondary data sources that can be used as expertise evidence to automatically extract candidate experts [4]. There are different types of documents that have been used in the current expert finding systems studies. The most used textual expertise source is publications, which have been used by authors in [36,38,44,48,49,53,58,59,61,62,66,67,68,70,71,72,73,80] as their main expertise source, while publications have been combined with other expertise sources in [22,40,41,43,44,47,55,60,69,75,88,89]. In addition to publications, reference [42] used movies as expertise evidence. Two studies [80,81] used medical documents. Moreover, another two studies [15,77] used employee documents. Also, a bug repository was used as expertise evidence by the authors in reference [36]. Reference [78] used enterprise terminologies in their system as expertise evidence, while reference [79] used transactional data. Additionally, relevance feedback and log repository have been used by authors in reference [74] and reference [35], respectively. The advantage of using documents as expertise sources is the simplicity of extracting up-to-date information about a particular expert. However, their disadvantage is that they cannot contain all the required information. For example, it is difficult to discover junior experts who have no publications. Meta databases are the main store of employees’ expertise in organizations. They are used to store personal profiles for employees [4]. For example, a university expertise database saves the profiles of university members with all academic information including personal information, research students, expertise areas, projects, and publications. Among many different expertise sources, faculty and university personal homepages are a valuable and reliable source, since they usually contain relatively well-formatted data [31]. The authors of references [5,26,27,44] used homepages as expertise evidences for their systems. Usually, building and updating such databases is an expensive task, but small organizations are able to keep their databases up-to-date with good quality information [4]. Thus, the shortcomings of this expertise source are (1) the completeness and update of information depends on the employees, and sometimes they are busy or unwilling to carry out this task [71]; (2) the employees need motivation and rewards from their organization to update their profiles regularly; (3) in an organization’s databases, the descriptions of expertise tend to be unstructured and general, and it is difficult to seek experts in a specific area of expertise with these descriptions; and (4) it is difficult to update the information in these databases in real time because of the static nature of these databases [1,4]. Additionally, emails have been used as expertise evidence by the authors in reference [87].
- Social Networks (SNs)—The rapid development in internet technologies creates a huge amount of user-generated data disseminated on SNs, which is becoming one of the most important expertise sources [53,86]. This user-generated data holds a lot of information such as users’ posts, question tags, opinions, activities, experience, etc., which can be valuable for expert finding [71]. SNs are one of the valuable expertise sources since they commonly contain up-to-date information and show meaningful relationships between people. Experts’ SNs can be used to extract the effective factors for their ranking and selection (e.g., organisation-related factors, temporal factors, and contextual factors). SNs were used widely as expertise sources by the authors of references [20,21,37,56,57,76,86]. Also, forums have been used by the authors in references [84,85]. Additionally, posts and questions tags have been used as expertise evidences by the authors of references [16,17,19,44,82,83].
- Hybrid expertise sources—Recent studies recommended that identifying an expert should not be based on a single expertise source. Thus, current expert finding systems studies integrated heterogeneous expertise sources to enhance the quality of expert finding systems. Several researchers combined different expertise sources, and these are presented in Table 4.
3.3. RQ3: What Are the Differences between Expertise Retrieval and Expertise Seeking, and What Are the Contextual Factors and Theories That Have Been Integrated with Expert Finding Systems?
3.3.1. RQ3a: What Are the Differences between Expertise Retrieval and Expertise Seeking?
3.3.2. What Are the Contextual Factors and Theories That Have Been Integrated with Expert Finding Systems?
3.4. RQ4: What Are the Methods That Have Been Used for Expert Finding Systems?
3.4.1. Generative Probabilistic Models
- (1)
- Okapi BM25 (OKAPI), where a vector of terms associated with researcher’s content was used to represent the researcher profile. In order to obtain the similarity between two profiles, this technique considered one profile as the query and the second profile as a document.
- (2)
- KL Divergence (KLD): In this technique, a probability distribution is used to represent a researcher profile. For example, a multinomial distribution can be used to model the term counts in a researcher’s associated documents and to count the similarity between two probability distributions. KullbackLeibler divergence is used.
- (3)
- Probabilistic Modelling (PM): Latent Dirichlet Allocation is a widely used tool for topic modelling in unsupervised clustering of data and exploratory analysis. For example, when researchers have a desire to work on multiple related areas, sometimes it is more suitable to model their profiles as topic mixtures rather than a single multinomial distribution.
- (4)
- Trace-Based Similarity (REL): used density matrices to represent vector subspaces for modelling concepts. Additionally, reference [27] used content-based similarity to develop a model for finding similar experts in a university.
3.4.2. Discriminative Probabilistic Models
3.4.3. Voting Models
3.4.4. Network-Based Models
3.4.5. Hybrid Methods
3.4.6. Others
3.5. RQ5: What Are the Datasets That Have Been Used for Expert Finding Systems?
4. Research Findings on Identified Gaps
- Academia domains versus others—Table 3 shows that, from the six main domain categories in this study, the majority of the selected papers (65%) used expert finding systems in academia, which is developed for different tasks like finding research collaborators, paper reviewers, supervisors, similar experts, group of experts, and university–industry collaborators. Although using expert finding systems in academia is promising, integrating these tasks into one comprehensive system for the whole university is important. This system can assist universities in managing their knowledge assets, which is important for innovation. It also assists universities in finding the gap in specific areas, can support expert seekers by providing them to find an expert based on their knowledge, and can encourage them to seek knowledge and help. Additionally, it can assist the experts themselves by appreciating their efforts when they help people and share their knowledge; this leads to an increase in their reputation and widens their networks. Expert finding systems research have not attracted much attention in other domains. For example, in medicine, it can be used to find pharmacists, medical laboratory staff, dentists, and other medical staff. Developing these systems will help people all over the world to find an expert for their specific needs at any time.
- Expertise sources availability—According to the critical analysis of the selected studies, the authors found that the availability of expertise sources is a main challenge in the current studies of expert finding systems due to the following issues:
- a)
- Information privacy—System developers and organization owners must clearly identify the benefits of their systems. If users perceive value from expert finding systems, they will use these systems and supply the required personal information. Additionally, privacy-preserving techniques should be developed, and users should be given fair control over the storage and usage of their information [75].
- b)
- Data integration—In general, integration of different expertise sources is a challenging task, and there are four problems in data integration need more effort from researchers in the future, which are the following: (1) nicknaming, referring to the concept of different names in multiple networks for the same person; (2) name ambiguity, referring to individuals in social networks that have very similar or exactly the same name and a name may refer to different people; (3) multiple references, or finding more than one profile for the same person in a network; and (4) local access to profiles, as sometimes it is difficult to access the whole profiles in a network simultaneously. Thus, there is a need for crawling methods to access the profiles.
- c)
- Information updateness and completeness—integrating several data sources is very important in order to guarantee the completeness of expertise-related evidence. For example, in the academia domain, various expertise sources could be used, such as homepages, publications, research descriptions, course descriptions, social networks, project/grant repositories, supervised student theses, citation indexes, and movies. This information can be collected from staff homepages if the homepages are updated. A lot of this information has a shorter lifetime, and incomplete data can lead to wrong decisions. Thus, there is a lack of research for developing motivation frameworks for organizations to motivate their employees to update their profiles regularly.
- Expert finding systems methods—there is a need for developing sophisticated algorithms to integrate several expertise related evidences. For example, in a university, the expert profile is an important source of information due to the high quality of the data, but the data is not complete and is not usually updated. Furthermore, a social network also consists of a huge volume of data, but generally, the data quality is poorer than that of university data repositories. Hence, universities must integrate these information sources.
- Data sets—The current data sets for expert finding systems have been developed for a particular environment—for example, UvT, TU, DBLP, CiteSeer, and LExR—were developed for academia. TREC was developed for enterprise, and Yahoo! Answer, Facebook, and Twitter datasets were developed for social networks. There is a need for research to develop data sets that combine information from academia and social networks and from enterprise and social networks because they can complement each other, and the completed benchmark data sets can encourage expert finding systems developers to develop different systems. The benchmark data sets reduce the effort needed for solving information updates problems, information completeness, data cleaning, and name ambiguity problems. Additionally, many of the data on the web (not developed as a well-known data set) are either not updated or suffer from fake entries, and sometimes developers face a lack of access to resources. Therefore, developing benchmark data sets will reduce these challenges.
- Combining expertise retrieval and expertise seeking—Expertise retrieval systems and expertise seeking are concerned with finding experts, but expertise retrieval involves developing algorithms for identifying a set of people who possess the necessary expertise for a specific query based on all documents related to this candidate. Expertise seeking can be described as the the selection of people as a consultation source based on information needs. It is needed for further human-based knowledge. Expertise seeking helps in developing models to identify the factors that could play a vital role in an expert’s selection based on a human-centred viewpoint. These factors have been called contextual factors in previous research. A majority of research in expertise retrieval systems is dependent on a system-centred perspective, which concentrates on the identification of good matches between the need for expertise and content of documents related to experts. Integrating contextual factors with expertise retrieval systems can improve their effectiveness. Recent research has tried to combine these factors with expertise retrieval systems. Based on this study, the most factors that have been combined from expertise seeking to expertise retrieval are expert-related factors such as quality and accessibility. From the 14 studies in Table 7 that combined contextual factors with expertise retrieval, 10 studies combined expert related factors and the reset combined social, organizational, motivational, and community factors. Accordingly, expert-related factors are the most important factors in expertise retrieval. A majority of the current expert finding systems focused on the global notion of expertise. Due to the difficulties noted in the determination of the accepted definition of an expert along with the heterogeneity of the expertise sources, the complete data about the expert cannot be acquired. Hence, one needs to consider a personalised view of the expertise based on user-specific information requirements. Therefore, there is a need for researchers to develop suitable models based on a theoretical foundation that can examine the manner in which contextual factors influence expert selections in every domain. In the academic domain, researchers must develop a contextual-based model for each particular task, since it can be difficult to develop a common contextual-based model for all of a university’s tasks. These models can be integrated with content-based models to improve the performance of expert retrieval [16,25,27]. Previous studies have shown that there is a lack of information system research based on theoretical background for expert finding systems, such as developing user satisfaction and system success models. Additionally, there is a need for qualitative research in expertise seeking to explain how human-related factors influence the expert finding problem. There is a further need to develop novel expertise seeking models for particular tasks and domains. Finally, several factors affected the source selection in expertise seeking; the most frequently used factors are quality and accessibility, but their interactions are not yet understood. Many studies have investigated task- and seeker-related factors and determined the manner in which source accessibility and quality were affected by the various moderating factors. These factors moderate the effect of source quality and accessibility.
5. Threats to the Validity
- Construct validity was confirmed by an automated and manual (snowballing) search from the beginning of data collection to diminish calculated risks. In order to further control this TTV, the main steps of analysis and additional QAs were carried out complementing clear selection criteria.
- Internal validity was addressed by a combination method of automated and snowballing search, which was used for more comprehensive selection approach in order to reduce biases in paper selection. Every study went through strict selection protocols after its extraction from the identified databases.
- External validity was diminished with a generalizability of results by including a 10-year timeframe in expert finding systems and expertise seeking studies. The moderate number of studies (96 studies) could be an indicator that this SLR is capable of maintaining a generalized report.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Balog, K.; Fang, Y.; De Rijke, M.; Serdyukov, P.; Si, L. Expertise Retrieval. Found. Trends® Inf. Retr. 2012, 6, 127–256. [Google Scholar] [CrossRef]
- Anderson, P. Perspective: Complexity Theory and Organization Science. Organ. Sci. 1999, 10, 216–232. [Google Scholar] [CrossRef]
- Weiss, D.J.; Shanteau, J. Empirical Assessment of Expertise. Hum. Factors 2003, 45, 104–116. [Google Scholar] [CrossRef] [PubMed]
- Lin, S.; Hong, W.; Wang, D.; Li, T. A Survey on Expert Finding Techniques. J. Intell. Inf. Syst. 2017, 49, 1–25. [Google Scholar] [CrossRef]
- Naeem, M.; Khan, M.B.; Afzal, M.T. Expert Discovery: A Web Mining Approach. J. Data Min. 2013, 1, 35–47. [Google Scholar]
- Mangaravite, V.; Santos, R.L.; Ribeiro, I.S.; Gonçalves, M.A.; Laender, A.H. The Lexr Collection for Expertise Retrieval in Academia. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016; pp. 721–724. [Google Scholar]
- Yimam-Seid, D.; Kobsa, A. Expert-Finding Systems for Organizations: Problem and Domain Analysis and the Demoir Approach. J. Organ. Comput. Electron. Commer. 2003, 13, 1–24. [Google Scholar] [CrossRef]
- Stankovic, M.; Wagner, C.; Jovanovic, J.; Laublet, P. Looking for Experts? What Can Linked Data do for You? Available online: https://www.researchgate.net/publication/221023369_Looking_for_Experts_What_can_Linked_Data_do_for_You (accessed on 11 October 2019).
- Balog, K.; Azzopardi, L.; De Rijke, M. A Language Modeling Framework for Expert Finding. Inf. Process. Manag. 2009, 45, 1–19. [Google Scholar] [CrossRef]
- Ehrlich, K. Locating Expertise: Design Issues for an Expertise Locator System. Shar. Expertise-Beyond Knowledge Management; Mit Press: Cambridge, MA, USA, 2003; pp. 137–158. [Google Scholar]
- Mcdonald, D.W.; Ackerman, M.S. Expertise Recommender: A Flexible Recommendation System and Architecture. In Proceedings of the 2000 ACM Conference on Computer Supported Cooperative Work, Philadelphia, PA, USA, 2000; pp. 231–240. [Google Scholar]
- Mcdonald, D.W. Evaluating Expertise Recommendations. In Proceedings of the 2001 International ACM Siggroup Conference on Supporting Group Work, Boulder, CO, USA, 30 September–3 October 2001; pp. 214–223. [Google Scholar]
- Mockus, A.; Herbsleb, J.D. Expertise Browser: A Quantitative Approach To Identifying Expertise. In Proceedings of the 24th International Conference on Software Engineering, Orlando, FL, USA, 25–25 May 2002; pp. 503–512. [Google Scholar]
- Craswell, N.; Hawking, D.; Vercoustre, A.-M.; Wilkins, P. P@ Noptic Expert: Searching for Experts Not Just for Documents. In Ausweb Poster Proceedings; Southern Cross University: Queensland, Australia, 2001; p. 17. [Google Scholar]
- Li, M.; Liu, L.; Li, C.-B. An Approach to Expert Recommendation Based on Fuzzy Linguistic Method and Fuzzy Text Classification in Knowledge Management Systems. Expert Syst. Appl. 2011, 38, 8586–8596. [Google Scholar] [CrossRef]
- Neshati, M.; Fallahnejad, Z.; Beigy, H. On Dynamicity of Expert Finding in Community Question Answering. Inf. Process. Manag. 2017, 53, 1026–1042. [Google Scholar] [CrossRef]
- Liu, D.-R.; Chen, Y.-H.; Kao, W.-C.; Wang, H.-W. Integrating Expert Profile, Reputation and Link Analysis for Expert Finding in Question-Answering Websites. Inf. Process. Manag. 2013, 49, 312–329. [Google Scholar] [CrossRef]
- Wang, G.A.; Jiao, J.; Abrahams, A.S.; Fan, W.; Zhang, Z. Expertrank: A Topic-Aware Expert Finding Algorithm for Online Knowledge Communities. Decis. Support Syst. 2013, 54, 1442–1451. [Google Scholar] [CrossRef]
- Huang, C.; Yao, L.; Wang, X.; Benatallah, B.; Sheng, Q.Z. Expert as a Service: Software Expert Recommendation Via Knowledge Domain Embeddings in Stack Overflow. In Proceedings of the 2017 IEEE International Conference on Web Services (ICWS), Honolulu, HI, USA, 25–30 June 2017; pp. 317–324. [Google Scholar]
- Sun, J.; Xu, W.; Ma, J.; Sun, J. Leverage Raf to Find Domain Experts on Research Social Network Services: A Big Data Analytics Methodology With Mapreduce Framework. Int. J. Prod. Econ. 2015, 165, 185–193. [Google Scholar] [CrossRef]
- Silva, A.T.P. A Research Analytics Framework for Expert Recommendation in Research Social Networks; City University of Hong Kong: Hong Kong, China, 2014. [Google Scholar]
- Silva, T.; Guo, Z.; Ma, J.; Jiang, H.; Chen, H. A Social Network-Empowered Research Analytics Framework for Project Selection. Decis. Support Syst. 2013, 55, 957–968. [Google Scholar] [CrossRef]
- Juang, M.-C.; Huang, C.-C.; Huang, J.-L. Efficient Algorithms for Team formation with a Leader in Social Networks. J. Supercomput. 2013, 66, 721–737. [Google Scholar] [CrossRef]
- Li, C.-T.; Shan, M.-K.; Lin, S.-D. Context-Based People Search in Labeled Social Networks. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management, Glasgow, Scotland, UK, 24–28 October 2011; pp. 1607–1612. [Google Scholar]
- Wang, Q.; Ma, J.; Liao, X.; Du, W. A Context-Aware Researcher Recommendation System for University-industry Collaboration on R&D Projects. Decis. Support Syst. 2017, 103, 46–57. [Google Scholar] [CrossRef]
- Alarfaj, F.; Kruschwitz, U.; Hunter, D.; Fox, C. Finding the Right Supervisor: Expert-Finding in a University Domain. In Proceedings of the 2012 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Student Research Workshop, Montréal, QC, Canada, 3–8 June 2012; pp. 1–6. [Google Scholar]
- Hofmann, K.; Balog, K.; Bogers, T.; De Rijke, M. Contextual Factors for Finding Similar Experts. J. Assoc. Inf. Sci. Technol. 2010, 61, 994–1014. [Google Scholar] [CrossRef]
- Fang, Y.; Si, L.; Mathur, A. Facfinder: Search for Expertise in Academic Institutions; Technical Report: Serc-Tr-294; Department of Computer Science, Purdue University: West Lafayette, Indiana, 2008. [Google Scholar]
- Petkova, D.; Croft, W.B. Proximity-Based Document Representation for Named Entity Retrieval. In Proceedings of the 16th ACM Conference on Conference on Information and Knowledge Management, Lisbon, Portugal, 6–10 November 2007; pp. 731–740. [Google Scholar]
- Balog, K.; Azzopardi, L.; De Rijke, M. Formal Models for Expert Finding in Enterprise Corpora. In Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Seattle, WA, USA, 6–11 August 2006; pp. 43–50. [Google Scholar]
- Fang, Y.; Si, L.; Mathur, A.P. Discriminative Graphical Models for Faculty Homepage Discovery. Inf. Retr. 2010, 13, 618–635. [Google Scholar] [CrossRef]
- Das, S.; Mitra, P.; Giles, C. Learning To Rank Homepages for Researchername Queries. In the International Workshop on Entity-Oriented Search; ACM, EOS, SIGIR 2011 Workshop: Beijing, China, 2011; pp. 53–58. [Google Scholar]
- Tang, J.; Zhang, J.; Yao, L.; Li, J.; Zhang, L.; Su, Z. Arnetminer: Extraction and Mining of Academic Social Networks. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 990–998. [Google Scholar]
- Brereton, P.; Kitchenham, B.A.; Budgen, D.; Turner, M.; Khalil, M. Lessons from Applying the Systematic Literature Review Process Within the Software Engineering Domain. J. Syst. Softw. 2007, 80, 571–583. [Google Scholar] [CrossRef]
- Paul, S.A. Find an Expert: Designing Expert Selection Interfaces for Formal Help-Giving. In Proceedings of the 34th Annual Conference on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; pp. 3038–3048. [Google Scholar]
- Wu, W.; Zhang, W.; Yang, Y.; Wang, Q. Drex: Developer Recommendation With K-Nearest-Neighbor Search and Expertise Ranking. In Proceedings of the 18th Asia Pacific Software Engineering Conference (Apsec), Ho Chi Minh, Vietnam, 5–8 December 2011; pp. 389–396. [Google Scholar]
- Sziklai, B. How to Identify Experts in a Community? Int. J. Game Theory 2018, 47, 155–173. [Google Scholar] [CrossRef]
- Tran, H.D.; Cabanac, G.; Hubert, G. Expert Suggestion for Conference Program Committees. In Proceedings of the 11th International Conference on Research Challenges in Information Science (Rcis), Brighton, UK, 10–12 May 2017; pp. 221–232. [Google Scholar]
- Liu, D.; Xu, W.; Du, W.; Wang, F. How to Choose Appropriate Experts for Peer Review: An Intelligent Recommendation Method in a Big Data Context. Data Sci. J. 2015, 14, 16. [Google Scholar] [CrossRef]
- Gollapalli, S.D.; Mitra, P.; Giles, C.L. Similar Researcher Search in Academic Environments. In Proceedings of the 12th ACM/IEEE-CS Joint Conference on Digital Libraries, Washington, DC, USA, 10–14 June 2012; pp. 167–170. [Google Scholar]
- Berendsen, R.; Rijke, M.; Balog, K.; Bogers, T.; Bosch, A. On the Assessment of Expertise Profiles. J. Assoc. Inf. Sci. Technol. 2013, 64, 2024–2044. [Google Scholar] [CrossRef]
- Kong, W.; Liu, Q.; Yang, Z.; Han, S. Collaborative Filtering Algorithm Incorporated with Cluster-Based Expert Selection. J. Inf. Comput. Sci. 2012, 9, 3421–3429. [Google Scholar]
- Smirnova, E.; Balog, K. A User-Oriented Model for Expert Finding. Adv. Inf. Retr. 2011, 6611, 580–592. [Google Scholar]
- Taylor, M.; Richards, D. Finding and Validating Expertise; ECIS: London, UK, 2011. [Google Scholar]
- Torkzadeh Mahani, N.; Dehghani, M.; Mirian, M.S.; Shakery, A.; Taheri, K. Expert Finding by the Dempster-Shafer Theory for Evidence Combination. Expert Syst. 2018, 35, 12231. [Google Scholar] [CrossRef]
- Cifariello, P.; Ferragina, P.; Ponza, M. Wiser: A Semantic Approach for Expert Finding in Academia Based on Entity Linking. Inf. Syst. 2019, 82, 1–16. [Google Scholar] [CrossRef]
- Datta, A.; Yong, J.T.T.; Braghin, S. The Zen of Multidisciplinary Team Recommendation. J. Assoc. Inf. Sci. Technol. 2014, 65, 2518–2533. [Google Scholar] [CrossRef]
- Heck, T.; Hanraths, O.; Stock, W.G. Expert Recommendation for Knowledge Management in Academia. In Proceedings of the Association for Information Science and Technology, ASIST 2011, New Orleans, LA, USA, 9–13 October 2011; pp. 1–4. [Google Scholar]
- Sriharee, G.; Anekboon, K. Multiple Aspect Ranking for Researcher Expertise Finding. In Proceedings of the IEEE International Conference on Knowledge Engineering and Applications (Ickea), Singapore, 28–30 September 2016; pp. 207–211. [Google Scholar]
- Uddin, M.N.; Duong, T.H.; Oh, K.-J.; Jo, G.-S. An Ontology Based Model for Experts Search and Ranking. In Asian Conference on Intelligent Information and Database Systems; Springer: Berlin/Heidelberg, Germany; pp. 150–160.
- Wu, C.-J.; Chung, J.-M.; Lu, C.-Y.; Lee, H.-M.; Ho, J.-M. Using Web-Mining for Academic Measurement and Scholar Recommendation in Expert Finding System. In Proceedings of the 2011 IEEE/Wic/Acm International Conference on Web Intelligence and Intelligent Agent Technology (Wi-Iat), Lyon, France, 22–27 August 2011; pp. 288–291. [Google Scholar]
- Wu, H.; He, J.; Pei, Y.; Long, X. Finding Research Community in Collaboration Network with Expertise Profiling. In International Conference on Intelligent Computing; Springer: Berlin/Heidelberg, Germany, 2010; pp. 337–344. [Google Scholar]
- Xu, Y.; Guo, X.; Hao, J.; Ma, J.; Lau, R.Y.K.; Xu, W. Combining Social Network and Semantic Concept Analysis for Personalized Academic Researcher Recommendation. Decis. Support Syst. 2012, 54, 564–573. [Google Scholar] [CrossRef]
- Zhan, Z.; Yang, L.; Bao, S.; Han, D.; Su, Z.; Yu, Y. Finding Appropriate Experts for Collaboration. In International Conference on Web-Age Information Management; Springer: Berlin/Heidelberg, Germany, 2011; pp. 327–339. [Google Scholar]
- Fazel-Zarandi, M.; Devlin, H.J.; Huang, Y.; Contractor, N. Expert Recommendation Based on Social Drivers, Social Network Analysis, and Semantic Data Representation. In Proceedings of the 2nd International Workshop on Information Heterogeneity and Fusion in Recommender Systems, Chicago, IL, USA, 27 October 2011; pp. 41–48. [Google Scholar]
- Davoodi, E.; Afsharchi, M.; Kianmehr, K. A Social Network-Based Approach to Expert Recommendation System. In International Conference on Hybrid Artificial Intelligence Systems; Springer: Berlin/Heidelberg, Germany, 2012; pp. 91–102. [Google Scholar]
- Davoodi, E.; Kianmehr, K.; Afsharchi, M. A Semantic Social Network-Based Expert Recommender System. Appl. Intell. 2013, 39, 1–13. [Google Scholar] [CrossRef]
- Price, S.; Flach, P.A. Computational Support for Academic Peer Review: A Perspective From Artificial Intelligence. Commun. ACM 2017, 60, 70–79. [Google Scholar] [CrossRef]
- Protasiewicz, J.; Pedrycz, W.; Kozłowski, M.; Dadas, S.; Stanisławek, T.; Kopacz, A.; Gałężewska, M. A Recommender System of Reviewers and Experts in Reviewing Problems. Knowl. Based Syst. 2016, 106, 164–178. [Google Scholar] [CrossRef]
- Afzal, M.T.; Maurer, H.A. Expertise Recommender System for Scientific Community. J. UCS 2011, 17, 1529–1549. [Google Scholar]
- Kargar, M.; An, A. Discovering Top-K Teams of Experts with/without a Leader in Social Networks. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management, Glasgow, Scotland, UK, 24–28 October 2011; pp. 985–994. [Google Scholar]
- Neshati, M.; Beigy, H.; Hiemstra, D. Multi-Aspect Group formation Using Facility Location Analysis. In Proceedings of the 17th Australasian Document Computing Symposium, Dunedin, New Zealand, 5–6 December 2012; pp. 62–71. [Google Scholar]
- Neshati, M.; Beigy, H.; Hiemstra, D. Expert Group Formation Using Facility Location Analysis. Inf. Process. Manag. 2014, 50, 361–383. [Google Scholar] [CrossRef]
- Yang, M.-S.; Kang, N.-K.; Kim, Y.-J.; Kim, J.-S.; Choi, K.-N.; Kim, Y.-K. Expert Recommendation System Based on Analyzing Expertise and Networks of Human Resources in National Science & Technology Information Service. J. Central South Univ. 2013, 20, 2212–2218. [Google Scholar]
- Xu, W.; Sun, J.; Ma, J.; Du, W. A Personalized Information Recommendation System for R&D Project Opportunity Finding in Big Data Contexts. J. Netw. Comput. Appl. 2016, 59, 362–369. [Google Scholar] [CrossRef]
- Chen, H.-H.; Treeratpituk, P.; Mitra, P.; Giles, C.L. Csseer: An Expert Recommendation System Based on Citeseerx. In Proceedings of the 13th ACM/IEEE-CS Joint Conference on Digital Libraries, Indianapolis, IN, USA, 22–26 July 2013; pp. 381–382. [Google Scholar]
- Deng, H.; Han, J.; Lyu, M.R.; King, I. Modeling and Exploiting Heterogeneous Bibliographic Networks for Expertise Ranking. In Proceedings of the 12th ACM/IEEE-CS Joint Conference on Digital Libraries, Washington, DC, USA, 10–14 June 2012; pp. 71–80. [Google Scholar]
- Deng, H.; King, I.; Lyu, M.R. Enhanced Models for Expertise Retrieval Using Community-Aware Strategies. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2012, 42, 93–106. [Google Scholar] [CrossRef] [PubMed]
- Moreira, C.; Martins, B.; Calado, P. Using Rank Aggregation for Expert Search in Academic Digital Libraries. arXiv 2015, arXiv:physics/1501.05140. [Google Scholar]
- Moreira, C.; Wichert, A. Finding Academic Experts on A Multisensor Approach Using Shannon’s Entropy. Expert Syst. Appl. 2013, 40, 5740–5754. [Google Scholar] [CrossRef]
- Neshati, M.; Hiemstra, D.; Asgari, E.; Beigy, H. Integration of Scientific and Social Networks. World Wide Web 2014, 17, 1051–1079. [Google Scholar] [CrossRef][Green Version]
- Ribeiro, I.S.; Santos, R.L.; Gonçalves, M.A.; Laender, A.H. On Tag Recommendation for Expertise Profiling: a Case Study in the Scientific Domain. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, Shanghai, China, 2–6 February 2015; pp. 189–198. [Google Scholar]
- Sateli, B.; Löffler, F.; König-Ries, B.; Witte, R. Scholarlens: Extracting Competences from Research Publications for the Automatic Generation of Semantic User Profiles. PeerJ Comput. Sci. 2017, 3, 121. [Google Scholar] [CrossRef]
- Alhabashneh, O.; Iqbal, R.; Doctor, F.; James, A. Fuzzy Rule Based Profiling Approach for Enterprise Information Seeking and Retrieval. Inf. Sci. 2017, 394, 18–37. [Google Scholar] [CrossRef]
- Beham, G.; Kump, B.; Ley, T.; Lindstaedt, S. Recommending Knowledgeable People in a Work-Integrated Learning System. Procedia Comput. Sci. 2010, 1, 2783–2792. [Google Scholar] [CrossRef][Green Version]
- Guy, I.; Avraham, U.; Carmel, D.; Ur, S.; Jacovi, M.; Ronen, I. Mining Expertise and Interests from Social Media. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 515–526. [Google Scholar]
- Liang, S.; De Rijke, M. formal Language Models for Finding Groups of Experts. Inf. Process. Manag. 2016, 52, 529–549. [Google Scholar] [CrossRef]
- Ruiz-Martínez, J.M.; Miñarro-Giménez, J.A.; Martínez-Béjar, R. An Ontological Model for Managing Professional Expertise. Knowl. Manag. Res. Pract. 2016, 14, 390–400. [Google Scholar] [CrossRef]
- Schunk, L.K.; Cong, G. Using Transactional Data from Erp Systems for Expert Finding. In Proceedings of theInternational Conference on Database and Expert Systems Applications, Bilbao, Spain, 30 August–3 September 2010; pp. 267–276. [Google Scholar]
- Chen, W.; Lu, W.; Han, S. Designing and Implementation of Expertise Search & Hotspot Detecting System. In Proceedings of the2010 6th International Conference on Networked Computing (INC), Gyeongju, Korea, 11–13 May 2010; pp. 1–5. [Google Scholar]
- Tekin, C.; Atan, O.; Van Der Schaar, M. Discover the Expert: Context-Adaptive Expert Selection for Medical Diagnosis. IEEE Trans. Emerg. Top. Comput. 2015, 3, 220–234. [Google Scholar] [CrossRef]
- Rafiei, M.; Kardan, A.A. A Novel Method for Expert Finding in Online Communities Based on Concept Map and Pagerank. Hum. Centric Comput. Inf. Sci. 2015, 5, 10. [Google Scholar] [CrossRef]
- Xu, C.; Wang, X.; Guo, Y. Collaborative Expert Recommendation for Community-Based Question Answering; Springer International Publishing: Cham, Switzerland, 2016; pp. 378–393. [Google Scholar]
- Faisal, M.; Daud, A.; Akram, A. Expert Ranking Using Reputation and Answer Quality of Co-Existing Users. Int. Arab J. Inf. Technol. (Iajit) 2017, 14, 118–126. [Google Scholar]
- Omidvar, A.; Garakani, M.; Safarpour, H.R. Context Based User Ranking in Forums for Expert Finding Using Wordnet Dictionary and Social Network Analysis. Inf. Technol. Manag. 2014, 15, 51–63. [Google Scholar] [CrossRef]
- Bozzon, A.; Brambilla, M.; Ceri, S.; Silvestri, M.; Vesci, G. Choosing the Right Crowd: Expert Finding in Social Networks. In Proceedings of the 16th International Conference on Extending Database Technology, Genoa, Italy, 18–22 March 2013; pp. 637–648. [Google Scholar]
- Rivera-Pelayo, V.; Braun, S.; Riss, U.V.; Witschel, H.F.; Hu, B. Building Expert Recommenders From Email-Based Personal Social Networks. In The Influence of Technology on Social Network Analysis and Mining; Springer: Vienna, Austria, 2013; pp. 129–156. [Google Scholar]
- Xie, X.; Li, Y.; Zhang, Z.; Pan, H.; Han, S. A Topic-Specific Contextual Expert Finding Method in Social Network. In Proceedings of Asia-Pacific Web Conference; Springer: Cham, Switzerland, 2016; pp. 292–303. [Google Scholar]
- Heck, T.; Peters, I.; Stock, W.G. Testing Collaborative Filtering Against Co-Citation Analysis and Bibliographic Coupling for Academic Author Recommendation. In Proceedings of the 3rd Acm Recsys’ 11 Workshop on Recommender Systems and the Social Web, Chicago, IL, USA, 23–27 October 2011; pp. 16–23. [Google Scholar]
- Hertzum, M. Expertise Seeking: A Review. Inf. Process. Manag. 2014, 50, 775–795. [Google Scholar] [CrossRef]
- Cross, R.; Sproull, L. More Than An Answer: Information Relationships for Actionable Knowledge. Organ. Sci. 2004, 15, 446–462. [Google Scholar] [CrossRef]
- Zimmer, J.C.; Henry, R.M. The Role of Social Capital in Selecting Interpersonal Information Sources. J. Assoc. Inf. Sci. Technol. 2017, 68, 5–21. [Google Scholar] [CrossRef]
- Nahapiet, J.; Ghoshal, S. Social Capital, Intellectual Capital, and the Organizational Advantage. Acad. Manag. Rev. 1998, 23, 242–266. [Google Scholar] [CrossRef]
- Yuan, Y.C.; Fulk, J.; Monge, P.R.; Contractor, N. Expertise Directory Development, Shared Task Interdependence, and Strength of Communication Network Ties as Multilevel Predictors of Expertise Exchange in Transactive Memory Work Groups. Commun. Res. 2010, 37, 20–47. [Google Scholar] [CrossRef]
- Fidel, R.; Green, M. The Many Faces of Accessibility: Engineers’ Perception of Information Sources. Inf. Process. Manag. 2004, 40, 563–581. [Google Scholar] [CrossRef]
- Cross, R.; Borgatti, S.P. The Ties that Share: Relational Characteristics that Facilitate Information Seeking. Soc. Cap. Inf. Technol. 2004, 137–161. [Google Scholar]
- Liu, J.; Belkin, N.J. Personalizing Information Retrieval for Multi-Session Tasks: Examining the Roles of Task Stage, Task Type, and Topic Knowledge on the Interpretation of Dwell Time as an Indicator of Document Usefulness. J. Assoc. Inf. Sci.Technol. 2015, 66, 58–81. [Google Scholar] [CrossRef]
- Allen, B. Information Needs: A Person-in-Situation Approach. In Proceedings of thean International Conference on Information Seeking in Context, Tampere, Finland, 14–16 August 1997; pp. 111–122. [Google Scholar]
- Ingwersen, P.; Järvelin, K. Information Retrieval in Context: Irix. In ACM Sigir Forum; ACM: New York, NY, USA, 2005; pp. 31–39. [Google Scholar]
- Lu, L.; Yuan, Y.C. Shall I Google it or Ask the Competent Villain Down the Hall? The Moderating Role of Information Need in Information Source Selection. J. Assoc. Inf. Sci. Technol. 2011, 62, 133–145. [Google Scholar] [CrossRef]
- Yuan, Y.C.; Carboni, I.; Ehrlich, K. The Impact of Awareness and Accessibility on Expertise Retrieval: A Multilevel Network Perspective. J. Assoc. Inf. Sci. Technol. 2010, 61, 700–714. [Google Scholar]
- Agarwal, N.K.; Xu, Y.C.; Poo, D.C. A Context-Based Investigation into Source Use By Information Seekers. J. Assoc. Inf. Sci. Technol. 2011, 62, 1087–1104. [Google Scholar] [CrossRef]
- Helms, R.W.; Diemer, D.; Lichtenstein, S. Exploring Barriers in Expertise Seeking: Why Don’t they Ask an Expert? In Proceedings of the 15th Pacific Asia Conference on Information Systems: Quality Research in Pacific, Brisbane, Qld, 7–11 July 2011. [Google Scholar]
- Nevo, D.; Benbasat, I.; Wand, Y. The Knowledge Demands of Expertise Seekers in Two Different Contexts: Knowledge Allocation Versus Knowledge Retrieval. In Proceedings of the 44th Hawaii International Conference on System Sciences, Hicss-44, Kauai, Hawaii, 5–8 January 2010. [Google Scholar]
- Woudstra, L.; Van Den Hooff, B.; Schouten, A.P. Dimensions of Quality and Accessibility: Selection of Human Information Sources from a Social Capital Perspective. Inf. Process. Manag. 2012, 48, 618–630. [Google Scholar] [CrossRef]
- Yuan, Y.C.; Carboni, I.; Ehrlich, K. The Impact of Interpersonal Affective Relationships and Awareness on Expertise Seeking: A Multilevel Network Investigation. Eur. J. Work Organ. Psychol. 2013, 23, 554–569. [Google Scholar] [CrossRef]
- Woudstra, L.; Hooff, B.; Schouten, A. The Quality Versus Accessibility Debate Revisited: A Contingency Perspective on Human Information Source Selection. J. Assoc. Inf. Sci. Technol. 2016, 67, 2060–2071. [Google Scholar] [CrossRef]
- Fang, H.; Zhai, C. Probabilistic Models for Expert Finding. In Proceedings of European Conference on Information Retrieval; Springer: Berlin/Heidelberg, Germany, 2007; pp. 418–430. [Google Scholar]
- Kong, X.; Jiang, H.; Wang, W.; Bekele, T.M.; Xu, Z.; Wang, M. Exploring Dynamic Research interest and Academic Influence for Scientific Collaborator Recommendation. Scientometrics 2017, 113, 369–385. [Google Scholar] [CrossRef]
- Ng, A.Y.; Jordan, M.I. On Discriminative Vs. Generative Classifiers: A Comparison of Logistic Regression and Naive Bayes. In Proceedings of the Advances in Neural Information Processing Systems 14 (NIPS 2001), Vancouver, BC, Canada, 3–8 December 2001; pp. 841–848. [Google Scholar]
- Nallapati, R. Discriminative Models for Information Retrieval. In Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Sheffield, UK, 25–29 July 2004; pp. 64–71. [Google Scholar]
- Cooper, W.S. Exploiting the Maximum Entropy Principle To Increase Retrieval Effectiveness. J. Assoc. Inf. Sci. Technol. 1983, 34, 31–39. [Google Scholar] [CrossRef]
- Fang, Y.; Si, L.; Mathur, A.P. Discriminative Models of Integrating Document Evidence and Document-Candidate Associations for Expert Search. In Proceedings of the 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Geneva, Switzerland, 19–23 July 2010; pp. 683–690. [Google Scholar]
- Yahyaei, S.; Monz, C. Applying Maximum Entropy To Known-Item Email Retrieval. In Proceedings of European Conference on Information Retrieval; Springer: Berlin/Heidelberg, Germany, 2008; pp. 406–413. [Google Scholar]
- Ko, J.; Nyberg, E.; Si, L. A Probabilistic Graphical Model for Joint Answer Ranking in Question Answering. In Proceedings of the 30th Annual International Acm Sigir Conference on Research and Development in Information Retrieval, Amsterdam, The Netherlands, 23–27 July 2007; pp. 343–350. [Google Scholar]
- Liu, T.-Y. Learning To Rank for Information Retrieval. Found. Trends® Inf. Retr. 2009, 3, 225–331. [Google Scholar] [CrossRef]
- Zhu, J.; Huang, X.; Song, D.; Rüger, S. Integrating Multiple Document Features in Language Models for Expert Finding. Knowl. Inf. Syst. 2010, 23, 29–54. [Google Scholar] [CrossRef]
- Macdonald, C.; Ounis, I. Voting for Candidates: Adapting Data Fusion Techniques for an Expert Search Task. In Proceedings of the 15th ACM International Conference on Information and Knowledge Management, Arlington, VA, USA, 6–11 November 2006; pp. 387–396. [Google Scholar]
- Saracevic, T.; Kantor, P. A Study of Information Seeking and Retrieving. Iii. Searchers, Searches, and Overlap. J. Am. Soc. Inf. Sci. 1988, 39, 197. [Google Scholar] [CrossRef]
- Kleinberg, J.M. Authoritative Sources in a Hyperlinked Environment. J. ACM (JACM) 1999, 46, 604–632. [Google Scholar] [CrossRef]
- Brin, S.; Page, L. The Anatomy of a Large-Scale Hypertextual Web Search Engine. Comput. Netw. Isdn Syst. 1998, 30, 107–117. [Google Scholar] [CrossRef]
- Sanderson, M. Test Collection Based Evaluation of Information Retrieval Systems. Found. Trends® Inf. Retr. 2010, 4, 247–375. [Google Scholar] [CrossRef]
- Bailey, P.; De Vries, A.P.; Craswell, N.; Soboroff, I. Overview of the Trec 2007 Enterprise Track; TREC: Austin, TX, USA, 2007.
- Balog, K.; Bogers, T.; Azzopardi, L.; De Rijke, M.; Van Den Bosch, A. Broad Expertise Retrieval in Sparse Data Environments. In Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Amsterdam, The Netherlands, 23–27 July 2007; pp. 551–558. [Google Scholar]
- Deng, H.; King, I.; Lyu, M.R. Formal Models for Expert Finding on Dblp Bibliography Data. In Proceedings of the 8th IEEE International Conference on Data Mining, ICDM’08, Pisa, Italy, 15–19 December 2008; pp. 163–172. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Code | Research Questions |
|---|---|
| RQ1 | Which domains use the expertise retrieval systems? |
| RQ2 | What are the expertise sources used for experts finding systems? |
| RQ3 | What are the differences between expertise retrieval and expertise seeking, and what are the contextual factors and theories that have been integrated with expert finding systems? |
| RQ4 | What are the methods that have been used for expert finding systems? |
| RQ5 | What are the data sets that have been used for expert finding systems? |
| Inclusion Criteria | Exclusion Criteria |
|---|---|
| Study manuscript written in English | Not in English |
| Published in years (2010–2019) and in the selected databases | Duplicated studies |
| Full-text | Articles that did not match the inclusion criteria |
| Directly or indirectly answers the defined research question(s) | Not related to the research questions of this study |
| The Domain | Task | Frequency | References |
|---|---|---|---|
| Academia University | Research collaboration | 1 | [37] |
| Paper reviewing | 2 | [38,39] | |
| university-industry collaboration | 1 | [25] | |
| Supervisor finding | 1 | [26] | |
| Similar researcher | 2 | [27,40] | |
| No specific task | 6 | [41,42,43,44,45,46] | |
| Academia Social Network | Research collaboration | 12 | [20,21,47,48,49,50,51,52,53,54,55] |
| Paper reviewing | 7 | [5,21,56,57,58,59,60] | |
| Finding group of experts | 3 | [61,62,63] | |
| R&D | 2 | [64,65] | |
| No specific task | 8 | [66,67,68,69,70,71,72,73] | |
| Enterprise | 10 | [15,22,35,36,74,75,76,77,78,79] | |
| Medicine | 2 | [80,81] | |
| Knowledge Sharing Communities | 6 | [16,17,19,44,82,83] | |
| Online forums | 2 | [84,85] | |
| Social network | 4 | [56,57,86,87,88] |
| Channel | Expertise Sources | Studies |
|---|---|---|
| Textual sources | Publications | [36,38,44,48,49,53,58,59,61,62,66,67,68,70,71,72,73,80] |
| Movies | [42] | |
| Medicine related documents, | [80,81] | |
| Employee documents | [15,77] | |
| Bug repository | [36] | |
| Transactional data | [79] | |
| Enterprise terminologies’ | [78] | |
| Relevance feedback | [74] | |
| Log repository | [35] | |
| Homepages | [5,26,27,44,46] | |
| Emails | [87] | |
| Social networks | Social network | [20,21,37,56,57,76,86] |
| Forums | [84,85] | |
| Posts and questions tags | [16,17,19,44,82,83] | |
| Hybrid expertise sources | Employee documents, publications and projects | [75] |
| Proposals, publications | [22] | |
| homepages and social network | [39] | |
| Publications, supervised student theses, course descriptions, and research descriptions | [41,43] | |
| Publications and social networks | [44,47,55,69,88] | |
| Publications and homepages | [40] | |
| publications and citation data | [48] | |
| Projects–homepages | [65] | |
| publications, citations, homepages, Experience | [60] | |
| webpages, project/grant repositories, citation indexes | [44] |
| The Concept | Definition | Research Area | Sociotechnical Perspective |
|---|---|---|---|
| Expertise Retrieval | Developing systems that enable expertise seekers to identify and select experts in a particular area. | information retrieval | system-centered perspective |
| Expertise Seeking | Developing models to identify the factors that affect expert selection. | knowledge management | human-centered perspective |
| Antecedents | Findings | Moderators | Study |
|---|---|---|---|
| Information quality source accessibility | + information quality | - | [92] |
| + source accessibility | |||
| Cognitive accessibility, physical accessibility, relational accessibility, reliability, relevance | + quality | [96] | |
| + accessibility | |||
| social accessibility of expertise providers, technological accessibility, and awareness | + social accessibility | - | [92] |
| + technological accessibility | |||
| + awareness | |||
| Quality and accessibility (Physical accessibility, cognitive accessibility, relational accessibility, relevance technical quality(reliability)) | Without time pressure: | time pressure | [98] |
| + Physical accessibility | |||
| + Cognitive accessibility | |||
| + Relational accessibility | |||
| + Relevance | |||
| + Technical quality(reliability)) | |||
| Under time pressure: | |||
| + Physical accessibility | |||
| + Cognitive accessibility | |||
| + Relational accessibility | |||
| + Relevance | |||
| − Technical quality(reliability) | |||
| Relationships and awareness | + Positive relationships | - | [97] |
| (No effect) Negative Relationship | |||
| +Awareness | |||
| Quality, accessibility | Both quality and accessibility are important. Information need can function as a contingency factor such that the relative importance of quality over accessibility shifts with information need. | Information need | [91] |
| Willingness to help, network ties self-identified expertise, awareness of other resources, communication skills | ‘Willingness to help’ and ‘network ties to the respondent’ were more important for knowledge allocation. ‘self-identified expertise’ and ‘awareness of other resources’ were more important for knowledge retrieval. There was no significant difference in the importance of ‘communication skills’ attribute. | [95] | |
| source factors: Source quality, access difficulty, communication difficulty, seeker-source relationship: lack of confront | + source quality | task factors: importance, urgency, complexity | [93] |
| + access difficulty | |||
| + communication difficulty | |||
| + importance | |||
| − urgency | |||
| − complexity | |||
| Environment factors Accessibility factors Communication factors Personality factors Context factors | [94] |
| Dimension | Factors | Contexts | Reference | |||||||
| Academia | Enterprise | Social Networks | Online Knowledge Communities | |||||||
| Research collaboration | Reviewing | finding similar experts | R& D task | Not Specified | ||||||
| Expert-related factors | Topic of knowledge, familiarity, reliability, availability, perspective up-to-dateness, approachability, cognitive effort, contacts, physical proximity, saves time | √ | [27] | |||||||
| connectivity | √ | √ | √ | √ | [20,21,22,39] | |||||
| quality | √ | √ | √ | √ | √ | [20,21,25,35,39] | ||||
| Relevance | √ | √ | √ | [17,22,25] | ||||||
| user reputation | √ | [17] | ||||||||
| authority | √ | [17] | ||||||||
| accessibility | √ | [35] | ||||||||
| productivity | √ | [22] | ||||||||
| time to contact an expert and the knowledge value | √ | [43] | ||||||||
| Trust | √ | [25] | ||||||||
| Community factors | Number of documents Number of authors for each community | √ | [54] | |||||||
| Temporal factors | Location and Time | √ | [88] | |||||||
| Organizational factors | Organizational structure and Media experience | √ | [27] | |||||||
| Social factors | Experience, background knowledge level and personal preferences of experts | √ | [56,57] | |||||||
| User motivation factors: | Most qualified Friend of friend Birds of a feather Social exchange follow the crowd | √ | [55] | |||||||
| Methods | References |
|---|---|
| Generative probabilistic models | [27,40,77,109] |
| Discriminative probabilistic models | [31] |
| Voting models | [26,60,69] |
| Network-based models | [18,24,46,47,67,84] |
| Hybrid methods | [16,17,25,42,53,54,55,56,57,68,70,79,82,87,88] |
| Others | [5,15,20,22,36,39,45,50,51,59,61,62,63,74,78,81,83,85] |
| The Collection The Collection | Environment | Year Year | Inter-Organization | Inter-Area | Expert Profiling | Expert Finding | No of Documents | Studies Used the Test Collection |
|---|---|---|---|---|---|---|---|---|
| TREC | enterprise | 2007 | ✔ | ✔ | 370,715 | [27,74] | ||
| 2006 | ✔ | ✔ | 331,037 | [77] | ||||
| UvT | academia | 2006 | ✔ | ✔ | ✔ | 36,699 | [40,43] | |
| TU | academia | 2008 | ✔ | ✔ | ✔ | 31,209 | [46] | |
| DBLP | academia | 2008 | ✔ | ✔ | ≥2,300,000 | [5,24,45,49,54,61,67,68,69,70] | ||
| CiteSeer | academia | 2008 | ✔ | ✔ | ≥750,000 | [47,66,88] | ||
| LExR | academia | 2015 | ✔ | ✔ | ✔ | ✔ | 11,942,014 | [6] |
| Social network | 2009 | ✔ | ✔ | ✔ | - | [88] | ||
| Microsoft Academic Search | academia | 2016 | ✔ | ✔ | ✔ | ✔ | >220,000,000 | [47] |
| ACM Digital Library | academia | 1950 | ✔ | ✔ | ✔ | ✔ | >1,000,000 | [27,38,47,62,63] |
| Google Scholar | academia | 2004 | ✔ | ✔ | ✔ | ✔ | >389,000,000 | [47,50] |
| IEEE Xplore | academia | 1988 | ✔ | ✔ | ✔ | >4,500,000,000 | [47] | |
| Social network | 2006 | ✔ | ✔ | ✔ | ✔ | - | [47] | |
| Scholarmate | Social network | 2007 | ✔ | ✔ | ✔ | - | [20,22,25] | |
| Academia.edu | academia | 2008 | ✔ | ✔ | ✔ | >21,000,000 | [47] | |
| Wikipedia | academia | 2001 | ✔ | ✔ | ✔ | >40,000,000 | [56,57] | |
| Stack Overflow | question and answer website | 2008 | ✔ | ✔ | ✔ | - | [16,19,83] | |
| Yahoo! Answer | question and answer website | 2005 | ✔ | ✔ | ✔ | - | [17] | |
| Ask Me Help Desk | question and answer website | 2003 | ✔ | ✔ | ✔ | - | [85] |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Husain, O.; Salim, N.; Alias, R.A.; Abdelsalam, S.; Hassan, A. Expert Finding Systems: A Systematic Review. Appl. Sci. 2019, 9, 4250. https://doi.org/10.3390/app9204250
Husain O, Salim N, Alias RA, Abdelsalam S, Hassan A. Expert Finding Systems: A Systematic Review. Applied Sciences. 2019; 9(20):4250. https://doi.org/10.3390/app9204250
Chicago/Turabian StyleHusain, Omayma, Naomie Salim, Rose Alinda Alias, Samah Abdelsalam, and Alzubair Hassan. 2019. "Expert Finding Systems: A Systematic Review" Applied Sciences 9, no. 20: 4250. https://doi.org/10.3390/app9204250
APA StyleHusain, O., Salim, N., Alias, R. A., Abdelsalam, S., & Hassan, A. (2019). Expert Finding Systems: A Systematic Review. Applied Sciences, 9(20), 4250. https://doi.org/10.3390/app9204250