Fault Diagnosis Method for Engine Control System Based on Probabilistic Neural Network and Support Vector Machine


Abstract
:1. Introduction
2. Fault Diagnosis Algorithm Selection
2.1. Introduction of Probabilistic Neural Network
2.2. Introduction of Support Vector Machines
- Linear kernel function: .
- Polynomial kernel function: .
- Radial basis kernel function: .
- Two-layer perceptron kernel function: .
3. Analysis of the Fault State and Establishment of the Fault Data Sample
3.1. Analysis of Fault Signal
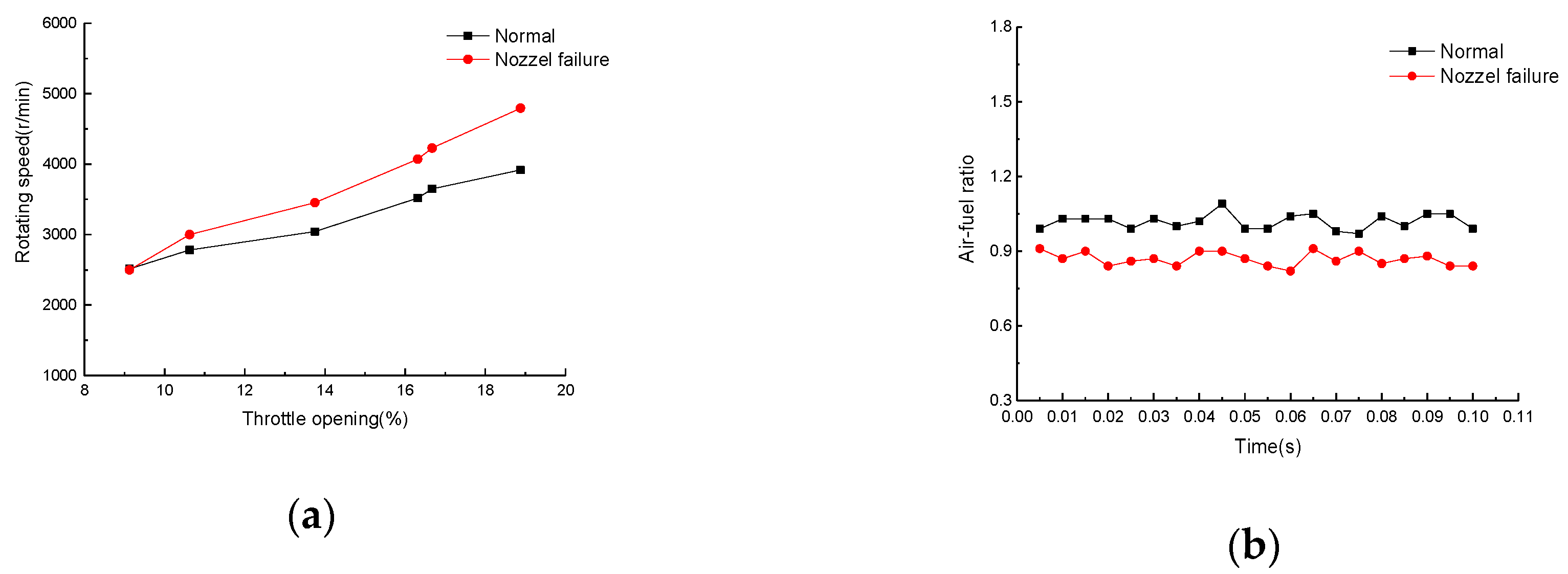
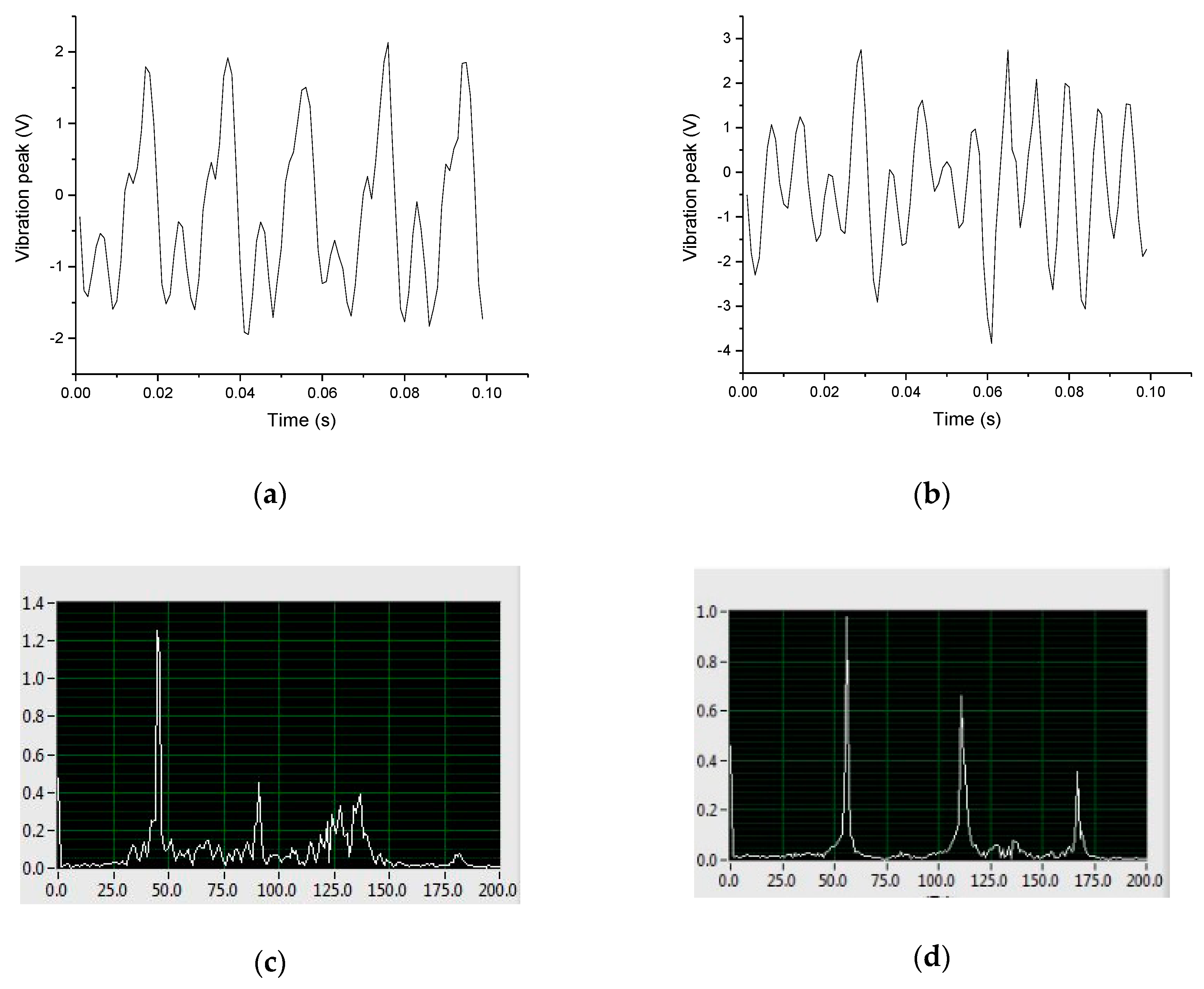
3.1.1. Fuel Injection Failure of the Injector
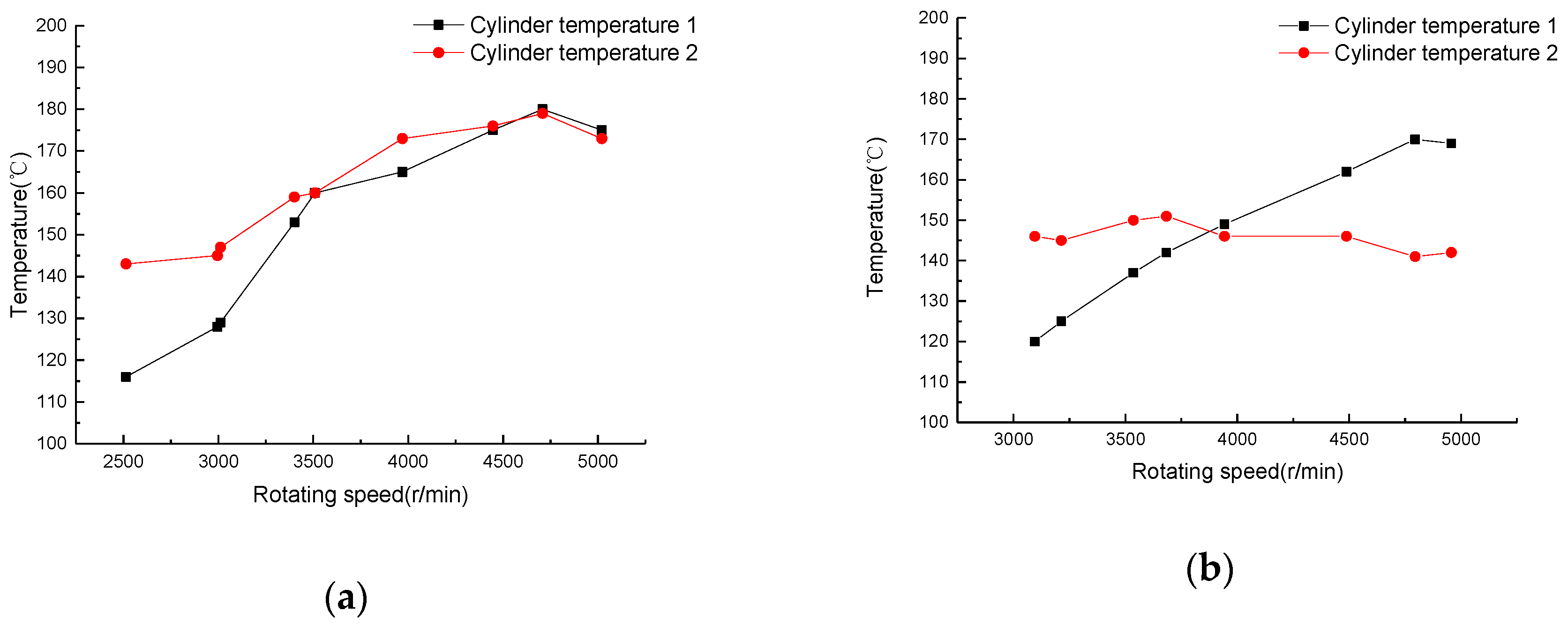
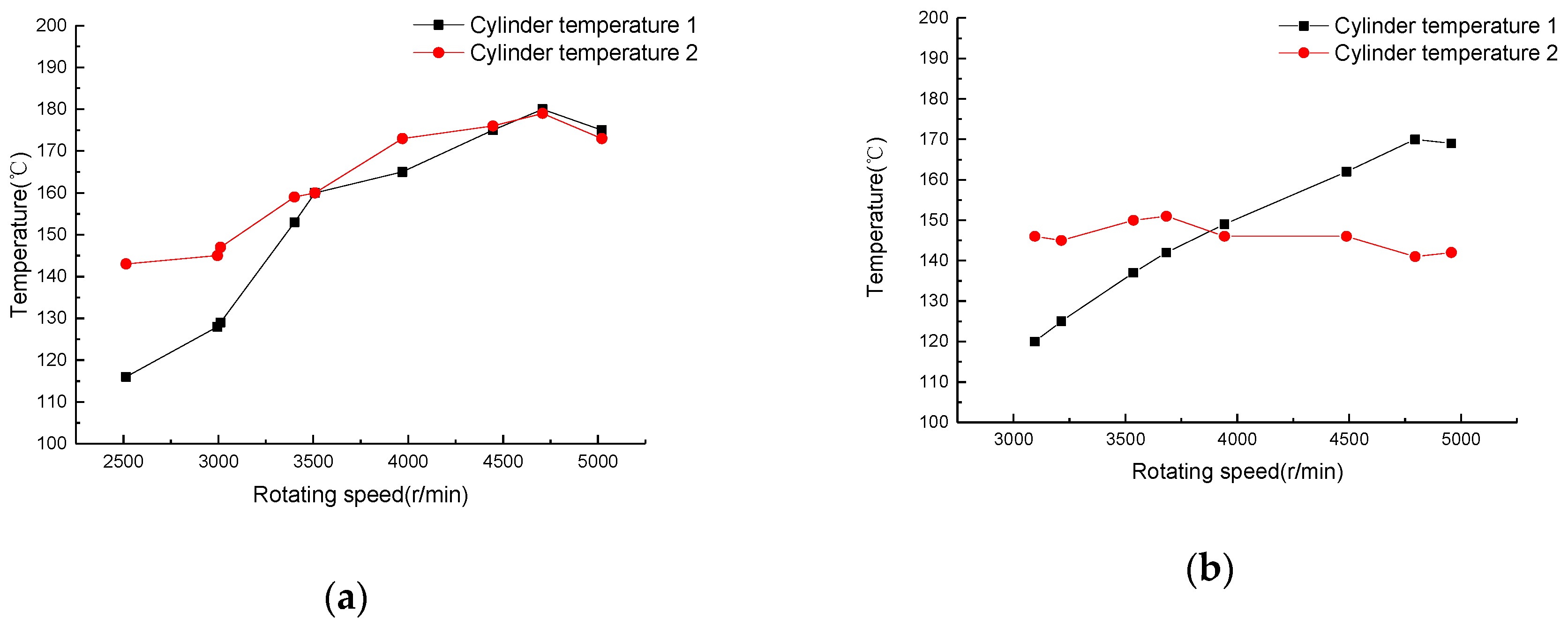
3.1.2. Low Fuel Supply Pressure
3.1.3. Leaks of the Exhaust Pipe
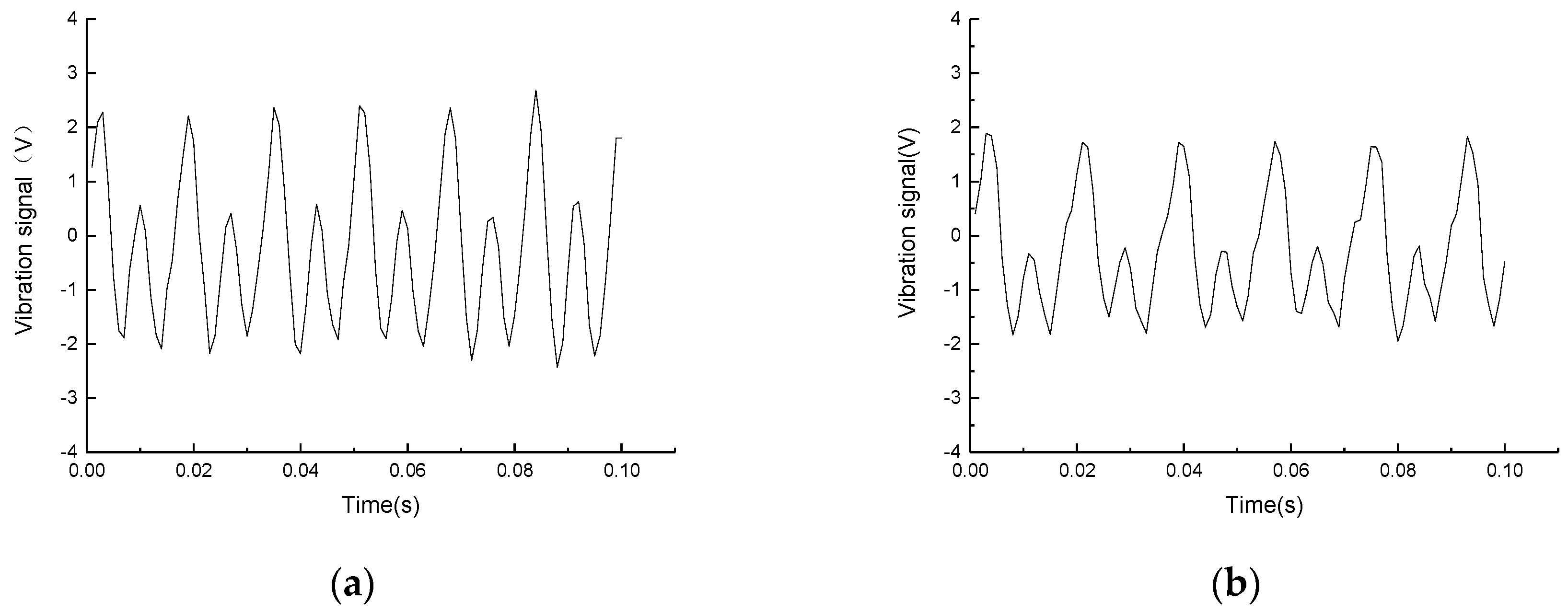
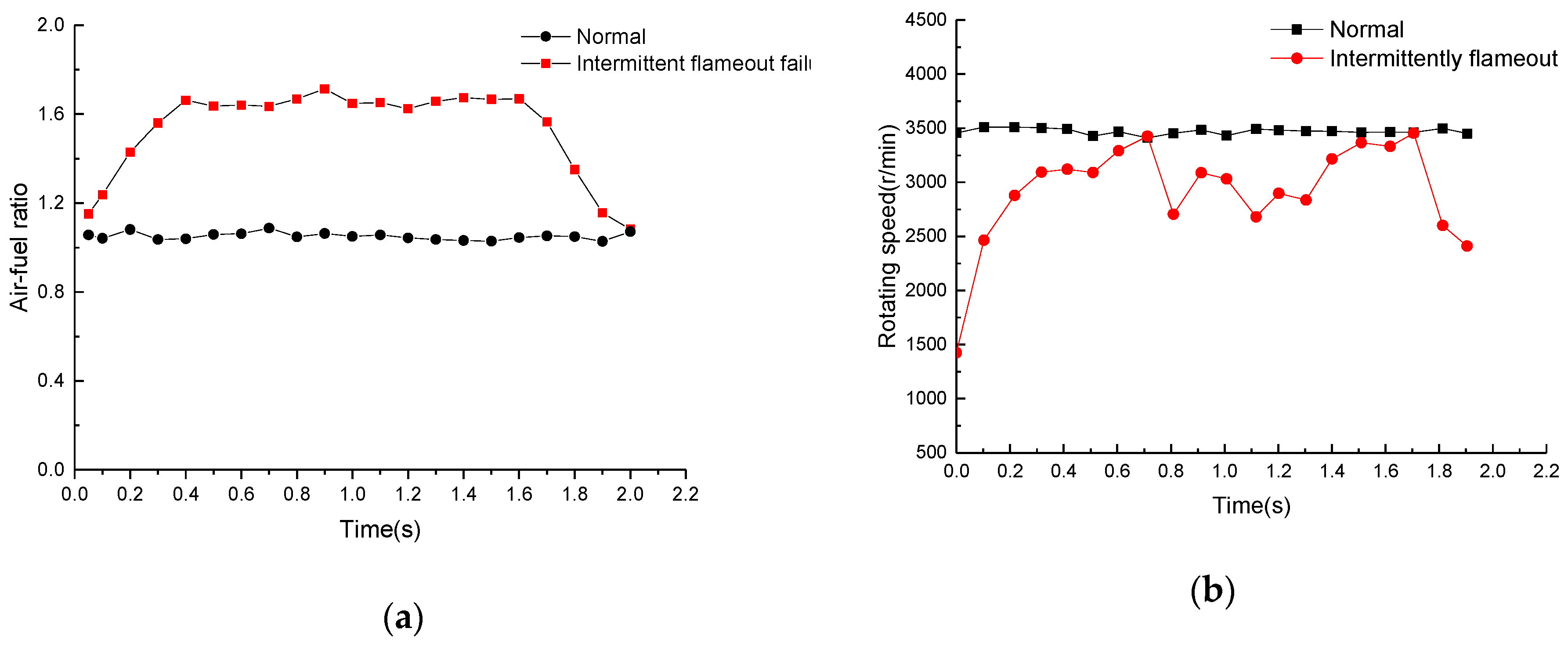
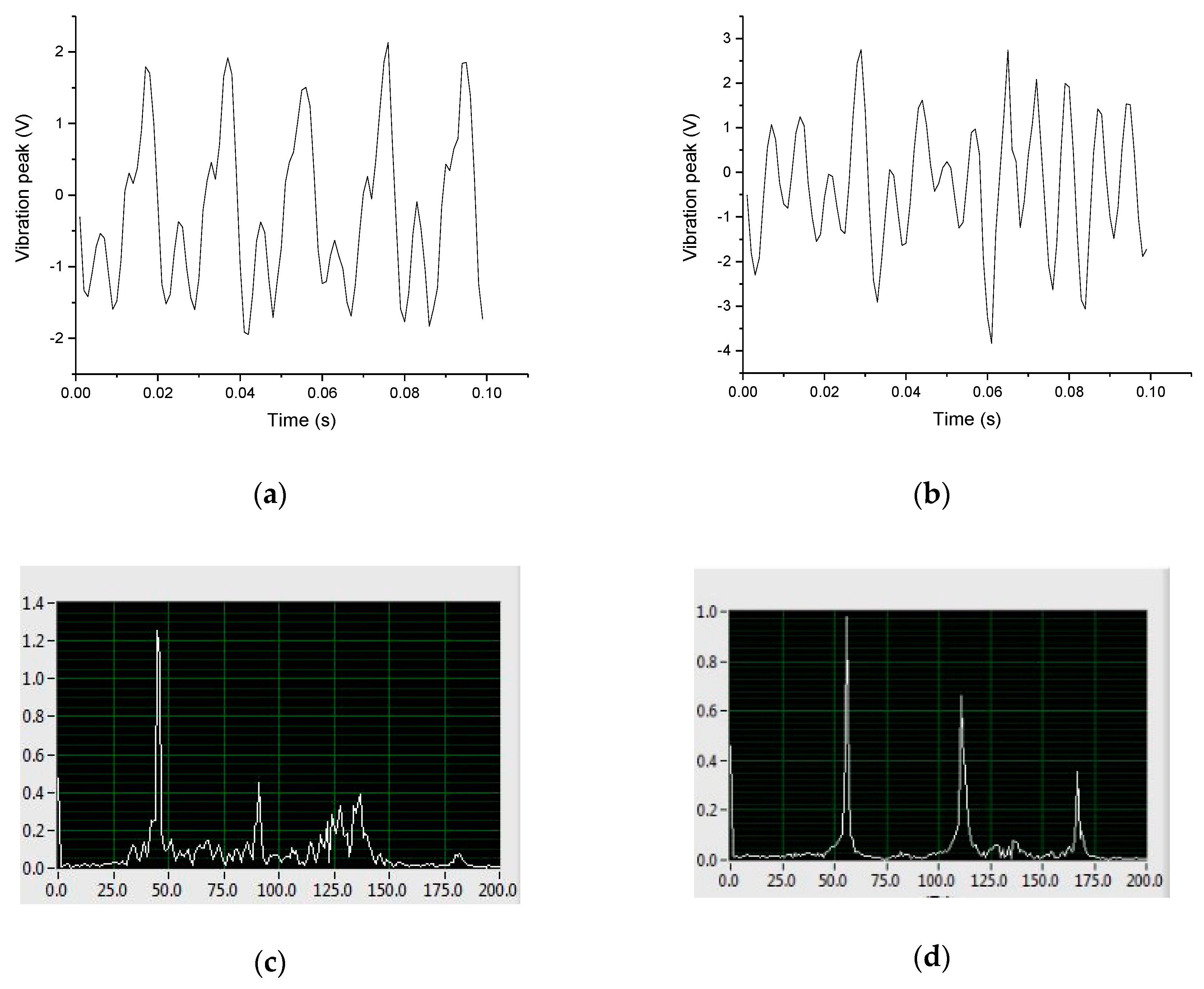
3.1.4. The Intermittently Flameout of Engine
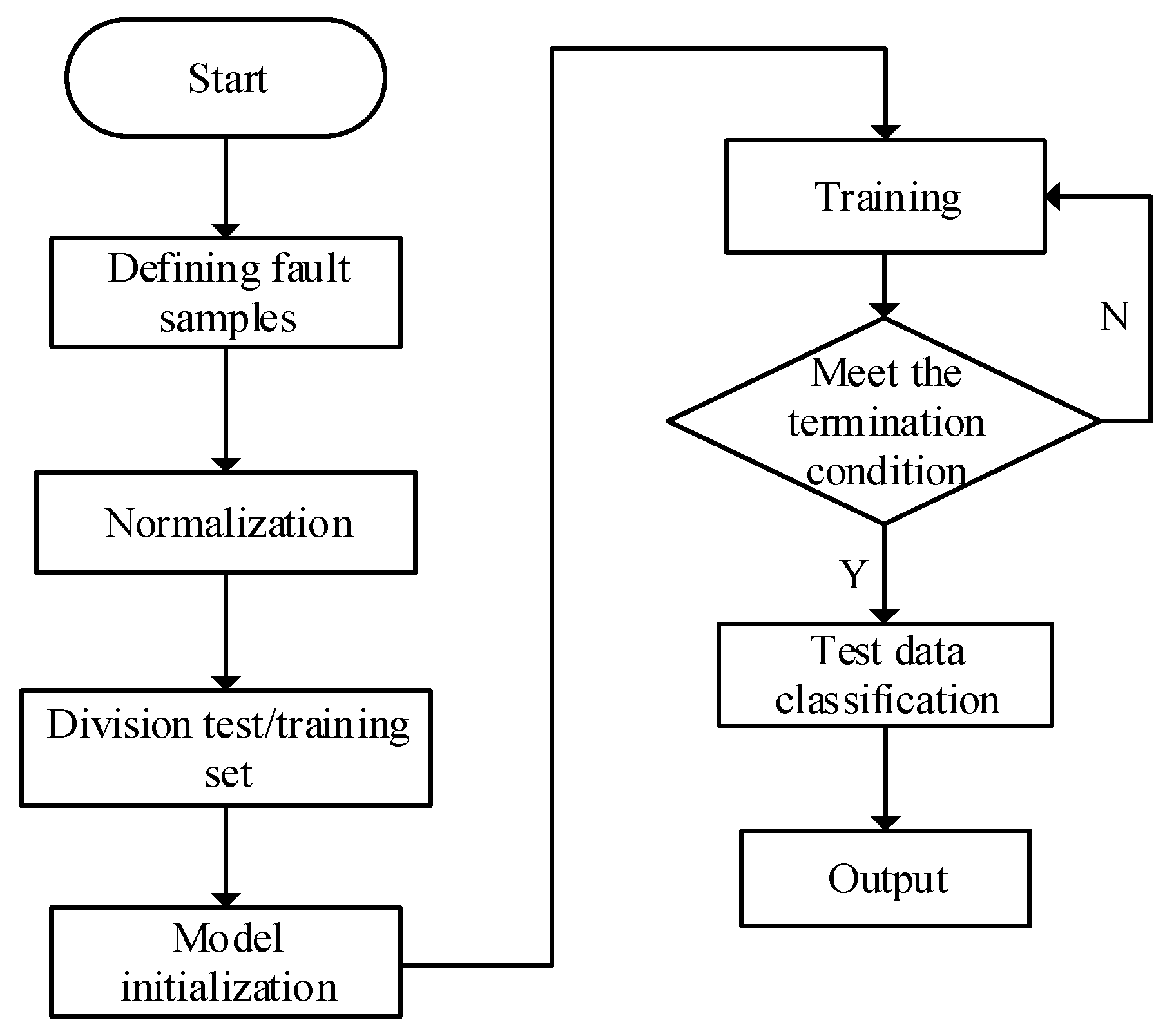
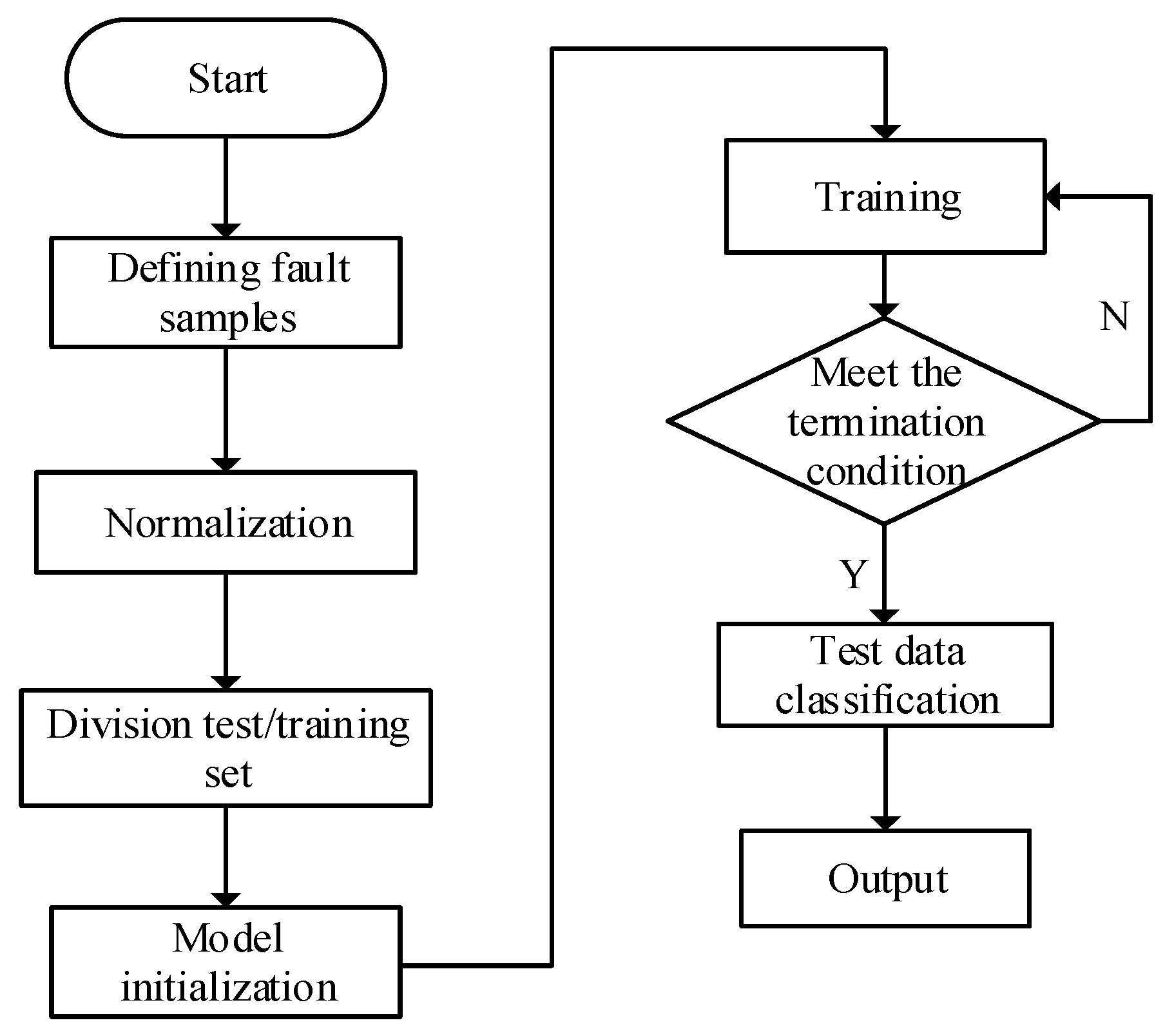
3.2. Creation of the Fault Diagnosis Data Sample
3.3. Data Processing
4. Introduction to Particle Swarm Optimization Algorithm
5. Results and Analysis of the Optimization Algorithm
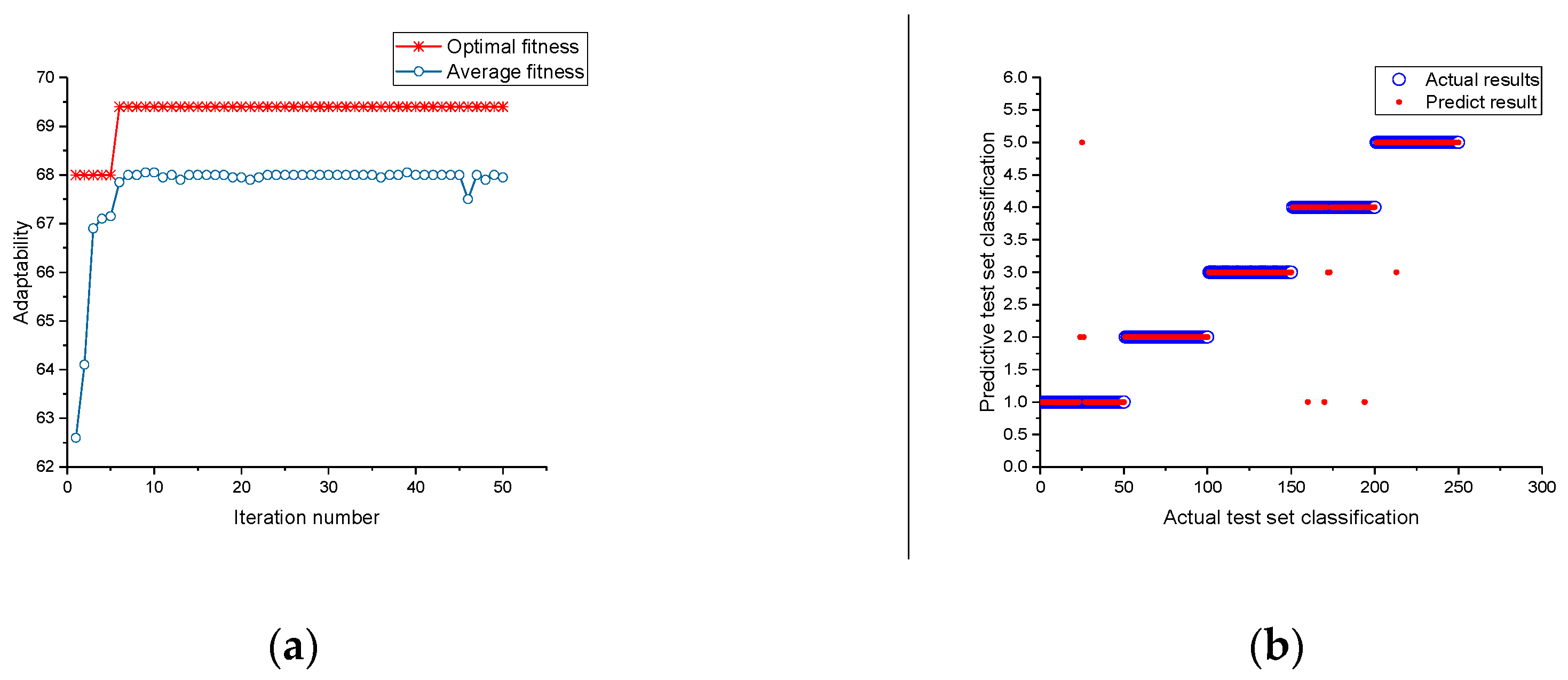
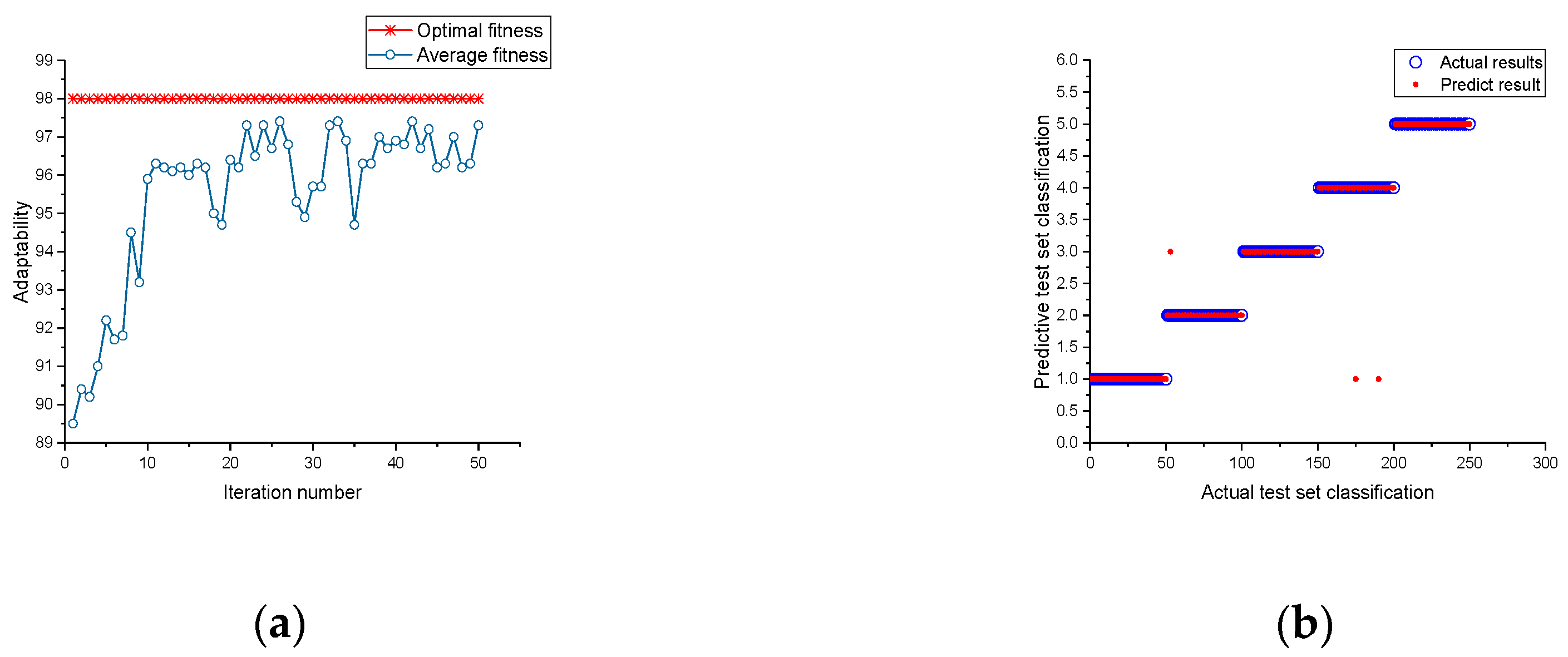
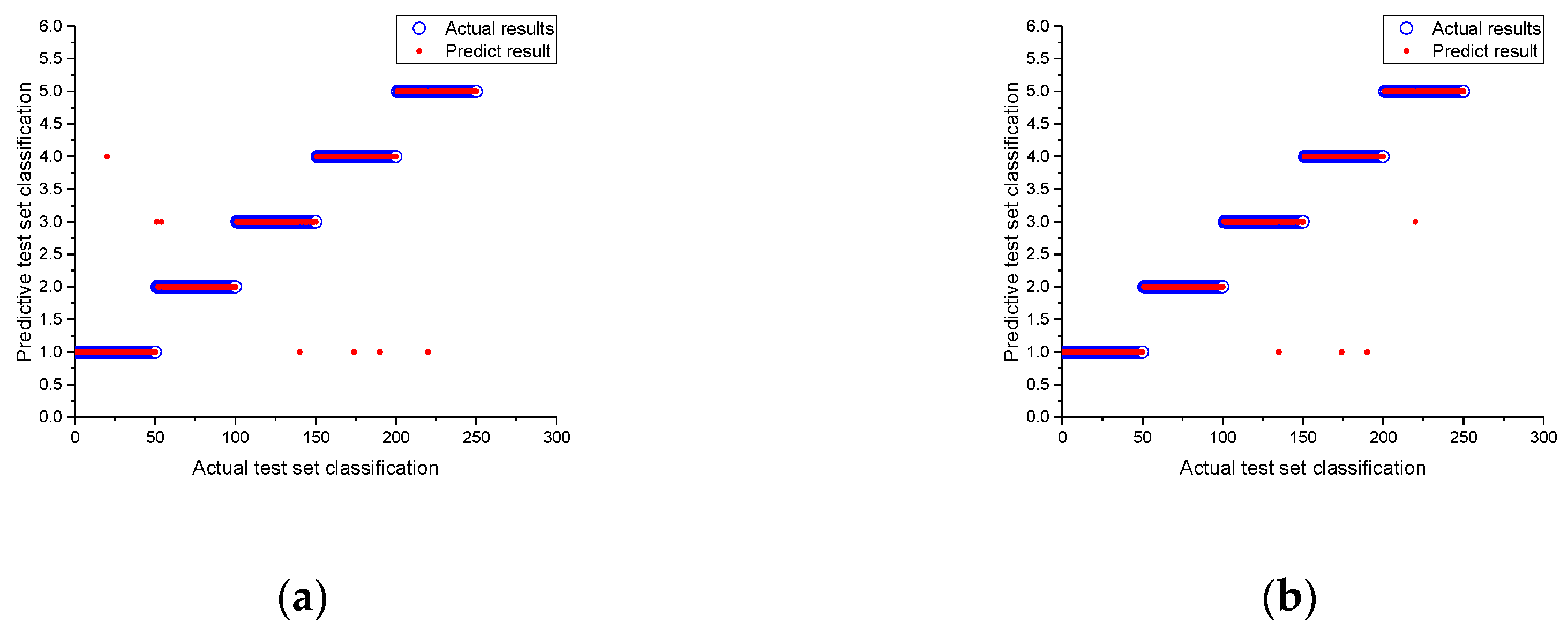
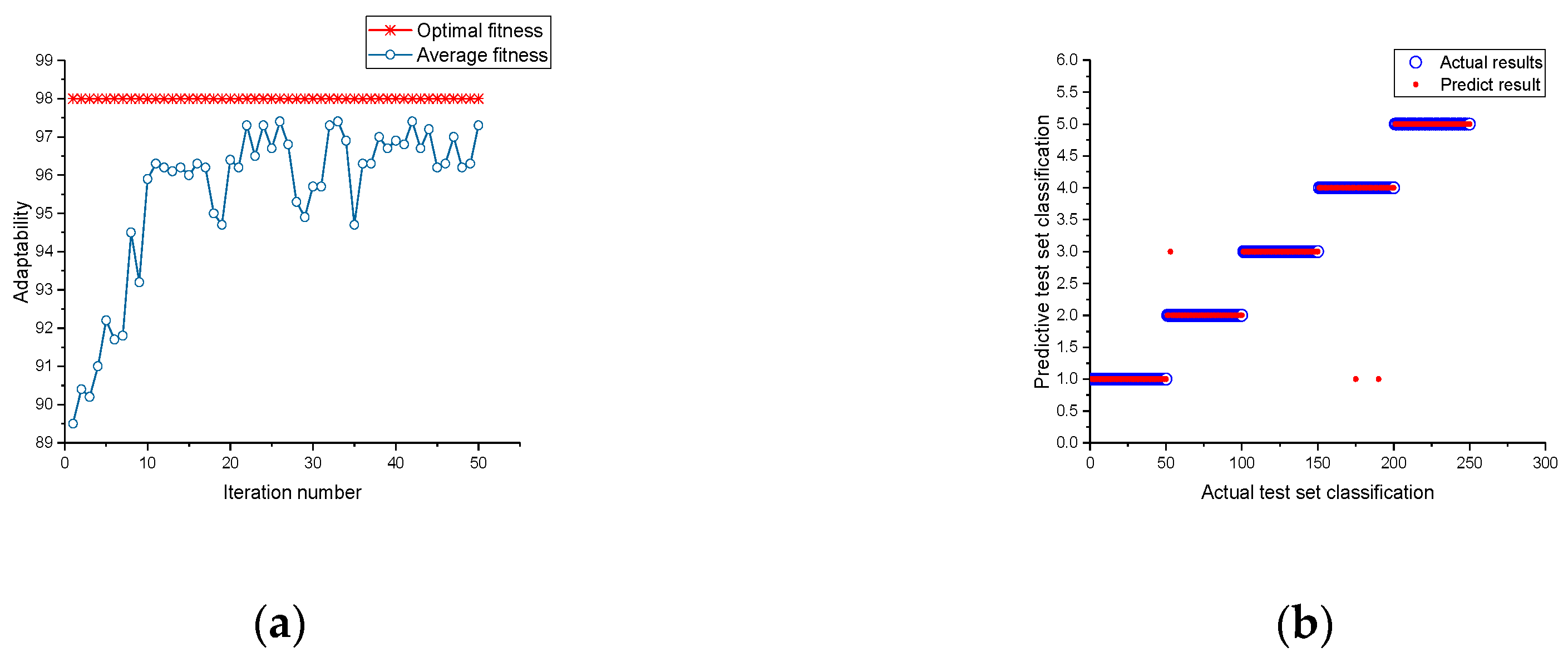
5.1. Results of the Probabilistic Neural Optimization
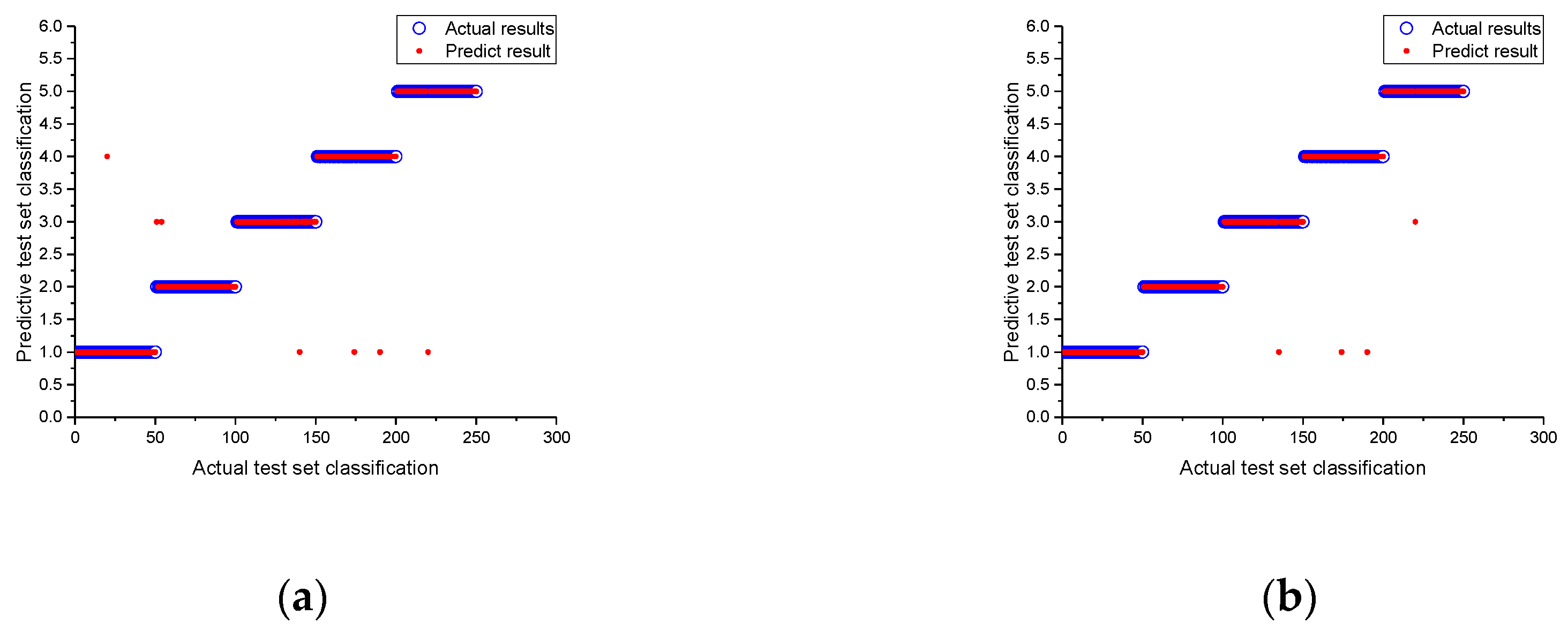
5.2. Results of the Support Vector Machine Optimization
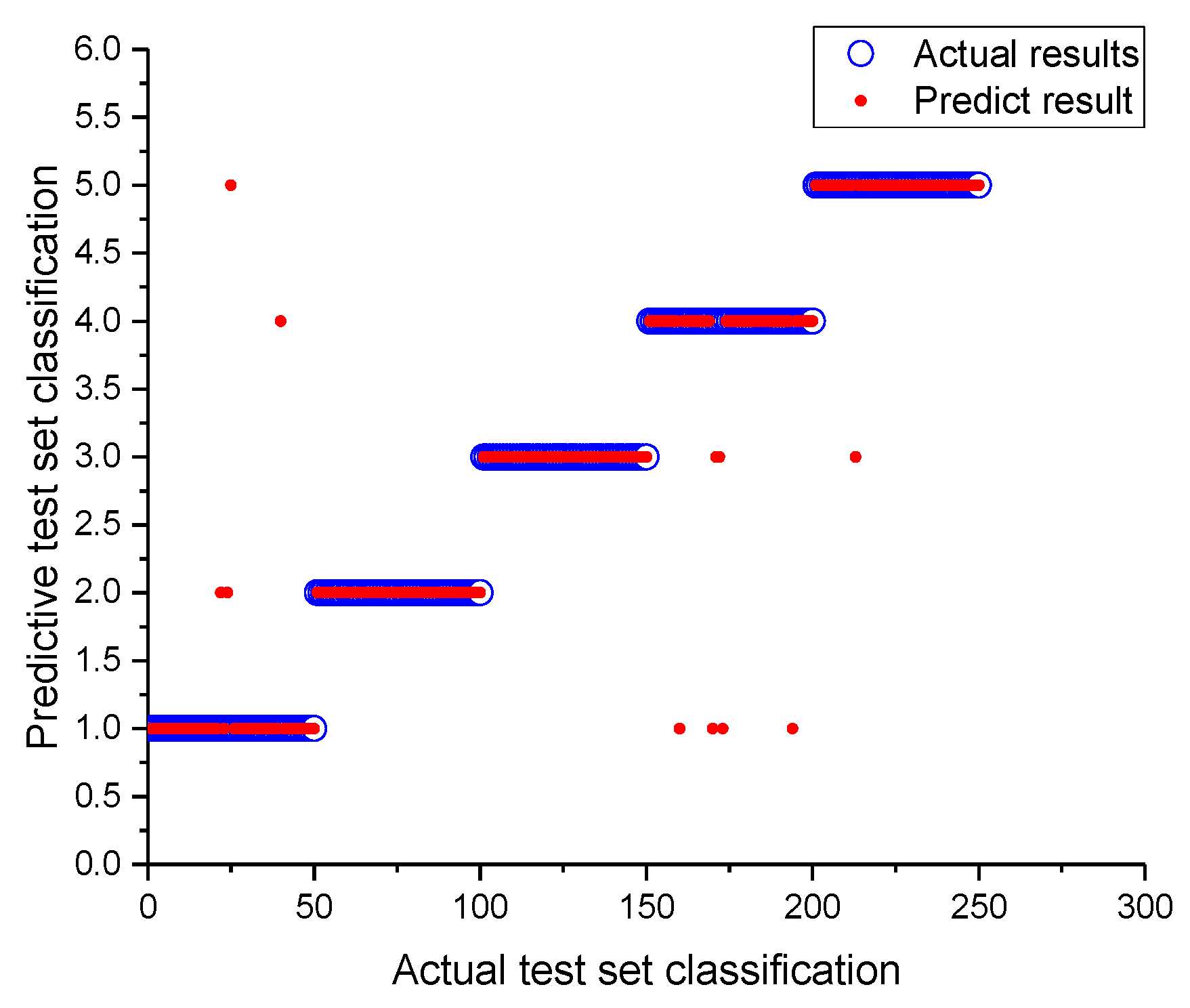
5.3. Comparison and Analysis of Diagnostic Method Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Barrett, W.J.; Rembold, J.P.; Burcham, F.W. Flight test of a full authority Digital Electronic Engine Control system in an F-15 aircraft. AIAA J. 1981. [Google Scholar] [CrossRef]
- Chen, Q. Some measures to improve engine reliability. Civ. Aviat. Technol. 2002, 1, 39–41. [Google Scholar]
- Yan, J. Research on Fault Diagnosis Expert System of Aviation Piston Engine Based on Fault Tree Analysis. Ph.D. Thesis, University of Electronic Science and Technology of China, Chengdu, China, 2010. [Google Scholar] [CrossRef]
- Akhenak, A.; Chadli, M.; Maquin, D.; Ragot, J. Sliding mode multiple observer for fault detection and isolation. In Proceedings of the 42nd IEEE International Conference on Decision and Control, Maui, HI, USA, 9–12 December 2003. [Google Scholar] [CrossRef]
- Jiang, B.; Staroswiecki, M.; Cocquempot, V. Fault Accommodation for Nonlinear Dynamic Systems. IEEE Trans. Autom. Control 2006, 51, 1578–1583. [Google Scholar] [CrossRef]
- Jiang, B.; Gao, Z.; Shi, P.; Xu, Y. Adaptive Fault-Tolerant Tracking Control of Near-Space Vehicle Using Takagi–Sugeno Fuzzy Models. IEEE Trans. Fuzzy Syst. 2010, 18, 1000–1007. [Google Scholar] [CrossRef]
- Chadli, M.; Davoodi, M.; Meskin, N. Distributed state estimation, fault detection and isolation filter design for heterogeneous multi-agent linear parameter-varying systems. IET Control Theory Appl. 2017, 11, 254–262. [Google Scholar] [CrossRef]
- Sebastiani, F. Machine learning in automated text categorization. ACM Comput. Surv. 2002, 34, 1–47. [Google Scholar] [CrossRef]
- Ye, Z.; Sun, J. Probabilistic neural networks based engine fault diagnosis. Acta Aeronaut. Astronaut. Sin. 2002, 23, 155–157. [Google Scholar] [CrossRef]
- Bedekar, P.P.; Bhide, S.R.; Kale, V.S. Fault section estimation in power system using Hebb’s rule and continuous genetic algorithm. Int. J. Electr. Power Energy Syst. 2011, 33, 457–465. [Google Scholar] [CrossRef]
- Ni, J. Reasearch on Fault Diagnosis and Hardware-in-loop Simulation for Actuator of Aero-Engine. Ph.D. Thesis, Nanjing University of Aeronautics and Astronautics, Nanjing, China, 2016. [Google Scholar]
- Ding, L. Engine Fault Diagnosis Based on IMF Band Energy Characteristics and Support Vector Machine. Intern. Combust. Engines Fitt. 2018, 5, 105–107. [Google Scholar]
- Dai, Y.; Wang, J.; Liu, G. Optimum Decoder for Barni’s Multiplicative Watermarking Based on Minimum Bayesian Risk Criterion. In Proceedings of the 2008 IEEE International Conference on Networking, Sensing and Control, Sanya, China, 6–8 April 2008 . [Google Scholar] [CrossRef]
- Lu, Y. Stock Market Trend Forcast Based on Parameter Optimized Support Vector Model. Ph.D. Thesis, Zhejiang Gongshang University, Hangzhou, China, 2013. [Google Scholar] [CrossRef]
- Wang, F. Research and Application of Support Vector Machine Algorithm. Ph.D. Thesis, Jiangnan University, Wuxi, China, 2008. [Google Scholar]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin, Germany, 1995. [Google Scholar] [CrossRef]
- Chen, G. Bayesian layered model based on MCMC simulation and its application. Sci. Technol. J. Electron. Ed. 2015, 4, 76–77. [Google Scholar] [CrossRef]
- Chen, M. Principles and Examples of MATLAB Neural Network; Tsinghua University Press: Beijing, China, 2013. [Google Scholar]
- Chen, Y.; Xiong, Q. Support Vector Machine method Application Tutorial; Meteorological Press: Beijing, China, 2011. [Google Scholar]
- Yang, X.; Hao, Z. Algorithm Design and Analysis of Support Vector Machine; Science Press: Beijing, China, 2013. [Google Scholar]
- Gong, C.; Wang, Z. Proficient in MATLAB Optimization Calculation; Publishing House of Electronics Industry: Beijing, China, 2014. [Google Scholar]
- Xu, J.; Li, Z.; Wang, H.; Qian, F. A new particle swarm optimization for multiobjective problem. Comput. Digit. Eng. 2006, 34, 31–34. [Google Scholar] [CrossRef]

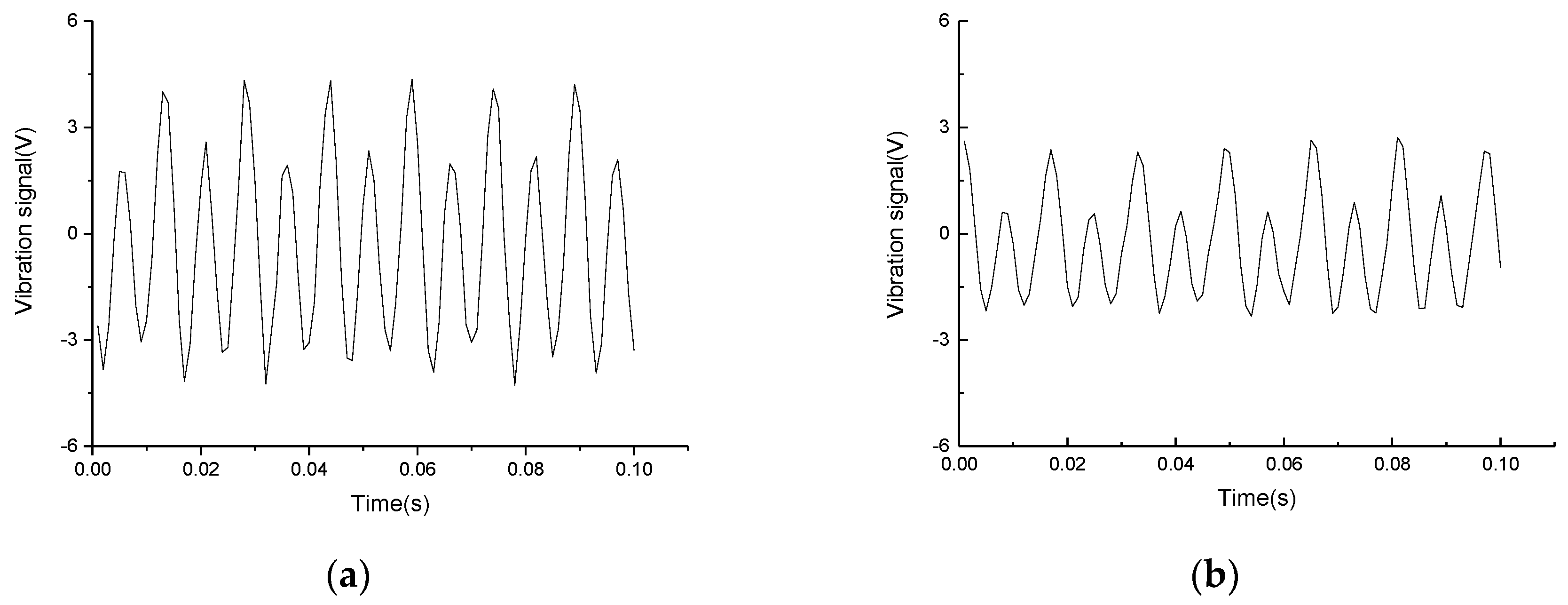




{kind=link}
{kind=link}
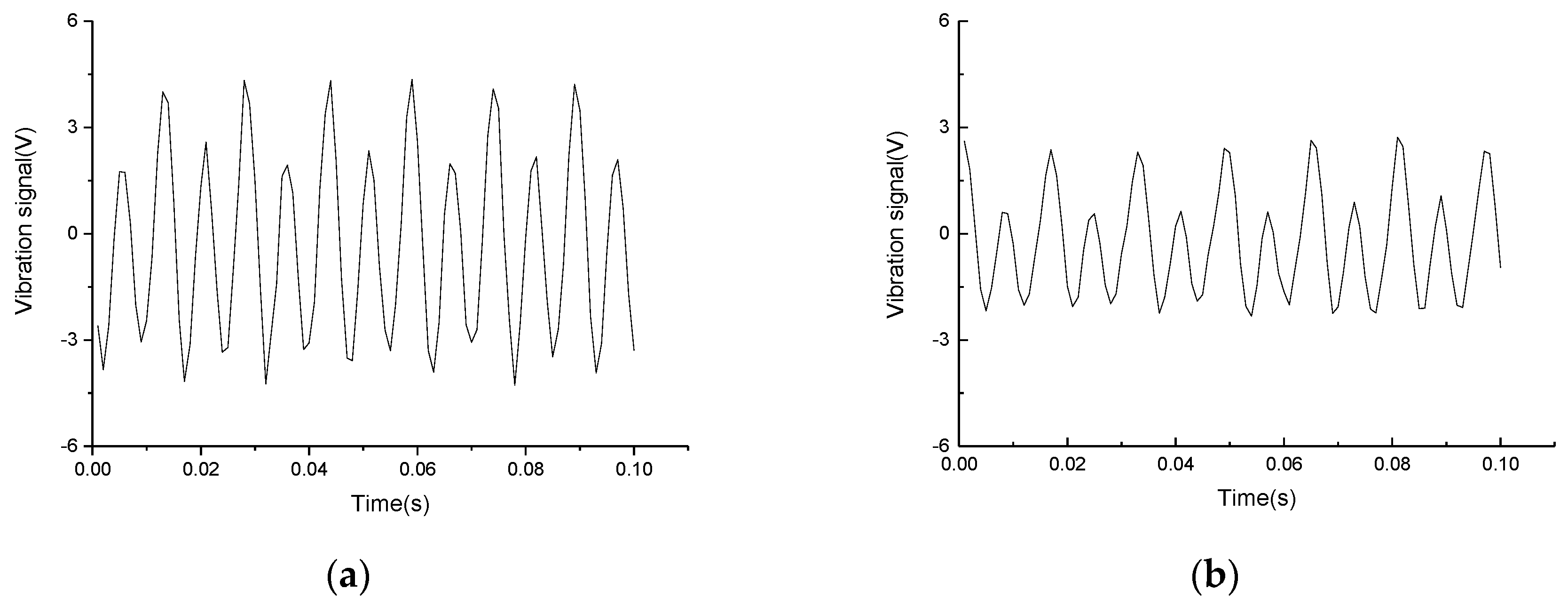{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fault Type | The Signature Signals Required for Establishing the Mapping |
|---|---|
| The fuel injection failure of the injector | Throttle opening, air-fuel ratio signal and vibration peak |
| Low fuel supply pressure | Rotating speed signal, vibration peak, air-fuel ratio signal, throttle opening, torque signal and cylinder temperature signal |
| Leaks of the exhaust pipe | Air-fuel ratio signal |
| The intermittent flameout of engine | Air-fuel ratio signal, rotating speed signal and vibration frequency domain signal |
| Rotating Speed (r/min) | Throttle Opening (%) | Vibration Frequency (Hz) | Vibration Peak Value (V) | Cylinder Temperature of Number 1 (°C) | Cylinder Temperature of Number 2 (°C) | Number One Cylinder λ | Number Two-Cylinder λ | State |
|---|---|---|---|---|---|---|---|---|
| 3539 | 16.563 | 59 | 2.30 | 158 | 159 | 0.98 | 1.02 | 1 |
| 3508 | 14.813 | 59 | 2.82 | 159 | 158 | 0.91 | 0.93 | 2 |
| 3494 | 17.813 | 58 | 1.95 | 138 | 151 | 1.13 | 1.26 | 3 |
| 3575 | 16.813 | 58 | 2.28 | 157 | 159 | 1.31 | 1.03 | 4 |
| 3461 | 16.875 | 59 | 2.23 | 158 | 157 | 1.20 | 1.23 | 5 |
| Kernel Function | Accuracy | SVM Train Parameter Options |
|---|---|---|
| Linear kernel function | 96.4% | c = 2, g = 1, t = 0 |
| Polynomial kernel function | 98.4% | c = 2, g = 1, t = 1 |
| Radial basis kernel function | 93.6% | c = 2, g = 1, t = 2 |
| Sigmoid kernel function | 40.4% | c = 2, g = 1, t = 3 |
| Classification Model | Classification Accuracy (%) | Optimized Accuracy with PSO (%) |
|---|---|---|
| Probabilistic neural network | 92.8 | 96.4 |
| C/v-SVM linear kernel function | 96.4/96.4 | 97.6/98.4 |
| C/v-SVM polynomial kernel function | 98.4/84.4 | 98.4/98.8 |
| C/v-SVM radial basis kernel function | 93.6/99.2 | 99.2/96.8 |
| C/v-SVM Sigmoid kernel function | 40.4/87.6 | 98.8/92.4 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, B.; Ke, H.; Ma, X.; Yu, B. Fault Diagnosis Method for Engine Control System Based on Probabilistic Neural Network and Support Vector Machine. Appl. Sci. 2019, 9, 4122. https://doi.org/10.3390/app9194122
Wang B, Ke H, Ma X, Yu B. Fault Diagnosis Method for Engine Control System Based on Probabilistic Neural Network and Support Vector Machine. Applied Sciences. 2019; 9(19):4122. https://doi.org/10.3390/app9194122
Chicago/Turabian StyleWang, Bo, Hongwei Ke, Xiaodong Ma, and Bing Yu. 2019. "Fault Diagnosis Method for Engine Control System Based on Probabilistic Neural Network and Support Vector Machine" Applied Sciences 9, no. 19: 4122. https://doi.org/10.3390/app9194122
APA StyleWang, B., Ke, H., Ma, X., & Yu, B. (2019). Fault Diagnosis Method for Engine Control System Based on Probabilistic Neural Network and Support Vector Machine. Applied Sciences, 9(19), 4122. https://doi.org/10.3390/app9194122